
Recentemente, conduzi um estudo em que era necessário processar várias centenas de milhares de conjuntos de dados de entrada. Para cada conjunto - realize alguns cálculos, colete os resultados de todos os cálculos juntos e selecione o "melhor" de acordo com alguns critérios. Em essência, este é um ataque de força bruta. O mesmo acontece ao selecionar os parâmetros dos modelos ML usando GridSearch.
No entanto, a partir de algum momento, o tamanho dos cálculos pode se tornar muito grande para um computador, mesmo que você o execute em vários processos usando joblib. Ou, mais precisamente, fica muito tempo para um experimentador impaciente.
E como em um apartamento moderno agora você pode encontrar mais de um computador "sobrecarregado", e a tarefa é claramente adequada ao paralelismo em massa - é hora de montar o cluster doméstico e executar essas tarefas nele.
A biblioteca do Dask ( https://dask.org/ ) é perfeita para criar um "cluster inicial" . É fácil de instalar e não exige em nós, o que reduz seriamente o "nível de entrada" na computação em cluster.
Para configurar seu cluster, você precisa em todos os computadores:
- instalar intérprete python
- dask
- (scheduler) (worker)
, , — , .
(https://docs.dask.org/) . , .
python
Dask pickle, , python.
3.6 3.7 , . 3.8 - pickle.
" ", , , .
Dask
Dask pip conda
pip install dask distributed bokeh
dask, bokeh , , "-" dask dashboard.
. .
gcc, :
- MacOS xcode
- docker image docker-worker, "" ,
python:3.6-slim-buster . , python:3.6.
dask
- . . — .
$ dask-scheduler
- , .
$ dask-worker schedulerhost:8786 --nprocs 4 --nthreads 1 --memory-limit 1GB --death-timeout 120 -name MyWorker --local-directory /tmp/
nprocs / nthreads — , , . GIL -, - , numpy. .memory-limit — , . — - , . , .death-timeout — , - , . -. , , .name — -, . , "" -.local-directory — ,
- Windows
, dask-worker . , , dask-worker .
" " . NSSM (https://www.nssm.cc/).
NSSM, , , . , , - . NSSM .
NSSM . " "
Firewall
firewall: -.
, , -, — . , — . , , .
- . , .
Dask
:
from dask.distributed import Client
client = Client('scheduler_host:port')
— "" , .
, , . pandas, numpy, scikit-learn, tensorflow.
, .
, ? — pip
def install_packages():
try:
import sys, subprocess
subprocess.check_call([sys.executable, '-m', 'pip', 'install', 'mypackage'])
return (0)
except:
return (1)
from dask.distributed import Client
client = Client('scheduler:8786')
client.run(install_packages)
, , . . "" , , .
, , — .
, , Dask .
. Client upload_file(). , .
- , zip.
from dask.distributed import Client
import numpy as np
from my_module import foo
from my_package import bar
def zoo(x)
return (x**2 + 2*x + 1)
x = np.random.rand(1000000)
client = Client('scheduler:8786')
# .
#
r3 = client.map(zoo, x)
# foo bar ,
#
client.upload_file('my_module.py')
client.upload_file('my_package.zip')
#
r1 = client.map(foo, x)
r2 = client.map(bar, x)
joblib
joblib . joblib — :
joblib
from joblib import Parallel, delayed
...
res = Parallel(n_jobs=-1)(delayed(my_proc)(c, ref_data) for c in candidates)
joblib + dask
from joblib import Parallel, delayed, parallel_backend
from dask.distributed import Client
...
client = Client('scheduler:8786')
with parallel_backend('dask'):
res = Parallel(n_jobs=-1)(delayed(my_proc)(c, ref_data) for c in candidates)
, , . , — :

16 , .

— 10-20 , 200.
, - .
from joblib import Parallel, delayed, parallel_backend
from dask.distributed import Client
...
client = Client('scheduler:8786')
with parallel_backend('dask', scatter = [ref_data]):
res = Parallel(n_jobs=-1, batch_size=<N>, pre_dispatch='3*n_jobs')(delayed(my_proc)(c, ref_data) for c in candidates)
batch_size. — , , .
pre_dispatch.
