Continuamos a avançar em direção à criação de dispositivos reais baseados no complexo Redd FPGA. Para outro projeto de All-Hardware, preciso de um analisador lógico simples, para que possamos seguir nessa direção. Sorte - e acesse o analisador de barramento USB (mas isso ainda é a longo prazo). O coração de qualquer analisador é a RAM e uma unidade que primeiro carrega dados para ele e depois os recupera. Hoje vamos projetá-lo.Para fazer isso, dominaremos o bloco DMA. Em geral, o DMA é o meu tópico favorito. Eu até fiz um ótimo artigo sobre DMA em alguns controladores ARM . A partir desse artigo, fica claro que o DMA obtém ciclos de relógio do barramento. No artigo atual, consideraremos como estão as coisas com o sistema de processador baseado em FPGA.
Artigos anteriores do ciclo Criação de Hardware
Começamos a criar o hardware. Para entender o quanto o bloco DMA entra em conflito com os ciclos do relógio, precisamos fazer medições precisas com alta carga no barramento Avalon-MM (Avalon Memory-Mapped). Já descobrimos que a ponte Altera JTAG para Avalon-MM não pode fornecer altas cargas de ônibus. Portanto, hoje temos que adicionar um núcleo de processador ao sistema para que ele acesse o barramento em alta velocidade. Como isso é feito foi descrito aqui . Para otimizar, vamos desativar os dois caches do núcleo do processador, mas criar um barramento fortemente conectado, como fizemos aqui .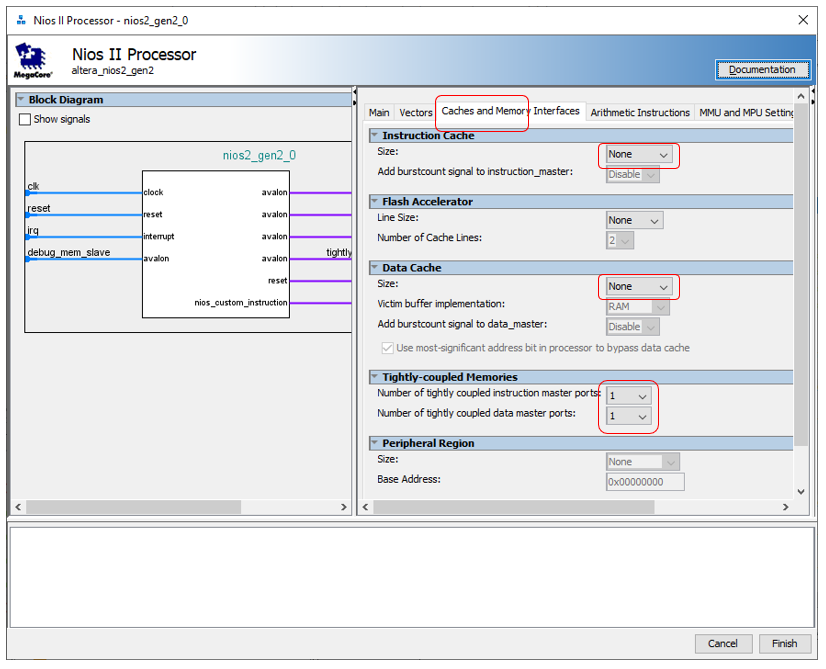 Adicione 8 kilobytes de memória de programa e memória de dados. Lembre-se que a memória deve ser dual-port e ter um endereço em uma linha especial (para evitar que ele jumping, bloqueá-lo, discutimos as razões para isso aqui ).
Adicione 8 kilobytes de memória de programa e memória de dados. Lembre-se que a memória deve ser dual-port e ter um endereço em uma linha especial (para evitar que ele jumping, bloqueá-lo, discutimos as razões para isso aqui ).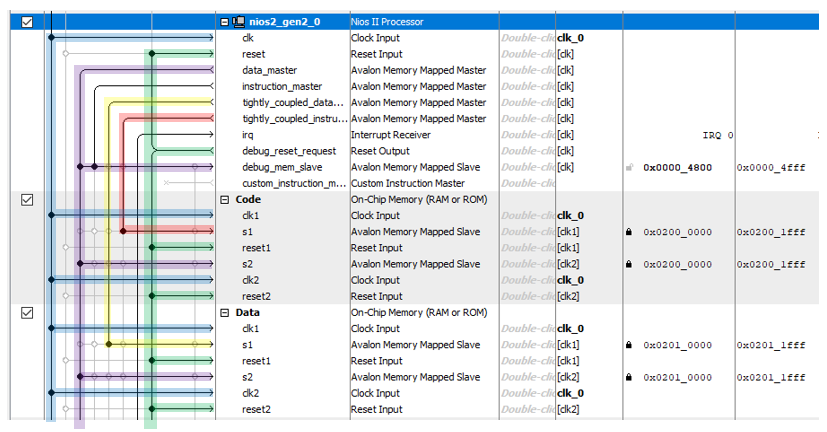 Já criamos o projeto mil vezes, portanto, não há nada particularmente interessante no próprio processo de criação (se houver, todas as etapas para sua criação são descritas aqui ).A base está pronta. Agora precisamos de uma fonte de dados que colocaremos na memória. O ideal é um cronômetro constantemente. Se durante alguma medida o bloco DMA não foi capaz de processar os dados, veremos isso imediatamente pelo valor ausente. Bem, isto é, se na memória houver valores 1234 e 1236, significa que no relógio, quando o timer emitiu 1235, o bloco DMA não transferiu dados. Crie um arquivoTimer_ST.sv com um contador tão simples:
Já criamos o projeto mil vezes, portanto, não há nada particularmente interessante no próprio processo de criação (se houver, todas as etapas para sua criação são descritas aqui ).A base está pronta. Agora precisamos de uma fonte de dados que colocaremos na memória. O ideal é um cronômetro constantemente. Se durante alguma medida o bloco DMA não foi capaz de processar os dados, veremos isso imediatamente pelo valor ausente. Bem, isto é, se na memória houver valores 1234 e 1236, significa que no relógio, quando o timer emitiu 1235, o bloco DMA não transferiu dados. Crie um arquivoTimer_ST.sv com um contador tão simples:module Timer_ST (
