 Nos últimos dois anos no meu tempo livre, pratiquei triatlo. Este esporte é muito popular em muitos países do mundo, especialmente nos EUA, Austrália e Europa. Atualmente, está ganhando popularidade rapidamente na Rússia e nos países da CEI. Trata-se de envolver amadores, não profissionais. Ao contrário de apenas nadar na piscina, andar de bicicleta e correr pela manhã, o triatlo envolve participar de competições e preparação sistemática para eles, mesmo sem ser profissional. Certamente entre seus amigos já existe pelo menos um "homem de ferro" ou alguém que planeja se tornar um. Massa, uma variedade de distâncias e condições, três esportes em um - tudo isso tem o potencial de formar uma grande quantidade de dados. A cada ano, várias centenas de competições de triatlo acontecem no mundo, nas quais participam centenas de milhares de pessoas.As competições são realizadas por vários organizadores. Cada um deles, é claro, publica os resultados por si só. Mas para atletas da Rússia e de alguns países da CEI, a equipeO tristats.ru coleta todos os resultados em um só lugar - em seu site com o mesmo nome. Isso torna muito conveniente procurar resultados, tanto seus quanto de seus amigos e rivais, ou mesmo seus ídolos. Mas para mim também deu a oportunidade de analisar um grande número de resultados programaticamente. Resultados publicados no trilife: leia .Este foi o meu primeiro projeto desse tipo, porque apenas recentemente comecei a fazer análise de dados em princípio, além de usar python. Portanto, quero falar sobre a implementação técnica deste trabalho, especialmente porque no processo surgiram várias nuances, às vezes exigindo uma abordagem especial. Será sobre descarte, análise, tipos e formatos de conversão, restauração de dados incompletos, criação de uma amostra representativa, visualização, vetorização e até computação paralela.O volume ficou grande, então eu quebrei tudo em cinco partes para poder dosar a informação e lembrar por onde começar depois do intervalo.Antes de prosseguir, é melhor ler primeiro meu artigo com os resultados do estudo, porque aqui essencialmente descrevemos a cozinha para sua criação. Demora 10-15 minutos.Você leu? Então vamos!
Nos últimos dois anos no meu tempo livre, pratiquei triatlo. Este esporte é muito popular em muitos países do mundo, especialmente nos EUA, Austrália e Europa. Atualmente, está ganhando popularidade rapidamente na Rússia e nos países da CEI. Trata-se de envolver amadores, não profissionais. Ao contrário de apenas nadar na piscina, andar de bicicleta e correr pela manhã, o triatlo envolve participar de competições e preparação sistemática para eles, mesmo sem ser profissional. Certamente entre seus amigos já existe pelo menos um "homem de ferro" ou alguém que planeja se tornar um. Massa, uma variedade de distâncias e condições, três esportes em um - tudo isso tem o potencial de formar uma grande quantidade de dados. A cada ano, várias centenas de competições de triatlo acontecem no mundo, nas quais participam centenas de milhares de pessoas.As competições são realizadas por vários organizadores. Cada um deles, é claro, publica os resultados por si só. Mas para atletas da Rússia e de alguns países da CEI, a equipeO tristats.ru coleta todos os resultados em um só lugar - em seu site com o mesmo nome. Isso torna muito conveniente procurar resultados, tanto seus quanto de seus amigos e rivais, ou mesmo seus ídolos. Mas para mim também deu a oportunidade de analisar um grande número de resultados programaticamente. Resultados publicados no trilife: leia .Este foi o meu primeiro projeto desse tipo, porque apenas recentemente comecei a fazer análise de dados em princípio, além de usar python. Portanto, quero falar sobre a implementação técnica deste trabalho, especialmente porque no processo surgiram várias nuances, às vezes exigindo uma abordagem especial. Será sobre descarte, análise, tipos e formatos de conversão, restauração de dados incompletos, criação de uma amostra representativa, visualização, vetorização e até computação paralela.O volume ficou grande, então eu quebrei tudo em cinco partes para poder dosar a informação e lembrar por onde começar depois do intervalo.Antes de prosseguir, é melhor ler primeiro meu artigo com os resultados do estudo, porque aqui essencialmente descrevemos a cozinha para sua criação. Demora 10-15 minutos.Você leu? Então vamos!Parte 1. Raspando e analisando
Dado: site tristats.ru . Existem dois tipos de tabelas que nos interessam. Esta é realmente uma tabela resumida de todas as raças e um protocolo dos resultados de cada uma delas.
 A tarefa número um era obter esses dados programaticamente e salvá-los para processamento adicional. Aconteceu que naquela época eu era novo em tecnologias da web e, portanto, não sabia imediatamente como fazer isso. Comecei de acordo com o que sabia - veja o código da página. Isso pode ser feito usando o botão direito do mouse ou a tecla F12 .
A tarefa número um era obter esses dados programaticamente e salvá-los para processamento adicional. Aconteceu que naquela época eu era novo em tecnologias da web e, portanto, não sabia imediatamente como fazer isso. Comecei de acordo com o que sabia - veja o código da página. Isso pode ser feito usando o botão direito do mouse ou a tecla F12 . O menu no Chrome contém duas opções: Ver código da página e Ver código . Não é a divisão mais óbvia. Naturalmente, eles dão resultados diferentes. Aquele que visualiza o código, é exatamente o mesmo que F12 - a representação html diretamente textual do que é exibido no navegador é baseada em elementos.
O menu no Chrome contém duas opções: Ver código da página e Ver código . Não é a divisão mais óbvia. Naturalmente, eles dão resultados diferentes. Aquele que visualiza o código, é exatamente o mesmo que F12 - a representação html diretamente textual do que é exibido no navegador é baseada em elementos.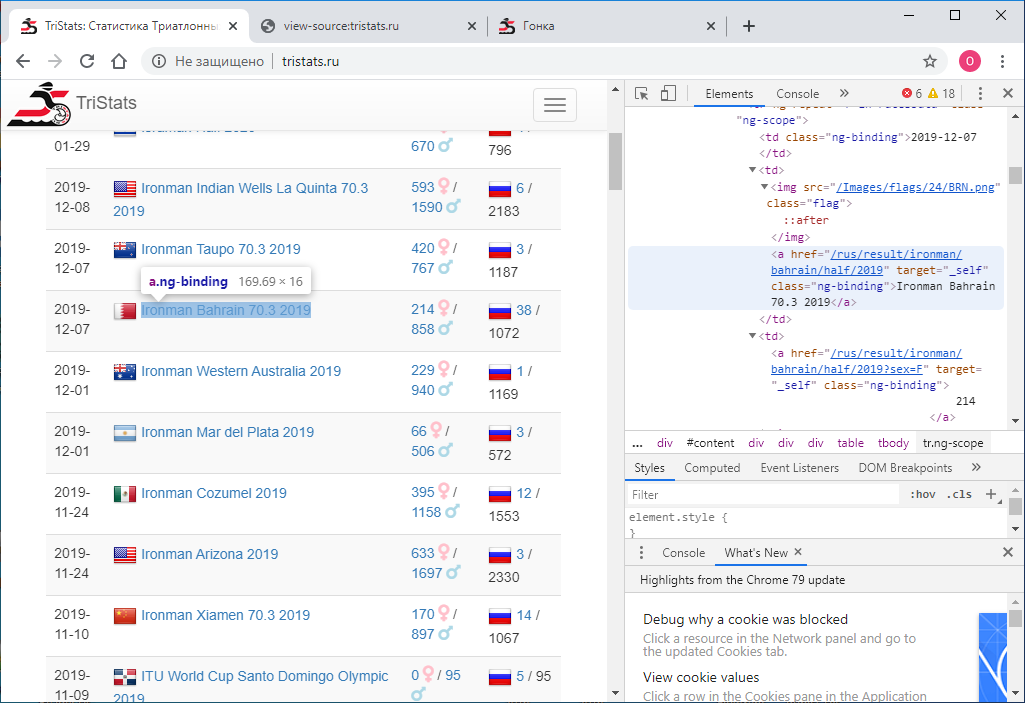 Por sua vez, visualizar o código da página fornece o código fonte da página. Também html , mas não há dados, apenas os nomes dos scripts JS que os descarregam. OK.
Por sua vez, visualizar o código da página fornece o código fonte da página. Também html , mas não há dados, apenas os nomes dos scripts JS que os descarregam. OK. Agora precisamos entender como usar o python para salvar o código de cada página como um arquivo de texto separado. Eu tento isso:
Agora precisamos entender como usar o python para salvar o código de cada página como um arquivo de texto separado. Eu tento isso:import requests
r = requests.get(url='http://tristats.ru/')
print(r.content)
E eu recebo ... o código fonte. Mas preciso do resultado de sua execução. Depois de estudar, pesquisar e perguntar, percebi que precisava de uma ferramenta para automatizar as ações do navegador, por exemplo, selênio . Eu coloquei. E também o ChromeDriver para trabalhar com o Google Chrome . Então eu usei da seguinte maneira:from selenium import webdriver
from selenium.webdriver.chrome.service import Service
service = Service(r'C:\ChromeDriver\chromedriver.exe')
service.start()
driver = webdriver.Remote(service.service_url)
driver.get('http://www.tristats.ru/')
print(driver.page_source)
driver.quit()
Esse código inicia uma janela do navegador e abre uma página na URL especificada. Como resultado, já obtemos código html com os dados desejados. Mas há um problema. O resultado são apenas 100 entradas e o número total de corridas é quase 2000. Como assim? O fato é que, inicialmente, apenas as 100 primeiras entradas são exibidas no navegador e, somente se você rolar até a parte inferior da página, as próximas 100 serão carregadas e assim por diante. Portanto, é necessário implementar a rolagem programaticamente. Para fazer isso, use o comando:driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
E a cada rolagem, verificaremos se o código da página carregada mudou ou não. Se não tiver sido alterado, verificaremos várias vezes a confiabilidade, por exemplo 10, a página inteira será carregada e você poderá parar. Entre os pergaminhos, definimos o tempo limite para um segundo, para que a página tenha tempo para carregar. (Mesmo que ela não tenha tempo, temos uma reserva - outros nove segundos).E o código completo ficará assim:from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
service = Service(r'C:\ChromeDriver\chromedriver.exe')
service.start()
driver = webdriver.Remote(service.service_url)
driver.get('http://www.tristats.ru/')
prev_html = ''
scroll_attempt = 0
while scroll_attempt < 10:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(1)
if prev_html == driver.page_source:
scroll_attempt += 1
else:
prev_html = driver.page_source
scroll_attempt = 0
with open(r'D:\tri\summary.txt', 'w') as f:
f.write(prev_html)
driver.quit()
Portanto, temos um arquivo html com uma tabela de resumo de todas as corridas. Precisa analisá-lo. Para fazer isso, use a biblioteca lxml .from lxml import html
Primeiro, encontramos todas as linhas da tabela. Para determinar o sinal de uma string, basta olhar para o arquivo html em um editor de texto. Pode ser, por exemplo, “tr ng-repeat = 'r in racesData' class = 'ng-scope'” ou algum fragmento que não pode mais ser encontrado em nenhuma tag.
Pode ser, por exemplo, “tr ng-repeat = 'r in racesData' class = 'ng-scope'” ou algum fragmento que não pode mais ser encontrado em nenhuma tag.with open(r'D:\tri\summary.txt', 'r') as f:
sum_html = f.read()
tree = html.fromstring(sum_html)
rows = tree.findall(".//*[@ng-repeat='r in racesData']")
então iniciamos o quadro de dados do pandas e cada elemento de cada linha da tabela é gravado nesse quadro de dados.import pandas as pd
rs = pd.DataFrame(columns=['date','name','link','males','females','rus','total'], index=range(len(rows)))
Para descobrir onde cada elemento específico está oculto, basta olhar o código html de um dos elementos de nossas linhas no mesmo editor de texto.<tr ng-repeat="r in racesData" class="ng-scope">
<td class="ng-binding">2015-04-26</td>
<td>
<img src="/Images/flags/24/USA.png" class="flag">
<a href="/rus/result/ironman/texas/half/2015" target="_self" class="ng-binding">Ironman Texas 70.3 2015</a>
</td>
<td>
<a href="/rus/result/ironman/texas/half/2015?sex=F" target="_self" class="ng-binding">605</a>
<i class="fas fa-venus fa-lg" style="color:Pink"></i>
/
<a href="/rus/result/ironman/texas/half/2015?sex=M" target="_self" class="ng-binding">1539</a>
<i class="fas fa-mars fa-lg" style="color:LightBlue"></i>
</td>
<td class="ng-binding">
<img src="/Images/flags/24/rus.png" class="flag">
<a ng-if="r.CountryCount > 0" href="/rus/result/ironman/texas/half/2015?country=rus" target="_self" class="ng-binding ng-scope">2</a>
/ 2144
</td>
</tr>
A maneira mais fácil de codificar a navegação para crianças aqui é que não existem muitas.for i in range(len(rows)):
rs.loc[i,'date'] = rows[i].getchildren()[0].text.strip()
rs.loc[i,'name'] = rows[i].getchildren()[1].getchildren()[1].text.strip()
rs.loc[i,'link'] = rows[i].getchildren()[1].getchildren()[1].attrib['href'].strip()
rs.loc[i,'males'] = rows[i].getchildren()[2].getchildren()[2].text.strip()
rs.loc[i,'females'] = rows[i].getchildren()[2].getchildren()[0].text.strip()
rs.loc[i,'rus'] = rows[i].getchildren()[3].getchildren()[3].text.strip()
rs.loc[i,'total'] = rows[i].getchildren()[3].text_content().split('/')[1].strip()
Aqui está o resultado: salve esse quadro de dados em um arquivo. Eu uso pickle , mas poderia ser csv , ou qualquer outra coisa.import pickle as pkl
with open(r'D:\tri\summary.pkl', 'wb') as f:
pkl.dump(df,f)
Nesta fase, todos os dados são de um tipo de sequência. Conversaremos mais tarde. A coisa mais importante que precisamos agora é de links. Nós os usaremos para raspar protocolos de todas as raças. Tornamos isso à imagem e semelhança de como foi feito para a tabela dinâmica. No ciclo de todas as raças para cada uma, abriremos a página por referência, rolaremos e obteremos o código da página. Na tabela de resumo, temos informações sobre o número total de participantes na corrida - total, vamos usá-lo para entender até que ponto você precisa continuar a rolar. Para fazer isso, determinaremos diretamente o processo de raspar cada página, o número de registros na tabela e compará-lo com o valor esperado do total. Assim que for igual, rolamos até o final e você pode prosseguir para a próxima corrida. Também definimos um tempo limite de 60 segundos. Comeram durante esse tempo, não chegamos ao total , vamos para a próxima corrida. O código da página será salvo em um arquivo. Salvaremos os arquivos de todas as corridas em uma pasta e os nomearemos pelo nome das corridas, ou seja, pelo valor na coluna de eventos na tabela de resumo. Para evitar um conflito de nomes, é necessário que todas as raças tenham nomes diferentes na tabela dinâmica. Verifique isto:df[df.duplicated(subset = 'event', keep=False)]
service.start()
driver = webdriver.Remote(service.service_url)
timeout = 60
for index, row in df.iterrows():
try:
driver.get('http://www.tristats.ru' + row['link'])
start = time.time()
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(1)
race_html = driver.page_source
tree = html.fromstring(race_html)
race_rows = tree.findall(".//*[@ng-repeat='r in resultsData']")
if len(race_rows) == int(row['total']):
break
if time.time() - start > timeout:
print('timeout')
break
with open(os.path.join(r'D:\tri\races', row['event'] + '.txt'), 'w') as f:
f.write(race_html)
except:
traceback.print_exc()
time.sleep(1)
driver.quit()
Este é um processo longo. Mas quando tudo está configurado e esse mecanismo pesado começa a girar, adicionando arquivos de dados um após o outro, surge uma sensação agradável de excitação. Apenas cerca de três protocolos são carregados por minuto, muito lentamente. Deixou para girar para a noite. Demorou cerca de 10 horas. De manhã, a maioria dos protocolos foi carregada. Como geralmente acontece ao trabalhar com uma rede, alguns falham. Recomeçou-os rapidamente com uma segunda tentativa.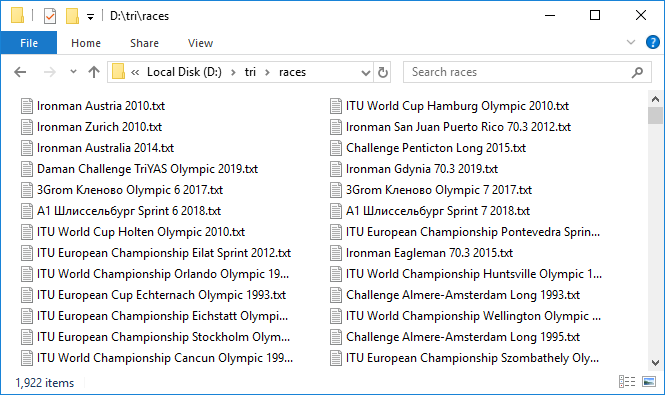 Portanto, temos 1.922 arquivos com uma capacidade total de quase 3 GB. Legal! Mas lidar com quase 300 corridas terminou em um tempo limite. Qual é o problema? Verificar seletivamente, verifica-se que, de fato, o valor total da tabela dinâmica e o número de entradas no protocolo de corrida que verificamos podem não coincidir. Isso é triste, porque não está claro qual é o motivo dessa discrepância. Ou isso se deve ao fato de que nem todos terminam ou algum tipo de bug no banco de dados. Em geral, o primeiro sinal de imperfeição de dados. De qualquer forma, verificamos aqueles em que o número de entradas é 100 ou 0, esses são os candidatos mais suspeitos. Havia oito deles. Faça o download novamente sob controle próximo. A propósito, em dois deles, na verdade, existem 100 entradas.Bem, nós temos todos os dados. Passamos à análise. Novamente, em um ciclo, percorreremos cada corrida, leremos o arquivo e salvaremos o conteúdo em um DataFrame do pandas . Combinaremos esses quadros de dados em um ditado , no qual os nomes das corridas serão as chaves - ou seja, os valores dos eventos da tabela dinâmica ou os nomes dos arquivos com o código html das páginas das corridas coincidem.