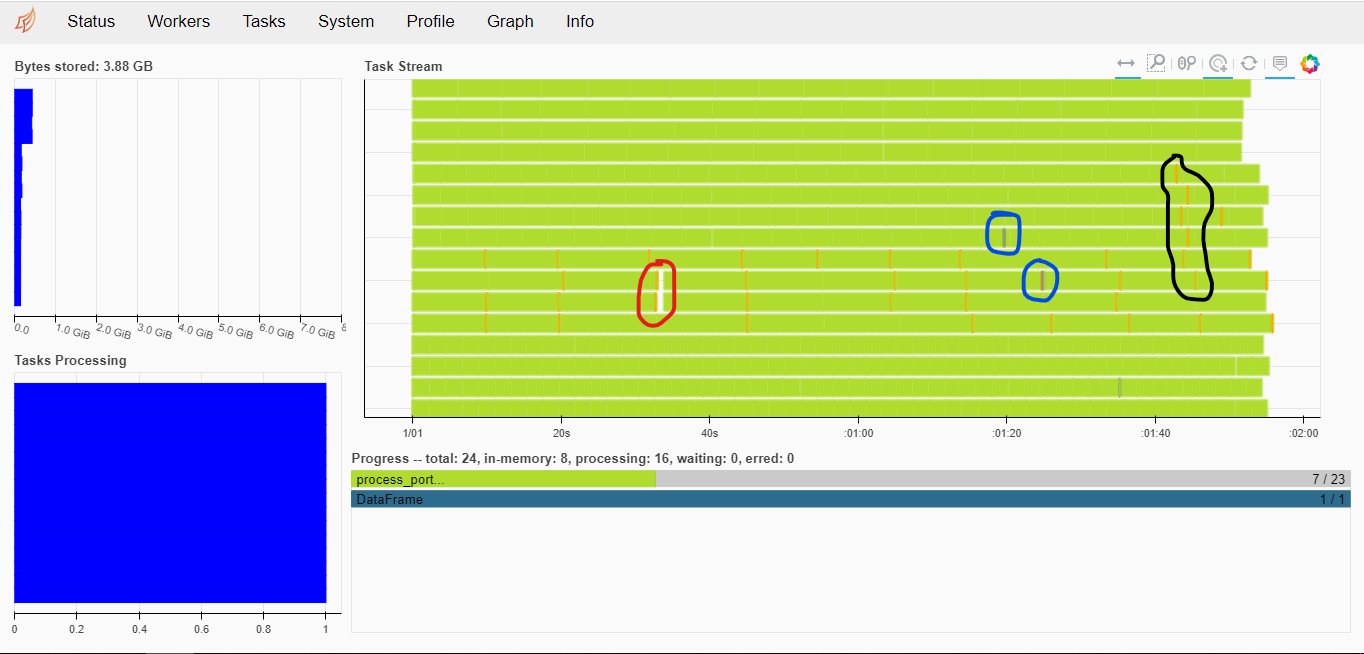
, .
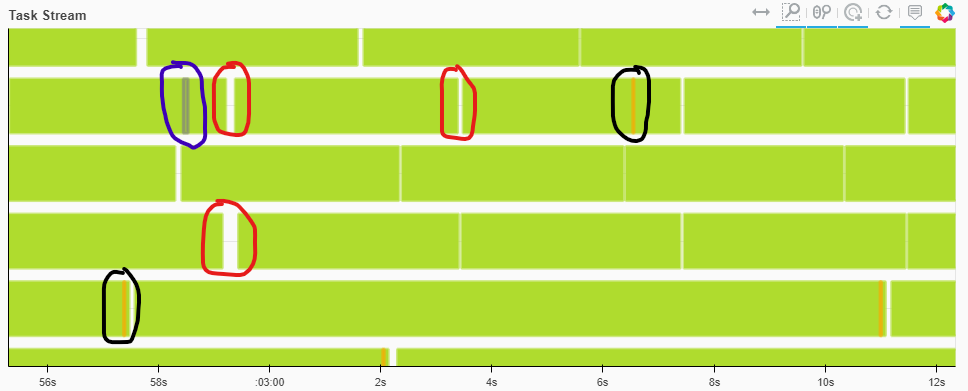
3.5-4 , . : , - , , .
