O acesso à GPU a partir de Java revela um poder tremendo. Ele descreve como a GPU funciona e como acessar a partir de Java.A programação de GPU é um mundo altíssimo para programadores de Java. Isso é compreensível, pois tarefas Java normais não são adequadas para a GPU. No entanto, as GPUs possuem teraflops de desempenho, então vamos explorar seus recursos.Para tornar o tópico acessível, passarei algum tempo explicando a arquitetura da GPU, juntamente com um pouco de história que facilitará uma imersão na programação de ferro.Uma vez mostradas as diferenças entre a GPU e a computação da CPU, mostrarei como usar a GPU no mundo Java. Finalmente, descreverei as principais estruturas e bibliotecas disponíveis para escrever código Java e executá-los na GPU, e darei alguns exemplos de código.Um pouco de fundo
A GPU foi popularizada pela NVIDIA em 1999. É um processador especial projetado para processar dados gráficos antes de serem transferidos para a tela. Em muitos casos, isso permite que alguns cálculos descarreguem a CPU, liberando recursos da CPU que aceleram esses cálculos descarregados. O resultado é que uma entrada grande pode ser processada e apresentada com uma resolução de saída mais alta, tornando a apresentação visual mais atraente e a taxa de quadros mais suave.A essência do processamento 2D / 3D está principalmente na manipulação de matrizes, que pode ser controlada usando uma abordagem distribuída. Qual será uma abordagem eficaz para o processamento de imagens? Para responder a isso, vamos comparar a arquitetura padrão da CPU (mostrada na Figura 1.) e a GPU.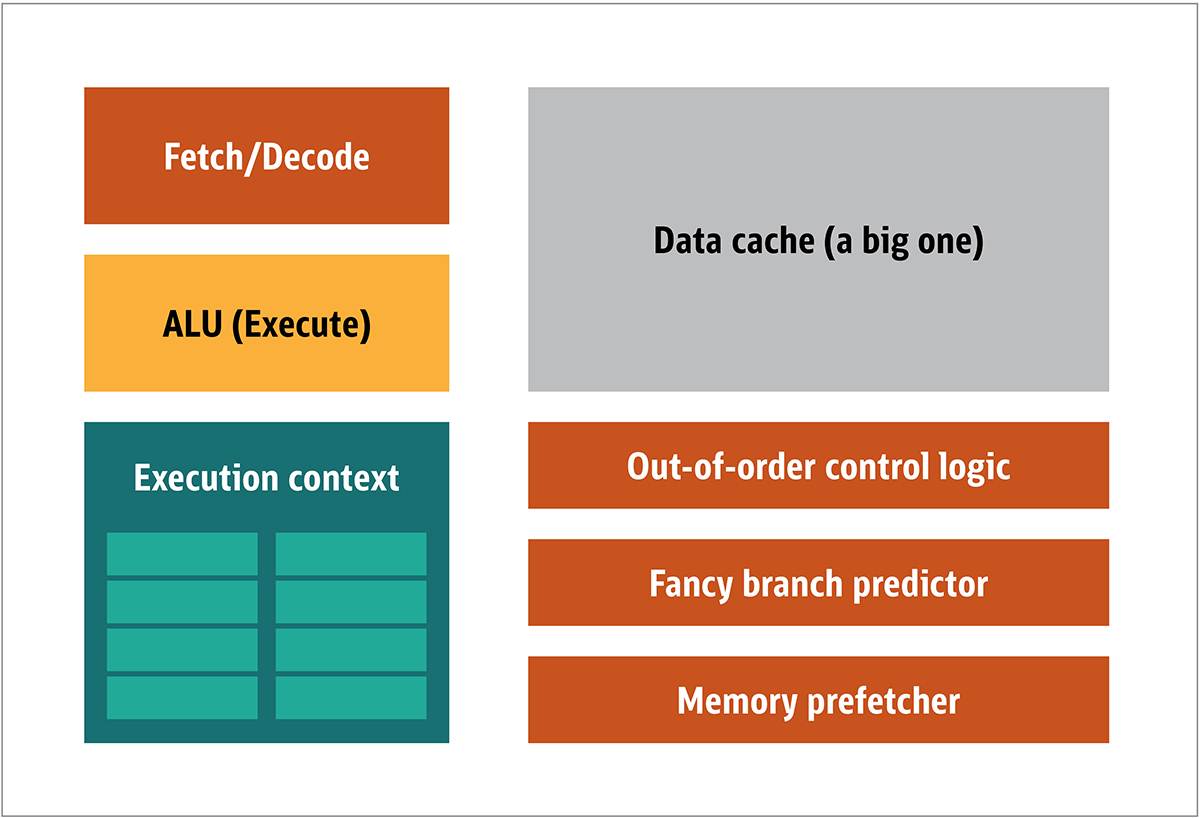 FIG. 1. Blocos de arquiteturada CPU Na CPU, os elementos de processamento reais - registros, unidade lógica aritmética (ALU) e contextos de execução - são apenas pequenas partes de todo o sistema. Para acelerar pagamentos irregulares em um pedido imprevisível, existe um cache grande, rápido e caro; vários tipos de colecionadores; e preditores de ramificação.Você não precisa de tudo isso na GPU, porque os dados são recebidos de maneira previsível e a GPU realiza um conjunto muito limitado de operações nos dados. Assim, é possível torná-los muito pequenos e um processador barato com uma arquitetura de blocos semelhante a esta é mostrado na Fig. 2.
