Vou explicar o título do artigo imediatamente. Inicialmente, foi planejado dar conselhos bons e confiáveis sobre como acelerar o uso da reflexão usando um exemplo simples, mas realista, mas durante o benchmarking, descobriu-se que a reflexão não funciona tão lentamente quanto eu pensava, o LINQ trabalha mais devagar do que sonhava em pesadelos. Mas no final, descobri que eu também cometi um erro nas medições ... Detalhes dessa história de vida sob o corte e nos comentários. Como o exemplo é bastante cotidiano e implementado em princípio, como geralmente é feito na empresa, mostrou-se bastante interessante, como me parece, uma demonstração da vida: não houve efeito perceptível na velocidade do assunto principal do artigo devido à lógica externa: Moq, Autofac, EF Core, etc. "Cintas".Comecei meu trabalho com a impressão deste artigo: Por que a reflexão é lentaComo você pode ver, o autor sugere o uso de delegados compilados em vez de invocar diretamente métodos de tipo de reflexão como uma ótima maneira de acelerar bastante o aplicativo. Existe, é claro, emissão de IL, mas eu gostaria de evitá-la, pois essa é a maneira mais trabalhosa de concluir a tarefa, que está repleta de erros.Considerando que sempre adotei uma opinião semelhante sobre a velocidade da reflexão, não pretendi lançar dúvidas particulares nas conclusões do autor.Costumo encontrar o uso ingênuo de reflexão em uma empresa. O tipo é usado. As informações da propriedade são obtidas. O método SetValue é chamado e todos estão felizes. O valor voou para o campo de destino, todo mundo está feliz. Pessoas muito inteligentes - pecadoras e líderes de equipe - escrevem suas extensões no objeto, baseando-se em uma implementação ingênua de mapeadores "universais" de um tipo em outro. A essência disso é geralmente: pegamos todos os campos, pegamos todas as propriedades, iteramos sobre eles: se os nomes dos membros do tipo coincidem, executamos SetValue. Periodicamente, capturamos exceções em casos em que um dos tipos não encontrou alguma propriedade, mas também existe uma saída que atinge o desempenho. Tente / pegue.Vi pessoas reinventando analisadores e mapeadores sem estar totalmente armado com informações sobre como as bicicletas inventaram antes deles funcionarem. Vi pessoas ocultando suas implementações ingênuas atrás de estratégias, atrás de interfaces, atrás de injeções, como se isso desculpasse as bacanas subseqüentes. Com essas implementações, virei o nariz. Na verdade, eu não medi o vazamento real de desempenho e, se possível, simplesmente alterei a implementação para uma mais "ótima", se minhas mãos chegassem. Como as primeiras medições, discutidas abaixo, fiquei seriamente envergonhada.Acho que muitos de vocês, ao ler Richter ou outros ideólogos, chegaram a uma afirmação bastante justa de que a reflexão no código é um fenômeno que tem um efeito muito negativo no desempenho do aplicativo.A chamada de reflexão força o CLR a percorrer a montagem em busca da correta, puxar seus metadados, analisá-los etc. Além disso, a reflexão durante a passagem da sequência leva à alocação de uma grande quantidade de memória. Nós gastamos memória, o CLR descobre o HZ e congela a corrida. Deve ser notavelmente lento, acredite em mim. A enorme quantidade de memória dos servidores de produção modernos ou das máquinas na nuvem não economiza em altos atrasos de processamento. De fato, quanto mais memória, maior a probabilidade de você perceber como o HZ funciona. A reflexão é, em teoria, um pano vermelho extra para ele.No entanto, todos nós usamos contêineres de IoC e mapeadores de datas, cujo princípio também se baseia na reflexão, no entanto, perguntas sobre seu desempenho geralmente não surgem. Não, não porque a introdução de dependências e a