A computação paralela fascina com a inesperada de seu comportamento. Mas o comportamento conjunto dos processos não pode ser imprevisível. Somente nesse caso ele pode ser estudado e compreendido em suas peculiaridades. A simultaneidade multithread moderna é única. No sentido literal. E essa é toda a sua essência ruim . A essência que pode e deve ser influenciada. A essência, que deve, em boa medida, ter sido alterada há muito tempo ...Embora exista outra opção. Não há necessidade de mudar nada e / ou influenciar algo. Que haja multithreading e coroutines, que seja ... e programação automática paralela (AP). Deixe-os competir e, quando necessário e possível, se complementem. Nesse sentido, o paralelismo moderno possui pelo menos uma vantagem - permite que você faça isso.Bem, vamos competir!?1. De serial para paralelo
Considere programar a equação aritmética mais simples:C2 = A + B + A1 + B1; (1)Haja blocos que implementem operações aritméticas simples. Nesse caso, os blocos de soma são suficientes. Uma ideia clara e precisa do número de blocos, sua estrutura e as relações entre eles fornece arroz. 1. E na Fig. 2. a configuração do meio VKP (a) é dada para resolver a equação (1).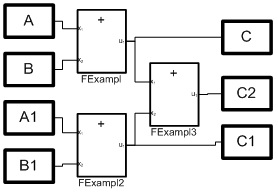 Figura 1. Modelo estrutural de processosMas o diagrama estrutural da Fig. 1 corresponde a um sistema de três equações:= A + B;C1 = A1 + B; (2)C2 = C + C1;Ao mesmo tempo (2), esta é uma implementação paralela da equação (1), que é um algoritmo para somar uma matriz de números, também conhecido como algoritmo de duplicação. Aqui a matriz é representada por quatro números A, B, A1, B1, as variáveis C e C1 são resultados intermediários e C2 é a soma da matriz.
Figura 1. Modelo estrutural de processosMas o diagrama estrutural da Fig. 1 corresponde a um sistema de três equações:= A + B;C1 = A1 + B; (2)C2 = C + C1;Ao mesmo tempo (2), esta é uma implementação paralela da equação (1), que é um algoritmo para somar uma matriz de números, também conhecido como algoritmo de duplicação. Aqui a matriz é representada por quatro números A, B, A1, B1, as variáveis C e C1 são resultados intermediários e C2 é a soma da matriz.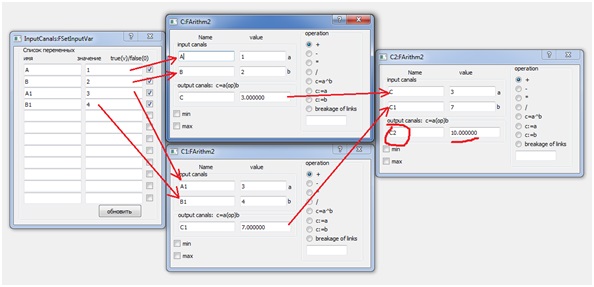 Figura 2. Tipo de diálogos para a configuração de três processos paralelos.Os
Figura 2. Tipo de diálogos para a configuração de três processos paralelos.Os
recursos de implementação incluem a continuidade de sua operação, quando qualquer alteração nos dados de entrada leva a uma recontagem do resultado. Após alterar os dados de entrada, serão necessários dois ciclos de clock e, quando os blocos forem conectados em série, o mesmo efeito será alcançado em três ciclos de clock. E quanto maior a matriz, maior o ganho de velocidade.2. Concorrência como um problema
Não se surpreenda se você for chamado de muitos argumentos em favor de uma ou outra solução paralela, mas ao mesmo tempo eles ficarão em silêncio sobre possíveis problemas que estão completamente ausentes na programação seqüencial comum. A principal razão para a interpretação semelhante do problema da implementação correta do paralelismo. Eles dizem o mínimo sobre ela. Se é que eles dizem. Entraremos em contato com ele na parte relacionada ao acesso paralelo aos dados.Qualquer processo pode ser representado como muitas etapas indivisíveis consecutivas. Para muitos processos, em cada uma dessas etapas, as ações pertencentes a todos os processos são executadas simultaneamente. E aqui podemos encontrar um problema que se manifesta no seguinte exemplo elementar.Suponha que existem dois processos paralelos que correspondem ao seguinte sistema de equações:c = a + b; (3)a = b + c;Suponha que as variáveis a, b, c tenham os valores iniciais 1, 1, 0. Podemos esperar que o protocolo de cálculo para as cinco etapas seja o seguinte:a b c
1.000 1.000 0.000
1.000 1.000 2.000
3.000 1.000 2.000
3.000 1.000 4.000
5.000 1.000 4.000
5.000 1.000 6.000