input clk,
input reset,
input logic source_ready,
output logic source_valid,
output logic[31:0] source_data
);
logic [31:0] counter;
always @ (posedge clk, posedge reset)
if (reset == 1)
begin
counter <= 0;
end else
begin
counter <= counter + 1;
end
assign source_valid = 1;
assign source_data [31:24] = counter [7:0];
assign source_data [23:16] = counter [15:8];
assign source_data [15:8] = counter [23:16];
assign source_data [7:0] = counter [31:24];
endmodule
Este contador é como um pioneiro: está sempre pronto (na saída source_valid é sempre um) e sempre conta (exceto nos momentos do estado de redefinição). Por que o módulo possui exatamente esses sinais - discutimos neste artigo .Agora criamos nosso próprio componente (como isso é feito é descrito aqui ). A automação escolheu erroneamente o barramento Avalon_MM para nós. Substitua-o por avalon_streaming_source e mapeie os sinais como mostrado abaixo: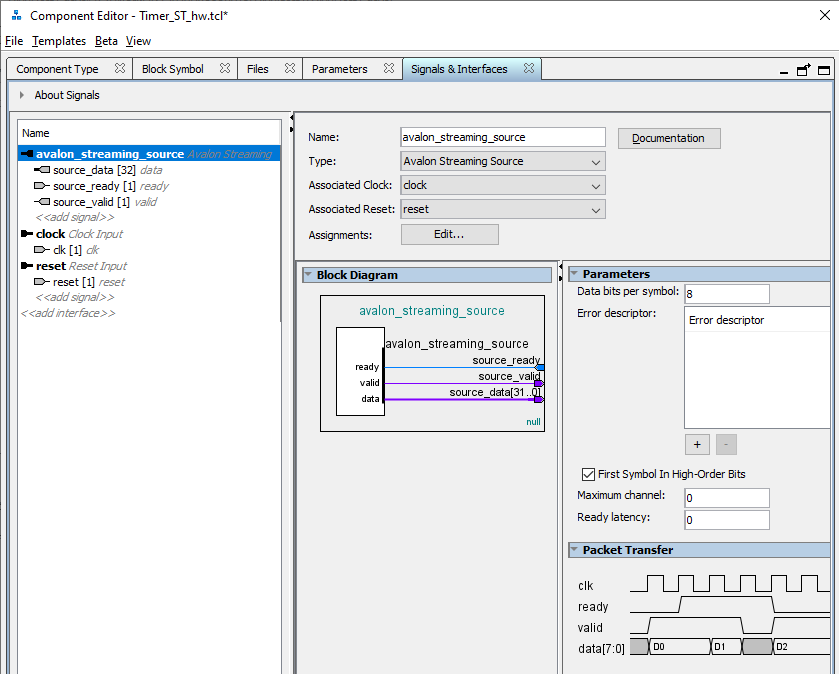 Ótimo. Adicione nosso componente ao sistema. Agora estamos procurando o bloco DMA ... E não encontramos um, mas três. Todos eles estão descritos no documento Embedded Peripheral IP User Guide da Altera (como sempre, dou nomes, mas não links, pois os links sempre mudam).
Ótimo. Adicione nosso componente ao sistema. Agora estamos procurando o bloco DMA ... E não encontramos um, mas três. Todos eles estão descritos no documento Embedded Peripheral IP User Guide da Altera (como sempre, dou nomes, mas não links, pois os links sempre mudam).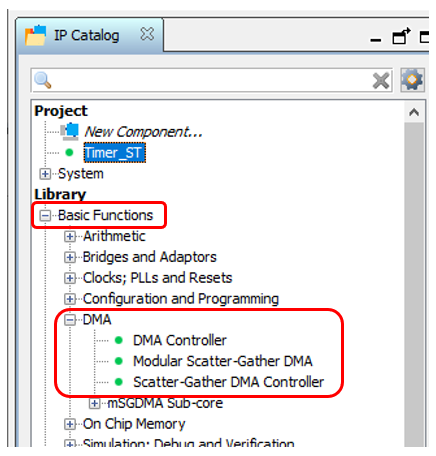 Qual usar? Eu não posso resistir à nostalgia. Em 2012, eu criei um sistema baseado no barramento PCIe. Todos os manuais da Altera continham um exemplo baseado no primeiro desses blocos. Mas ele com o componente PCIe deu uma velocidade de não mais de 4 megabytes por segundo. Naqueles dias, cuspi e escrevi meu bloco de DMA. Agora, não me lembro da velocidade dele, mas ele dirigiu os dados das unidades SATA até o limite dos recursos de unidades e SSDs da época. Ou seja, afiei um dente neste bloco. Mas não irei fazer uma comparação dos três blocos. O fato é que hoje temos que trabalhar com uma fonte baseada no Avalon-ST (Avalon Streaming Interface), e apenas o bloco Modular Scatter-Gather DMA suporta essas fontes . Aqui nós colocamos no diagrama.Nas configurações do bloco, selecione o modoStreaming para a memória mapeada . Além disso - quero direcionar os dados desde o início até o preenchimento da SDRAM, substituindo a unidade máxima de transferência de dados de 1 kilobyte para 4 megabytes. É verdade que fui avisado que, no final, o parâmetro FMax não será tão quente (mesmo se você substituir o bloco máximo por 2 kilobytes). Hoje, porém, o FMax é aceitável (104 MHz), e então vamos descobrir. Eu deixei os parâmetros restantes inalterados. Você também pode definir o modo de transmissão como Somente acesso total à palavra, isso aumentará o FMax para 109 MHz. Mas não vamos lutar por desempenho hoje.
