 O efeito de inchar tabelas e índices (inchaço) é amplamente conhecido e está presente não apenas no Postgres. Existem maneiras de lidar com isso imediatamente, como VACUUM FULL ou CLUSTER, mas elas bloqueiam as tabelas durante a operação e, portanto, nem sempre podem ser usadas.O artigo terá um pouco de teoria sobre como ocorre o inchaço, como lidar com ele, sobre restrições adiadas e sobre os problemas que eles trazem para o uso da extensão pg_repack.Este artigo é baseado na minha apresentação no PgConf.Russia 2020.
O efeito de inchar tabelas e índices (inchaço) é amplamente conhecido e está presente não apenas no Postgres. Existem maneiras de lidar com isso imediatamente, como VACUUM FULL ou CLUSTER, mas elas bloqueiam as tabelas durante a operação e, portanto, nem sempre podem ser usadas.O artigo terá um pouco de teoria sobre como ocorre o inchaço, como lidar com ele, sobre restrições adiadas e sobre os problemas que eles trazem para o uso da extensão pg_repack.Este artigo é baseado na minha apresentação no PgConf.Russia 2020.Por que inchaço ocorre
O Postgres é baseado no modelo multi-versão ( MVCC ). Sua essência é que cada linha da tabela pode ter várias versões, enquanto as transações não veem mais que uma dessas versões, mas não necessariamente a mesma. Isso permite que várias transações funcionem simultaneamente e praticamente não afetam uma a outra.Obviamente, todas essas versões precisam ser armazenadas. O Postgres trabalha com memória página por página e a página é a quantidade mínima de dados que podem ser lidos a partir do disco ou gravados. Vejamos um pequeno exemplo para entender como isso acontece.Suponha que tenhamos uma tabela na qual adicionamos vários registros. Na primeira página do arquivo em que a tabela está armazenada, novos dados apareceram. Essas são versões ativas de strings que estão disponíveis para outras transações após uma confirmação (por simplicidade, assumiremos que o nível de isolamento Read Committed).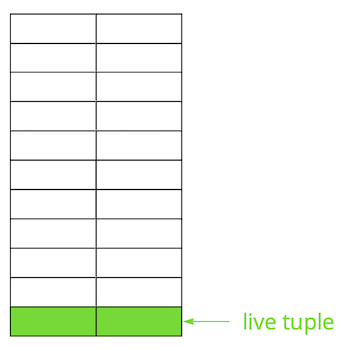 Em seguida, atualizamos uma das entradas e, assim, marcamos a versão antiga como irrelevante.
Em seguida, atualizamos uma das entradas e, assim, marcamos a versão antiga como irrelevante.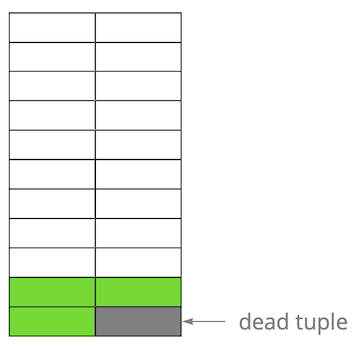 Passo a passo, atualizando e excluindo a versão das linhas, obtivemos uma página na qual cerca da metade dos dados é "lixo". Esses dados não são visíveis para nenhuma transação.
Passo a passo, atualizando e excluindo a versão das linhas, obtivemos uma página na qual cerca da metade dos dados é "lixo". Esses dados não são visíveis para nenhuma transação.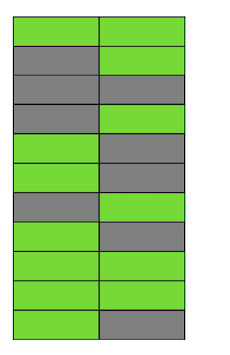 O Postgres possui um mecanismo VACUUM, que limpa versões irrelevantes e libera espaço para novos dados. Mas se ele não estiver configurado de forma agressiva o suficiente ou estiver ocupado trabalhando em outras tabelas, os “dados indesejados” permanecerão e precisamos usar páginas adicionais para novos dados.Portanto, em nosso exemplo, em algum momento, a tabela consistirá em quatro páginas, mas haverá apenas metade dos dados ativos. Como resultado, ao acessar a tabela, leremos muito mais dados do que o necessário.
