Acontece que os sistemas estão com erros, diminuem a velocidade, quebram. Quanto maior o sistema, mais difícil é encontrar a causa. Para descobrir por que algo não está funcionando como o esperado, para corrigir ou evitar problemas futuros, é preciso olhar para dentro. Para isso, os sistemas devem possuir a propriedade de observabilidade , que é alcançada pela instrumentação no sentido amplo da palavra.No HighLoad ++, Peter Zaitsev (Percona) revisou a infraestrutura disponível para rastreamento no Linux e falou sobre o bpfTrace, que (como o nome indica) oferece muitas vantagens. Fizemos uma versão em texto do relatório, para que fosse conveniente revisar os detalhes e sempre havia materiais adicionais à mão.A instrumentação pode ser dividida em dois grandes blocos:- Estático , quando a coleta de informações é conectada ao código: registros de registro, contadores, hora, etc.
- Dinâmico , quando o código não é instrumentado por si só, mas é possível fazê-lo quando necessário.
Outra opção de classificação é baseada na abordagem de registro de dados:- Rastreamento - eventos são gerados se um determinado código tiver funcionado.
- Amostragem - o status do sistema é verificado, por exemplo, 100 vezes por segundo e determina o que está acontecendo nele.
A instrumentação estática existe há muitos anos e está em quase tudo. No Linux, muitas ferramentas padrão, como Vmstat ou top, o utilizam. Eles lêem dados de procfs, onde, grosso modo, diferentes temporizadores e contadores são gravados a partir do código do kernel.Mas você não pode inserir muitos desses contadores; não pode cobrir tudo no mundo com eles. Portanto, a instrumentação dinâmica pode ser útil, o que permite que você assista exatamente o que precisa. Por exemplo, se houver algum problema com a pilha TCP / IP, você poderá aprofundar-se e instruir detalhes específicos.
Dtrace
O DTrace é uma das primeiras estruturas conhecidas de rastreamento dinâmico criadas pela Sun Microsystems. Começou a ser fabricado em 2001 e, pela primeira vez, foi lançado no Solaris 10 em 2005. A abordagem acabou sendo muito popular e, posteriormente, entrou em muitas outras distribuições.Curiosamente, o DTrace permite instrumentar o espaço do kernel e o espaço do usuário. Você pode colocar rastreamentos em qualquer chamada de função e instruir programas especificamente: introduzir pontos de rastreamento especiais do DTrace, que para os usuários podem ser mais compreensíveis do que os nomes de serviço das funções.Isso foi especialmente importante para o Solaris, porque não é um sistema operacional aberto. Não foi possível apenas olhar o código e entender que o ponto de rastreamento precisa ser colocado nessa função, como agora pode ser feito no novo software Linux de código aberto.Um dos recursos exclusivos, especialmente na época, do DTrace é que, embora o rastreamento não esteja ativado, não custa nada . Funciona de tal maneira que simplesmente substitui algumas instruções da CPU por uma chamada do DTrace, que executa essas instruções quando retorna.No DTrace, a instrumentação é escrita em uma linguagem D especial, semelhante a C e Awk.Posteriormente, o DTrace apareceu em quase todos os lugares, exceto no Linux: no MacOS em 2007, no FreeBSD em 2008, no NetBSD em 2010. A Oracle em 2011 incluiu o DTrace no Oracle Unbreakable Linux. Mas poucas pessoas usam o Oracle Linux e o DTrace nunca entrou no Linux principal.Curiosamente, em 2017, a Oracle finalmente licenciou o DTrace sob a GPLv2, o que em princípio tornou possível incluí-lo no Linux principal sem dificuldades de licenciamento, mas já era tarde demais. Naquela época, o Linux tinha um bom BPF, que era usado principalmente para padronização.O DTrace será incluído no Windows, agora está disponível em algumas versões de teste.Rastreio do Linux
O que há no Linux em vez do DTrace? De fato, no Linux há muitas coisas na melhor (ou pior) manifestação do espírito de código aberto, várias estruturas de rastreamento diferentes se acumularam ao longo desse tempo. Portanto, descobrir o que não é tão simples.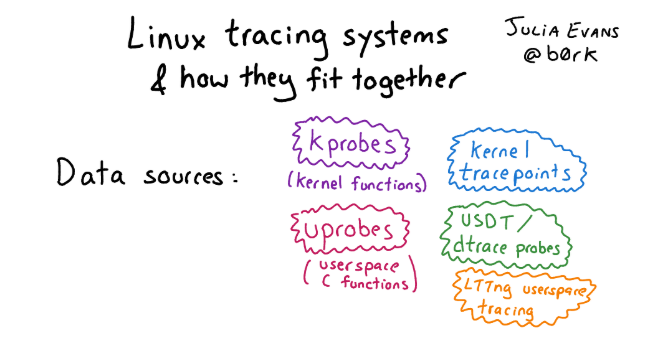 Se você deseja se familiarizar com essa variedade e se interessar por história, consulte o artigo com imagens e uma descrição detalhada das abordagens para rastreamento no Linux.Se falamos sobre a infraestrutura para rastreamento no Linux em geral, existem três níveis:
Se você deseja se familiarizar com essa variedade e se interessar por história, consulte o artigo com imagens e uma descrição detalhada das abordagens para rastreamento no Linux.Se falamos sobre a infraestrutura para rastreamento no Linux em geral, existem três níveis:- Interface para instrumentação do kernel: Kprobe, Uprobe, Dtrace probe, etc.
