fundo
Recentemente, no âmbito das atividades educacionais, eu precisava usar o bom e velho algoritmo genético para encontrar as funções mínima e máxima de duas variáveis. No entanto, para minha surpresa, não houve implementação semelhante em python na Internet, e esta seção não foi abordada no artigo sobre o algoritmo genético na Wikipedia. Por isso, decidi escrever meu pequeno pacote em Python com uma visualização do algoritmo, de acordo com o qual seria conveniente configurar esse algoritmo e procurar as sutilezas do modelo selecionado.Neste breve artigo, gostaria de compartilhar o processo, as observações e os resultados.
Por isso, decidi escrever meu pequeno pacote em Python com uma visualização do algoritmo, de acordo com o qual seria conveniente configurar esse algoritmo e procurar as sutilezas do modelo selecionado.Neste breve artigo, gostaria de compartilhar o processo, as observações e os resultados.O princípio do algoritmo
Não falarei sobre o princípio global do trabalho de algoritmos genéticos, mas se você não ouviu falar sobre isso, pode se familiarizar com ele na Wikipedia .No momento, o pacote implementa apenas um GA, que é parametrizado pelos dados de entrada através de um guiche simples. Vou falar brevemente sobre as funções genéticas selecionadas e as soluções algorítmicas básicas.O indivíduo monocromossômico carrega em cada uma de suas informações gênicas sobre as coordenadas x ou y correspondentes. Uma população é determinada por muitos indivíduos, mas a