Ao formá-lo, partimos do fato de que os operadores são executados em paralelo (simultaneamente) e dentro de uma medida discreta (etapa). Para instruções em loop, será uma iteração do loop. Também podemos assumir que, no processo de cálculos, as variáveis têm valores fixados no início de uma medida discreta, e suas alterações ocorrem no final. Isso é bastante consistente com a situação real, quando leva algum tempo para concluir a operação. É frequentemente associado a um atraso inerente a um determinado bloco.Mas, provavelmente, você obterá algo como este protocolo: a b c
1.000 1.000 0.000
3.000 1.000 2.000
5.000 1.000 4.000
7.000 1.000 6.000
9.000 1.000 8.000
11.000 1.000 10.000
É equivalente ao trabalho de um processo executando duas instruções consecutivas em um ciclo:c = a + b; a = b + c; (4)Mas pode acontecer que a execução das instruções seja exatamente o oposto e, em seguida, o protocolo seja o seguinte: a b c
1.000 1.000 0.000
1.000 1.000 2.000
3.000 1.000 4.000
5.000 1.000 6.000
7.000 1.000 8.000
9.000 1.000 10.000
Na programação multithread, a situação é ainda pior. Na ausência de sincronização de processos, não é apenas difícil prever a sequência de inicialização dos operadores, mas seu trabalho também será interrompido em qualquer lugar. Tudo isso não pode deixar de afetar os resultados do trabalho conjunto dos operadores.Dentro da estrutura da tecnologia AP, o trabalho com variáveis de processo comuns é permitido de maneira simples e correta. Aqui, na maioria das vezes, não são necessários esforços especiais para sincronizar processos e trabalhar com dados. Mas será necessário destacar ações que serão consideradas condicionalmente instantâneas e indivisíveis, além de criar modelos de processos automáticos. No nosso caso, as ações serão operadores de soma e os autômatos com transições cíclicas serão responsáveis por seu lançamento.A Listagem 1 mostra o código para um processo que implementa a operação de soma. Seu modelo é uma máquina de estados finitos (ver Fig. 3) com um estado e uma transição de loop incondicional, para a qual a única ação y1, tendo realizado a operação de somar duas variáveis, coloca o resultado na terceira. Fig. 3. Modelo automatizado da operação de somatório
Fig. 3. Modelo automatizado da operação de somatórioListagem 1. Implementação de um processo de autômato para uma operação de soma#include "lfsaappl.h"
class FSumABC :
public LFsaAppl
{
public:
LFsaAppl* Create(CVarFSA *pCVF) { Q_UNUSED(pCVF)return new FSumABC(nameFsa); }
bool FCreationOfLinksForVariables();
FSumABC(string strNam);
CVar *pVarA;
CVar *pVarB;
CVar *pVarC;
CVar *pVarStrNameA;
CVar *pVarStrNameB;
CVar *pVarStrNameC;
protected:
void y1();
};
#include "stdafx.h"
#include "FSumABC.h"
static LArc TBL_SumABC[] = {
LArc("s1", "s1","--", "y1"),
LArc()
};
FSumABC::FSumABC(string strNam):
LFsaAppl(TBL_SumABC, strNam, nullptr, nullptr)
{ }
bool FSumABC::FCreationOfLinksForVariables() {
pVarA = CreateLocVar("a", CLocVar::vtBool, "variable a");
pVarB = CreateLocVar("b", CLocVar::vtBool, "variable c");
pVarC = CreateLocVar("c", CLocVar::vtBool, "variable c");
pVarStrNameA = CreateLocVar("strNameA", CLocVar::vtString, "");
string str = pVarStrNameA->strGetDataSrc();
if (str != "") { pVarA = pTAppCore->GetAddressVar(pVarStrNameA->strGetDataSrc().c_str(), this); }
pVarStrNameB = CreateLocVar("strNameB", CLocVar::vtString, "");
str = pVarStrNameB->strGetDataSrc();
if (str != "") { pVarB = pTAppCore->GetAddressVar(pVarStrNameB->strGetDataSrc().c_str(), this); }
pVarStrNameC = CreateLocVar("strNameC", CLocVar::vtString, "");
str = pVarStrNameC->strGetDataSrc();
if (str != "") { pVarC = pTAppCore->GetAddressVar(pVarStrNameC->strGetDataSrc().c_str(), this); }
return true;
}
void FSumABC::y1() {
pVarC->SetDataSrc(this, pVarA->GetDataSrc() + pVarB->GetDataSrc());
}
Importante, ou melhor, mesmo necessário, aqui está o uso das variáveis de ambiente do CPSU. Suas “propriedades de sombra” garantem a interação correta dos processos. Além disso, o ambiente permite alterar o modo de operação, excluindo o registro de variáveis na memória intermediária de sombra. Uma análise dos protocolos obtidos nesse modo nos permite verificar a necessidade de usar variáveis de sombra.3. E as corotinas? ...