FIG. 1. Blocos de arquiteturada CPU Na CPU, os elementos de processamento reais - registros, unidade lógica aritmética (ALU) e contextos de execução - são apenas pequenas partes de todo o sistema. Para acelerar pagamentos irregulares em um pedido imprevisível, existe um cache grande, rápido e caro; vários tipos de colecionadores; e preditores de ramificação.Você não precisa de tudo isso na GPU, porque os dados são recebidos de maneira previsível e a GPU realiza um conjunto muito limitado de operações nos dados. Assim, é possível torná-los muito pequenos e um processador barato com uma arquitetura de blocos semelhante a esta é mostrado na Fig. 2.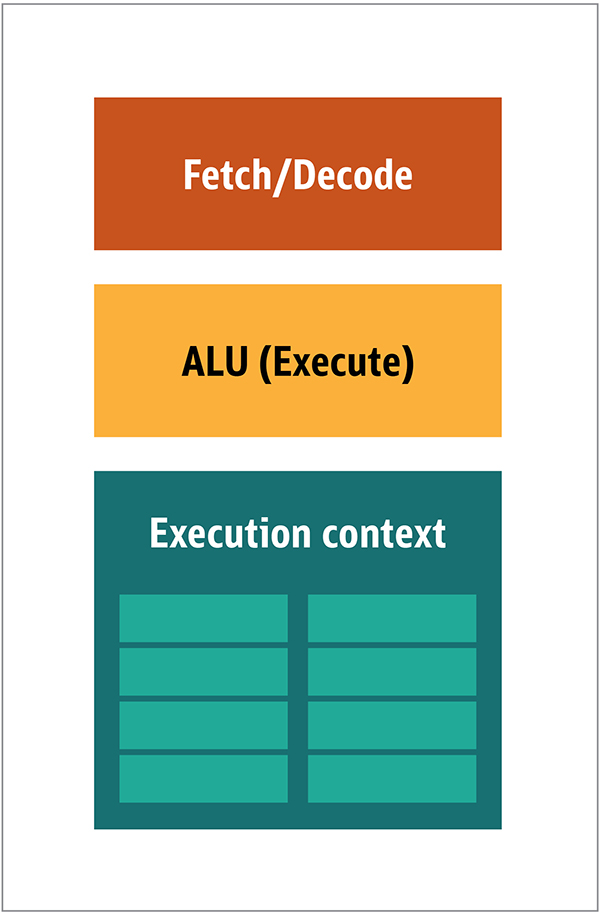 Fig. 2. Arquitetura de bloco para um núcleo simples de GPUComo esses processadores são mais baratos e os dados processados neles em pedaços paralelos, é simples fazer com que muitos deles funcionem em paralelo. Ele é projetado com referência a várias instruções, vários dados ou MIMD (pronunciado "mim-dee").A segunda abordagem é baseada no fato de que frequentemente uma única instrução é aplicada a várias partes de dados. Isso é conhecido como uma única instrução, vários dados ou SIMD (pronunciado "sim-dee"). Nesse design, uma única GPU contém várias ALUs e contextos de execução, pequenas áreas transferidas para dados de contexto compartilhado, conforme mostrado na Figura 3.