- «», . , probe, , user space . : , user space, Kernel Module, - , eBPF.
- -, , : Perf, SystemTap, SysDig, BCC .. bpfTtrace , , .
eBPF — Linux
Com todas essas estruturas, o eBPF se tornou o padrão no Linux nos últimos anos. Esta é uma ferramenta mais avançada, altamente flexível e eficaz que permite quase tudo.O que é o eBPF e de onde ele veio? De fato, o eBPF é um Extended Berkeley Packet Filter, e o BPF foi desenvolvido em 1992 como uma máquina virtual para filtragem eficiente de pacotes por um firewall. Inicialmente, ele não tinha relação com monitoramento, observabilidade ou rastreamento.Nas versões mais modernas, o eBPF foi expandido (daí a palavra estendida), como uma estrutura comum para lidar com eventos . As versões atuais são integradas ao compilador JIT para maior eficiência.Diferenças do eBPF do BPF clássico:- registradores adicionados;
- uma pilha apareceu;
- Existem estruturas de dados adicionais (mapas).
 Agora, as pessoas costumam esquecer que havia um BPF antigo, e o eBPF é simplesmente chamado de BPF. Na maioria das expressões modernas, eBPF e BPF são a mesma coisa. Portanto, a ferramenta é chamada bpfTrace, não eBpfTrace.O eBPF está incluído no Linux principal desde 2014 e está gradualmente incluído em muitas ferramentas Linux, incluindo Perf, SystemTap, SysDig. Existe uma padronização.Curiosamente, o desenvolvimento ainda está em andamento. Os kernels modernos suportam o eBPF cada vez melhor.
Agora, as pessoas costumam esquecer que havia um BPF antigo, e o eBPF é simplesmente chamado de BPF. Na maioria das expressões modernas, eBPF e BPF são a mesma coisa. Portanto, a ferramenta é chamada bpfTrace, não eBpfTrace.O eBPF está incluído no Linux principal desde 2014 e está gradualmente incluído em muitas ferramentas Linux, incluindo Perf, SystemTap, SysDig. Existe uma padronização.Curiosamente, o desenvolvimento ainda está em andamento. Os kernels modernos suportam o eBPF cada vez melhor.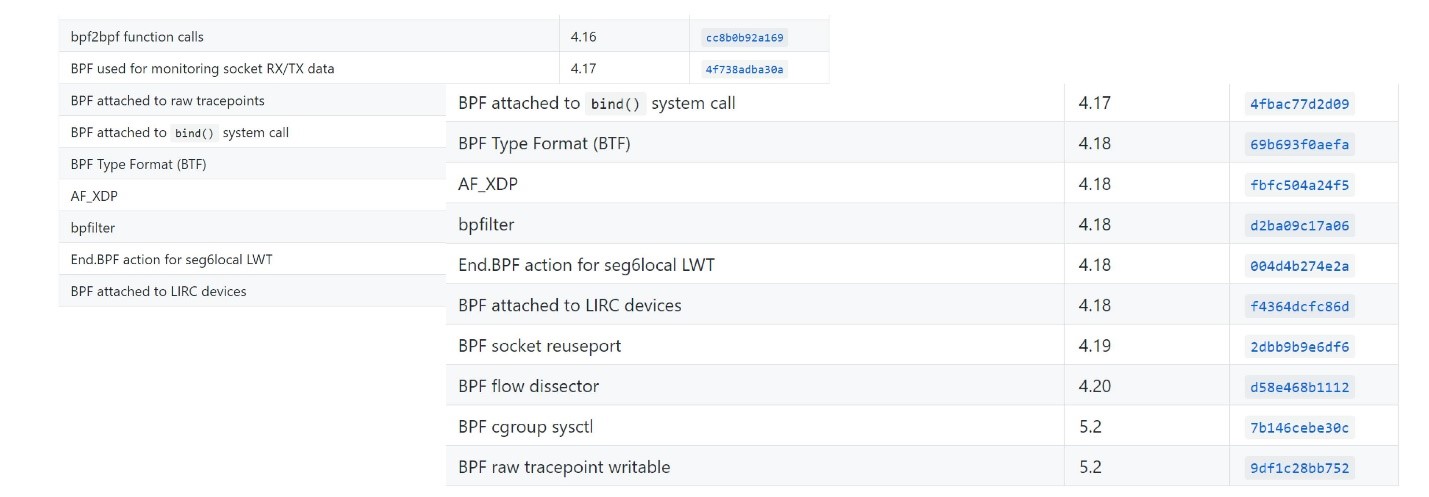 Você pode ver quais versões modernas do kernel apareceram aqui .