população é segmentada em quatro indivíduos. Essa solução, é claro, se deve a uma tentativa de evitar a convergência para um ótimo local, pois a tarefa é encontrar um extremo global. Tal partição, como a prática demonstrou, em muitos casos não permite que um genótipo domine toda a população, mas, pelo contrário, confere maior dinâmica à "evolução". Para cada parte da população, o seguinte algoritmo é aplicado:- A seleção ocorre de forma semelhante ao método de classificação. 3 indivíduos são selecionados com os melhores indicadores de função de condicionamento físico (ou seja, os indivíduos são classificados em ordem crescente / decrescente da função definida pelo usuário, que atua como a função de adaptação).
- Em seguida, a função de cruzamento é aplicada de forma que uma nova geração (ou melhor, um novo segmento de uma população de 4 indivíduos) receba 2 pares de genes não-silenciados de um indivíduo com uma melhor indicação da função de condicionamento físico e um par de genes mutados de dois outros indivíduos. Mais informações sobre a compilação da função de mutação serão escritas na próxima seção.
O princípio da operação de seleção, cruzamento e mutação se parece visualmente com isso (na geração N, os cromossomos dos indivíduos já estão classificados na ordem correta, e um pequeno quadrado preto significa mutação):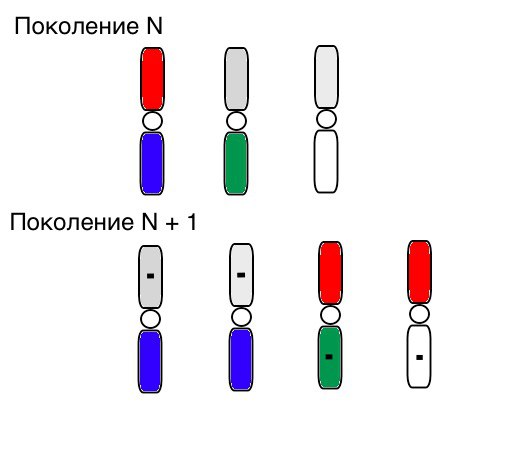
Testes e observações primárias
Portanto, testamos esse algoritmo em dois exemplos simples:Teste 1