Portanto, temos 1.922 arquivos com uma capacidade total de quase 3 GB. Legal! Mas lidar com quase 300 corridas terminou em um tempo limite. Qual é o problema? Verificar seletivamente, verifica-se que, de fato, o valor total da tabela dinâmica e o número de entradas no protocolo de corrida que verificamos podem não coincidir. Isso é triste, porque não está claro qual é o motivo dessa discrepância. Ou isso se deve ao fato de que nem todos terminam ou algum tipo de bug no banco de dados. Em geral, o primeiro sinal de imperfeição de dados. De qualquer forma, verificamos aqueles em que o número de entradas é 100 ou 0, esses são os candidatos mais suspeitos. Havia oito deles. Faça o download novamente sob controle próximo. A propósito, em dois deles, na verdade, existem 100 entradas.Bem, nós temos todos os dados. Passamos à análise. Novamente, em um ciclo, percorreremos cada corrida, leremos o arquivo e salvaremos o conteúdo em um DataFrame do pandas . Combinaremos esses quadros de dados em um ditado , no qual os nomes das corridas serão as chaves - ou seja, os valores dos eventos da tabela dinâmica ou os nomes dos arquivos com o código html das páginas das corridas coincidem.rd = {}
for e in rs['event']:
place = []
... sex = [], name=..., country, group, place_in_group, swim, t1, bike, t2, run
result = []
with open(os.path.join(r'D:\tri\races', e + '.txt'), 'r')
race_html = f.read()
tree = html.fromstring(race_html)
rows = tree.findall(".//*[@ng-repeat='r in resultsData']")
for j in range(len(rows)):
row = rows[j]
parts = row.text_content().split('\n')
parts = [r.strip() for r in parts if r.strip() != '']
place.append(parts[0])
if len([a for a in row.findall('.//i')]) > 0:
sex.append([a for a in row.findall('.//i')][0].attrib['ng-if'][10:-1])
else:
sex.append('')
name.append(parts[1])
if len(parts) > 10:
country.append(parts[2].strip())
k=0
else:
country.append('')
k=1
group.append(parts[3-k])
... place_in_group.append(...), swim.append ..., t1, bike, t2, run
result.append(parts[10-k])
race = pd.DataFrame()
race['place'] = place
... race['sex'] = sex, race['name'] = ..., 'country', 'group', 'place_in_group', 'swim', ' t1', 'bike', 't2', 'run'
race['result'] = result
rd[e] = race
with open(r'D:\tri\details.pkl', 'wb') as f:
pkl.dump(rd,f)
for index, row in rs.iterrows():
e = row['event']
with open(os.path.join(r'D:\tri\races', e + '.txt'), 'r') as f:
race_html = f.read()
tree = html.fromstring(race_html)
header_elem = [tb for tb in tree.findall('.//tbody') if tb.getchildren()[0].getchildren()[0].text == ''][0]
location = header_elem.getchildren()[1].getchildren()[1].text.strip()
rs.loc[index, 'loc'] = location
with open(r'D:\tri\summary1.pkl', 'wb') as f:
pkl.dump(df,f)
Parte 2. Tipo de conversão e formatação
Então, baixamos todos os dados e os colocamos nos quadros de dados. No entanto, todos os valores são do tipo str . Isso se aplica à data, aos resultados, ao local e a todos os outros parâmetros. Todos os parâmetros devem ser convertidos para os tipos apropriados.Vamos começar com a tabela dinâmica.data e hora
evento , loc e ligação será deixada como está. date converter para pandas datetime da seguinte maneira:rs['date'] = pd.to_datetime(rs['date'])
O restante é convertido em um tipo inteiro:cols = ['males', 'females', 'rus', 'total']
rs[cols] = rs[cols].astype(int)
Tudo correu bem, nenhum erro surgiu. Então, está tudo bem - salve:with open(r'D:\tri\summary2.pkl', 'wb') as f:
pkl.dump(rs, f)
Agora correndo quadros de dados. Como todas as corridas são mais convenientes e mais rápidas para processar de uma só vez, e não uma de cada vez, as coletaremos em um grande dataframe ar (abreviação de todos os registros ) usando o método concat .ar = pd.concat(rd)
ar contém 1.416.365 entradas.Agora converta local e local no grupo em um valor inteiro.ar[['place', 'place in group']] = ar[['place', 'place in group']].astype(int))
Em seguida, processamos as colunas com valores temporários. Vamos lançá- los no tipo Timedelta de pandas . Mas, para que a conversão seja bem-sucedida, você precisa preparar adequadamente os dados. Você pode ver que alguns valores inferiores a uma hora ficam sem especificar a própria dica. Precisa adicioná-lo.for col in ['swim', 't1', 'bike', 't2', 'run', 'result']:
strlen = ar[col].str.len()
ar.loc[strlen==5, col] = '0:' + ar.loc[strlen==5, col]
ar.loc[strlen==4, col] = '0:0' + ar.loc[strlen==4, col]
Agora, os tempos, ainda com as strings restantes, ficam assim: Converter em Timedelta :for col in ['swim', 't1', 'bike', 't2', 'run', 'result']:
ar[col] = pd.to_timedelta(ar[col])
Chão
Ir em frente. Verifique se na coluna sexo existem apenas os valores de M e F :ar['sex'].unique()
Out: ['M', 'F', '']
De fato, ainda existe uma cadeia vazia, ou seja, o sexo não está especificado. Vamos ver quantos desses casos:len(ar[ar['sex'] == ''])
Out: 2538
Nem tanto é bom. No futuro, tentaremos reduzir ainda mais esse valor. Enquanto isso, deixe a coluna de sexo como está na forma de linhas. Salvaremos o resultado antes de passar para transformações mais sérias e arriscadas. Para manter a continuidade entre os arquivos, transformamos o quadro de dados combinado ar novamente no dicionário de quadros de dados rd :for event in ar.index.get_level_values(0).unique():
rd[event] = ar.loc[event]
with open(r'D:\tri\details1.pkl', 'wb') as f:
pkl.dump(rd,f)
A propósito, devido à conversão dos tipos de algumas colunas, o tamanho dos arquivos diminuiu de 367 KB para 295 KB na tabela dinâmica e de 251 MB para 168 MB nos protocolos de corrida.Código do país
Agora vamos ver o país.ar['country'].unique()
Out: ['CRO', 'CZE', 'SLO', 'SRB', 'BUL', 'SVK', 'SWE', 'BIH', 'POL', 'MK', 'ROU', 'GRE', 'FRA', 'HUN', 'NOR', 'AUT', 'MNE', 'GBR', 'RUS', 'UAE', 'USA', 'GER', 'URU', 'CRC', 'ITA', 'DEN', 'TUR', 'SUI', 'MEX', 'BLR', 'EST', 'NED', 'AUS', 'BGI', 'BEL', 'ESP', 'POR', 'UKR', 'CAN', 'IRL', 'JPN', 'HKG', 'JEY', 'SGP', 'BRA', 'QAT', 'LUX', 'RSA', 'NZL', 'LAT', 'PHI', 'KSA', 'SEY', 'MAS', 'OMA', 'ARG', 'ECU', 'THA', 'JOR', 'BRN', 'CIV', 'FIN', 'IRN', 'BER', 'LBA', 'KUW', 'LTU', 'SRI', 'HON', 'INA', 'LBN', 'PAN', 'EGY', 'MLT', 'WAL', 'ISL', 'CYP', 'DOM', 'IND', 'VIE', 'MRI', 'AZE', 'MLD', 'LIE', 'VEN', 'ALG', 'SYR', 'MAR', 'KZK', 'PER', 'COL', 'IRQ', 'PAK', 'CZK', 'KAZ', 'CHN', 'NEP', 'ISR', 'MKD', 'FRO', 'BAN', 'ARU', 'CPV', 'ALB', 'BIZ', 'TPE', 'KGZ', 'BNN', 'CUB', 'SNG', 'VTN', 'THI', 'PRG', 'KOR', 'RE', 'TW', 'VN', 'MOL', 'FRE', 'AND', 'MDV', 'GUA', 'MON', 'ARM', 'F.I.TRI.', 'BAHREIN', 'SUECIA', 'REPUBLICA CHECA', 'BRASIL', 'CHI', 'MDA', 'TUN', 'NDL', 'Danish(Dane)', 'Welsh', 'Austrian', 'Unknown', 'AFG', 'Argentinean', 'Pitcairn', 'South African', 'Greenland', 'ESTADOS UNIDOS', 'LUXEMBURGO', 'SUDAFRICA', 'NUEVA ZELANDA', 'RUMANIA', 'PM', 'BAH', 'LTV', 'ESA', 'LAB', 'GIB', 'GUT', 'SAR', 'ita', 'aut', 'ger', 'esp', 'gbr', 'hun', 'den', 'usa', 'sui', 'slo', 'cze', 'svk', 'fra', 'fin', 'isr', 'irn', 'irl', 'bel', 'ned', 'sco', 'pol', 'SMR', 'mex', 'STEEL T BG', 'KINO MANA', 'IVB', 'TCH', 'SCO', 'KEN', 'BAS', 'ZIM', 'Joe', 'PUR', 'SWZ', 'Mark', 'WLS', 'MYA', 'BOT', 'REU', 'NAM', 'NCL', 'BOL', 'GGY', 'ISV', 'TWN', 'GUM', 'FIJ', 'COK', 'NGR', 'IRI', 'GAB', 'ANT', 'GEO', 'COG', 'sue', 'SUD', 'BAR', 'CAY', 'BO', 'VE', 'AX', 'MD', 'PAR', 'UM', 'SEN', 'NIG', 'RWA', 'YEM', 'PLE', 'GHA', 'ITU', 'UZB', 'MGL', 'MAC', 'DMA', 'TAH', 'TTO', 'AHO', 'JAM', 'SKN', 'GRN', 'PRK', 'NFK', 'SOL', 'Sandy', 'SAM', 'PNG', 'SGS', 'Suchy, Jorg', 'SOG', 'GEQ', 'BVT', 'DJI', 'CHA', 'ANG', 'YUG', 'IOT', 'HAI', 'SJM', 'CUW', 'BHU', 'ERI', 'FLK', 'HMD', 'GUF', 'ESH', 'sandy', 'UMI', 'selsmark, 'Alise', 'Eddie', '31/3, Colin', 'CC', '', '', '', '', '', ' ', '', '', '', '-', '', 'GRL', 'UGA', 'VAT', 'ETH', 'ASA', 'PYF', 'ATA', 'ALA', 'MTQ', 'ZZ', 'CXR', 'AIA', 'TJK', 'GUY', 'KR', 'PF', 'BN', 'MO', 'LA', 'CAM', 'NCA', 'ZAM', 'MAD', 'TOG', 'VIR', 'ATF', 'VAN', 'SLE', 'GLP', 'SCG', 'LAO', 'IMN', 'BUR', 'IR', 'SY', 'CMR', 'GBS', 'SUR', 'MOZ', 'BLM', 'MSR', 'CAF', 'BEN', 'COD', 'CCK', 'TUV', 'TGA', 'GI', 'XKX', 'NRU', 'NC', 'LBR', 'TAN', 'VIN', 'SSD', 'GP', 'PS', 'IM', 'JE', '', 'MLI', 'FSM', 'LCA', 'GMB', 'MHL', 'NH', 'FL', 'CT', 'UT', 'AQ', 'Korea', 'Taiwan', 'NewCaledonia', 'Czech Republic', 'PLW', 'BRU', 'RUN', 'NIU', 'KIR', 'SOM', 'TKM', 'SPM', 'BDI', 'COM', 'TCA', 'SHN', 'DO2', 'DCF', 'PCN', 'MNP', 'MYT', 'SXM', 'MAF', 'GUI', 'AN', 'Slovak republic', 'Channel Islands', 'Reunion', 'Wales', 'Scotland', 'ica', 'WLF', 'D', 'F', 'I', 'B', 'L', 'E', 'A', 'S', 'N', 'H', 'R', 'NU', 'BES', 'Bavaria', 'TLS', 'J', 'TKL', 'Tirol"', 'P', '?????', 'EU', 'ES-IB', 'ES-CT', '', 'SOO', 'LZE', '', '', '', '', '', '']
412 valores únicos.Basicamente, um país é indicado por um código de três dígitos em maiúsculas. Mas, aparentemente, nem sempre. De fato, existe uma norma internacional ISO 3166 , na qual, para todos os países, inclusive aqueles que não existem mais, são prescritos os códigos correspondentes de três e dois dígitos. Para python, uma das implementações deste padrão pode ser encontrada no pacote pycountry . Veja como funciona:import pycountry as pyco
pyco.countries.get(alpha_3 = 'RUS')
Out: Country(alpha_2='RU', alpha_3='RUS', name='Russian Federation', numeric='643')
Assim, verificaremos todos os códigos de três dígitos, levando a maiúsculas, que dão uma resposta em countries.get (...) e historic_countries.get (...) :valid_a3 = [c for c in ar['country'].unique() if pyco.countries.get(alpha_3 = c.upper()) != None or pyco.historic_countries.get(alpha_3 = c.upper()) != None])
Havia 190 de 412 deles, ou seja, menos da metade.Para os 222 restantes (denotamos sua lista por tofix ), criaremos um dicionário de correspondência de correção , no qual a chave será o nome original e o valor será um código de três dígitos de acordo com o padrão ISO.tofix = list(set(ar['country'].unique()) - set(valid_a3))
Primeiro, verifique os códigos de dois dígitos com pycountry.countries.get (alpha_2 = ...) , levando a maiúsculas:for icc in tofix:
if pyco.countries.get(alpha_2 = icc.upper()) != None:
fix[icc] = pyco.countries.get(alpha_2 = icc.upper()).alpha_3
else:
if pyco.historic_countries.get(alpha_2 = icc.upper()) != None:
fix[icc] = pyco.historic_countries.get(alpha_2 = icc.upper()).alpha_3
Em seguida, os nomes completos através de pycountry.countries.get (name = ...), pycountry.countries.get (common_name = ...) , levando-os ao formato str.title () :for icc in tofix:
if pyco.countries.get(common_name = icc.title()) != None:
fix[icc] = pyco.countries.get(common_name = icc.title()).alpha_3
else:
if pyco.countries.get(name = icc.title()) != None:
fix[icc] = pyco.countries.get(name = icc.title()).alpha_3
else:
if pyco.historic_countries.get(name = icc.title()) != None:
fix[icc] = pyco.historic_countries.get(name = icc.title()).alpha_3
