O que devo fazer se quiser anotar muitos “fatos” no banco de dados com um volume muito maior do que ele pode suportar? Primeiro, é claro, trazemos os dados para uma forma normal mais econômica e obtemos “dicionários”, que escreveremos uma vez . Mas como fazer isso de forma mais eficaz?Essa é exatamente a questão que enfrentamos ao desenvolver o monitoramento e a análise dos logs do servidor PostgreSQL , quando outros métodos de otimização do registro no banco de dados foram esgotados.Faremos uma reserva imediata de que nossos coletores estão executando o Node.js , para não interagirmos com os registros e caches do processador de nenhuma maneira. E a opção de usar "centenas" ou serviços / bancos de dados em cache externos oferece muito atraso para fluxos de entrada de várias centenas de Mbps .Portanto, tentamos armazenar em cache tudo na RAM , especificamente na memória do processo JavaScript. Sobre como organizar isso de forma mais eficiente, e iremos além.Cache de disponibilidade
Nossa principal tarefa é garantir que a única instância de qualquer objeto entre no banco de dados. Estes são os textos originais repetidamente repetidos de consultas SQL, modelos de planos para sua implementação , nós desses planos - em resumo, alguns blocos de texto .Historicamente, como identificador, usamos um UUIDvalor-, obtido como resultado do cálculo direto do hash MD5 a partir do texto do objeto. Depois disso, verificamos a disponibilidade desse hash no "dicionário" local na memória do processo e, se não estiver lá, somente então escrevemos no banco de dados na tabela "dicionário".Ou seja, não precisamos armazenar o valor do texto original (e às vezes leva dezenas de kilobytes) - apenas o fato da presença do hash correspondente no dicionário é suficiente .Dicionário de Chaves
Esse dicionário pode ser mantido Arraye usado Array.includes()para verificar a disponibilidade, mas isso é bastante redundante - a pesquisa diminui (pelo menos nas versões anteriores do V8) linearmente do tamanho da matriz, O (N). E nas implementações modernas, apesar de todas as otimizações, perde a uma velocidade de 2-3%.Portanto, na era pré-ES6, o armazenamento era a solução tradicional Object, com valores armazenados como chaves. Mas todos atribuíram os valores das chaves ao que ele queria - por exemplo Boolean:var dict = {};
function has(key) {
return dict[key] !== undefined;
}
function add(key) {
dict[key] = true;
}