Qual usar? Eu não posso resistir à nostalgia. Em 2012, eu criei um sistema baseado no barramento PCIe. Todos os manuais da Altera continham um exemplo baseado no primeiro desses blocos. Mas ele com o componente PCIe deu uma velocidade de não mais de 4 megabytes por segundo. Naqueles dias, cuspi e escrevi meu bloco de DMA. Agora, não me lembro da velocidade dele, mas ele dirigiu os dados das unidades SATA até o limite dos recursos de unidades e SSDs da época. Ou seja, afiei um dente neste bloco. Mas não irei fazer uma comparação dos três blocos. O fato é que hoje temos que trabalhar com uma fonte baseada no Avalon-ST (Avalon Streaming Interface), e apenas o bloco Modular Scatter-Gather DMA suporta essas fontes . Aqui nós colocamos no diagrama.Nas configurações do bloco, selecione o modoStreaming para a memória mapeada . Além disso - quero direcionar os dados desde o início até o preenchimento da SDRAM, substituindo a unidade máxima de transferência de dados de 1 kilobyte para 4 megabytes. É verdade que fui avisado que, no final, o parâmetro FMax não será tão quente (mesmo se você substituir o bloco máximo por 2 kilobytes). Hoje, porém, o FMax é aceitável (104 MHz), e então vamos descobrir. Eu deixei os parâmetros restantes inalterados. Você também pode definir o modo de transmissão como Somente acesso total à palavra, isso aumentará o FMax para 109 MHz. Mas não vamos lutar por desempenho hoje.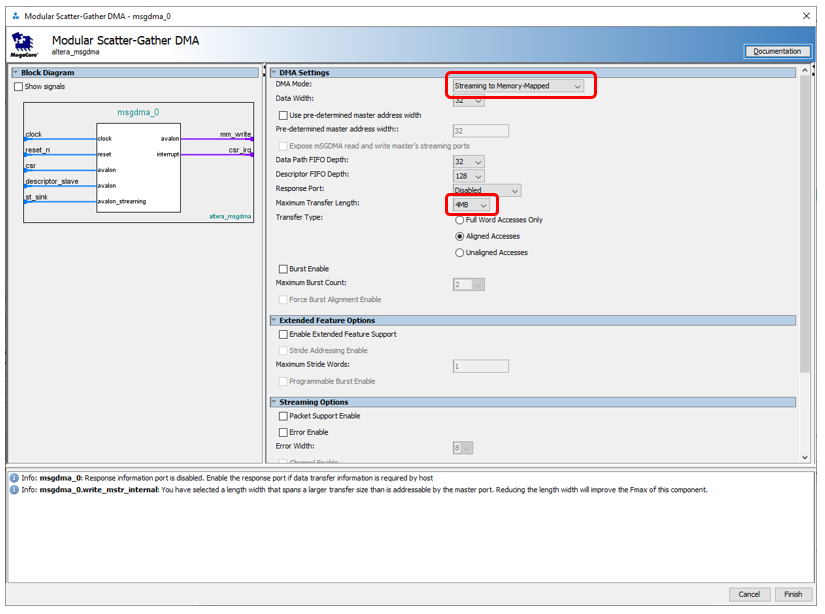 Assim. A fonte é, DMA é. Receptor ... SDRAM? Em futuras condições de combate, sim. Hoje, porém, precisamos de uma memória com características conhecidas. Infelizmente, a SDRAM precisa enviar periodicamente comandos que levam vários ciclos de clock, além disso, essa memória pode ser ocupada pela regeneração. Portanto, em vez disso, agora usaremos a memória FPGA incorporada. Tudo está funcionando para ela em uma única etapa, sem atrasos imprevisíveis.Como o controlador SDRAM é de porta única, a memória interna também pode ser usada exclusivamente no modo de porta única. É importante. O fato é que queremos gravar na memória usando o mestre do bloco DMA, mas, por outro lado, queremos ler essa memória usando o núcleo do processador ou o bloco Altera JTAG-to-Avalon-MM. A mão estende a mão e conecta os blocos de gravação e leitura a duas portas diferentes ... Mas você não pode! Pelo contrário, é proibido pelas condições do problema. Porque hoje é possível, mas amanhã substituiremos a memória por uma exclusivamente de porta única. Em geral, temos um bloco de três componentes (timer, DMA e memória):
Assim. A fonte é, DMA é. Receptor ... SDRAM? Em futuras condições de combate, sim. Hoje, porém, precisamos de uma memória com características conhecidas. Infelizmente, a SDRAM precisa enviar periodicamente comandos que levam vários ciclos de clock, além disso, essa memória pode ser ocupada pela regeneração. Portanto, em vez disso, agora usaremos a memória FPGA incorporada. Tudo está funcionando para ela em uma única etapa, sem atrasos imprevisíveis.Como o controlador SDRAM é de porta única, a memória interna também pode ser usada exclusivamente no modo de porta única. É importante. O fato é que queremos gravar na memória usando o mestre do bloco DMA, mas, por outro lado, queremos ler essa memória usando o núcleo do processador ou o bloco Altera JTAG-to-Avalon-MM. A mão estende a mão e conecta os blocos de gravação e leitura a duas portas diferentes ... Mas você não pode! Pelo contrário, é proibido pelas condições do problema. Porque hoje é possível, mas amanhã substituiremos a memória por uma exclusivamente de porta única. Em geral, temos um bloco de três componentes (timer, DMA e memória): Bem, e apenas por uma questão de proforma, adicionarei UT e sysid ao sistema JTAG (embora o segundo não tenha ajudado, eu ainda precisava conjurá-lo com um adaptador JTAG). O que é e como sua adição resolve pequenos problemas, já estudamos. Não vou pintar os pneus, está tudo claro com eles. Apenas mostre como tudo fica no meu projeto:
Bem, e apenas por uma questão de proforma, adicionarei UT e sysid ao sistema JTAG (embora o segundo não tenha ajudado, eu ainda precisava conjurá-lo com um adaptador JTAG). O que é e como sua adição resolve pequenos problemas, já estudamos. Não vou pintar os pneus, está tudo claro com eles. Apenas mostre como tudo fica no meu projeto: é isso. O sistema está pronto. Atribuímos endereços, atribuímos vetores de processador, geramos um sistema (não esqueça que você precisa salvar com o mesmo nome que o próprio projeto, depois ele irá para o nível superior da hierarquia), adicione-o ao projeto. Torne a perna de redefinição virtual, conecte clk à perna pin_25. Estamos montando o projeto, despejando-o no equipamento ... Como está, coitadinho, no escritório vazio por causa da localização remota total? ... É solitário e assustador para ela, provavelmente, sozinho ... Mas fiquei distraído.