Portanto, reduzimos o número de valores não reconhecidos para 190. Ainda bastante: você pode notar que entre eles ainda existem muitos códigos de três dígitos, mas isso não é um ISO. O que então? Acontece que há outro padrão - olímpico . Infelizmente, sua implementação não está incluída no pycountry e você deve procurar outra coisa. A solução foi encontrada na forma de um arquivo csv no datahub.io . Coloque o conteúdo desse arquivo em um DataFrame do pandas chamado cdf . ioc - Comitê Olímpico Internacional (COI)['URU', '', 'PAR', 'SUECIA', 'KUW', 'South African', '', 'Austrian', 'ISV', 'H', 'SCO', 'ES-CT', ', 'GUI', 'BOT', 'SEY', 'BIZ', 'LAB', 'PUR', ' ', 'Scotland', '', '', 'TCH', 'TGA', 'UT', 'BAH', 'GEQ', 'NEP', 'TAH', 'ica', 'FRE', 'E', 'TOG', 'MYA', '', 'Danish (Dane)', 'SAM', 'TPE', 'MON', 'ger', 'Unknown', 'sui', 'R', 'SUI', 'A', 'GRN', 'KZK', 'Wales', '', 'GBS', 'ESA', 'Bavaria', 'Czech Republic', '31/3, Colin', 'SOL', 'SKN', '', 'MGL', 'XKX', 'WLS', 'MOL', 'FIJ', 'CAY', 'ES-IB', 'BER', 'PLE', 'MRI', 'B', 'KSA', '', '', 'LAT', 'GRE', 'ARU', '', 'THI', 'NGR', 'MAD', 'SOG', 'MLD', '?????', 'AHO', 'sco', 'UAE', 'RUMANIA', 'CRO', 'RSA', 'NUEVA ZELANDA', 'KINO MANA', 'PHI', 'sue', 'Tirol"', 'IRI', 'POR', 'CZK', 'SAR', 'D', 'BRASIL', 'DCF', 'HAI', 'ned', 'N', 'BAHREIN', 'VTN', 'EU', 'CAM', 'Mark', 'BUL', 'Welsh', 'VIN', 'HON', 'ESTADOS UNIDOS', 'I', 'GUA', 'OMA', 'CRC', 'PRG', 'NIG', 'BHU', 'Joe', 'GER', 'RUN', 'ALG', '', 'Channel Islands', 'Reunion', 'REPUBLICA CHECA', 'slo', 'ANG', 'NewCaledonia', 'GUT', 'VIE', 'ASA', 'BAR', 'SRI', 'L', '', 'J', 'BAS', 'LUXEMBURGO', 'S', 'CHI', 'SNG', 'BNN', 'den', 'F.I.TRI.', 'STEEL T BG', 'NCA', 'Slovak republic', 'MAS', 'LZE', '-', 'F', 'BRU', '', 'LBA', 'NDL', 'DEN', 'IVB', 'BAN', 'Sandy', 'ZAM', 'sandy', 'Korea', 'SOO', 'BGI', '', 'LTV', 'selsmark, Alise', 'TAN', 'NED', '', 'Suchy, Jorg', 'SLO', 'SUDAFRICA', 'ZIM', 'Eddie', 'INA', '', 'SUD', 'VAN', 'FL', 'P', 'ITU', 'ZZ', 'Argentinean', 'CHA', 'DO2', 'WAL']
len(([x for x in tofix if x.upper() in list(cdf['ioc'])]))
Out: 82
Entre os códigos de três dígitos do tofix, 82 COI correspondentes foram encontrados. Adicione-os ao nosso dicionário correspondente.for icc in tofix:
if icc.upper() in list(cdf['ioc']):
ind = cdf[cdf['ioc'] == icc.upper()].index[0]
fix[icc] = cdf.loc[ind, 'iso3']
Restam 108 valores brutos. Eles são finalizados manualmente, às vezes recorrendo ao Google para obter ajuda. Mas mesmo o controle manual não resolve completamente o problema. Restam 49 valores que já são impossíveis de interpretar. A maioria desses valores provavelmente são apenas erros de dados.{'BGI': 'BRB', 'WAL': 'GBR', 'MLD': 'MDA', 'KZK': 'KAZ', 'CZK': 'CZE', 'BNN': 'BEN', 'SNG': 'SGP', 'VTN': 'VNM', 'THI': 'THA', 'PRG': 'PRT', 'MOL': 'MDA', 'FRE': 'FRA', 'F.I.TRI.': 'ITA', 'BAHREIN': 'BHR', 'SUECIA': 'SWE', 'REPUBLICA CHECA': 'CZE', 'BRASIL': 'BRA', 'NDL': 'NLD', 'Danish (Dane)': 'DNK', 'Welsh': 'GBR', 'Austrian': 'AUT', 'Argentinean': 'ARG', 'South African': 'ZAF', 'ESTADOS UNIDOS': 'USA', 'LUXEMBURGO': 'LUX', 'SUDAFRICA': 'ZAF', 'NUEVA ZELANDA': 'NZL', 'RUMANIA': 'ROU', 'sco': 'GBR', 'SCO': 'GBR', 'WLS': 'GBR', '': 'IND', '': 'IRL', '': 'ARM', '': 'BGR', '': 'SRB', ' ': 'BLR', '': 'GBR', '': 'FRA', '': 'HND', '-': 'CRI', '': 'AZE', 'Korea': 'KOR', 'NewCaledonia': 'FRA', 'Czech Republic': 'CZE', 'Slovak republic': 'SVK', 'Channel Islands': 'FRA', 'Reunion': 'FRA', 'Wales': 'GBR', 'Scotland': 'GBR', 'Bavaria': 'DEU', 'Tirol"': 'AUT', '': 'KGZ', '': 'BLR', '': 'BLR', '': 'BLR', '': 'RUS', '': 'BLR', '': 'RUS'}
unfixed = [x for x in tofix if x not in fix.keys()]
Out: ['', 'H', 'ES-CT', 'LAB', 'TCH', 'UT', 'TAH', 'ica', 'E', 'Unknown', 'R', 'A', '31/3, Colin', 'XKX', 'ES-IB','B','SOG','?????','KINO MANA','sue','SAR','D', 'DCF', 'N', 'EU', 'Mark', 'I', 'Joe', 'RUN', 'GUT', 'L', 'J', 'BAS', 'S', 'STEEL T BG', 'LZE', 'F', 'Sandy', 'DO2', 'sandy', 'SOO', 'LTV', 'selsmark, Alise', 'Suchy, Jorg' 'Eddie', 'FL', 'P', 'ITU', 'ZZ']
Essas chaves terão uma string vazia no dicionário correspondente.for cc in unfixed:
fix[cc] = ''
Por fim, adicionamos aos códigos de dicionário correspondentes válidos, mas escritos em letras minúsculas.for cc in valid_a3:
if cc.upper() != cc:
fix[cc] = cc.upper()
Agora é hora de aplicar as substituições encontradas. Para salvar os dados iniciais para posterior comparação, copie o país coluna de matéria-país . Em seguida, usando o dicionário de correspondência criado, corrigimos os valores na coluna do país que não correspondem ao ISO.for cc in fix:
ind = ar[ar['country'] == cc].index
ar.loc[ind,'country'] = fix[cc]
Aqui, é claro, não se pode prescindir da vetorização, a tabela possui quase um milhão e meio de linhas. Mas, de acordo com o dicionário, fazemos um ciclo, mas de que outra forma? Verifique quantos registros foram alterados:len(ar[ar['country'] != ar['country raw']])
Out: 315955
isto é, mais de 20% do total.ar[ar['country'] != ar['country raw']].sample(10)
len(ar[ar['country'] == ''])
Out: 3221
Este é o número de registros sem um país ou com um país informal. O número de países únicos diminuiu de 412 para 250. Aqui estão eles: Agora não há desvios. Salvamos o resultado em um novo arquivo details2.pkl , depois de converter o quadro de dados combinado novamente em um dicionário de quadros de dados, como foi feito anteriormente.['', 'ABW', 'AFG', 'AGO', 'AIA', 'ALA', 'ALB', 'AND', 'ANT', 'ARE', 'ARG', 'ARM', 'ASM', 'ATA', 'ATF', 'AUS', 'AUT', 'AZE', 'BDI', 'BEL', 'BEN', 'BES', 'BGD', 'BGR', 'BHR', 'BHS', 'BIH', 'BLM', 'BLR', 'BLZ', 'BMU', 'BOL', 'BRA', 'BRB', 'BRN', 'BTN', 'BUR', 'BVT', 'BWA', 'CAF', 'CAN', 'CCK', 'CHE', 'CHL', 'CHN', 'CIV', 'CMR', 'COD', 'COG', 'COK', 'COL', 'COM', 'CPV', 'CRI', 'CTE', 'CUB', 'CUW', 'CXR', 'CYM', 'CYP', 'CZE', 'DEU', 'DJI', 'DMA', 'DNK', 'DOM', 'DZA', 'ECU', 'EGY', 'ERI', 'ESH', 'ESP', 'EST', 'ETH', 'FIN', 'FJI', 'FLK', 'FRA', 'FRO', 'FSM', 'GAB', 'GBR', 'GEO', 'GGY', 'GHA', 'GIB', 'GIN', 'GLP', 'GMB', 'GNB', 'GNQ', 'GRC', 'GRD', 'GRL', 'GTM', 'GUF', 'GUM', 'GUY', 'HKG', 'HMD', 'HND', 'HRV', 'HTI', 'HUN', 'IDN', 'IMN', 'IND', 'IOT', 'IRL', 'IRN', 'IRQ', 'ISL', 'ISR', 'ITA', 'JAM', 'JEY', 'JOR', 'JPN', 'KAZ', 'KEN', 'KGZ', 'KHM', 'KIR', 'KNA', 'KOR', 'KWT', 'LAO', 'LBN', 'LBR', 'LBY', 'LCA', 'LIE', 'LKA', 'LTU', 'LUX', 'LVA', 'MAC', 'MAF', 'MAR', 'MCO', 'MDA', 'MDG', 'MDV', 'MEX', 'MHL', 'MKD', 'MLI', 'MLT', 'MMR', 'MNE', 'MNG', 'MNP', 'MOZ', 'MSR', 'MTQ', 'MUS', 'MYS', 'MYT', 'NAM', 'NCL', 'NER', 'NFK', 'NGA', 'NHB', 'NIC', 'NIU', 'NLD', 'NOR', 'NPL', 'NRU', 'NZL', 'OMN', 'PAK', 'PAN', 'PCN', 'PER', 'PHL', 'PLW', 'PNG', 'POL', 'PRI', 'PRK', 'PRT', 'PRY', 'PSE', 'PYF', 'QAT', 'REU', 'ROU', 'RUS', 'RWA', 'SAU', 'SCG', 'SDN', 'SEN', 'SGP', 'SGS', 'SHN', 'SJM', 'SLB', 'SLE', 'SLV', 'SMR', 'SOM', 'SPM', 'SRB', 'SSD', 'SUR', 'SVK', 'SVN', 'SWE', 'SWZ', 'SXM', 'SYC', 'SYR', 'TCA', 'TCD', 'TGO', 'THA', 'TJK', 'TKL', 'TKM', 'TLS', 'TON', 'TTO', 'TUN', 'TUR', 'TUV', 'TWN', 'TZA', 'UGA', 'UKR', 'UMI', 'URY', 'USA', 'UZB', 'VAT', 'VCT', 'VEN', 'VGB', 'VIR', 'VNM', 'VUT', 'WLF', 'WSM', 'YEM', 'YUG', 'ZAF', 'ZMB', 'ZWE']
Localização
Agora, lembre-se de que a menção de países também está na tabela dinâmica, na coluna loc . Ele também precisa ser trazido para uma aparência padrão. Aqui está uma história um pouco diferente: nem os códigos ISO nem Olímpicos são visíveis. Tudo é descrito de forma bastante livre. A cidade, o país e outros componentes do endereço são listados por vírgula e em ordem aleatória. Em algum lugar em primeiro lugar, em algum lugar no último. pycountry não vai ajudar aqui. E há muitos recordes - para a corrida de 1922, 525 locais únicos (em sua forma original). Mas aqui foi encontrada uma ferramenta adequada. Isso é geopy , ou seja, o geolocalizador Nominatim . Funciona assim:from geopy.geocoders import Nominatim
geolocator = Nominatim(user_agent='triathlon results researcher')
geolocator.geocode(' , , ', language='en')
Out: Location( , – , , Altaysky District, Altai Krai, Siberian Federal District, Russia, (51.78897945, 85.73956296106752, 0.0))
Mediante solicitação, de forma aleatória, fornece um endereço de resposta estruturado e coordenadas. Se você definir o idioma, como aqui - inglês, o que puder - será traduzido. Antes de tudo, precisamos do nome padrão do país para posterior tradução no código ISO. Apenas ocupa o último lugar na propriedade address . Como o geolocator envia uma solicitação ao servidor toda vez, esse processo não é rápido e leva 500 minutos para 500 registros. Além disso, acontece que a resposta não vem. Nesse caso, uma segunda solicitação às vezes ajuda. Na minha primeira resposta não chegou a 130 pedidos. A maioria deles foi processada com duas tentativas. No entanto, 34 nomes não foram processados, mesmo por várias tentativas adicionais. Aqui estão eles:['Tongyeong, Korea, Korea, South', 'Constanta, Mamaia, Romania, Romania', 'Weihai, China, China', '. , .', 'Odaiba Marin Park, Tokyo, Japan, Japan', 'Sweden, Smaland, Kalmar', 'Cholpon-Ata city, Resort Center "Kapriz", Kyrgyzstan', 'Luxembourg, Region Moselle, Moselle', 'Chita Peninsula, Japan', 'Kraichgau Region, Germany', 'Jintang, Chengdu, Sichuan Province, China, China', 'Madrid, Spain, Spain', 'North American Pro Championship, St. George, Utah, USA', 'Milan Idroscalo Linate, Italy', 'Dexing, Jiangxi Province, China, China', 'Mooloolaba, Australia, Australia', 'Nathan Benderson Park (NBP), 5851 Nathan Benderson Circle, Sarasota, FL 34235., United States', 'Strathclyde Country Park, North Lanarkshire, Glasgow, Great Britain', 'Quijing, China', 'United States of America , Hawaii, Kohala Coast', 'Buffalo City, East London, South Africa', 'Spain, Vall de Cardener', ', . ', 'Asian TriClub Championship, Hefei, China', 'Taizhou, Jiangsu Province, China, China', ', , «»', 'Buffalo, Gallagher Beach, Furhmann Blvd, United States', 'North American Pro Championship | St. George, Utah, USA', 'Weihai, Shandong, China, China', 'Tarzo - Revine Lago, Italy', 'Lausanee, Switzerland', 'Queenstown, New Zealand, New Zealand', 'Makuhari, Japan, Japan', 'Szombathlely, Hungary']
Pode-se ver que em muitos há uma dupla menção ao país, e isso realmente interfere. Em geral, eu tive que processar manualmente esses nomes restantes e os endereços padrão foram obtidos para todos. Além disso, a partir desses endereços, selecionei um país e escrevi esse país em uma nova coluna na tabela dinâmica. Como, como eu disse, trabalhar com geopy não é rápido, decidi salvar imediatamente as coordenadas da localização - latitude e longitude. Eles serão úteis mais tarde para visualização no mapa. Depois disso, usando pyco.countries.get (name = '...'). Alpha_3 pesquisou o país por nome e alocou um código de três dígitos.Distância
Outra ação importante que precisa ser executada na tabela dinâmica é determinar a distância para cada corrida. Isso é útil para o cálculo de velocidades no futuro. No triatlo, existem quatro distâncias principais - sprint, olímpico, semi-ferro e ferro. Você pode ver que nos nomes das corridas geralmente há uma indicação da distância - estas são Sprint , Olímpico , Meio , Palavras Completas . Além disso, diferentes organizadores têm suas próprias designações de distâncias. Metade do Ironman, por exemplo, é designada como 70,3 - pelo número de milhas à distância, a Olympic - 5150 pelo número de quilômetros (51,5), e o ferro pode ser designado como Cheioou, em geral, como falta de explicação - por exemplo, Ironman Arizona 2019 . Ironman - ele é ferro! No Desafio, a distância do ferro é designada como Longa e a distância do semi- ferro é designada como Média . Nosso IronStar russo significa cheio como 226 e metade como 113 - pelo número de quilômetros, mas geralmente as palavras Completo e Meio também estão presentes. Agora aplique todo esse conhecimento e marque todas as corridas de acordo com as palavras-chave presentes nos nomes.sprints = rs.loc[[i for i in rs.index if 'sprint' in rs.loc[i, 'event'].lower()]]
olympics1 = rs.loc[[i for i in rs.index if 'olympic' in rs.loc[i, 'event'].lower()]]
olympics2 = rs.loc[[i for i in rs.index if '5150' in rs.loc[i, 'event'].lower()]]
olympics = pd.concat([olympics1, olympics2])
rsd = pd.concat([sprints, olympics, halfs, fulls])