O Postgres possui um mecanismo VACUUM, que limpa versões irrelevantes e libera espaço para novos dados. Mas se ele não estiver configurado de forma agressiva o suficiente ou estiver ocupado trabalhando em outras tabelas, os “dados indesejados” permanecerão e precisamos usar páginas adicionais para novos dados.Portanto, em nosso exemplo, em algum momento, a tabela consistirá em quatro páginas, mas haverá apenas metade dos dados ativos. Como resultado, ao acessar a tabela, leremos muito mais dados do que o necessário.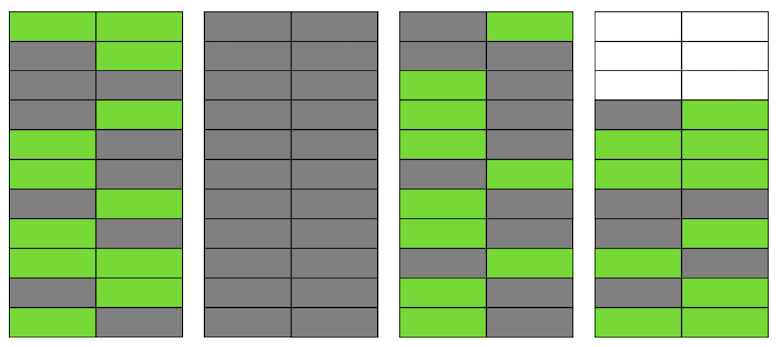 Mesmo que o VACUUM agora exclua todas as versões irrelevantes de cadeias, a situação não melhorará drasticamente. Teremos espaço livre nas páginas ou até páginas inteiras para novas linhas, mas continuaremos a ler mais dados do que o necessário.A propósito, se uma página completamente em branco (a segunda em nosso exemplo) estivesse no final do arquivo, o VACUUM poderia cortá-la. Mas agora ela está no meio, então nada pode ser feito com ela.
Mesmo que o VACUUM agora exclua todas as versões irrelevantes de cadeias, a situação não melhorará drasticamente. Teremos espaço livre nas páginas ou até páginas inteiras para novas linhas, mas continuaremos a ler mais dados do que o necessário.A propósito, se uma página completamente em branco (a segunda em nosso exemplo) estivesse no final do arquivo, o VACUUM poderia cortá-la. Mas agora ela está no meio, então nada pode ser feito com ela.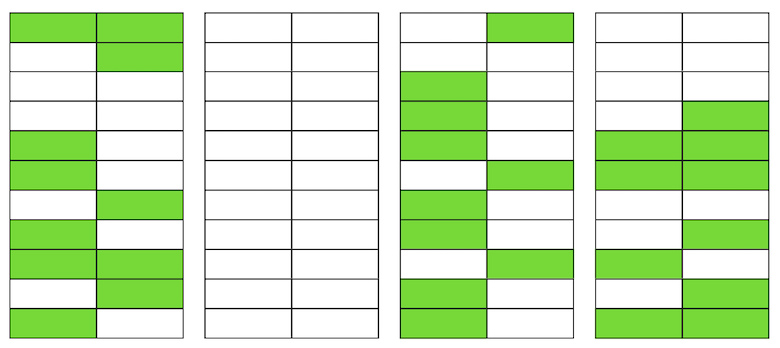 Quando o número de páginas em branco ou muito planas se torna grande, chamado inchaço, ele começa a afetar o desempenho.Tudo descrito acima é a mecânica da ocorrência de inchaço nas tabelas. Nos índices, isso acontece da mesma maneira.
Quando o número de páginas em branco ou muito planas se torna grande, chamado inchaço, ele começa a afetar o desempenho.Tudo descrito acima é a mecânica da ocorrência de inchaço nas tabelas. Nos índices, isso acontece da mesma maneira.Eu tenho um inchaço?