Você pode ver quais versões modernas do kernel apareceram aqui .Programas EBPF
Então, o que é eBPF e por que é interessante?O eBPF é um programa em seu código de código especial , que é incluído diretamente no kernel e executa o processamento de eventos de rastreamento. Além disso, o fato de ser feito em um bytecode especial permite que o kernel realize certas verificações de que o código é bastante seguro. Por exemplo, verifique se ele não usa loops, porque o loop na seção crítica do kernel pode travar o sistema inteiro.Mas isso não permite ser completamente seguro. Por exemplo, se você escrever um programa eBPF muito complexo, insira-o em um evento no kernel que ocorra 10 milhões de vezes por segundo, então tudo poderá ficar muito lento. Mas, ao mesmo tempo, o eBPF é muito mais seguro do que a abordagem antiga, quando apenas alguns Módulos do Kernel foram inseridos através do insmod, e qualquer coisa poderia estar nesses módulos. Se alguém cometer um erro, ou simplesmente por incompatibilidade binária, todo o núcleo poderá cair.O código eBPF pode ser compilado pelo LLVM Clang, ou seja, geralmente usa um subconjunto de C para criar programas eBPF, o que, é claro, é bastante complicado. E é importante que a compilação dependa do kernel: cabeçalhos são usados para entender para que estruturas são usadas e para que são usadas, etc. Isso não é muito conveniente no sentido de que alguns módulos relacionados a um núcleo específico são sempre fornecidos ou precisam ser recompilados.O diagrama mostra como o eBPF funciona. http://www.brendangregg.com/ebpf.htmlO usuário cria um programa eBPF. Além disso, o kernel, por sua vez, verifica e carrega. Depois disso, o eBPF pode se conectar a várias ferramentas para rastreamentos, informações de processo, salvá-lo em mapas (estrutura de dados para armazenamento temporário). Em seguida, o programa do usuário pode ler estatísticas, receber eventos de perf, etc.Ele mostra quais recursos do eBPF em quais versões dos kernels do Linux.
