 A Internet está cheia de artigos sobre modelos de linguagem baseados em N-gram. Ao mesmo tempo, existem poucas bibliotecas prontas para o trabalho.Existem KenLM , SriLM e IRSTLM . Eles são populares e usados em muitos projetos grandes. Mas há problemas:
A Internet está cheia de artigos sobre modelos de linguagem baseados em N-gram. Ao mesmo tempo, existem poucas bibliotecas prontas para o trabalho.Existem KenLM , SriLM e IRSTLM . Eles são populares e usados em muitos projetos grandes. Mas há problemas:- As bibliotecas são antigas, não estão em desenvolvimento.
- Suporte deficiente para o idioma russo.
- Trabalhe apenas com texto limpo e especialmente preparado
- Suporte deficiente para UTF-8. Por exemplo, SriLM com o tolower bandeira quebra a codificação.
O KenLM
se destaca um pouco da lista . É regularmente suportado e não apresenta problemas com o UTF-8, mas também é exigente quanto à qualidade do texto.Uma vez eu precisei de uma biblioteca para construir um modelo de linguagem. Depois de muitas tentativas e erros, cheguei à conclusão de que preparar um conjunto de dados para ensinar um modelo de linguagem é muito complicado e um processo longo. Especialmente se for russo ! Mas eu queria de alguma forma automatizar tudo.Em sua pesquisa, ele começou na biblioteca do SriLM . Observarei imediatamente que este não é um empréstimo de código ou bifurcação do SriLM . Todo o código é escrito completamente do zero.Um pequeno exemplo de texto:
! .
A falta de espaço entre as frases é um erro de digitação bastante comum. É difícil encontrar esse erro em uma grande quantidade de dados, enquanto quebra o tokenizador.Após o processamento, o seguinte N-grama aparecerá no modelo de idioma:
-0.3009452 !
Obviamente, existem muitos outros problemas, erros de digitação, caracteres especiais, abreviações, várias fórmulas matemáticas ... Tudo isso deve ser tratado corretamente.ANYKS LM ( ALM )
A biblioteca suporta apenas sistemas operacionais Linux , MacOS X e FreeBSD . Não tenho Windows e nenhum suporte está planejado.Breve descrição da funcionalidade
- Suporte para UTF-8 sem dependências de terceiros.
- Suporte para formatos de dados: Arpa, Vocab, Sequência de mapas, N-gramas, Dicionário binário.
- : Kneser-Nay, Modified Kneser-Nay, Witten-Bell, Additive, Good-Turing, Absolute discounting.
- , , , .
- , N-, N- , N-.
- — N-, .
- : , -.
- N- — N-, backoff .
- N- backoff-.
- , : , , , , Python3.
- « », .
- 〈unk〉 .
- N- Python3.
- , .
- . : , , .
- Diferentemente de outros modelos de idioma, o ALM é garantido para coletar todos os N-gramas do texto, independentemente do seu comprimento (exceto o Kneser-Nay modificado). Existe também a possibilidade de registro obrigatório de todos os N-gramas raros, mesmo que eles se encontrem apenas uma vez.
Dos formatos de modelo de idioma padrão, apenas o formato ARPA é suportado . Honestamente, não vejo razão para apoiar todo o zoológico em todos os tipos de formatos.O formato ARPA diferencia maiúsculas de minúsculas e esse também é um problema definitivo.Às vezes, é útil conhecer apenas a presença de dados específicos no N-grama. Por exemplo, você precisa entender a presença de números no grama N, e o significado deles não é tão importante.Exemplo:
, 2
Como resultado, o N-grama entra no modelo de linguagem:
-0.09521468 2
O número específico, neste caso, não importa. A venda na loja pode durar 1 e 3 e quantos dias você quiser.Para resolver esse problema, o ALM usa a tokenização de classe.Tokens suportados
Padrão:〈s〉 - Símbolo do início da frase〈/s〉 - Símbolo do final da frase〈unk〉 - Símbolo de uma palavra desconhecidaNão padrão:〈url〉 - Símbolo do endereço da URL〈num〉 - Símbolo de números (árabe ou romano)〈data〉 - Data do símbolo (18 de julho de 2004 | 18/07/2004)〈time〉 - Time Token (15:44:56)〈abbr〉 - Abreviatura Token (1 | 2 | 20)〉 anum〉 - Pseudo -Token números (T34 | 895-M-86 | 39km)〈math〉 - Token de operações matemáticas (+ | - | = | / | * | ^)〈range〉 - Token do intervalo de números (1-2 | 100-200 | 300- 400)praprox〉- Um token de número aproximado (~ 93 | ~ 95.86 | 10 ~ 20)〉score〉 - Um token de conta numérico (4: 3 | 01:04)〉dimen〉 - Token geral (200x300 | 1920x1080)〈fract〉 - Um token de fração de fração (5/20 | 192/864)〈punct〉 - Token de caractere de pontuação (. | ... |, |! |? |: |;)〈Specl〉 - Token de caractere especial (~ | @ | # | No. |% | & | $ | § | ±)olisolat〉 - Símbolo do símbolo de isolamento ("| '|" | "|„ | “|` | (|) | [|] | {|})É claro que o suporte a cada um dos tokens pode ser desativado se são necessários esses gramas N.Sevocê precisar processar outras tags (por exemplo, você precisa encontrar nomes de países no texto), o ALM suporta conexão de scripts externos em Python3.Um exemplo de um script de detecção de token:
def init():
"""
:
"""
def run(token, word):
"""
:
@token
@word
"""
if token and (token == "<usa>"):
if word and (word.lower() == ""): return "ok"
elif token and (token == "<russia>"):
if word and (word.lower() == ""): return "ok"
return "no"
Esse script adiciona mais duas tags à lista de tags padrão: 〈usa〉 e 〈russia〉 .Além do script para detectar tokens, há suporte para um script para o pré-processamento de palavras processadas. Este script pode alterar a palavra antes de adicionar a palavra ao modelo de idioma.Um exemplo de um script de processamento de texto:
def init():
"""
:
"""
def run(word, context):
"""
:
@word
@context
"""
return word
Essa abordagem pode ser útil se for necessário montar um modelo de linguagem que consiste em lemas ou raízes .Formatos de texto do modelo de idioma suportados pelo ALM
ARPA:
\data\
ngram 1=52
ngram 2=68
ngram 3=15
\1-grams:
-1.807052 1- -0.30103
-1.807052 2 -0.30103
-1.807052 3~4 -0.30103
-2.332414 -0.394770
-3.185530 -0.311249
-3.055896 -0.441649
-1.150508 </s>
-99 <s> -0.3309932
-2.112406 <unk>
-1.807052 T358 -0.30103
-1.807052 VII -0.30103
-1.503878 -0.39794
-1.807052 -0.30103
-1.62953 -0.30103
...
\2-grams:
-0.29431 1-
-0.29431 2
-0.29431 3~4
-0.8407791 <s>
-1.328447 -0.477121
...
\3-grams:
-0.09521468
-0.166590
...
\end\
ARPA é o formato de texto padrão para o modelo de idioma de linguagem natural usado pelo Sphinx / CMU e Kaldi .NGRAMS:
\data\
ad=1
cw=23832
unq=9390
ngram 1=9905
ngram 2=21907
ngram 3=306
\1-grams:
<s> 2022 | 1
<num> 117 | 1
<unk> 19 | 1
<abbr> 16 | 1
<range> 7 | 1
</s> 2022 | 1
244 | 1
244 | 1
11 | 1
762 | 1
112 | 1
224 | 1
1 | 1
86 | 1
978 | 1
396 | 1
108 | 1
77 | 1
32 | 1
...
\2-grams:
<s> <num> 7 | 1
<s> <unk> 1 | 1
<s> 84 | 1
<s> 83 | 1
<s> 57 | 1
82 | 1
11 | 1
24 | 1
18 | 1
31 | 1
45 | 1
97 | 1
71 | 1
...
\3-grams:
<s> <num> </s> 3 | 1
<s> 6 | 1
<s> 4 | 1
<s> 2 | 1
<s> 3 | 1
2 | 1
</s> 2 | 1
2 | 1
2 | 1
2 | 1
2 | 1
2 | 1
</s> 2 | 1
</s> 3 | 1
2 | 1
...