abstração de modelos de contexto externo limitado sejam coisas tão necessárias que precisamos sacrificar o desempenho em qualquer caso. Tudo é mais simples - realmente não afeta muito o desempenho.O fato é que as estruturas mais comuns baseadas na tecnologia de reflexão usam todos os tipos de truques para trabalhar com ela da melhor maneira possível. Isso geralmente é um cache. Geralmente, essas são expressões e delegados compilados a partir da árvore de expressões. O mesmo mapeador automático mantém um dicionário competitivo, combinando tipos com funções que podem ser convertidas entre si sem chamar reflexão.Como isso é alcançado? De fato, isso não difere da lógica que a própria plataforma usa para gerar o código JIT. Quando você chama um método pela primeira vez, ele compila (e, sim, esse processo não é rápido); nas chamadas subseqüentes, o controle é transferido para o método já compilado e não haverá perdas de desempenho especiais.No nosso caso, você também pode usar a compilação JIT e, em seguida, usar o comportamento compilado com o mesmo desempenho que seus equivalentes AOT. Nesse caso, expressões virão em nosso auxílio.Resumidamente, podemos formular o princípio em questão da seguinte maneira: Oresultado final da reflexão deve ser armazenado em cache na forma de um delegado contendo uma função compilada. Também faz sentido armazenar em cache todos os objetos necessários com informações sobre tipos nos campos do seu tipo que são armazenados fora dos objetos - o trabalhador.Há lógica nisso. O senso comum nos diz que, se algo puder ser compilado e armazenado em cache, isso deve ser feito.Olhando para o futuro, deve-se dizer que o cache ao trabalhar com reflexão tem suas vantagens, mesmo que você não use o método proposto para compilar expressões. Na verdade, aqui estou simplesmente repetindo as teses do autor do artigo a que me refiro acima.Agora sobre o código. Vejamos um exemplo que se baseia na minha dor recente que tive de enfrentar na produção séria de uma organização de crédito séria. Todas as entidades são fictícias para que ninguém adivinhe.Existe uma certa entidade. Que seja contato. Existem letras com um corpo padronizado, a partir do qual o analisador e o hidratador criam esses mesmos contatos. Chegou uma carta, lemos, desmontamos os pares de valores-chave, criamos um contato e salvamos no banco de dados.Isso é elementar. Suponha que um contato tenha o nome, a idade e o número de contato da propriedade. Esses dados são transmitidos em uma carta. Além disso, a empresa deseja que o suporte possa adicionar rapidamente novas chaves para mapear as propriedades da entidade aos pares no corpo da letra. No caso de alguém impresso no modelo ou antes da liberação, seria necessário iniciar com urgência o mapeamento de um novo parceiro, ajustando-o ao novo formato. Em seguida, podemos adicionar uma nova correlação de mapeamento como uma correção de dados barata. Ou seja, um exemplo de vida.Implementamos, criamos testes. Trabalho.Não vou dar o código: havia muitas fontes, e elas estão disponíveis no GitHub pelo link no final do artigo. Você pode baixá-los, torturá-los além do reconhecimento e medi-los, pois isso afetaria o seu caso. Vou dar apenas o código de dois métodos de modelo que distinguem o hidratador, que deveria ter sido rápido do hidratador, que deveria ter sido lento.A lógica é a seguinte: o método de modelo recebe os pares formados pela lógica do analisador de base. O nível LINQ é o analisador e a lógica básica do hidratador, solicitando o contexto db e combinando chaves com pares do analisador (para essas funções, existe um código sem LINQ para comparação). Em seguida, os pares são transferidos para o método de hidratação principal e os valores dos pares são definidos para as propriedades correspondentes da entidade."Rápido" (prefixo rápido nos benchmarks): protected override Contact GetContact(PropertyToValueCorrelation[] correlations)