Fig. 2. Arquitetura de bloco para um núcleo simples de GPUComo esses processadores são mais baratos e os dados processados neles em pedaços paralelos, é simples fazer com que muitos deles funcionem em paralelo. Ele é projetado com referência a várias instruções, vários dados ou MIMD (pronunciado "mim-dee").A segunda abordagem é baseada no fato de que frequentemente uma única instrução é aplicada a várias partes de dados. Isso é conhecido como uma única instrução, vários dados ou SIMD (pronunciado "sim-dee"). Nesse design, uma única GPU contém várias ALUs e contextos de execução, pequenas áreas transferidas para dados de contexto compartilhado, conforme mostrado na Figura 3.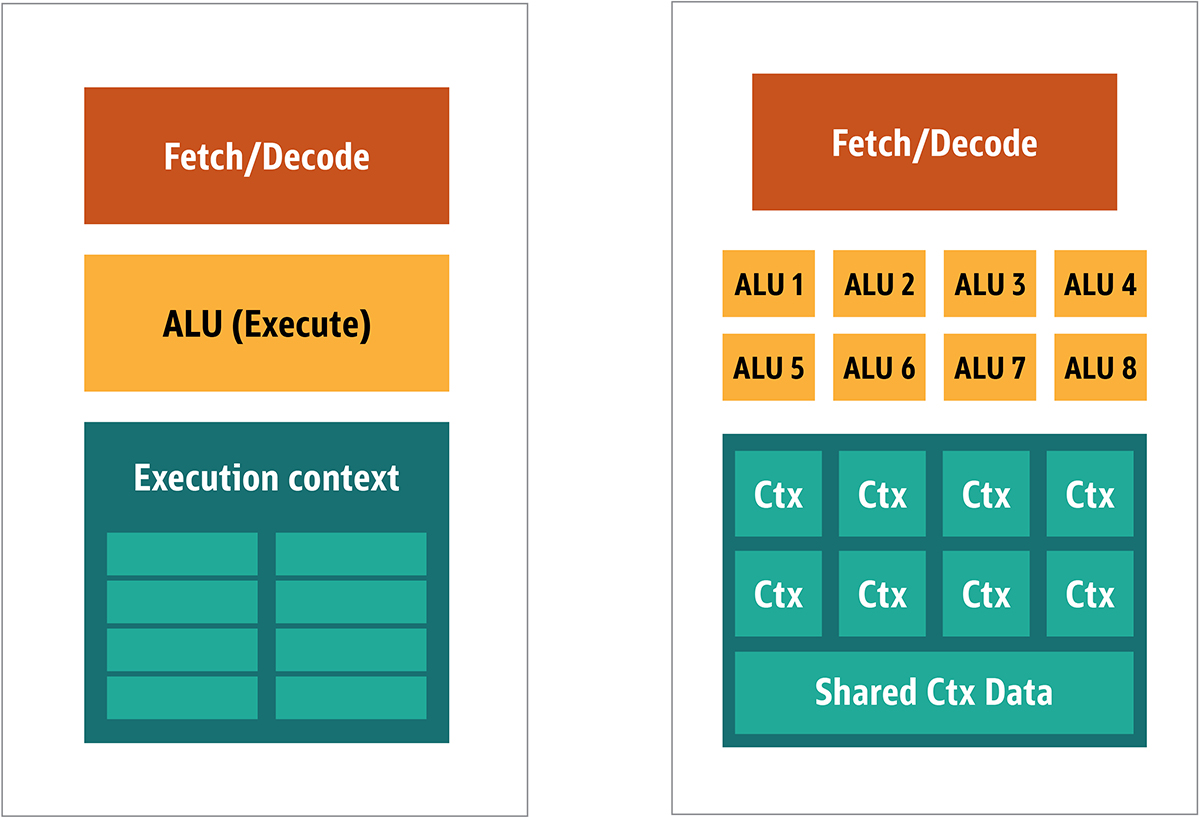 Fig. 3. Comparação da arquitetura no estilo MIMD dos blocos de GPU (à esquerda) com o design do SIMD (à direita)A mistura do processamento SIMD e MIMD fornece a largura de banda máxima que eu ignorarei. Nesse design, você tem vários processadores SIMD executando paralelamente, como na Figura 4.
