 (imagem tirada daqui )
(imagem tirada daqui )
Hoje, gostaríamos de falar sobre a tarefa de pós-processamento dos resultados do reconhecimento de campos de texto com base no conhecimento a priori do campo. Anteriormente, já escrevemos sobre o método de correção de campo com base em trigramas , o que permite corrigir alguns erros de reconhecimento de palavras escritas em idiomas naturais. No entanto, uma parte significativa de documentos importantes, incluindo documentos de identificação, são campos de natureza diferente - datas, números, códigos VIN de carros, números TIN e SNILS, zonas legíveis por máquinacom suas somas de verificação e muito mais. Embora não possam ser atribuídos aos campos de uma linguagem natural, no entanto, esses campos costumam ter algum modelo de linguagem, às vezes implícito, o que significa que alguns algoritmos de correção também podem ser aplicados a eles. Nesta publicação, discutiremos dois mecanismos para resultados de reconhecimento de pós-processamento que podem ser usados para um grande número de documentos e tipos de campo.O modelo de linguagem do campo pode ser dividido condicionalmente em três componentes:- Sintaxe : regras que governam a estrutura de uma representação de campo de texto. Exemplo: o campo "data de validade do documento" em uma zona legível por máquina é representado como sete dígitos "DDDDDDD".
- : , . : “ ” - – , 3- 4- – , 5- 6- – , 7- – .
- : , . : “ ” , , “ ”.
Tendo informações sobre a estrutura semântica e sintática do documento e o campo reconhecido, é possível criar um algoritmo especializado para pós-processamento do resultado do reconhecimento. No entanto, considerando a necessidade de apoiar e desenvolver sistemas de reconhecimento e a complexidade de seu desenvolvimento, é interessante considerar métodos e ferramentas "universais" que permitiriam, com o mínimo esforço (dos desenvolvedores), criar um algoritmo de pós-processamento bastante bom que funcionasse com uma classe extensa documentos e campos. A metodologia para configurar e suportar esse algoritmo seria unificada e apenas o modelo de linguagem seria um componente variável da estrutura do algoritmo.Vale a pena notar que o pós-processamento dos resultados do reconhecimento de campo de texto nem sempre é útil e, às vezes, até prejudicial: se você possui um módulo de reconhecimento de linha bastante bom e trabalha em sistemas críticos com documentos de identificação, algum tipo de pós-processamento é melhor minimizar e produzir resultados "como estão", ou monitorar claramente quaisquer alterações e relatá-las ao cliente. No entanto, em muitos casos, quando se sabe que o documento é válido e que o modelo de linguagem do campo é confiável, o uso de algoritmos de pós-processamento pode aumentar significativamente a qualidade do reconhecimento final.Portanto, o artigo discutirá dois métodos de pós-processamento que afirmam ser universais. O primeiro é baseado em conversores finitos ponderados, requer uma descrição do modelo de linguagem na forma de uma máquina de estados finitos, não é muito fácil de usar, mas é mais universal. O segundo é mais fácil de usar, mais eficiente, requer apenas escrever uma função para verificar a validade do valor do campo, mas também possui várias desvantagens.Método do transmissor de extremidade ponderada
Um modelo bonito e bastante geral que permite criar um algoritmo universal para resultados de reconhecimento de pós-processamento é descrito neste trabalho . O modelo baseia-se na estrutura de dados dos transdutores de estado finito ponderado (WFST).Os WFSTs são uma generalização de máquinas de estado finito ponderado - se uma máquina de estado finito ponderado codifica alguma linguagem ponderada  (ou seja, um conjunto ponderado de linhas sobre um determinado alfabeto
(ou seja, um conjunto ponderado de linhas sobre um determinado alfabeto  ), o WFST codifica um mapa ponderado de um idioma
), o WFST codifica um mapa ponderado de um idioma  acima do alfabeto