Existem várias maneiras de determinar se você tem um inchaço. A idéia do primeiro é usar estatísticas internas do Postgres, que contêm informações aproximadas sobre o número de linhas nas tabelas, o número de linhas "ativas" etc. Na Internet, você pode encontrar muitas variações de scripts prontos. Tomamos como base um script do PostgreSQL Experts, que pode avaliar as tabelas bloat junto com os índices toast e bloat btree. Em nossa experiência, seu erro é de 10 a 20%.Outra maneira é usar a extensão pgstattuple , que permite que você olhe dentro das páginas e obtenha valores de inchaço estimados e precisos. Mas no segundo caso, você precisa digitalizar a tabela inteira.Um pequeno valor de inchaço, até 20%, consideramos aceitável. Pode ser considerado como um análogo do fator de preenchimento para tabelas e índices . Em 50% e acima, problemas de desempenho podem começar.Maneiras de lidar com o inchaço
Existem várias maneiras de lidar com o inchaço imediato no Postgres, mas elas estão longe de ser sempre adequadas para todos.Defina AUTOVACUUM para que o inchaço não ocorra . E, mais precisamente, para mantê-lo em um nível aceitável para você. Este parece ser o conselho do "capitão", mas, na realidade, isso nem sempre é fácil de conseguir. Por exemplo, você está desenvolvendo ativamente com alterações regulares no esquema de dados ou algum tipo de migração de dados está ocorrendo. Como resultado, seu perfil de carregamento pode mudar com frequência e, como regra, pode ser diferente para tabelas diferentes. Isso significa que você precisa trabalhar constantemente um pouco à frente da curva e ajustar AUTOVACUUM ao perfil de mudança de cada tabela. Mas é óbvio que isso não é fácil.Outro motivo comum para o AUTOVACUUM não ter tempo para processar tabelas é a presença de transações demoradas que impedem a limpeza de dados devido ao fato de estar disponível para essas transações. A recomendação aqui também é óbvia - elimine as transações suspensas e minimize o tempo das transações ativas. Mas se a carga no seu aplicativo for um híbrido de OLAP e OLTP, ao mesmo tempo, você poderá ter muitas atualizações frequentes e solicitações curtas, além de operações demoradas - por exemplo, criando um relatório. Em tal situação, vale a pena pensar em espalhar a carga em diferentes bases, o que permitirá um ajuste mais preciso de cada uma delas.Outro exemplo - mesmo que o perfil seja uniforme, mas o banco de dados esteja com uma carga muito alta, mesmo o AUTOVACUUM mais agressivo pode não aguentar, e ocorrerá um inchaço. A escala (vertical ou horizontal) é a única solução.Mas e a situação quando você configurou o AUTOVACUUM, mas o inchaço continua a crescer.Comando VÁCUO CHEIOreconstrói o conteúdo de tabelas e índices e deixa apenas dados relevantes neles. Para eliminar o inchaço, ele funciona perfeitamente, mas durante sua execução, um bloqueio exclusivo na tabela (AccessExclusiveLock) é capturado, o que não permitirá consultas a essa tabela, nem mesmo as seleciona. Se você puder interromper seu serviço ou parte dele por um tempo (de dezenas de minutos a várias horas, dependendo do tamanho do banco de dados e do seu hardware), essa opção é a melhor. Infelizmente, não temos tempo para executar o VACUUM FULL durante a manutenção agendada, portanto esse método não é adequado para nós.Comando CLUSTEREle também reconstrói o conteúdo das tabelas, assim como o VACUUM FULL, ao mesmo tempo em que permite especificar o índice de acordo com o qual os dados serão ordenados fisicamente no disco (mas no futuro o pedido não será garantido). Em certas situações, essa é uma boa otimização para várias consultas - com a leitura de vários registros por índice. A desvantagem do comando é a mesma do VACUUM FULL - ele bloqueia a tabela durante a operação.O comando REINDEX é semelhante aos dois anteriores, mas reconstrói um índice específico ou todos os índices na tabela. Os bloqueios são um pouco mais fracos: o ShareLock na tabela (impede modificações, mas permite a seleção) e o AccessExclusiveLock no índice reconstruível (bloqueia solicitações usando esse índice). No entanto, na versão 12 do Postgres, o parâmetro CONCURRENTLY, que permite recriar o índice sem bloquear a adição, modificação ou exclusão paralela de registros.Nas versões anteriores do Postgres, é possível obter um resultado semelhante ao REINDEX CONCURRENTLY com CREATE INDEX CONCURRENTLY . Ele permite que você crie um índice sem bloqueio estrito (ShareUpdateExclusiveLock, que não interfere nas consultas paralelas), substitua o índice antigo por um novo e exclua o índice antigo. Isso elimina os índices de inchaço sem interferir no seu aplicativo. É importante considerar que, ao recriar índices, haverá uma carga adicional no subsistema de disco.Portanto, se existem maneiras de os índices eliminarem o inchaço “quente”, então para as tabelas não há. Aqui várias extensões externas entram em jogo : pg_repack(anteriormente pg_reorg), pgcompact , pgcompacttable e outros. Na estrutura deste artigo, não os compararei e falarei apenas sobre pg_repack, que, após algum refinamento, usamos em casa.Como o pg_repack funciona
Suponha que tenhamos uma tabela muito normal para nós mesmos - com índices, restrições e, infelizmente, com inchaço. A primeira etapa é pg_repack cria uma tabela de log para armazenar dados sobre todas as alterações durante a operação. O gatilho replicará essas alterações para cada inserção, atualização e exclusão. Em seguida, é criada uma tabela semelhante à estrutura original, mas sem índices e restrições, para não retardar o processo de inserção de dados.Em seguida, pg_repack transfere dados da tabela antiga para a nova, filtrando automaticamente todas as linhas irrelevantes e, em seguida, cria índices para a nova tabela. Durante a execução de todas essas operações, as alterações são acumuladas na tabela de log.O próximo passo é transferir as alterações para a nova tabela. A migração é realizada em várias iterações e, quando menos de 20 entradas permanecem na tabela de log, o pg_repack captura um bloqueio estrito, transfere os dados mais recentes e substitui a tabela antiga pela nova nas tabelas do sistema Postgres. Este é o único e muito curto momento em que você não pode trabalhar com a tabela. Depois disso, a tabela antiga e a tabela com os logs são excluídas e o espaço é liberado no sistema de arquivos. O processo está concluído.Em teoria, tudo parece ótimo, o que na prática? Testamos o pg_repack sem carga e sob carga, verificamos sua operação em caso de parada prematura (em outras palavras, Ctrl + C). Todos os testes foram positivos.Fomos ao prod - e então tudo deu errado como esperávamos.A primeira panqueca em prod
No primeiro cluster, recebemos um erro por violar uma restrição exclusiva:$ ./pg_repack -t tablename -o id
INFO: repacking table "tablename"
ERROR: query failed:
ERROR: duplicate key value violates unique constraint "index_16508"
DETAIL: Key (id, index)=(100500, 42) already exists.