Fig. 3. Comparação da arquitetura no estilo MIMD dos blocos de GPU (à esquerda) com o design do SIMD (à direita)A mistura do processamento SIMD e MIMD fornece a largura de banda máxima que eu ignorarei. Nesse design, você tem vários processadores SIMD executando paralelamente, como na Figura 4. Fig. 4. Trabalhar vários processadores SIMD em paralelo; existem 16 núcleos com 128 ALUsComo você possui vários processadores pequenos e simples, é possível programá-los para obter um efeito especial na saída.
Fig. 4. Trabalhar vários processadores SIMD em paralelo; existem 16 núcleos com 128 ALUsComo você possui vários processadores pequenos e simples, é possível programá-los para obter um efeito especial na saída.Executando programas na GPU
A maioria dos efeitos gráficos iniciais nos jogos eram realmente pequenos programas codificados em execução na GPU e aplicados a fluxos de dados da CPU.Isso era óbvio, mesmo quando algoritmos codificados eram insuficientes, especialmente no design de jogos, onde os efeitos visuais são uma das principais direções mágicas. Em resposta, grandes vendedores abriram o acesso à GPU e, em seguida, desenvolvedores de terceiros poderiam programá-los.Uma abordagem típica era escrever um pequeno programa chamado shaders em uma linguagem especial (geralmente uma subespécie de C) e compilá-los usando compiladores especiais para a arquitetura desejada. O termo shaders foi escolhido porque os shaders são frequentemente usados para controlar os efeitos de luz e sombra, mas isso não significa que eles possam controlar outros efeitos especiais.Cada fornecedor de GPU tinha sua própria linguagem de programação e infraestrutura para criar sombreadores para sua arquitetura. Nesta abordagem, muitas plataformas foram criadas.Os principais são:- DirectCompute: API / API de shader privado da Microsoft que fazem parte do Direct3D, começando com o DirectX 10.
- AMD FireStream: tecnologias privadas de ATI / Radeon desatualizadas pela AMD.
- OpenACC: Consórcio de múltiplos fornecedores, solução de computação paralela
- ++ AMP: Microsoft C++
- CUDA: Nvidia,
- OpenL: , Apple, Khronos Group
Na maioria das vezes, trabalhar com a GPU é de programação de baixo nível. Para tornar isso um pouco mais compreensível para os desenvolvedores, para codificação, várias abstrações foram fornecidas. O mais famoso é o DirectX, da Microsoft, e o OpenGL, do Khronos Group. Essas são APIs para escrever código de alto nível, que podem ser simplificadas para a GPU, mais semanticamente, para o programador.Até onde eu sei, não há infraestrutura Java para o DirectX, mas há uma boa solução para o OpenGL. O JSR 231 começou em 2002 e é dirigido aos programadores de GPU, mas foi abandonado em 2008 e suporta apenas o OpenGL 2.0.O suporte ao OpenGL continua no projeto JOCL independente (que também suporta o OpenCL) e está disponível para o público. Assim, o famoso jogo Minecraft foi escrito usando JOCL.GPGPU vindo
Até agora, Java e a GPU não tinham um ponto em comum, embora devessem. O Java é frequentemente usado em empresas, ciência de dados e no setor financeiro, onde há muita computação e onde é necessário muito poder de computação. É assim que a idéia de GPU de uso geral (GPGPU) é. A idéia de usar a GPU nesse caminho começou quando os fabricantes de adaptadores de vídeo começaram a dar acesso ao buffer de quadro do programa, permitindo que os desenvolvedores leiam o conteúdo. Alguns hackers determinaram que podem usar todo o poder da GPU para computação universal.A receita foi assim:- Codifique dados como uma matriz raster.
- Escreva shaders para lidar com eles.
- Envie os dois para a placa gráfica.
- Obter resultado do buffer de quadros
- Decodifique dados de uma matriz raster.