No rsd , foram produzidos 1 925 registros, ou seja, três a mais do que o número total de corridas, então alguns caíram sob dois critérios. Vamos olhar para eles:rsd[rsd.duplicated(keep=False)]['event'].sort_index()
olympics.drop(65)
Faremos o mesmo com a interseção com Ironman Dun Laoghaire Full Swim 70.3 2019 Aqui é o melhor horário às 4:00. Isso é típico para metade. Exclua o registro com o índice 85 dos totais .fulls.drop(85)
Agora, anotaremos as informações de distância no quadro de dados principal e veremos o que aconteceu:rs['dist'] = ''
rs.loc[sprints.index,'dist'] = 'sprint'
rs.loc[olympics.index,'dist'] = 'olympic'
rs.loc[halfs.index,'dist'] = 'half'
rs.loc[fulls.index,'dist'] = 'full'
rs.sample(10)
len(rs[rs['dist'] == ''])
Out: 0
E confira nossos problemáticos e ambíguos:rs.loc[[38,65,82],['event','dist']]
pkl.dump(rs, open(r'D:\tri\summary5.pkl', 'wb'))
Faixas etárias
Agora, de volta aos protocolos de corrida.Já analisamos o gênero, país e resultados do participante e os trouxemos para um formulário padrão. Mas mais duas colunas permaneciam - o grupo e, de fato, o próprio nome. Vamos começar com os grupos. No triatlo, é habitual dividir os participantes por faixas etárias. Um grupo de profissionais também se destaca com frequência. De fato, o deslocamento ocorre em cada grupo separadamente - os três primeiros lugares em cada grupo são premiados. Nos grupos, a qualificação está sendo selecionada para campeonatos, por exemplo, no Konu.Combine todos os registros e veja quais grupos geralmente existem.rd = pkl.load(open(r'D:\tri\details2.pkl', 'rb'))
ar = pd.concat(rd)
ar['group'].unique()
Aconteceu que havia um grande número de grupos - 581. Cem selecionados aleatoriamente se parecem com isso: Vamos ver qual deles é o mais numeroso:['MSenior', 'FAmat.', 'M20', 'M65-59', 'F25-29', 'F18-22', 'M75-59', 'MPro', 'F24', 'MCORP M', 'F21-30', 'MSenior 4', 'M40-50', 'FAWAD', 'M16-29', 'MK40-49', 'F65-70', 'F65-70', 'M12-15', 'MK18-29', 'M50up', 'FSEMIFINAL 2 PRO', 'F16', 'MWhite', 'MOpen 25-29', 'F', 'MPT TRI-2', 'M16-24', 'FQUALIFIER 1 PRO', 'F15-17', 'FSEMIFINAL 2 JUNIOR', 'FOpen 60-64', 'M75-80', 'F60-69', 'FJUNIOR A', 'F17-18', 'FAWAD BLIND', 'M75-79', 'M18-29', 'MJUN19-23', 'M60-up', 'M70', 'MPTS5', 'F35-40', "M'S PT1", 'M50-54', 'F65-69', 'F17-20', 'MP4', 'M16-29', 'F18up', 'MJU', 'MPT4', 'MPT TRI-3', 'MU24-39', 'MK35-39', 'F18-20', "M'S", 'F50-55', 'M75-80', 'MXTRI', 'F40-45', 'MJUNIOR B', 'F15', 'F18-19', 'M20-29', 'MAWAD PC4', 'M30-37', 'F21-30', 'Mpro', 'MSEMIFINAL 1 JUNIOR', 'M25-34', 'MAmat.', 'FAWAD PC5', 'FA', 'F50-60', 'FSenior 1', 'M80-84', 'FK45-49', 'F75-79', 'M<23', 'MPTS3', 'M70-75', 'M50-60', 'FQUALIFIER 3 PRO', 'M9', 'F31-40', 'MJUN16-19', 'F18-19', 'M PARA', 'F35-44', 'MParaathlete', 'F18-34', 'FA', 'FAWAD PC2', 'FAll Ages', 'M PARA', 'F31-40', 'MM85', 'M25-39']
ar['group'].value_counts()[:30]
Out:
M40-44 199157
M35-39 183738
M45-49 166796
M30-34 154732
M50-54 107307
M25-29 88980
M55-59 50659
F40-44 48036
F35-39 47414
F30-34 45838
F45-49 39618
MPRO 38445
F25-29 31718
F50-54 26253
M18-24 24534
FPRO 23810
M60-64 20773
M 12799
F55-59 12470
M65-69 8039
F18-24 7772
MJUNIOR 6605
F60-64 5067
M20-24 4580
FJUNIOR 4105
M30-39 3964
M40-49 3319
F 3306
M70-74 3072
F20-24 2522
Você pode ver que esses são grupos de cinco anos, separadamente para homens e separadamente para mulheres, bem como grupos profissionais MPRO e FPRO .Portanto, nosso padrão será:ag = ['MPRO', 'M18-24', 'M25-29', 'M30-34', 'M35-39', 'M40-44', 'M45-49', 'M50-54', 'M55-59', 'M60-64', 'M65-69', 'M70-74', 'M75-79', 'M80-84', 'M85-90', 'FPRO', 'F18-24', 'F25-29', 'F30-34', 'F35-39', 'F40-44', 'F45-49', 'F50-54', 'F55-59', 'F60-64', 'F65-69', 'F70-74', 'F75-79', 'F80-84', 'F85-90']
Este conjunto cobre quase 95% de todos os finalizadores.Obviamente, não seremos capazes de levar todos os grupos a esse padrão. Mas procuramos aqueles que são semelhantes a eles e damos pelo menos uma parte. Primeiro, vamos trazer para maiúsculas e remover os espaços. Eis o que aconteceu: converta-os para os nossos padrões.['F25-29F', 'F30-34F', 'F30-34-34', 'F35-39F', 'F40-44F', 'F45-49F', 'F50-54F', 'F55-59F', 'FAG:FPRO', 'FK30-34', 'FK35-39', 'FK40-44', 'FK45-49', 'FOPEN50-54', 'FOPEN60-64', 'MAG:MPRO', 'MK30-34', 'MK30-39', 'MK35-39', 'MK40-44', 'MK40-49', 'MK50-59', 'M40-44', 'MM85-89', 'MOPEN25-29', 'MOPEN30-34', 'MOPEN35-39', 'MOPEN40-44', 'MOPEN45-49', 'MOPEN50-54', 'MOPEN70-74', 'MPRO:', 'MPROM', 'M0-44"']
fix = { 'F25-29F': 'F25-29', 'F30-34F' : 'F30-34', 'F30-34-34': 'F30-34', 'F35-39F': 'F35-39', 'F40-44F': 'F40-44', 'F45-49F': 'F45-49', 'F50-54F': 'F50-54', 'F55-59F': 'F55-59', 'FAG:FPRO': 'FPRO', 'FK30-34': 'F30-34', 'FK35-39': 'F35-39', 'FK40-44': 'F40-44', 'FK45-49': 'F45-49', 'FOPEN50-54': 'F50-54', 'FOPEN60-64': 'F60-64', 'MAG:MPRO': 'MPRO', 'MK30-34': 'M30-34', 'MK30-39': 'M30-39', 'MK35-39': 'M35-39', 'MK40-44': 'M40-44', 'MK40-49': 'M40-49', 'MK50-59': 'M50-59', 'M40-44': 'M40-44', 'MM85-89': 'M85-89', 'MOPEN25-29': 'M25-29', 'MOPEN30-34': 'M30-34', 'MOPEN35-39': 'M35-39', 'MOPEN40-44': 'M40-44', 'MOPEN45-49': 'M45-49', 'MOPEN50-54': 'M50-54', 'MOPEN70-74': 'M70- 74', 'MPRO:' :'MPRO', 'MPROM': 'MPRO', 'M0-44"' : 'M40-44'}
Agora, aplicamos nossa transformação ao quadro de dados principal ar , mas primeiro salve os valores do grupo original na nova coluna bruta do grupo .ar['group raw'] = ar['group']
Na coluna do grupo , deixamos apenas os valores que atendem ao nosso padrão.Agora podemos apreciar nossos esforços:len(ar[(ar['group'] != ar['group raw'])&(ar['group']!='')])
Out: 273
Um pouco no nível de um milhão e meio. Mas você não saberá até tentar.Selecionados 10 olhar como este: Salvar a nova versão do quadro de dados, depois de convertê-lo de volta para o rd dicionário .pkl.dump(rd, open(r'D:\tri\details3.pkl', 'wb'))
Nome
Agora vamos cuidar dos nomes. Vamos ver seletivamente 100 nomes de diferentes raças:list(ar['name'].sample(100))
Out: ['Case, Christine', 'Van der westhuizen, Wouter', 'Grace, Scott', 'Sader, Markus', 'Schuller, Gunnar', 'Juul-Andersen, Jeppe', 'Nelson, Matthew', ' ', 'Westman, Pehr', 'Becker, Christoph', 'Bolton, Jarrad', 'Coto, Ricardo', 'Davies, Luke', 'Daniltchev, Alexandre', 'Escobar Labastida, Emmanuelle', 'Idzikowski, Jacek', 'Fairaislova Iveta', 'Fisher, Kulani', 'Didenko, Viktor', 'Osborne, Jane', 'Kadralinov, Zhalgas', 'Perkins, Chad', 'Caddell, Martha', 'Lynaire PARISH', 'Busing, Lynn', 'Nikitin, Evgeny', 'ANSON MONZON, ROBERTO', 'Kaub, Bernd', 'Bank, Morten', 'Kennedy, Ian', 'Kahl, Stephen', 'Vossough, Andreas', 'Gale, Karen', 'Mullally, Kristin', 'Alex FRASER', 'Dierkes, Manuela', 'Gillett, David', 'Green, Erica', 'Cunnew, Elliott', 'Sukk, Gaspar', 'Markina Veronika', 'Thomas KVARICS', 'Wu, Lewen', 'Van Enk, W.J.J', 'Escobar, Rosario', 'Healey, Pat', 'Scheef, Heike', 'Ancheta, Marlon', 'Heck, Andreas', 'Vargas Iii, Raul', 'Seferoglou, Maria', 'chris GUZMAN', 'Casey, Timothy', 'Olshanikov Konstantin', 'Rasmus Nerrand', 'Lehmann Bence', 'Amacker, Kirby', 'Parks, Chris', 'Tom, Troy', 'Karlsson, Ulf', 'Halfkann, Dorothee', 'Szabo, Gergely', 'Antipov Mikhail', 'Von Alvensleben, Alvo', 'Gruber, Peter', 'Leblanc, Jean-Philippe', 'Bouchard, Jean-Francois', 'Marchiotto MASSIMO', 'Green, Molly', 'Alder, Christoph', 'Morris, Huw', 'Deceur, Marc', 'Queenan, Derek', 'Krause, Carolin', 'Cockings, Antony', 'Ziehmer Chris', 'Stiene, John', 'Chmet Daniela', 'Chris RIORDAN', 'Wintle, Mel', ' ', 'GASPARINI CHRISTIAN', 'Westbrook, Christohper', 'Martens, Wim', 'Papson, Chris', 'Burdess, Shaun', 'Proctor, Shane', 'Cruzinha, Pedro', 'Hamard, Jacques', 'Petersen, Brett', 'Sahyoun, Sebastien', "O'Connell, Keith", 'Symoshenko, Zhan', 'Luternauer, Jan', 'Coronado, Basil', 'Smith, Alex', 'Dittberner, Felix', 'N?sman, Henrik', 'King, Malisa', 'PUHLMANN Andre']
É complicado. Há várias opções para as entradas: Nome Sobrenome, Sobrenome Nome, Sobrenome, Nome, Sobrenome, Nome , etc. Ou seja, uma ordem diferente, um registro diferente, em algum lugar onde existe um separador - uma vírgula. Existem também muitos protocolos nos quais o cirílico é utilizado. Também não há uniformidade, e esses formatos podem ser encontrados: “Sobrenome Nome”, “Nome Sobrenome”, “Nome Sobrenome Sobrenome”, “Sobrenome Nome Sobrenome”. Embora, de fato, o nome do meio também seja encontrado na ortografia latina. E aqui, a propósito, surge mais um problema - transliteração. Também deve ser observado que, mesmo onde não há nome do meio, o registro não pode ser limitado a duas palavras. Por exemplo, para hispânicos, o nome mais o sobrenome geralmente consiste em três ou quatro palavras. Os holandeses têm o prefixo Van, os chineses e coreanos também têm nomes compostos geralmente com três palavras. Em geral, você precisa desvendar todo esse rebus e padronizá-lo ao máximo. Como regra, dentro de uma corrida, o formato do nome é o mesmo para todos, mas mesmo aqui há erros que, no entanto, não vamos resolver. Vamos começar armazenando os valores existentes no novo nome da coluna bruto :ar['name raw'] = ar['name']
A grande maioria dos protocolos está em latim, então a primeira coisa que gostaria de fazer é transliterar. Vamos ver quais caracteres podem ser incluídos no nome do participante.set( ''.join(ar['name'].unique()))
Out: [' ', '!', '"', '#', '&', "'", '(', ')', '*', '+', ',', '-', '.', '/', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', ':', ';', '>', '?', '@', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', '[', '\\', ']', '^', '_', '`', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', '|', '\x7f', '\xa0', '¤', '¦', '§', '', '«', '\xad', '', '°', '±', 'µ', '¶', '·', '»', '', 'І', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', 'є', 'і', 'ў', '–', '—', '‘', '’', '‚', '“', '”', '„', '†', '‡', '…', '‰', '›', '']
O que há apenas! Além das letras e espaços reais, ainda existem vários caracteres estranhos diferentes. Desses, o período '.', O hífen '-' e o apóstrofo “'” podem ser considerados válidos, ou seja, não estão presentes por engano. Além disso, notou-se que em muitos nomes e sobrenomes alemães e noruegueses há um ponto de interrogação '?'. Aparentemente, eles estão substituindo os caracteres do alfabeto latino estendido - '?', 'A', 'o', 'u',? e outros exemplos: A vírgula, embora ocorra com muita frequência, é apenas um separador, adotado em certas raças, de modo que também cairá na categoria de inaceitável. Os números também não devem aparecer nos nomes.Pierre-Alexandre Petit, Jean-louis Lafontaine, Faris Al-Sultan, Jean-Francois Evrard, Paul O'Mahony, Aidan O'Farrell, John O'Neill, Nick D'Alton, Ward D'Hulster, Hans P.J. Cami, Luis E. Benavides, Maximo Jr. Rueda, Prof. Dr. Tim-Nicolas Korf, Dr. Boris Scharlowsk, Eberhard Gro?mann, Magdalena Wei?, Gro?er Axel, Meyer-Szary Krystian, Morten Halkj?r, RASMUSSEN S?ren Balle
bs = [s for s in symbols if not (s.isalpha() or s in " . - ' ? ,")]
bs
Out: ['!', '"', '#', '&', '(', ')', '*', '+', '/', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', ':', ';', '>', '@', '[', '\\', ']', '^', '_', '`', '|', '\x7f', '\xa0', '¤', '¦', '§', '', '«', '\xad', '', '°', '±', '¶', '·', '»', '–', '—', '‘', '’', '‚', '“', '”', '„', '†', '‡', '…', '‰', '›', '']
Removeremos temporariamente todos esses caracteres para descobrir quantas entradas eles estão presentes:for s in bs:
ar['name'] = ar['name'].str.replace(s, '')
corr = ar[ar['name'] != ar['name raw']]
Existem 2.184 registros, ou seja, apenas 0,15% do número total - muito poucos. Vamos dar uma olhada em 100 deles:list(corr['name raw'].sample(100))