, batch_size pre_dispatch . 8-10 .
, , - (, , ), scatter. .
, .
GridSearchCV
scikit-learn joblib , — dask
:
...
lr = LogisticRegression(C=1, solver="liblinear", penalty='l1', max_iter=300)
grid = {"C": 10.0 ** np.arange(-2, 3)}
cv = GridSearchCV(lr, param_grid=grid, n_jobs=-1, cv=3,
scoring='f1_weighted',
verbose=True, return_train_score=True )
client = Client('scheduler:8786')
with joblib.parallel_backend('dask'):
cv.fit(x1, y)
clf = cv.best_estimator_
print("Best params:", cv.best_params_)
print("Best score:", cv.best_score_)
:
Fitting 3 folds for each of 5 candidates, totalling 15 fits
[Parallel(n_jobs=-1)]: Using backend DaskDistributedBackend with 12 concurrent workers.
[Parallel(n_jobs=-1)]: Done 8 out of 15 | elapsed: 2.0min remaining: 1.7min
[Parallel(n_jobs=-1)]: Done 15 out of 15 | elapsed: 16.1min finished
/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/sklearn/linear_model/_logistic.py:1539: UserWarning: 'n_jobs' > 1 does not have any effect when 'solver' is set to 'liblinear'. Got 'n_jobs' = 16.
" = {}.".format(effective_n_jobs(self.n_jobs)))
Best params: {'C': 10.0}
Best score: 0.9748830491726451
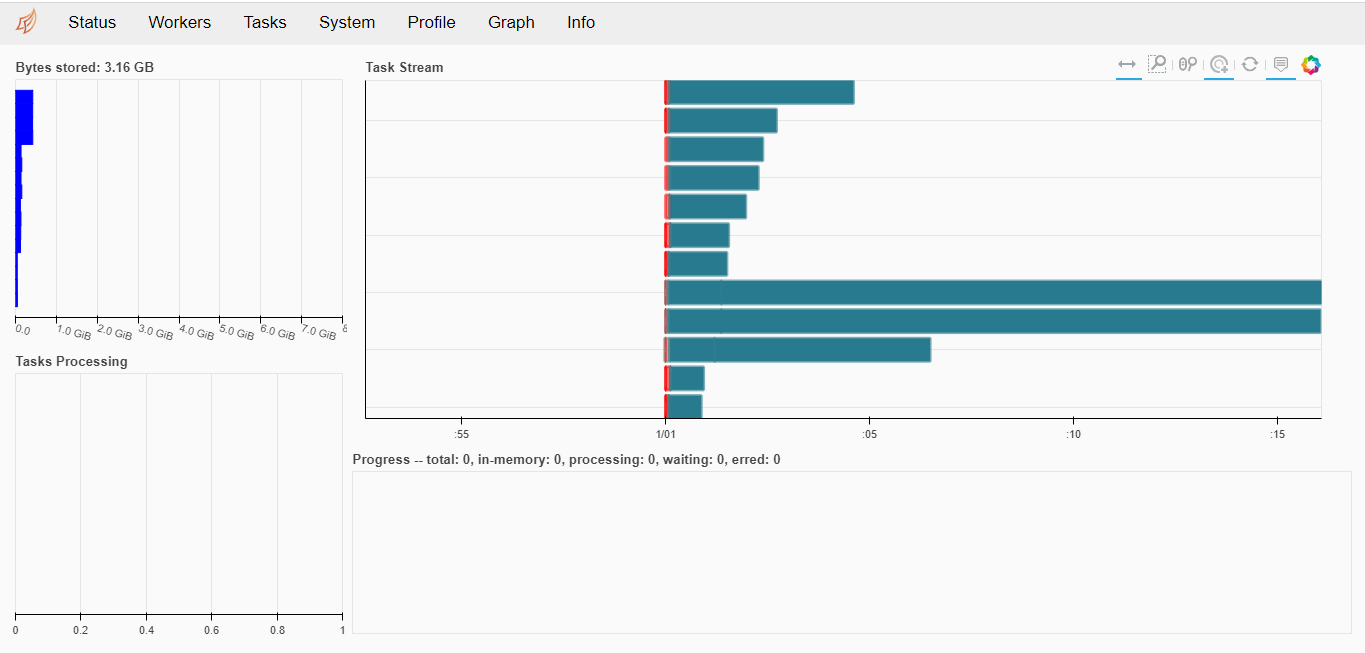
dask. -.