Esta é uma explicação muito simples. Não tenho certeza se isso funcionará na produção, mas realmente funciona.Então, vários estudos do Stanford Institute começaram a simplificar o uso de GPUs. Em 2005, eles criaram o BrookGPU, que era um pequeno ecossistema que incluía uma linguagem de programação, compilador e tempo de execução.O BrookGPU compilou programas escritos na linguagem de programação de encadeamento Brook, que era uma variante do ANSI C. Ele pode segmentar o OpenGL v1.3 +, DirectX v9 + ou AMD Close to Metal para o lado do servidor e é executado no Microsoft Windows e Linux. Para depuração, o BrookGPU também pode simular uma placa gráfica virtual na CPU.No entanto, isso não decolou, devido ao equipamento disponível na época. No mundo da GPGPU, você precisa copiar dados para o dispositivo (nesse contexto, o dispositivo se refere à GPU e ao dispositivo em que está localizado), aguarde a GPU calcular os dados e copie-os novamente para o programa de controle. Isso cria muitos atrasos. E em meados dos anos 2000, quando o projeto estava em desenvolvimento ativo, esses atrasos também excluíram o uso intensivo da GPU para computação básica.No entanto, muitas empresas viram o futuro nessa tecnologia. Vários desenvolvedores de adaptadores de vídeo começaram a fornecer às GPGPUs suas tecnologias proprietárias, e outras alianças formadas forneceram modelos de programação menos básicos e versáteis que funcionavam em uma grande quantidade de hardware.Agora que já contei tudo, vamos verificar as duas tecnologias de computação de GPU mais bem-sucedidas - OpenCL e CUDA - veja também como o Java funciona com elas.OpenCL e Java
Como outros pacotes de infraestrutura, o OpenCL fornece uma implementação básica em C. Isso está tecnicamente disponível usando a Java Native Interface (JNI) ou Java Native Access (JNA), mas essa abordagem será muito difícil para a maioria dos desenvolvedores.Felizmente, este trabalho já foi realizado por várias bibliotecas: JOCL, JogAmp e JavaCL. Infelizmente, o JavaCL se tornou um projeto morto. Mas o projeto JOCL está vivo e muito adaptado. Vou usá-lo para os seguintes exemplos.Mas primeiro eu tenho que explicar o que é OpenCL. Mencionei anteriormente que o OpenCL fornece um modelo muito básico adequado para programar todos os tipos de dispositivos - não apenas GPUs e CPUs, mas também processadores DSP e FPGAs.Vejamos o exemplo mais simples: dobrar vetores é provavelmente o exemplo mais brilhante e mais simples. Você tem duas matrizes de números para adição e uma para o resultado. Você pega um elemento da primeira matriz e um elemento da segunda matriz e, em seguida, coloca a soma na matriz de resultados, conforme mostrado na Fig. 5.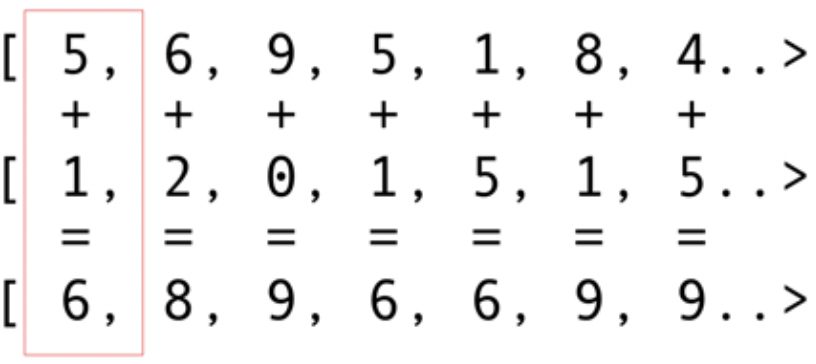 Fig. 5. Adicionando os elementos de duas matrizes e armazenando a soma na matriz resultanteComo você pode ver, a operação é muito consistente e, no entanto, distribuída. Você pode enviar cada operação de adição para diferentes GPUs principais. Isso significa que, se você tiver 2048 núcleos, como na Nvidia 1080, poderá executar operações de adição 2048 ao mesmo tempo. Isso significa que aqui os potenciais teraflops de energia do computador estão esperando por você. Este código para uma matriz de 10 milhões de números é obtido no site da JOCL:
Fig. 5. Adicionando os elementos de duas matrizes e armazenando a soma na matriz resultanteComo você pode ver, a operação é muito consistente e, no entanto, distribuída. Você pode enviar cada operação de adição para diferentes GPUs principais. Isso significa que, se você tiver 2048 núcleos, como na Nvidia 1080, poderá executar operações de adição 2048 ao mesmo tempo. Isso significa que aqui os potenciais teraflops de energia do computador estão esperando por você. Este código para uma matriz de 10 milhões de números é obtido no site da JOCL:public class ArrayGPU {
