Olá, meu nome é Alexander Vasin, sou desenvolvedor de back-end na Edadil. A idéia desse material começou com o fato de que eu queria analisar a tarefa introdutória ( Ya.Disk ) na Escola de Desenvolvimento de Backend Yandex. Comecei a descrever todas as sutilezas da escolha de certas tecnologias, a metodologia de teste ... Acabou não havendo análise, mas um guia muito detalhado sobre como escrever backends em Python. Desde a ideia inicial, havia apenas requisitos para o serviço, no exemplo dos quais é conveniente desmontar ferramentas e tecnologias. Como resultado, acordei com cem mil caracteres. Exatamente era necessário muito para considerar tudo em grandes detalhes. Portanto, o programa para os próximos 100 kilobytes: como criar um back-end de serviço, desde a escolha das ferramentas até a implantação. TL; DR: Aqui está um representante do GitHub com o aplicativo, e quem ama longreads (reais) - por favor, sob cat.Vamos desenvolver e testar o serviço da API REST em Python, empacotá-lo em um contêiner Docker leve e implantá-lo usando o Ansible.
TL; DR: Aqui está um representante do GitHub com o aplicativo, e quem ama longreads (reais) - por favor, sob cat.Vamos desenvolver e testar o serviço da API REST em Python, empacotá-lo em um contêiner Docker leve e implantá-lo usando o Ansible.Você pode implementar o serviço da API REST de maneiras diferentes usando ferramentas diferentes. A solução descrita não é a única correta. Escolhi a implementação e as ferramentas com base em minha experiência e preferências pessoais.
O que nós fazemos?
Imagine que uma loja de presentes online planeja iniciar uma ação em diferentes regiões. Para que uma estratégia de vendas seja eficaz, é necessária uma análise de mercado. A loja possui um fornecedor que envia regularmente (por exemplo, por correio) o descarregamento de dados com informações sobre os residentes.Vamos desenvolver um serviço de API REST Python que analisará os dados fornecidos e identificará a demanda por presentes de residentes de diferentes faixas etárias em diferentes cidades por mês.Implementamos os seguintes manipuladores no serviço:POST /imports
Adiciona um novo upload com dados;
GET /imports/$import_id/citizens
Retorna os residentes da descarga especificada;
PATCH /imports/$import_id/citizens/$citizen_id
Altera informações sobre o residente (e seus parentes) na descarga especificada;
GET /imports/$import_id/citizens/birthdays
, ( ), ;
GET /imports/$import_id/towns/stat/percentile/age
50-, 75- 99- ( ) .
?
Então, estamos escrevendo um serviço em Python usando estruturas familiares, bibliotecas e DBMS.Em 4 palestras do curso em vídeo, vários DBMSs e seus recursos são descritos. Para minha implementação, escolhi o PostgreSQL DBMS , que se estabeleceu como uma solução confiável, com excelente documentação em russo , uma forte comunidade russa (você sempre pode encontrar a resposta para uma pergunta em russo) e até cursos gratuitos . O modelo relacional é bastante versátil e bem compreendido por muitos desenvolvedores. Embora o mesmo possa ser feito em qualquer DBMS NoSQL, neste artigo consideraremos o PostgreSQL.O principal objetivo do serviço - transmissão de dados pela rede entre o banco de dados e os clientes - não implica uma grande carga no processador, mas requer a capacidade de processar várias solicitações ao mesmo tempo. Em 10 palestras consideradas abordagem assíncrona. Ele permite que você atenda com eficiência vários clientes no mesmo processo do sistema operacional (ao contrário, por exemplo, do modelo pré-fork usado no Flask / Django, que cria vários processos para processar solicitações de usuários, cada um deles consome memória, mas fica ocioso na maioria das vezes ) Portanto, como uma biblioteca para escrever o serviço, escolhi o aiohttp assíncrono . A 5ª palestra do curso em vídeo informa que SQLAlchemy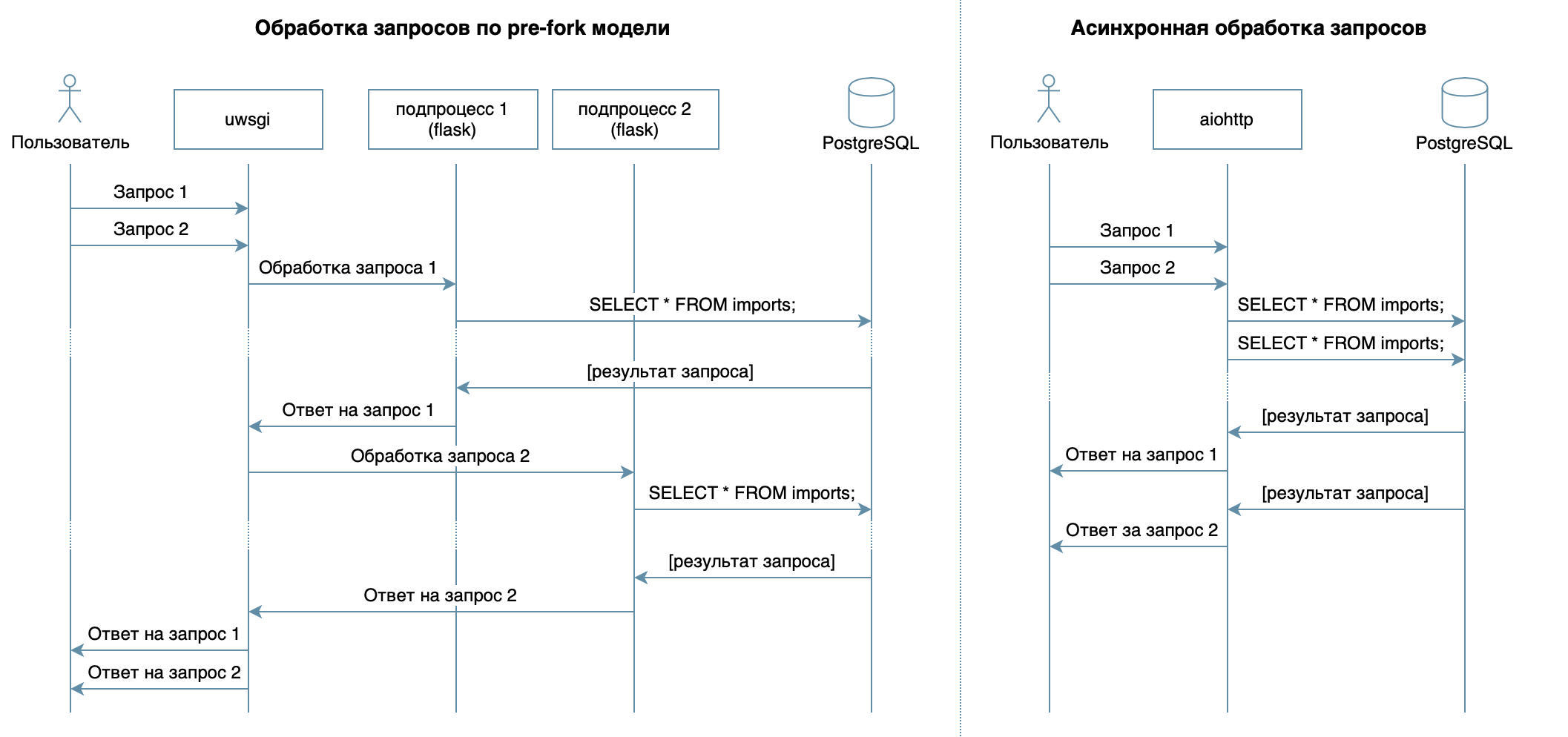 permite decompor consultas complexas em partes, reutilizá-las, gerar consultas com um conjunto dinâmico de campos (por exemplo, o processador PATCH permite atualização parcial dos residentes com campos arbitrários) e se concentrar diretamente na lógica comercial. O driver asyncpg pode lidar com essas solicitações e transferir os dados o mais rápido possível , e o asyncpgsa os ajudará a fazer amigos .Minha ferramenta favorita para gerenciar o estado do banco de dados e trabalhar com migrações é o Alembic . A propósito, recentemente falei sobre isso em Moscow Python .A lógica da validação foi descrita sucintamente pelos esquemas de Marshmallow (incluindo checagens de vínculos familiares). Usando o módulo aiohttp-specVinculei manipuladores aiohttp e esquemas para validação de dados, e o bônus foi gerar documentação no formato Swagger e exibi-la em uma interface gráfica .Para escrever provas, eu escolhi
permite decompor consultas complexas em partes, reutilizá-las, gerar consultas com um conjunto dinâmico de campos (por exemplo, o processador PATCH permite atualização parcial dos residentes com campos arbitrários) e se concentrar diretamente na lógica comercial. O driver asyncpg pode lidar com essas solicitações e transferir os dados o mais rápido possível , e o asyncpgsa os ajudará a fazer amigos .Minha ferramenta favorita para gerenciar o estado do banco de dados e trabalhar com migrações é o Alembic . A propósito, recentemente falei sobre isso em Moscow Python .A lógica da validação foi descrita sucintamente pelos esquemas de Marshmallow (incluindo checagens de vínculos familiares). Usando o módulo aiohttp-specVinculei manipuladores aiohttp e esquemas para validação de dados, e o bônus foi gerar documentação no formato Swagger e exibi-la em uma interface gráfica .Para escrever provas, eu escolhi pytest, mais sobre isso em 3 palestras .Para depurar e criar um perfil desse projeto, usei o depurador PyCharm ( aula 9 ).Em 7, a palestra descreve como qualquer Docker de computador (ou mesmo em SO diferente) pode ser executado empacotado sem precisar ajustar o ambiente do aplicativo para iniciar e fácil instalar / atualizar / excluir o aplicativo no servidor.Para a implantação, escolhi o Ansible. Ele permite descrever declarativamente o estado desejado do servidor e seus serviços, funciona via ssh e não requer software especial.Desenvolvimento
Decidi dar um nome ao pacote Python analyzere usar a seguinte estrutura: No arquivo
No arquivo analyzer/__init__.py, publiquei informações gerais sobre o pacote: descrição ( documentação ), versão, licença, contatos do desenvolvedor.Pode ser visualizado com a ajuda integrada$ python
>>> import analyzer
>>> help(analyzer)
Help on package analyzer:
NAME
analyzer
DESCRIPTION
REST API, .
PACKAGE CONTENTS
api (package)
db (package)
utils (package)
DATA
__all__ = ('__author__', '__email__', '__license__', '__maintainer__',...
__email__ = 'alvassin@yandex.ru'
__license__ = 'MIT'
__maintainer__ = 'Alexander Vasin'
VERSION
0.0.1
AUTHOR
Alexander Vasin
FILE
/Users/alvassin/Work/backendschool2019/analyzer/__init__.py
O pacote possui dois pontos de entrada - o serviço da API REST ( analyzer/api/__main__.py) e o utilitário de gerenciamento de estado do banco de dados ( analyzer/db/__main__.py). Os arquivos são chamados __main__.pypor um motivo - em primeiro lugar, esse nome atrai a atenção, deixa claro que o arquivo é um ponto de entrada.Em segundo lugar, graças a esta abordagem dos pontos de entrada python -m:
$ python -m analyzer.api --help
$ python -m analyzer.db --help
Por que você precisa começar com o setup.py?