Out: ['Scha¶ffl, Ga?nter', 'Howard, Brian &', 'Chapiewski, Guilherme (Gc)', 'Derkach 1svd_mail_ru', 'Parker H1 Lauren', 'Leal le?n, Yaneri', 'TencA, David', 'Cortas La?pez, Alejandro', 'Strid, Bja¶rn', '(Crutchfield) Horan, Katie', 'Vigneron, Jean-Michel.Vigneron@gmail.Com', '\xa0', 'Telahr, J†rgen', 'St”rmer, Melanie', 'Nagai B1 Keiji', 'Rinc?n, Mariano', 'Arkalaki, Angela (Evangelia)', 'Barbaro B1 Bonin Anna G:Charlotte', 'Ra?esch, Ja¶rg', "CAVAZZI NICCOLO\\'", 'D„nzel, Thomas', 'Ziska, Steffen (Gerhard)', 'Kobilica B1 Alen', 'Mittelholcz, Bala', 'Jimanez Aguilar, Juan Antonio', 'Achenza H1 Giovanni', 'Reppe H2 Christiane', 'Filipovic B2 Lazar', 'Machuca Ka?hnel, Ruban Alejandro', 'Gellert (Silberprinz), Christian', 'Smith (Guide), Matt', 'Lenatz H1 Benjamin', 'Da¶llinger, Christian', 'Mc Carthy B1 Patrick Donnacha G:Bryan', 'Fa¶llmer, Chris', 'Warner (Rivera), Lisa', 'Wang, Ruijia (Ray)', 'Mc Carthy B1 Donnacha', 'Jones, Nige (Paddy)', 'Sch”ler, Christoph', '\xa0', 'Holthaus, Adelhard (Allard)', 'Mi;Arro, Ana', 'Dr: Koch Stefan', '\xa0', '\xa0', 'Ziska, Steffen (Gerhard)', 'Albarraca\xadn Gonza?lez, Juan Francisco', 'Ha¶fling, Imke', 'Johnston, Eddie (Edwin)', 'Mulcahy, Bob (James)', 'Gottschalk, Bj”rn', '\xa0', 'Gretsch H2 Kendall', 'Scorse, Christopher (Chris)', 'Kiel‚basa, Pawel', 'Kalan, Magnus', 'Roderick "eric" SIMBULAN', 'Russell;, Mark', 'ROPES AND GRAY TEAM 3', 'Andrade, H?¦CTOR DANIEL', 'Landmann H2 Joshua', 'Reyes Rodra\xadguez, Aithami', 'Ziska, Steffen (Gerhard)', 'Ziska, Steffen (Gerhard)', 'Heuza, Pierre', 'Snyder B1 Riley Brad G:Colin', 'Feldmann, Ja¶rg', 'Beveridge H1 Nic', 'FAGES`, perrine', 'Frank", Dieter', 'Saarema¤el, Indrek', 'Betancort Morales, Arida–y', 'Ridderberg, Marie_Louise', '\xa0', 'Ka¶nig, Johannes', 'W Van(der Klugt', 'Ziska, Steffen (Gerhard)', 'Johnson, Nick26', 'Heinz JOHNER03', 'Ga¶rg, Andra', 'Maruo B2 Atsuko', 'Moral Pedrero H1 Eva Maria', '\xa0', 'MATUS SANTIAGO Osc1r', 'Stenbrink, Bja¶rn', 'Wangkhan, Sm1.Thaworn', 'Pullerits, Ta¶nu', 'Clausner, 8588294149', 'Castro Miranda, Josa Ignacio', 'La¶fgren, Pontuz', 'Brown, Jann ( Janine )', 'Ziska, Steffen (Gerhard)', 'Koay, Sa¶ren', 'Ba¶hm, Heiko', 'Oleksiuk B2 Vita', 'G Van(de Grift', 'Scha¶neborn, Guido', 'Mandez, A?lvaro', 'Garca\xada Fla?rez, Daniel']
Como resultado, após muita pesquisa, foi decidido: substituir todos os caracteres alfabéticos, além de um espaço, um hífen, um apóstrofo e um ponto de interrogação, por uma vírgula, um ponto e um símbolo e espaços '\ xa0' e substituir todos os outros caracteres por uma string vazia, ou seja, basta excluir.ar['name'] = ar['name raw']
for s in symbols:
if s.isalpha() or s in " - ? '":
continue
if s in ".,\xa0":
ar['name'] = ar['name'].str.replace(s, ' ')
else:
ar['name'] = ar['name'].str.replace(s, '')
Então se livre de espaços extras:ar['name'] = ar['name'].str.split().str.join(' ')
ar['name'] = ar['name'].str.strip()
Vamos ver o que aconteceu:ar.loc[corr.index].sample(10)
qmon = ar[(ar['name'].str.replace('?', '').str.strip() == '')&(ar['name']!='')]
Existem 3.429. Parece algo assim: Nosso objetivo de trazer nomes para o mesmo padrão é fazer com que os mesmos nomes pareçam iguais, mas diferentes de maneiras diferentes. No caso de nomes que consistem apenas em pontos de interrogação, eles diferem apenas no número de caracteres, mas isso não garante que nomes com o mesmo número sejam realmente iguais. Portanto, substituímos todos por uma string vazia e não serão considerados no futuro.ar.loc[qmon.index, 'name'] = ''
O número total de entradas em que o nome é a cadeia vazia é 3.454. Não muito - sobreviveremos. Agora que nos livramos de caracteres desnecessários, podemos prosseguir para a transliteração. Para fazer isso, primeiro traga tudo para minúsculas para não fazer o trabalho duplo.ar['name'] = ar['name'].str.lower()
Em seguida, crie um dicionário:trans = {'':'a', '':'b', '':'v', '':'g', '':'d', '':'e', '':'e', '':'zh', '':'z', '':'i', '':'y', '':'k', '':'l', '':'m', '':'n', '':'o', '':'p', '':'r', '':'s', '':'t', '':'u', '':'f', '':'kh', '':'ts', '':'ch', '':'sh', '':'shch', '':'', '':'y', '':'', '':'e', '':'yu', '':'ya', 'є':'e', 'і': 'i','ў':'w','µ':'m'}
Também incluía letras do chamado alfabeto cirílico estendido - 'є', 'і', 'ў' , que são usadas nas línguas bielorrussa e ucraniana, além da letra grega 'µ' . Aplique a transformação:for s in trans:
ar['name'] = ar['name'].str.replace(s, trans[s])
Agora, a partir da letra minúscula, traduziremos tudo para o formato familiar, onde o nome e o sobrenome começam com uma letra maiúscula:ar['name'] = ar['name'].str.title()
Vamos ver o que aconteceu.ar[ar['name raw'].str.lower().str[0].isin(trans.keys())].sample(10)
set( ''.join(ar['name'].unique()))
Out: [' ', "'", '-', '?', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J','K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']
Tudo está correto. Como resultado, as correções afetaram 1.253.882 ou 89% dos registros, o número de nomes exclusivos diminuiu de 660.207 para 599.186, ou seja, 61 mil ou quase 10%. Uau! Salve em um novo arquivo, depois de converter a união dos registros ar novamente no dicionário de protocolo rd .pkl.dump(rd, open(r'D:\tri\details4.pkl', 'wb'))
Agora precisamos restaurar a ordem. Ou seja, com a aparência de todos os registros - Nome Sobrenome ou Sobrenome Nome . Qual deles deve ser determinado. É verdade que, além do nome e sobrenome, alguns protocolos também contêm nomes do meio. E pode acontecer que a mesma pessoa seja escrita de maneira diferente em diferentes protocolos - em algum lugar com um nome do meio, em algum lugar sem. Isso interferirá na identificação dele, portanto, tente remover o nome do meio. Os nomes patronímicos para homens geralmente têm o final "hiv" e para as mulheres - "vna" . Mas há exceções. Por exemplo - Ilyich, Ilyinichna, Nikitich, Nikitichna. É verdade que existem muito poucas exceções. Como já observado, o formato dos nomes em um protocolo pode ser considerado permanente. Portanto, para se livrar dos patronímicos, você precisa encontrar a raça em que eles estão presentes. Para fazer isso, encontre o número total de fragmentos "vich" e "vna" no nome da colunae compare-os com o número total de entradas em cada protocolo. Se esses números estiverem próximos, haverá um nome do meio, caso contrário não. Não é razoável procurar uma correspondência estrita, porque mesmo em corridas onde os nomes do meio são gravados, por exemplo, estrangeiros podem participar, e eles serão gravados sem ele. Também acontece que o participante esqueceu ou não quis indicar seu nome do meio. Por outro lado, também existem sobrenomes terminados em “vich”, muitos na Bielorrússia e em outros países com os idiomas do grupo eslavo. Além disso, fizemos transliteração. Foi possível fazer essa análise antes da transliteração, mas existe a chance de perder um protocolo no qual existem nomes do meio, mas inicialmente ele já está em latim. Então está tudo bem.Então, procuraremos todos os protocolos nos quais o número de fragmentos “vich” e “vna” na colunanome é mais de 50% do número total de entradas no protocolo.wp = {}
for e in rd:
nvich = (''.join(rd[e]['name'])).count('vich')
nvna = (''.join(rd[e]['name'])).count('vna')
if nvich + nvna > 0.5*len(rd[e]):
wp[e] = rd[e]
Existem 29 protocolos, um deles é: E é interessante que, em vez de 50%, tomarmos 20% ou vice-versa 70%, o resultado não será alterado, ainda haverá 29. Então fizemos a escolha certa. Assim, menos de 20% - o efeito de sobrenomes, mais de 70% - o efeito de registros individuais sem nomes do meio. Depois de verificar o país com a ajuda de uma tabela dinâmica, 25 deles estavam na Rússia e 4 na Abkházia. Se movendo. Processaremos apenas registros com três componentes, ou seja, aqueles em que haja (presumivelmente) sobrenome, nome e nome do meio.sum_n3w = 0
sum_nnot3w = 0
for e in wp:
sum_n3w += len([n for n in wp[e]['name'] if len(n.split()) == 3])
sum_nnot3w += len(wp[e]) - n3w
A maioria desses registros é de 86%. Agora aqueles em que os três componentes são divididos em colunas nome0, nome1, nome2 :for e in wp:
ind3 = [i for i in rd[e].index if len(rd[e].loc[i,'name'].split()) == 3]
rd[e]['name0'] = ''
rd[e]['name1'] = ''
rd[e]['name2'] = ''
rd[e].loc[ind3, 'name0'] = rd[e].loc[ind3,'name'].str.split().str[0]
rd[e].loc[ind3, 'name1'] = rd[e].loc[ind3,'name'].str.split().str[1]
rd[e].loc[ind3, 'name2'] = rd[e].loc[ind3,'name'].str.split().str[2]
Eis a aparência de um dos protocolos: Aqui, em particular, fica claro que a gravação dos dois componentes não foi processada. Agora, para cada protocolo, você precisa determinar qual coluna tem um nome do meio. Existem apenas duas opções - nome1, nome2 , porque não pode estar em primeiro lugar. Uma vez determinado, coletaremos um novo nome já sem ele.for e in wp:
n1=(''.join(rd[e]['name1'])).count('vich')+(''.join(rd[e]['name1'])).count('vna')
n2=(''.join(rd[e]['name2'])).count('vich')+(''.join(rd[e]['name2'])).count('vna')
if (n1 > n2):
rd[e]['new name'] = rd[e]['name0'] + ' ' + rd[e]['name2']
else:
rd[e]['new name'] = rd[e]['name0'] + ' ' + rd[e]['name1']
for e in wp:
ind = rd[e][rd[e]['new name'].str.strip() != ''].index
rd[e].loc[ind, 'name'] = rd[e].loc[ind, 'new name']
rd[e] = rd[e].drop(columns = ['name0','name1','name2','new name'])
pkl.dump(rd, open(r'D:\tri\details5.pkl', 'wb'))
Agora você precisa trazer os nomes para a mesma ordem. Ou seja, é necessário que em todos os protocolos o nome seja seguido primeiro pelo sobrenome ou vice-versa - primeiro o sobrenome, depois o primeiro nome, também em todos os protocolos. Depende de que mais, agora vamos descobrir. A situação é um pouco complicada pelo fato de o nome completo poder consistir em mais de duas palavras, mesmo depois que removemos o nome do meio.ar['nwin'] = ar['name'].str.count(' ') + 1
ar.loc[ar['name'] == '','nwin'] = 0
100*ar['nwin'].value_counts()/len(ar)
Número de palavras em um nome Número de registros Parcela de registros (%) Obviamente, a grande maioria (91%) são duas palavras - apenas um nome e um sobrenome. Mas entradas com três e quatro palavras também são muitas. Vejamos a nacionalidade desses registros:ar[ar['nwin'] >= 3]['country'].value_counts()[:12]
Out:
ESP 28435
MEX 10561
USA 7608
DNK 7178
BRA 6321
NLD 5748
DEU 4310
PHL 3941
ZAF 3862
ITA 3691
BEL 3596
FRA 3323
Bem, em primeiro lugar está a Espanha, em segundo lugar - o México, um país hispânico, além dos Estados Unidos, onde também existem historicamente muitos hispânicos. Brasil e Filipinas também são nomes em espanhol (e português). A Dinamarca, a Holanda, a Alemanha, a África do Sul, a Itália, a Bélgica e a França são outra questão; simplesmente, às vezes, surge algum tipo de prefixo do sobrenome; portanto, existem mais de duas palavras. Em todos esses casos, no entanto, geralmente o próprio nome consiste em uma palavra e o sobrenome de duas, três. Obviamente, há exceções a essa regra, mas não as processaremos mais. Primeiro, para cada protocolo, você precisa determinar que tipo de ordem existe: sobrenome-nome ou vice-versa. Como fazer isso? Ocorreu-me a seguinte idéia: primeiro, a variedade de sobrenomes geralmente é muito maior que a variedade de nomes. Deve ser assim mesmo dentro da estrutura de um protocolo. Em segundo lugar,o tamanho do nome geralmente é menor que o tamanho do sobrenome (mesmo para sobrenomes não compostos). Usaremos uma combinação desses critérios para determinar a ordem preliminar.Selecione a primeira e a última palavra no nome completo:ar['new name'] = ar['name']
ind = ar[ar['nwin'] < 2].index
ar.loc[ind, 'new name'] = '. .'