Essa restrição tinha o nome gerado automaticamente index_16508 - foi criada por pg_repack. Pelos atributos incluídos em sua composição, determinamos a "nossa" restrição, que corresponde a ela. O problema acabou sendo que essa não é uma restrição comum, mas uma restrição adiada , ou seja, sua verificação é realizada depois do comando sql, o que leva a consequências inesperadas.Restrições adiadas: por que elas são necessárias e como funcionam
Um pouco de teoria sobre restrições adiadas.Considere um exemplo simples: temos uma tabela de referência de carro com dois atributos - o nome e a ordem do carro no diretório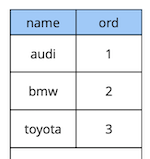
create table cars
(
name text constraint pk_cars primary key,
ord integer not null constraint uk_cars unique
);
Digamos que precisássemos trocar o primeiro e o segundo carros. A solução "na testa" é atualizar o primeiro valor para o segundo e o segundo para o primeiro:begin;
update cars set ord = 2 where name = 'audi';
update cars set ord = 1 where name = 'bmw';
commit;
Mas, ao executar esse código, esperamos obter uma violação da restrição, porque a ordem dos valores na tabela é única:[23305] ERROR: duplicate key value violates unique constraint “uk_cars”
Detail: Key (ord)=(2) already exists.
Como fazer diferente? Opção um: adicione uma substituição adicional do valor por um pedido que não existe na tabela, por exemplo, "-1". Na programação, isso é chamado de "troca dos valores de duas variáveis pela terceira". A única desvantagem desse método é a atualização adicional.Opção 2: redesenhe a tabela para usar um tipo de dados de ponto flutuante para o valor do pedido em vez de números inteiros. Então, ao atualizar o valor de 1, por exemplo, para 2,5, o primeiro registro será automaticamente "levantado" entre o segundo e o terceiro. Esta solução funciona, mas existem duas limitações. Em primeiro lugar, não funcionará para você se o valor for usado em algum lugar da interface. Em segundo lugar, dependendo da precisão do tipo de dados, você terá um número limitado de inserções possíveis antes de recalcular os valores de todos os registros.Opção três: torne a restrição adiada para que seja verificada apenas no momento da confirmação:create table cars
(
name text constraint pk_cars primary key,
ord integer not null constraint uk_cars unique deferrable initially deferred
);
Como a lógica de nossa solicitação inicial garante que todos os valores sejam únicos no momento da confirmação, ela será bem-sucedida.O exemplo acima é, obviamente, muito sintético, mas revela a ideia. Em nosso aplicativo, usamos restrições adiadas para implementar a lógica responsável pela resolução de conflitos enquanto trabalhamos simultaneamente com objetos de widget comuns no quadro. O uso de tais restrições nos permite facilitar um pouco o código do aplicativo.Em geral, dependendo do tipo de restrição no Postgres, há três níveis de granularidade para verificá-las: nível de linha, transação e expressão.