Certa vez, um colega compartilhou seus pensamentos sobre a API para clusters de computação distribuída, e eu respondi brincando: "Obviamente, uma API ideal seria uma chamada simples, telefork()para que seu processo acorde em cada máquina do cluster, retornando o valor do ID da instância". Mas no final, essa ideia tomou conta de mim. Eu não conseguia entender por que é tão estúpido e simples, muito mais simples do que qualquer API para trabalho remoto, e por que os sistemas de computadores não parecem capazes disso. Eu também parecia entender como isso pode ser implementado, e eu já tinha um bom nome, que é a parte mais difícil de qualquer projeto. Então eu comecei a trabalhar.No primeiro final de semana, ele fez um protótipo básico, e no segundo final de semana trouxe uma demonstração que poderiaCom o que se parece
Eu implementei o código como uma biblioteca Rust, mas teoricamente você pode agrupar o programa na API C e executar as ligações da FFI para teleportar até o processo Python. A implementação é apenas cerca de 500 linhas de código (mais 200 linhas de comentários):use telefork::{telefork, TeleforkLocation};
fn main() {
let args: Vec<String> = std::env::args().collect();
let destination = args.get(1).expect("expected arg: address of teleserver");
let mut stream = std::net::TcpStream::connect(destination).unwrap();
match telefork(&mut stream).unwrap() {
TeleforkLocation::Child(val) => {
println!("I teleported to another computer and was passed {}!", val);
}
TeleforkLocation::Parent => println!("Done sending!"),
};
}
Também escrevi um ajudante chamado yoyoteleforks para o servidor, executa o fechamento transmitido e depois os teleforks de volta. Isso cria a ilusão de que você pode executar facilmente um pedaço de código em um servidor remoto, por exemplo, com muito maior poder de processamento.
let scene = create_scene();
let mut backbuffer = vec![Vec3::new(0.0, 0.0, 0.0); width * height];
telefork::yoyo(destination, || {
render_scene(&scene, width, height, &mut backbuffer);
});
save_png_file(width, height, &backbuffer);
Anatomia do processo Linux
Vamos ver como é o processo no Linux (no qual o sistema operacional host mãe está sendo executado telefork):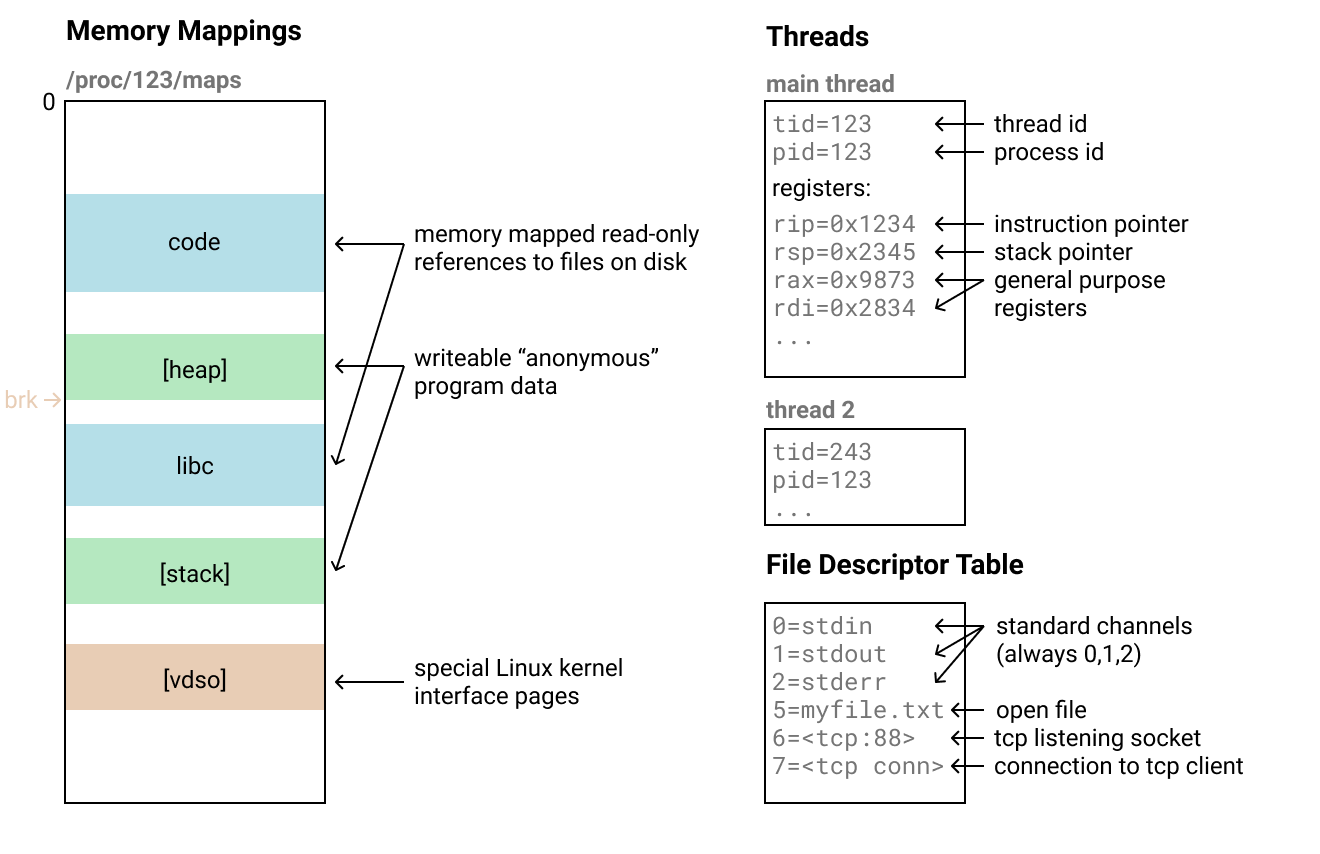
- (memory mappings): , . «» 4 .