\end\
Ngrams - formato de texto não padrão do modelo de idioma, é uma modificação do formato ARPA .Descrição:- ad - Número de documentos no gabinete
- cw - O número de palavras em todos os documentos do corpus
- unq - Número de palavras únicas coletadas
VOCAB:
\data\
ad=1
cw=23832
unq=9390
\words:
33 244 | 1 | 0.010238 | 0.000000 | -3.581616
34 11 | 1 | 0.000462 | 0.000000 | -6.680889
35 762 | 1 | 0.031974 | 0.000000 | -2.442838
40 12 | 1 | 0.000504 | 0.000000 | -6.593878
330344 47 | 1 | 0.001972 | 0.000000 | -5.228637
335190 17 | 1 | 0.000713 | 0.000000 | -6.245571
335192 1 | 1 | 0.000042 | 0.000000 | -9.078785
335202 22 | 1 | 0.000923 | 0.000000 | -5.987742
335206 7 | 1 | 0.000294 | 0.000000 | -7.132874
335207 29 | 1 | 0.001217 | 0.000000 | -5.711489
2282019644 1 | 1 | 0.000042 | 0.000000 | -9.078785
2282345502 10 | 1 | 0.000420 | 0.000000 | -6.776199
2282416889 2 | 1 | 0.000084 | 0.000000 | -8.385637
3009239976 1 | 1 | 0.000042 | 0.000000 | -9.078785
3009763109 1 | 1 | 0.000042 | 0.000000 | -9.078785
3013240091 1 | 1 | 0.000042 | 0.000000 | -9.078785
3014009989 1 | 1 | 0.000042 | 0.000000 | -9.078785
3015727462 2 | 1 | 0.000084 | 0.000000 | -8.385637
3025113549 1 | 1 | 0.000042 | 0.000000 | -9.078785
3049820849 1 | 1 | 0.000042 | 0.000000 | -9.078785
3061388599 1 | 1 | 0.000042 | 0.000000 | -9.078785
3063804798 1 | 1 | 0.000042 | 0.000000 | -9.078785
3071212736 1 | 1 | 0.000042 | 0.000000 | -9.078785
3074971025 1 | 1 | 0.000042 | 0.000000 | -9.078785
3075044360 1 | 1 | 0.000042 | 0.000000 | -9.078785
3123271427 1 | 1 | 0.000042 | 0.000000 | -9.078785
3123322362 1 | 1 | 0.000042 | 0.000000 | -9.078785
3126399411 1 | 1 | 0.000042 | 0.000000 | -9.078785
…
O vocabulário é um formato de dicionário de texto não padrão no modelo de idioma.Descrição:- oc - ocorrência de caso
- dc - ocorrência em documentos
- tf - (term frequency — ) — . , , : [tf = oc / cw]
- idf - (inverse document frequency — ) — , , : [idf = log(ad / dc)]
- tf-idf - : [tf-idf = tf * idf]
- wltf - , : [wltf = 1 + log(tf * dc)]
MAP:
1:{2022,1,0}|42:{57,1,0}|279603:{2,1,0}
1:{2022,1,0}|42:{57,1,0}|320749:{2,1,0}
1:{2022,1,0}|42:{57,1,0}|351283:{2,1,0}
1:{2022,1,0}|42:{57,1,0}|379815:{3,1,0}
1:{2022,1,0}|42:{57,1,0}|26122748:{3,1,0}
1:{2022,1,0}|44:{6,1,0}
1:{2022,1,0}|48:{1,1,0}
1:{2022,1,0}|51:{11,1,0}|335967:{3,1,0}
1:{2022,1,0}|53:{14,1,0}|371327:{3,1,0}
1:{2022,1,0}|53:{14,1,0}|40260976:{7,1,0}
1:{2022,1,0}|65:{68,1,0}|34:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|3277:{3,1,0}
1:{2022,1,0}|65:{68,1,0}|278003:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|320749:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|11353430797:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|34270133320:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|51652356484:{2,1,0}
1:{2022,1,0}|65:{68,1,0}|66967237546:{2,1,0}
1:{2022,1,0}|2842:{11,1,0}|42:{7,1,0}
…
Mapa - o conteúdo do arquivo, tem um significado puramente técnico. Utilizado em conjunto com o arquivo de vocabulário , você pode combinar vários modelos de idiomas, modificar, armazenar, distribuir e exportar para qualquer formato ( arpa , ngrams , binário alm ).Formatos de arquivo de texto auxiliar suportados pelo ALM
Muitas vezes, ao montar um modelo de linguagem, ocorrem erros de digitação no texto, que substituem as letras (por letras visualmente semelhantes de outro alfabeto).O ALM resolve esse problema com um arquivo com letras de aparência semelhante.p
c
o
t
k
e
a
h
x
b
m
Se, ao ensinar um modelo de idioma, transferir arquivos com uma lista de domínios e abreviações de primeiro nível, o ALM poderá ajudar na detecção mais precisa das tags de classe 〈url〉 e 〈abbr〉 .Arquivo da lista de abreviações:
…
Arquivo de lista de zonas de domínio:
ru
su
cc
net
com
org
info
…
Para uma detecção mais precisa do token 〉url〉 , você deve adicionar suas zonas de domínio de primeiro nível (todas as zonas de domínio do exemplo já estão pré-instaladas) .Contêiner binário do modelo de linguagem do ALM
Para construir um contêiner binário para o modelo de idioma, é necessário criar um arquivo JSON com uma descrição dos seus parâmetros.Opções JSON:
{
"aes": 128,
"name": "Name dictionary",
"author": "Name author",
"lictype": "License type",
"lictext": "License text",
"contacts": "Contacts data",
"password": "Password if needed",
"copyright": "Copyright author"
}
Descrição:- aes - bits de tamanho de criptografia AES (128, 192, 256)
- name - nome do dicionário
- author - Autor do dicionário
- lictype - Tipo de licença
- lictext - Texto da licença
- contatos - detalhes de contato do autor
- password - Senha de criptografia (se necessário), a criptografia é realizada apenas ao definir uma senha
- copyright - direitos autorais do proprietário do dicionário
Todos os parâmetros são opcionais, exceto o nome do contêiner.Exemplos de biblioteca do ALM
Operação do tokenizador
O tokenizer recebe texto na entrada e gera JSON na saída.$ echo 'Hello World?' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
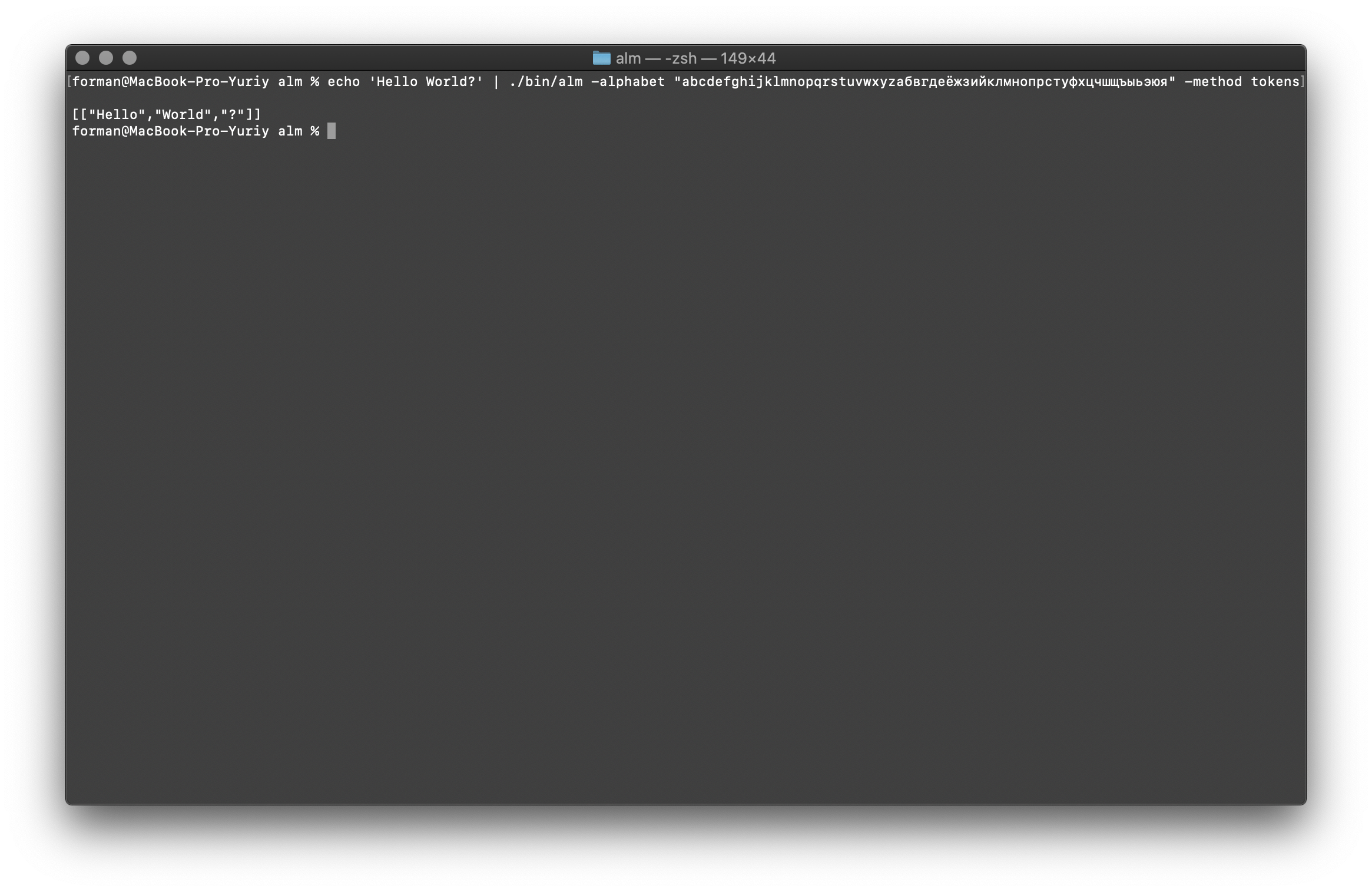 Teste:
Teste:Hello World?