Mas é óbvio que estamos armazenando claramente o excesso aqui - o próprio valor da chave que ninguém precisa. Mas e se não estiver armazenado? Então o objeto Set apareceu .Os testes mostram que a pesquisa com ajuda é Set.has()aproximadamente 20 a 25% mais rápida que a verificação de chaves c Object. Mas essa não é sua única vantagem. Como armazenamos menos, precisamos de menos memória - e isso afeta diretamente o desempenho quando se trata de centenas de milhares dessas chaves.Assim, Objectem que existem 100 chaves UUID em uma representação de texto, ele ocupa 6.216 bytes na memória :
Setcom o mesmo conteúdo - 2.632 bytes :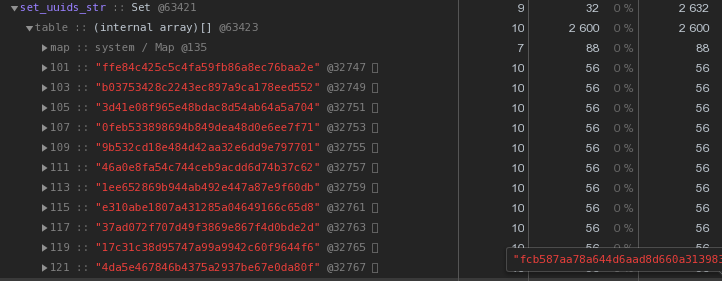 Ou seja,
Ou seja, Setfunciona mais rápido e ao mesmo tempo leva2,5 vezes menos memória - o vencedor é óbvio.Otimizamos o armazenamento de chaves UUID
Em geral, na natureza dos sistemas distribuídos, as chaves UUID são bastante comuns - em nosso VLSI, elas são, no mínimo, usadas para identificar documentos e regulamentos no gerenciamento de documentos eletrônicos , pessoas em mensagens , ...Agora, vamos ver mais de perto a figura acima - cada UUID é a chave armazenada na representação hexadecimal “custa” 56 bytes de memória . Mas como temos centenas de milhares deles, é razoável perguntar: "É possível ter menos?"Primeiro, lembre-se de que o UUID é um identificador de 16 bytes. Essencialmente, um pedaço de dados binários. E para transmissão por email, por exemplo, os dados binários são codificados em base64 - tente aplicá-los:let str = Buffer.from(uuidstr, 'hex').toString('base64');
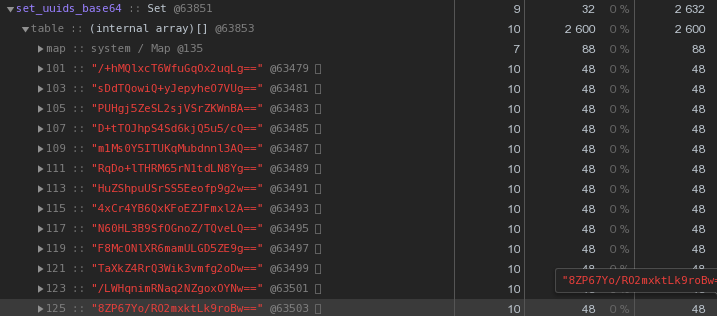 Já 48 bytes cada um são melhores, mas imperfeitos. Vamos tentar traduzir a representação hexadecimal diretamente em uma string:
Já 48 bytes cada um são melhores, mas imperfeitos. Vamos tentar traduzir a representação hexadecimal diretamente em uma string:let str = Buffer.from(uuidstr, 'hex').toString('binary');
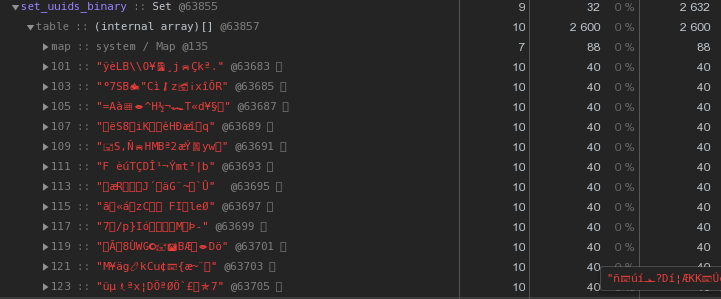 Em vez de 56 bytes por chave - 40 bytes, economizando quase 30% !
Em vez de 56 bytes por chave - 40 bytes, economizando quase 30% !Mestre, trabalhador - onde armazenar dicionários?
Considerando que os dados de vocabulário dos trabalhadores se cruzam fortemente, fizemos o armazenamento dos dicionários e os escrevemos no banco de dados no processo mestre e a transmissão de dados dos trabalhadores através do mecanismo de mensagens do IPC .No entanto, uma parte significativa do tempo do mestre foi gasta, channel.onreadou seja, processando o recebimento de pacotes com informações de "dicionário" de processos filhos: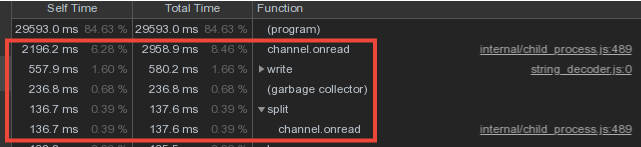
Barreira de gravação de conjunto duplo