acima do alfabeto  para um idioma
para um idioma  acima do alfabeto
acima do alfabeto  . Uma máquina de estados finitos ponderada, colocando uma string
. Uma máquina de estados finitos ponderada, colocando uma string  sobre o alfabeto , atribui algum peso a ela
sobre o alfabeto , atribui algum peso a ela  , enquanto WFST, recebendo uma string
, enquanto WFST, recebendo uma string sobre o alfabeto , associa a ele um conjunto de pares (possivelmente infinitos)
sobre o alfabeto , associa a ele um conjunto de pares (possivelmente infinitos)  , onde
, onde  está a linha acima do alfabeto no qual a linha é convertida e
está a linha acima do alfabeto no qual a linha é convertida e  é o peso dessa conversão. Cada transição do conversor é caracterizada por dois estados (entre os quais a transição é feita), os caracteres de entrada (do alfabeto ), os caracteres de saída (do alfabeto ) e o peso da transição. Um caractere vazio (sequência vazia) é considerado um elemento dos dois alfabetos. O peso da conversão de
é o peso dessa conversão. Cada transição do conversor é caracterizada por dois estados (entre os quais a transição é feita), os caracteres de entrada (do alfabeto ), os caracteres de saída (do alfabeto ) e o peso da transição. Um caractere vazio (sequência vazia) é considerado um elemento dos dois alfabetos. O peso da conversão de  sequência em sequência
sequência em sequência  é a soma dos produtos dos pesos de transição ao longo de todos os caminhos nos quais a concatenação dos caracteres de entrada forma a sequência e a concatenação dos caracteres de saída forma a sequênciae que transferem o conversor do estado inicial para um dos terminais.A operação de composição é determinada no WFST, no qual o método de pós-processamento é baseado. Vamos ser dada dois transformadores
é a soma dos produtos dos pesos de transição ao longo de todos os caminhos nos quais a concatenação dos caracteres de entrada forma a sequência e a concatenação dos caracteres de saída forma a sequênciae que transferem o conversor do estado inicial para um dos terminais.A operação de composição é determinada no WFST, no qual o método de pós-processamento é baseado. Vamos ser dada dois transformadores  e
e  , e converter a linha de cima
, e converter a linha de cima  para a linha de cima
para a linha de cima  com o peso
com o peso  , e converter sobre para a linha
, e converter sobre para a linha  de cima
de cima  com o peso
com o peso  . Em seguida, o conversor
. Em seguida, o conversor  , chamado de composição dos conversores, converte a string em uma string com um peso
, chamado de composição dos conversores, converte a string em uma string com um peso . A composição dos transdutores é uma operação computacionalmente cara, mas pode ser calculada preguiçosamente - os estados e transições do transdutor resultante podem ser construídos no momento em que precisam ser acessados.O algoritmo para pós-processamento do resultado do reconhecimento baseado no WFST é baseado em três fontes principais de informação - o
. A composição dos transdutores é uma operação computacionalmente cara, mas pode ser calculada preguiçosamente - os estados e transições do transdutor resultante podem ser construídos no momento em que precisam ser acessados.O algoritmo para pós-processamento do resultado do reconhecimento baseado no WFST é baseado em três fontes principais de informação - o  modelo de hipótese , o modelo de erro
modelo de hipótese , o modelo de erro  e o modelo de linguagem
e o modelo de linguagem  . Todos os três modelos são apresentados na forma de transdutores finais ponderados:
. Todos os três modelos são apresentados na forma de transdutores finais ponderados:- ( WFST – , ), , . ,
 , ():
, ():  ,
,  –
–  - ,
- ,  – () .
– () .  - , :
- , :  - ,
- ,  - – ,
- – ,  -
-  -
-  . - , . , .
. - , . , .
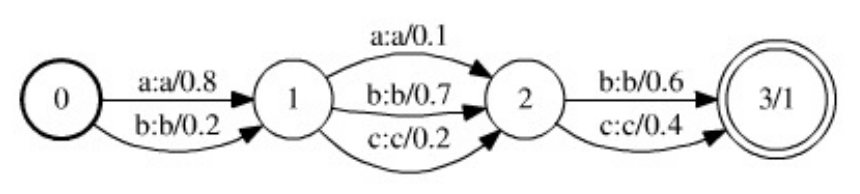
. 1. , WFST ( ). .
- , , . WFST ( ). . , .
- . .. , ( ).