http://www.brendangregg.com/ebpf.htmlO usuário cria um programa eBPF. Além disso, o kernel, por sua vez, verifica e carrega. Depois disso, o eBPF pode se conectar a várias ferramentas para rastreamentos, informações de processo, salvá-lo em mapas (estrutura de dados para armazenamento temporário). Em seguida, o programa do usuário pode ler estatísticas, receber eventos de perf, etc.Ele mostra quais recursos do eBPF em quais versões dos kernels do Linux.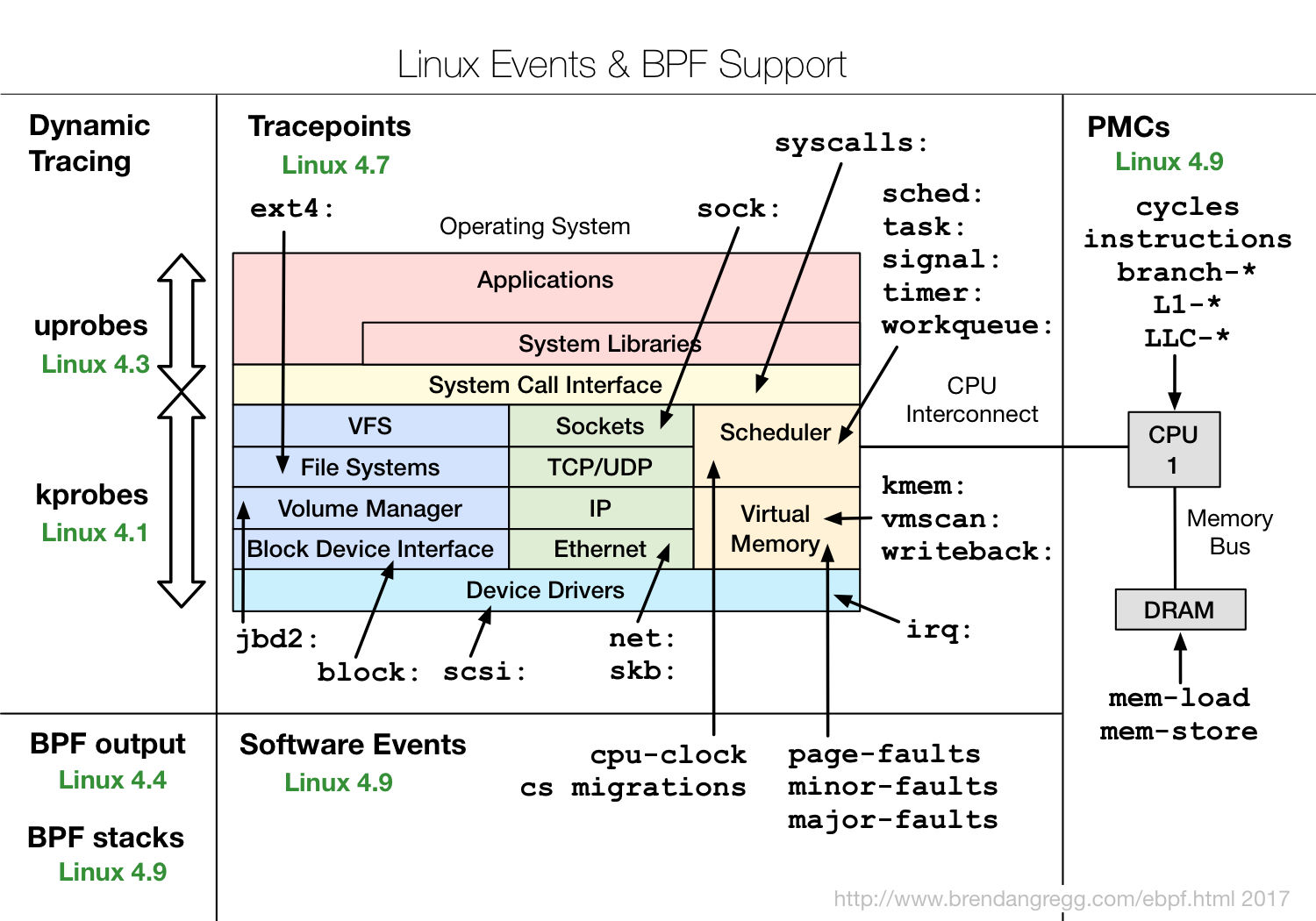 Pode-se observar que quase todos os subsistemas do kernel Linux são cobertos, além de haver boa integração com os dados de hardware, o eBPF tem acesso a todos os tipos de falta de cache ou previsão de falta de ramificação, etc.Se você está interessado no eBPF, confira o projeto IO Visor, ele contém a maioria das ferramentas. A empresa IO Visor está envolvida em seu desenvolvimento, elas terão as versões mais recentes e uma documentação muito boa. Cada vez mais ferramentas eBPF estão aparecendo nas distribuições Linux, então eu recomendo que você sempre use as últimas versões disponíveis.