/proc/<pid>/maps. , , .
- : , . , , - , , , . , .
- : , . - , . , , , TCP-, .
- . stdin/stdout/stderr, 0, 1 2.
- , , , .
- Diversos : Existem outras partes do estado do processo que variam na complexidade da replicação. Mas na maioria dos casos eles não importam, por exemplo, brk (ponteiro de heap). Alguns deles podem ser restaurados apenas com a ajuda de truques estranhos ou chamadas especiais do sistema, como PR_SET_MM_MAP , o que complica a recuperação.
Assim, a implementação básica teleforkpode ser feita com um simples mapeamento de memória e registros dos principais threads. Isso deve ser suficiente para programas simples que executam principalmente cálculos sem interagir com os recursos do SO, como arquivos (em princípio, para o teletransporte, basta abrir o arquivo no sistema e fechá-lo antes de chamar telefork).Como teleforcar um processo
Não fui o primeiro a pensar em recriar processos em outra máquina. Portanto, o depurador rr e o depurador de gravação fazem coisas muito semelhantes . Enviei algumas perguntas ao autor deste programa @rocallahan , e ele me falou sobre o sistema CRIU para migração "quente" de contêineres entre hosts. A CRIU pode transferir o processo Linux para outro sistema, suporta a recuperação de todos os tipos de descritores de arquivos e outros estados; no entanto, o código é realmente complexo e usa muitas chamadas de sistema que requerem assemblies de kernel especiais e permissões de raiz. Usando o link da página wiki da CRIU, encontrei o DMTCP criado para capturas instantâneas de tarefas distribuídas em supercomputadores, para que possam ser reiniciadas mais tarde, e este programaO código acabou sendo mais simples .Esses exemplos não me forçaram a abandonar as tentativas de implementar meu próprio sistema, pois esses são programas extremamente complexos que requerem corredores e infraestrutura especiais, e eu queria implementar o mais simples possível teletransporte de processos como uma chamada de biblioteca. Então, estudei os fragmentos do código-fonte rr, CRIU, DMTCP e alguns exemplos de ptrace - e montei meu próprio procedimento telefork. Meu método funciona à sua maneira, é uma mistura de várias técnicas.Para se teletransportar um processo, você precisa fazer algum trabalho no processo original que chama teleforke algum trabalho ao lado da chamada de função, que recebe o processo de streaming no servidor e o recria do fluxo (funçãotelepad) Eles podem ocorrer ao mesmo tempo, mas toda a serialização também pode ser feita antes do download, por exemplo, soltando-o em um arquivo e depois baixando-o.A seguir, é apresentada uma visão geral simplificada dos dois processos. Se você quiser entender em detalhes, sugiro ler o código fonte . Ele está contido em um arquivo e é fortemente comentado para ler em ordem e entender como tudo funciona.Enviando um processo usando telefork
A função teleforkrecebe um fluxo com capacidade de gravação, pelo qual transfere todo o estado do seu processo.- «» . , , . fork .
- .
/proc/<pid>/maps , . proc_maps crate.
- . DMTCP, , , . ,
[vdso], , , .
- . , , process_vm_readv , .
- Registros de transferência . Eu uso a opção
PTRACE_GETREGSpara a chamada do sistema ptrace . Permite obter todos os valores do registro do processo filho. Depois, escrevo-as em uma mensagem no canal.
Executando chamadas do sistema em um processo filho
Para transformar o processo de destino em uma cópia do processo de entrada, você precisará forçar o processo a executar várias chamadas de sistema, sem acesso a nenhum código, porque excluímos tudo. Fazemos chamadas remotas do sistema usando o ptrace , uma chamada universal do sistema para manipular e verificar outros processos:- syscall. syscall , . ,
process_vm_readv [vdso] , , , syscall Linux, . , [vdso].
- ,
PTRACE_SETREGS. syscall, rax Linux, rdi, rsi, rdx, r10, r8, r9.