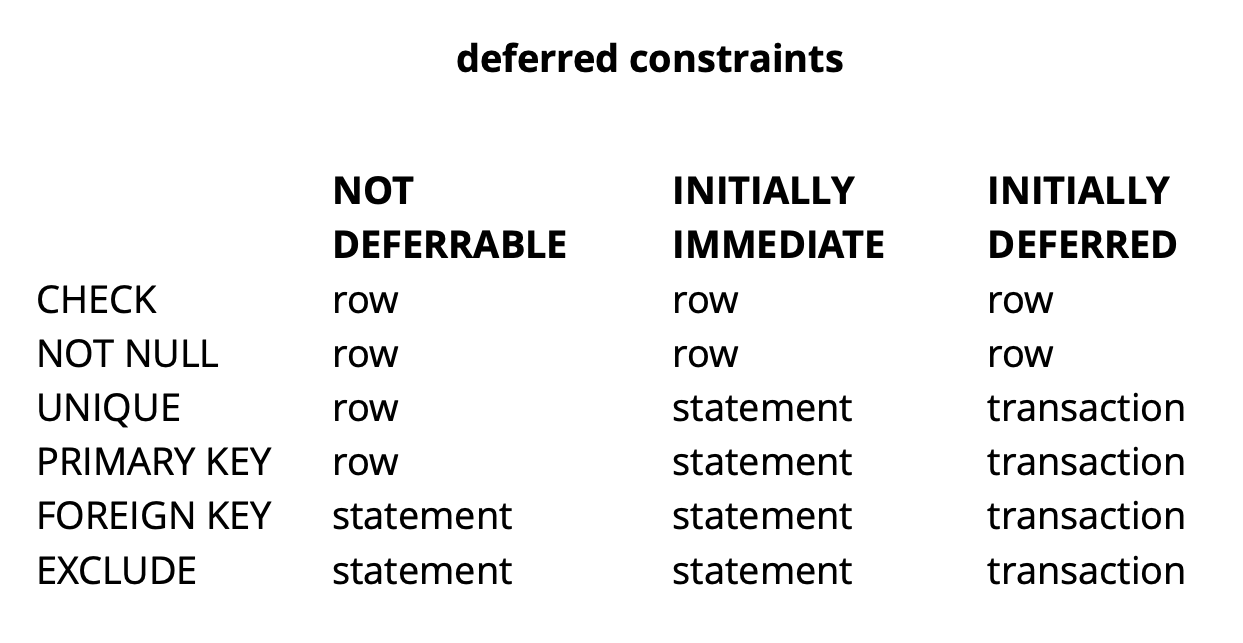 Fonte: begriffsCHECK e NOT NULL são sempre verificados no nível da linha. Para outras restrições, como pode ser visto na tabela, existem opções diferentes. Leia mais aqui .Para resumir brevemente, as restrições pendentes em algumas situações fornecem código mais legível e menos comandos. No entanto, você precisa pagar por isso, complicando o processo de depuração, pois o momento em que o erro ocorreu e o momento em que você descobriu sobre ele são separados no tempo. Outro possível problema é que o planejador nem sempre pode criar o plano ideal se uma restrição atrasada estiver envolvida na solicitação.
Fonte: begriffsCHECK e NOT NULL são sempre verificados no nível da linha. Para outras restrições, como pode ser visto na tabela, existem opções diferentes. Leia mais aqui .Para resumir brevemente, as restrições pendentes em algumas situações fornecem código mais legível e menos comandos. No entanto, você precisa pagar por isso, complicando o processo de depuração, pois o momento em que o erro ocorreu e o momento em que você descobriu sobre ele são separados no tempo. Outro possível problema é que o planejador nem sempre pode criar o plano ideal se uma restrição atrasada estiver envolvida na solicitação.Refinamento pg_repack
Descobrimos o que são restrições pendentes, mas como elas estão relacionadas ao nosso problema? Lembre-se do erro que recebemos anteriormente:$ ./pg_repack -t tablename -o id
INFO: repacking table "tablename"
ERROR: query failed:
ERROR: duplicate key value violates unique constraint "index_16508"
DETAIL: Key (id, index)=(100500, 42) already exists.
Ocorre no momento da cópia dos dados da tabela de log para a nova tabela. Parece estranho porque os dados na tabela de log são confirmados junto com os dados na tabela original. Se eles satisfazem as restrições da tabela original, como podem violar as mesmas restrições na nova?Como se viu, a raiz do problema está na etapa anterior do pg_repack, na qual apenas índices são criados, mas não restrições: a tabela antiga tinha uma restrição exclusiva e a nova criou um índice exclusivo. É importante observar aqui que, se a restrição for normal e não adiada, o índice exclusivo criado em vez dele será equivalente a essa restrição, porque As restrições exclusivas do Postgres são implementadas criando um índice exclusivo. Mas, no caso de uma restrição adiada, o comportamento não é o mesmo, porque o índice não pode ser adiado e é sempre verificado no momento em que o comando sql é executado.Assim, a essência do problema está no "adiamento" da verificação: na tabela original, ela ocorre no momento do commit e no novo - no momento da execução do comando sql. Portanto, precisamos garantir que as verificações sejam executadas da mesma maneira nos dois casos: sempre adiadas ou sempre imediatamente.Então, que idéias tivemos?