No futuro, pensaremos em como distribuir o aplicativo: ele pode ser empacotado em um arquivo zip (além de roda / ovo), um pacote rpm, um arquivo pkg para macOS e instalado em um computador remoto, em uma máquina virtual, em um MacBook ou em Docker. recipiente.O principal objetivo do arquivo setup.pyé descrever o pacote com o aplicativo . O arquivo deve conter informações gerais sobre o pacote (nome, versão, autor etc.), mas também nele você pode especificar os módulos necessários para o trabalho, dependências "extras" (por exemplo, para teste), pontos de entrada (por exemplo, comandos executáveis) ) e requisitos para o intérprete. Os plugins Setuptools permitem coletar artefato do pacote descrito. Existem plugins integrados: zip, egg, rpm, macOS pkg. Os plugins restantes são distribuídos via PyPI: wheel ,distutils/setuptoolsxar , pex .No final das contas, descrevendo um arquivo, temos grandes oportunidades. É por isso que o desenvolvimento de um novo projeto deve começar setup.py.Na função, os setup()módulos dependentes são indicados por uma lista:setup(..., install_requires=["aiohttp", "SQLAlchemy"])
Mas descrevi as dependências em arquivos separados requirements.txte requirements.dev.txtcujo conteúdo é usado setup.py. Parece-me mais flexível, além de haver um segredo: mais tarde, você poderá criar uma imagem do Docker mais rapidamente. As dependências serão definidas como uma etapa separada antes da instalação do próprio aplicativo e, ao reconstruir o contêiner do Docker, ele estará no cache.Para setup.pypoder ler as dependências dos arquivos requirements.txte requirements.dev.txt, a função está gravada:def load_requirements(fname: str) -> list:
requirements = []
with open(fname, 'r') as fp:
for req in parse_requirements(fp.read()):
extras = '[{}]'.format(','.join(req.extras)) if req.extras else ''
requirements.append(
'{}{}{}'.format(req.name, extras, req.specifier)
)
return requirements
É interessante notar que setuptoolsquando a distribuição fonte montagem padrão inclui apenas os arquivos de montagem .py, .c, .cppe .h. Para um arquivo de dependência requirements.txte requirements.dev.txtbater no saco, eles devem ser claramente especificados no arquivo MANIFEST.in.inteiramente setup.pyimport os
from importlib.machinery import SourceFileLoader
from pkg_resources import parse_requirements
from setuptools import find_packages, setup
module_name = 'analyzer'
module = SourceFileLoader(
module_name, os.path.join(module_name, '__init__.py')
).load_module()
def load_requirements(fname: str) -> list:
requirements = []
with open(fname, 'r') as fp:
for req in parse_requirements(fp.read()):
extras = '[{}]'.format(','.join(req.extras)) if req.extras else ''
requirements.append(
'{}{}{}'.format(req.name, extras, req.specifier)
)
return requirements
setup(
name=module_name,
version=module.__version__,
author=module.__author__,
author_email=module.__email__,
license=module.__license__,
description=module.__doc__,
long_description=open('README.rst').read(),
url='https://github.com/alvassin/backendschool2019',
platforms='all',
classifiers=[
'Intended Audience :: Developers',
'Natural Language :: Russian',
'Operating System :: MacOS',
'Operating System :: POSIX',
'Programming Language :: Python',
'Programming Language :: Python :: 3',
'Programming Language :: Python :: 3.8',
'Programming Language :: Python :: Implementation :: CPython'
],
python_requires='>=3.8',
packages=find_packages(exclude=['tests']),
install_requires=load_requirements('requirements.txt'),
extras_require={'dev': load_requirements('requirements.dev.txt')},
entry_points={
'console_scripts': [
'{0}-api = {0}.api.__main__:main'.format(module_name),
'{0}-db = {0}.db.__main__:main'.format(module_name)
]
},
include_package_data=True
)
Você pode instalar um projeto no modo de desenvolvimento usando o seguinte comando (no modo editável, o Python não instalará o pacote inteiro em uma pasta site-packages, mas apenas criará links, para que quaisquer alterações feitas nos arquivos do pacote sejam visíveis imediatamente):
pip install -e '.[dev]'
pip install -e .
Como especificar versões de dependência?
É ótimo quando os desenvolvedores estão trabalhando ativamente em seus pacotes - os bugs estão sendo ativamente corrigidos, novas funcionalidades aparecem e o feedback pode ser obtido mais rapidamente. Às vezes, porém, as alterações nas bibliotecas dependentes não são compatíveis com versões anteriores e podem levar a erros no seu aplicativo, se você não pensar nisso antes.Para cada pacote dependente, você pode especificar uma versão específica, por exemplo aiohttp==3.6.2. Em seguida, será garantido que o aplicativo seja construído especificamente com as versões das bibliotecas dependentes com as quais foi testado. Mas essa abordagem tem uma desvantagem - se os desenvolvedores corrigirem um bug crítico em um pacote dependente que não afeta a compatibilidade com versões anteriores, essa correção não entra no aplicativo.Existe uma abordagem para o controle de versão Semantic Versioning, o que sugere o envio da versão no formato MAJOR.MINOR.PATCH:MAJOR - aumenta quando são adicionadas alterações incompatíveis com versões anteriores;MINOR - Aumenta ao adicionar nova funcionalidade com suporte para compatibilidade com versões anteriores;PATCH - aumenta ao adicionar correções de erros com suporte à compatibilidade com versões anteriores.
Se um pacote dependente segue esta abordagem (dos quais os autores são geralmente relatados nos arquivos LEIA-ME e changelog), é suficiente para corrigir o valor de MAJOR, MINORe para limitar o valor mínimo para PATCH-versão: >= MAJOR.MINOR.PATCH, == MAJOR.MINOR.*.Esse requisito pode ser implementado usando o operador ~ = . Por exemplo, aiohttp~=3.6.2permitirá que o PIP seja instalado na aiohttpversão 3.6.3, mas não na 3.7.Se você especificar o intervalo de versões de dependência, isso dará mais uma vantagem - não haverá conflitos de versão entre bibliotecas dependentes.Se você estiver desenvolvendo uma biblioteca que exija um pacote de dependência diferente, permita que ela não seja uma versão específica, mas um intervalo. Então será muito mais fácil para os usuários da sua biblioteca usá-la (de repente, o aplicativo deles exige o mesmo pacote de dependência, mas de uma versão diferente).O versionamento semântico é apenas um acordo entre autores e consumidores de pacotes. Não garante que os autores escrevam código sem erros e não possam cometer erros na nova versão do seu pacote.Base de dados
Nós projetamos o esquema
A descrição do manipulador POST / imports fornece um exemplo de descarregamento com informações sobre residentes:Exemplo de Upload{
"citizens": [
{
"citizen_id": 1,
"town": "",
"street": " ",
"building": "1675",
"apartment": 7,
"name": " ",
"birth_date": "26.12.1986",
"gender": "male",
"relatives": [2]
},
{
"citizen_id": 2,
"town": "",
"street": " ",
"building": "1675",
"apartment": 7,
"name": " ",
"birth_date": "01.04.1997",
"gender": "male",
"relatives": [1]
},
{
"citizen_id": 3,
"town": "",
"street": " ",
"building": "2",
"apartment": 11,
"name": " ",
"birth_date": "23.11.1986",
"gender": "female",
"relatives": []
},
...
]
}
O primeiro pensamento foi armazenar todas as informações sobre o residente em uma tabela citizens, onde o relacionamento seria representado por um campo relativesna forma de uma lista de números inteiros .Mas esse método tem várias desvantagensGET /imports/$import_id/citizens/birthdays , , citizens . relatives UNNEST.
, 10- :
SELECT
relations.citizen_id,
relations.relative_id,
date_part('month', relatives.birth_date) as relative_birth_month
FROM (
SELECT
citizens.import_id,
citizens.citizen_id,
UNNEST(citizens.relatives) as relative_id
FROM citizens
WHERE import_id = 1
) as relations
INNER JOIN citizens as relatives ON
relations.import_id = relatives.import_id AND
relations.relative_id = relatives.citizen_id
relatives PostgreSQL, : relatives , . ( ) .
Além disso, decidi trazer todos os dados necessários para o trabalho para uma terceira forma normal e a seguinte estrutura foi obtida:
- A tabela de importações consiste em uma coluna de incremento automático
import_id. É necessário criar uma verificação de chave estrangeira na tabela citizens.
- A tabela de cidadãos armazena dados escalares sobre o residente (todos os campos, exceto informações sobre relacionamentos familiares).
Um par ( import_id, citizen_id) é usado como chave primária , garantindo a exclusividade dos residentes citizen_iddentro da estrutura import_id.
Uma chave estrangeira citizens.import_id -> imports.import_idgarante que o campo citizens.import_idcontenha apenas descargas existentes.
- relations .
( ): citizens relations .
(import_id, citizen_id, relative_id) , import_id citizen_id c relative_id.
: (relations.import_id, relations.citizen_id) -> (citizens.import_id, citizens.citizen_id) (relations.import_id, relations.relative_id) -> (citizens.import_id, citizens.citizen_id), , citizen_id relative_id .
Essa estrutura garante a integridade dos dados usando o PostgreSQL , permite que você obtenha com eficiência residentes com parentes do banco de dados, mas está sujeita a uma condição de corrida ao atualizar informações sobre residentes com consultas competitivas (veremos mais de perto a implementação do manipulador PATCH).Descreva o esquema em SQLAlchemy
No capítulo 5, falei sobre como criar consultas usando SQLAlchemy, você precisa descrever o esquema do banco de dados usando objetos especiais: as tabelas são descritas usando sqlalchemy.Tablee vinculadas a um registro sqlalchemy.MetaDataque armazena todas as metainformações sobre o banco de dados. A propósito, o registro MetaDatapode não apenas armazenar as meta-informações descritas em Python, mas também representar o estado real do banco de dados na forma de objetos SQLAlchemy.Esse recurso também permite que o Alembic compare condições e gere um código de migração automaticamente.A propósito, cada banco de dados tem seu próprio esquema de nomenclatura de restrições padrão. Para que você não perca tempo nomeando novas restrições ou pesquisando / lembrando que restrição está prestes a remover, o SQLAlchemy sugere o uso de padrões de nomeação de convenções de nomenclatura . Eles podem ser definidos no registro MetaData.Crie um registro MetaData e passe padrões de nomenclatura para ele
from sqlalchemy import MetaData
convention = {
'all_column_names': lambda constraint, table: '_'.join([
column.name for column in constraint.columns.values()
]),
'ix': 'ix__%(table_name)s__%(all_column_names)s',
'uq': 'uq__%(table_name)s__%(all_column_names)s',
'ck': 'ck__%(table_name)s__%(constraint_name)s',
'fk': 'fk__%(table_name)s__%(all_column_names)s__%(referred_table_name)s',
'pk': 'pk__%(table_name)s'
}
metadata = MetaData(naming_convention=convention)
Se você especificar padrões de nomeação, o Alembic os utilizará durante a geração automática de migrações e nomeará todas as restrições de acordo com eles. No futuro, o registro criado MetaDataserá necessário para descrever as tabelas:Descrevemos o esquema do banco de dados com objetos SQLAlchemy
from enum import Enum, unique
from sqlalchemy import (
Column, Date, Enum as PgEnum, ForeignKey, ForeignKeyConstraint, Integer,
String, Table
)
@unique
class Gender(Enum):
female = 'female'
male = 'male'
imports_table = Table(
'imports',
metadata,
Column('import_id', Integer, primary_key=True)
)
citizens_table = Table(
'citizens',
metadata,
Column('import_id', Integer, ForeignKey('imports.import_id'),
primary_key=True),
Column('citizen_id', Integer, primary_key=True),
Column('town', String, nullable=False, index=True),
Column('street', String, nullable=False),
Column('building', String, nullable=False),
Column('apartment', Integer, nullable=False),
Column('name', String, nullable=False),
Column('birth_date', Date, nullable=False),
Column('gender', PgEnum(Gender, name='gender'), nullable=False),
)
relations_table = Table(
'relations',
metadata,
Column('import_id', Integer, primary_key=True),
Column('citizen_id', Integer, primary_key=True),
Column('relative_id', Integer, primary_key=True),
ForeignKeyConstraint(
('import_id', 'citizen_id'),
('citizens.import_id', 'citizens.citizen_id')
),
ForeignKeyConstraint(
('import_id', 'relative_id'),
('citizens.import_id', 'citizens.citizen_id')
),
)
Personalizar Alambique
Quando o esquema do banco de dados é descrito, é necessário gerar migrações, mas para isso você precisa primeiro configurar o Alembic, que também é discutido no Capítulo 5 .Para usar o comando alembic, você deve executar as seguintes etapas:- Instalar pacote:
pip install alembic - Inicializar Alambique:
cd analyzer && alembic init db/alembic.