private static String programSource =
"__kernel void "+
"sampleKernel(__global const float *a,"+
" __global const float *b,"+
" __global float *c)"+
"{"+
" int gid = get_global_id(0);"+
" c[gid] = a[gid] + b[gid];"+
"}";
public static void main(String args[])
{
int n = 10_000_000;
float srcArrayA[] = new float[n];
float srcArrayB[] = new float[n];
float dstArray[] = new float[n];
for (int i=0; i<n; i++)
{
srcArrayA[i] = i;
srcArrayB[i] = i;
}
Pointer srcA = Pointer.to(srcArrayA);
Pointer srcB = Pointer.to(srcArrayB);
Pointer dst = Pointer.to(dstArray);
final int platformIndex = 0;
final long deviceType = CL.CL_DEVICE_TYPE_ALL;
final int deviceIndex = 0;
CL.setExceptionsEnabled(true);
int numPlatformsArray[] = new int[1];
CL.clGetPlatformIDs(0, null, numPlatformsArray);
int numPlatforms = numPlatformsArray[0];
cl_platform_id platforms[] = new cl_platform_id[numPlatforms];
CL.clGetPlatformIDs(platforms.length, platforms, null);
cl_platform_id platform = platforms[platformIndex];
cl_context_properties contextProperties = new cl_context_properties();
contextProperties.addProperty(CL.CL_CONTEXT_PLATFORM, platform);
int numDevicesArray[] = new int[1];
CL.clGetDeviceIDs(platform, deviceType, 0, null, numDevicesArray);
int numDevices = numDevicesArray[0];
cl_device_id devices[] = new cl_device_id[numDevices];
CL.clGetDeviceIDs(platform, deviceType, numDevices, devices, null);
cl_device_id device = devices[deviceIndex];
cl_context context = CL.clCreateContext(
contextProperties, 1, new cl_device_id[]{device},
null, null, null);
cl_command_queue commandQueue =
CL.clCreateCommandQueue(context, device, 0, null);
cl_mem memObjects[] = new cl_mem[3];
memObjects[0] = CL.clCreateBuffer(context,
CL.CL_MEM_READ_ONLY | CL.CL_MEM_COPY_HOST_PTR,
Sizeof.cl_float * n, srcA, null);
memObjects[1] = CL.clCreateBuffer(context,
CL.CL_MEM_READ_ONLY | CL.CL_MEM_COPY_HOST_PTR,
Sizeof.cl_float * n, srcB, null);
memObjects[2] = CL.clCreateBuffer(context,
CL.CL_MEM_READ_WRITE,
Sizeof.cl_float * n, null, null);
cl_program program = CL.clCreateProgramWithSource(context,
1, new String[]{ programSource }, null, null);
CL.clBuildProgram(program, 0, null, null, null, null);
cl_kernel kernel = CL.clCreateKernel(program, "sampleKernel", null);
CL.clSetKernelArg(kernel, 0,
Sizeof.cl_mem, Pointer.to(memObjects[0]));
CL.clSetKernelArg(kernel, 1,
Sizeof.cl_mem, Pointer.to(memObjects[1]));
CL.clSetKernelArg(kernel, 2,
Sizeof.cl_mem, Pointer.to(memObjects[2]));
long global_work_size[] = new long[]{n};
long local_work_size[] = new long[]{1};
CL.clEnqueueNDRangeKernel(commandQueue, kernel, 1, null,
global_work_size, local_work_size, 0, null, null);
CL.clEnqueueReadBuffer(commandQueue, memObjects[2], CL.CL_TRUE, 0,
n * Sizeof.cl_float, dst, 0, null, null);
CL.clReleaseMemObject(memObjects[0]);
CL.clReleaseMemObject(memObjects[1]);
CL.clReleaseMemObject(memObjects[2]);
CL.clReleaseKernel(kernel);
CL.clReleaseProgram(program);
CL.clReleaseCommandQueue(commandQueue);
CL.clReleaseContext(context);
}
private static String getString(cl_device_id device, int paramName) {
long size[] = new long[1];
CL.clGetDeviceInfo(device, paramName, 0, null, size);
byte buffer[] = new byte[(int)size[0]];
CL.clGetDeviceInfo(device, paramName, buffer.length, Pointer.to(buffer), null);
return new String(buffer, 0, buffer.length-1);
}
}