Depois de definir um modelo de hipóteses, erros e um modelo de linguagem, a tarefa de pós-processamento dos resultados do reconhecimento agora pode ser apresentada da seguinte maneira: considere a composição dos três modelos  (em termos da composição do WFST). O conversor
(em termos da composição do WFST). O conversor  codifica todas as conversões possíveis de strings do modelo de hipótese em strings do modelo de linguagem , aplicando transformações codificadas no modelo de erro em strings . Além disso, o peso dessa transformação inclui o peso da hipótese original, o peso da transformação e o peso da sequência resultante (no caso de um modelo de linguagem ponderada). Por conseguinte, nesse modelo, o pós-processamento ideal do resultado do reconhecimento corresponderá ao caminho ótimo (em termos de peso) no conversortraduzindo-o do inicial para um dos estados terminais. A linha de entrada nesse caminho corresponderá à hipótese inicial selecionada e a linha de saída ao resultado do reconhecimento corrigido. O caminho ideal pode ser buscado usando algoritmos para encontrar os caminhos mais curtos em gráficos direcionados.As vantagens dessa abordagem são sua generalidade e flexibilidade. O modelo de erro, por exemplo, pode ser facilmente expandido de forma a levar em consideração a exclusão e adição de caracteres (para isso, vale a pena adicionar transições com um símbolo de saída ou entrada vazio, respectivamente, ao modelo de erro). No entanto, este modelo tem desvantagens significativas. Primeiro, o modelo de linguagem aqui deve ser apresentado como um transformador finito ponderado finito. Para linguagens complexas, esse autômato pode ser bastante complicado e, em caso de alteração ou refinamento do modelo de linguagem, será necessário reconstruí-lo. Note-se também que a composição dos três transdutores, como resultado, tem como regra um transdutor ainda mais volumoso,e essa composição é calculada toda vez que você inicia o pós-processamento de um resultado de reconhecimento. Devido ao volume da composição, a busca pelo caminho ideal na prática deve ser realizada com métodos heurísticos, como a pesquisa A *.Usando o modelo de verificação de gramáticas, é possível construir um modelo mais simples da tarefa de resultados de reconhecimento de pós-processamento, que não será tão geral quanto o modelo baseado no WFST, mas facilmente extensível e fácil de implementar.Uma gramática de verificação é um par
codifica todas as conversões possíveis de strings do modelo de hipótese em strings do modelo de linguagem , aplicando transformações codificadas no modelo de erro em strings . Além disso, o peso dessa transformação inclui o peso da hipótese original, o peso da transformação e o peso da sequência resultante (no caso de um modelo de linguagem ponderada). Por conseguinte, nesse modelo, o pós-processamento ideal do resultado do reconhecimento corresponderá ao caminho ótimo (em termos de peso) no conversortraduzindo-o do inicial para um dos estados terminais. A linha de entrada nesse caminho corresponderá à hipótese inicial selecionada e a linha de saída ao resultado do reconhecimento corrigido. O caminho ideal pode ser buscado usando algoritmos para encontrar os caminhos mais curtos em gráficos direcionados.As vantagens dessa abordagem são sua generalidade e flexibilidade. O modelo de erro, por exemplo, pode ser facilmente expandido de forma a levar em consideração a exclusão e adição de caracteres (para isso, vale a pena adicionar transições com um símbolo de saída ou entrada vazio, respectivamente, ao modelo de erro). No entanto, este modelo tem desvantagens significativas. Primeiro, o modelo de linguagem aqui deve ser apresentado como um transformador finito ponderado finito. Para linguagens complexas, esse autômato pode ser bastante complicado e, em caso de alteração ou refinamento do modelo de linguagem, será necessário reconstruí-lo. Note-se também que a composição dos três transdutores, como resultado, tem como regra um transdutor ainda mais volumoso,e essa composição é calculada toda vez que você inicia o pós-processamento de um resultado de reconhecimento. Devido ao volume da composição, a busca pelo caminho ideal na prática deve ser realizada com métodos heurísticos, como a pesquisa A *.Usando o modelo de verificação de gramáticas, é possível construir um modelo mais simples da tarefa de resultados de reconhecimento de pós-processamento, que não será tão geral quanto o modelo baseado no WFST, mas facilmente extensível e fácil de implementar.Uma gramática de verificação é um par  , onde está o alfabeto e