Este comando criará um arquivo de configuração analyzer/alembic.inie uma pasta analyzer/db/alembiccom o seguinte conteúdo:
env.py- Ligado toda vez que você inicia o Alambique. Conecta-se ao registro Alembic sqlalchemy.MetaDatacom uma descrição do estado desejado do banco de dados e contém instruções para iniciar as migrações.
script.py.mako - o modelo com base no qual as migrações são geradas.versions - a pasta na qual o Alembic pesquisará (e gerará) migrações.
- Especifique o endereço do banco de dados no arquivo alembic.ini:
; analyzer/alembic.ini
[alembic]
sqlalchemy.url = postgresql://user:hackme@localhost/analyzer
- Especifique uma descrição do estado desejado do banco de dados (registro
sqlalchemy.MetaData) para que o Alembic possa gerar migrações automaticamente:
from analyzer.db import schema
target_metadata = schema.metadata
O Alembic está configurado e já pode ser usado, mas, no nosso caso, essa configuração tem várias desvantagens:- O utilitário
alembicpesquisa alembic.inino diretório de trabalho atual. Você alembic.inipode especificar o caminho para o argumento da linha de comando, mas isso é inconveniente: desejo poder chamar o comando de qualquer pasta sem parâmetros adicionais. - Para configurar o Alembic para funcionar com um banco de dados específico, você precisa alterar o arquivo
alembic.ini. Seria muito mais conveniente especificar as configurações do banco de dados para a variável de ambiente e / ou um argumento de linha de comando, por exemplo --pg-url. - O nome do utilitário
alembicnão se correlaciona muito bem com o nome do nosso serviço (e o usuário pode realmente não ter o Python e não sabe nada sobre o Alembic). Seria muito mais conveniente para o usuário final se todos os comandos executáveis do serviço tivessem um prefixo comum, por exemplo analyzer-*.
Esses problemas são resolvidos com um pequeno invólucro. analyzer/db/__main__.py:- O Alembic usa um módulo padrão para processar argumentos de linha de comando
argparse. Permite adicionar um argumento opcional --pg-urlcom um valor padrão de uma variável de ambiente ANALYZER_PG_URL.
O códigoimport os
from alembic.config import CommandLine, Config
from analyzer.utils.pg import DEFAULT_PG_URL
def main():
alembic = CommandLine()
alembic.parser.add_argument(
'--pg-url', default=os.getenv('ANALYZER_PG_URL', DEFAULT_PG_URL),
help='Database URL [env var: ANALYZER_PG_URL]'
)
options = alembic.parser.parse_args()
config = Config(file_=options.config, ini_section=options.name,
cmd_opts=options)
config.set_main_option('sqlalchemy.url', options.pg_url)
exit(alembic.run_cmd(config, options))
if __name__ == '__main__':
main()
- O caminho para o arquivo
alembic.inipode ser calculado em relação ao local do arquivo executável, e não ao diretório de trabalho atual do usuário.
O códigoimport os
from alembic.config import CommandLine, Config
from pathlib import Path
PROJECT_PATH = Path(__file__).parent.parent.resolve()
def main():
alembic = CommandLine()
options = alembic.parser.parse_args()
if not os.path.isabs(options.config):
options.config = os.path.join(PROJECT_PATH, options.config)
config = Config(file_=options.config, ini_section=options.name,
cmd_opts=options)
alembic_location = config.get_main_option('script_location')
if not os.path.isabs(alembic_location):
config.set_main_option('script_location',
os.path.join(PROJECT_PATH, alembic_location))
exit(alembic.run_cmd(config, options))
if __name__ == '__main__':
main()
Quando o utilitário para gerenciar o estado do banco de dados está pronto, ele pode ser registrado setup.pycomo um comando executável com um nome compreensível para o usuário final, por exemplo analyzer-db:Registre um comando executável em setup.pyfrom setuptools import setup
setup(..., entry_points={
'console_scripts': [
'analyzer-db = analyzer.db.__main__:main'
]
})
Após a reinstalação do módulo, um arquivo será gerado env/bin/analyzer-dbe o comando analyzer-dbficará disponível:$ pip install -e '.[dev]'
Geramos migrações
Para gerar migrações, são necessários dois estados: o estado desejado (que descrevemos com objetos SQLAlchemy) e o estado real (o banco de dados, no nosso caso, está vazio).Decidi que a maneira mais fácil de gerar o Postgres com o Docker era adicionar um comando make postgresque executa um contêiner com o PostgreSQL na porta 5432 em segundo plano:Levante o PostgreSQL e gere migração$ make postgres
...
$ analyzer-db revision --message="Initial" --autogenerate
INFO [alembic.runtime.migration] Context impl PostgresqlImpl.
INFO [alembic.runtime.migration] Will assume transactional DDL.
INFO [alembic.autogenerate.compare] Detected added table 'imports'
INFO [alembic.autogenerate.compare] Detected added table 'citizens'
INFO [alembic.autogenerate.compare] Detected added index 'ix__citizens__town' on '['town']'
INFO [alembic.autogenerate.compare] Detected added table 'relations'
Generating /Users/alvassin/Work/backendschool2019/analyzer/db/alembic/versions/d5f704ed4610_initial.py ... done
O Alembic geralmente faz um bom trabalho de rotina para gerar migrações, mas eu gostaria de chamar a atenção para o seguinte:- Os tipos de dados do usuário especificados nas tabelas criadas são criados automaticamente (no nosso caso -
gender), mas o código para excluí-los downgradenão é gerado. Se você aplicar, reverter e aplicar a migração novamente, isso causará um erro porque o tipo de dados especificado já existe.
Exclua o tipo de dados de gênero no método de downgradefrom alembic import op
from sqlalchemy import Column, Enum
GenderType = Enum('female', 'male', name='gender')
def upgrade():
...
op.create_table('citizens', ...,
Column('gender', GenderType, nullable=False))
...
def downgrade():
op.drop_table('citizens')
GenderType.drop(op.get_bind())
- No método,
downgradealgumas ações podem às vezes ser removidas (se excluirmos a tabela inteira, você não poderá excluir seus índices separadamente):
por exemplodef downgrade():
op.drop_table('relations')
op.drop_index(op.f('ix__citizens__town'), table_name='citizens')
op.drop_table('citizens')
op.drop_table('imports')
Quando a migração está fixa e pronta, aplicamos:$ analyzer-db upgrade head
INFO [alembic.runtime.migration] Context impl PostgresqlImpl.
INFO [alembic.runtime.migration] Will assume transactional DDL.
INFO [alembic.runtime.migration] Running upgrade -> d5f704ed4610, Initial
inscrição
Antes de começar a criar manipuladores, você deve configurar o aplicativo aiohttp.Se você observar o início rápido do aiohttp, poderá escrever algo como istoimport logging
from aiohttp import web
def main():
logging.basicConfig(level=logging.DEBUG)
app = web.Application()
app.router.add_route(...)
web.run_app(app)
Este código levanta uma série de perguntas e possui várias desvantagens:- Como configurar o aplicativo? No mínimo, você deve especificar o host e a porta para conectar clientes, além de informações para conectar-se ao banco de dados.
Gosto muito de resolver esse problema com a ajuda do módulo ConfigArgParse: ele estende o padrão argparsee permite o uso de argumentos de linha de comando, variáveis de ambiente (indispensáveis para a configuração de contêineres do Docker) e até arquivos de configuração (além de combinar esses métodos) para a configuração. Com ConfigArgParseele, você também pode validar os valores dos parâmetros de configuração do aplicativo.
Um exemplo de processamento de parâmetros usando ConfigArgParsefrom aiohttp import web
from configargparse import ArgumentParser, ArgumentDefaultsHelpFormatter
from analyzer.utils.argparse import positive_int
parser = ArgumentParser(
auto_env_var_prefix='ANALYZER_',
formatter_class=ArgumentDefaultsHelpFormatter
)
parser.add_argument('--api-address', default='0.0.0.0',
help='IPv4/IPv6 address API server would listen on')
parser.add_argument('--api-port', type=positive_int, default=8081,
help='TCP port API server would listen on')
def main():
args = parser.parse_args()
app = web.Application()
web.run_app(app, host=args.api_address, port=args.api_port)
if __name__ == '__main__':
main()
, ConfigArgParse, argparse, ( -h --help). :
$ python __main__.py --help
usage: __main__.py [-h] [--api-address API_ADDRESS] [--api-port API_PORT]
If an arg is specified in more than one place, then commandline values override environment variables which override defaults.
optional arguments:
-h, --help show this help message and exit
--api-address API_ADDRESS
IPv4/IPv6 address API server would listen on [env var: ANALYZER_API_ADDRESS] (default: 0.0.0.0)
--api-port API_PORT TCP port API server would listen on [env var: ANALYZER_API_PORT] (default: 8081)
- — , «» . , .
os.environ.clear(), Python (, asyncio?), , ConfigArgParser.
import os
from typing import Callable
from configargparse import ArgumentParser
from yarl import URL
from analyzer.api.app import create_app
from analyzer.utils.pg import DEFAULT_PG_URL
ENV_VAR_PREFIX = 'ANALYZER_'
parser = ArgumentParser(auto_env_var_prefix=ENV_VAR_PREFIX)
parser.add_argument('--pg-url', type=URL, default=URL(DEFAULT_PG_URL),
help='URL to use to connect to the database')
def clear_environ(rule: Callable):
"""
,
rule
"""
for name in filter(rule, tuple(os.environ)):
os.environ.pop(name)
def main():
args = parser.parse_args()
clear_environ(lambda i: i.startswith(ENV_VAR_PREFIX))
app = create_app(args)
...
if __name__ == '__main__':
main()
- stderr/ .
9 , logging.basicConfig() stderr.