Seria bom saber como as corotinas representadas pela linguagem Kotlin irão lidar com a tarefa. Tomemos como modelo de solução o programa considerado na discussão de [1]. Possui uma estrutura que é facilmente reduzida à aparência necessária. Para fazer isso, substitua as variáveis lógicas nele por um tipo numérico e adicione outra variável. Em vez de operações lógicas, usaremos a operação de soma. O código correspondente é mostrado na listagem 2.Listagem 2. Programa de soma paralela Kotlinimport kotlinx.coroutines.*
suspend fun main() =
coroutineScope {
var a = 1
var b = 1
var c = 0;
withContext(Dispatchers.Default) {
for (i in 0..4) {
var res = listOf(async { a+b }, async{ b+c }).map { it.await() }
c = res[0]
a = res[1]
println("$a, $b, $c")
}
}
}
Não há dúvidas sobre o resultado deste programa, pois corresponde exatamente ao primeiro dos protocolos acima.No entanto, a conversão do código-fonte não foi tão óbvia quanto parece, porque Parecia natural usar o seguinte fragmento de código:listOf(async { = a+b }, async{ = b+c })
Como mostra o teste (isso pode ser feito on-line no site da Kotlin - kotlinlang.org/#try-kotlin ), seu uso leva a um resultado completamente imprevisível, que também muda de um lançamento para outro. E apenas uma análise mais cuidadosa do programa de origem levou ao código correto.Código que contém um erro do ponto de vista do funcionamento do programa, mas é legítimo do ponto de vista da linguagem, nos faz temer pela confiabilidade dos programas nele. Essa opinião, provavelmente, pode ser contestada pelos especialistas da Kotlin. No entanto, a facilidade de cometer um erro, que não pode ser explicado apenas pela falta de entendimento da “programação de corotina”, está, no entanto, pressionando persistentemente por tais conclusões.4. Máquinas de eventos em Qt
Anteriormente, estabelecemos que um autômato de evento não é um autômato em sua definição clássica. Ele é bom ou ruim, mas, até certo ponto, a máquina de eventos ainda é um parente das máquinas clássicas. É distante, próximo, mas devemos falar sobre isso diretamente, para que não haja conceitos errados sobre isso. Começamos a conversar sobre isso em [2], mas tudo por continuar. Agora faremos isso examinando outros exemplos do uso de máquinas de eventos no Qt.Obviamente, um autômato de evento pode ser considerado um caso degenerado de um autômato clássico com uma duração de ciclo indefinida e / ou variável associada a um evento. A possibilidade de tal interpretação foi mostrada em um artigo anterior ao resolver apenas um e, além disso, um exemplo bastante específico (ver detalhes [2]). Em seguida, tentaremos eliminar essa lacuna.A biblioteca Qt apenas associa transições de máquina a eventos, o que é uma limitação séria. Por exemplo, na mesma linguagem UML, uma transição está associada não apenas a um evento chamado evento inicial, mas também a uma condição de proteção - uma expressão lógica calculada após o recebimento do evento [3]. No MATLAB, a situação é mais mitigada e soa assim: “se o nome do evento não for especificado, a transição ocorrerá quando ocorrer um evento” [4]. Mas aqui e ali, a causa raiz da transição são os eventos. Mas e se não houver eventos?Se não houver eventos, então ... você pode tentar criá-los. Listagem 3 e Figura 4 demonstram como fazer isso, usando o descendente da classe de autômatos LFsaAppl do ambiente VKPa como um "invólucro" do evento Qt-class. Aqui, a ação y2 com uma periodicidade do tempo discreto do espaço do autômato envia um sinal iniciando o início da transição do autômato Qt. O último, usando o método s0Exited, inicia a ação y1, que implementa a operação de soma. Observe que a máquina de eventos é criada estritamente pela ação y3 após verificar a inicialização das variáveis locais da classe LFsaAppl. Fig. 4. Combinação de máquinas clássicas e de eventos
Fig. 4. Combinação de máquinas clássicas e de eventos
Listagem 3. Implementando um modelo de soma com um autômato de eventos#include "lfsaappl.h"
class QStateMachine;
class QState;
class FSumABC :
public QObject,
public LFsaAppl
{
Q_OBJECT
...