ar['wfin'] = ar['new name'].str.split().str[0]
ar['lwin'] = ar['new name'].str.split().str[-1]
Converta o quadro de dados ar combinado de volta no dicionário rd para que as novas colunas nwin, ns0, ns caiam no quadro de dados de cada corrida. A seguir, determinamos o número de protocolos com a ordem “Nome Sobrenome” e o número de protocolos com a ordem inversa, de acordo com nosso critério. Consideraremos apenas as entradas em que o nome completo consiste em duas palavras. Ao mesmo tempo, salve o nome (primeiro nome) em uma nova coluna:name_surname = {}
surname_name = {}
for e in rd:
d = rd[e][rd[e]['nwin'] == 2]
if len(d['fwin'].unique()) < len(d['lwin'].unique()) and len(''.join(d['fwin'])) < len(''.join(d['lwin'])):
name_surname[e] = d
rd[e]['first name'] = rd[e]['fwin']
if len(d['fwin'].unique()) > len(d['lwin'].unique()) and len(''.join(d['fwin'])) > len(''.join(d['lwin'])):
surname_name[e] = d
rd[e]['first name'] = rd[e]['lwin']
O resultado foi o seguinte: os protocolos ordem Nome e Sobrenome - 244, e protocolo Sobrenome e nome - 1.508.Conseqüentemente, levaremos ao formato mais comum. A soma acabou sendo menor que o valor total, porque verificamos o cumprimento de dois critérios ao mesmo tempo e mesmo com uma desigualdade estrita. Existem protocolos em que apenas um dos critérios é cumprido ou é possível, mas é improvável que a igualdade ocorra. Mas isso é completamente sem importância, pois o formato está definido.Agora, supondo que tenhamos determinado o pedido com precisão suficientemente alta, sem esquecer que ele não é 100% exato, usaremos essas informações. Encontre os nomes mais populares na coluna do primeiro nome :vc = ar['first name'].value_counts()
tome aqueles que se encontraram mais de cem vezes:pfn=vc[vc>100]
havia 1.673 deles. Aqui estão as primeiras cem, organizadas em ordem decrescente de popularidade: Agora, usando esta lista, percorreremos todos os protocolos e comparamos onde há mais correspondências - na primeira palavra do nome ou na última. Consideraremos apenas nomes de duas palavras. Se houver mais correspondências com a última palavra, a ordem está correta; se com a primeira, significa o contrário. Além disso, aqui já estamos mais confiantes, para que você possa usar esse conhecimento e adicionaremos uma lista de nomes de seu próximo protocolo à lista inicial de nomes populares a cada passagem. Classificamos previamente os protocolos pela frequência de ocorrência de nomes da lista inicial, a fim de evitar erros aleatórios e preparamos uma lista mais extensa para os protocolos em que há poucas correspondências e que serão processados no final do ciclo.['Michael', 'David', 'Thomas', 'John', 'Daniel', 'Mark', 'Peter', 'Paul', 'Christian', 'Robert', 'Martin', 'James', 'Andrew', 'Chris', 'Richard', 'Andreas', 'Matthew', 'Brian', 'Patrick', 'Scott', 'Kevin', 'Stefan', 'Jason', 'Eric', 'Christopher', 'Alexander', 'Simon', 'Mike', 'Tim', 'Frank', 'Stephen', 'Steve', 'Andrea', 'Jonathan', 'Markus', 'Marco', 'Adam', 'Ryan', 'Jan', 'Tom', 'Marc', 'Carlos', 'Jennifer', 'Matt', 'Steven', 'Jeff', 'Sergey', 'William', 'Aleksandr', 'Sarah', 'Alex', 'Jose', 'Andrey', 'Benjamin', 'Sebastian', 'Ian', 'Anthony', 'Ben', 'Oliver', 'Antonio', 'Ivan', 'Sean', 'Manuel', 'Matthias', 'Nicolas', 'Dan', 'Craig', 'Dmitriy', 'Laura', 'Luis', 'Lisa', 'Kim', 'Anna', 'Nick', 'Rob', 'Maria', 'Greg', 'Aleksey', 'Javier', 'Michelle', 'Andre', 'Mario', 'Joseph', 'Christoph', 'Justin', 'Jim', 'Gary', 'Erik', 'Andy', 'Joe', 'Alberto', 'Roberto', 'Jens', 'Tobias', 'Lee', 'Nicholas', 'Dave', 'Tony', 'Olivier', 'Philippe']
sbpn = pd.DataFrame(columns = ['event', 'num pop names'], index=range(len(rd)))
for i in range(len(rd)):
e = list(rd.keys())[i]
sbpn.loc[i, 'event'] = e
sbpn.loc[i, 'num pop names'] = len(set(pfn).intersection(rd[e]['first name']))
sbnp=sbnp.sort_values(by = 'num pop names',ascending=False)
sbnp = sbnp.reset_index(drop=True)
tofix = []
for i in range(len(rd)):
e = sbpn.loc[i, 'event']
if len(set(list(rd[e]['fwin'])).intersection(pfn)) > len(set(list(rd[e]['lwin'])).intersection(pfn)):
tofix.append(e)
pfn = list(set(pfn + list(rd[e]['fwin'])))
else:
pfn = list(set(pfn + list(rd[e]['lwin'])))
Havia 235 protocolos. Ou seja, quase o mesmo que aconteceu na primeira aproximação (244). Para ter certeza, olhei seletivamente os três primeiros registros de cada um, verifiquei se tudo estava correto. Verifique também se o primeiro estágio da classificação forneceu 36 entradas falsas no Sobrenome do Nome da Classe e 2 falsas no Nome do Nome da Classe . Eu olhei para os três primeiros discos de cada um, de fato, o segundo estágio funcionou perfeitamente. Agora, de fato, resta corrigir os protocolos em que a ordem errada é encontrada:for e in tofix:
ind = rd[e][rd[e]['nwin'] > 1].index
rd[e].loc[ind,'name'] = rd[e].loc[ind,'name'].str.split(n=1).str[1] + ' ' + rd[e].loc[ind,'name'].str.split(n=1).str[0]
Aqui na divisão, limitamos o número de peças usando o parâmetro n . A lógica é a seguinte: um nome é uma palavra, a primeira em um nome completo. Todo o resto é um sobrenome (pode consistir em várias palavras). Apenas troque-os.Agora nos livramos de colunas desnecessárias e salvamos:for e in rd:
rd[e] = rd[e].drop(columns = ['new name', 'first name', 'fwin','lwin', 'nwin'])
pkl.dump(rd, open(r'D:\tri\details6.pkl', 'wb'))
Verifique o resultado. Uma dúzia aleatória de registros fixos: um total de 108 mil registros foram corrigidos. O número de nomes completos exclusivos diminuiu de 598 para 547 mil. Bem! Com a formatação concluída.Parte 3. Recuperação de dados incompletos
Agora vá para recuperar os dados ausentes. E existem tais.País
Vamos começar com o país. Encontre todos os registros em que o país não está indicado:arnc = ar[ar['country'] == '']
Existem 3.221 deles, e aqui estão 10 aleatórios:nnc = arnc['name'].unique()
O número de nomes exclusivos entre registros sem país é 3 051. Vamos ver se esse número pode ser reduzido.O fato é que, no triatlo, as pessoas raramente se limitam a apenas uma corrida, geralmente participam de competições periodicamente, várias vezes por temporada, de ano para ano, treinando constantemente. Portanto, para muitos nomes nos dados, provavelmente há mais de um registro. Para restaurar informações sobre o país, tente encontrar registros com o mesmo nome entre aqueles em que o país está indicado.arwc = ar[ar['country'] != '']
nwc = arwc['name'].unique()
tofix = set(nnc).intersection(nwc)
Out: ['Kleber-Schad Ute Cathrin', 'Sellner Peter', 'Pfeiffer Christian', 'Scholl Thomas', 'Petersohn Sandra', 'Marchand Kurt', 'Janneck Britta', 'Angheben Riccardo', 'Thiele Yvonne', 'Kie?Wetter Martin', 'Schymik Gerhard', 'Clark Donald', 'Berod Brigitte', 'Theile Markus', 'Giuliattini Burbui Margherita', 'Wehrum Alexander', 'Kenny Oisin', 'Schwieger Peter', 'Grosse Bianca', 'Schafter Carsten', 'Breck Dirk', 'Mautes Christoph', 'Herrmann Andreas', 'Gilbert Kai', 'Steger Peter', 'Jirouskova Jana', 'Jehrke Michael', 'Valentine David', 'Reis Michael', 'Wanka Michael', 'Schomburg Jonas', 'Giehl Caprice', 'Zinser Carsten', 'Schumann Marcus', 'Magoni Livio', 'Lauden Yann', 'Mayer Dieter', 'Krisa Stefan', 'Haberecht Bernd', 'Schneider Achim', 'Gibanel Curto Antonio', 'Miranda Antonio', 'Juarez Pedro', 'Prelle Gerrit', 'Wuste Kay', 'Bullock Graeme', 'Hahner Martin', 'Kahl Maik', 'Schubnell Frank', 'Hastenteufel Marco', …]
Havia 2.236 deles, ou seja, quase três quartos. Agora, para cada nome desta lista, você precisa determinar o país pelos registros onde está. Mas acontece que o mesmo nome é encontrado em vários registros e em diferentes países. Este é o xará, ou talvez a pessoa tenha se mudado. Portanto, primeiro processamos aqueles em que tudo é único.fix = {}
for n in tofix:
nr = arwc[arwc['name'] == n]
if len(nr['country'].unique()) == 1:
fix[n] = nr['country'].iloc[0]
Feito em um loop. Mas, francamente, funciona por um longo tempo - cerca de três minutos. Se houvesse uma ordem de magnitude em mais entradas, você provavelmente teria que criar uma implementação de vetor. Havia 2.013 entradas, ou 90% do potencial.Os nomes para os quais diferentes países podem aparecer em diferentes registros levam o país que ocorre com mais frequência.if n not in fix:
nr = arwc[arwc['name'] == n]
vc = nr['country'].value_counts()
if vc[0] > vc[1]:
fix[n] = vc.index[0]
Assim, foram encontradas correspondências para 2.208 nomes, ou 99% de todos os possíveis. Aplicamos as seguintes correspondências:{'Kleber-Schad Ute Cathrin': 'DEU', 'Sellner Peter': 'AUT', 'Pfeiffer Christian': 'AUT', 'Scholl Thomas': 'DEU', 'Petersohn Sandra': 'DEU', 'Marchand Kurt': 'BEL', 'Janneck Britta': 'DEU', 'Angheben Riccardo': 'ITA', 'Thiele Yvonne': 'DEU', 'Kie?Wetter Martin': 'DEU', 'Clark Donald': 'GBR', 'Berod Brigitte': 'FRA', 'Theile Markus': 'DEU', 'Giuliattini Burbui Margherita': 'ITA', 'Wehrum Alexander': 'DEU', 'Kenny Oisin': 'IRL', 'Schwieger Peter': 'DEU', 'Schafter Carsten': 'DEU', 'Breck Dirk': 'DEU', 'Mautes Christoph': 'DEU', 'Herrmann Andreas': 'DEU', 'Gilbert Kai': 'DEU', 'Steger Peter': 'AUT', 'Jirouskova Jana': 'CZE', 'Jehrke Michael': 'DEU', 'Wanka Michael': 'DEU', 'Giehl Caprice': 'DEU', 'Zinser Carsten': 'DEU', 'Schumann Marcus': 'DEU', 'Magoni Livio': 'ITA', 'Lauden Yann': 'FRA', 'Mayer Dieter': 'DEU', 'Krisa Stefan': 'DEU', 'Haberecht Bernd': 'DEU', 'Schneider Achim': 'DEU', 'Gibanel Curto Antonio': 'ESP', 'Juarez Pedro': 'ESP', 'Prelle Gerrit': 'DEU', 'Wuste Kay': 'DEU', 'Bullock Graeme': 'GBR', 'Hahner Martin': 'DEU', 'Kahl Maik': 'DEU', 'Schubnell Frank': 'DEU', 'Hastenteufel Marco': 'DEU', 'Tedde Roberto': 'ITA', 'Minervini Domenico': 'ITA', 'Respondek Markus': 'DEU', 'Kramer Arne': 'DEU', 'Schreck Alex': 'DEU', 'Bichler Matthias': 'DEU', …}
for n in fix:
ind = arnc[arnc['name'] == n].index
ar.loc[ind, 'country'] = fix[n]
pkl.dump(rd, open(r'D:\tri\details7.pkl', 'wb'))
Chão
Como no caso de países, existem registros nos quais o sexo do participante não é indicado.ar[ar['sex'] == '']
Existem 2.538. Relativamente poucos, mas novamente tentaremos ganhar ainda menos. Salve os valores originais em uma nova coluna.ar['sex raw'] =ar['sex']
Ao contrário dos países onde recuperamos informações por nome de outros protocolos, tudo é um pouco mais complicado aqui. O fato é que os dados estão cheios de erros e existem muitos nomes (total de 2 101) encontrados com marcas de ambos os sexos.arws = ar[(ar['sex'] != '')&(ar['name'] != '')]
snds = arws[arws.duplicated(subset='name',keep=False)]
snds = snds.drop_duplicates(subset=['name','sex'], keep = 'first')
snds = snds.sort_values(by='name')
snds = snds[snds.duplicated(subset = 'name', keep=False)]
snds
rss = [rd[e] for e in rd if len(rd[e][rd[e]['sex'] != '']['sex'].unique()) == 1]
Existem 633. Parece que isso é bem possível, apenas um protocolo separadamente para mulheres, separadamente para homens. Mas o fato é que quase todos esses protocolos contêm faixas etárias de ambos os sexos (as faixas etárias masculinas começam com a letra M , do sexo feminino - com a letra F ). Por exemplo: Espera-se que o nome da faixa etária comece com a letra M para homens e com a letra F para mulheres. Nos dois exemplos anteriores, apesar dos erros na coluna de sexo'ITU World Cup Tiszaujvaros Olympic 2002'
, o nome do grupo ainda parecia descrever corretamente o sexo do membro. Com base em vários exemplos de amostra, assumimos que o grupo está indicado corretamente e que o sexo pode ser indicado erroneamente. Encontre todas as entradas em que a primeira letra no nome do grupo não corresponde ao sexo. Tomaremos o nome inicial do grupo do grupo em bruto , pois durante a padronização muitos registros foram deixados sem um grupo, mas agora precisamos apenas da primeira letra, portanto o padrão não é importante.ar['grflc'] = ar['group raw'].str.upper().str[0]
grncs = ar[(ar['grflc'].isin(['M','F']))&(ar['sex']!=ar['grflc'])]
Existem 26 161 tais registros. Bem, vamos corrigir o sexo de acordo com o nome da faixa etária:ar.loc[grncs.index, 'sex'] = grncs['grflc']
Vejamos o resultado: Bom. Quantos registros restam agora sem gênero?ar[(ar['sex'] == '')&(ar['name'] != '')]
Acontece exatamente um! Bem, o grupo não está realmente indicado, mas, aparentemente, esta é uma mulher. Emily é um nome feminino, além deste participante (ou seu homônimo) terminado um ano antes, e nesse protocolo sexo e grupo são indicados. Restaure aqui manualmente * e siga em frente.ar.loc[arns.index, 'sex'] = 'F'
Agora todos os registros estão com o gênero.* Em geral, é claro, é errado fazer isso - com execuções repetidas, se algo na cadeia mudar antes, por exemplo, na conversão de nomes, pode haver mais de um registro sem gênero e nem todos serão do sexo feminino, e nem todos serão do sexo feminino, ocorrerá um erro. Portanto, você deve inserir uma lógica pesada para procurar um participante com o mesmo nome e sexo em outros protocolos, como restaurar um país e testá-lo de alguma forma, ou, para não complicar desnecessariamente, adicionar a essa lógica uma verificação para verificar apenas um registro e o nome é tal e tal; caso contrário, lance uma exceção que interromperá o laptop inteiro; você poderá observar um desvio do plano e intervir.if len(arns) == 1 and arns['name'].iloc[0] == 'Stather Emily':
ar.loc[arns.index, 'sex'] = 'F'
else:
raise Exception('Different scenario!')