, . aiomisc.
aiomiscimport logging
from aiomisc.log import basic_config
basic_config(logging.DEBUG, buffered=True)
- , ? ,
fork , (, Windows ).
import os
from sys import argv
import forklib
from aiohttp.web import Application, run_app
from aiomisc import bind_socket
from setproctitle import setproctitle
def main():
sock = bind_socket(address='0.0.0.0', port=8081, proto_name='http')
setproctitle(f'[Master] {os.path.basename(argv[0])}')
def worker():
setproctitle(f'[Worker] {os.path.basename(argv[0])}')
app = Application()
run_app(app, sock=sock)
forklib.fork(os.cpu_count(), worker, auto_restart=True)
if __name__ == '__main__':
main()
- - ? , ( — ) ,
nobody. — .
import os
import pwd
from aiohttp.web import run_app
from aiomisc import bind_socket
from analyzer.api.app import create_app
def main():
sock = bind_socket(address='0.0.0.0', port=8085, proto_name='http')
user = pwd.getpwnam('nobody')
os.setgid(user.pw_gid)
os.setuid(user.pw_uid)
app = create_app(...)
run_app(app, sock=sock)
if __name__ == '__main__':
main()
create_app, .
Todas as respostas bem-sucedidas do manipulador serão retornadas no formato JSON. Também seria conveniente que os clientes recebessem informações sobre erros em um formato serializado (por exemplo, para ver quais campos não passaram na validação).A documentação aiohttpoferece um método json_responseque pega um objeto, o serializa em JSON e retorna um novo objeto aiohttp.web.Responsecom um cabeçalho Content-Type: application/jsone dados serializados.Como serializar dados usando json_responsefrom aiohttp.web import Application, View, run_app
from aiohttp.web_response import json_response
class SomeView(View):
async def get(self):
return json_response({'hello': 'world'})
app = Application()
app.router.add_route('*', '/hello', SomeView)
run_app(app)
Mas há outra maneira: o aiohttp permite registrar um serializador arbitrário para um tipo específico de dados de resposta no registro aiohttp.PAYLOAD_REGISTRY. Por exemplo, você pode especificar um serializador aiohttp.JsonPayloadpara objetos do tipo Mapeamento .Neste caso, será suficiente para o manipulador para retornar um objeto Responsecom os dados de resposta no parâmetro body. O aiohttp encontrará um serializador que corresponda ao tipo de dados e serialize a resposta.Além do fato de a serialização de objetos ser descrita em um só lugar, essa abordagem também é mais flexível - permite implementar soluções muito interessantes (consideraremos um dos casos de uso no manipulador GET /imports/$import_id/citizens).Como serializar dados usando aiohttp.PAYLOAD_REGISTRYfrom types import MappingProxyType
from typing import Mapping
from aiohttp import PAYLOAD_REGISTRY, JsonPayload
from aiohttp.web import run_app, Application, Response, View
PAYLOAD_REGISTRY.register(JsonPayload, (Mapping, MappingProxyType))
class SomeView(View):
async def get(self):
return Response(body={'hello': 'world'})
app = Application()
app.router.add_route('*', '/hello', SomeView)
run_app(app)
É importante entender que json_response, assim aiohttp.JsonPayload, eles usam um método padrão json.dumpsque não pode serializar tipos de dados complexos, por exemplo, datetime.dateou asyncpg.Record( asyncpgretorna registros do banco de dados como instâncias desta classe). Além disso, alguns objetos complexos podem conter outros: em um registro do banco de dados pode haver um campo de tipo datetime.date.Os desenvolvedores de Python resolveram esse problema: o método json.dumpspermite que você use o argumento defaultpara especificar uma função que é chamada quando é necessário serializar um objeto desconhecido. A função deve converter um objeto desconhecido em um tipo que pode serializar o módulo json.Como estender o JsonPayload para serializar objetos arbitráriosimport json
from datetime import date
from functools import partial, singledispatch
from typing import Any
from aiohttp.payload import JsonPayload as BaseJsonPayload
from aiohttp.typedefs import JSONEncoder
@singledispatch
def convert(value):
raise NotImplementedError(f'Unserializable value: {value!r}')
@convert.register(Record)
def convert_asyncpg_record(value: Record):
"""
,
asyncpg
"""
return dict(value)
@convert.register(date)
def convert_date(value: date):
"""
date —
.
..
"""
return value.strftime('%d.%m.%Y')
dumps = partial(json.dumps, default=convert)
class JsonPayload(BaseJsonPayload):
def __init__(self,
value: Any,
encoding: str = 'utf-8',
content_type: str = 'application/json',
dumps: JSONEncoder = dumps,
*args: Any,
**kwargs: Any) -> None:
super().__init__(value, encoding, content_type, dumps, *args, **kwargs)
Manipuladores
o aiohttp permite implementar manipuladores com funções e classes assíncronas. As classes são mais extensíveis: em primeiro lugar, o código pertencente a um manipulador pode ser colocado em um único local e, em segundo lugar, as classes permitem que você use a herança para se livrar da duplicação de código (por exemplo, cada manipulador requer uma conexão com o banco de dados).Classe base do manipuladorfrom aiohttp.web_urldispatcher import View
from asyncpgsa import PG
class BaseView(View):
URL_PATH: str
@property
def pg(self) -> PG:
return self.request.app['pg']
Como é difícil ler um arquivo grande, decidi dividir os manipuladores em arquivos. Arquivos pequenos incentivam a conectividade fraca e, se, por exemplo, houver importações de anel dentro de manipuladores, isso significa que algo pode estar errado com a composição das entidades.POST / importações
O manipulador de entrada recebe json com dados sobre residentes. O tamanho máximo permitido da solicitação no aiohttp é controlado pela opção client_max_sizee tem 2 MB por padrão . Se o limite for excedido, aiohttp retornará uma resposta HTTP com o status 413: Solicitar erro muito grande da entidade.Ao mesmo tempo, o json correto com as linhas e os números mais longos pesará ~ 63 megabytes, portanto, as restrições no tamanho da solicitação precisam ser expandidas.Em seguida, você precisa verificar e desserializar os dados . Se estiverem incorretos, você precisará retornar uma resposta HTTP 400: Bad Request.Eu precisava de dois esquemas Marhsmallow. O primeiro CitizenSchema, verifica os dados de cada residente individual e também desserializa a sequência de feliz aniversário no objeto datetime.date:- Tipo de dados, formato e disponibilidade de todos os campos obrigatórios;
- Falta de campos desconhecidos;
- A data de nascimento deve ser indicada no formato
DD.MM.YYYYe não pode ter qualquer significado no futuro; - A lista de parentes de cada residente deve conter identificadores exclusivos de residentes existentes neste upload.
O segundo esquema ImportSchema,, verifica a descarga como um todo:citizen_id cada residente na descarga deve ser único;- Os laços familiares devem ser de mão dupla (se o residente nº 1 tiver um residente nº 2 na lista de parentes, o residente nº 2 também deverá ter um nº 1 relativo).
Se os dados estiverem corretos, eles deverão ser adicionados ao banco de dados com um novo e exclusivo import_id.Para adicionar dados, você precisa executar várias consultas em tabelas diferentes. Para evitar dados parcialmente parcialmente adicionados ao banco de dados em caso de erro ou exceção (por exemplo, ao desconectar um cliente que não recebeu uma resposta completa, o aiohttp lançará uma exceção CancelledError ), você deve usar uma transação .É necessário adicionar dados às tabelas em partes , pois em uma consulta ao PostgreSQL não pode haver mais que 32.767 argumentos. Existem citizens9 campos na tabela . Portanto, para uma consulta, apenas 32.767 / 9 = 3.640 linhas podem ser inseridas nessa tabela e em um upload pode haver até 10.000 habitantes.GET / importações / $ import_id / cidadão
O manipulador retorna todos os residentes para descarregar com o especificado import_id. Se o upload especificado não existir , você deverá retornar a resposta HTTP 404: Não Encontrado. Esse comportamento parece ser comum para manipuladores que precisam de um descarregamento existente, por isso puxei o código de verificação para uma classe separada.Classe base para manipuladores com descarregamentosfrom aiohttp.web_exceptions import HTTPNotFound
from sqlalchemy import select, exists
from analyzer.db.schema import imports_table
class BaseImportView(BaseView):
@property
def import_id(self):
return int(self.request.match_info.get('import_id'))
async def check_import_exists(self):
query = select([
exists().where(imports_table.c.import_id == self.import_id)
])
if not await self.pg.fetchval(query):
raise HTTPNotFound()
Para obter uma lista de parentes para cada residente, você precisará executar LEFT JOINde tabela citizensem tabela relations, agregando o campo relations.relative_idagrupado por import_ide citizen_id.Se o residente não tiver parentes, ele LEFT JOINretornará o relations.relative_idvalor para ele no campo NULLe, como resultado da agregação, a lista de parentes será semelhante [NULL].Para corrigir esse valor incorreto, usei a função array_remove .O banco de dados armazena a data em um formato YYYY-MM-DD, mas precisamos de um formato DD.MM.YYYY.Tecnicamente, você pode formatar a data com uma consulta SQL ou no lado Python no momento de serializar a resposta com json.dumps(asyncpg retorna o valor do campo birth_datecomo uma instância da classedatetime.date)Eu escolhi a serialização no lado do Python, pois ele birth_dateé o único objeto datetime.dateno projeto com um único formato (consulte a seção “Serializando dados” ).Apesar de o processador executar duas solicitações (verificar a existência de uma descarga e uma solicitação de uma lista de residentes), não é necessário usar uma transação . Por padrão, o PostgreSQL usa o nível de isolamento READ COMMITTEDe , mesmo em uma transação, todas as alterações em outras transações concluídas com sucesso serão visíveis (adicionando novas linhas, alterando as existentes).O maior upload em uma exibição de texto pode levar ~ 63 megabytes - isso é bastante, especialmente considerando que várias solicitações para recebimento de dados podem chegar ao mesmo tempo. Existe uma maneira bastante interessante de obter dados do banco de dados usando o cursor e enviá-los ao cliente em partes .Para fazer isso, precisamos implementar dois objetos:- Um objeto de
SelectQuerytipo AsyncIterableque retorna registros do banco de dados. Na primeira chamada, ele se conecta ao banco de dados, abre uma transação e cria um cursor; durante uma iteração adicional, ele retorna registros do banco de dados. É retornado pelo manipulador.
Código SelectQueryfrom collections import AsyncIterable
from asyncpgsa.transactionmanager import ConnectionTransactionContextManager
from sqlalchemy.sql import Select
class SelectQuery(AsyncIterable):
"""
, PostgreSQL
, ,
"""
PREFETCH = 500
__slots__ = (
'query', 'transaction_ctx', 'prefetch', 'timeout'
)
def __init__(self, query: Select,
transaction_ctx: ConnectionTransactionContextManager,
prefetch: int = None,
timeout: float = None):
self.query = query
self.transaction_ctx = transaction_ctx
self.prefetch = prefetch or self.PREFETCH
self.timeout = timeout
async def __aiter__(self):
async with self.transaction_ctx as conn:
cursor = conn.cursor(self.query, prefetch=self.prefetch,
timeout=self.timeout)
async for row in cursor:
yield row
- Um serializador
AsyncGenJSONListPayloadque pode iterar sobre geradores assíncronos, serializar dados de um gerador assíncrono para JSON e enviar dados para clientes em partes. É registrado aiohttp.PAYLOAD_REGISTRYcomo um serializador de objetos AsyncIterable.