protected:
int x1();
void y1(); void y2(); void y3(); void y12();
signals:
void GoState();
private slots:
void s0Exited();
private:
QStateMachine * machine;
QState * s0;
};
#include "stdafx.h"
#include "FSumABC.h"
#include <QStateMachine>
#include <QState>
static LArc TBL_SumABC[] = {
LArc("st", "st","^x1", "y12"),
LArc("st", "s1","x1", "y3"),
LArc("s1", "s1","--", "y2"),
LArc()
};
FSumABC::FSumABC(string strNam):
QObject(),
LFsaAppl(TBL_SumABC, strNam, nullptr, nullptr)
{ }
...
int FSumABC::x1() { return pVarA&&pVarB&&pVarC; }
void FSumABC::y1() {
pVarC->SetDataSrc(this, pVarA->GetDataSrc() + pVarB->GetDataSrc());
}
void FSumABC::y2() { emit GoState(); }
void FSumABC::y3() {
s0 = new QState();
QSignalTransition *ps = s0->addTransition(this, SIGNAL(GoState()), s0);
connect (s0, SIGNAL(entered()), this, SLOT(s0Exited()));
machine = new QStateMachine(nullptr);
machine->addState(s0);
machine->setInitialState(s0);
machine->start();
}
void FSumABC::y12() { FInit(); }
void FSumABC::s0Exited() { y1(); }
Acima, implementamos uma máquina muito simples. Ou, mais precisamente, uma combinação de autômatos clássicos e de eventos. Se a implementação anterior da classe FSumABC for substituída pela criada, simplesmente não haverá diferenças no aplicativo. Porém, para modelos mais complexos, as propriedades limitadas dos autômatos acionados por eventos começam a se manifestar completamente. No mínimo, já em processo de criação de um modelo. A Listagem 4 mostra a implementação do modelo do elemento AND-NOT na forma de um autômato de eventos (para obter mais detalhes sobre o modelo de autômato usado do elemento AND-NOT, consulte [2]).Listagem 4. Implementando um modelo de elemento AND NOT por uma máquina de eventos#include <QObject>
class QStateMachine;
class QState;
class MainWindow;
class ine : public QObject
{
Q_OBJECT
public:
explicit ine(MainWindow *parent = nullptr);
bool bX1, bX2, bY;
signals:
void GoS0();
void GoS1();
private slots:
void s1Exited();
void s0Exited();
private:
QStateMachine * machine;
QState * s0;
QState * s1;
MainWindow *pMain{nullptr};
friend class MainWindow;
};
#include "ine.h"
#include <QStateMachine>
#include <QState>
#include "mainwindow.h"
#include "ui_mainwindow.h"
ine::ine(MainWindow *parent) :
QObject(parent)
{
pMain = parent;
s0 = new QState();
s1 = new QState();
s0->addTransition(this, SIGNAL(GoS1()), s1);
s1->addTransition(this, SIGNAL(GoS0()), s0);
connect (s0, SIGNAL(entered()), this, SLOT(s0Exited()));
connect (s1, SIGNAL(entered()), this, SLOT(s1Exited()));
machine = new QStateMachine(nullptr);
machine->addState(s0);