- Dê um passo usando o parâmetro
PTRACE_SINGLESTEPpara executar o comando syscall.
- Leia os registradores com
PTRACE_GETREGSpara restaurar o valor de retorno syscall e veja se foi bem-sucedido.
Aceitação do processo em telepad
Usando isso e as primitivas já descritas, podemos recriar o processo:- Garfo um processo filho congelado . Semelhante ao envio, mas desta vez precisamos de um processo filho que possamos manipular para transformá-lo em um clone do processo transferido.
- Verifique os cartões de alocação de memória . Desta vez, precisamos conhecer todos os cartões de alocação de memória existentes para removê-los e abrir espaço para o processo de entrada.
- . ,
munmap.
- .
mremap, .
- .
mmap , process_vm_writev .
- .
PTRACE_SETREGS , , rax. raise(SIGSTOP), . , telepad.
- Um valor arbitrário é usado para que o servidor de telefork possa transferir o descritor de arquivo da conexão TCP para a qual o processo entrou e pode enviar dados de volta ou, no caso
yoyo, teleportar de volta para a mesma conexão.
- Reinicie o processo com o novo conteúdo usando
PTRACE_DETACH.
Implementação mais competente
Algumas partes da minha implementação de telefork não são perfeitamente projetadas. Eu sei como corrigi-los, mas na forma atual eu gosto do sistema, e às vezes eles são realmente difíceis de corrigir. Aqui estão alguns exemplos interessantes:- (vDSO).
mremap vDSO , DMTCP, , . vDSO, . - , CPU glibc vDSO . , vDSO, syscall, rr, vDSO vDSO .
brk . DMTCP, , brk , brk . , , — PR_SET_MM_MAP, .
- . Rust « », , FS GS, , , -
glibc pid tid, . CRIU, PID TID .
- . , , , / , / FUSE. , TCP-, DMTCP CRIU ,
perf_event_open.
- .
fork() Unix , , .
Acho que você já entendeu que, com as interfaces de baixo nível corretas, é possível implementar algumas coisas loucas que pareciam impossíveis para alguém. Aqui estão algumas reflexões sobre como desenvolver as idéias básicas do telefork. Embora muitas das opções acima possam provavelmente ser totalmente implementadas apenas em um kernel completamente novo ou fixo:- Telefork de cluster . A fonte inicial de inspiração para o telefork foi a idéia de transmitir um processo para todas as máquinas em um cluster de computação. Pode até implementar métodos multicast UDP ou ponto a ponto para acelerar a distribuição em todo o cluster. Você provavelmente também deseja ter primitivas de comunicação.
- . CRIU , -
userfaultfd. , SIGSEGV mmap. , , — .
- ! , .
userfaultfd userfaultfd, , , MESI, . , , . — , . , , , . : syscall, -, syscall, . , . , , , . , , . , , ( , ) , .
Eu realmente gosto muito, porque aqui está um exemplo de uma das minhas técnicas favoritas - mergulhar em uma camada de abstração menos conhecida, que cumpre com relativa facilidade o que pensávamos ser quase impossível. Os cálculos de teletransporte podem parecer impossíveis ou muito difíceis. Você pode pensar que seria necessário métodos como serializar todo o estado, copiar o executável binário na máquina remota e iniciá-lo lá com sinalizadores de linha de comando especiais para recarregar o estado. Mas não, tudo é muito mais simples. Sob sua linguagem de programação favorita, há uma camada de abstração onde você pode escolher um subconjunto de funções bastante simples - e, no fim de semana, implementar o teletransporte dos cálculos mais puros em qualquer linguagem de programação em 500 linhas de código. eu acho queque esse mergulho para outro nível de abstração muitas vezes leva a soluções mais simples e mais universais. Outro dos meus projetos como este éNumderline .À primeira vista, esses projetos parecem ser hacks extremos e, em grande parte, são. Eles fazem coisas como ninguém espera e, quando quebram, fazem isso no nível da abstração, no qual programas semelhantes não devem funcionar - por exemplo, os descritores de arquivos desaparecem misteriosamente. Mas, às vezes, você pode definir corretamente o nível de abstração e codificar todas as situações possíveis, para que, no final, tudo funcione de maneira suave e mágica. Acho que os bons exemplos aqui são rr (embora o telefork tenha conseguido demiti-lo) e a migração na nuvem de máquinas virtuais em tempo real (de fato, o telefork no nível do hypervisor).Também gosto de apresentar essas coisas como idéias para formas alternativas de trabalhar com sistemas de computadores. Por que nossas APIs de computação em cluster são muito mais complicadas do que um programa simples que converte funções em um cluster? Por que a programação do sistema de rede é muito mais complicada que a multithread? Obviamente, você pode dar todos os tipos de boas razões, mas elas geralmente se baseiam em como é difícil fazer um exemplo dos sistemas existentes. Ou talvez com a abstração correta ou com esforço suficiente, tudo funcione de maneira fácil e sem problemas? Fundamentalmente, não há nada impossível.
