Introdução
Se você não dormiu demais nos últimos dois anos, certamente ouviu falar de transformadores - a arquitetura da atenção canônica é tudo que você precisa . Por que os transformadores são tão bons? Por exemplo, eles evitam a recorrência, o que lhes permite criar com eficiência uma representação de dados na qual muitas informações contextuais podem ser compactadas, o que afeta positivamente a capacidade de gerar textos e a capacidade inigualável de transferir o aprendizado.
Os Transformers lançaram uma avalanche de trabalho em modelagem de linguagem - uma tarefa na qual o modelo seleciona a palavra seguinte, levando em consideração as probabilidades das palavras anteriores, ou seja, aprendendo p(x)onde está o xtoken atual. Como você pode imaginar, essa tarefa não requer marcação e, portanto, você pode usar enormes matrizes de texto não anotadas. Um modelo de linguagem já treinado pode gerar texto tão bem que os autores às vezes se recusam a criar modelos treinados .
Mas e se quisermos adicionar algumas "canetas" à geração de texto? Por exemplo, faça geração condicional configurando um tema ou controlando outros atributos. Esse formulário já requer probabilidade condicional p(x|a), onde aé o atributo desejado. Interessante? Vamos ao que interessa!
Os autores do artigo oferecem uma abordagem simples (e, portanto, Plug and Play) e elegante à geração condicional, usando um modelo pesado de linguagem pré-treinada (doravante LM) e vários classificadores simples, assim amostrando a partir de uma distribuição de visualização p(x|a) ∝ p(a|x)p(x). Note-se que o LM original não é modificado de forma alguma. Os autores propõem duas formas de classificadores, denominados modelos de atributos no artigo: BoW para controle de tópicos e um classificador linear para controle de tonalidade. Os autores fazem uma análise bastante detalhada de suas principais contribuições, comparando as idéias e abordagens de seu método com outros artigos. Um dos pontos mais importantes é a facilidade de abordagem, e aqui, talvez, apenas observe esta placa:
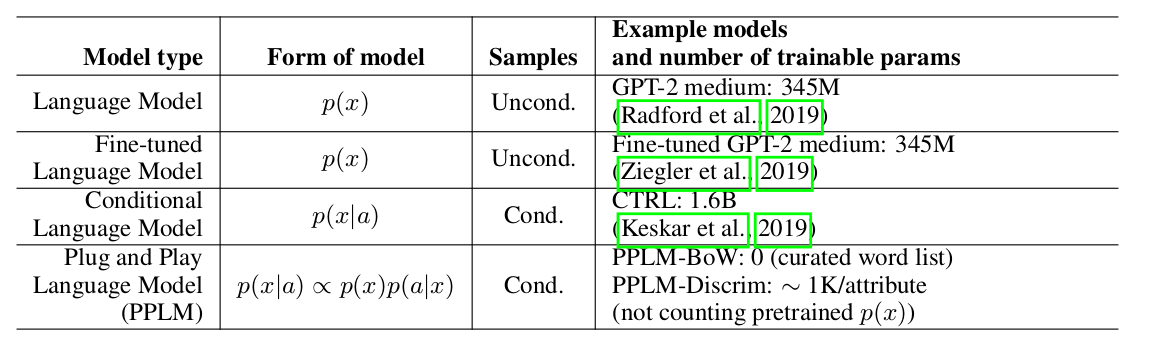
pode-se ver que o PPLM supera todos os concorrentes no número de parâmetros.
Decodificação ponderada 2.0
Uber weighted decoding: , . , , . , . , , , .
Uber : , LM, . , , , ( , ) . ( perturb_past — , .
? log-likelihood: p(x) a attribute model p(a|x). , backward pass .
log-likelihood? , :
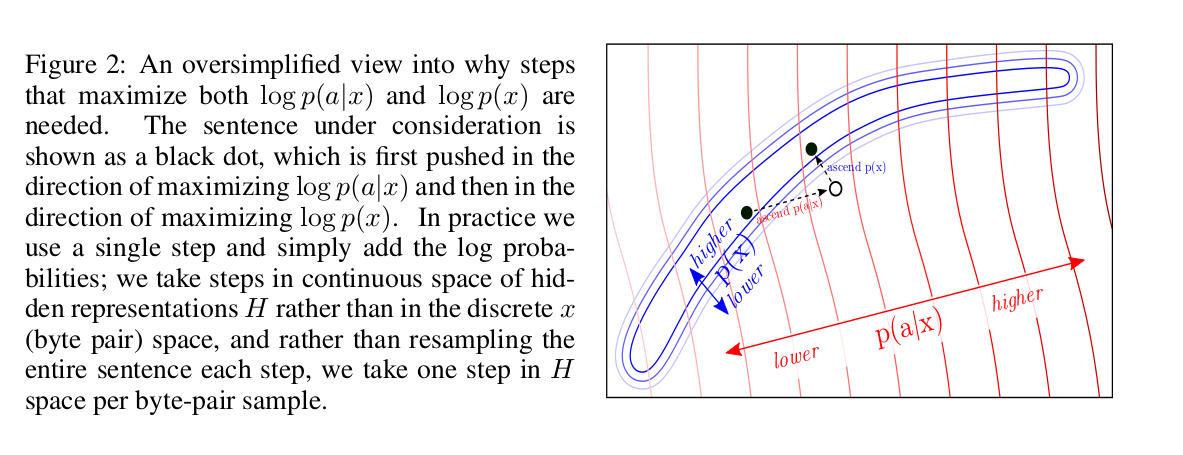
, , LM. , fluency LM.