— .
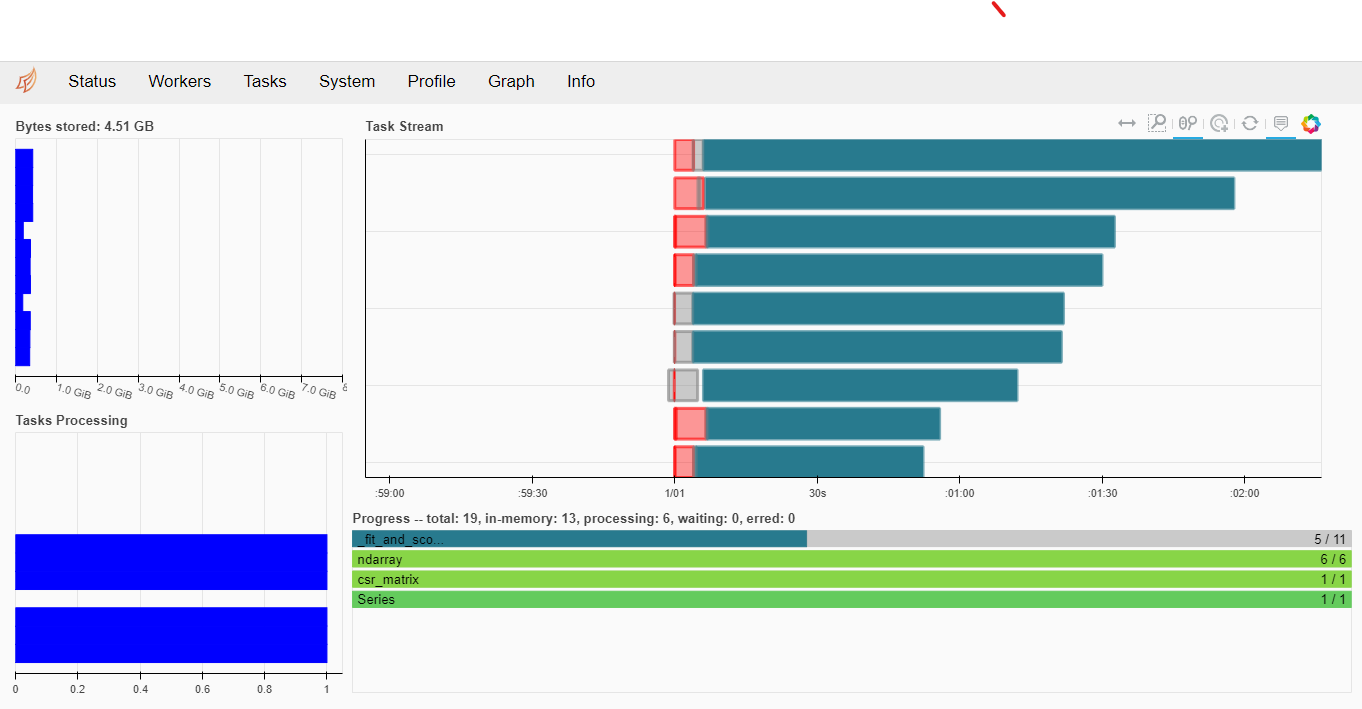
, ( ) — . — .
A biblioteca Dask é uma ótima ferramenta para dimensionar para uma classe específica de tarefas. Mesmo se você usar apenas o básico dask.distributed e deixar de lado as extensões especializadas dask.dataframe, dask.array, dask.ml - poderá acelerar significativamente os experimentos. Em alguns casos, uma aceleração quase linear dos cálculos pode ser alcançada.
E tudo isso se baseia no que você já tem em casa e é usado para assistir a vídeos, rolar através de feeds de notícias ou jogos intermináveis. Use esses recursos ao máximo!