Este código não é como o código Java, mas é. Vou explicar mais o código; não gaste muito tempo com isso agora, porque discutirei brevemente soluções complexas.O código será documentado, mas vamos fazer uma pequena explicação. Como você pode ver, o código é muito semelhante ao código em C. Isso é normal porque o JOCL é apenas OpenCL. No começo, aqui está um código na linha, e esse código é a parte mais importante: é compilado usando o OpenCL e depois enviado para a placa de vídeo, onde é executada. Este código é chamado Kernel. Não confunda este termo com o OC Kernel; Este é o código do dispositivo. Este código é escrito em um subconjunto de C.Depois que o kernel vem o código Java para instalar e configurar o dispositivo, dividir os dados e criar os buffers de memória apropriados para os dados resultantes.Para resumir: aqui está o "código do host", que geralmente é uma ligação de linguagem (no nosso caso, em Java) e o "código do dispositivo". Você sempre destaca o que funcionará no host e o que deve funcionar no dispositivo, porque o host controla o dispositivo.O código anterior deve mostrar a GPU equivalente a "Hello World!" Como você pode ver, a maior parte é enorme.Não vamos esquecer os recursos do SIMD. Se o seu dispositivo suportar extensão SIMD, você poderá acelerar o código aritmético. Por exemplo, vamos dar uma olhada no código de multiplicação da matriz do kernel. Este código está em uma linha Java simples no aplicativo.__kernel void MatrixMul_kernel_basic(int dim,
__global float *A,
__global float *B,
__global float *C){
int iCol = get_global_id(0);
int iRow = get_global_id(1);
float result = 0.0;
for(int i=0; i< dim; ++i)
{
result +=
A[iRow*dim + i]*B[i*dim + iCol];
}
C[iRow*dim + iCol] = result;
}
Tecnicamente, esse código funcionará em partes de dados que foram instaladas para você pela estrutura OpenCL, com as instruções que você chamou na parte preparatória.Se a sua placa de vídeo suportar instruções SIMD e puder processar um vetor de quatro números de ponto flutuante, pequenas otimizações poderão transformar o código anterior no seguinte:#define VECTOR_SIZE 4
__kernel void MatrixMul_kernel_basic_vector4(
size_t dim,
const float4 *A,
const float4 *B,
float4 *C)
{
size_t globalIdx = get_global_id(0);
size_t globalIdy = get_global_id(1);
float4 resultVec = (float4){ 0, 0, 0, 0 };
size_t dimVec = dim / 4;
for(size_t i = 0; i < dimVec; ++i) {
float4 Avector = A[dimVec * globalIdy + i];
float4 Bvector[4];
Bvector[0] = B[dimVec * (i * 4 + 0) + globalIdx];
Bvector[1] = B[dimVec * (i * 4 + 1) + globalIdx];
Bvector[2] = B[dimVec * (i * 4 + 2) + globalIdx];
Bvector[3] = B[dimVec * (i * 4 + 3) + globalIdx];
resultVec += Avector[0] * Bvector[0];
resultVec += Avector[1] * Bvector[1];
resultVec += Avector[2] * Bvector[2];
resultVec += Avector[3] * Bvector[3];
}
C[dimVec * globalIdy + globalIdx] = resultVec;
}
Com esse código, você pode dobrar o desempenho.Legal. Você acabou de abrir a GPU para o mundo Java! Mas como desenvolvedor Java, você realmente deseja fazer todo esse trabalho sujo, com código C, e trabalhando com detalhes de baixo nível? Eu não quero. Mas agora que você tem algum conhecimento de como a GPU é usada, vejamos outra solução diferente do código JOCL que acabei de apresentar.CUDA e Java
CUDA é a solução da Nvidia para esse problema de programação. O CUDA fornece muito mais bibliotecas prontas para uso para operações padrão da GPU, como matrizes, histogramas e até redes neurais profundas. Uma lista de bibliotecas já apareceu com várias soluções prontas. Isso é tudo do projeto JCuda:- JCublas: tudo para matrizes
- JCufft: Transformação rápida de Fourier
- JCurand: tudo para números aleatórios
- JCusparse: matrizes raras
- JCusolver: fatoração de números
- JNvgraph: tudo para gráficos
- JCudpp: biblioteca CUDA de dados paralelos primitivos e alguns algoritmos de classificação
- JNpp: processamento de imagem da GPU
- JCudnn: biblioteca de rede neural profunda
Estou pensando em usar o JCurand, que gera números aleatórios. Você pode usar isso no código Java sem outra linguagem especial do Kernel. Por exemplo:...