machine->addState(s1);
machine->setInitialState(s1);
machine->start();
}
void ine::s1Exited() {
bY = !(bX1&&bX2);
pMain->ui->checkBoxY->setChecked(bY);
}
void ine::s0Exited() {
bY = !(bX1&&bX2);
pMain->ui->checkBoxY->setChecked(bY);
}
Torna-se claro que os autômatos de eventos no Qt se baseiam estritamente nos autômatos de Moore. Isso limita os recursos e a flexibilidade do modelo, como ações são associadas apenas a estados. Como resultado, por exemplo, é impossível distinguir entre duas transições do estado 0 para 1 para o autômato mostrado na Fig. 4 em [2].Obviamente, para implementar o Miles, você pode usar o procedimento conhecido para mudar para máquinas Moore. Mas isso leva a um aumento no número de estados e elimina a associação simples, visual e útil dos estados modelo com o resultado de suas ações. Por exemplo, após essas transformações, o estado único da saída do modelo 1 de [2] precisa comparar dois estados do autômato de Moore.Em um modelo mais complexo, problemas com condições de transição começam a aparecer com obviedade. Para contorná-los para a implementação do software do elemento AND-NOT em consideração, uma análise do estado dos canais de entrada foi incorporada ao diálogo de controle do modelo, conforme mostrado na Listagem 5.Listagem 5. Diálogo de controle do elemento NAND#include "mainwindow.h"
#include "ui_mainwindow.h"
#include "ine.h"
MainWindow::MainWindow(QWidget *parent)
: QMainWindow(parent)
, ui(new Ui::MainWindow)
{
ui->setupUi(this);
pine = new ine(this);
connect(this, SIGNAL(GoState0()), pine, SIGNAL(GoS0()));
connect(this, SIGNAL(GoState1()), pine, SIGNAL(GoS1()));
}
MainWindow::~MainWindow()
{
delete ui;
}
void MainWindow::on_checkBoxX1_clicked(bool checked)
{
bX1 = checked;
pine->bX1 = bX1;
bY = !(bX1&&bX2);
if (!(bX1&&bX2)) emit GoState0();
else emit GoState1();
}
void MainWindow::on_checkBoxX2_clicked(bool checked)
{
bX2 = checked;
pine->bX2 = bX2;
bY = !(bX1&&bX2);
if (!(bX1&&bX2)) emit GoState0();
else emit GoState1();
}
Em suma, tudo o que foi dito acima complica claramente o modelo e cria problemas com a compreensão de seu trabalho. Além disso, essas soluções locais podem não funcionar ao considerar composições delas. Um bom exemplo nesse caso seria uma tentativa de criar um modelo de acionador RS (para obter mais detalhes sobre um modelo de autômato de dois componentes de um acionador RS, consulte [5]). No entanto, o prazer do resultado alcançado será entregue aos fãs das máquinas de eventos. Se ... a menos que, é claro, eles tenham sucesso;)5. Função quadrática e ... borboleta?