Pode-se observar que quase todos os subsistemas do kernel Linux são cobertos, além de haver boa integração com os dados de hardware, o eBPF tem acesso a todos os tipos de falta de cache ou previsão de falta de ramificação, etc.Se você está interessado no eBPF, confira o projeto IO Visor, ele contém a maioria das ferramentas. A empresa IO Visor está envolvida em seu desenvolvimento, elas terão as versões mais recentes e uma documentação muito boa. Cada vez mais ferramentas eBPF estão aparecendo nas distribuições Linux, então eu recomendo que você sempre use as últimas versões disponíveis.Desempenho EBPF
Em termos de desempenho, o eBPF é bastante eficaz. Para entender quanto e se há sobrecarga, você pode adicionar uma sonda, que se contrai várias vezes por segundo e verificar quanto tempo leva para executá-la.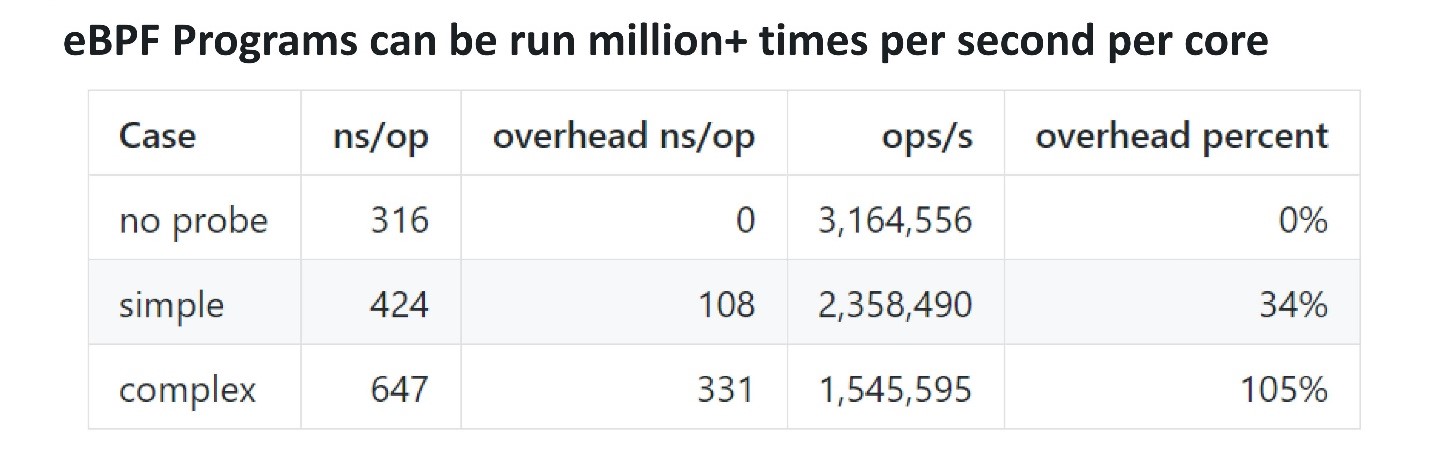 Os caras da Cloudflare fizeram uma referência . Uma simples análise do eBPF levou cerca de 100 ns, enquanto uma mais complexa levou 300 ns. Isso significa que mesmo uma sonda complexa pode ser chamada em um único núcleo cerca de 3 milhões de vezes por segundo. Se o probe disparar 100 mil ou um milhão de vezes por segundo em um processador com vários núcleos, isso não afetará muito o desempenho.
