Olá queridos assinantes! Você provavelmente já sabe que lançamos um novo curso "Visão Computacional" , com aulas que começarão nos próximos dias. Antecipando o início das aulas, preparamos outra tradução interessante para imersão no mundo do currículo.
Meu hobby é jogar jogos de tabuleiro e, como estou familiarizado com redes neurais convolucionais, decidi criar um aplicativo que pode derrotar uma pessoa em um jogo de cartas. Queria criar um modelo do zero usando meu próprio conjunto de dados e ver como ele funciona com um pequeno conjunto de dados. Decidi começar com o simples jogo Dobble (também conhecido como Spot it!).Se você não souber o que é Dobble, lembrarei brevemente das regras do jogo: Dobble é um jogo simples de reconhecimento de padrões, no qual os jogadores tentam encontrar uma imagem representada simultaneamente em dois cartões. Cada carta do jogo Dobble original contém oito personagens diferentes e, em cartas diferentes, são de tamanhos diferentes. Quaisquer duas cartas têm apenas um símbolo comum. Se você encontrar o símbolo primeiro, pegue um cartão. Quando o baralho de 55 cartas termina, aquele com mais cartas vence. Experimente você mesmo: que símbolo é comum para esses dois cartões?
Experimente você mesmo: que símbolo é comum para esses dois cartões?Por onde começar?
O primeiro passo para resolver qualquer tarefa de análise de dados é coletar dados. Tirei seis fotos de cada cartão no telefone. No total, 330 fotos foram tiradas. Quatro deles você vê abaixo. Você pode perguntar: isso é suficiente para criar uma boa rede neural convolucional? Voltaremos a isso!
Processamento de imagem
OK, os dados que temos, o que vem a seguir? Provavelmente a parte mais importante no caminho para o sucesso: processamento de imagens. Precisamos obter caracteres de cada imagem. Algumas dificuldades nos esperam aqui. Nas fotos acima, é perceptível que alguns personagens são mais difíceis de distinguir do que outros: o boneco de neve e o fantasma (na terceira foto) e a agulha (na quarta) de cores claras, e os borrões (na segunda foto) e o ponto de exclamação (na quarta foto) consistem em várias partes . Para processar caracteres claros, adicionaremos contraste. Depois disso, redimensionaremos e salvaremos a imagem.Adicionar contraste
Para adicionar contraste, usamos o espaço de cores do laboratório. L é leveza, a é o componente cromático na faixa de verde a magenta eb é o componente cromático na faixa de azul a amarelo. Podemos extrair facilmente esses componentes usando o OpenCV :import cv2
import imutils
imgname = 'picture1'
image = cv2.imread(f’{imgname}.jpg’)
lab = cv2.cvtColor(image, cv2.COLOR_BGR2LAB)
l, a, b = cv2.split(lab)
 Da esquerda para a direita: a imagem original, o componente de luminosidade, componente ae componente bAgora adicionamos contraste ao componente de luminosidade, novamente combinamos todos os componentes e convertemos em uma imagem normal:
Da esquerda para a direita: a imagem original, o componente de luminosidade, componente ae componente bAgora adicionamos contraste ao componente de luminosidade, novamente combinamos todos os componentes e convertemos em uma imagem normal:clahe = cv2.createCLAHE(clipLimit=3.0, tileGridSize=(8,8))
cl = clahe.apply(l)
limg = cv2.merge((cl,a,b))
final = cv2.cvtColor(limg, cv2.COLOR_LAB2BGR)
 Da esquerda para a direita: a imagem original, o componente de luminosidade, a imagem com alto contraste e a imagem convertida novamente em RGB
Da esquerda para a direita: a imagem original, o componente de luminosidade, a imagem com alto contraste e a imagem convertida novamente em RGBMudança de tamanho
Agora redimensione e salve a imagem:resized = cv2.resize(final, (800, 800))
# save the image
cv2.imwrite(f'{imgname}processed.jpg', blurred)
Feito!Reconhecimento de cartão e personagem
Agora que a imagem está processada, podemos detectar um cartão na imagem. Usando o OpenCV, estamos procurando contornos externos. Em seguida, convertemos a imagem em meios-tons, selecionamos o valor limite (no nosso caso, 190) para criar uma imagem em preto e branco e procurar um caminho. O código:image = cv2.imread(f’{imgname}processed.jpg’)
gray = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
thresh = cv2.threshold(gray, 190, 255, cv2.THRESH_BINARY)[1]
# find contours
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
output = image.copy()
# draw contours on image
for c in cnts:
cv2.drawContours(output, [c], -1, (255, 0, 0), 3)
 Imagem processada convertida em meios-tons usando limiar e selecionando contornos externosSe ordenarmos os contornos externos por área, encontraremos o contorno com a maior área - este será o nosso cartão. Para extrair os caracteres, podemos criar um fundo branco.