É conveniente representar os dados de entrada como um processo paralelo externo. Acima disso, havia o diálogo para gerenciar o modelo de um elemento AND-NOT. Além disso, a taxa de alteração de dados pode afetar significativamente o resultado. Para confirmar isso, consideramos o cálculo da função quadrática y = ax² + bx + c, que implementamos na forma de um conjunto de blocos de funcionamento paralelo e de interação.Sabe-se que o gráfico de uma função quadrática tem o formato de uma parábola. Mas a parábola representada pelo matemático e a parábola que o osciloscópio, por exemplo, exibirá, a rigor, nunca corresponderá. A razão para isso é que o matemático geralmente pensa em categorias instantâneas, acreditando que uma alteração na quantidade de entrada leva imediatamente ao cálculo da função. Mas na vida real isso não é de todo verdade. A aparência do gráfico da função dependerá da velocidade da calculadora, da taxa de alteração dos dados de entrada etc. etc. Sim, e os próprios programas de velocidade podem diferir um do outro. Esses fatores afetarão a forma da função, na qual, em uma determinada situação, será difícil adivinhar a parábola. Estaremos convencidos disso ainda mais.Assim, adicionamos ao bloco soma os blocos de multiplicação, divisão e exponenciação. Tendo esse conjunto, podemos "coletar" expressões matemáticas de qualquer complexidade. Mas também podemos ter "cubos" que implementam funções mais complexas. Fig. 5. a implementação de uma função quadrática é mostrada em duas versões - multi-bloco (ver seta com uma etiqueta - 1, e também na Fig. 6) e uma variante de um bloco (na figura 5 seta com uma etiqueta 2). Fig.5. Duas opções para implementar a função quadrática
Fig.5. Duas opções para implementar a função quadrática Fig. 6. Modelo estrutural para calcular uma função quadráticaIsso na figura 5. parece “borrado” (veja a seta marcada como 3), quando ampliado adequadamente (veja gráficos (tendências), marcado como 4), está convencido de que o assunto não está nas propriedades gráficas. Este é o resultado da influência do tempo no cálculo das variáveis: a variável y1 é o valor de saída da variante de múltiplos blocos (cor vermelha do gráfico) e a variável y2 é o valor de saída da variante de bloco único (cor preta). Mas esses dois gráficos são diferentes dos "gráficos abstratos" [y2 (t), x (t-1)] (verde). Este último é construído para o valor da variável y2 e o valor da variável de entrada atrasado em um ciclo de clock (veja a variável com o nome x [t-1]).Assim, quanto maior a taxa de alteração da função de entrada x (t), mais forte será o “efeito de desfoque” e mais longe os gráficos y1, y2 serão do gráfico [y2 (t), x (t-1)]. O "defeito" detectado pode ser usado para seus próprios fins. Por exemplo, nada nos impede de aplicar um sinal senoidal à entrada. Consideraremos uma opção ainda mais complicada, quando o primeiro coeficiente da equação também mudar de maneira semelhante. O resultado do experimento demonstra uma tela do meio VKPa, mostrada na Fig. 7.
Fig. 6. Modelo estrutural para calcular uma função quadráticaIsso na figura 5. parece “borrado” (veja a seta marcada como 3), quando ampliado adequadamente (veja gráficos (tendências), marcado como 4), está convencido de que o assunto não está nas propriedades gráficas. Este é o resultado da influência do tempo no cálculo das variáveis: a variável y1 é o valor de saída da variante de múltiplos blocos (cor vermelha do gráfico) e a variável y2 é o valor de saída da variante de bloco único (cor preta). Mas esses dois gráficos são diferentes dos "gráficos abstratos" [y2 (t), x (t-1)] (verde). Este último é construído para o valor da variável y2 e o valor da variável de entrada atrasado em um ciclo de clock (veja a variável com o nome x [t-1]).Assim, quanto maior a taxa de alteração da função de entrada x (t), mais forte será o “efeito de desfoque” e mais longe os gráficos y1, y2 serão do gráfico [y2 (t), x (t-1)]. O "defeito" detectado pode ser usado para seus próprios fins. Por exemplo, nada nos impede de aplicar um sinal senoidal à entrada. Consideraremos uma opção ainda mais complicada, quando o primeiro coeficiente da equação também mudar de maneira semelhante. O resultado do experimento demonstra uma tela do meio VKPa, mostrada na Fig. 7. Fig. 7. Resultados da simulação com um sinal de entrada sinusoidalA tela no canto inferior esquerdo mostra o sinal fornecido às entradas de realizações de uma função quadrática. Acima estão os gráficos dos valores de saída y1 e y2. Gráficos na forma de "asas" são valores plotados em duas coordenadas. Assim, com a ajuda de várias realizações da função quadrática, desenhamos a metade da "borboleta". Desenhar um todo é uma questão de tecnologia ...Mas os paradoxos do paralelismo não param por aí. Na fig. A Figura 8 mostra tendências na mudança "reversa" da variável independente x. Eles já passam para a esquerda do gráfico "abstrato" (o último, notamos, não mudou de posição!).