Resultado:[
["Hello","World","?"]
]
Vamos tentar algo mais difícil ...$ echo ' ??? ....' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
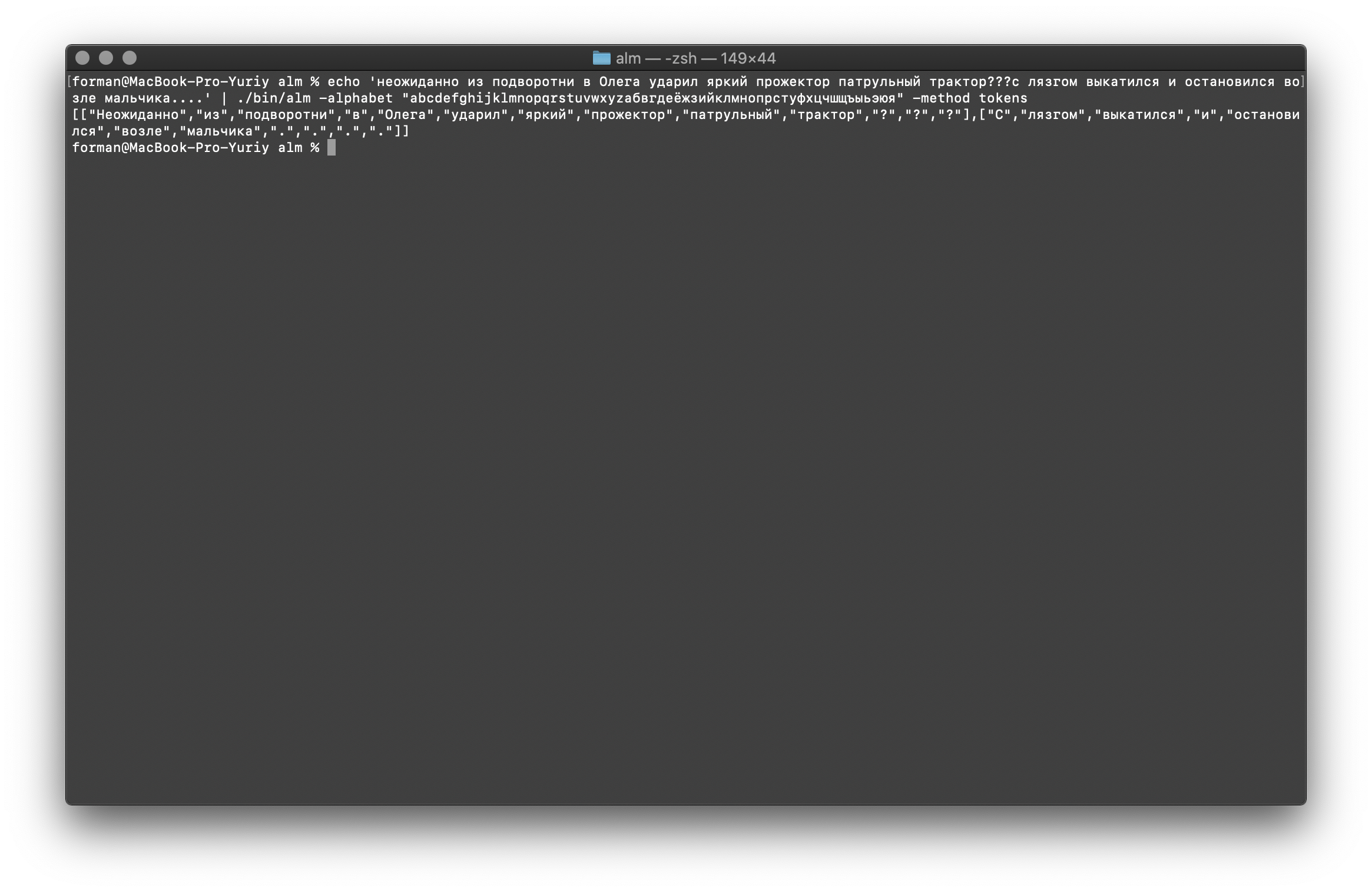 Teste:
Teste: ??? ....
Resultado:[
[
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"?",
"?",
"?"
],[
"",
"",
"",
"",
"",
"",
"",
".",
".",
".",
"."
]
]
Como você pode ver, o tokenizer funcionou corretamente e corrigiu os erros básicos.Mude um pouco o texto e veja o resultado.$ echo ' ... .' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
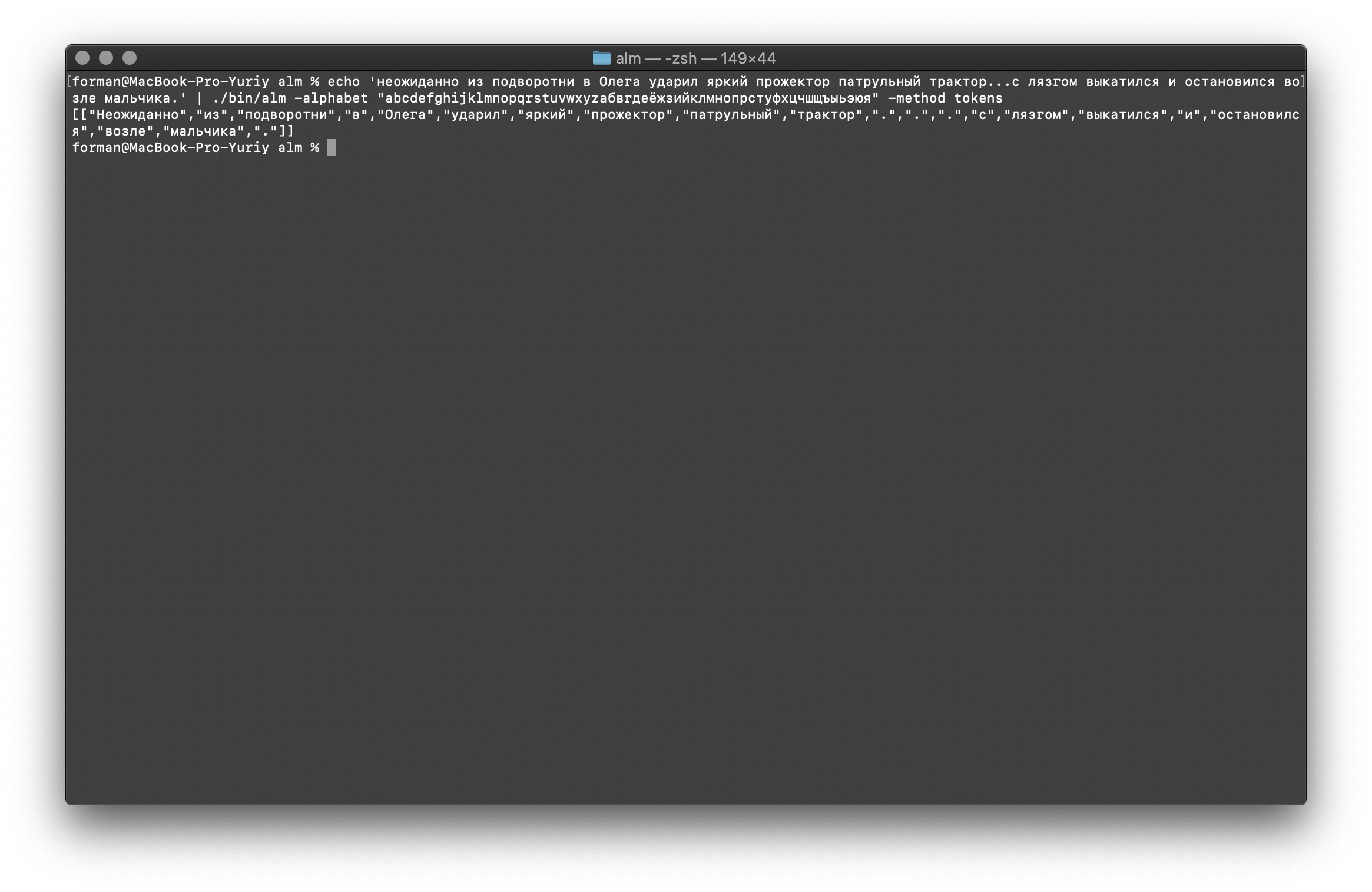 Teste:
Teste: ... .