{
var contact = new Contact();
foreach (var setterMapItem in _proprtySettersMap)
{
var correlation = correlations.FirstOrDefault(x => x.PropertyName == setterMapItem.Key);
setterMapItem.Value(contact, correlation?.Value);
}
return contact;
}
Como podemos ver, uma coleção estática com setters de propriedades é usada - lambdas compiladas que chamam a entidade setter. Gerado pelo seguinte código: static FastContactHydrator()
{
var type = typeof(Contact);
foreach (var property in type.GetProperties())
{
_proprtySettersMap[property.Name] = GetSetterAction(property);
}
}
private static Action<Contact, string> GetSetterAction(PropertyInfo property)
{
var setterInfo = property.GetSetMethod();
var paramValueOriginal = Expression.Parameter(property.PropertyType, "value");
var paramEntity = Expression.Parameter(typeof(Contact), "entity");
var setterExp = Expression.Call(paramEntity, setterInfo, paramValueOriginal).Reduce();
var lambda = (Expression<Action<Contact, string>>)Expression.Lambda(setterExp, paramEntity, paramValueOriginal);
return lambda.Compile();
}
Em geral, é claro. Percorremos as propriedades, criamos representantes para eles que chamam os levantadores e os salvamos. Então ligamos quando necessário."Lento" (prefixo lento nos benchmarks): protected override Contact GetContact(PropertyToValueCorrelation[] correlations)
{
var contact = new Contact();
foreach (var property in _properties)
{
var correlation = correlations.FirstOrDefault(x => x.PropertyName == property.Name);
if (correlation?.Value == null)
continue;
property.SetValue(contact, correlation.Value);
}
return contact;
}
Aqui, imediatamente contornamos as propriedades e chamamos SetValue diretamente.Para maior clareza e como referência, implementei um método ingênuo que grava os valores de seus pares de correlação diretamente nos campos da entidade. O prefixo é manual.Agora tomamos o BenchmarkDotNet e estudamos a produtividade. E de repente ... (spoiler não é o resultado certo, os detalhes estão abaixo)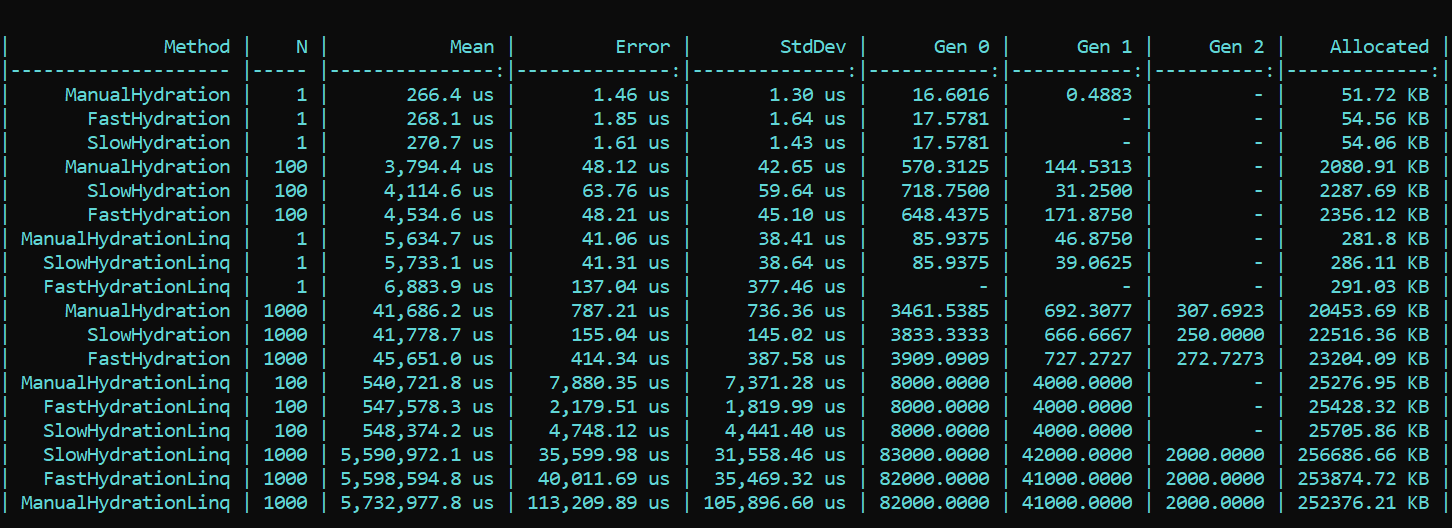 O que vemos aqui? Os métodos que usam triunfantemente o prefixo Fast acabam sendo mais lentos em quase todas as passagens do que os métodos com o prefixo Slow. Isso vale para alocação e velocidade. Por outro lado, a implementação bonita e elegante do mapeamento usando métodos LINQ projetados para essa finalidade, pelo contrário, consome muito o desempenho. A diferença de pedidos. A tendência não muda com um número diferente de passes. A diferença é apenas em escala. Com o LINQ 4 a 200 vezes mais lento, há mais detritos na mesma escala.ATUALIZADOEu não podia acreditar nos meus olhos, mas, mais importante, nem meus olhos nem meu código foram acreditados pelo nosso colega - Dmitry Tikhonov 0x1000000. Depois de verificar novamente minha solução, ele descobriu brilhantemente e apontou um erro que eu perdi devido a várias alterações na implementação. Depois de corrigir o erro encontrado na configuração do Moq, todos os resultados se encaixaram. De acordo com os resultados do reteste, a principal tendência não muda - o LINQ afeta o desempenho ainda mais forte que a reflexão. No entanto, é bom que o trabalho com a compilação de expressões não seja inútil e o resultado seja visível na alocação e no tempo de execução. A primeira execução, quando os campos estáticos são inicializados, é naturalmente mais lenta no método "rápido", mas a situação muda ainda mais.Aqui está o resultado do novo teste:
O que vemos aqui? Os métodos que usam triunfantemente o prefixo Fast acabam sendo mais lentos em quase todas as passagens do que os métodos com o prefixo Slow. Isso vale para alocação e velocidade. Por outro lado, a implementação bonita e elegante do mapeamento usando métodos LINQ projetados para essa finalidade, pelo contrário, consome muito o desempenho. A diferença de pedidos. A tendência não muda com um número diferente de passes. A diferença é apenas em escala. Com o LINQ 4 a 200 vezes mais lento, há mais detritos na mesma escala.ATUALIZADOEu não podia acreditar nos meus olhos, mas, mais importante, nem meus olhos nem meu código foram acreditados pelo nosso colega - Dmitry Tikhonov 0x1000000. Depois de verificar novamente minha solução, ele descobriu brilhantemente e apontou um erro que eu perdi devido a várias alterações na implementação. Depois de corrigir o erro encontrado na configuração do Moq, todos os resultados se encaixaram. De acordo com os resultados do reteste, a principal tendência não muda - o LINQ afeta o desempenho ainda mais forte que a reflexão. No entanto, é bom que o trabalho com a compilação de expressões não seja inútil e o resultado seja visível na alocação e no tempo de execução. A primeira execução, quando os campos estáticos são inicializados, é naturalmente mais lenta no método "rápido", mas a situação muda ainda mais.Aqui está o resultado do novo teste: Conclusão: ao usar a reflexão em uma empresa, o recurso a truques não é particularmente necessário - o LINQ aumentará o desempenho com mais força. No entanto, em métodos altamente carregados que exigem otimização, é possível preservar a reflexão na forma de inicializadores e delegar compiladores, que fornecerão lógica "rápida". Assim, você pode manter a flexibilidade da reflexão e a velocidade do aplicativo.Um código com uma referência está disponível aqui. Todos podem verificar duas vezes minhas palavras:HabraReflectionTestsPS: o código usa IoC nos testes e o design explícito nos benchmarks. O fato é que, na implementação final, compartilho todos os fatores que podem afetar o desempenho e gerar ruído.PPS: Obrigado a Dmitry Tikhonov @ 0x1000000por detectar meu erro na configuração do Moq, que afetou as primeiras medições. Se algum dos leitores tiver carma suficiente, goste, por favor. O homem parou, o homem leu, o homem verificou duas vezes e indicou um erro. Eu acho que isso é digno de respeito e simpatia.PPPS: graças ao leitor meticuloso que chegou ao fundo do estilo e do design. Sou a favor da uniformidade e conveniência. A diplomacia da apresentação deixa muito a desejar, mas levei em conta as críticas. Eu peço a concha.
Conclusão: ao usar a reflexão em uma empresa, o recurso a truques não é particularmente necessário - o LINQ aumentará o desempenho com mais força. No entanto, em métodos altamente carregados que exigem otimização, é possível preservar a reflexão na forma de inicializadores e delegar compiladores, que fornecerão lógica "rápida". Assim, você pode manter a flexibilidade da reflexão e a velocidade do aplicativo.Um código com uma referência está disponível aqui. Todos podem verificar duas vezes minhas palavras:HabraReflectionTestsPS: o código usa IoC nos testes e o design explícito nos benchmarks. O fato é que, na implementação final, compartilho todos os fatores que podem afetar o desempenho e gerar ruído.PPS: Obrigado a Dmitry Tikhonov @ 0x1000000por detectar meu erro na configuração do Moq, que afetou as primeiras medições. Se algum dos leitores tiver carma suficiente, goste, por favor. O homem parou, o homem leu, o homem verificou duas vezes e indicou um erro. Eu acho que isso é digno de respeito e simpatia.PPPS: graças ao leitor meticuloso que chegou ao fundo do estilo e do design. Sou a favor da uniformidade e conveniência. A diplomacia da apresentação deixa muito a desejar, mas levei em conta as críticas. Eu peço a concha.