Código AsyncGenJSONListPayloadimport json
from functools import partial
from aiohttp import Payload
dumps = partial(json.dumps, default=convert, ensure_ascii=False)
class AsyncGenJSONListPayload(Payload):
"""
AsyncIterable,
JSON
"""
def __init__(self, value, encoding: str = 'utf-8',
content_type: str = 'application/json',
root_object: str = 'data',
*args, **kwargs):
self.root_object = root_object
super().__init__(value, content_type=content_type, encoding=encoding,
*args, **kwargs)
async def write(self, writer):
await writer.write(
('{"%s":[' % self.root_object).encode(self._encoding)
)
first = True
async for row in self._value:
if not first:
await writer.write(b',')
else:
first = False
await writer.write(dumps(row).encode(self._encoding))
await writer.write(b']}')
Além disso, no manipulador, será possível criar um objeto SelectQuery, passar uma consulta SQL e uma função para abrir a transação e retorná-lo para Response body:Código do manipulador
from aiohttp.web_response import Response
from aiohttp_apispec import docs, response_schema
from analyzer.api.schema import CitizensResponseSchema
from analyzer.db.schema import citizens_table as citizens_t
from analyzer.utils.pg import SelectQuery
from .query import CITIZENS_QUERY
from .base import BaseImportView
class CitizensView(BaseImportView):
URL_PATH = r'/imports/{import_id:\d+}/citizens'
@docs(summary=' ')
@response_schema(CitizensResponseSchema())
async def get(self):
await self.check_import_exists()
query = CITIZENS_QUERY.where(
citizens_t.c.import_id == self.import_id
)
body = SelectQuery(query, self.pg.transaction())
return Response(body=body)
aiohttpele detecta um aiohttp.PAYLOAD_REGISTRYserializador registrado AsyncGenJSONListPayloadpara objetos do tipo no registro AsyncIterable. Em seguida, o serializador irá percorrer o objeto SelectQuerye enviar dados para o cliente. Na primeira chamada, o objeto SelectQueryrecebe uma conexão com o banco de dados, abre uma transação e cria um cursor; durante uma iteração adicional, ele recebe dados do banco de dados com o cursor e os retorna linha por linha.Essa abordagem permite não alocar memória para toda a quantidade de dados com cada solicitação, mas tem uma peculiaridade: o aplicativo não poderá retornar o status HTTP correspondente ao cliente se ocorrer um erro (afinal, o status HTTP, os cabeçalhos já foram enviados ao cliente e os dados estão sendo gravados).Quando ocorre uma exceção, não há mais nada a não ser desconectar. Uma exceção, é claro, pode ser protegida, mas o cliente não será capaz de entender exatamente qual erro ocorreu.Por outro lado, uma situação semelhante pode surgir, mesmo que o processador receba todos os dados do banco de dados, mas a rede pisca enquanto transmite dados para o cliente - ninguém está seguro disso.PATCH / importações / $ import_id / cidadão / $ citizen_id
O manipulador recebe o identificador da descarga import_id, o residente citizen_ide o json com os novos dados sobre o residente. No caso de um descarregamento inexistente ou um residente , uma resposta HTTP deve ser retornada 404: Not Found.Os dados transmitidos pelo cliente devem ser verificados e desserializados . Se estiverem incorretos, você deve retornar uma resposta HTTP 400: Bad Request. Eu implementei um esquema de marshmallow PatchCitizenSchemaque verifica:- O tipo e formato dos dados para os campos especificados.
- Data de nascimento. Ele deve ser especificado em um formato
DD.MM.YYYYe não pode ser significativo no futuro. - Uma lista de parentes de cada residente. Ele deve ter identificadores exclusivos para os residentes.
A existência dos parentes indicados no campo relativesnão pode ser verificada separadamente: se um relationsresidente inexistente for adicionado à tabela, o PostgreSQL retornará um erro ForeignKeyViolationErrorque pode ser processado e o status HTTP pode ser retornado 400: Bad Request.Qual status deve ser retornado se o cliente enviar dados incorretos para um residente ou descarregamento inexistente ? É semanticamente mais correto verificar primeiro a existência de um descarregador e um residente (se não houver nenhum, retornar 404: Not Found) e somente depois se o cliente enviou os dados corretos (se não, retornar 400: Bad Request). Na prática, geralmente é mais barato verificar os dados primeiro e, somente se estiverem corretos, acessar o banco de dados.Ambas as opções são aceitáveis, mas decidi escolher uma segunda opção mais barata, pois, em qualquer caso, o resultado da operação é um erro que não afeta nada (o cliente corrige os dados e também descobre que o residente não existe).Se os dados estiverem corretos, é necessário atualizar as informações sobre o residente no banco de dados . No manipulador, você precisará fazer várias consultas para tabelas diferentes. Se ocorrer um erro ou exceção, as alterações no banco de dados devem ser desfeitas, portanto, as consultas devem ser executadas em uma transação .O método PATCH permite transferir apenas alguns campos para um residente.O manipulador deve ser gravado de forma a não falhar ao acessar dados que o cliente não especificou e também não executa consultas em tabelas nas quais os dados não foram alterados.Se o cliente especificou o campo relatives, é necessário obter uma lista de parentes existentes. Se tiver sido alterado, determine quais registros da tabela relativesdevem ser excluídos e quais adicionar, a fim de alinhar o banco de dados com a solicitação do cliente. Por padrão, o PostgreSQL usa isolamento de transação READ COMMITTED. Isso significa que, como parte da transação atual, as alterações serão visíveis aos registros existentes (e novos) de outras transações concluídas. Isso pode levar a uma condição de corrida entre solicitações competitivas .Suponha que haja uma descarga com os residentes#1. #2, #3sem parentesco. O serviço recebe duas solicitações simultâneas para alterar o residente nº 1: {"relatives": [2]}e {"relatives": [3]}. O aiohttp criará dois manipuladores que recebem simultaneamente o estado atual do residente do PostgreSQL.Cada manipulador não detectará um único relacionamento relacionado e decidirá adicionar um novo relacionamento com o parente especificado. Como resultado, o residente nº 1 tem o mesmo campo que os parentes [2,3]. Esse comportamento não pode ser chamado de óbvio. Espera-se duas opções para decidir o resultado da corrida: concluir apenas a primeira solicitação e a segunda retornar uma resposta HTTP
Esse comportamento não pode ser chamado de óbvio. Espera-se duas opções para decidir o resultado da corrida: concluir apenas a primeira solicitação e a segunda retornar uma resposta HTTP409: Conflict(para que o cliente repita a solicitação) ou executar solicitações sucessivamente (a segunda solicitação será processada somente após a conclusão da primeira).A primeira opção pode ser implementada ativando o modo de isolamentoSERIALIZABLE. Se durante o processamento da solicitação alguém já conseguiu alterar e confirmar os dados, uma exceção será lançada, que poderá ser processada e o status HTTP correspondente retornado.A desvantagem desta solução - um grande número de bloqueios no PostgreSQL, SERIALIZABLElançará uma exceção, mesmo que consultas competitivas alterem os registros de residentes de diferentes descarregamentos.Você também pode usar o mecanismo de bloqueio de recomendação . Se você obtiver esse bloqueio import_id, solicitações competitivas para diferentes descarregamentos poderão ser executadas em paralelo.Para processar solicitações competitivas em um upload, você pode implementar o comportamento de qualquer uma das opções: a função pg_try_advisory_xact_locktenta obter um bloqueio eretorna o resultado booleano imediatamente (se não foi possível obter o bloqueio - uma exceção pode ser lançada), mas pg_advisory_xact_lockaguarda até que orecurso fique disponível para bloqueio (nesse caso, as solicitações serão executadas sequencialmente, decidi por essa opção).Como resultado, o manipulador deve retornar as informações atuais sobre o residente atualizado . Foi possível limitar-nos a retornar dados de sua solicitação ao cliente (já que estamos retornando uma resposta ao cliente, isso significa que não houve exceções e todas as solicitações foram concluídas com êxito). Ou - use a palavra-chave RETURNING em consultas que modificam o banco de dados e geram uma resposta a partir dos resultados. Mas essas duas abordagens não nos permitiriam ver e testar o caso com a corrida dos estados.Não havia requisitos de alta carga para o serviço, então decidi solicitar todos os dados sobre o residente novamente e retornar ao cliente um resultado honesto do banco de dados.GET / importações / $ import_id / cidadãos / aniversários
O manipulador calcula o número de presentes que cada residente da descarga receberá de seus parentes (primeira ordem). O número é agrupado por mês para upload com o especificado import_id. No caso de um upload inexistente , uma resposta HTTP deve ser retornada 404: Not Found.Existem duas opções de implementação:- Obtenha dados de residentes com parentes no banco de dados e, no lado do Python, agregue dados por mês e gere listas para os meses para os quais não há dados no banco de dados.
- Compile uma solicitação json no banco de dados e adicione stubs para os meses ausentes.
Eu decidi pela primeira opção - visualmente, parece mais compreensível e suportado. O número de aniversários em um determinado mês pode ser obtido fazendo JOINda tabela com laços familiares ( relations.citizen_id- o residente para quem consideramos o aniversário dos parentes) na tabela citizens(contendo a data de nascimento a partir da qual você deseja obter o mês).Os valores do mês não devem conter zeros à esquerda. O mês obtido do campo birth_dateusando a função date_partpode conter um zero à esquerda. Para removê-lo, eu realizada castpara integerna consulta SQL.Apesar de o manipulador precisar atender a duas solicitações (verifique a existência de descarregamento e obtenha informações sobre aniversários e presentes), uma transação não é necessária .Por padrão, o PostgreSQL usa o modo READ COMMITTED, no qual todos os registros novos (adicionados por outras transações) e os existentes (modificados por outras transações) são visíveis na transação atual depois de concluídos com êxito.Por exemplo, se um novo upload for adicionado no momento do recebimento dos dados, ele não afetará os existentes. Se, no momento do recebimento dos dados, uma solicitação para alterar o residente for atendida, os dados ainda não estarão visíveis (se a transação que está alterando os dados não tiver sido concluída) ou a transação será concluída completamente e todas as alterações serão imediatamente visíveis. A integridade obtida do banco de dados não será violada.GET / importações / $ import_id / cidades / stat / percentil / idade
O manipulador calcula os percentis 50, 75 e 99 das idades (anos completos) de residentes por cidade na amostra com o import_id especificado. No caso de um upload inexistente , uma resposta HTTP deve ser retornada 404: Not Found.Apesar de o processador executar duas solicitações (verificar a existência de descarregamento e obter uma lista de residentes), não é necessário usar uma transação .Existem duas opções de implementação:- Obtenha a idade dos residentes no banco de dados, agrupados por cidade e, em seguida, no lado do Python, calcule os percentis usando numpy (que é especificado como referência na tarefa) e arredonde até duas casas decimais.
- PostgreSQL: percentile_cont , SQL-, numpy .