Resultado:[
[
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
".",
".",
".",
"",
"",
"",
"",
"",
"",
"",
"."
]
]
Como você pode ver, o resultado mudou. Agora tente outra coisa.$ echo ' 5–7 . : 1 . ( +37–38°), 5–10 . – ( +12–15°) ..»| |()' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
 Teste:
Teste: 5–7 . : 1 . ( +37–38°), 5–10 . – ( +12–15°) ..»| |()
Resultado:[
[
"",
"",
"",
"",
"5–7",
".",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
":",
"1",
".",
"",
"",
"(",
"+37–38°",
")",
",",
"",
"5–10",
".",
"–",
"",
"",
"(",
"+12–15°",
")",
"",
"..",
"»",
"|",
"|",
"(",
")"
]
]
Combine tudo de volta ao texto
Primeiro, restaure o primeiro teste.$ echo '[["Hello","World","?"]]' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
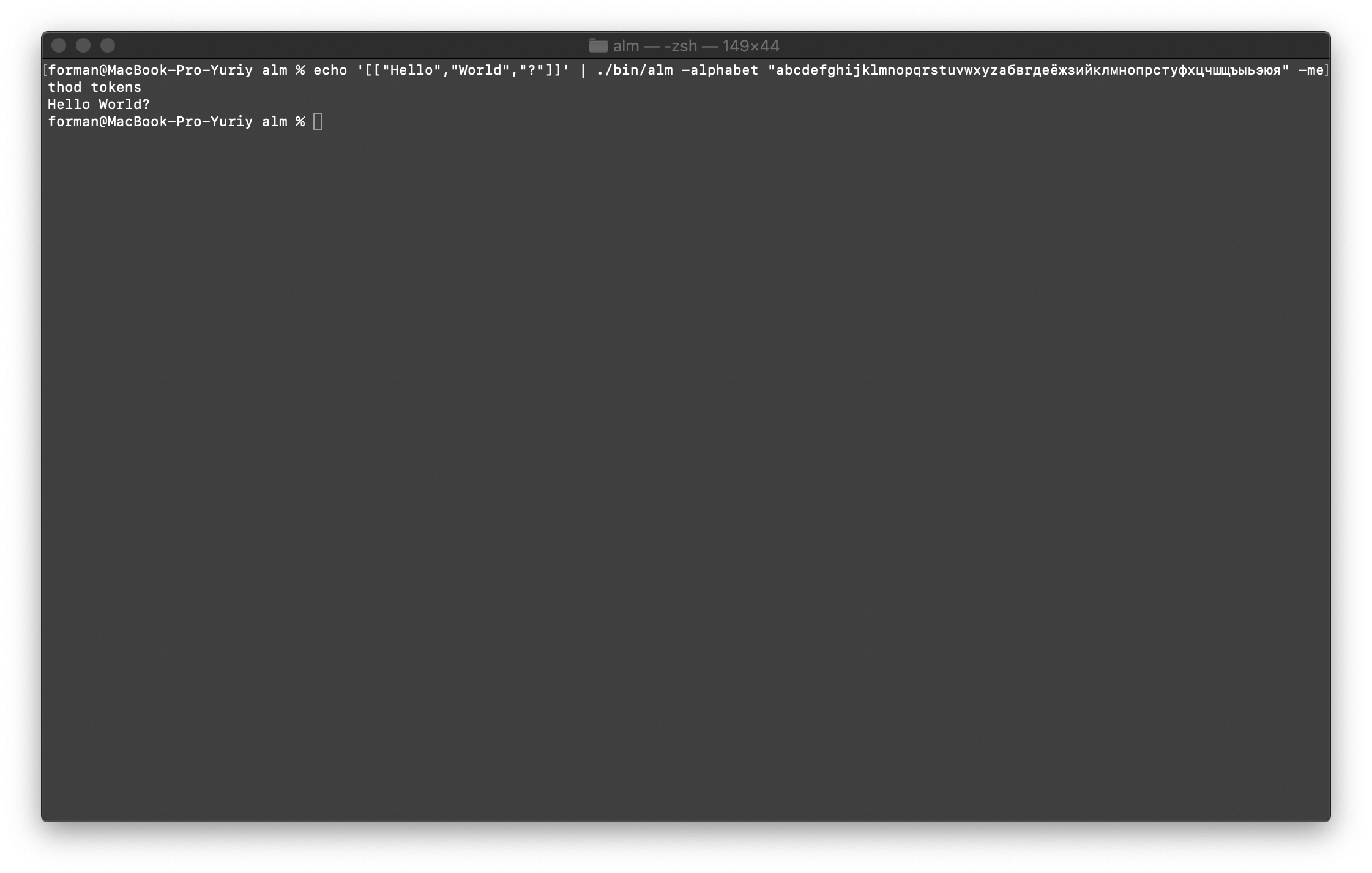 Teste:
Teste:[["Hello","World","?"]]
Resultado:Hello World?
Agora vamos restaurar o teste mais complexo.$ echo '[["","","","","","","","","","","?","?","?"],["","","","","","","",".",".",".","."]]' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
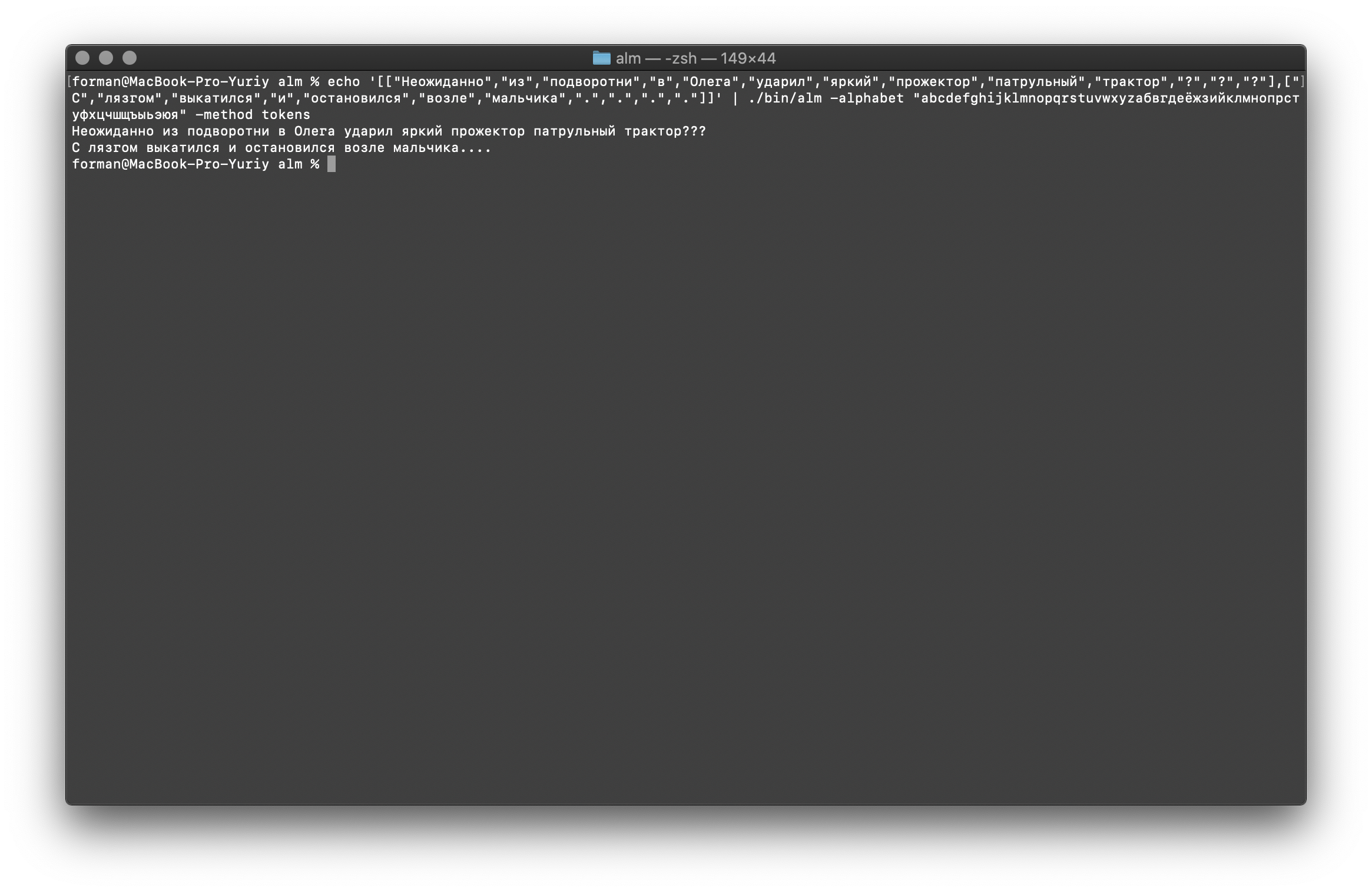 Teste:
Teste:[["","","","","","","","","","","?","?","?"],["","","","","","","",".",".",".","."]]