, onde está o alfabeto e  é o predicado de admissibilidade de uma sequência sobre o alfabeto , ou seja,
é o predicado de admissibilidade de uma sequência sobre o alfabeto , ou seja,  . Uma gramática de verificação codifica um determinado idioma sobre o alfabeto da seguinte maneira: uma linha
. Uma gramática de verificação codifica um determinado idioma sobre o alfabeto da seguinte maneira: uma linha  pertence ao idioma se o predicado receber um valor verdadeiro nessa linha. Vale notar que a verificação gramatical é uma maneira mais geral de representar um modelo de linguagem do que uma máquina de estado. De fato, qualquer linguagem representada como uma máquina de estados finitos, pode ser representado na forma de uma gramática de verificação (com um predicado
pertence ao idioma se o predicado receber um valor verdadeiro nessa linha. Vale notar que a verificação gramatical é uma maneira mais geral de representar um modelo de linguagem do que uma máquina de estado. De fato, qualquer linguagem representada como uma máquina de estados finitos, pode ser representado na forma de uma gramática de verificação (com um predicado  , onde
, onde  é o conjunto de linhas aceito pelo autômato . No entanto, nem todos os idiomas que podem ser representados como uma gramática de verificação são representáveis como um autômato finito no caso geral (por exemplo, um idioma de palavras de tamanho ilimitado em excesso). alfabeto
é o conjunto de linhas aceito pelo autômato . No entanto, nem todos os idiomas que podem ser representados como uma gramática de verificação são representáveis como um autômato finito no caso geral (por exemplo, um idioma de palavras de tamanho ilimitado em excesso). alfabeto  , no qual o número de caracteres é
, no qual o número de caracteres é  maior que o número de caracteres
maior que o número de caracteres  .)Deixe o resultado do reconhecimento (modelo de hipótese) ser dado como uma sequência de células(igual ao da seção anterior). Por conveniência, assumimos que cada célula contém K alternativas e todas as estimativas alternativas assumem um valor positivo. A avaliação (peso) da sequência será considerada o produto das classificações de cada um dos caracteres dessa sequência. Se o modelo de linguagem é fornecido na forma de uma gramática de verificação , o problema de pós-processamento pode ser formulado como um problema discreto de otimização (maximização) no conjunto de controles
.)Deixe o resultado do reconhecimento (modelo de hipótese) ser dado como uma sequência de células(igual ao da seção anterior). Por conveniência, assumimos que cada célula contém K alternativas e todas as estimativas alternativas assumem um valor positivo. A avaliação (peso) da sequência será considerada o produto das classificações de cada um dos caracteres dessa sequência. Se o modelo de linguagem é fornecido na forma de uma gramática de verificação , o problema de pós-processamento pode ser formulado como um problema discreto de otimização (maximização) no conjunto de controles  (o conjunto de todas as linhas de comprimento sobre o alfabeto ) com o predicado de admissibilidade e funcional
(o conjunto de todas as linhas de comprimento sobre o alfabeto ) com o predicado de admissibilidade e funcional  , onde
, onde  está a estimativa de símbolo
está a estimativa de símbolo  na i-célula .Qualquer problema discreto de otimização (ou seja, com um conjunto finito de controles) pode ser resolvido usando uma enumeração completa de controles. O algoritmo descrito itera eficientemente sobre os controles (linhas) em ordem decrescente do valor funcional até que o predicado de validade aceite o valor verdadeiro. Definimos como o
na i-célula .Qualquer problema discreto de otimização (ou seja, com um conjunto finito de controles) pode ser resolvido usando uma enumeração completa de controles. O algoritmo descrito itera eficientemente sobre os controles (linhas) em ordem decrescente do valor funcional até que o predicado de validade aceite o valor verdadeiro. Definimos como o  número máximo de iterações do algoritmo, ou seja, o número máximo de linhas com a estimativa máxima na qual o predicado será calculado.Primeiro, classificamos as alternativas em ordem decrescente de estimativas e assumimos ainda que, para qualquer célula, a desigualdade
número máximo de iterações do algoritmo, ou seja, o número máximo de linhas com a estimativa máxima na qual o predicado será calculado.Primeiro, classificamos as alternativas em ordem decrescente de estimativas e assumimos ainda que, para qualquer célula, a desigualdade  para é verdadeira
para é verdadeira  . A posição será a sequência de índices