Imagem processada convertida em meios-tons usando limiar e selecionando contornos externosSe ordenarmos os contornos externos por área, encontraremos o contorno com a maior área - este será o nosso cartão. Para extrair os caracteres, podemos criar um fundo branco.# sort by area, grab the biggest one
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[0]
# create mask with the biggest contour
mask = np.zeros(gray.shape,np.uint8)
mask = cv2.drawContours(mask, [cnts], -1, 255, cv2.FILLED)
# card in foreground
fg_masked = cv2.bitwise_and(image, image, mask=mask)
# white background (use inverted mask)
mask = cv2.bitwise_not(mask)
bk = np.full(image.shape, 255, dtype=np.uint8)
bk_masked = cv2.bitwise_and(bk, bk, mask=mask)
# combine back- and foreground
final = cv2.bitwise_or(fg_masked, bk_masked)
 Máscara, plano de fundo, imagem de primeiro plano, imagem finalAgora é hora do reconhecimento de caracteres! Podemos usar a imagem resultante para detectar contornos externos novamente, esses contornos serão símbolos. Se criarmos um quadrado ao redor de cada símbolo, podemos extrair essa área. Aqui o código é um pouco mais longo:
Máscara, plano de fundo, imagem de primeiro plano, imagem finalAgora é hora do reconhecimento de caracteres! Podemos usar a imagem resultante para detectar contornos externos novamente, esses contornos serão símbolos. Se criarmos um quadrado ao redor de cada símbolo, podemos extrair essa área. Aqui o código é um pouco mais longo:
gray = cv2.cvtColor(final, cv2.COLOR_RGB2GRAY)
thresh = cv2.threshold(gray, 195, 255, cv2.THRESH_BINARY)[1]
thresh = cv2.bitwise_not(thresh)
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
cnts = sorted(cnts, key=cv2.contourArea, reverse=True)[:10]
i = 0
for c in cnts:
if cv2.contourArea(c) > 1000:
mask = np.zeros(gray.shape, np.uint8)
mask = cv2.drawContours(mask, [c], -1, 255, cv2.FILLED)
fg_masked = cv2.bitwise_and(image, image, mask=mask)
mask = cv2.bitwise_not(mask)
bk = np.full(image.shape, 255, dtype=np.uint8)
bk_masked = cv2.bitwise_and(bk, bk, mask=mask)
finalcont = cv2.bitwise_or(fg_masked, bk_masked)
output = finalcont.copy()
x,y,w,h = cv2.boundingRect(c)
if w < h:
x += int((w-h)/2)
w = h
else:
y += int((h-w)/2)
h = w
roi = finalcont[y:y+h, x:x+w]
roi = cv2.resize(roi, (400,400))
cv2.imwrite(f"{imgname}_icon{i}.jpg", roi)
i += 1
 Imagem em preto e branco (com limite), contornos detectados, um símbolo fantasma e um coração (caracteres extraídos com máscaras)
Imagem em preto e branco (com limite), contornos detectados, um símbolo fantasma e um coração (caracteres extraídos com máscaras)Classificação de caracteres
E agora o mais chato! Você precisa classificar os caracteres. Você precisará dos diretórios de treinamento, teste e validação, 57 diretórios cada (temos 57 caracteres diferentes no total). A estrutura da pasta é a seguinte:symbols
├── test
│ ├── anchor
│ ├── apple
│ │ ...
│ └── zebra
├── train
│ ├── anchor
│ ├── apple
│ │ ...