Resultado: ???
….
Como você pode ver, o tokenizer conseguiu restaurar o texto inicialmente quebrado.Continue.$ echo '[["","","","","","","","","","",".",".",".","","","","","","","","."]]' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
 Teste:
Teste:[["","","","","","","","","","",".",".",".","","","","","","","","."]]
Resultado: ... .
E, finalmente, verifique a opção mais difícil.$ echo '[["","","","","5–7",".","","","","","","","","","","","","","",":","1",".","","","(","+37–38°",")",",","","5–10",".","–","","","(","+12–15°",")","","..","»","|","|","(",")"]]' | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method tokens
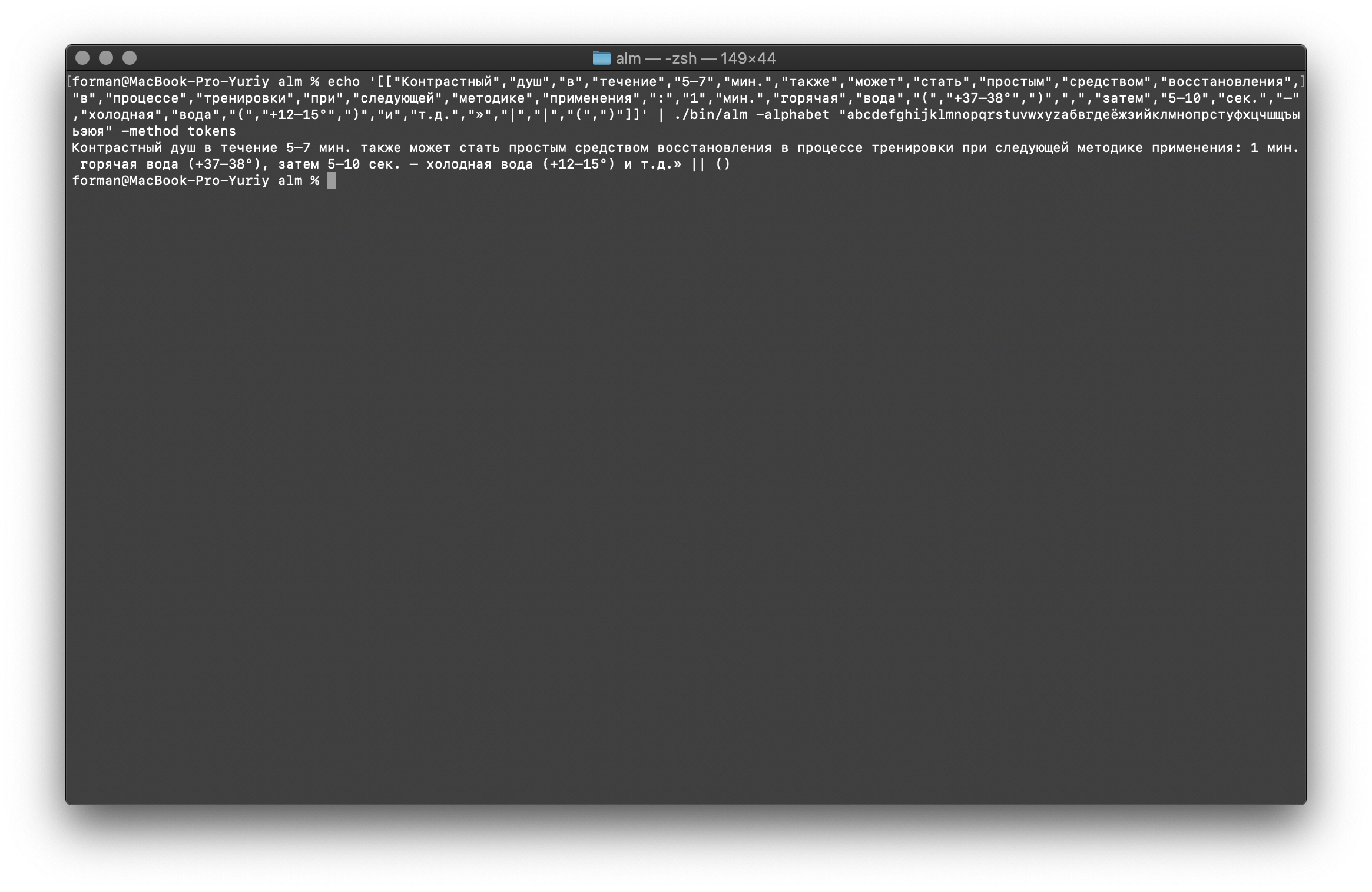 Teste:
Teste:[["","","","","5–7",".","","","","","","","","","","","","","",":","1",".","","","(","+37–38°",")",",","","5–10",".","–","","","(","+12–15°",")","","..","»","|","|","(",")"]]
Resultado: 5–7 . : 1 . (+37–38°), 5–10 . – (+12–15°) ..» || ()
Como pode ser visto nos resultados, o tokenizer pode corrigir a maioria dos erros no design do texto.Treinamento do modelo de linguagem
$ ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -size 3 -smoothing wittenbell -method train -debug 1 -w-arpa ./lm.arpa -w-map ./lm.map -w-vocab ./lm.vocab -w-ngram ./lm.ngrams -allow-unk -interpolate -corpus ./text.txt -threads 0 -train-segments
Descreverei os parâmetros de montagem com mais detalhes.- tamanho - o tamanho do comprimento de N gramas (o tamanho é definido como 3 gramas )
- smoothing - algoritmo de suavização (algoritmo selecionado por Witten-Bell )
- método - Método de trabalho ( treinamento especificado pelo método )
- debug - modo Debug (o indicador de status de aprendizado está definido)
- w-arpa — ARPA
- w-map — MAP
- w-vocab — VOCAB
- w-ngram — NGRAM
- allow-unk — 〈unk〉
- interpolate —
- corpus — . ,
- threads - Use multithreading para treinamento (0 - para treinamento, todos os núcleos de processador disponíveis serão fornecidos,> 0 o número de núcleos participantes do treinamento)
- segmentos de trem - o edifício de treinamento será segmentado igualmente em todos os núcleos
Mais informações podem ser obtidas usando o sinalizador [-help] .
Cálculo de perplexidade
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method ppl -debug 2 -r-arpa ./lm.arpa -confidence -threads 0
 Teste:
Teste: ??? ….