Fig. 7. Resultados da simulação com um sinal de entrada sinusoidalA tela no canto inferior esquerdo mostra o sinal fornecido às entradas de realizações de uma função quadrática. Acima estão os gráficos dos valores de saída y1 e y2. Gráficos na forma de "asas" são valores plotados em duas coordenadas. Assim, com a ajuda de várias realizações da função quadrática, desenhamos a metade da "borboleta". Desenhar um todo é uma questão de tecnologia ...Mas os paradoxos do paralelismo não param por aí. Na fig. A Figura 8 mostra tendências na mudança "reversa" da variável independente x. Eles já passam para a esquerda do gráfico "abstrato" (o último, notamos, não mudou de posição!). FIG. 8. O tipo de gráfico com mudança linear direta e reversa do sinal de entradaNeste exemplo, o erro "duplo" do sinal de saída em relação ao seu valor "instantâneo" se torna aparente. E quanto mais lento o sistema de computação ou quanto maior a frequência do sinal, maior o erro. Uma onda senoidal é um exemplo de mudança para frente e para trás de um sinal de entrada. Devido a isso, as “asas” na Fig. 4 assumiram esta forma. Sem o efeito "erro de retorno", eles seriam duas vezes mais estreitos.
FIG. 8. O tipo de gráfico com mudança linear direta e reversa do sinal de entradaNeste exemplo, o erro "duplo" do sinal de saída em relação ao seu valor "instantâneo" se torna aparente. E quanto mais lento o sistema de computação ou quanto maior a frequência do sinal, maior o erro. Uma onda senoidal é um exemplo de mudança para frente e para trás de um sinal de entrada. Devido a isso, as “asas” na Fig. 4 assumiram esta forma. Sem o efeito "erro de retorno", eles seriam duas vezes mais estreitos.6. Controlador PID adaptável
Vamos considerar mais um exemplo no qual os problemas considerados são mostrados. Na fig. A Figura 9 mostra a configuração do meio VKP (a) ao modelar um controlador PID adaptável. Um diagrama de blocos também é mostrado no qual o controlador PID é representado por uma unidade chamada PID. No nível da caixa preta, é semelhante à implementação em bloco único anteriormente considerada de uma função quadrática.O resultado da comparação dos resultados do cálculo do modelo do controlador PID dentro de um determinado pacote matemático e o protocolo obtido a partir dos resultados da simulação no ambiente VKP (a) é mostrado na Fig. 10, onde o gráfico vermelho é os valores calculados e o gráfico azul é o protocolo. A razão para essa incompatibilidade é que o cálculo dentro da estrutura do pacote matemático, conforme mostrado por análises adicionais, corresponde à operação seqüencial dos objetos quando eles primeiro trabalham no controlador PID e param, e depois no modelo do objeto, etc. no loop. O ambiente VKPa implementa / modela a operação paralela de objetos de acordo com a situação real, quando o modelo e o objeto trabalham em paralelo. Fig. 9. Implementação do controlador PID
Fig. 9. Implementação do controlador PID Fig. 10. Comparação de valores calculados com resultados de simulação do controlador PIDComo, como já anunciamos, no VKP (a) existe um modo para simular a operação seqüencial de blocos estruturais, não é difícil verificar a hipótese de um modo de cálculo seqüencial para o controlador PID. Alterando o modo de operação do meio para serial, obtemos a coincidência dos gráficos, como mostra a Fig. 11.