│ └── zebra
└── validation
├── anchor
├── apple
│ ...
└── zebra
Levará algum tempo para colocar os caracteres extraídos (mais de 2500 peças) nos diretórios necessários! Eu tenho código para criar subpastas, um conjunto de testes e um kit de validação no GitHub . Talvez da próxima vez seja melhor fazer a classificação com base no algoritmo de agrupamento ...Treinamento em rede neural convolucional
Após a parte chata, a diversão vem novamente! É hora de criar e treinar uma rede neural convolucional. Você pode encontrar informações sobre redes neurais convolucionais aqui .Arquitetura de modelo
Temos a tarefa de classificação multi-classe com um rótulo. Para cada personagem, precisamos de um rótulo. É por isso que precisaremos de uma função para ativar a camada de softmax de saída com 57 nós e a entropia cruzada categórica como uma função de perda.A arquitetura do modelo final é a seguinte:
from keras import layers
from keras import models
from keras import optimizers
from keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(400, 400, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(256, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(256, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(57, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=optimizers.RMSprop(lr=1e-4), metrics=['acc'])
Aumento de Dados
Para melhorar o desempenho, usei o aumento de dados. O aumento de dados é o processo de aumentar o volume e a variedade de dados de entrada. Isso pode ser feito girando, deslocando, dimensionando, cortando e invertendo as imagens existentes. Keras pode aumentar facilmente os dados:
train_dir = 'symbols/train'
validation_dir = 'symbols/validation'
test_dir = 'symbols/test'
train_datagen = ImageDataGenerator(rescale=1./255, rotation_range=40, width_shift_range=0.1, height_shift_range=0.1, shear_range=0.1, zoom_range=0.1, horizontal_flip=True, vertical_flip=True)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(train_dir, target_size=(400,400), batch_size=20, class_mode='categorical')
validation_generator = test_datagen.flow_from_directory(validation_dir, target_size=(400,400), batch_size=20, class_mode='categorical')
Se você estava interessado, o fantasma aumentado fica assim: A imagem original do fantasma à esquerda, fantasmas aumentados em todas as outras fotos
A imagem original do fantasma à esquerda, fantasmas aumentados em todas as outras fotosModelo de treinamento
Vamos treinar o modelo, salvá-lo para usar em previsões e verificar os resultados.history = model.fit_generator(train_generator, steps_per_epoch=100, epochs=100, validation_data=validation_generator, validation_steps=50)
model.save('models/model.h5')
 Previsões perfeitas!
Previsões perfeitas!resultados
O modelo básico que eu treinei sem aumento de dados, desistências e com menos camadas. Este modelo deu os seguintes resultados: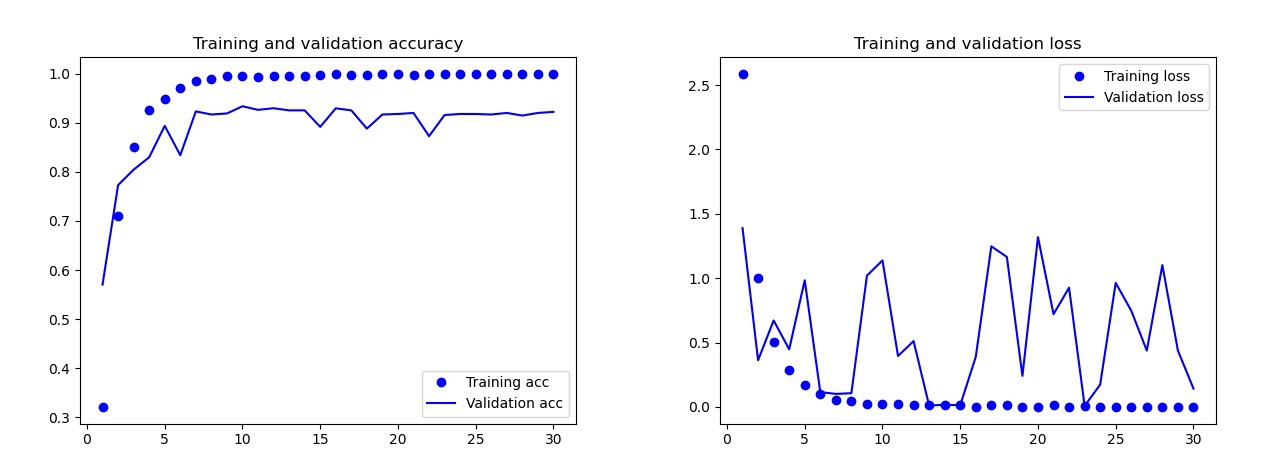 Os resultados do modelo básico Aolho nu, é claro que esse modelo é treinado novamente. Os resultados da versão final do modelo (seu código é apresentado nas seções anteriores) são muito melhores. No gráfico abaixo, você pode ver a precisão e as perdas durante o treinamento e no conjunto de validação.