. A posição será a sequência de índices  correspondente à linha
correspondente à linha . Avaliação da posição, ou seja, valor funcional nessa posição, considere as avaliações alternativas de produtos correspondentes aos índices incluídos na posição:
. Avaliação da posição, ou seja, valor funcional nessa posição, considere as avaliações alternativas de produtos correspondentes aos índices incluídos na posição:  . Para armazenar posições, você precisa da estrutura de dados PositionBase , que permite adicionar novas posições (obtendo seus endereços), obter a posição no endereço e verificar se a posição especificada foi adicionada ao banco de dados.No processo de listagem de posições, selecionaremos uma posição não visualizada com uma classificação máxima e, em seguida, adicionaremos à fila para consideração do PositionQueue todas as posições que podem ser obtidas a partir da atual, adicionando um a um dos índices incluídos na posição. A fila para consideração PositionQueue conterá triplos
. Para armazenar posições, você precisa da estrutura de dados PositionBase , que permite adicionar novas posições (obtendo seus endereços), obter a posição no endereço e verificar se a posição especificada foi adicionada ao banco de dados.No processo de listagem de posições, selecionaremos uma posição não visualizada com uma classificação máxima e, em seguida, adicionaremos à fila para consideração do PositionQueue todas as posições que podem ser obtidas a partir da atual, adicionando um a um dos índices incluídos na posição. A fila para consideração PositionQueue conterá triplos  , em que
, em que - avaliação da posição não
- avaliação da posição não  revisada , - endereço da posição visualizada no PositionBase a partir da qual essa posição foi obtida,
revisada , - endereço da posição visualizada no PositionBase a partir da qual essa posição foi obtida,  - índice do elemento position com o endereço que foi aumentado em um para obter essa posição. O posicionamento de uma fila PositionQueue exigirá uma estrutura de dados que permita adicionar outra tripla , bem como recuperar uma tripla com classificação máxima .Na primeira iteração do algoritmo, é necessário considerar a posição
- índice do elemento position com o endereço que foi aumentado em um para obter essa posição. O posicionamento de uma fila PositionQueue exigirá uma estrutura de dados que permita adicionar outra tripla , bem como recuperar uma tripla com classificação máxima .Na primeira iteração do algoritmo, é necessário considerar a posição  com a estimativa máxima. Se o predicado pegar o valor verdadeiro na linha correspondente a esta posição, o algoritmo termina. Caso contrário, a posição é adicionada ao PositionBase e, emPositionQueue adiciona todos os triplos da exibição
com a estimativa máxima. Se o predicado pegar o valor verdadeiro na linha correspondente a esta posição, o algoritmo termina. Caso contrário, a posição é adicionada ao PositionBase e, emPositionQueue adiciona todos os triplos da exibição  , para todos
, para todos  , onde
, onde  é o endereço da posição inicial no PositionBase . A cada iteração subsequente do algoritmo, o triplo com o valor máximo da estimativa é extraído do PositionQueue , a posição em questão é restaurada no endereço da posição e do índice iniciais . Se a posição já tiver sido adicionada ao banco de dados das posições PositionBase consideradas , ela será ignorada e as três seguintes com o valor máximo da estimativa serão extraídas do PositionQueue . Caso contrário, o valor do predicado é verificado na linha correspondente à posição . Se o predicadopega o valor verdadeiro nessa linha e o algoritmo termina. Se o predicado não aceitar o valor verdadeiro nessa linha, a linha será adicionada ao PositionBase (com o endereço atribuído
é o endereço da posição inicial no PositionBase . A cada iteração subsequente do algoritmo, o triplo com o valor máximo da estimativa é extraído do PositionQueue , a posição em questão é restaurada no endereço da posição e do índice iniciais . Se a posição já tiver sido adicionada ao banco de dados das posições PositionBase consideradas , ela será ignorada e as três seguintes com o valor máximo da estimativa serão extraídas do PositionQueue . Caso contrário, o valor do predicado é verificado na linha correspondente à posição . Se o predicadopega o valor verdadeiro nessa linha e o algoritmo termina. Se o predicado não aceitar o valor verdadeiro nessa linha, a linha será adicionada ao PositionBase (com o endereço atribuído  ), todas as posições derivadas serão adicionadas à fila PositionQueue e a próxima iteração continuará.