Agora vamos pensar por um segundo - os trabalhadores enviam e enviam ao mestre os mesmos dados de vocabulário (basicamente, esses são os modelos de plano e os corpos de solicitação repetidos), ele os analisa com o suor e ... não faz nada, porque eles já foram enviados ao banco de dados antes !Portanto, se Set"protegemos" o banco de dados da regravação do mestre com um dicionário, por que não usar a mesma abordagem para "proteger" o mestre de ser transferido do trabalhador?Na verdade, isso foi feito e reduzimos os custos diretos de manutenção do canal de troca três vezes :
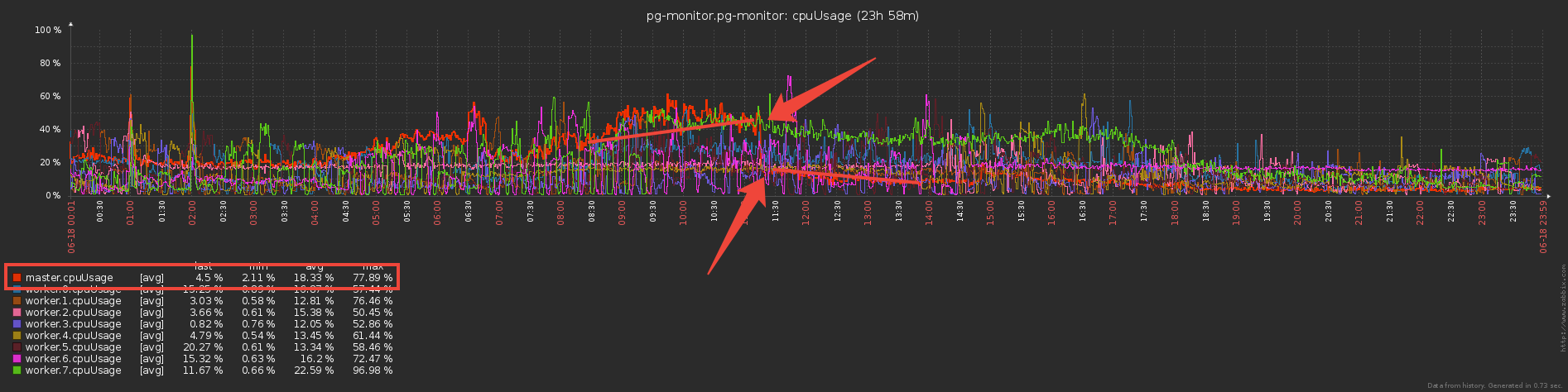 Mas agora os trabalhadores parecem fazer mais trabalho - armazenar dicionários e filtrar por eles? Ou não? .. De fato, eles começaram a trabalhar significativamente menos, já que a transferência de grandes volumes (mesmo via IPC!) Não é barata.
Mas agora os trabalhadores parecem fazer mais trabalho - armazenar dicionários e filtrar por eles? Ou não? .. De fato, eles começaram a trabalhar significativamente menos, já que a transferência de grandes volumes (mesmo via IPC!) Não é barata.Nice bonus
Desde que o assistente agora começou a receber uma quantidade muito menor de informações, começou a alocar muito menos memória para esses contêineres - o que significa que o tempo gasto no trabalho do Garbage Collector diminuiu significativamente, o que afetou positivamente a latência do sistema como um todo.Esse esquema fornece proteção contra entradas repetidas no nível do coletor, mas e se tivermos vários coletores? Somente o gatilho com ajudará aqui INSERT ... ON CONFLICT DO NOTHING.Acelerar o cálculo de hash
Em nossa arquitetura, todo o fluxo de logs de um servidor PostgreSQL é processado por um trabalhador.Ou seja, um servidor é uma tarefa para o trabalhador. Ao mesmo tempo, o carregamento de trabalhadores é equilibrado pelo objetivo das tarefas do servidor, para que o consumo de CPU pelos trabalhadores de todos os coletores seja aproximadamente o mesmo. Este é um distribuidor de serviços separado.“Em média”, cada trabalhador lida com dezenas de tarefas que produzem aproximadamente a mesma carga total. No entanto, existem servidores que superam significativamente o restante no número de entradas de log. E mesmo que o expedidor deixe essa tarefa como a única no trabalhador, seu download é muito maior que os outros:Removemos o perfil da CPU deste trabalhador: Nas linhas superiores, o cálculo dos hashes MD5. E eles são realmente calculados uma quantidade enorme - para todo o fluxo de objetos recebidos.