Fig. 10. Comparação de valores calculados com resultados de simulação do controlador PIDComo, como já anunciamos, no VKP (a) existe um modo para simular a operação seqüencial de blocos estruturais, não é difícil verificar a hipótese de um modo de cálculo seqüencial para o controlador PID. Alterando o modo de operação do meio para serial, obtemos a coincidência dos gráficos, como mostra a Fig. 11. Fig. 11. Operação sequencial do controlador PID e objeto de controle
Fig. 11. Operação sequencial do controlador PID e objeto de controle
7. Conclusões
Dentro da estrutura do CPSU (a), o modelo computacional confere aos programas propriedades que são características dos objetos "vivos" reais. Daí a associação figurativa com a "matemática viva". Como mostra a prática, nós, nos modelos, somos simplesmente obrigados a levar em conta o que não pode ser ignorado na vida real. Na computação paralela, esse é principalmente o tempo e a finitude dos cálculos. Obviamente, sem esquecer a adequação do modelo matemático [automático] a um ou outro objeto "vivo".É impossível lutar contra o que não pode ser derrotado. Já estava na hora. Isso é possível apenas em um conto de fadas. Mas faz sentido levar isso em conta e / ou até usá-lo para seus próprios propósitos. Na programação paralela moderna, ignorar o tempo leva a muitos problemas dificilmente controlados e detectados - corrida de sinal, processos de impasse, problemas com sincronização, etc. etc. A tecnologia VKP (a) está praticamente livre de tais problemas, simplesmente porque inclui um modelo em tempo real e leva em consideração a finitude dos processos de computação. Ele contém o que a maioria de seus análogos é simplesmente ignorada.Em conclusão. Borboletas são borboletas, mas você pode, por exemplo, considerar um sistema de equações de funções quadráticas e lineares. Para fazer isso, basta adicionar ao modelo já criado um modelo de função linear e um processo que controla sua coincidência. Portanto, a solução será encontrada por modelagem. Provavelmente não será tão preciso quanto analítico, mas será obtido de maneira mais simples e rápida. E, em muitos casos, isso é mais do que suficiente. E encontrar uma solução analítica é, geralmente, uma questão em aberto.Em conexão com este último, os AVMs foram recuperados. Para aqueles que não estão atualizados ou se esqueceram, - computadores analógicos. Os princípios estruturais são, em geral, a abordagem para encontrar uma solução.inscrição
1) Vídeo : youtu.be/vf9gNBAmOWQ2) Arquivo de exemplos : github.com/lvs628/FsaHabr/blob/master/FsaHabr.zip .3) Arquivo das bibliotecas Qt dll necessárias versão 5.11.2 : github.com/lvs628/FsaHabr/blob/master/QtDLLs.zip Osexemplos são desenvolvidos no ambiente Windows 7. Para instalá-los, abra o arquivo de exemplos e, se o Qt não estiver instalado ou a versão atual do Qt é diferente da versão 5.11.2, abra adicionalmente o arquivo Qt e grave o caminho para as bibliotecas na variável de ambiente Path. Em seguida, execute \ FsaHabr \ VCPaMain \ release \ FsaHabr.exe e use a caixa de diálogo para selecionar o diretório de configuração de um exemplo, por exemplo, \ FsaHabr \ 9.ParallelOperators \ Heading1 \ Pict1.C2 = A + B + A1 + B1 \ (consulte também vídeo).Comente. Na primeira inicialização, em vez da caixa de diálogo de seleção de diretório, uma caixa de diálogo de seleção de arquivo pode aparecer. Também selecionamos o diretório de configuração e algum arquivo nele, por exemplo, vSetting.txt. Se a caixa de diálogo de seleção da configuração não aparecer, antes de iniciar, exclua o arquivo ConfigFsaHabr.txt no diretório em que o arquivo FsaHabr.exe está localizado.
Para não repetir a seleção da configuração na caixa de diálogo "kernel: automatic spaces" (pode ser aberta usando o item de menu: FSA-tools / Space Management / Management), clique no botão "lembrar o caminho do diretório" e desmarque "exibir a caixa de diálogo de seleção da configuração na inicialização" " No futuro, para selecionar uma configuração diferente, essa opção precisará ser definida novamente.Literatura
1. NPS, transportador, computação automática e, novamente ... corotinas. [Recurso eletrônico], Modo de acesso: habr.com/en/post/488808 grátis. Yaz. russo (data do tratamento 02.22.2020).2. As máquinas automáticas são uma coisa do evento? [Recurso eletrônico], Modo de acesso: habr.com/en/post/483610 grátis. Yaz. russo (data do tratamento 02.22.2020).3. BUCH G., RAMBO J., JACOBSON I. UML. Manual do usuário. Segunda edição. IT Academy: Moscou, 2007 - 493 p.4. Rogachev G.N. Stateflow V5. Manual do usuário. [Recurso eletrônico], Modo de acesso: bourabai.kz/cm/stateflow.htm grátis. Yaz. russo (data de circulação 10.04.2020).5)Modelo de computação paralela [Recurso eletrônico], Modo de acesso: habr.com/en/post/486622 grátis. Yaz. russo (data de circulação 04/11/2020).