), todas as posições derivadas serão adicionadas à fila PositionQueue e a próxima iteração continuará.FindSuitableString(M, N, K, P, C[1], ..., C[N]):
i : 1 ... N:
C[i]
( )
PositionBase PositionQueue
S_1 = {1, 1, 1, ..., 1}
P(S_1):
: S_1,
( )
S_1 PositionBase R(S_1)
i : 1 ... N:
K > 1, :
<Q * q[i][2] / q[i][1], R(S_1), i> PositionQueue
( )
( )
PositionBase M:
PositionQueue:
PositionQueue <Q, R, I> Q
S_from = PositionBase R
S_curr = {S_from[1], S_from[2], ..., S_from[I] + 1, ..., S_from[N]}
S_curr PositionBase:
:
S_curr PositionBase R(S_curr)
( )
P(S_curr):
: S_curr,
( )
i : 1 ... N:
K > S_curr[i]:
<Q * q[i][S_curr[i] + 1] / q[i][S_curr[i]],
R(S_curr),
i> PositionQueue
( )
( )
( )
( )
M
Observe que, durante as iterações, o predicado será verificado não mais de uma vez, não haverá mais adições ao PositionBase e, além do PositionQueue , a extração do PositionQueue e uma pesquisa no PositionBase ocorrerão mais de  uma vez. Se a implementação PositionQueue usou "agrupamento" de estrutura de dados e, para a organização PositionBase, usando a estrutura de dados "Bor", a complexidade do algoritmo é
uma vez. Se a implementação PositionQueue usou "agrupamento" de estrutura de dados e, para a organização PositionBase, usando a estrutura de dados "Bor", a complexidade do algoritmo é  : where
: where  - teste trudoemost predicado no comprimento da linha .Talvez a desvantagem mais importante do algoritmo baseado na verificação de gramáticas seja que ele não pode processar hipóteses de comprimentos diferentes (que podem surgir devido a erros de segmentação : perda ou ocorrência de caracteres extras, caracteres de colagem e recorte etc.), enquanto alterações em hipóteses como “excluir um caractere”, “adicionar um caractere” ou mesmo “substituir um caractere por um par” podem ser codificadas no modelo de erro do algoritmo baseado no WFST.No entanto, a velocidade e a facilidade de uso (ao trabalhar com um novo tipo de campo, você só precisa dar ao algoritmo acesso à função de validação de valor) tornam o método baseado na verificação de gramáticas uma ferramenta muito poderosa no arsenal do desenvolvedor de sistemas de reconhecimento de documentos. Usamos essa abordagem para um grande número de campos, como várias datas, número do cartão bancário (predicado - verificação do código da Lua ), campos de áreas de documentos legíveis por máquina com soma de verificação e muitos outros.
- teste trudoemost predicado no comprimento da linha .Talvez a desvantagem mais importante do algoritmo baseado na verificação de gramáticas seja que ele não pode processar hipóteses de comprimentos diferentes (que podem surgir devido a erros de segmentação : perda ou ocorrência de caracteres extras, caracteres de colagem e recorte etc.), enquanto alterações em hipóteses como “excluir um caractere”, “adicionar um caractere” ou mesmo “substituir um caractere por um par” podem ser codificadas no modelo de erro do algoritmo baseado no WFST.No entanto, a velocidade e a facilidade de uso (ao trabalhar com um novo tipo de campo, você só precisa dar ao algoritmo acesso à função de validação de valor) tornam o método baseado na verificação de gramáticas uma ferramenta muito poderosa no arsenal do desenvolvedor de sistemas de reconhecimento de documentos. Usamos essa abordagem para um grande número de campos, como várias datas, número do cartão bancário (predicado - verificação do código da Lua ), campos de áreas de documentos legíveis por máquina com soma de verificação e muitos outros.
A publicação foi preparada com base no artigo : Um algoritmo universal para pós-processamento de resultados de reconhecimento com base na validação de gramáticas. K.B. Bulatov, D.P. Nikolaev, V.V. Postnikov. Proceedings of ISA RAS, Vol. 65, No. 4, 2015, pp. 68-73.