A segunda opção requer a transferência de menos dados entre o aplicativo e o PostgreSQL, mas não possui uma armadilha muito óbvia: no PostgreSQL, o arredondamento é matemático ( SELECT ROUND(2.5)retornos 3) e, em Python - accounting, para o número inteiro mais próximo ( round(2.5)retornos 2).Para testar o manipulador, a implementação deve ser a mesma no PostgreSQL e no Python (parece mais fácil implementar uma função com arredondamento matemático no Python). Vale ressaltar que, ao calcular percentis, o numpy e o PostgreSQL podem retornar números ligeiramente diferentes, mas, considerando o arredondamento, essa diferença não será perceptível.Teste
O que precisa ser verificado nesta aplicação? Primeiro, que os manipuladores atendam aos requisitos e executem o trabalho necessário em um ambiente o mais próximo possível do ambiente de combate. Em segundo lugar, migrações que alteram o estado do banco de dados funcionam sem erros. Em terceiro lugar, há várias funções auxiliares que também podem ser corretamente cobertas por testes.Decidi usar a estrutura pytest devido à sua flexibilidade e facilidade de uso. Oferece um mecanismo poderoso para preparar o ambiente para testes - equipamentos , isto é, funcionam com um decoradorpytest.mark.fixturecujos nomes podem ser especificados pelo parâmetro no teste. Se o pytest detectar um parâmetro com um nome de aparelho na anotação de teste, ele executará esse aparelho e passará o resultado no valor desse parâmetro. E se o dispositivo elétrico for um gerador, o parâmetro test assumirá o valor retornado yielde, após o término do teste, a segunda parte do dispositivo será executada, o que pode limpar recursos ou fechar conexões.Para a maioria dos testes, precisamos de um banco de dados PostgreSQL. Para isolar testes um do outro, você pode criar um banco de dados separado antes de cada teste e excluí-lo após a execução.Crie um banco de dados de dispositivo elétrico para cada testeimport os
import uuid
import pytest
from sqlalchemy import create_engine
from sqlalchemy_utils import create_database, drop_database
from yarl import URL
from analyzer.utils.pg import DEFAULT_PG_URL
PG_URL = os.getenv('CI_ANALYZER_PG_URL', DEFAULT_PG_URL)
@pytest.fixture
def postgres():
tmp_name = '.'.join([uuid.uuid4().hex, 'pytest'])
tmp_url = str(URL(PG_URL).with_path(tmp_name))
create_database(tmp_url)
try:
yield tmp_url
finally:
drop_database(tmp_url)
def test_db(postgres):
"""
, PostgreSQL
"""
engine = create_engine(postgres)
assert engine.execute('SELECT 1').scalar() == 1
engine.dispose()
O módulo sqlalchemy_utils fez um ótimo trabalho nessa tarefa , levando em consideração os recursos de diferentes bancos de dados e drivers. Por exemplo, o PostgreSQL não permite a execução CREATE DATABASEem um bloco de transação. Ao criar um banco de dados, ele sqlalchemy_utilsconverte psycopg2(que geralmente executa todas as solicitações em uma transação) no modo de confirmação automática.Outra característica importante: se pelo menos um cliente estiver conectado ao PostgreSQL, o banco de dados não poderá ser excluído, mas sqlalchemy_utilsdesconectará todos os clientes antes de excluir o banco de dados. O banco de dados será excluído com êxito, mesmo se algum teste com conexões ativas travar.Precisamos do PostgreSQL em diferentes estados: para testar migrações, precisamos de um banco de dados limpo, enquanto os manipuladores exigem que todas as migrações sejam aplicadas. Você pode alterar programaticamente o estado de um banco de dados usando comandos Alembic, pois eles exigem que o objeto de configuração Alembic os chame.Criar um objeto de configuração de Alambiquefrom types import SimpleNamespace
import pytest
from analyzer.utils.pg import make_alembic_config
@pytest.fixture()
def alembic_config(postgres):
cmd_options = SimpleNamespace(config='alembic.ini', name='alembic',
pg_url=postgres, raiseerr=False, x=None)
return make_alembic_config(cmd_options)
Observe que os aparelhos alembic_configtêm um parâmetro postgres- pytestpermite não apenas indicar a dependência do teste em aparelhos, mas também as dependências entre os aparelhos.Esse mecanismo permite separar de forma flexível a lógica e escrever códigos muito concisos e reutilizáveis.Manipuladores
Os manipuladores de teste requerem um banco de dados com tabelas e tipos de dados criados. Para aplicar migrações, você deve chamar programaticamente o comando upgrade Alembic. Para chamá-lo, você precisa de um objeto com a configuração Alembic, que já definimos com acessórios alembic_config. O banco de dados com migrações parece uma entidade completamente independente e pode ser representado como um dispositivo elétrico:from alembic.command import upgrade
@pytest.fixture
async def migrated_postgres(alembic_config, postgres):
upgrade(alembic_config, 'head')
return postgres
Quando há muitas migrações no projeto, seu aplicativo para cada teste pode levar muito tempo. Para acelerar o processo, você pode criar um banco de dados com migrações uma vez e usá-lo como modelo .Além do banco de dados para testar manipuladores, você precisará de um aplicativo em execução, bem como de um cliente configurado para trabalhar com esse aplicativo. Para facilitar o teste do aplicativo, coloquei sua criação em uma função create_appque utiliza parâmetros para execução: um banco de dados, uma porta para a API REST e outros.Os argumentos para iniciar o aplicativo também podem ser representados como um acessório separado. Para criá-los, você precisará determinar a porta livre para executar o aplicativo de teste e o endereço para o banco de dados temporário migrado.Para determinar a porta livre, usei o equipamento aiomisc_unused_portdo pacote aiomisc.Um equipamento padrão aiohttp_unused_porttambém seria bom, mas retorna uma função para determinar as portas livres, enquanto aiomisc_unused_portretorna imediatamente o número da porta. Para nosso aplicativo, precisamos determinar apenas uma porta livre, por isso decidi não escrever uma linha de código extra com uma chamada aiohttp_unused_port.@pytest.fixture
def arguments(aiomisc_unused_port, migrated_postgres):
return parser.parse_args(
[
'--log-level=debug',
'--api-address=127.0.0.1',
f'--api-port={aiomisc_unused_port}',
f'--pg-url={migrated_postgres}'
]
)
Todos os testes com manipuladores implicam solicitações para a API REST; aiohttpnão é necessário trabalhar diretamente com o aplicativo . Portanto, criei um equipamento que inicia o aplicativo e, usando a fábrica, aiohttp_clientcria e retorna um cliente de teste padrão conectado ao aplicativo aiohttp.test_utils.TestClient.from analyzer.api.app import create_app
@pytest.fixture
async def api_client(aiohttp_client, arguments):
app = create_app(arguments)
client = await aiohttp_client(app, server_kwargs={
'port': arguments.api_port
})
try:
yield client
finally:
await client.close()
Agora, se você especificar o dispositivo elétrico nos parâmetros de teste api_client, o seguinte acontecerá:postgres ( migrated_postgres).alembic_config Alembic, ( migrated_postgres).migrated_postgres ( arguments).aiomisc_unused_port ( arguments).arguments ( api_client).api_client .- .
api_client .postgres .
As luminárias permitem evitar a duplicação de código, mas além de preparar o ambiente nos testes, há outro local em potencial em que haverá muitas das mesmas solicitações de aplicativo de código.Primeiro, ao fazer uma solicitação, esperamos obter um determinado status HTTP. Em segundo lugar, se o status corresponder ao esperado, antes de trabalhar com os dados, é necessário garantir que eles tenham o formato correto. É fácil cometer um erro aqui e escrever um manipulador que faça os cálculos corretos e retorne o resultado correto, mas não passa na validação automática devido ao formato de resposta incorreto (por exemplo, esqueça de envolver a resposta em um dicionário com uma chave data). Todas essas verificações podem ser feitas em um só lugar.No móduloanalyzer.testing Eu preparei para cada manipulador uma função auxiliar que verifica o status do HTTP, bem como o formato de resposta usando o Marshmallow.GET / importações / $ import_id / cidadão
Decidi começar com um manipulador que retorna residentes, porque é muito útil para verificar os resultados de outros manipuladores que alteram o estado do banco de dados.Intencionalmente, não usei código que adiciona dados ao banco de dados do manipulador POST /imports, embora não seja difícil transformá-lo em uma função separada. O código do manipulador tem a propriedade de alterar e, se houver algum erro no código adicionado ao banco de dados, é possível que o teste pare de funcionar como pretendido e implicitamente para os desenvolvedores parem de mostrar erros.Para este teste, defini os seguintes conjuntos de dados de teste:- Descarregando com vários parentes. Verifica se, para cada residente, uma lista com identificadores de parentes será formada corretamente.
- Descarregando com um morador sem parentes. Verifica se o campo
relativesé uma lista vazia (devido LEFT JOINà consulta SQL, a lista de parentes pode ser igual [None]). - Descarregando com um residente que é parente dele mesmo.
- Descarga vazia. Verifica se o manipulador permite adicionar descarregamento vazio e não falha com um erro.
Para executar o mesmo teste separadamente em cada upload, usei outro mecanismo pytest muito poderoso - a parametrização . Esse mecanismo permite agrupar a função de teste no decorador pytest.mark.parametrizee descrever nele quais parâmetros a função de teste deve ter para cada caso de teste individual.Como parametrizar um testeimport pytest
from analyzer.utils.testing import generate_citizen
datasets = [
[
generate_citizen(citizen_id=1, relatives=[2, 3]),
generate_citizen(citizen_id=2, relatives=[1]),
generate_citizen(citizen_id=3, relatives=[1])
],
[
generate_citizen(relatives=[])
],
[
generate_citizen(citizen_id=1, name='', gender='male',
birth_date='17.02.2020', relatives=[1])
],
[],
]
@pytest.mark.parametrize('dataset', datasets)
async def test_get_citizens(api_client, dataset):
"""
4 ,
"""
Portanto, o teste adicionará o upload ao banco de dados e, usando uma solicitação ao manipulador, ele receberá informações sobre os residentes e comparará o upload de referência com o recebido. Mas como você compara os residentes?Cada residente consiste em campos escalares e um campo relatives- uma lista de identificadores de parentes. Uma lista no Python é um tipo ordenado e, ao comparar a ordem dos elementos de cada lista, importa, mas ao comparar listas com irmãos, a ordem não deve importar.Se você trouxer relativespara o conjunto antes da comparação, ao compará-lo, não funcionará para encontrar uma situação em que um dos habitantes do campo relativestenha duplicatas. Se você classificar a lista com os identificadores de parentes, isso contornará o problema de ordem diferente de identificadores de parentes, mas ao mesmo tempo detectará duplicatas.Ao comparar duas listas com residentes, pode-se encontrar um problema semelhante: tecnicamente, a ordem dos residentes na descarga não é importante, mas é importante detectar se há dois residentes com os mesmos identificadores em uma descarga e não na outra. Portanto, além de organizar a lista com parentes, os parentes de cada residente precisam organizar os residentes em cada descarga.Como a tarefa de comparar residentes surgirá mais de uma vez, implementei duas funções: uma para comparar dois residentes e a segunda para comparar duas listas com residentes:Comparar residentesfrom typing import Iterable, Mapping
def normalize_citizen(citizen):
"""
"""
return {**citizen, 'relatives': sorted(citizen['relatives'])}
def compare_citizens(left: Mapping, right: Mapping) -> bool:
"""
"""
return normalize_citizen(left) == normalize_citizen(right)
def compare_citizen_groups(left: Iterable, right: Iterable) -> bool:
"""
,
"""
left = [normalize_citizen(citizen) for citizen in left]
left.sort(key=lambda citizen: citizen['citizen_id'])
right = [normalize_citizen(citizen) for citizen in right]
right.sort(key=lambda citizen: citizen['citizen_id'])
return left == right
Para garantir que esse manipulador não retorne residentes de outras descargas, decidi adicionar uma descarga adicional a um habitante antes de cada teste.POST / importações
Eu defini os seguintes conjuntos de dados para testar o manipulador:- Dados corretos, com expectativa de serem adicionados com sucesso ao banco de dados.