, :

forward pass LM, p(a|x) — attribute model. backward pass, , attribute model, , . , .
, : “” k k forward backward pass’, n. LM forward pass. , : ( num of iterations=3 gen length=5, ).
, ( colab , ) , , , “the kitten” “military” :
- The kitten is a creature with no real personality, it is just a pet. You can use it as a combat item.
- The kitten that is now being called the "suspected killer" of a woman in a San Diego apartment complex was shot by another person who then shot him, according to authorities.
combat, shot, killer — , military. LM :
- The kitten that escaped a cage has been rescued from a cat sanctuary in Texas.
- The cat, named "Lucky," was found wandering in the back yard of the Humane Society at the time of the incident on Friday.
attribute models
, BoW discriminator. :
p_t+1 — LM, w_i — i- .
Discriminator model , BoW, , , , . , .
, LM, LM weighted decoding CTRL (conditional LM). fluency , , perplexity . PPLM :
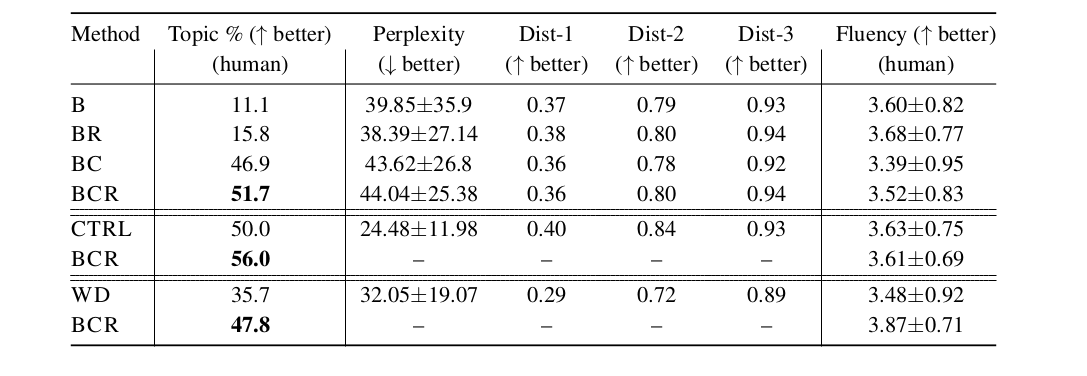
:
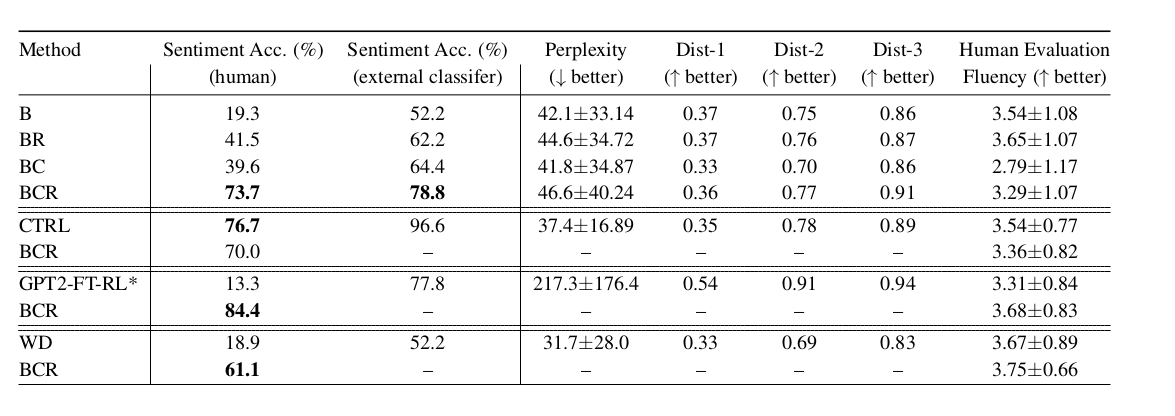
- B — baseline, GPT-2 LM;
- BR — , B,
r , log-likelihood ; - BC — , ;
- BCR — , BC,
r , log-likelihood ; - CTRL — Keskar et al, 2019;
- GPT2-FT-RL — GPT2, fine-tuned RL ;
- WD — weighted decoding,
p(a|x);
— , LM, . , , - :)