int n = 100;
curandGenerator generator = new curandGenerator();
float hostData[] = new float[n];
Pointer deviceData = new Pointer();
cudaMalloc(deviceData, n * Sizeof.FLOAT);
curandCreateGenerator(generator, CURAND_RNG_PSEUDO_DEFAULT);
curandSetPseudoRandomGeneratorSeed(generator, 1234);
curandGenerateUniform(generator, deviceData, n);
cudaMemcpy(Pointer.to(hostData), deviceData,
n * Sizeof.FLOAT, cudaMemcpyDeviceToHost);
System.out.println(Arrays.toString(hostData));
curandDestroyGenerator(generator);
cudaFree(deviceData);
...
Ele usa uma GPU para criar um grande número aleatório de alta qualidade, com base em uma matemática muito forte.No JCuda, você também pode escrever um código CUDA genérico e chamá-lo de Java chamando algum arquivo JAR em seu caminho de classe. Veja a documentação do JCuda para ótimos exemplos.Fique acima do código de baixo nível
Tudo parece ótimo, mas há muito código, muita instalação, muitos idiomas diferentes para executar tudo. Existe uma maneira de usar a GPU pelo menos parcialmente?E se você não quiser pensar em todo esse OpenCL, CUDA e outras coisas desnecessárias? E se você quiser apenas programar em Java e não pensar em tudo que não é óbvio? O projeto Aparapi pode ajudar. Aparapi é baseado em uma "API paralela". Penso nisso como uma parte do Hibernate para programação de GPU que usa OpenCL sob o capô. Vamos dar uma olhada em um exemplo de adição de vetor.public static void main(String[] _args) {
final int size = 512;
final float[] a = new float[size];
final float[] b = new float[size];
for (int i = 0; i < size; i++){
a[i] = (float) (Math.random() * 100);
b[i] = (float) (Math.random() * 100);
}
final float[] sum = new float[size];
Kernel kernel = new Kernel(){
@Override public void run() {
I int gid = getGlobalId();
sum[gid] = a[gid] + b[gid];
}
};
kernel.execute(Range.create(size));
for(int i = 0; i < size; i++) {
System.out.printf("%6.2f + %6.2f = %8.2f\n", a[i], b[i], sum[i])
}
kernel.dispose();
}
Aqui está o código Java puro (retirado da documentação do Aparapi), também aqui e ali, você pode ver um determinado termo Kernel e getGlobalId. Você ainda precisa entender como programar a GPU, mas pode usar a abordagem da GPGPU de maneira mais semelhante ao Java. Além disso, o Aparapi fornece uma maneira fácil de usar o contexto OpenGL para a camada OpenCL - permitindo que os dados permaneçam completamente na placa gráfica - e, assim, evite problemas de latência da memória.Se você precisar fazer muitos cálculos independentes, consulte Aparapi. Existem muitos exemplos de como usar a computação paralela.Além disso, existe um projeto chamado TornadoVM - ele transfere automaticamente os cálculos apropriados da CPU para a GPU, fornecendo otimização em massa imediata.achados
Existem muitas aplicações em que as GPUs podem trazer algumas vantagens, mas você pode dizer que ainda existem alguns obstáculos. No entanto, Java e a GPU podem fazer grandes coisas juntos. Neste artigo, apenas toquei neste tópico extenso. Pretendia mostrar várias opções de alto e baixo nível para acessar a GPU a partir de Java. A exploração dessa área trará enormes benefícios de desempenho, especialmente para tarefas complexas que exigem vários cálculos que podem ser executados em paralelo.Link de origem