- ( ).
. , , insert , . - ( , ).
, .
- .
, . :)
, aiohttp PostgreSQL 32 767 ( ).
- Descarga vazia
O manipulador deve levar em consideração esse caso e não cair, tentando executar uma inserção vazia na tabela com os habitantes.
- Dados com erros, espere uma resposta HTTP 400: Solicitação incorreta.
- A data de nascimento está incorreta (futuro).
- citizen_id não é exclusivo no upload.
- Um parentesco é indicado incorretamente (existe apenas de um residente para outro, mas não há feedback).
- O residente tem um parente inexistente na descarga.
- Os laços familiares não são únicos.
Se o processador funcionou com sucesso e os dados foram adicionados, é necessário adicionar os residentes ao banco de dados e compará-los com o descarregamento padrão. Para obter residentes, usei o manipulador já testado GET /imports/$import_id/citizense, para comparação, uma função compare_citizen_groups.PATCH / importações / $ import_id / cidadão / $ citizen_id
A validação dos dados é, de várias maneiras, semelhante à descrita no manipulador, POST /importscom algumas exceções: existe apenas um residente e o cliente pode passar apenas os campos que ele deseja .Decidi usar os seguintes conjuntos com dados incorretos para verificar se o manipulador retornará uma resposta HTTP 400: Bad request:- O campo está especificado, mas possui um tipo e / ou formato de dados incorretos
- A data de nascimento está incorreta (hora futura).
- O campo
relativescontém um parente que não existe na descarga.
Também é necessário verificar se o manipulador atualiza corretamente as informações sobre o residente e seus parentes.Para fazer isso, crie um upload com três habitantes, dois dos quais são parentes, e envie uma solicitação com novos valores para todos os campos escalares e um novo identificador relativo no campo relatives.Para garantir que o manipulador faça a distinção entre residentes de descarregamentos diferentes antes do teste (e, por exemplo, não altere residentes com os mesmos identificadores de outro descarregamento), criei um descarregamento adicional com três residentes com os mesmos identificadores.O manipulador deve salvar os novos valores dos campos escalares, adicionar um novo parente especificado e remover o relacionamento com um parente antigo não especificado. Todas as mudanças no parentesco devem ser bilaterais. Não deve haver alterações em outras descargas.Como esse manipulador pode estar sujeito às condições de corrida (isso foi discutido na seção Desenvolvimento), adicionei dois testes adicionais . Um reproduz o problema com o estado da corrida (estende a classe do manipulador e remove a trava), o segundo prova que o problema com o estado da corrida não é reproduzido.GET / importações / $ import_id / cidadãos / aniversários
Para testar esse manipulador, selecionei os seguintes conjuntos de dados:- Uma descarga na qual um residente tem um parente em um mês e dois parentes em outro.
- Descarregando com um morador sem parentes. Verifica se o manipulador não leva isso em consideração nos cálculos.
- Descarga vazia. Verifica se o manipulador não falhará e retornará o dicionário correto com 12 meses na resposta.
- Descarregando com um residente que é parente dele mesmo. Verifica se um residente comprará um presente para o mês de seu nascimento.
O manipulador deve retornar todos os meses na resposta, mesmo se não houver aniversários nesses meses. Para evitar duplicação, criei uma função para a qual você pode passar o dicionário para complementá-lo com valores para meses ausentes.Para garantir que o manipulador faça a distinção entre residentes de descarregamentos diferentes, adicionei um descarregamento adicional com dois parentes. Se o manipulador os usar erroneamente nos cálculos, os resultados estarão incorretos e o manipulador cairá com um erro.GET / importações / $ import_id / cidades / stat / percentil / idade
A peculiaridade desse teste é que os resultados de seu trabalho dependem da hora atual: a idade dos habitantes é calculada com base na data atual. Para garantir que os resultados do teste não sejam alterados ao longo do tempo, a data atual, as datas de nascimento dos residentes e os resultados esperados devem ser registrados. Isso facilitará a reprodução de casos até iguais.Qual é a melhor data de correção? O manipulador usa a função PostgreSQL para calcular a idade dos residentes AGE, que assume o primeiro parâmetro como a data para a qual é necessário calcular a idade e o segundo como a data base (definida por uma constante TownAgeStatView.CURRENT_DATE).Substituímos a data base no manipulador pelo tempo de testefrom unittest.mock import patch
import pytz
CURRENT_DATE = datetime(2020, 2, 17, tzinfo=pytz.utc)
@patch('analyzer.api.handlers.TownAgeStatView.CURRENT_DATE', new=CURRENT_DATE)
async def test_get_ages(...):
...
Para testar o manipulador, selecionei os seguintes conjuntos de dados (para todos os residentes, indiquei uma cidade, porque o manipulador agrega os resultados por cidade):- , ( — 364 ). , .
- , ( — ). — , , 1 .
- . .
A numpyreferência para o cálculo de percentis - com interpolação linear e os resultados da referência para o teste que eu calculei para eles.Você também precisa arredondar os valores do percentil fracionário para duas casas decimais. Se você usou o PostgreSQL para arredondar no manipulador e o Python para calcular os dados de referência, pode notar que o arredondamento no Python 3 e no PostgreSQL pode fornecer resultados diferentes .por exemplo# Python 3
round(2.5)
> 2
-- PostgreSQL
SELECT ROUND(2.5)
> 3
O fato é que o Python usa arredondamento de banco para o par mais próximo e o PostgreSQL usa matemática (metade). Caso os cálculos e arredondamentos sejam realizados no PostgreSQL, seria correto usar o arredondamento matemático também nos testes.No começo, descrevi conjuntos de dados com datas de nascimento em formato de texto, mas era inconveniente ler um teste nesse formato: cada vez que eu precisava calcular a idade de cada habitante em minha mente para lembrar o que um conjunto de dados específico estava verificando. É claro que você pode se dar bem com os comentários no código, mas decidi ir um pouco mais longe e escrevi uma função age2dateque permite descrever a data de nascimento na forma de idade: o número de anos e dias.Por exemplo, assimimport pytz
from analyzer.utils.testing import generate_citizen
CURRENT_DATE = datetime(2020, 2, 17, tzinfo=pytz.utc)
def age2date(years: int, days: int = 0, base_date=CURRENT_DATE) -> str:
birth_date = copy(base_date).replace(year=base_date.year - years)
birth_date -= timedelta(days=days)
return birth_date.strftime(BIRTH_DATE_FORMAT)
generate_citizen(birth_date='17.02.2009')
generate_citizen(birth_date=age2date(years=11))
Para garantir que o manipulador faça a distinção entre residentes de descarregamentos diferentes, adicionei um descarregamento adicional a um residente de outra cidade: se o manipulador o usar por engano, uma cidade extra aparecerá nos resultados e o teste será interrompido.Um fato interessante: quando eu escrevi esse teste em 29 de fevereiro de 2020, de repente parei de gerar descargas com moradores devido a um bug no Faker (2020 é um ano bissexto, e outros anos que Faker escolheu nem sempre foram bissextos também) não era 29 de fevereiro). Lembre-se de registrar datas e testar casos de ponta!
Migrações
À primeira vista, o código de migração parece óbvio e menos propenso a erros. Por que testá-lo? É um erro muito perigoso: os erros mais insidiosos das migrações podem se manifestar no momento mais inoportuno. Mesmo que eles não estraguem os dados, eles podem causar tempo de inatividade desnecessário.A migração inicial existente no projeto altera a estrutura do banco de dados, mas não altera os dados. Quais erros comuns podem ser protegidos contra essas migrações?downgrade ( , , ).
, (--): , — .
- C .
- ( ).
A maioria desses erros será detectada pelo teste da escada . Sua idéia - para usar uma única migração, consistentemente realizar os modos upgrade, downgrade, upgradepara cada migração. Esse teste é suficiente para ser adicionado ao projeto uma vez, não requer apoio e será fiel.Mas se a migração, além da estrutura, alterasse os dados, seria necessário escrever pelo menos um teste separado, verificando se os dados mudam corretamente no método upgradee retornam ao estado inicial em downgrade. Apenas no caso: um projeto com exemplos de teste de diferentes migrações , que eu preparei para um relatório sobre Alambique no Moscow Python.Montagem
O artefato final que vamos implantar e que queremos obter como resultado da montagem é uma imagem do Docker. Para construir, você deve selecionar a imagem base com o Python. A imagem oficial python:latestpesa ~ 1 GB e, se usada como imagem de base, a imagem com o aplicativo será enorme. Existem imagens baseadas no Alpine OS , cujo tamanho é muito menor. Porém, com um número crescente de pacotes instalados, o tamanho da imagem final aumentará e, como resultado, mesmo a imagem coletada com base no Alpine não será tão pequena. Eu escolhi o snakepacker / python como a imagem base - ele pesa um pouco mais do que as imagens alpinas, mas é baseado no Ubuntu, que oferece uma grande variedade de pacotes e bibliotecas.Outra maneirareduza o tamanho da imagem com o aplicativo - não inclua na imagem final o compilador, bibliotecas e arquivos com cabeçalhos para a montagem, que não são necessários para o funcionamento do aplicativo.Para fazer isso, você pode usar o conjunto de várias etapas do Docker:- Usando uma imagem "pesada"
snakepacker/python:all(~ 1 GB, ~ 500 MB compactado), crie um ambiente virtual, instale todas as dependências e o pacote de aplicativos nele. Esta imagem é necessária exclusivamente para montagem, pode conter um compilador, todas as bibliotecas e arquivos necessários com cabeçalhos.
FROM snakepacker/python:all as builder
RUN python3.8 -m venv /usr/share/python3/app
COPY dist/ /mnt/dist/
RUN /usr/share/python3/app/bin/pip install /mnt/dist/*
- Copiamos o ambiente virtual finalizado em uma imagem "leve"
snakepacker/python:3.8(~ 100 MB, compactada ~ 50 MB), que contém apenas o intérprete da versão exigida do Python.
Importante: em um ambiente virtual, caminhos absolutos são usados, portanto, eles devem ser copiados para o mesmo endereço em que foram montados no contêiner do coletor.