É importante observar aqui que, se a restrição for normal e não adiada, o índice exclusivo criado em vez dele será equivalente a essa restrição, porque As restrições exclusivas do Postgres são implementadas criando um índice exclusivo. Mas, no caso de uma restrição adiada, o comportamento não é o mesmo, porque o índice não pode ser adiado e é sempre verificado no momento em que o comando sql é executado.Assim, a essência do problema está no "adiamento" da verificação: na tabela original, ela ocorre no momento do commit e no novo - no momento da execução do comando sql. Portanto, precisamos garantir que as verificações sejam executadas da mesma maneira nos dois casos: sempre adiadas ou sempre imediatamente.Então, que idéias tivemos?Crie um índice semelhante ao adiado
A primeira idéia é realizar as duas verificações no modo imediato. Isso pode dar origem a vários gatilhos falsos positivos da restrição, mas se houver poucos deles, isso não deve afetar o trabalho dos usuários, pois para eles esses conflitos são uma situação normal. Eles ocorrem, por exemplo, quando dois usuários começam a editar simultaneamente o mesmo widget e o cliente do segundo usuário não tem tempo para obter informações de que o widget já está bloqueado para edição pelo primeiro usuário. Nessa situação, o servidor recusa o segundo usuário e seu cliente reverte as alterações e bloqueia o widget. Um pouco mais tarde, quando o primeiro usuário concluir a edição, o segundo receberá informações de que o widget não está mais bloqueado e poderá repetir sua ação.Para garantir que as verificações estejam sempre no modo de emergência, criamos um novo índice semelhante à restrição adiada original:CREATE UNIQUE INDEX CONCURRENTLY uk_tablename__immediate ON tablename (id, index);
DROP INDEX CONCURRENTLY uk_tablename__immediate;
No ambiente de teste, recebemos apenas alguns erros esperados. Sucesso! Novamente lançamos o pg_repack no prod e obtivemos 5 erros no primeiro cluster em uma hora de trabalho. Este é um resultado aceitável. No entanto, já no segundo cluster, o número de erros aumentou muitas vezes e tivemos que parar o pg_repack.Por que isso aconteceu? A probabilidade de um erro depende de quantos usuários trabalham simultaneamente com os mesmos widgets. Aparentemente, naquele momento com os dados armazenados no primeiro cluster, havia muito menos mudanças competitivas do que no restante, ou seja, nós tivemos apenas "sorte".A ideia não deu certo. Nesse momento, vimos duas outras opções de solução: reescrever nosso código de aplicativo para abandonar as restrições pendentes ou "ensinar" o pg_repack para trabalhar com eles. Nós escolhemos o segundo.Substituir índices na nova tabela por restrições adiadas da tabela de origem
O objetivo da revisão era óbvio - se a tabela original tiver uma restrição adiada, para a nova você precisará criar essa restrição, não um índice.Para testar nossas alterações, escrevemos um teste simples:- tabela com restrição diferida e um registro;
- insira dados no loop que entrem em conflito com o registro existente;
- make update - os dados não conflitam mais;
- confirmar a alteração.
create table test_table
(
id serial,
val int,
constraint uk_test_table__val unique (val) deferrable initially deferred
);
INSERT INTO test_table (val) VALUES (0);
FOR i IN 1..10000 LOOP
BEGIN
INSERT INTO test_table VALUES (0) RETURNING id INTO v_id;
UPDATE test_table set val = i where id = v_id;
COMMIT;
END;
END LOOP;
A versão original do pg_repack sempre falhava na primeira inserção, a versão revisada funcionava sem erros. Bem.Vamos ao produto e, novamente, obtemos um erro na mesma fase de cópia de dados da tabela de log para a nova:$ ./pg_repack -t tablename -o id
INFO: repacking table "tablename"
ERROR: query failed:
ERROR: duplicate key value violates unique constraint "index_16508"
DETAIL: Key (id, index)=(100500, 42) already exists.
Situação clássica: tudo funciona em ambientes de teste, mas não em prod ?!APPLY_COUNT e a junção de dois lotes
Começamos a analisar o código literalmente linha por linha e descobrimos um ponto importante: os dados são transferidos da tabela de logs para a nova com lotes, a constante APPLY_COUNT indica o tamanho do lote:for (;;)
{
num = apply_log(connection, table, APPLY_COUNT);
if (num > MIN_TUPLES_BEFORE_SWITCH)
continue;
...