Resultado:info: <s> <punct> <punct> <punct> </s>
info: p( | <s> ) = [2gram] 0.00209192 [ -2.67945500 ] / 0.99999999
info: p( | ...) = [3gram] 0.91439744 [ -0.03886500 ] / 1.00000035
info: p( | ...) = [3gram] 0.86302624 [ -0.06397600 ] / 0.99999998
info: p( | ...) = [3gram] 0.98003368 [ -0.00875900 ] / 1.00000088
info: p( | ...) = [3gram] 0.85783547 [ -0.06659600 ] / 0.99999955
info: p( | ...) = [3gram] 0.95238819 [ -0.02118600 ] / 0.99999897
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( <punct> | ...) = [3gram] 0.78127873 [ -0.10719400 ] / 1.00000031
info: p( <punct> | <punct> ...) = [2gram] 0.29417110 [ -0.53140000 ] / 0.99999998
info: p( <punct> | <punct> ...) = [3gram] 0.51262054 [ -0.29020400 ] / 0.99999998
info: p( </s> | <punct> ...) = [3gram] 0.45569787 [ -0.34132300 ] / 0.99999998
info: 1 sentences, 13 words, 0 OOVs
info: 0 zeroprobs, logprob= -4.18477000 ppl= 1.99027067 ppl1= 2.09848266
info: <s> <punct> <punct> <punct> <punct> </s>
info: p( | <s> ) = [2gram] 0.00809597 [ -2.09173100 ] / 0.99999999
info: p( | ...) = [3gram] 0.19675329 [ -0.70607800 ] / 0.99999972
info: p( | ...) = [3gram] 0.97959599 [ -0.00895300 ] / 1.00000090
info: p( | ...) = [3gram] 0.98007204 [ -0.00874200 ] / 0.99999931
info: p( | ...) = [3gram] 0.85785325 [ -0.06658700 ] / 1.00000018
info: p( | ...) = [3gram] 0.81482810 [ -0.08893400 ] / 1.00000027
info: p( | ...) = [3gram] 0.93507404 [ -0.02915400 ] / 1.00000058
info: p( <punct> | ...) = [3gram] 0.76391493 [ -0.11695500 ] / 0.99999971
info: p( <punct> | <punct> ...) = [2gram] 0.29417110 [ -0.53140000 ] / 0.99999998
info: p( <punct> | <punct> ...) = [3gram] 0.51262054 [ -0.29020400 ] / 0.99999998
info: p( <punct> | <punct> ...) = [3gram] 0.51262054 [ -0.29020400 ] / 0.99999998
info: p( </s> | <punct> ...) = [3gram] 0.45569787 [ -0.34132300 ] / 0.99999998
info: 1 sentences, 11 words, 0 OOVs
info: 0 zeroprobs, logprob= -4.57026500 ppl= 2.40356248 ppl1= 2.60302678
info: 2 sentences, 24 words, 0 OOVs
info: 0 zeroprobs, logprob= -8.75503500 ppl= 2.23975957 ppl1= 2.31629103
info: work time shifting: 0 seconds
Penso que não há nada de especial para comentar, por isso continuaremos mais.Verificação de existência de contexto
$ echo "<s> </s>" | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method checktext -debug 1 -r-arpa ./lm.arpa -confidence
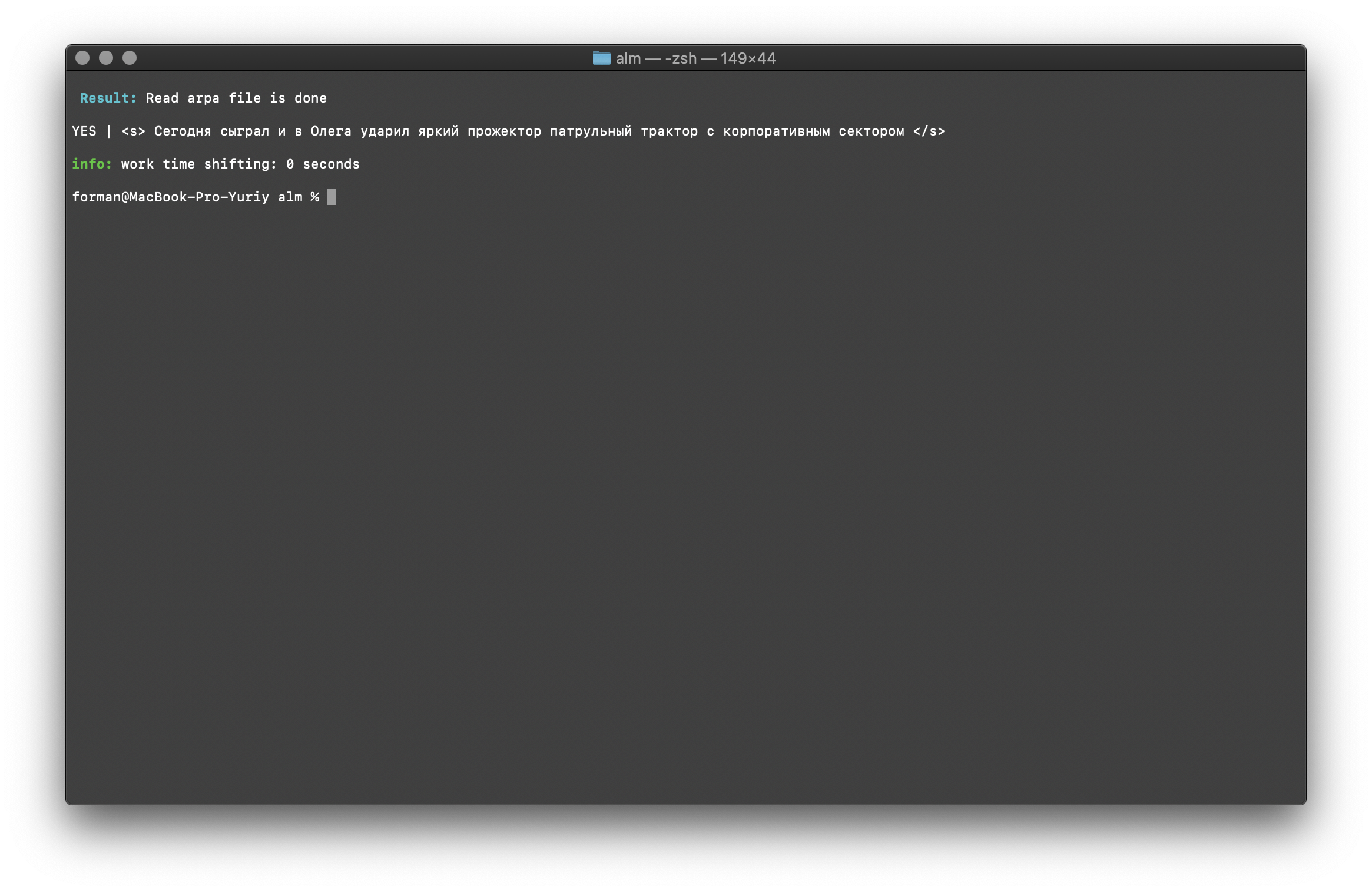 Teste:
Teste:<s> </s>
Resultado:YES | <s> </s>
O resultado mostra que o texto que está sendo verificado possui o contexto correto em termos do modelo de linguagem montado.Sinalizador [ -confidence ] - significa que o modelo de idioma será carregado como foi construído, sem overkenkenization.Correção de maiúsculas e minúsculas
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method fixcase -debug 1 -r-arpa ./lm.arpa -confidence
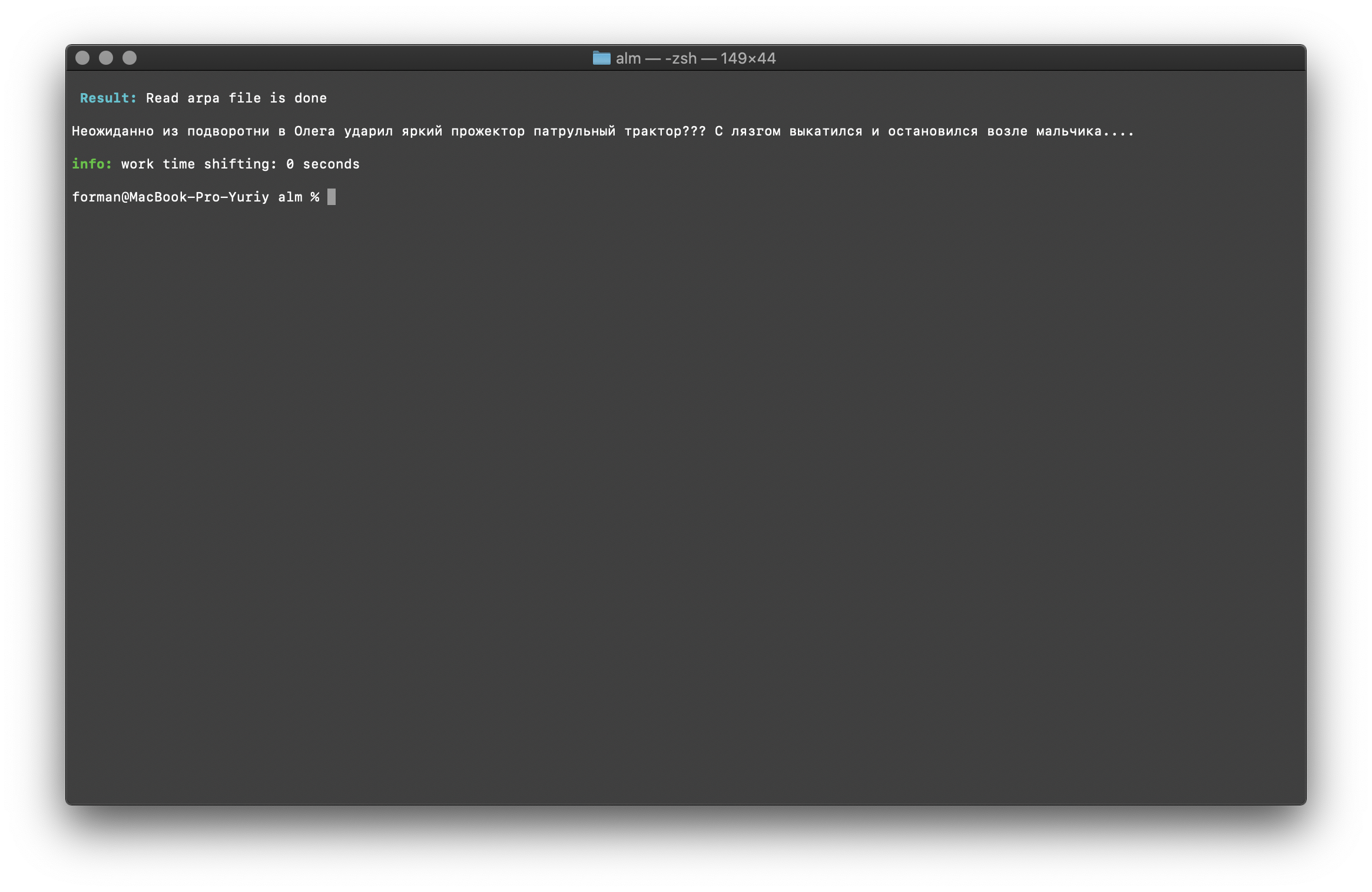 Teste:
Teste: ??? ....