é isso. O sistema está pronto. Atribuímos endereços, atribuímos vetores de processador, geramos um sistema (não esqueça que você precisa salvar com o mesmo nome que o próprio projeto, depois ele irá para o nível superior da hierarquia), adicione-o ao projeto. Torne a perna de redefinição virtual, conecte clk à perna pin_25. Estamos montando o projeto, despejando-o no equipamento ... Como está, coitadinho, no escritório vazio por causa da localização remota total? ... É solitário e assustador para ela, provavelmente, sozinho ... Mas fiquei distraído.Criando uma peça de software
Treinamento
No Editor do BSP, com o movimento usual da mão, ative o suporte ao C ++. Inseri tantas vezes uma captura de tela deste caso que paro de fazê-lo. Mas outra captura de tela, embora já tenha sido vista, ainda é tão comum. Então, vamos discutir mais uma vez. Lembramos que o sistema está tentando colocar dados no maior pedaço de memória. E esse é o buffer . Portanto, forçamos tudo para Data :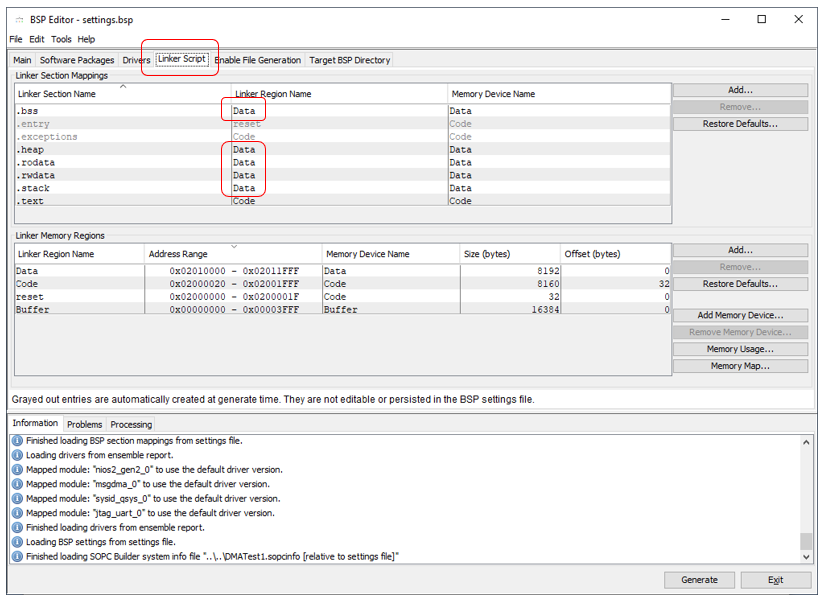
Experiência do programa
Nós criamos um código que simplesmente enche a memória com o conteúdo da fonte (no papel do contador).Ver código#include "sys/alt_stdio.h"
#include <altera_msgdma.h>
#include <altera_msgdma_descriptor_regs.h>
#include <system.h>
#include <string.h>
int main()
{
alt_putstr("Hello from Nios II!\n");
memset (BUFFER_BASE,0,BUFFER_SIZE_VALUE);
// ,
IOWR_ALTERA_MSGDMA_CSR_CONTROL(MSGDMA_0_CSR_BASE,
ALTERA_MSGDMA_CSR_STOP_DESCRIPTORS_MASK);
// , ,
// , . .
// FIFO
IOWR_ALTERA_MSGDMA_DESCRIPTOR_READ_ADDRESS(MSGDMA_0_DESCRIPTOR_SLAVE_BASE,
(alt_u32)0);
IOWR_ALTERA_MSGDMA_DESCRIPTOR_WRITE_ADDRESS(MSGDMA_0_DESCRIPTOR_SLAVE_BASE,
(alt_u32)BUFFER_BASE);
IOWR_ALTERA_MSGDMA_DESCRIPTOR_LENGTH(MSGDMA_0_DESCRIPTOR_SLAVE_BASE,
BUFFER_SIZE_VALUE);
IOWR_ALTERA_MSGDMA_DESCRIPTOR_CONTROL_STANDARD(MSGDMA_0_DESCRIPTOR_SLAVE_BASE,
ALTERA_MSGDMA_DESCRIPTOR_CONTROL_GO_MASK);
// ,
IOWR_ALTERA_MSGDMA_CSR_CONTROL(MSGDMA_0_CSR_BASE,
ALTERA_MSGDMA_CSR_STOP_ON_ERROR_MASK
& (~ALTERA_MSGDMA_CSR_STOP_DESCRIPTORS_MASK)
&(~ALTERA_MSGDMA_CSR_GLOBAL_INTERRUPT_MASK)) ;
//
static const alt_u32 errMask = ALTERA_MSGDMA_CSR_STOPPED_ON_ERROR_MASK |
ALTERA_MSGDMA_CSR_STOPPED_ON_EARLY_TERMINATION_MASK |
ALTERA_MSGDMA_CSR_STOP_STATE_MASK |
ALTERA_MSGDMA_CSR_RESET_STATE_MASK;
volatile alt_u32 status;
do
{
status = IORD_ALTERA_MSGDMA_CSR_STATUS(MSGDMA_0_CSR_BASE);
} while (!(status & errMask) &&(status & ALTERA_MSGDMA_CSR_BUSY_MASK));
alt_putstr("You can play with memory!\n");
/* Event loop never exits. */
while (1);
return 0;
}
Começamos, aguardamos a mensagem "Você pode brincar com a memória!" , coloque o programa em pausa e observe a memória, começando no endereço 0. No começo, fiquei com muito medo: no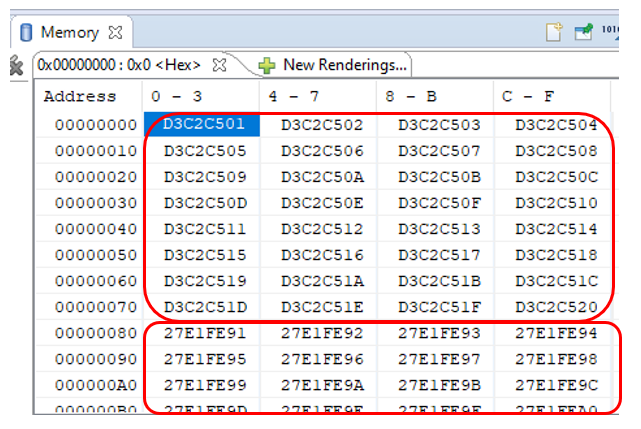 endereço 0x80, o contador altera seu valor acentuadamente. Além disso, uma quantidade muito grande. Mas acabou que está tudo bem. Em nosso local, o contador nunca para e está sempre pronto, e o DMA tem sua própria fila de leitura antecipada. Deixe-me lembrá-lo das configurações do bloco DMA:
endereço 0x80, o contador altera seu valor acentuadamente. Além disso, uma quantidade muito grande. Mas acabou que está tudo bem. Em nosso local, o contador nunca para e está sempre pronto, e o DMA tem sua própria fila de leitura antecipada. Deixe-me lembrá-lo das configurações do bloco DMA: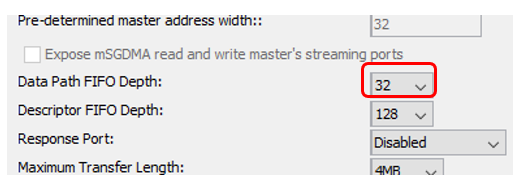 0x80 bytes são 0x20 palavras de trinta e dois bits. Apenas 32 decimais. Tudo se encaixa. Nas condições de depuração, isso não é assustador. Em condições de combate, a fonte funcionará mais corretamente (sua prontidão será redefinida). Portanto, simplesmente ignoramos esta seção. Em outras áreas, o medidor conta sequencialmente. Vou mostrar apenas o fragmento de despejo em largura. Pegue uma palavra que eu examinei na íntegra.