Nas linhas superiores, o cálculo dos hashes MD5. E eles são realmente calculados uma quantidade enorme - para todo o fluxo de objetos recebidos.xxHash
Como otimizar esta parte, exceto por esses hashes, não podemos?Decidimos tentar outra função de hash - xxHash , que implementa o algoritmo de hash não criptográfico extremamente rápido . E o módulo para o Node.js é o xxhash-addon , que usa a versão mais recente da biblioteca xxHash 0.7.3 com o novo algoritmo XXH3.Verifique executando cada opção em um conjunto de linhas de diferentes comprimentos:const crypto = require('crypto');
const { XXHash3, XXHash64 } = require('xxhash-addon');
const hasher3 = new XXHash3(0xDEADBEAF);
const hasher64 = new XXHash64(0xDEADBEAF);
const buf = Buffer.allocUnsafe(16);
const getBinFromHash = (hash) => buf.fill(hash, 'hex').toString('binary');
const funcs = {
xxhash64 : (str) => hasher64.hash(Buffer.from(str)).toString('binary')
, xxhash3 : (str) => hasher3.hash(Buffer.from(str)).toString('binary')
, md5 : (str) => getBinFromHash(crypto.createHash('md5').update(str).digest('hex'))
};
const check = (hash) => {
let log = [];
let cnt = 10000;
while (cnt--) log.push(crypto.randomBytes(cnt).toString('hex'));
console.time(hash);
log.forEach(funcs[hash]);
console.timeEnd(hash);
};
Object.keys(funcs).forEach(check);
Resultados:xxhash64 : 148.268ms
xxhash3 : 108.337ms
md5 : 317.584ms
Como esperado , o xxhash3 foi muito mais rápido que o MD5 !Resta verificar se há resistência a colisões. Seções de tabelas de dicionários estão sendo criadas para nós todos os dias, portanto, fora dos limites do dia, podemos permitir com segurança a interseção de hashes.Mas, por via das dúvidas, verificamos com uma margem no intervalo de três dias - nem um único conflito que nos convém mais que o suficiente.Substituição de Hash
Mas simplesmente não podemos aceitar e alterar os antigos campos UUID para o novo hash nas tabelas de dicionário, porque o banco de dados e o frontend existente esperam que os objetos continuem sendo identificados pelo UUID.Portanto, adicionaremos mais um cache ao coletor - para o MD5 já calculado. Agora será um mapa , no qual as chaves são xxhash3, os valores são MD5. Para linhas idênticas, não recontamos o MD5 "caro" novamente, mas o retiramos do cache:const getHashFromBin = (bin) => Buffer.from(bin, 'binary').toString('hex');
const dictmd5 = new Map();
const getmd5 = (data) => {
const hash = xxhash(data);
let md5hash = dictmd5.get(hash);
if (!md5hash) {
md5hash = md5(data);
dictmd5.set(hash, getBinFromHash(md5hash));
return md5hash;
}
return getHashFromBin(md5hash);
};
Removemos o perfil - a fração do tempo para calcular hashes diminuiu acentuadamente, felicidades! Então agora contamos xxhash3, depois verificamos o cache MD5 e obtemos o MD5 desejado, e depois verificamos o cache do dicionário - se esse md5 não estiver lá, envie-o para o banco de dados para gravação.Algo muitas verificações ... Por que verificar o cache do dicionário se você já verificou o cache MD5? Acontece que todos os caches de dicionário não são mais necessários e basta ter apenas um cache - para o MD5, com o qual todas as operações básicas serão executadas:
Então agora contamos xxhash3, depois verificamos o cache MD5 e obtemos o MD5 desejado, e depois verificamos o cache do dicionário - se esse md5 não estiver lá, envie-o para o banco de dados para gravação.Algo muitas verificações ... Por que verificar o cache do dicionário se você já verificou o cache MD5? Acontece que todos os caches de dicionário não são mais necessários e basta ter apenas um cache - para o MD5, com o qual todas as operações básicas serão executadas: como resultado, substituímos a verificação em vários dicionários de "objetos" por um cache do MD5, e a operação intensiva de recursos do cálculo do MD5 é O hash é executado apenas para novas entradas, usando o xxhash muito mais eficiente para o fluxo de entrada.obrigadoKilor para obter ajuda na preparação do artigo.
como resultado, substituímos a verificação em vários dicionários de "objetos" por um cache do MD5, e a operação intensiva de recursos do cálculo do MD5 é O hash é executado apenas para novas entradas, usando o xxhash muito mais eficiente para o fluxo de entrada.obrigadoKilor para obter ajuda na preparação do artigo.