Os caras da Cloudflare fizeram uma referência . Uma simples análise do eBPF levou cerca de 100 ns, enquanto uma mais complexa levou 300 ns. Isso significa que mesmo uma sonda complexa pode ser chamada em um único núcleo cerca de 3 milhões de vezes por segundo. Se o probe disparar 100 mil ou um milhão de vezes por segundo em um processador com vários núcleos, isso não afetará muito o desempenho.Frontend para eBPF
Se você está interessado no eBPF e no tópico Observabilidade em geral, provavelmente já ouviu falar de Brendan Gregg. Ele escreve e fala muito sobre isso e criou uma imagem tão bonita que mostra ferramentas para o eBPF. Aqui você pode ver que, por exemplo, você pode usar o Raw BPF - basta escrever pelo codecode - isso fornecerá uma gama completa de recursos, mas será muito difícil trabalhar com ele. O BPF bruto é sobre como escrever um aplicativo Web no assembler - em princípio, é possível, mas sem a necessidade de fazê-lo.Curiosamente, o bpfTrace, por um lado, permite obter quase tudo, desde BCC e BPF bruto, mas é muito mais fácil de usar.Na minha opinião, duas ferramentas são mais úteis:
Aqui você pode ver que, por exemplo, você pode usar o Raw BPF - basta escrever pelo codecode - isso fornecerá uma gama completa de recursos, mas será muito difícil trabalhar com ele. O BPF bruto é sobre como escrever um aplicativo Web no assembler - em princípio, é possível, mas sem a necessidade de fazê-lo.Curiosamente, o bpfTrace, por um lado, permite obter quase tudo, desde BCC e BPF bruto, mas é muito mais fácil de usar.Na minha opinião, duas ferramentas são mais úteis:- Cco. Apesar do fato de que, de acordo com o esquema de Gregg, o BCC é complexo, inclui muitas funções prontas que podem ser simplesmente iniciadas na linha de comando.
- BpfTrace . Ele permite que você escreva seu próprio kit de ferramentas ou use soluções prontas.
Você pode imaginar como é mais fácil escrever no bpfTrace se observar o código da mesma ferramenta em duas versões.
DTrace vs bpfTrace
Em geral, o DTrace e o bpfTrace são usados para a mesma coisa. http://www.brendangregg.com/blog/2018-10-08/dtrace-for-linux-2018.htmlA diferença é que também há um CBC no ecossistema BPF que pode ser usado para ferramentas complexas. Portanto, não há equivalente de Cco no DTrace para criar kits de ferramentas complexos, geralmente use o pacote Shell + DTrace.Ao criar o bpfTrace, não havia tarefa para emular completamente o DTrace. Ou seja, você não pode pegar um script do DTrace e executá-lo no bpfTrace. Mas isso não faz muito sentido, porque a lógica nas ferramentas de nível inferior é bastante simples. Geralmente é mais importante entender com quais pontos de rastreamento você precisa se conectar, e os nomes das chamadas do sistema e o que eles fazem diretamente em um nível baixo diferem no Linux, Solaris, FreeBSD. É aí que a diferença surge.Nesse caso, o bpfTrace é criado 15 anos após o DTrace. Possui alguns recursos adicionais que o DTrace não possui. Por exemplo, ele pode fazer rastreamentos de pilha.Mas é claro, muito é herdado do DTrace. Por exemplo, nomes de funções e sintaxe são semelhantes , embora não sejam completamente equivalentes.Os scripts DTrace e bpfTrace são próximos no tamanho do código e semelhantes nos recursos de complexidade e idioma.
http://www.brendangregg.com/blog/2018-10-08/dtrace-for-linux-2018.htmlA diferença é que também há um CBC no ecossistema BPF que pode ser usado para ferramentas complexas. Portanto, não há equivalente de Cco no DTrace para criar kits de ferramentas complexos, geralmente use o pacote Shell + DTrace.Ao criar o bpfTrace, não havia tarefa para emular completamente o DTrace. Ou seja, você não pode pegar um script do DTrace e executá-lo no bpfTrace. Mas isso não faz muito sentido, porque a lógica nas ferramentas de nível inferior é bastante simples. Geralmente é mais importante entender com quais pontos de rastreamento você precisa se conectar, e os nomes das chamadas do sistema e o que eles fazem diretamente em um nível baixo diferem no Linux, Solaris, FreeBSD. É aí que a diferença surge.Nesse caso, o bpfTrace é criado 15 anos após o DTrace. Possui alguns recursos adicionais que o DTrace não possui. Por exemplo, ele pode fazer rastreamentos de pilha.Mas é claro, muito é herdado do DTrace. Por exemplo, nomes de funções e sintaxe são semelhantes , embora não sejam completamente equivalentes.Os scripts DTrace e bpfTrace são próximos no tamanho do código e semelhantes nos recursos de complexidade e idioma.
bpfTrace
Vamos ver com mais detalhes o que há no bpfTrace, como ele pode ser usado e o que é necessário para isso.Requisitos de Linux para usar o bpfTrace: Para usar todos os recursos, você precisa de uma versão de pelo menos 4.9. O BpfTrace permite fazer várias sondas diferentes, começando com uprobe para instrumentar uma chamada de função em um aplicativo de usuário, sondas de kernel, etc.