0x80 bytes são 0x20 palavras de trinta e dois bits. Apenas 32 decimais. Tudo se encaixa. Nas condições de depuração, isso não é assustador. Em condições de combate, a fonte funcionará mais corretamente (sua prontidão será redefinida). Portanto, simplesmente ignoramos esta seção. Em outras áreas, o medidor conta sequencialmente. Vou mostrar apenas o fragmento de despejo em largura. Pegue uma palavra que eu examinei na íntegra. Não confiando em meus olhos, escrevi um código que verifica automaticamente os dados:
Não confiando em meus olhos, escrevi um código que verifica automaticamente os dados: volatile alt_u32* pData = (alt_u32*)BUFFER_BASE;
volatile alt_u32 cur = pData[0x10];
int nLine = 0;
for (volatile int i=0x11;i<BUFFER_SIZE_VALUE/4;i++)
{
if (pData[i]!=cur+1)
{
alt_printf("Problem at 0x%x\n",i*4);
if (nLine++ > 10)
{
break;
}
}
cur = pData[i];
}
Ele também não revela nenhum problema.Tentando encontrar pelo menos alguns problemas
De fato, a ausência de problemas nem sempre é boa. Como parte do artigo, eu precisava encontrar os problemas e depois mostrar como eles foram corrigidos. Afinal, os problemas são óbvios. Um ônibus ocupado não pode transmitir dados sem atrasos! Deve haver atrasos! Mas vamos verificar por que tudo acontece tão bem. Primeiro de tudo, pode acontecer que tudo esteja no FIFO do bloco DMA. Reduza ao mínimo o tamanho: tudo continua funcionando! Boa. Certifique-se de provocar o número de acessos ao barramento mais do que a dimensão FIFO. Adicione um contador de visitas:
tudo continua funcionando! Boa. Certifique-se de provocar o número de acessos ao barramento mais do que a dimensão FIFO. Adicione um contador de visitas:
Mesmo texto: volatile alt_u32 status;
volatile int n = 0;
do
{
status = IORD_ALTERA_MSGDMA_CSR_STATUS(MSGDMA_0_CSR_BASE);
n += 1;
} while (!(status & errMask) &&(status & ALTERA_MSGDMA_CSR_BUSY_MASK));
No final do trabalho, são 29. São mais de 16. Ou seja, o FIFO deve estourar. Por precaução, vamos adicionar mais leituras de registro de status. Não ajuda.Com tristeza, desconectei-me do complexo remoto Redd, refiz o projeto para minha tábua de pão existente, à qual posso me conectar com um osciloscópio agora (no escritório, ninguém está à distância, não consigo alcançar o osciloscópio). Adicionadas duas portas ao timer: output clk_copy,