Resultado: ??? ....
Os registros no texto são restaurados levando em consideração o contexto do modelo de linguagem.As bibliotecas descritas acima para trabalhar com modelos de linguagem estatística diferenciam maiúsculas de minúsculas. Por exemplo, o N-grama " em Moscou amanhã vai chover " não é o mesmo que o N-grama " em Moscou vai chover amanhã ", esses são N-gramas completamente diferentes. Mas e se for necessário que o caso faça distinção entre maiúsculas e minúsculas e ao mesmo tempo duplicar os mesmos N-gramas seja irracional? O ALM representa todos os N gramas em minúsculas. Isso elimina a possibilidade de duplicação de N-gramas. O ALM também mantém sua classificação de registros de palavras em cada N-grama. Ao exportar para o formato de texto de um modelo de idioma, os registros são restaurados dependendo de sua classificação.Verificando o número de N gramas
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method counts -debug 1 -r-arpa ./lm.arpa -confidence
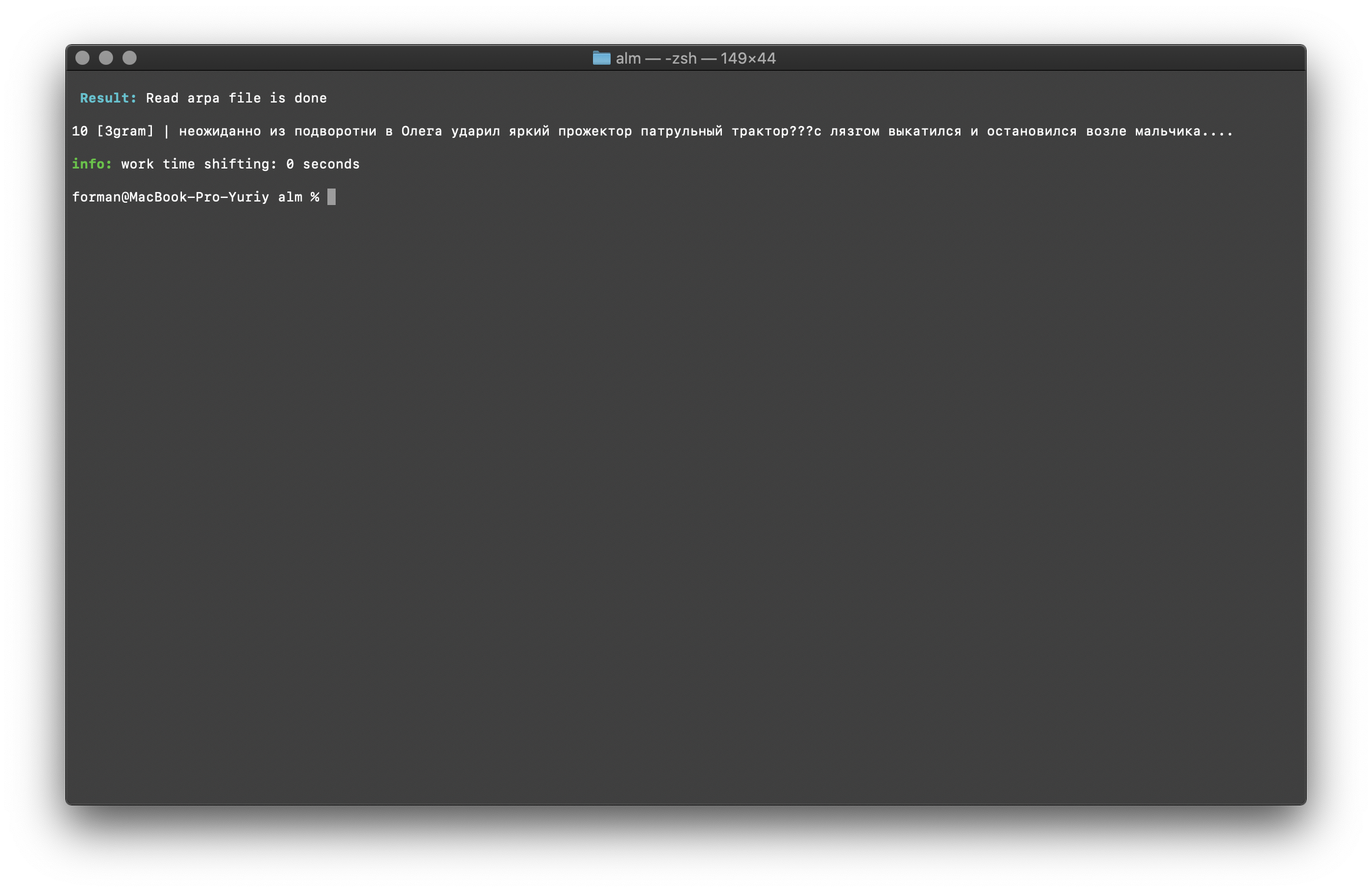 Teste:
Teste: ??? ....
Resultado:10 [3gram] |
N- , .