Para usar todos os recursos, você precisa de uma versão de pelo menos 4.9. O BpfTrace permite fazer várias sondas diferentes, começando com uprobe para instrumentar uma chamada de função em um aplicativo de usuário, sondas de kernel, etc. Curiosamente, existe um equivalente de uretprobe para uma função de uprobe personalizada. Para o kernel, a mesma coisa é kprobe e kretprobe. Isso significa que, de fato, na estrutura de rastreamento, você pode gerar eventos quando a função é chamada e após a conclusão dessa função - isso geralmente é usado para cronometrar. Ou você pode analisar os valores que a função retornou e agrupá-los de acordo com os parâmetros com os quais a função foi chamada. Se você pegar uma chamada de função e retornar dela, poderá fazer muitas coisas legais.Dentro do bpfTrace, funciona assim: escrevemos um programa bpf que é analisado, convertido em C e processado através do Clang, que gera código de byte bpf, após o qual o programa é carregado.
Curiosamente, existe um equivalente de uretprobe para uma função de uprobe personalizada. Para o kernel, a mesma coisa é kprobe e kretprobe. Isso significa que, de fato, na estrutura de rastreamento, você pode gerar eventos quando a função é chamada e após a conclusão dessa função - isso geralmente é usado para cronometrar. Ou você pode analisar os valores que a função retornou e agrupá-los de acordo com os parâmetros com os quais a função foi chamada. Se você pegar uma chamada de função e retornar dela, poderá fazer muitas coisas legais.Dentro do bpfTrace, funciona assim: escrevemos um programa bpf que é analisado, convertido em C e processado através do Clang, que gera código de byte bpf, após o qual o programa é carregado. O processo é bastante difícil, então existem limitações. Em servidores poderosos, o bpfTrace funciona bem. Mas arrastar o Clang para um pequeno dispositivo incorporado para descobrir o que está acontecendo não é uma boa ideia. Ply é adequado para isso . Obviamente, ele não possui todos os recursos do bpfTrace, mas gera diretamente o bytecode.
O processo é bastante difícil, então existem limitações. Em servidores poderosos, o bpfTrace funciona bem. Mas arrastar o Clang para um pequeno dispositivo incorporado para descobrir o que está acontecendo não é uma boa ideia. Ply é adequado para isso . Obviamente, ele não possui todos os recursos do bpfTrace, mas gera diretamente o bytecode.Suporte Linux
Uma versão estável do bpfTrace foi lançada há cerca de um ano, por isso não está disponível em distribuições Linux mais antigas. É melhor pegar pacotes ou compilar a versão mais recente que o IO Visor distribui.Curiosamente, o último Ubuntu LTS 18.04 não possui o bpfTrace, mas pode ser entregue usando o pacote snap. Por um lado, isso é conveniente, mas por outro lado, devido à maneira como os pacotes snap são criados e isolados, nem todas as funções funcionam. Para rastreamento de kernel, um pacote com snap funciona bem; para rastreamento de usuário, pode não funcionar corretamente.
Exemplo de rastreamento de processo
Considere o exemplo mais simples que permite obter estatísticas sobre solicitações de E / S:bpftrace -e 'kprobe:vfs_read { @start[tid] = nsecs; }
kretprobe:vfs_read /@start[tid]/ { @ns[comm] = hist(nsecs - @start[tid]); delete(@start[tid]); }'
Aqui nos conectamos à função vfs_read, kretprobe e kprobe. Além disso, para cada ID de thread (tid), ou seja, para cada solicitação, rastreamos o início e o fim de sua execução. Os dados podem ser agrupados não apenas pela totalidade de todo o sistema, mas também por diferentes processos. Abaixo está a saída IO do MySQL. A distribuição de E / S bimodal clássica é visível. Um grande número de solicitações rápidas são dados que são lidos no cache. O segundo pico é a leitura de dados do disco, onde a latência é muito maior.Você pode salvar isso como um script (a extensão bt geralmente é usada), escrever comentários, formatá-lo e apenas usá-lo ainda mais
A distribuição de E / S bimodal clássica é visível. Um grande número de solicitações rápidas são dados que são lidos no cache. O segundo pico é a leitura de dados do disco, onde a latência é muito maior.Você pode salvar isso como um script (a extensão bt geralmente é usada), escrever comentários, formatá-lo e apenas usá-lo ainda mais #bpftrace read.bt.// read.bt file
tracepoint:syscalls:sys_enter_read
{
@start[tid] = nsecs;
}
tracepoint:syscalls:sys_exit_read / @start[tid]/
{
@times = hist(nsecs - @start[tid]);
delete(@start[tid]);
}
O conceito geral da linguagem é bastante simples.- Sintaxe: selecione o probe para conectar
probe[,probe,...] /filter/ { action }. - Filtro: especifique um filtro, por exemplo, apenas dados em um determinado processo de um determinado Pid.