output ready_copy
E os nomeou: assign clk_copy = clk;
assign ready_copy = source_ready;
Como resultado, o módulo começou a ficar assim:module Timer_ST (
input clk,
input reset,
input logic source_ready,
output logic source_valid,
output logic[31:0] source_data,
output clk_copy,
output ready_copy
);
logic [31:0] counter;
always @ (posedge clk, posedge reset)
if (reset == 1)
begin
counter <= 0;
end else
begin
counter <= counter + 1;
end
assign source_valid = 1;
assign source_data [31:24] = counter [7:0];
assign source_data [23:16] = counter [15:8];
assign source_data [15:8] = counter [23:16];
assign source_data [7:0] = counter [31:24];
assign clk_copy = clk;
assign ready_copy = source_ready;
endmodule
Em casa, tenho um modelo menor com um cristal, então tive que reduzir o apetite da memória. E aconteceu que meu programa primitivo não caberia em uma seção de 4 kilobytes. Portanto, o tópico levantado no último artigo é, oh, quão relevante. Memória no sistema - apenas o suficiente!Quando o programa é iniciado, obtemos um aumento imediato de 16 ou 17 medidas. Isso é preenchido com o FIFO do bloco DMA. O mesmo efeito que me assustou no começo. São esses dados que formarão o preenchimento de buffer muito falso.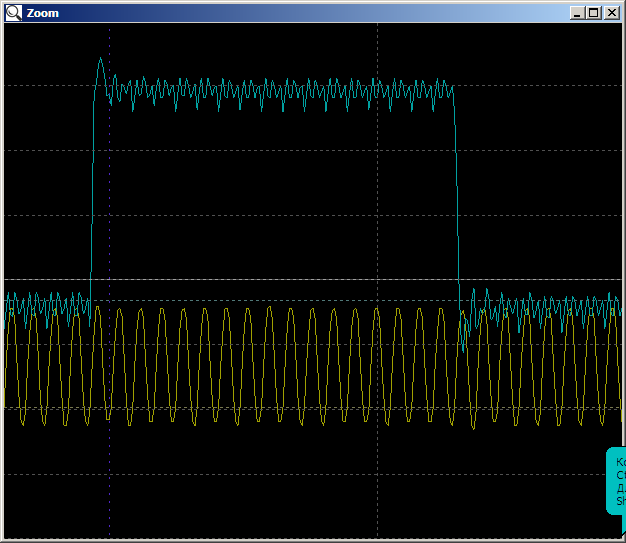 Em seguida, temos uma imagem bonita em 40960 nanossegundos, ou seja, 2048 ciclos (com um cristal doméstico, o buffer teve que ser reduzido para 8 kilobytes, ou seja, 2048 palavras de trinta e dois bits). Aqui está o começo:
Em seguida, temos uma imagem bonita em 40960 nanossegundos, ou seja, 2048 ciclos (com um cristal doméstico, o buffer teve que ser reduzido para 8 kilobytes, ou seja, 2048 palavras de trinta e dois bits). Aqui está o começo: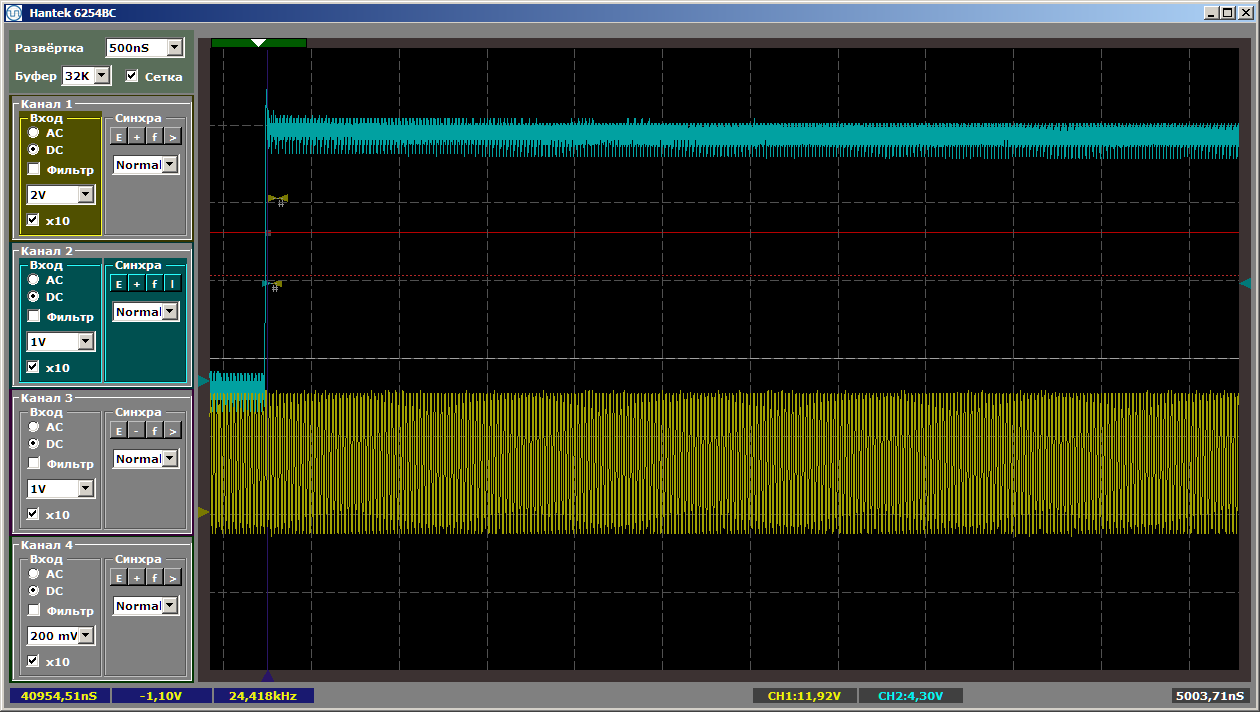 Aqui está o fim:
Aqui está o fim: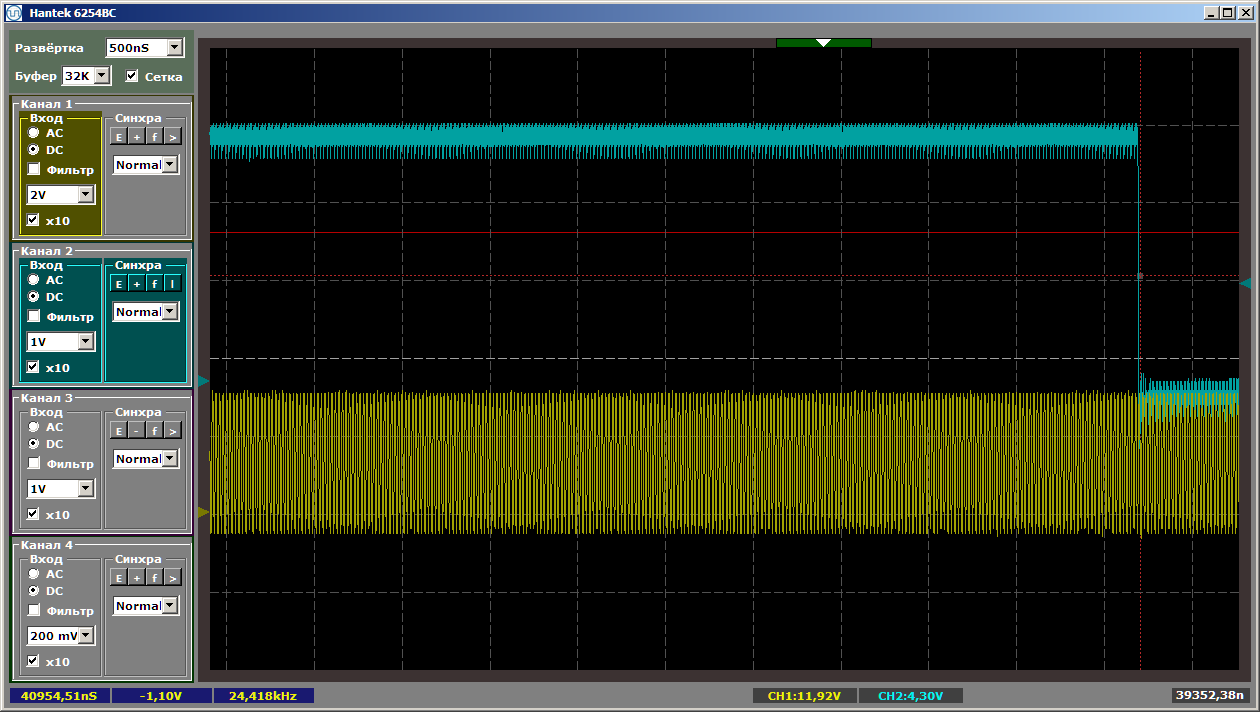 Bem, e por toda parte - nem um único fracasso. Não, estava claro que isso iria acontecer, mas havia alguma esperança ...Talvez devêssemos tentar escrever no ônibus, e não apenas ler a partir dele?