}
O problema é que os dados da transação original, na qual várias operações podem violar a restrição, podem ser transferidos para a junção de dois lotes durante a transferência - metade das equipes será confirmada na primeira partida e a outra metade na segunda. E aqui está a sorte: se as equipes do primeiro lote não violarem nada, tudo estará bem, mas se violarem - ocorrerá um erro.APPLY_COUNT é igual a 1000 entradas, o que explica por que nossos testes foram bem-sucedidos - eles não cobriram o caso de "junção de lotes". Usamos dois comandos - inserir e atualizar, para que exatamente 500 transações de duas equipes fossem sempre colocadas no lote e não tivemos problemas. Depois de adicionar a segunda atualização, nossa edição parou de funcionar:FOR i IN 1..10000 LOOP
BEGIN
INSERT INTO test_table VALUES (1) RETURNING id INTO v_id;
UPDATE test_table set val = i where id = v_id;
UPDATE test_table set val = i where id = v_id;
COMMIT;
END;
END LOOP;
Portanto, a próxima tarefa é garantir que os dados da tabela de origem que foram alterados em uma transação caiam na nova tabela também dentro da mesma transação.Recusa de Butching
E, novamente, tivemos duas soluções. Primeiro: vamos abandonar completamente o lote e fazer a transferência de dados em uma transação. A favor desta solução estava a sua simplicidade - as alterações de código necessárias eram mínimas (a propósito, em versões mais antigas, o pg_reorg funcionava dessa maneira). Mas há um problema - estamos criando uma transação longa, e isso, como foi dito anteriormente, é uma ameaça ao surgimento de um novo inchaço.A segunda solução é mais complicada, mas provavelmente mais correta: crie uma coluna na tabela de log com o identificador da transação que adicionou os dados à tabela. Em seguida, ao copiar dados, poderemos agrupá-los por esse atributo e garantir que as alterações relacionadas sejam transferidas juntas. Um lote será formado a partir de várias transações (ou uma grande) e seu tamanho variará dependendo da quantidade de dados alterados nessas transações. É importante observar que, como os dados de diferentes transações caem na tabela de logs em ordem aleatória, não será possível lê-los sequencialmente, como antes. o seqscan para cada solicitação filtrada por tx_id é muito caro, você precisa de um índice, mas ele atrasará o método devido à sobrecarga de atualizá-lo. Em geral, como sempre, você precisa sacrificar alguma coisa.Então, decidimos começar com a primeira opção, como uma mais simples. Primeiro, era necessário entender se uma transação longa seria um problema real. Como a principal transferência de dados da tabela antiga para a nova também ocorre em uma transação longa, a pergunta se transformou em "quanto aumentaremos essa transação?" A duração da primeira transação depende principalmente do tamanho da tabela. A duração do novo depende de quantas alterações