FROM snakepacker/python:3.8 as api
COPY --from=builder /usr/share/python3/app /usr/share/python3/app
RUN ln -snf /usr/share/python3/app/bin/analyzer-* /usr/local/bin/
CMD ["analyzer-api"]
Para reduzir o tempo necessário para construir a imagem , os módulos dependentes do aplicativo podem ser instalados antes de serem instalados no ambiente virtual. O Docker os armazenará em cache e não será reinstalado se não tiverem sido alterados.Dockerfile inteiramente
FROM snakepacker/python:all as builder
RUN python3.8 -m venv /usr/share/python3/app
RUN /usr/share/python3/app/bin/pip install -U pip
COPY requirements.txt /mnt/
RUN /usr/share/python3/app/bin/pip install -Ur /mnt/requirements.txt
COPY dist/ /mnt/dist/
RUN /usr/share/python3/app/bin/pip install /mnt/dist/* \
&& /usr/share/python3/app/bin/pip check
FROM snakepacker/python:3.8 as api
COPY --from=builder /usr/share/python3/app /usr/share/python3/app
RUN ln -snf /usr/share/python3/app/bin/analyzer-* /usr/local/bin/
CMD ["analyzer-api"]
Para facilitar a montagem, adicionei um comando make uploadque coleta a imagem do Docker e a carrega no hub.docker.com.Ci
Agora que o código está coberto de testes e podemos criar uma imagem do Docker, é hora de automatizar esses processos. A primeira coisa que vem à mente: execute testes para criar solicitações de pool e, ao adicionar alterações na ramificação principal, colete uma nova imagem do Docker e faça o upload para o Docker Hub (ou Pacotes do GitHub , se você não distribuir a imagem publicamente).Resolvi esse problema com as ações do GitHub . Para isso, foi necessário criar um arquivo YAML em uma pasta .github/workflowse descrever nele um fluxo de trabalho (com duas tarefas: teste publish), que eu nomeei CI.A tarefa testé executada sempre que o fluxo de trabalho é iniciado CI, usando serviçospega um contêiner com o PostgreSQL, espera que ele fique disponível e é iniciado pytestno contêiner snakepacker/python:all.A tarefa publishé executada apenas se as alterações foram adicionadas à ramificação mastere se a tarefa testfoi bem-sucedida. Ele coleta a distribuição de origem pelo contêiner snakepacker/python:all, depois coleta e carrega a imagem do Docker docker/build-push-action@v1.Descrição completa do fluxo de trabalhoname: CI
# Workflow
# - master
on:
push:
branches: [ master ]
pull_request:
branches: [ master ]
jobs:
# workflow
test:
runs-on: ubuntu-latest
services:
postgres:
image: docker://postgres
ports:
- 5432:5432
env:
POSTGRES_USER: user
POSTGRES_PASSWORD: hackme
POSTGRES_DB: analyzer
steps:
- uses: actions/checkout@v2
- name: test
uses: docker://snakepacker/python:all
env:
CI_ANALYZER_PG_URL: postgresql://user:hackme@postgres/analyzer
with:
args: /bin/bash -c "pip install -U '.[dev]' && pylama && wait-for-port postgres:5432 && pytest -vv --cov=analyzer --cov-report=term-missing tests"
# Docker-
publish:
# master
if: github.event_name == 'push' && github.ref == 'refs/heads/master'
# , test
needs: test
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: sdist
uses: docker://snakepacker/python:all
with:
args: make sdist
- name: build-push
uses: docker/build-push-action@v1
with:
username: ${{ secrets.REGISTRY_LOGIN }}
password: ${{ secrets.REGISTRY_TOKEN }}
repository: alvassin/backendschool2019
target: api
tags: 0.0.1, latest
Agora, ao adicionar alterações ao mestre na guia Ações no GitHub, você pode ver o início dos testes, a montagem e o carregamento da imagem do Docker: E ao criar uma solicitação de pool na ramificação mestre, os resultados da tarefa também serão exibidos
E ao criar uma solicitação de pool na ramificação mestre, os resultados da tarefa também serão exibidos test:
Implantar
Para implantar o aplicativo no servidor fornecido, é necessário instalar o Docker, Docker Compose, iniciar os contêineres com o aplicativo e o PostgreSQL e aplicar as migrações.Essas etapas podem ser automatizadas usando o sistema de gerenciamento de configuração da Ansible. Está escrito em Python, não requer agentes especiais (se conecta diretamente via ssh), usa modelos jinja e permite descrever declarativamente o estado desejado nos arquivos YAML. A abordagem declarativa permite que você não pense no estado atual do sistema e nas ações necessárias para levar o sistema ao estado desejado. Todo esse trabalho repousa sobre os ombros dos módulos Ansible.O Ansible permite agrupar tarefas relacionadas logicamente em funções e reutilizá-las. Vamos precisar de dois papéis:docker(instala e configura o Docker) e analyzer(instala e configura o aplicativo).A funçãodocker adiciona um repositório com o Docker ao sistema, instala e configura pacotes docker-cee docker-compose.Opcionalmente, você pode definir a API REST para reiniciar automaticamente após a reinicialização do servidor. O Ubuntu permite que você resolva esse problema com a ajuda de um sistema de inicialização systemd. Ele controla unidades que representam vários recursos (daemons, soquetes, pontos de montagem e outros). Para adicionar uma nova unidade ao systemd, você deve descrever sua configuração em um arquivo .service separado e colocar esse arquivo em uma das pastas especiais, por exemplo, em /etc/systemd/system. Em seguida, a unidade pode ser lançada e ativar o carregamento automático para ela.Pacotedocker-cedurante a instalação, ele criará automaticamente um arquivo com a configuração da unidade - você só precisa garantir que esteja em execução e ligado quando o sistema for iniciado. Para o Docker Compose docker-compose@.serviceserá criado pelo Ansible. O símbolo @no nome indica ao sistema que a unidade é um modelo. Isso permite que você inicie o serviço docker-composecom um parâmetro - por exemplo, com o nome do nosso serviço, que será substituído em vez de %ino arquivo de configuração da unidade:[Unit]
Description=%i service with docker compose
Requires=docker.service
After=docker.service
[Service]
Type=oneshot
RemainAfterExit=true
WorkingDirectory=/etc/docker/compose/%i
ExecStart=/usr/local/bin/docker-compose up -d --remove-orphans
ExecStop=/usr/local/bin/docker-compose down
[Install]
WantedBy=multi-user.target
A funçãoanalyzer gerará um arquivo a partir do modelo docker-compose.ymlno endereço /etc/docker/compose/analyzer, registrará o aplicativo como um serviço iniciado automaticamente systemde aplicará a migração. Quando as funções estiverem prontas, você precisará descrever o manual.---
- name: Gathering facts
hosts: all
become: yes
gather_facts: yes
- name: Install docker
hosts: docker
become: yes
gather_facts: no
roles:
- docker
- name: Install analyzer
hosts: api
become: yes
gather_facts: no
roles:
- analyzer
A lista de hosts, bem como as variáveis usadas nas funções, podem ser especificadas no arquivo de inventário hosts.ini.[api]
130.193.51.154
[docker:children]
api
[api:vars]
analyzer_image = alvassin/backendschool2019
analyzer_pg_user = user
analyzer_pg_password = hackme
analyzer_pg_dbname = analyzer
Depois que todos os arquivos Ansible estiverem prontos, execute-o:$ ansible-playbook -i hosts.ini deploy.yml
Sobre o teste de estresse, , . , -
. : , — , 10 . , (, , CI-): .
, , , 10 . ? , , . , , .
RPS, : . , ,
import_id,
POST /imports . .
, Python 3,
Locust.
,
locustfile.py locust. - .
Locust . , .
self.round .
locustfile.py
import logging
from http import HTTPStatus
from locust import HttpLocust, constant, task, TaskSet
from locust.exception import RescheduleTask
from analyzer.api.handlers import (
CitizenBirthdaysView, CitizensView, CitizenView, TownAgeStatView
)
from analyzer.utils.testing import generate_citizen, generate_citizens, url_for
class AnalyzerTaskSet(TaskSet):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.round = 0
def make_dataset(self):
citizens = [
generate_citizen(citizen_id=1, relatives=[2]),
generate_citizen(citizen_id=2, relatives=[1]),
*generate_citizens(citizens_num=9998, relations_num=1000,
start_citizen_id=3)
]
return {citizen['citizen_id']: citizen for citizen in citizens}
def request(self, method, path, expected_status, **kwargs):
with self.client.request(
method, path, catch_response=True, **kwargs
) as resp:
if resp.status_code != expected_status:
resp.failure(f'expected status {expected_status}, '
f'got {resp.status_code}')
logging.info(
'round %r: %s %s, http status %d (expected %d), took %rs',
self.round, method, path, resp.status_code, expected_status,
resp.elapsed.total_seconds()
)
return resp
def create_import(self, dataset):
resp = self.request('POST', '/imports', HTTPStatus.CREATED,
json={'citizens': list(dataset.values())})
if resp.status_code != HTTPStatus.CREATED:
raise RescheduleTask
return resp.json()['data']['import_id']
def get_citizens(self, import_id):
url = url_for(CitizensView.URL_PATH, import_id=import_id)
self.request('GET', url, HTTPStatus.OK,
name='/imports/{import_id}/citizens')
def update_citizen(self, import_id):
url = url_for(CitizenView.URL_PATH, import_id=import_id, citizen_id=1)
self.request('PATCH', url, HTTPStatus.OK,
name='/imports/{import_id}/citizens/{citizen_id}',
json={'relatives': [i for i in range(3, 10)]})
def get_birthdays(self, import_id):
url = url_for(CitizenBirthdaysView.URL_PATH, import_id=import_id)
self.request('GET', url, HTTPStatus.OK,
name='/imports/{import_id}/citizens/birthdays')
def get_town_stats(self, import_id):
url = url_for(TownAgeStatView.URL_PATH, import_id=import_id)
self.request('GET', url, HTTPStatus.OK,
name='/imports/{import_id}/towns/stat/percentile/age')
@task
def workflow(self):
self.round += 1
dataset = self.make_dataset()
import_id = self.create_import(dataset)
self.get_citizens(import_id)
self.update_citizen(import_id)
self.get_birthdays(import_id)
self.get_town_stats(import_id)
class WebsiteUser(HttpLocust):
task_set = AnalyzerTaskSet
wait_time = constant(1)
100 c , , :

, ( — 95 , — ). .

— Ansible ~20.15 ~20.30 Locust.

O que mais pode ser feito?
A criação de perfil do aplicativo mostrou que cerca de um quarto do tempo total de execução da consulta é gasto na serialização e desserialização de JSON: há muitos dados enviados e recebidos do serviço. Esses processos podem ser significativamente acelerados usando a biblioteca orjson , mas o serviço precisará ser preparado um pouco - orjsonnão é um substituto para o módulo jsonpadrão.Em geral, a produção requer várias cópias do serviço para garantir a tolerância a falhas e lidar com a carga. Para gerenciar um grupo de serviços, você precisa de uma ferramenta que mostre se uma cópia do serviço está "ativa". Esse problema pode ser resolvido por um manipulador /healthque pesquisa todos os recursos necessários para o trabalho, no nosso caso, um banco de dados. E seSELECT 1executado em menos de um segundo, o serviço está ativo. Caso contrário, você precisa prestar atenção.Quando um aplicativo trabalha intensivamente com uma rede, o uvloop pode aumentar de maneira interessante o desempenho.Um fator importante é a legibilidade do código. Um dos meus colegas, Yuri Shikanov, escreveu um módulo cinza que combina várias ferramentas para verificação e execução automáticas de código, fáceis de adicionar a um pre-commitgancho Git, configurado com um único arquivo de configuração ou variáveis de ambiente. Gray permite classificar importações ( isort ), otimiza expressões python de acordo com as novas versões da linguagem ( pyupgrade ), adiciona vírgulas no final das chamadas de função, importações, listas, etc. (add-trailing-vírgula ) e também aspas para um único formulário ( unificar ).* * *
Isso é tudo para mim: desenvolvemos, cobertos com testes, montamos e implantamos o serviço e também realizamos testes de carga.Agradecimentos
Gostaria de expressar minha profunda gratidão aos rapazes que se dedicaram a escrever este artigo, revisar o código, apresentar minhas idéias e comentários: a Maria Zelenova zelmaVladimir Solomatin leenrAnastasia Semenova morkovYuri Shikanov dizballanzeMikhail Shushpanov mishushPavel Mosein pavkazzz e especialmente para Dmitry Orlov orlovdl.