Bem, e por toda parte - nem um único fracasso. Não, estava claro que isso iria acontecer, mas havia alguma esperança ...Talvez devêssemos tentar escrever no ônibus, e não apenas ler a partir dele? Adicionei um bloco GPIO ao sistema: adicionei uma entrada enquanto aguardava a preparação:
Adicionei um bloco GPIO ao sistema: adicionei uma entrada enquanto aguardava a preparação:
Mesmo texto volatile alt_u32 status;
volatile int n = 0;
do
{
status = IORD_ALTERA_MSGDMA_CSR_STATUS(MSGDMA_0_CSR_BASE);
IOWR_ALTERA_AVALON_PIO_DATA (PIO_0_BASE,0x01);
IOWR_ALTERA_AVALON_PIO_DATA (PIO_0_BASE,0x00);
n += 1;
} while (!(status & errMask) &&(status & ALTERA_MSGDMA_CSR_BUSY_MASK));
Não há problemas e é isso! Quem é o culpado?Não há milagres, mas há coisas inexploradas
Quem é o culpado? Com tristeza, comecei a estudar todos os menus da ferramenta Platform Designer e, ao que parece, encontrei uma pista. Como é geralmente um pneu? O conjunto de fios aos quais os clientes estão conectados. Assim? Parece tão. Vemos isso nas figuras do editor. Apenas, o segundo objetivo do artigo era mostrar como o ônibus pode ser dividido em dois segmentos independentes, cada um dos quais funciona sem interferir no outro.Mas vamos ver as mensagens que aparecem quando o sistema é gerado. Destaque palavras-chave: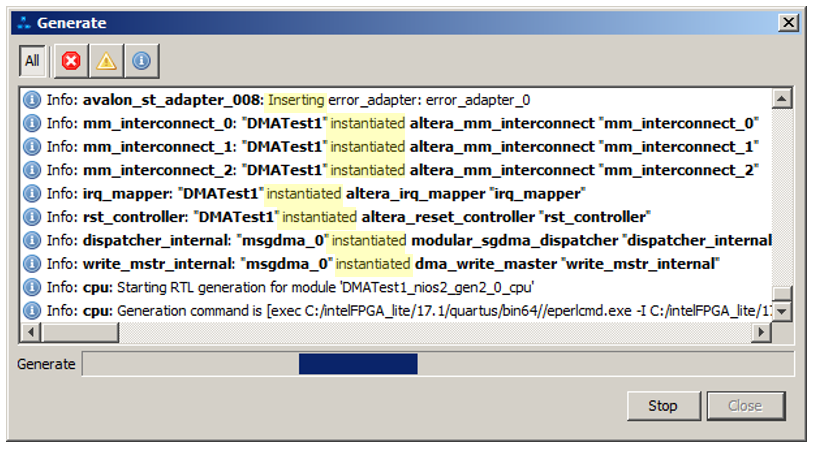 E há muitas mensagens semelhantes: é adicionada, é adicionada. Acontece que após a edição com canetas, muitas coisas adicionais são adicionadas ao sistema. Como você olharia para um esquema em que tudo isso já está disponível? Ainda estou nadando nisto, mas podemos obter a resposta mais provável na estrutura do artigo escolhendo este item de menu: a
E há muitas mensagens semelhantes: é adicionada, é adicionada. Acontece que após a edição com canetas, muitas coisas adicionais são adicionadas ao sistema. Como você olharia para um esquema em que tudo isso já está disponível? Ainda estou nadando nisto, mas podemos obter a resposta mais provável na estrutura do artigo escolhendo este item de menu: a imagem aberta é impressionante por si só, mas não vou dar. E imediatamente selecionarei esta guia:
imagem aberta é impressionante por si só, mas não vou dar. E imediatamente selecionarei esta guia: E aí vemos o seguinte:
E aí vemos o seguinte: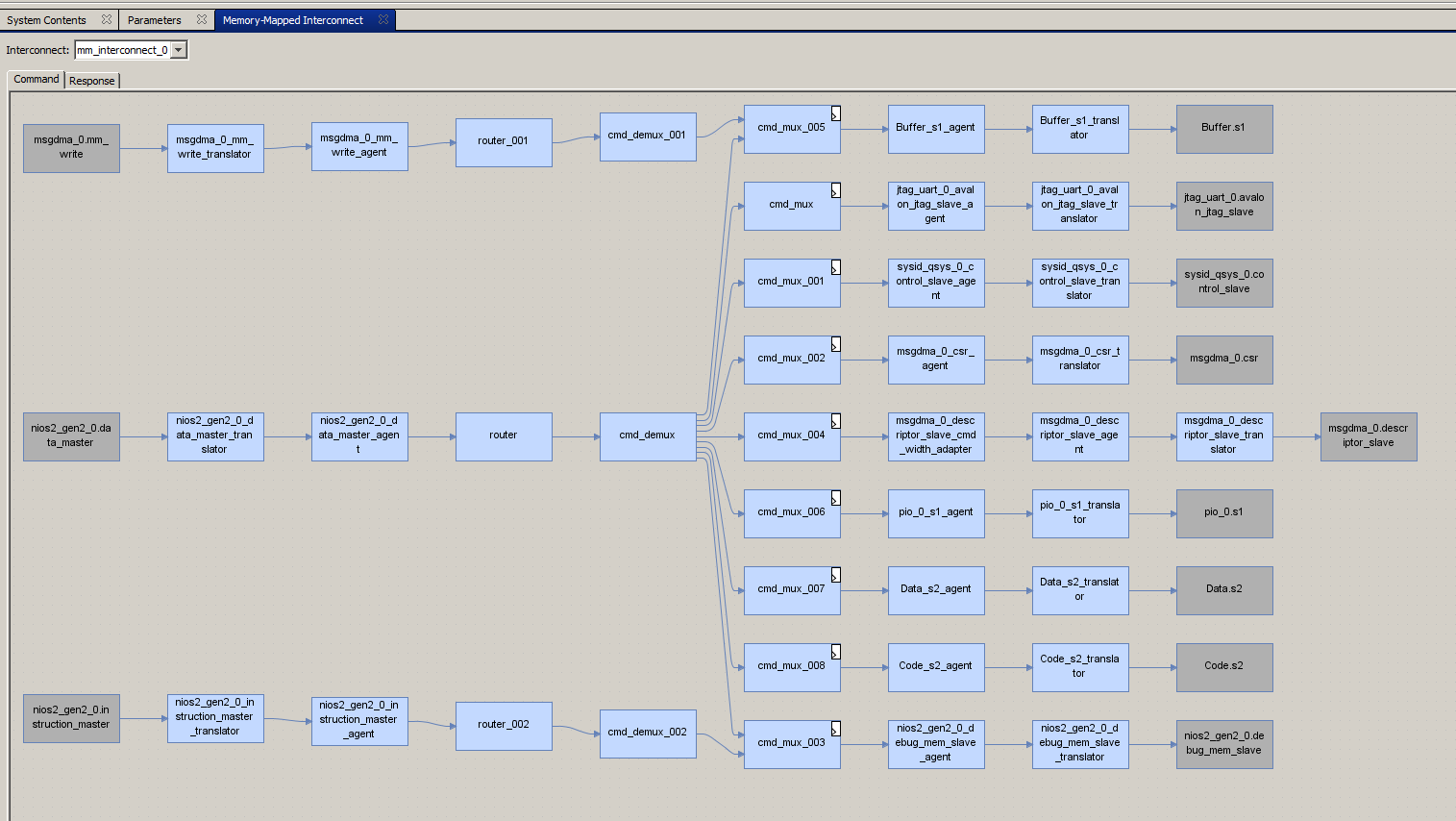 Mostrarei maior o mais importante:
Mostrarei maior o mais importante: Os pneus não estão combinados! Eles são segmentados! Não posso justificar (talvez os especialistas me corrijam nos comentários), mas parece que o sistema inseriu as opções para nós! São esses switches que criam os segmentos de barramento isolados, e o sistema principal pode trabalhar em paralelo com a unidade DMA, que neste momento pode acessar a memória sem conflito!