Parece que isso pode se acalmar. Mas o fato é que as correções são baseadas na suposição de que o grupo está indicado corretamente. E de fato é. Quase sempre. Por pouco. Ainda assim, várias inconsistências foram acidentalmente notadas, então agora vamos tentar determinar todas elas, bem ou o máximo possível. Como já mencionado, no primeiro exemplo, era precisamente o fato de o gênero não corresponder ao nome com base em suas próprias idéias sobre nomes masculinos e femininos nos protegiam.Encontre todos os nomes nos registros masculinos e femininos. Aqui, o nome é entendido como o nome, e não o nome completo, ou seja, sem sobrenome, o que é chamado de primeiro nome em inglês .ar['fn'] = ar['name'].str.split().str[-1]
mfn = list(ar[ar['sex'] == 'M']['fn'].unique())
Um total de 32.508 nomes masculinos estão listados. Aqui estão os 50 mais populares:['Michael', 'David', 'Thomas', 'John', 'Daniel', 'Mark', 'Peter', 'Paul', 'Christian', 'Robert', 'Martin', 'James', 'Andrew', 'Chris', 'Richard', 'Andreas', 'Matthew', 'Brian', 'Kevin', 'Patrick', 'Scott', 'Stefan', 'Jason', 'Eric', 'Alexander', 'Christopher', 'Simon', 'Mike', 'Tim', 'Frank', 'Stephen', 'Steve', 'Jonathan', 'Marco', 'Markus', 'Adam', 'Ryan', 'Tom', 'Jan', 'Marc', 'Carlos', 'Matt', 'Steven', 'Jeff', 'Sergey', 'William', 'Aleksandr', 'Andrey', 'Benjamin', 'Jose']
ffn = list(ar[ar['sex'] == 'F']['fn'].unique())
Menos mulheres - 14 423. Mais populares: Bom, parece lógico. Vamos ver se existem cruzamentos.['Jennifer', 'Sarah', 'Laura', 'Lisa', 'Anna', 'Michelle', 'Maria', 'Andrea', 'Nicole', 'Jessica', 'Julie', 'Elizabeth', 'Stephanie', 'Karen', 'Christine', 'Amy', 'Rebecca', 'Susan', 'Rachel', 'Anne', 'Heather', 'Kelly', 'Barbara', 'Claudia', 'Amanda', 'Sandra', 'Julia', 'Lauren', 'Melissa', 'Emma', 'Sara', 'Katie', 'Melanie', 'Kim', 'Caroline', 'Erin', 'Kate', 'Linda', 'Mary', 'Alexandra', 'Christina', 'Emily', 'Angela', 'Catherine', 'Claire', 'Elena', 'Patricia', 'Charlotte', 'Megan', 'Daniela']
mffn = set(mfn).intersection(ffn)
Há sim. E existem 2.811. Vamos examiná-los mais de perto. Para começar, descobrimos quantos registros com esses nomes:armfn = ar[ar['fn'].isin(mffn)]
Existem 725 562. Isso é metade! É maravilhoso! Existem quase 37.000 nomes exclusivos, mas metade dos registros tem um total de 2.800. Vamos ver quais são esses nomes, quais são os mais populares. Para fazer isso, crie um novo quadro de dados onde esses nomes serão índices:df = pd.DataFrame(armfn['fn'].value_counts())
df = df.rename(columns={'fn':'total'})
Calculamos quantos registros masculinos e femininos com cada um deles.df['M'] = armfn[armfn['sex'] == 'M']['fn'].value_counts()
df['F'] = armfn[armfn['sex'] == 'F']['fn'].value_counts()
df.sort_values(by = 'F', ascending=False)
import gender_guesser.detector as gg
d = gg.Detector()
d.get_gender(u'Oleg')
Out: 'male'
d.get_gender(u'Evgeniya')
Out: 'female'
Está tudo bem. Mas se você verificar o nome Andrea , ele também dará o sexo feminino , o que não é inteiramente verdade. É verdade que há uma saída. Se você olhar para a propriedade de nomes do detector, toda a ambiguidade se tornará visível lá.d.names['Andrea']
Out: {'female': ' 4 4 3 4788 64 579 34 1 7 ',
'mostly_female': '5 6 7 ',
'male': ' 7 '}
Sim, isto é, get_gender apenas oferece a opção mais provável, mas, na realidade, pode ser muito mais complicado. Verifique outros nomes:d.names['Maria']
Out: {'female': '686 6 A 85986 A BA 3B98A75457 6 ',
'mostly_female': ' BBC A 678A9 '}
d.names['Oleg']
Out: {'male': ' 6 2 99894737 3 '}
Ou seja, a lista de nomes para cada nome corresponde a um ou mais pares de valores-chave, onde a chave - é sexo: masculino, FEMININO, maioritariamente masculino, principalmente feminino, andy e o valor - a lista de valores do país correspondente: 1,2,3 ... 9ABC . Os países são:d.COUNTRIES
Out: ['great_britain', 'ireland', 'usa', 'italy', 'malta', 'portugal', 'spain', 'france', 'belgium', 'luxembourg', 'the_netherlands', 'east_frisia', 'germany', 'austria', 'swiss', 'iceland', 'denmark', 'norway', 'sweden', 'finland', 'estonia', 'latvia', 'lithuania', 'poland', 'czech_republic', 'slovakia', 'hungary', 'romania', 'bulgaria', 'bosniaand', 'croatia', 'kosovo', 'macedonia', 'montenegro', 'serbia', 'slovenia', 'albania', 'greece', 'russia', 'belarus', 'moldova', 'ukraine', 'armenia', 'azerbaijan', 'georgia', 'the_stans', 'turkey', 'arabia', 'israel', 'china', 'india', 'japan', 'korea', 'vietnam', 'other_countries']
Não entendi completamente o que significam os significados alfanuméricos ou a ausência deles na lista. Mas isso não era importante, pois decidi me limitar a usar apenas os nomes que têm uma interpretação inequívoca. Ou seja, para o qual existe apenas um par de valores-chave e a chave é masculina ou feminina . Para cada nome do nosso quadro de dados, escreva sua interpretação de adivinhador de gênero :df['sex from gg'] = ''
for n in df.index:
if n in list(d.names.keys()):
options = list(d.names[n].keys())
if len(options) == 1 and options[0] == 'male':
df.loc[n, 'sex from gg'] = 'M'
if len(options) == 1 and options[0] == 'female':
df.loc[n, 'sex from gg'] = 'F'
Descobriram 1.150 nomes. Aqui estão os mais populares que já foram discutidos acima: Bem, nada mal. Agora aplique essa lógica a todos os registros.all_names = ar['fn'].unique()
male_names = []
female_names = []
for n in all_names:
if n in list(d.names.keys()):
options = list(d.names[n].keys())
if len(options) == 1:
if options[0] == 'male':
male_names.append(n)
if options[0] == 'female':
female_names.append(n)
Encontrados 7 091 nomes masculinos e 5 054 femininos. Aplique a transformação:tofixm = ar[ar['fn'].isin(male_names)]
ar.loc[tofixm.index, 'sex'] = 'M'
tofixf = ar[ar['fn'].isin(female_names)]
ar.loc[tofixf.index, 'sex'] = 'F'
Nós olhamos para o resultado:ar[ar['sex']!=ar['sex raw']]
Corrigidas 30.352 entradas (juntamente com a correção pelo nome do grupo). Como sempre, 10 aleatórias: agora que temos certeza de que identificamos corretamente o sexo, também alinharemos grupos padrão. Vamos ver onde eles não correspondem:ar['gfl'] = ar['group'].str[0]
gncws = ar[(ar['sex'] != ar['gfl']) & (ar['group']!='')]
4.248 entradas. Substitua a primeira letra:ar.loc[gncws.index, 'group'] = ar.loc[gncws.index, 'sex'] + ar.loc[gncws.index, 'group'].str[1:].index, 'sex']
pkl.dump(rd, open(r'D:\tri\details8.pkl', 'wb'))
Isso é tudo, com a recuperação de dados incompletos.Atualização do Boletim
Resta atualizar a tabela de resumo com dados atualizados sobre o número de homens e mulheres, etc.rs['total raw'] = rs['total']
rs['males raw'] = rs['males']
rs['females raw'] = rs['females']
rs['rus raw'] = rs['rus']
for i in rs.index:
e = rs.loc[i,'event']
rs.loc[i,'total'] = len(rd[e])
rs.loc[i,'males'] = len(rd[e][rd[e]['sex'] == 'M'])
rs.loc[i,'females'] = len(rd[e][rd[e]['sex'] == 'F'])
rs.loc[i,'rus'] = len(rd[e][rd[e]['country'] == 'RUS'])
len(rs[rs['total'] != rs['total raw']])
Out: 288
len(rs[rs['males'] != rs['males raw']])
Out:962
len(rs[rs['females'] != rs['females raw']])
Out: 836
len(rs[rs['rus'] != rs['rus raw']])
Out: 8
pkl.dump(rs, open(r'D:\tri\summary6.pkl', 'wb'))
Parte 4. Amostragem
Agora, o triatlo é muito popular. Durante a temporada, há muitas competições abertas nas quais um grande número de atletas, principalmente amadores, participa. Mas não foi sempre assim. Existem registros em nossos dados desde 1990. Percorrendo tristats.ru, notei que há muito mais corridas nos últimos anos e muito poucas no primeiro. Mas agora que nossos dados foram preparados, você pode analisá-los mais de perto.Período de dez anos
Conte o número de corridas e finalistas em cada ano:rs['year'] = pd.DatetimeIndex(rs['date']).year
years = range(rs['year'].min(),rs['year'].max())
rsy = pd.DataFrame(columns = ['races', 'finishers', 'rus', 'RUS'], index = years)
for y in rsy.index:
rsy.loc[y,'races'] = len(rs[rs['year'] == y])
rsy.loc[y,'finishers'] = sum(rs[rs['year'] == y]['total'])
rsy.loc[y,'rus'] = sum(rs[rs['year'] == y]['rus'])
rsy.loc[y,'RUS'] = len(rs[(rs['year'] == y)&(rs['country'] == 'RUS')])
 Pode-se ver que o número de corridas e participantes no início do período e no final é simplesmente incomensurável. Um aumento significativo no número total de corridas começa em 2011, enquanto o número de partidas na Rússia também aumenta. Além disso, um aumento no número de participantes pode ser observado em 2009. Isso pode indicar aumento do interesse entre os participantes, ou seja, aumento da demanda, após os quais dois anos depois a oferta aumentou, ou seja, o número de partidas. No entanto, não esqueça que os dados podem não estar completos e estão faltando algumas, e possivelmente muitas corridas. Inclusive devido ao fato de o projeto de coleta desses dados ter começado apenas em 2010, o que também pode explicar o salto significativo no gráfico neste exato momento. Incluindo, portanto, para uma análise mais aprofundada, decidi levar os últimos 10 anos. Este é um período bastante longo,para acompanhar qualquer tendência ao longo de vários anos, embora curta o suficiente para não chegar lá, principalmente competições profissionais dos anos 90 e início dos anos 2000.
Pode-se ver que o número de corridas e participantes no início do período e no final é simplesmente incomensurável. Um aumento significativo no número total de corridas começa em 2011, enquanto o número de partidas na Rússia também aumenta. Além disso, um aumento no número de participantes pode ser observado em 2009. Isso pode indicar aumento do interesse entre os participantes, ou seja, aumento da demanda, após os quais dois anos depois a oferta aumentou, ou seja, o número de partidas. No entanto, não esqueça que os dados podem não estar completos e estão faltando algumas, e possivelmente muitas corridas. Inclusive devido ao fato de o projeto de coleta desses dados ter começado apenas em 2010, o que também pode explicar o salto significativo no gráfico neste exato momento. Incluindo, portanto, para uma análise mais aprofundada, decidi levar os últimos 10 anos. Este é um período bastante longo,para acompanhar qualquer tendência ao longo de vários anos, embora curta o suficiente para não chegar lá, principalmente competições profissionais dos anos 90 e início dos anos 2000.rs = rs[(rs['year']>=2010)&(rs['year']<= 2019)]
 No período selecionado, a propósito, 84% das corridas e 94% dos finalistas caíram.
No período selecionado, a propósito, 84% das corridas e 94% dos finalistas caíram.Começos amadores
Assim, a grande maioria dos participantes nas partidas selecionadas são atletas amadores, portanto, boas estatísticas podem ser obtidas com eles. Sinceramente, isso foi de grande interesse para mim, já que eu próprio participei de tais partidas, mas em nível está muito longe dos campeões olímpicos. Obviamente, competições profissionais também ocorreram no período selecionado. Para não misturar os indicadores das raças amadoras e profissionais, decidiu-se retirar o último da consideração. Como identificá-los? Pela velocidade. Nós os calculamos. Em um dos estágios iniciais da preparação dos dados, já determinamos que tipo de distância havia em cada corrida - sprint, olímpico, meio, ferro. Para cada um deles, a quilometragem das etapas é claramente definida - natação, ciclismo e corrida. Isso é 0,75 + 20 + 5 para o sprint, 1,5 + 40 + 10 para o Olímpico, 1,9 + 90 + 21,1 para o meio e 3.8 + 180 + 42,2 para ferro. É claro que, de fato, para qualquer tipo, números reais podem variar de raça para raça condicionalmente até um por cento, mas não há informações sobre isso, portanto, assumiremos que tudo estava correto.rs['km'] = ''
rs.loc[rs['dist'] == 'sprint', 'km'] = 0.75+20+5
rs.loc[rs['dist'] == 'olympic', 'km'] = 1.5+40+10
rs.loc[rs['dist'] == 'half', 'km'] = 1.9+90+21.1
rs.loc[rs['dist'] == 'full', 'km'] = 3.8+180+42.2
Calculamos as velocidades média e máxima para cada corrida. O máximo aqui é a velocidade média do atleta que conquistou o primeiro lugar.for index, row in rs.iterrows():
e = row['event']
rd[e]['th'] = pd.TimedeltaIndex(rd[e]['result']).seconds/3600
rd[e]['v'] = rs.loc[i, 'km'] / rd[e]['th']
for index, row in rs.iterrows():
e = row['event']
rs.loc[index,'vmax'] = rd[e]['v'].max()
rs.loc[index,'vavg'] = rd[e]['v'].mean()
 Bem, você pode ver que a maior parte das velocidades se acumulava entre 15 km / he 30 km / h, mas há um certo número de valores completamente "cósmicos". Classifique pela velocidade média e veja quantas delas:
Bem, você pode ver que a maior parte das velocidades se acumulava entre 15 km / he 30 km / h, mas há um certo número de valores completamente "cósmicos". Classifique pela velocidade média e veja quantas delas:rs = rs.sort_values(by='vavg')
 Aqui, alteramos a escala e podemos estimar o intervalo com mais precisão. Para velocidades médias, é de cerca de 17 km / ha 27 km / h, no máximo - de 18 km / ha 32 km / h. Além disso, existem "caudas" com velocidades médias muito baixas e muito altas. As velocidades baixas provavelmente correspondem a competições extremas, como o Norseman , e as altas velocidades podem ocorrer no caso de natação cancelada, onde, em vez de um sprint, houve um super sprint, ou simplesmente dados errados. Outro ponto importante é o passo suave na área de 1200 ao longo do eixo Xe valores mais altos da velocidade média após ela. Lá você pode ver uma diferença significativamente menor entre as velocidades média e máxima do que nos primeiros dois terços do gráfico. Aparentemente, esta é uma competição profissional. Para distingui-los mais claramente, calculamos a razão entre velocidade máxima e média. Nas competições profissionais em que não há pessoas aleatórias e todos os participantes têm um nível muito alto de aptidão física, essa proporção deve ser mínima.
Aqui, alteramos a escala e podemos estimar o intervalo com mais precisão. Para velocidades médias, é de cerca de 17 km / ha 27 km / h, no máximo - de 18 km / ha 32 km / h. Além disso, existem "caudas" com velocidades médias muito baixas e muito altas. As velocidades baixas provavelmente correspondem a competições extremas, como o Norseman , e as altas velocidades podem ocorrer no caso de natação cancelada, onde, em vez de um sprint, houve um super sprint, ou simplesmente dados errados. Outro ponto importante é o passo suave na área de 1200 ao longo do eixo Xe valores mais altos da velocidade média após ela. Lá você pode ver uma diferença significativamente menor entre as velocidades média e máxima do que nos primeiros dois terços do gráfico. Aparentemente, esta é uma competição profissional. Para distingui-los mais claramente, calculamos a razão entre velocidade máxima e média. Nas competições profissionais em que não há pessoas aleatórias e todos os participantes têm um nível muito alto de aptidão física, essa proporção deve ser mínima.rs['vmdbva'] = rs['vmax']/rs['vavg']
rs = rs.sort_values(by='vmdbva')
 Nesse gráfico, o primeiro trimestre se destaca com muita clareza: a relação velocidade máxima / média é pequena, alta velocidade média, um pequeno número de participantes. Esta é uma competição profissional. O passo na curva verde está em torno de 1,2. Vamos deixar apenas registros com um valor de proporção maior que 1,2 em nossa amostra.
Nesse gráfico, o primeiro trimestre se destaca com muita clareza: a relação velocidade máxima / média é pequena, alta velocidade média, um pequeno número de participantes. Esta é uma competição profissional. O passo na curva verde está em torno de 1,2. Vamos deixar apenas registros com um valor de proporção maior que 1,2 em nossa amostra.rs = rs[rs['vmdbva'] > 1.2]
Também removemos registros com baixas e altas velocidades atípicas. Em Quais são os recordes mundiais de triatlo para cada distância? publicou tempos recordes de ultrapassar distâncias diferentes para 2019. Se você contá-los em velocidades médias, poderá ver que não pode ser superior a 33 km / h, mesmo para os mais rápidos. Portanto, consideraremos os protocolos em que as velocidades médias são maiores, inválidas e os removeremos de consideração.rs = rs[(rs['vavg'] > 17)&(rs['vmax'] < 33)]
Aqui está o que resta:
 Agora tudo parece bastante homogêneo e não levanta questões. Como resultado de toda essa seleção, perdemos 777 dos protocolos de 1922, ou 40%. Ao mesmo tempo, o número total de finalizadores não diminuiu muito - apenas 13%.Portanto, restam 1.145 corridas com 1.231.772 finalistas. Essa amostra se tornou o material para minha análise e visualização.
Agora tudo parece bastante homogêneo e não levanta questões. Como resultado de toda essa seleção, perdemos 777 dos protocolos de 1922, ou 40%. Ao mesmo tempo, o número total de finalizadores não diminuiu muito - apenas 13%.Portanto, restam 1.145 corridas com 1.231.772 finalistas. Essa amostra se tornou o material para minha análise e visualização.Parte 5. Análise e visualização
Neste trabalho, análise e visualização propriamente dita foram as partes mais simples. A ponta do iceberg, cuja parte subaquática era apenas a preparação dos dados. A análise, de fato, foi uma operação aritmética simples na Série pandas , calculando médias, filtrando - tudo isso é feito pelas ferramentas elementares dos pandas e o código acima está cheio de exemplos. A visualização, por sua vez, foi feita principalmente usando o matplotlib mais padrão . Lote usado , bar, torta . Em alguns lugares, no entanto, tive que mexer com as assinaturas dos eixos, no caso de datas e pictogramas, mas isso não é algo que atraia uma descrição detalhada aqui. Só vale a pena falar sobre a apresentação dos dados geográficos. Pelo menos não ématplotlib .Dados geográficos
Para cada corrida, temos informações sobre o local. No início, usando geopy, calculamos as coordenadas para cada local. Muitas corridas são realizadas anualmente no mesmo local. Uma ferramenta muito útil para renderizar dados geográficos em python é o folium . Veja como funciona:import folium
m = folium.Map()
folium.Marker(['55.7522200', '37.6155600'], popup='').add_to(m)
E temos um mapa interativo diretamente no laptop Jupiter. Agora, para os nossos dados. Primeiro, iniciaremos uma nova coluna a partir de uma combinação de nossas coordenadas:
Agora, para os nossos dados. Primeiro, iniciaremos uma nova coluna a partir de uma combinação de nossas coordenadas:rs['coords'] = rs['latitude'].astype(str) + ', ' + rs['longitude'].astype(str)
As coordenadas únicas de coords são 291. E a única locais loc são 324, o que significa que alguns nomes são ligeiramente diferentes, ao mesmo tempo que corresponde ao mesmo ponto. Não é assustador, consideraremos a exclusividade por cabos . Calculamos quantos eventos passaram o tempo todo em cada local (com coordenadas exclusivas):vc = rs['coords'].value_counts()
vc
Out:
43.7009358, 7.2683912 22
43.5854823, 39.723109 20
29.03970805, -13.636291 16
47.3723941, 8.5423328 16
59.3110918, 24.420907 15
51.0834196, 10.4234469 15
54.7585694, 38.8818137 14
20.4317585, -86.9202745 13
52.3727598, 4.8936041 12
41.6132925, 2.6576102 12
... ...