- Ação: um miniprograma que converte diretamente em um programa bpf e é executado quando o bpfTrace é chamado.
Mais detalhes podem ser encontrados aqui .Ferramentas Bpftrace
O BpfTrace também possui uma caixa de ferramentas. Agora, muitas ferramentas simples no BCC são implementadas no bpfTrace. A coleção ainda é pequena, mas há algo que não está no BCC. Por exemplo, o killsnoop permite rastrear os sinais causados por kill ().Se você estiver interessado em examinar o código bpf, no bpfTrace poderá
A coleção ainda é pequena, mas há algo que não está no BCC. Por exemplo, o killsnoop permite rastrear os sinais causados por kill ().Se você estiver interessado em examinar o código bpf, no bpfTrace poderá -vver o código de bytes gerado. Isso é útil se você deseja entender uma sonda pesada ou não. Depois de analisar o código e apenas ter estimado seu tamanho (uma página ou duas), você pode entender como é complicado.
Exemplo de rastreamento do MySQL
Deixe-me mostrar um exemplo do MySQL, como ele funciona. O MySQL possui uma função dispatch_commandna qual todas as execuções de consultas do MySQL ocorrem.bpftrace -e 'uprobe:/usr/sbin/mysqld:dispatch_command { printf("%s\n", str(arg2)); }'
failed to stat uprobe target file /usr/sbin/mysqld: No such file or directory
Eu só queria conectar uma sonda para imprimir o texto das consultas que chegam ao MySQL - uma tarefa primitiva. Tem um problema - diz que não existe esse arquivo. Como não quando aqui está:root@mysql1:/# ls -la /usr/sbin/mysqld
-rwxr-xr-x 1 root root 60718384 Oct 25 09:19 /usr/sbin/mysqld
Essas são apenas surpresas com o snap. Se definido por snap, pode haver problemas no nível do aplicativo.Então eu instalei através da versão apt, um Ubuntu mais recente, iniciei novamente:root@mysql1:~# bpftrace -e 'uprobe:/usr/sbin/mysqld:dispatch_command { printf("%s\n", str(arg2)); }'
Attaching 1 probe...
Could not resolve symbol: /usr/sbin/mysqld:dispatch_command
“Não existe esse símbolo” - como não ?! Examino nmse existe esse símbolo ou não:root@mysql1:~# nm -D /usr/sbin/mysqld | grep dispatch_command
00000000005af770 T
_Z16dispatch_command19enum_server_commandP3THDPcjbb
root@localhost:~# bpftrace -e 'uprobe:/usr/sbin/mysqld:_Z16dispatch_command19enum_server_commandP3THDPcjbb { printf("%s\n", str(arg2)); }'
Attaching 1 probe...
select @@version_comment limit 1
select 1
Existe esse símbolo, mas como o MySQL é compilado a partir do C ++, o mangling é usado lá. Na verdade, o nome atual da função que é usada nesse comando, o seguinte: _Z16dispatch_command19enum_server_commandP3THDPcjbb. Se você o usar em uma função, poderá se conectar e obter o resultado. No ecossistema perf, muitas ferramentas tornam a desmontagem automática e o bpfTrace ainda não é capaz.Também preste atenção na bandeira -Dpara nm. É importante porque o MySQL, e agora muitos outros pacotes, vem sem símbolos dinâmicos (símbolos de depuração) - eles vêm em outros pacotes. Se você quiser usar esses caracteres, precisará de uma bandeira -D, caso contrário, nm não os verá.: ++ 25–26 , . , , .
: ++ Online . 5 900 , , -.
: DevOpsConf 2019 HighLoad++ 2019 — , .
— , .