Os pneus não estão combinados! Eles são segmentados! Não posso justificar (talvez os especialistas me corrijam nos comentários), mas parece que o sistema inseriu as opções para nós! São esses switches que criam os segmentos de barramento isolados, e o sistema principal pode trabalhar em paralelo com a unidade DMA, que neste momento pode acessar a memória sem conflito!Provocamos problemas reais
Tendo recebido todo esse conhecimento, concluímos que podemos muito bem provocar problemas. Isso é necessário para garantir que o sistema de teste possa criá-los, o que significa que o ambiente de desenvolvimento realmente os resolve independentemente. Não nos referiremos a dispositivos abstratos no barramento, mas à mesma memória Buffer, para que o bloco cmd_mux_005 distribua o barramento entre o núcleo do processador e o bloco DMA. Reescrevemos a função de longa espera da seguinte maneira: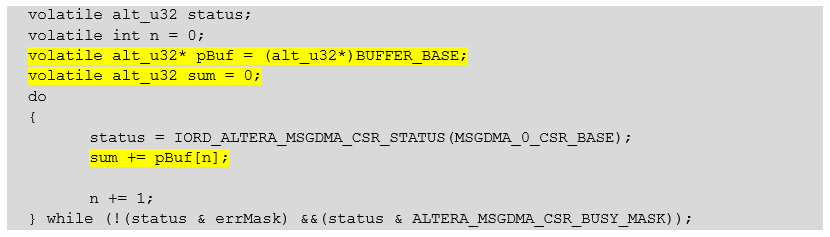
Mesmo texto volatile alt_u32 status;
volatile int n = 0;
volatile alt_u32* pBuf = (alt_u32*)BUFFER_BASE;
volatile alt_u32 sum = 0;
do
{
status = IORD_ALTERA_MSGDMA_CSR_STATUS(MSGDMA_0_CSR_BASE);
sum += pBuf[n];
n += 1;
} while (!(status & errMask) &&(status & ALTERA_MSGDMA_CSR_BUSY_MASK));
E finalmente, mergulhos apareceram na forma de onda! A função de verificação de memória também encontrou muitas omissões:
A função de verificação de memória também encontrou muitas omissões: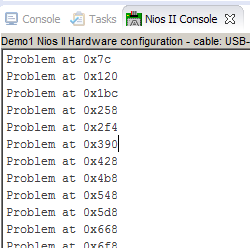 Sim, e vemos muito bem que os dados são alterados de uma linha para
Sim, e vemos muito bem que os dados são alterados de uma linha para outra : e aqui está um exemplo de um ponto ruim específico (6CCE488F está ausente):
outra : e aqui está um exemplo de um ponto ruim específico (6CCE488F está ausente): Agora vemos que o experimento foi feito corretamente, apenas o ambiente de desenvolvimento realizado otimização para nós. É esse o caso quando pronuncio a frase “todos machucam com inteligência todo o aço” não com zombaria, mas com gratidão. Obrigado aos desenvolvedores do Quartus por esse assunto!
Agora vemos que o experimento foi feito corretamente, apenas o ambiente de desenvolvimento realizado otimização para nós. É esse o caso quando pronuncio a frase “todos machucam com inteligência todo o aço” não com zombaria, mas com gratidão. Obrigado aos desenvolvedores do Quartus por esse assunto!Conclusão
Aprendemos como inserir um bloco DMA no sistema para transferir dados de streaming para a memória. Também garantimos que o processo de download de outros dispositivos no barramento não interfira no processo de download. O ambiente de desenvolvimento criará automaticamente um segmento isolado que será executado em paralelo com outras seções do barramento. Obviamente, se alguém se volta para o mesmo segmento, os conflitos e o tempo gasto para resolvê-los são inevitáveis, mas o programador pode muito bem prever tais coisas.No próximo artigo, substituiremos a RAM por um controlador SDRAM e o temporizador por uma "cabeça" real e faremos o primeiro analisador lógico. Vai funcionar? Ainda não sei. Espero que os problemas não apareçam.