Agora crie um mapa e adicione marcadores nele na forma de círculos, cujo raio dependerá do número de eventos realizados no local. Adicione marcadores com o nome do local aos marcadores.m = folium.Map(location=[25,10], zoom_start=2)
for c in rs['coords'].unique():
row = [r[1] for r in rs.iterrows() if r[1]['coords'] == c][0]
folium.Circle([row['latitude'], row['longitude']],
popup=(row['location']+'\n('+str(vc[c])+' races)'),
radius = 10000*int(vc[c]),
color='darkorange',
fill=True,
stroke=True,
weight=1).add_to(m)
Feito. Você pode ver o resultado:
Progresso dos participantes
De fato, além de orientar, o trabalho em outro cronograma também não era trivial. Este é o gráfico de progresso mais recente dos participantes. Aqui está: Vamos analisar, ao mesmo tempo, darei o código para renderização, como um exemplo do uso do matplotlib :
Vamos analisar, ao mesmo tempo, darei o código para renderização, como um exemplo do uso do matplotlib :fig = plt.figure()
fig.set_size_inches(10, 6)
ax = fig.add_axes([0,0,1,1])
b = ax.bar(exp,numrecs, color = 'navajowhite')
ax1 = ax.twinx()
for i in range(len(exp_samp)):
ax1.plot(exp_samp[i], vproc_samp[i], '.')
p, = ax1.plot(exp, vpm, 'o-',markersize=8, linewidth=2, color='C0')
for i in range(len(exp)):
if i < len(exp)-1 and (vpm[i] < vpm[i+1]):
ax1.text(x = exp[i]+0.1, y = vpm[i]-0.2, s = '{0:3.1f}%'.format(vpm[i]),size=12)
else:
ax1.text(x = exp[i]+0.1, y = vpm[i]+0.1, s = '{0:3.1f}%'.format(vpm[i]),size=12)
ax.legend((b,p), (' ', ''),loc='center right')
ax.set_xlabel(' ')
ax.set_ylabel('')
ax1.set_ylabel('% ')
ax.set_xticks(np.arange(1, 11, step=1))
ax.set_yticks(np.arange(0, 230000, step=25000))
ax1.set_ylim(97.5,103.5)
ax.yaxis.set_label_position("right")
ax.yaxis.tick_right()
ax1.yaxis.set_label_position("left")
ax1.yaxis.tick_left()
plt.show()
Agora, sobre como os dados foram calculados para ele. Primeiro, você tinha que escolher os nomes dos participantes que terminaram pelo menos em duas corridas e em anos civis diferentes e, ao mesmo tempo, não são profissionais.Primeiro, para cada protocolo, preencha uma nova coluna chamada data , que indicará a data da corrida. Também precisaremos de um ano a partir dessa data, faremos a coluna ano . Como vamos analisar a velocidade de cada atleta em relação à velocidade média na corrida, calculamos imediatamente essa velocidade na nova coluna vproc - a velocidade como porcentagem da média.for index, row in rs.iterrows():
e = row['event']
rd[e]['date'] = row['date']
rd[e]['year'] = row['year']
rd[e]['vproc'] = 100 * rd[e]['v'] / rd[e]['v'].mean()
Aqui está a aparência dos protocolos: Em seguida, combine todos os protocolos em um único quadro de dados.' Sprint 2019'ar = pd.concat(rd)
Para cada participante, deixaremos apenas uma entrada em cada ano civil:ar1 = ar.drop_duplicates(subset = ['name','year'], keep='first')
A seguir, de todos os nomes exclusivos dessas entradas, encontramos os que ocorrem pelo menos duas vezes:nvc = ar1['name'].value_counts()
names = list(nvc[nvc > 1].index)
Existem 219.890. Vamos remover os nomes dos atletas profissionais desta lista:pro_names = ar[ar['group'].isin(['MPRO','FPRO'])]['name'].unique()
names = list(set(names) - set(pro_names))
Bem como os nomes dos atletas que começaram a se apresentar antes de 2010. Para fazer isso, faça o upload dos dados que foram salvos antes da amostragem nos últimos 10 anos. Coloque-os nos objetos rsa (resumo de todas as corridas) e rda (detalhes de todas as corridas).rdo = {}
for e in rda:
if rsa[rsa['event'] == e]['year'].iloc[0] < 2010:
rdo[e] = rda[e]
aro = pd.concat(rdo)
old_names = aro['name'].unique()
names = list(set(names) - set(old_names))
E, finalmente, encontramos nomes que ocorrem mais de uma vez no mesmo dia. Assim, minimizamos a presença de nomes completos em nossa amostra.namesakes = ar[ar.duplicated(subset = ['name','date'], keep = False)]['name'].unique()
names = list(set(names) - set(namesakes))
Portanto, existem 198.075 nomes restantes. No conjunto de dados inteiro, selecionamos apenas os registros com os nomes encontrados:ars = ar[ar['name'].isin(names)]
Agora, para cada registro, você precisa determinar a que ano na carreira do atleta corresponde - o primeiro, o segundo, o terceiro ou o décimo. Fazemos um loop por todos os nomes e calculamos.ars['exp'] = ''
for n in names:
ind = ars[ars['name'] == n].index
yos = ars.loc[ind, 'year'].min()
ars.loc[ind, 'exp'] = ars.loc[ind, 'year'] - yos + 1
Aqui está um exemplo do que aconteceu: Aparentemente, os nomes ainda permaneciam. Isso é esperado, mas não assustador, já que calcularemos a média de tudo, e não deve haver tantos. Em seguida, criamos matrizes para o gráfico:exp = []
vpm = []
numrecs = []
for x in range(ars['exp'].min(), ars['exp'].max() + 1):
exp.append(x)
vpm.append(ars[ars['exp'] == x]['vproc'].mean())
numrecs.append(len(ars[ars['exp'] == x]))
É isso aí, existe uma base: agora, para decorá-lo com pontos que correspondem a resultados específicos, escolheremos 1000 nomes aleatórios e criaremos matrizes com os resultados para eles.
agora, para decorá-lo com pontos que correspondem a resultados específicos, escolheremos 1000 nomes aleatórios e criaremos matrizes com os resultados para eles.names_samp = random.sample(names,1000)
ars_samp = ars[ars['name'].isin(names_samp)]
ars_samp = ars_samp.reset_index(drop = True)
exp_samp = []
vproc_samp = []
for n in names_samp:
nr = ars_samp[ars_samp['name'] == n]
nr = nr.sort_values('exp')
exp_samp.append(list(nr['exp']))
vproc_samp.append(list(nr['vproc']))
Adicione um loop para criar gráficos a partir desta amostra aleatória.for i in range(len(exp_samp)):
ax1.plot(exp_samp[i], vproc_samp[i], '.')
Agora está tudo pronto: em geral, não é difícil. Mas há um problema. Para calcular a experiência de exp em um ciclo, todos os nomes, que são quase 200 mil, levam oito horas. Eu tive que depurar o algoritmo em pequenas amostras e depois executar o cálculo para a noite. Em princípio, isso pode ser feito uma vez, mas se você encontrar algum tipo de erro ou quiser alterar algo, e precisar recontá-lo novamente, ele começará a se desgastar. E assim, quando eu ia publicar um relatório à noite, aconteceu que novamente era necessário recontar tudo novamente. Esperar até a manhã não fazia parte dos meus planos e comecei a procurar uma maneira de acelerar o cálculo. Decidiu paralelizar.Encontrado em algum lugar uma maneira de fazer isso com o multiprocessamento. Para trabalhar no Windows, precisamos colocar a lógica principal de cada tarefa paralela em um arquivo workers.py separado :
em geral, não é difícil. Mas há um problema. Para calcular a experiência de exp em um ciclo, todos os nomes, que são quase 200 mil, levam oito horas. Eu tive que depurar o algoritmo em pequenas amostras e depois executar o cálculo para a noite. Em princípio, isso pode ser feito uma vez, mas se você encontrar algum tipo de erro ou quiser alterar algo, e precisar recontá-lo novamente, ele começará a se desgastar. E assim, quando eu ia publicar um relatório à noite, aconteceu que novamente era necessário recontar tudo novamente. Esperar até a manhã não fazia parte dos meus planos e comecei a procurar uma maneira de acelerar o cálculo. Decidiu paralelizar.Encontrado em algum lugar uma maneira de fazer isso com o multiprocessamento. Para trabalhar no Windows, precisamos colocar a lógica principal de cada tarefa paralela em um arquivo workers.py separado :import pickle as pkl
def worker(args):
names = args[0]
ars=args[1]
num=args[2]
ars = ars.sort_values(by='name')
ars = ars.reset_index(drop=True)
for n in names:
ind = ars[ars['name'] == n].index
yos = ars.loc[ind, 'year'].min()
ars.loc[ind, 'exp'] = ars.loc[ind, 'year'] - yos + 1
with open(r'D:\tri\par\prog' + str(num) + '.pkl', 'wb') as f:
pkl.dump(ars,f)
O procedimento é transferido para uma porção de um dos nomes de nomes , parte datafreyma ar apenas com estes nomes e o número de série de tarefas paralelas - núm . Os cálculos são gravados no quadro de dados e, no final, o quadro de dados é gravado no arquivo. No laptop que chama esse trabalhador , preparamos os argumentos adequadamente:num_proc = 8
args = []
for i in range(num_proc):
step = int(len(names_samp)/num_proc) + 1
names_i = names_samp[i*step:min((i+1)*step, len(names_samp))]
ars_i = ars[ars['name'].isin(names_i)]
args.append([names_i, ars_i, i])
Começamos a computação paralela:from multiprocessing import Pool
import workers
if __name__ == '__main__':
p=Pool(processes = num_proc)
p.map(workers.worker,args)
E, no final, lemos os resultados dos arquivos e coletamos as peças de volta em todo o quadro de dados:ars=pd.DataFrame(columns = ars.columns)
for i in range(num_proc):
with open(r'D:\tri\par\prog'+str(i)+'.pkl', 'rb') as f:
arsi = pkl.load(f)
print(len(arsi))
ars = pd.concat([ars, arsi])
Assim, foi possível obter uma aceleração de 40 vezes e, em vez de 8 horas, concluir o cálculo em 11 minutos e publicar um relatório naquela noite. Ao mesmo tempo, aprendi a paralelizar em python , acho que será útil. Aqui, a aceleração acabou sendo mais do que apenas 8 vezes o número de núcleos, devido ao fato de que cada tarefa usou um pequeno quadro de dados, o que torna a pesquisa mais rápida. Em princípio, os cálculos seqüenciais poderiam ser acelerados dessa maneira, mas a pergunta é: como você adivinha?No entanto, não consegui me acalmar e, mesmo após a publicação, estava constantemente pensando em como fazer o cálculo usando vetorização, ou seja, operações em colunas inteiras do quadro de dados da série pandas. Tais cálculos são uma ordem de grandeza mais rápida que qualquer ciclo paralelo, mesmo em um superaglomerado. E veio com. Acontece que, para cada nome para encontrar o ano do início de uma carreira, é necessário pelo contrário - para cada ano, para encontrar os participantes que começaram nela. Para fazer isso, você deve primeiro determinar todos os nomes para o primeiro ano de nossa amostra, isto é 2010. Assim, processamos todos os registros com esses nomes usando este ano. Em seguida, pegamos o próximo ano - 2011.Mais uma vez, encontramos todos os nomes com entradas neste ano, mas tiramos deles apenas os não processados, ou seja, aqueles que não foram atendidos em 2010 e são processados usando-os em 2011. E assim por diante pelo resto do ano. O mesmo ciclo, mas não duzentas mil iterações, mas nove no total.for y in range(ars['year'].min(),ars['year'].max()):
arsynp = ars[(ars['exp'] == '') & (ars['year'] == y)]
namesy = arsynp['name'].unique()
ind = ars[ars['name'].isin(namesy)].index
ars.loc[ind, 'exp'] = ars.loc[ind,'year'] - y + 1
Esse ciclo é concluído em apenas alguns segundos. E o código acabou sendo muito mais conciso.Conclusão
Bem, finalmente, muito trabalho foi concluído. Para mim, esse foi, de fato, o primeiro projeto desse tipo. Quando o peguei, o objetivo principal era praticar o uso de python e suas bibliotecas. Esta tarefa está mais do que concluída. E os próprios resultados foram bastante apresentáveis. Que conclusões tirei para mim mesmo após a conclusão?Primeiro: os dados são imperfeitos. Provavelmente isso é verdade para quase qualquer tarefa de análise. Mesmo se eles estão completamente estruturado, e que muitas vezes acontece de forma diferente, você precisa estar preparado para mexer com eles antes de começar a calcular as características e busca de tendências - encontrar erros, outliers desvios dos padrões, etc.Segundo:Qualquer tarefa tem uma solução. Isso é mais como um slogan, mas geralmente é. Só que essa decisão pode não ser tão óbvia e não está nos dados em si, mas fora da caixa. Como exemplo - o processamento dos nomes dos participantes descritos acima ou a raspagem de sites.Terceiro: o conhecimento do domínio é crucial. Isso permitirá preparar melhor os dados, removendo dados obviamente inválidos ou fora do padrão, evitar erros de interpretação, usar informações que não estão nos dados, por exemplo, distâncias neste projeto, apresentar os resultados da forma aceita na comunidade, evitando conclusões estúpidas e incorretas.Quarto: trabalhar em pythonHá um rico conjunto de ferramentas. Às vezes parece que vale a pena pensar em algo, você começa a pesquisar - ele já existe. Isso é ótimo! Muito obrigado aos criadores por esta contribuição, especialmente pelas ferramentas que foram úteis aqui: selênio para raspagem, pycountry para determinar o código do país de acordo com o padrão ISO, códigos de país (datahub) para códigos olímpicos, geopia para determinar as coordenadas no endereço, folio - para visualização de dados geográficos, adivinhadores de gênero - para análise de nomes, multiprocessamento - para computação paralela, matplotlib , numpy e, é claro, pandas - sem ter para onde ir.Quinto: a vetorização é o nosso tudo. É extremamente importante poder usar as ferramentas internas dos pandas , pois é muito eficaz. Suponho que, na maioria dos casos, quando o número de registros é medido a partir de dezenas de milhares, essa habilidade se torna simplesmente necessária.Sexto:Manipular dados é uma má ideia. É necessário tentar minimizar qualquer intervenção manual - em primeiro lugar, ela não é dimensionada, ou seja, quando a quantidade de dados aumenta várias vezes, o tempo de processamento manual aumenta para valores inaceitáveis e, em segundo lugar, haverá pouca repetibilidade - você esquecerá algo, cometerá algum erro . Tudo é apenas programático, se algo cai fora do padrão geral para uma solução de software, tudo bem, você pode sacrificar parte dos dados, ainda haverá mais vantagens.Sétimo:O código deve ser mantido em ordem de funcionamento. Parece que poderia ser mais óbvio! De fato, quando se trata de codificar para seu próprio uso, cujo objetivo é publicar os resultados desse código, nem tudo é tão rigoroso aqui. Eu trabalhei em Jupiter Notebooks, e esse ambiente, na minha opinião, simplesmente não precisa criar produtos de software integrais. Ele está configurado para lançamento linha por linha, por partes, e tem suas vantagens - é rápido: desenvolvimento, depuração e execução ao mesmo tempo. Mas muitas vezes a tentação é apenas editar alguma linha e obter rapidamente um novo resultado, em vez de duplicar ou empacotar def. Evidentemente, essa tentação deve ser evitada. Deve-se buscar um bom código, mesmo “para si mesmo”, pelo menos porque, mesmo para um trabalho de análise, o lançamento é feito várias vezes, e investir tempo no início certamente valerá a pena no futuro. E você pode adicionar testes, mesmo em laptops, na forma de verificações de parâmetros críticos e gerar exceções - é muito útil.Oitavo: economize com mais frequência. Em cada etapa, salvei uma nova versão do arquivo. No total, eles eram cerca de 10. Isso é conveniente, pois quando um erro é detectado, ajuda a determinar rapidamente em que estágio ocorreu. Além disso, salvei os dados de origem nas colunas marcadas em bruto - isso permite que você verifique rapidamente o resultado e veja a discrepância.Nono:É necessário medir o investimento de tempo e o resultado. Em alguns lugares, levei muito tempo para restaurar dados, que formam uma fração de um por cento do total. Na verdade, isso não fazia sentido, você só tinha que jogá-los fora, e isso é tudo. E eu o faria se fosse um projeto comercial, não um treinamento automático. Isso permitiria obter o resultado muito mais rapidamente. O princípio de Pareto funciona aqui - 80% do resultado é alcançado em 20% do tempo.E o último:O trabalho em tais projetos amplia muito os horizontes. De bom grado, você aprende algo novo - por exemplo, os nomes de países estranhos - como as Ilhas Pitcairn, que o código ISO para a Suíça é CHE, do latim “Confoederatio Helvetica”, qual é o nome espanhol, na verdade, sobre o próprio triatlo - registros, seus donos, locais de corridas, histórico de eventos e assim por diante.Talvez o suficiente. Isso é tudo. Obrigado a todos que leram até o fim!