se acumulam na tabela durante a transferência de dados, ou seja, a partir da intensidade da carga. A execução do pg_repack ocorreu durante a carga mínima no serviço e a quantidade de alterações foi incomparavelmente pequena em comparação com o tamanho da tabela original. Decidimos que podemos negligenciar o tempo da nova transação (para comparação, isso é uma média de 1 hora e 2-3 minutos).As experiências foram positivas. Correndo no prod também. Para maior clareza, uma imagem com o tamanho de uma das bases após a execução: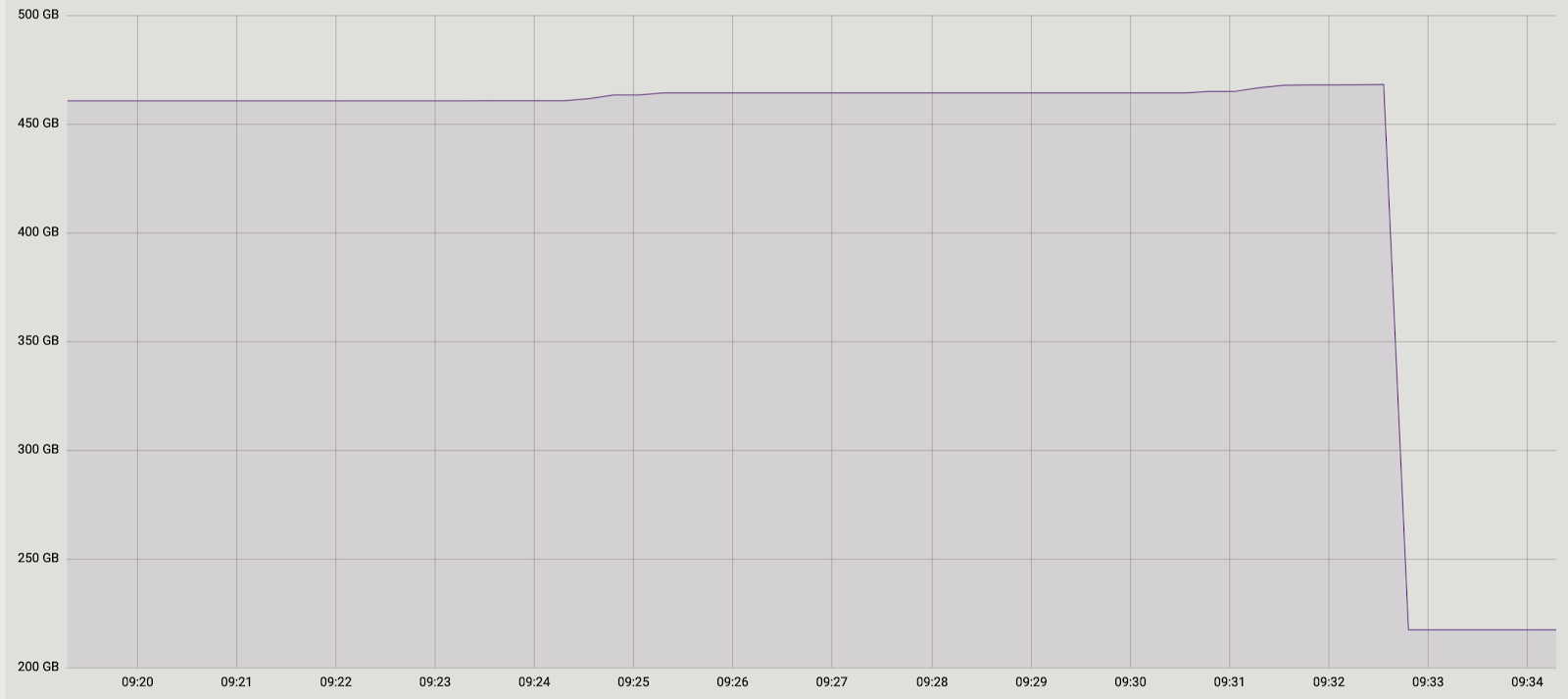 Como essa solução nos serviu completamente, não tentamos implementar a segunda, mas estamos pensando em discuti-la com os desenvolvedores da extensão. Infelizmente, nossa revisão atual ainda não está pronta para publicação, pois resolvemos o problema apenas com restrições pendentes exclusivas e, para um patch de pleno direito, é necessário dar suporte a outros tipos. Esperamos poder fazer isso no futuro.Talvez você tenha uma pergunta, por que nos envolvemos nessa história com a conclusão de pg_repack e, por exemplo, não usamos seus análogos? Em algum momento, também pensamos nisso, mas a experiência positiva de usá-lo anteriormente, em tabelas sem restrições pendentes, nos motivou a tentar entender a essência do problema e corrigi-lo. Além disso, para usar outras soluções, também leva tempo para a realização de testes, por isso decidimos que primeiro tentaríamos resolver o problema e, se percebermos que não poderíamos fazê-lo em um período de tempo razoável, começaríamos a considerar análogos.
Como essa solução nos serviu completamente, não tentamos implementar a segunda, mas estamos pensando em discuti-la com os desenvolvedores da extensão. Infelizmente, nossa revisão atual ainda não está pronta para publicação, pois resolvemos o problema apenas com restrições pendentes exclusivas e, para um patch de pleno direito, é necessário dar suporte a outros tipos. Esperamos poder fazer isso no futuro.Talvez você tenha uma pergunta, por que nos envolvemos nessa história com a conclusão de pg_repack e, por exemplo, não usamos seus análogos? Em algum momento, também pensamos nisso, mas a experiência positiva de usá-lo anteriormente, em tabelas sem restrições pendentes, nos motivou a tentar entender a essência do problema e corrigi-lo. Além disso, para usar outras soluções, também leva tempo para a realização de testes, por isso decidimos que primeiro tentaríamos resolver o problema e, se percebermos que não poderíamos fazê-lo em um período de tempo razoável, começaríamos a considerar análogos.achados
O que podemos recomendar com base em nossa própria experiência:- Monitore seu inchaço. Com base nos dados de monitoramento, você pode entender como o vácuo automático está configurado.
- Defina AUTOVACUUM para manter o inchaço em um nível razoável.
- bloat “ ”, . – .
- – , .