A verificação do número de N-gramas é realizada pelo tamanho do N-grama no modelo de idioma. Também há a oportunidade de verificar bigrams e trigramas .Bigram Check
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method counts -ngrams bigram -debug 1 -r-arpa ./lm.arpa -confidence
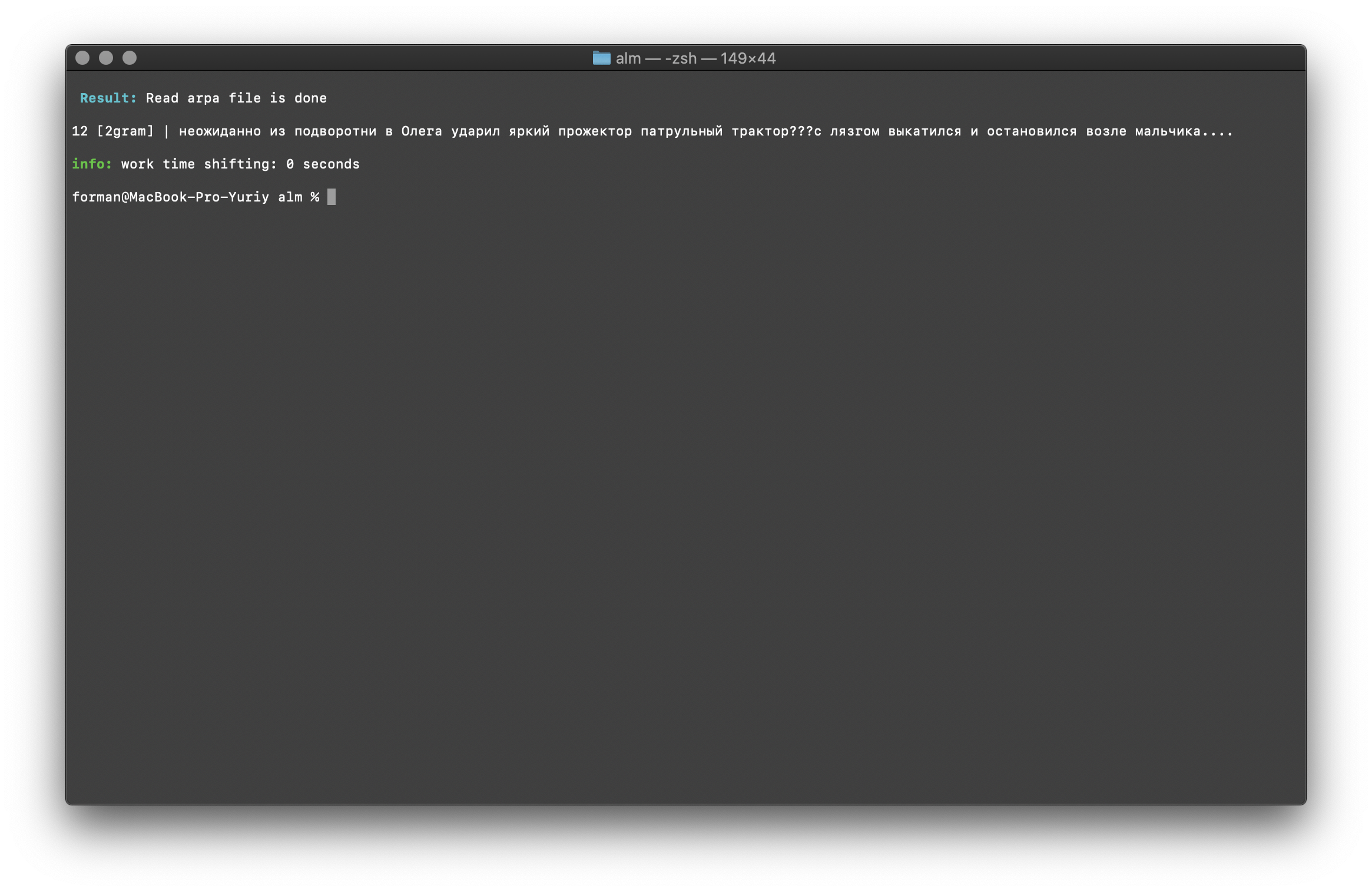 Teste:
Teste: ??? ....
Resultado:12 [2gram] | ??? ….
Verificação de Trigrama
$ echo " ??? ...." | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method counts -ngrams trigram -debug 1 -r-arpa ./lm.arpa -confidence
Teste: ??? ....
Resultado:10 [3gram] | ??? ….
Pesquise N gramas em texto
$ echo " " | ./alm -alphabet "abcdefghijklmnopqrstuvwxyz" -method find -debug 1 -r-arpa ./lm.arpa -confidence
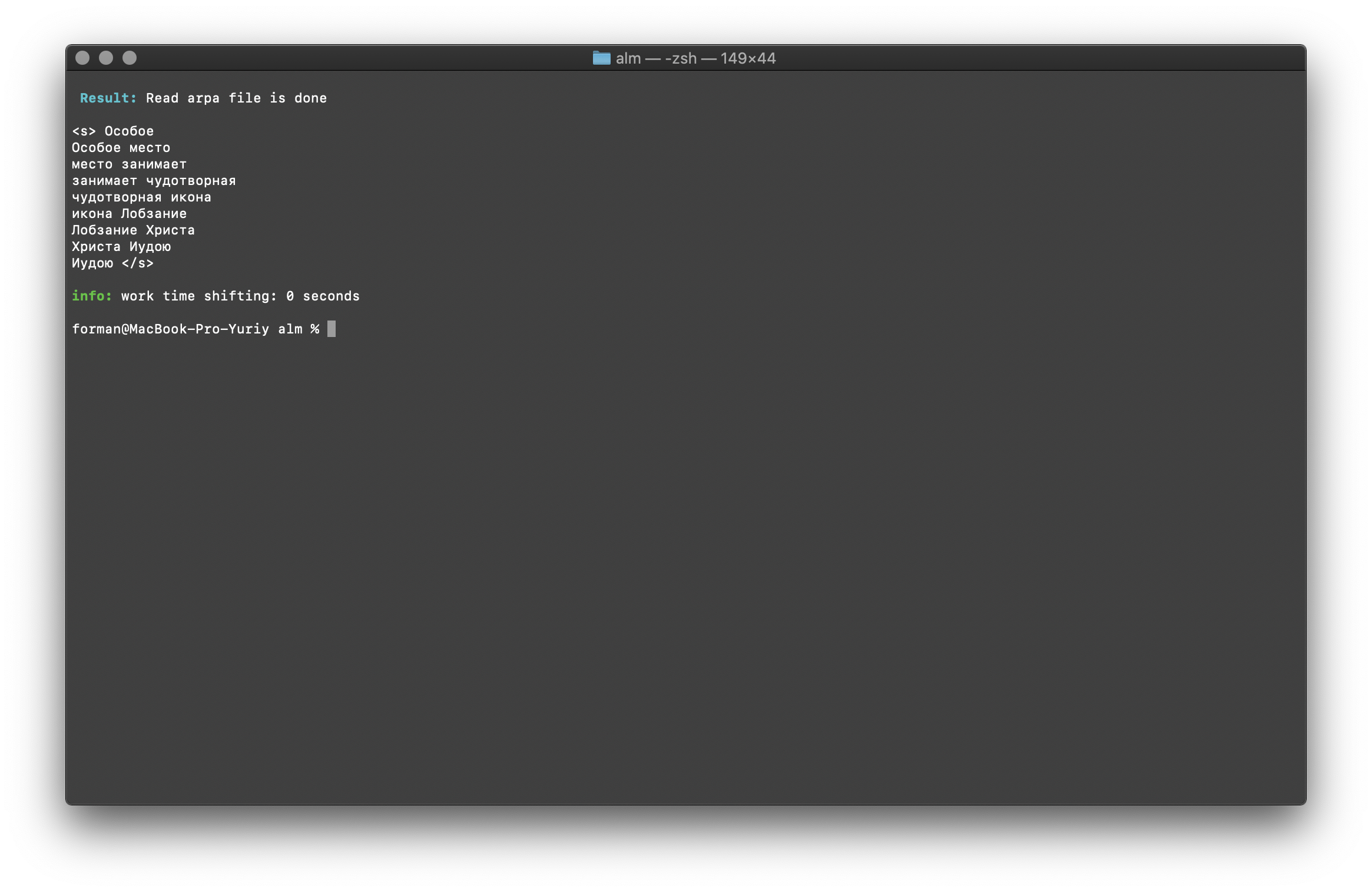 Teste:
Teste:
Resultado:<s>
</s>
Uma lista de N gramas que são encontradas no texto. Não há nada de especial para explicar aqui.Variáveis ambientais
Todos os parâmetros podem ser passados através de variáveis de ambiente. As variáveis começam com o prefixo ALM_ e devem ser escritas em maiúsculas. Caso contrário, os nomes das variáveis correspondem aos parâmetros do aplicativo.Se os parâmetros do aplicativo e as variáveis de ambiente forem especificados, os parâmetros do aplicativo terão prioridade.$ export $ALM_SMOOTHING=wittenbell
$ export $ALM_W-ARPA=./lm.arpa
Assim, o processo de montagem pode ser automatizado. Por exemplo, através de scripts BASH.Conclusão
Entendo que existem tecnologias mais promissoras como RnnLM ou Bert . Mas tenho certeza de que os modelos estatísticos de N-gram serão relevantes por um longo tempo.Este trabalho levou muito tempo e esforço. Ele trabalhava na biblioteca em seu tempo livre do trabalho básico, à noite e nos fins de semana. O código não cobriu os testes, erros e bugs são possíveis. Serei grato por testar. Também estou aberto a sugestões de aprimoramento e novas funcionalidades da biblioteca. O ALM é distribuído sob a licença MIT , que permite usá-lo quase sem restrições.Espero receber comentários, críticas, sugestões.Site do projeto Repositório do projeto