Talvez você tenha enfrentado a tarefa de computação paralela em quadros de dados de pandas. Este problema pode ser resolvido pelo Python nativo e com a ajuda de uma biblioteca maravilhosa - paralela. Neste artigo, mostrarei como essa biblioteca permite processar seus dados usando todas as capacidades disponíveis.
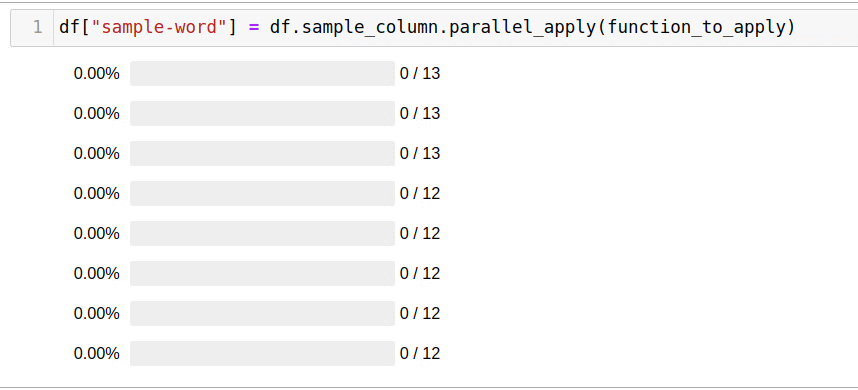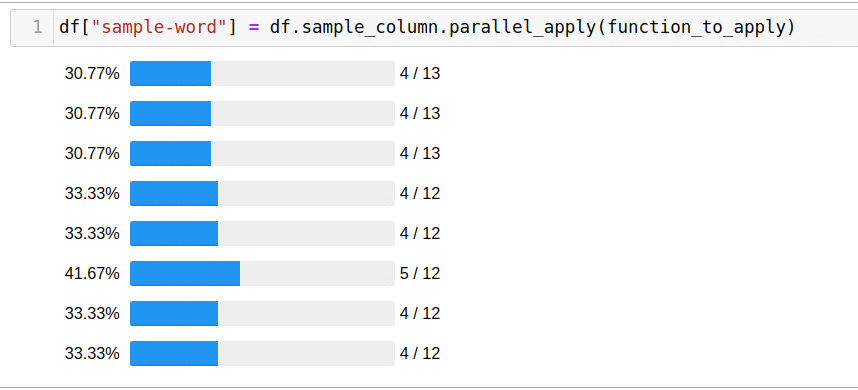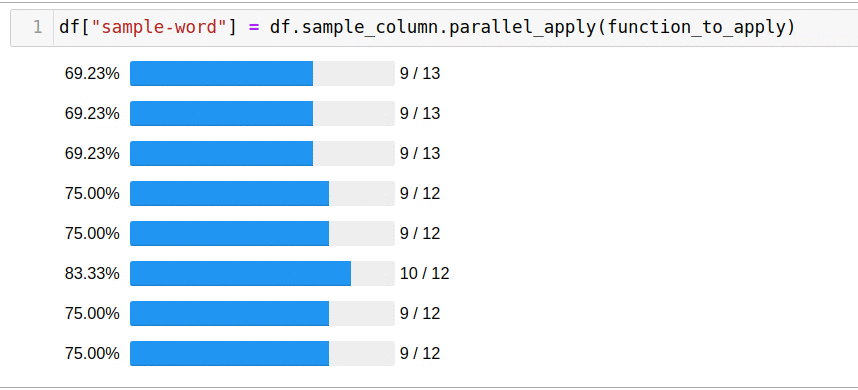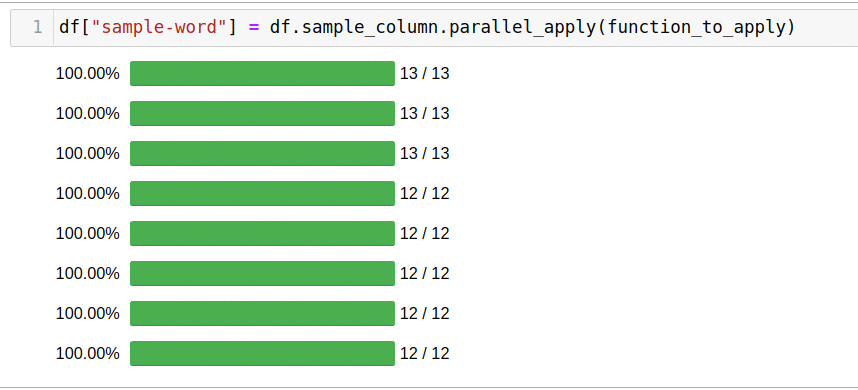
A biblioteca permite que você não pense no número de encadeamentos, criando processos e fornece uma interface interativa para monitorar o progresso.
Instalação
pip install pandas jupyter pandarallel requests tqdm
Como você pode ver, eu também instalo o tqdm. Com isso, demonstrarei claramente a diferença na velocidade de execução do código em uma abordagem sequencial e paralela.
Costumização
import pandas as pd
import requests
from tqdm import tqdm
tqdm.pandas()
from pandarallel import pandarallel
pandarallel.initialize(progress_bar=True)
Você pode encontrar a lista completa de configurações na documentação paralela.
Crie um quadro de dados
Para experimentos, crie um quadro de dados simples - 100 linhas, 1 coluna.
df = pd.DataFrame(
[i for i in range(100)],
columns=["sample_column"]
)

Exemplo de uma tarefa adequada para paralelização
Como sabemos, a solução de nem todos os problemas pode ser paralela. Um exemplo simples de uma tarefa adequada é chamar alguma fonte externa, como uma API ou banco de dados. Na função abaixo, eu chamo uma API que me retorna uma palavra aleatória. Meu objetivo é adicionar uma coluna com palavras derivadas dessa API ao quadro de dados.
def function_to_apply(i):
r = requests.get(f'https://random-word-api.herokuapp.com/word').json()
return r[0]
df["sample-word"] = df.sample_column.progress_apply(function_to_apply)
, tqdm, — progress_apply apply. , , progress bar.

"" 35 .
, parallel_apply:
df["sample-word"] = df.sample_column.parallel_apply(function_to_apply)
5 .
pandas , pandarallel, Github .

! — .