Os resultados do modelo básico Aolho nu, é claro que esse modelo é treinado novamente. Os resultados da versão final do modelo (seu código é apresentado nas seções anteriores) são muito melhores. No gráfico abaixo, você pode ver a precisão e as perdas durante o treinamento e no conjunto de validação. Resultados do modelo final: no modelo deteste, esse modelo cometeu apenas um erro: reconheceu a bomba como uma gota. Eu decidi ficar nesse modelo, a precisão no conjunto de testes era de 0,995.
Resultados do modelo final: no modelo deteste, esse modelo cometeu apenas um erro: reconheceu a bomba como uma gota. Eu decidi ficar nesse modelo, a precisão no conjunto de testes era de 0,995.Reconhecimento de um símbolo comum em dois cartões
Agora você pode começar a procurar símbolos comuns em dois cartões. Usamos duas fotografias, faremos previsões para cada imagem separadamente e usaremos a interseção de conjuntos para descobrir qual símbolo está nos dois cartões. Temos 3 opções de trabalho:- Algo deu errado durante a previsão: nenhum caractere comum foi encontrado.
- Há um símbolo na interseção (a previsão pode ser verdadeira ou falsa).
- Há mais de um caractere no cruzamento. Nesse caso, escolhi o símbolo com a maior probabilidade (a média de ambas as previsões).
O código para prever toda a combinação das duas imagens no catálogo está no GitHub 's main.py.E aqui estão os resultados:
Conclusão
Esse não é o modelo perfeito? Infelizmente não. Quando tirei novas fotos dos cartões e dei a eles os modelos de previsão, houve alguns problemas com o boneco de neve. Às vezes, ele reconhecia o olho ou a zebra como um boneco de neve! Como resultado, às vezes os resultados eram estranhos: bem, onde está o boneco de neve aqui?Esse modelo é melhor que o homem? Dependendo do que precisamos: as pessoas reconhecem perfeitamente, mas o modelo faz isso mais rápido! Percebi a hora em que o computador está lidando: dei um baralho de 55 cartas e tive que obter um símbolo comum para cada combinação de duas cartas. No total, são 1485 combinações. O computador fez isso em menos de 140 segundos. Ele cometeu alguns erros, mas definitivamente derrotará qualquer pessoa quando se trata de velocidade!
bem, onde está o boneco de neve aqui?Esse modelo é melhor que o homem? Dependendo do que precisamos: as pessoas reconhecem perfeitamente, mas o modelo faz isso mais rápido! Percebi a hora em que o computador está lidando: dei um baralho de 55 cartas e tive que obter um símbolo comum para cada combinação de duas cartas. No total, são 1485 combinações. O computador fez isso em menos de 140 segundos. Ele cometeu alguns erros, mas definitivamente derrotará qualquer pessoa quando se trata de velocidade! Não acho difícil criar um modelo 100% funcional. Isso pode ser alcançado através do treinamento de transferência. Para entender o que o modelo faz, poderíamos visualizar camadas para a imagem de teste. Você pode fazer isso da próxima vez!
Não acho difícil criar um modelo 100% funcional. Isso pode ser alcançado através do treinamento de transferência. Para entender o que o modelo faz, poderíamos visualizar camadas para a imagem de teste. Você pode fazer isso da próxima vez!
Aprenda mais sobre o curso e passe no teste de admissão