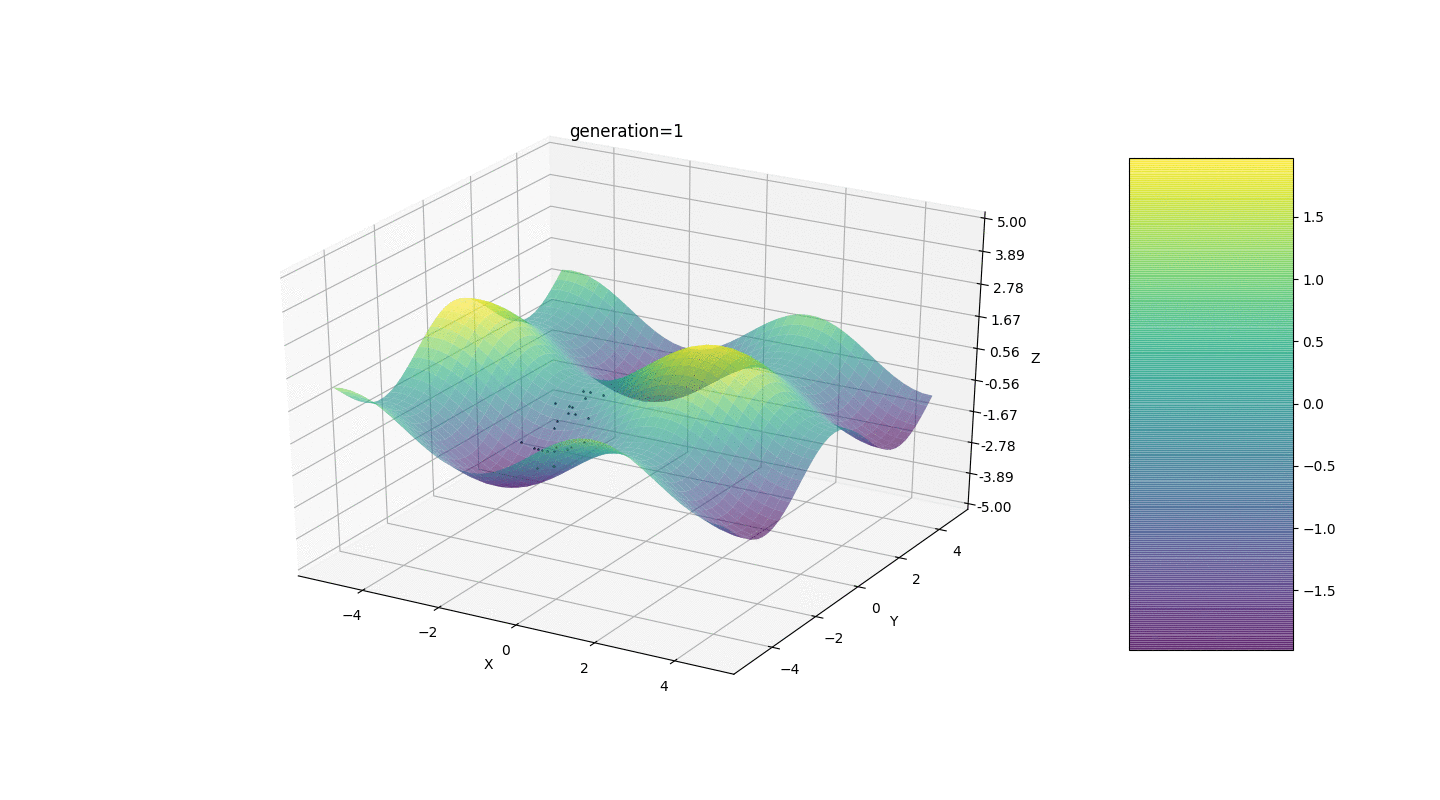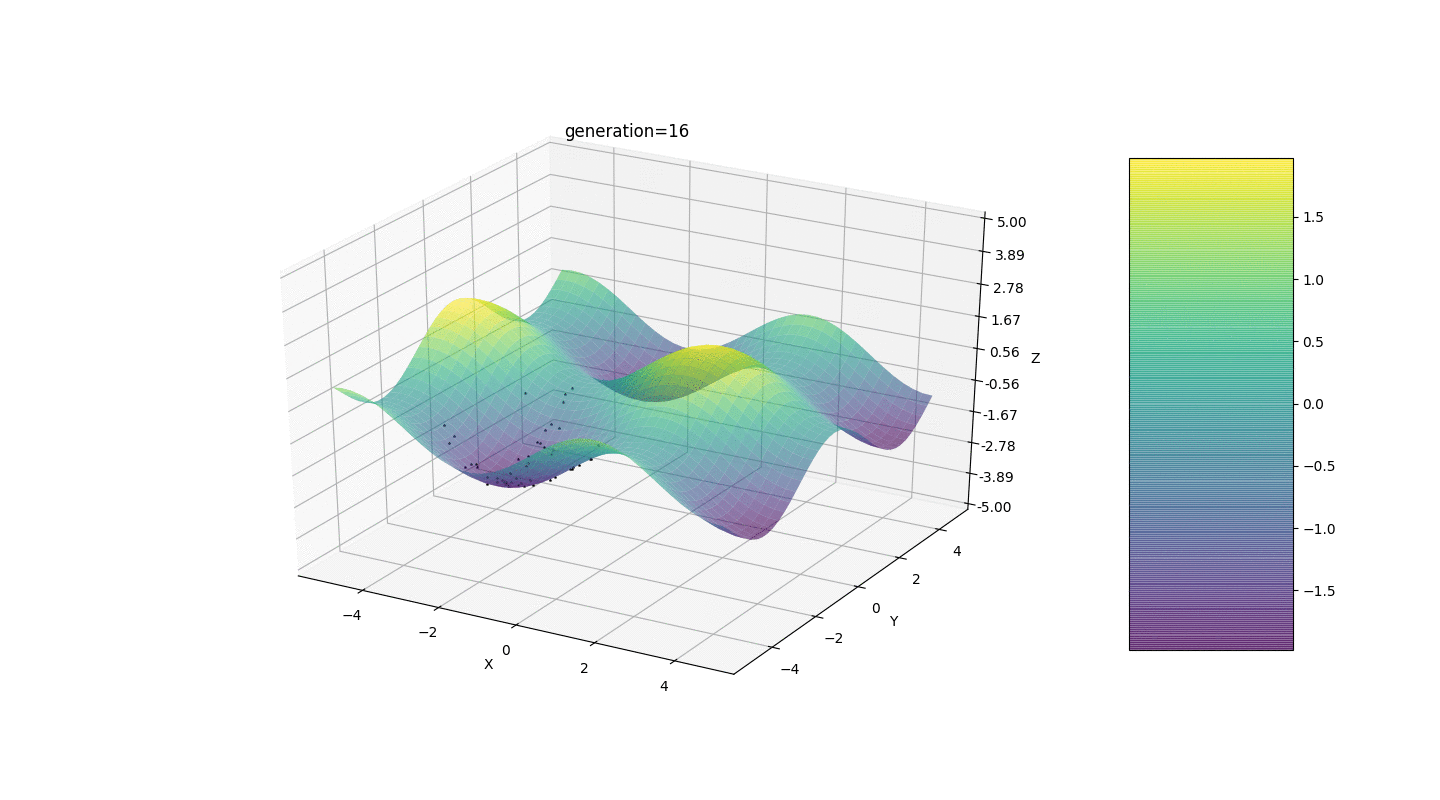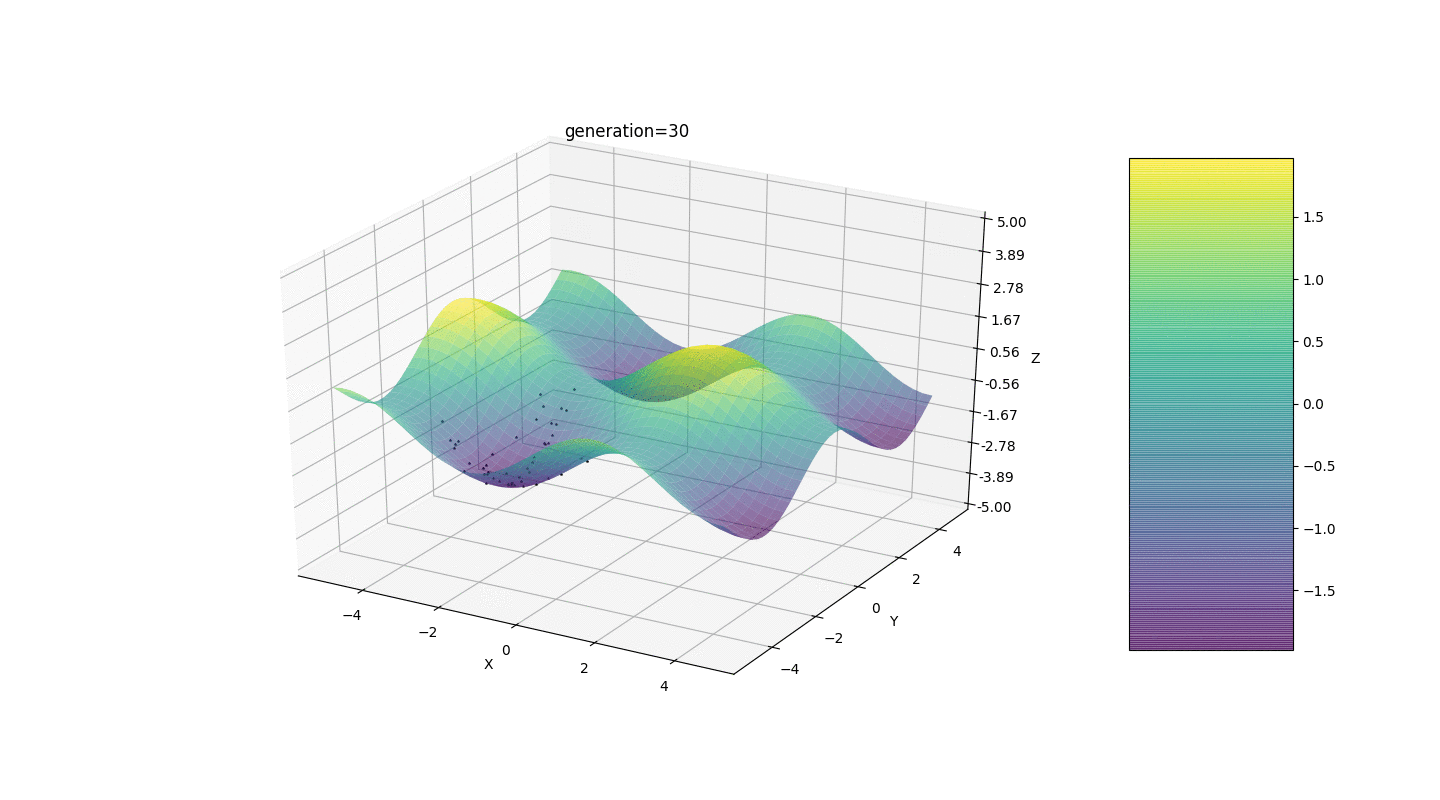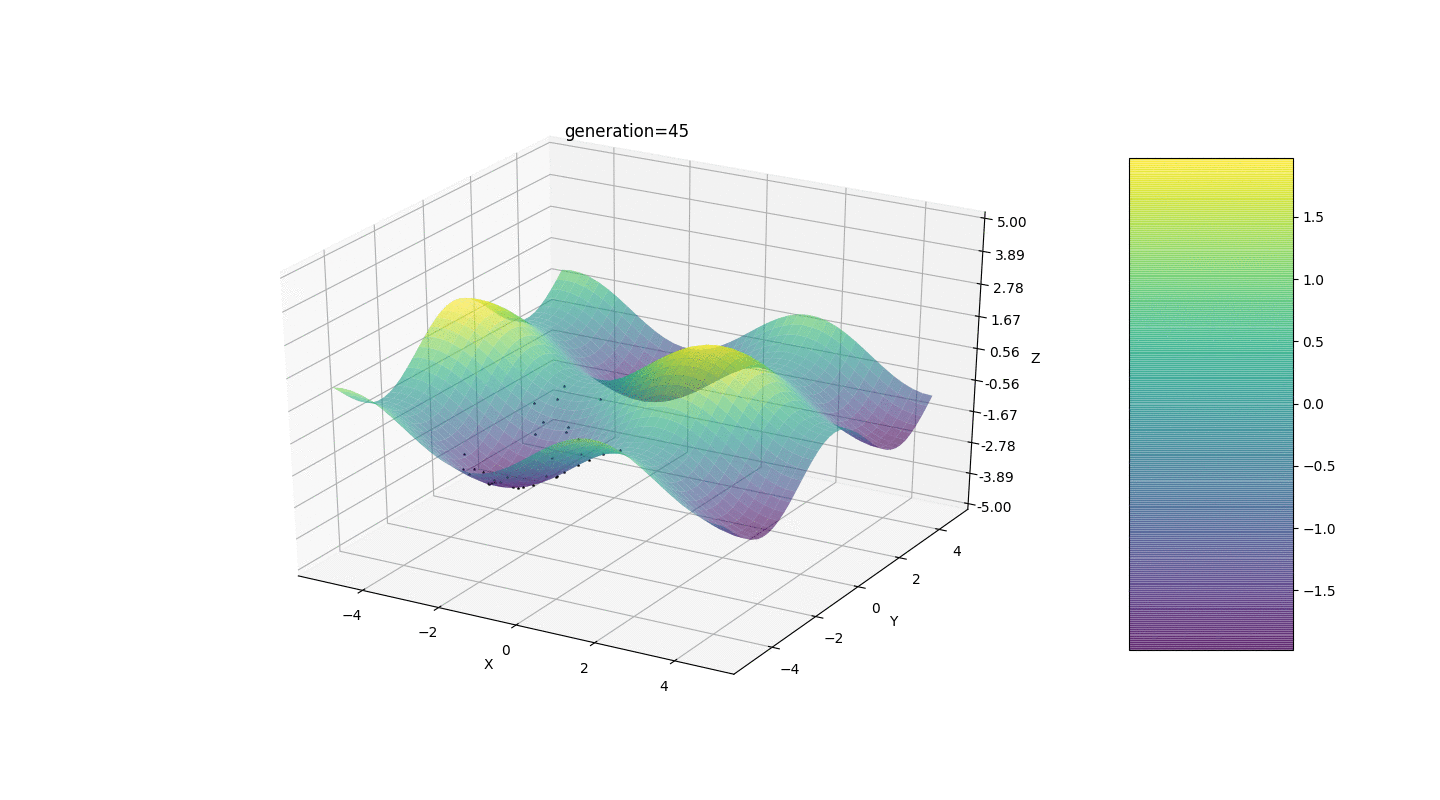
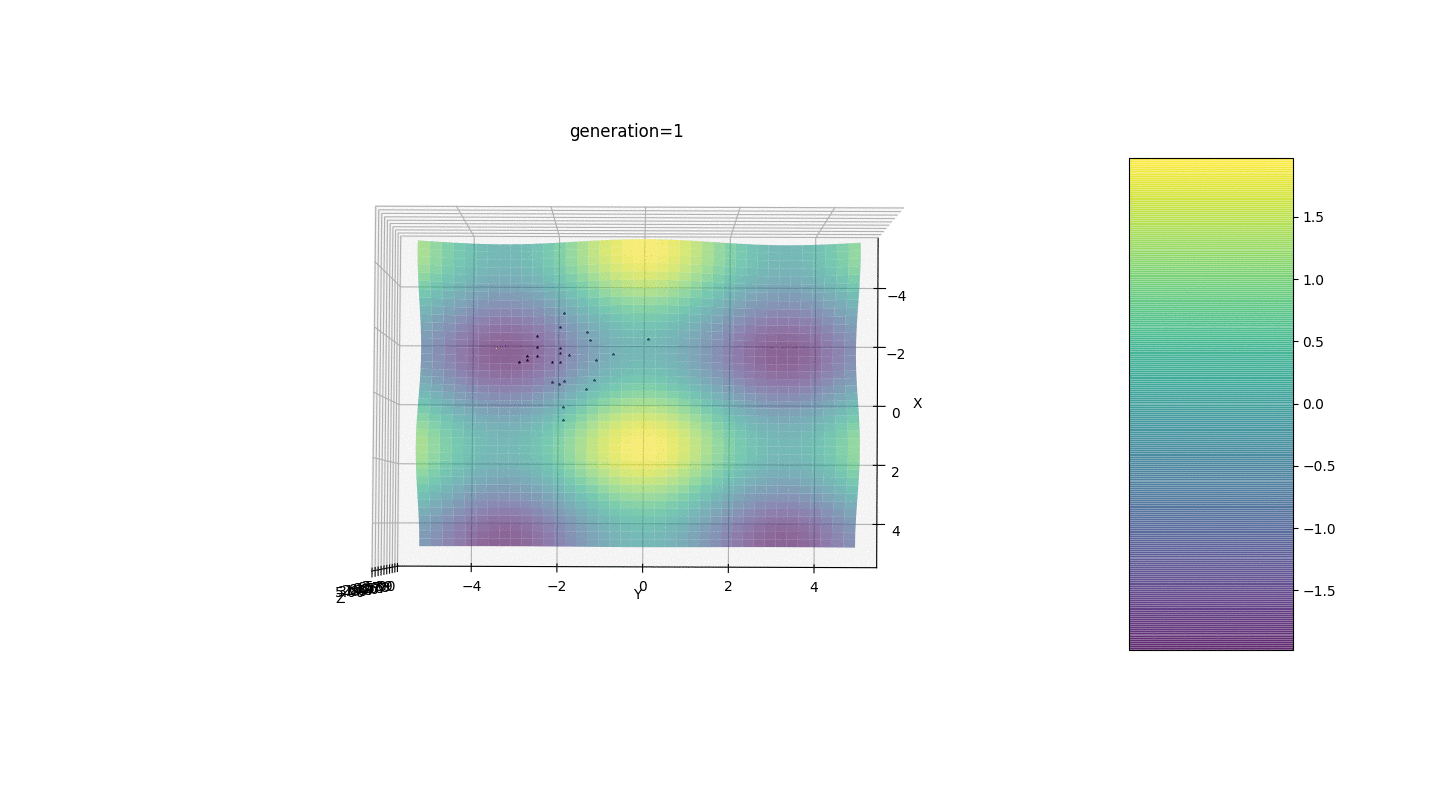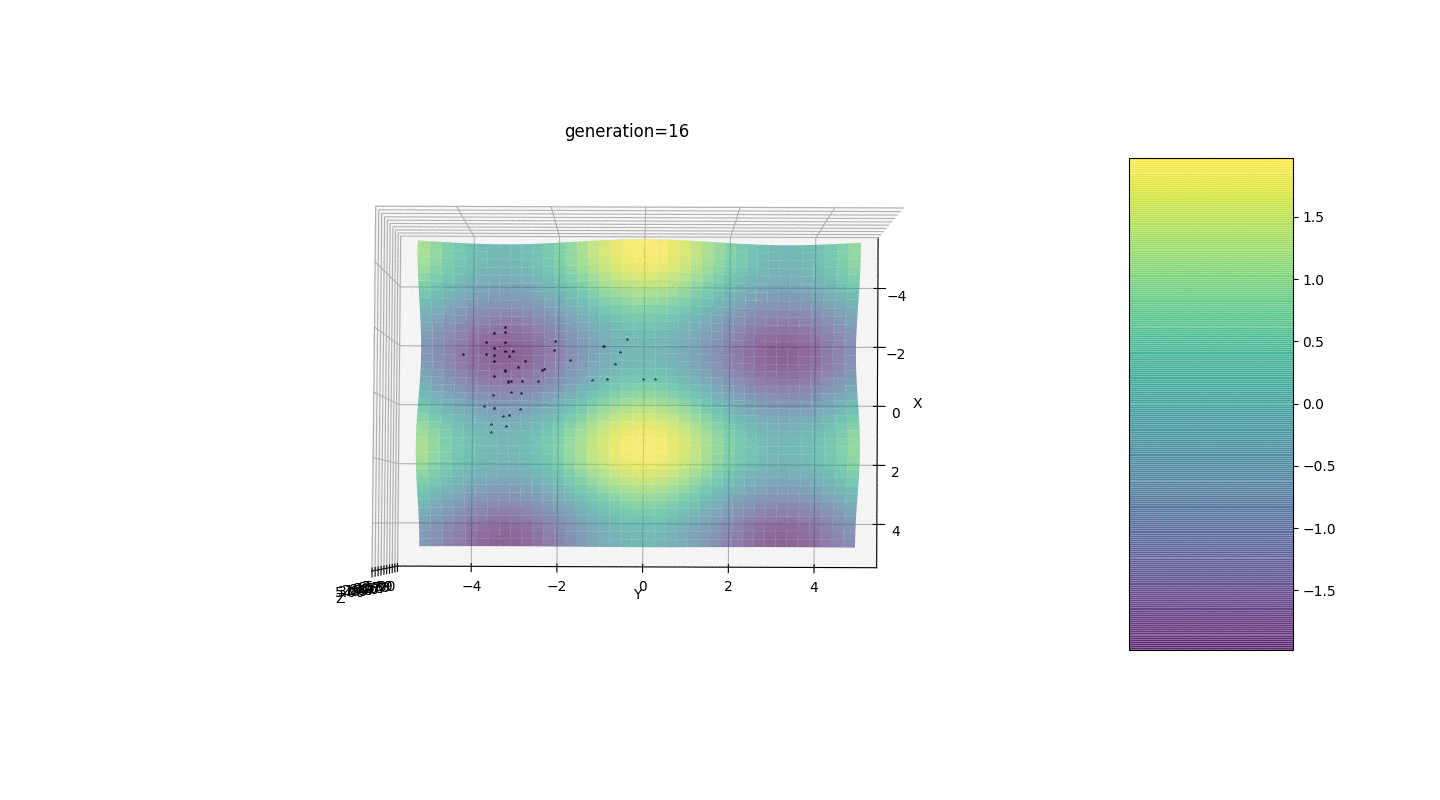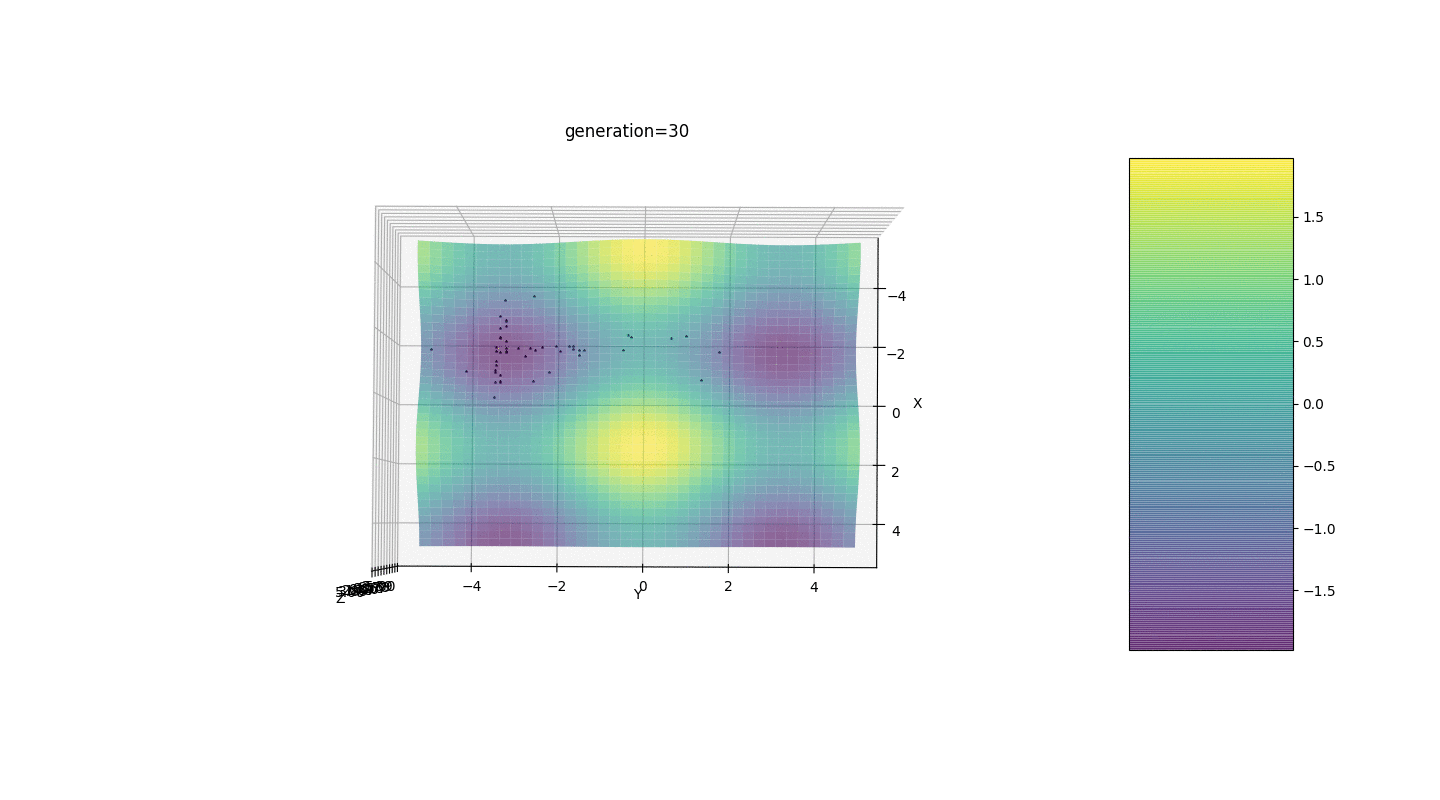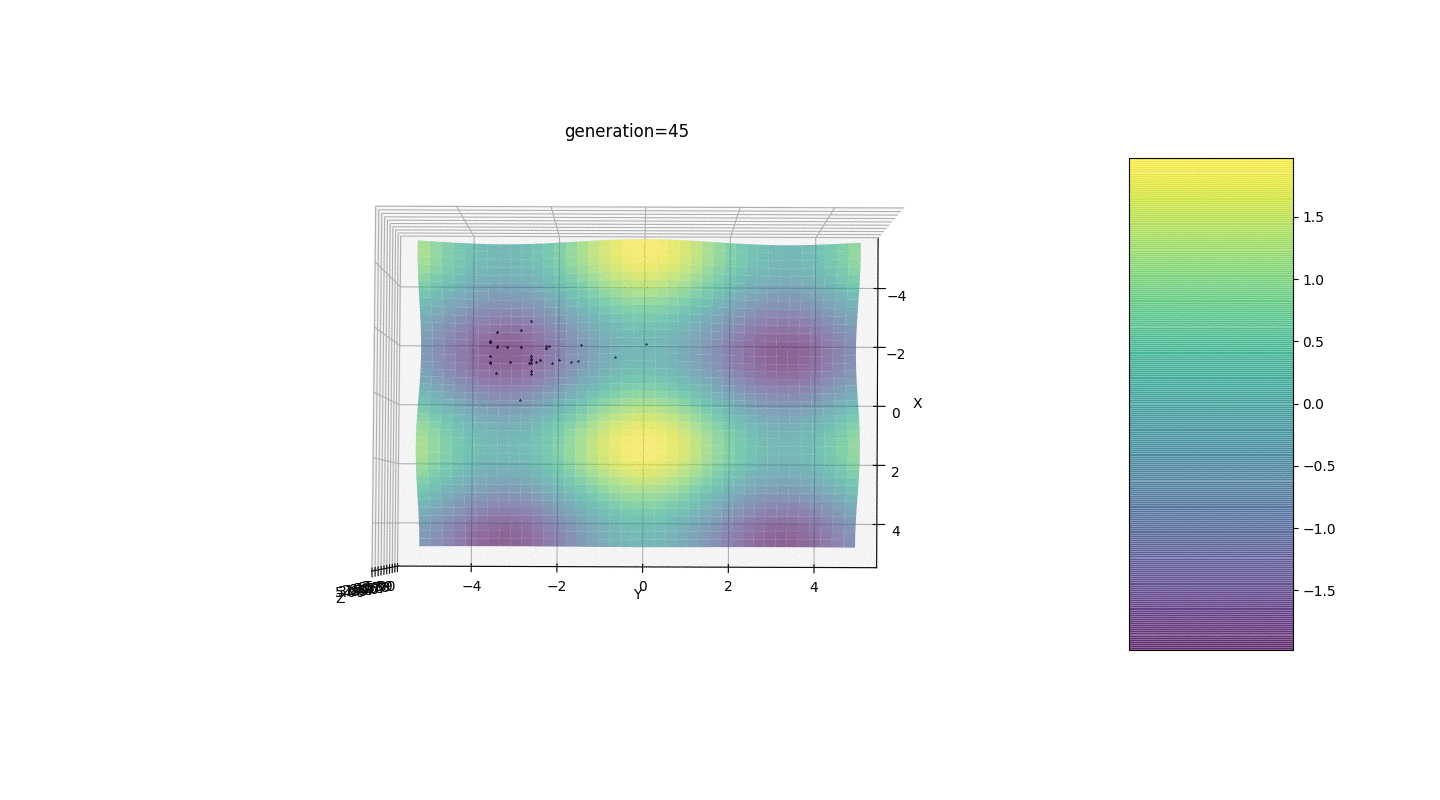
 Teste 2
Teste 2

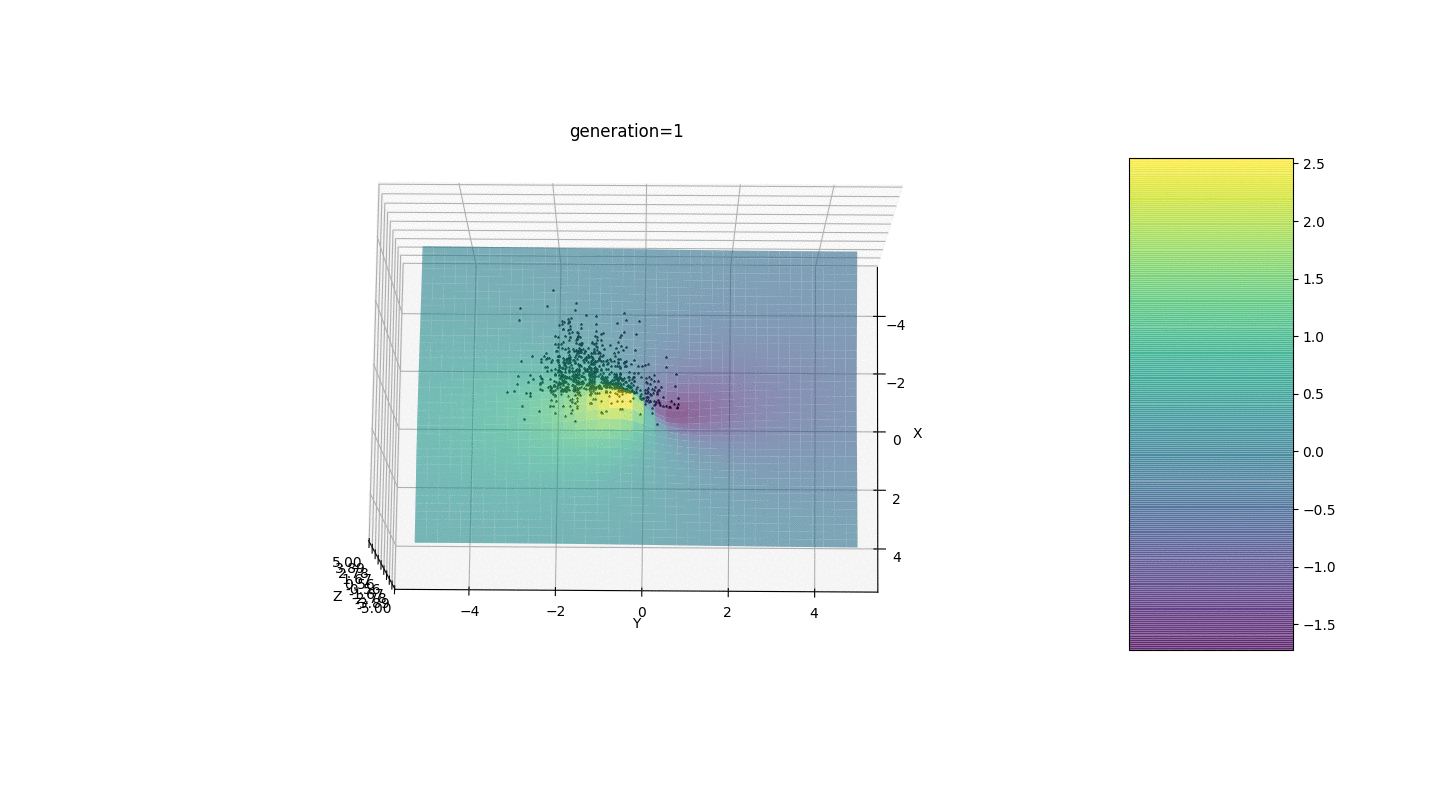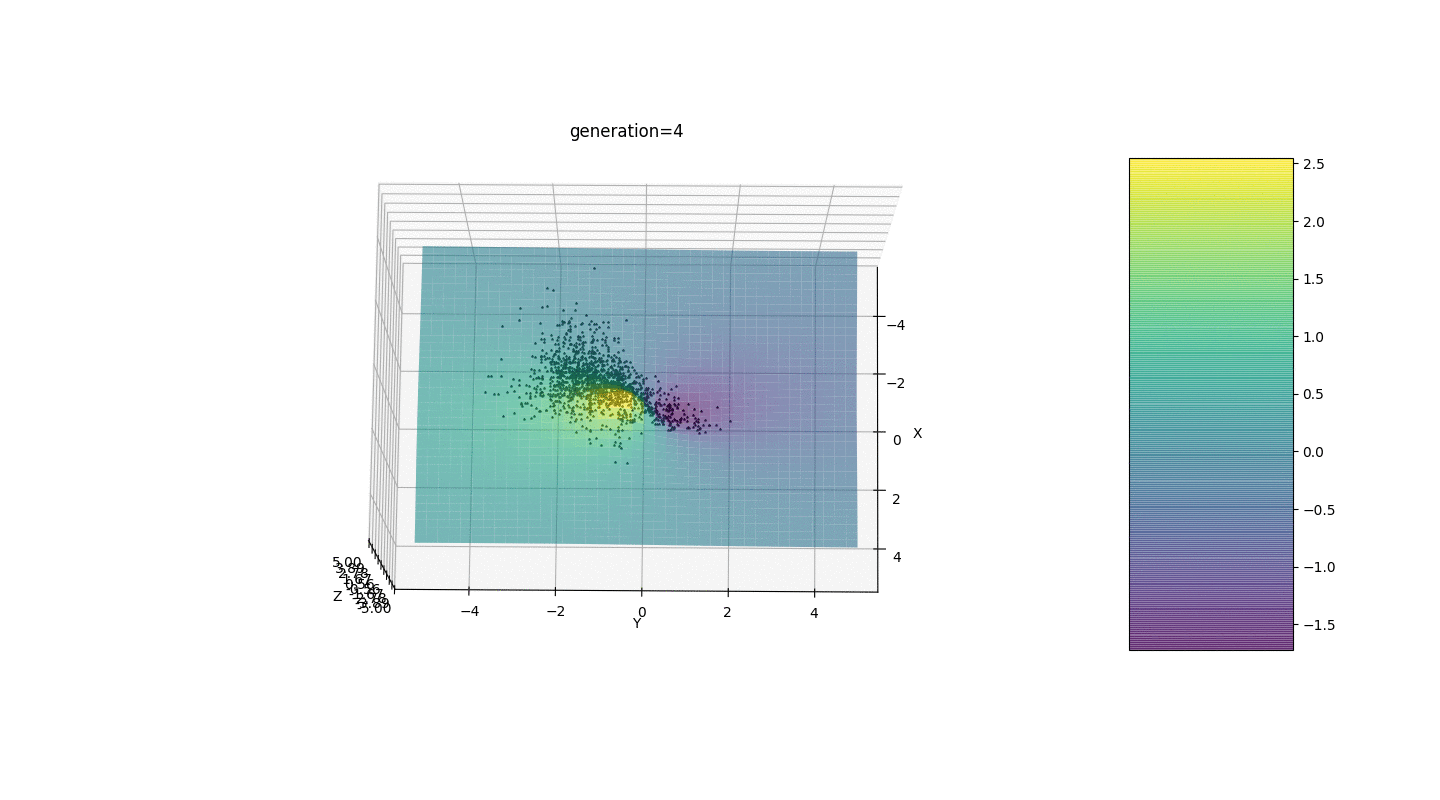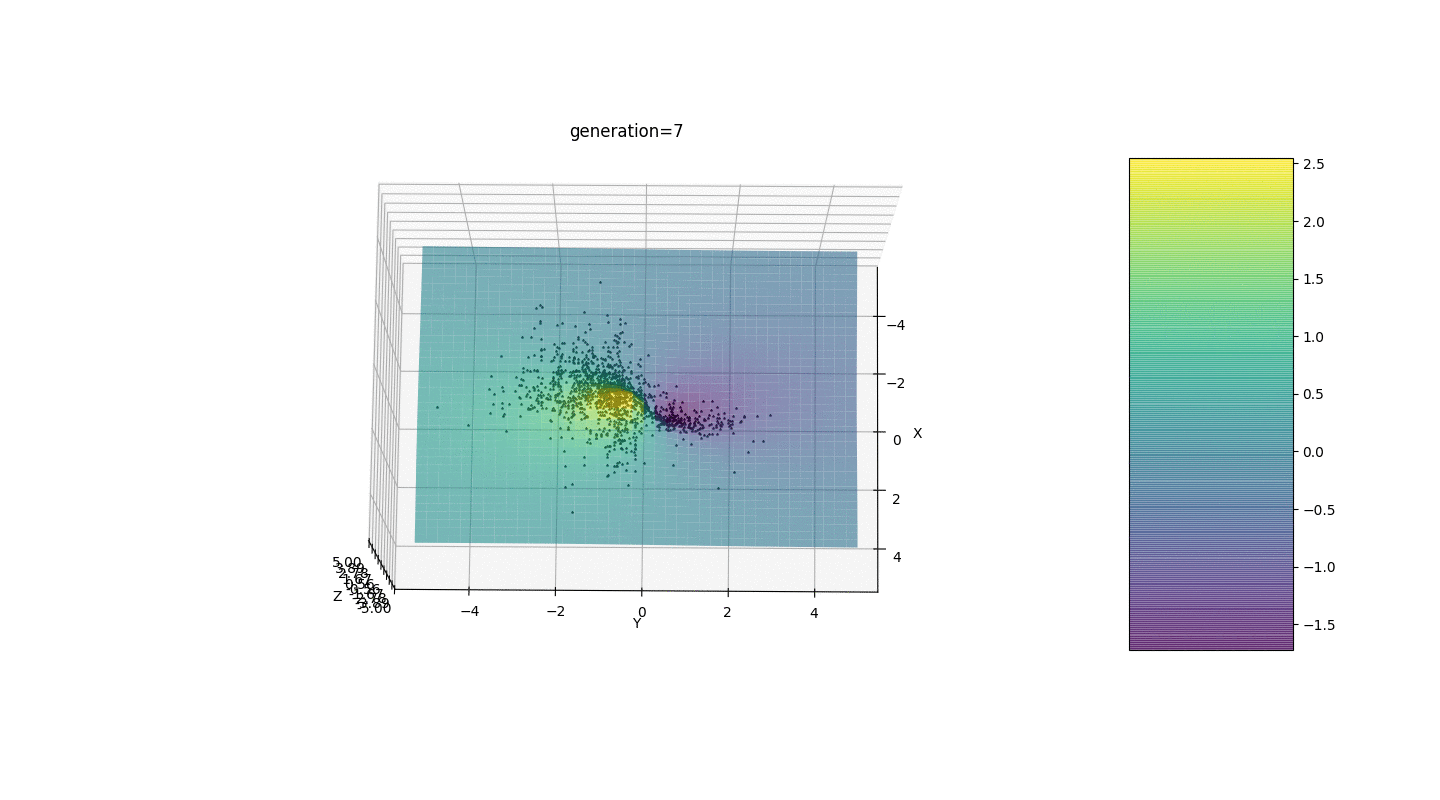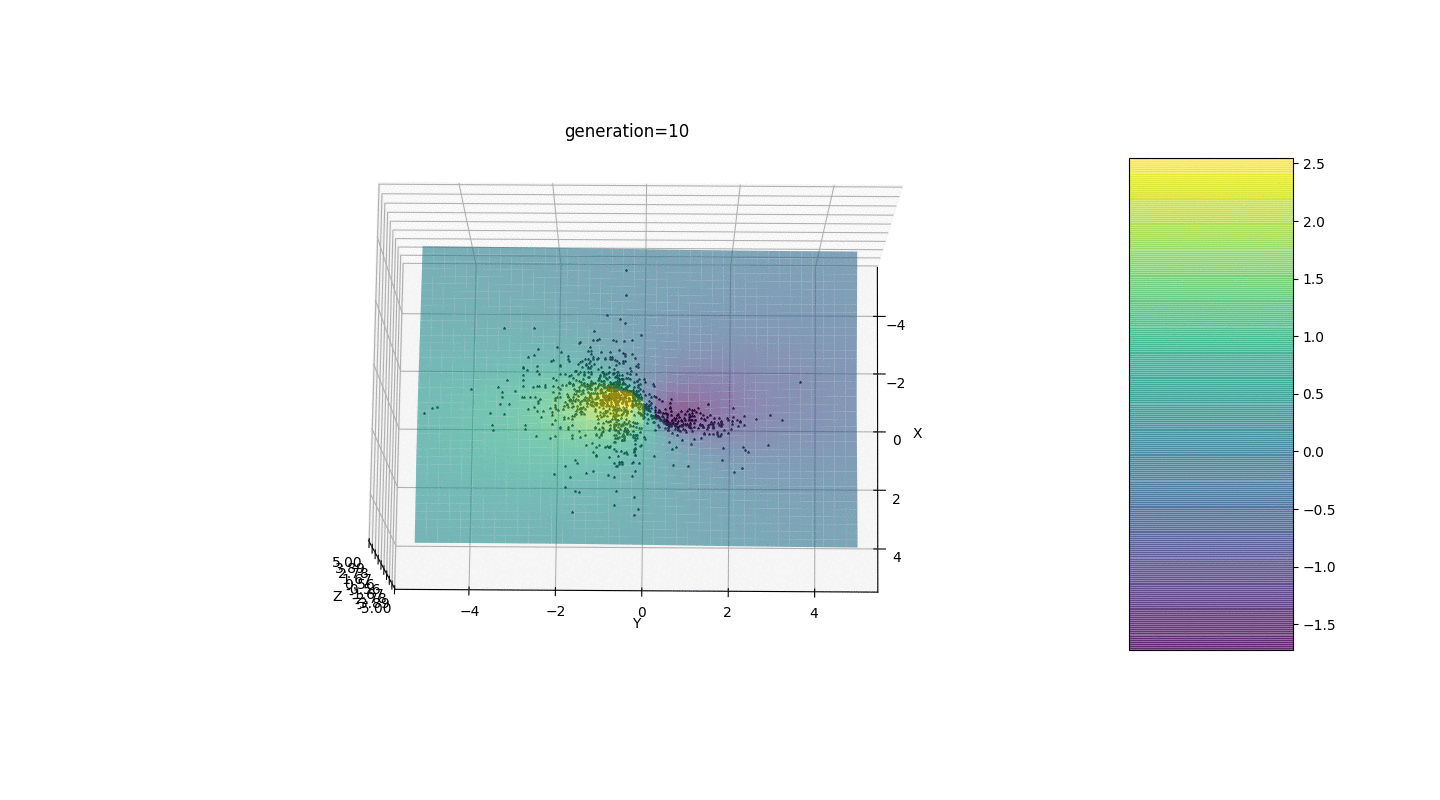
 Após testar e estudar a operação do algoritmo pelo método de olhar e cutucada aleatória, várias hipóteses-padrões foram revelados:
Após testar e estudar a operação do algoritmo pelo método de olhar e cutucada aleatória, várias hipóteses-padrões foram revelados:- , ,
- - . , , , ( )
- 5-15 , «»
- A geração zero é preenchida com números aleatórios apenas em um quadrado
e pode haver casos em que esta praça cubra um extremo local, o que não nos convém
Considere uma superfície com muitos extremos da forma:Os extremos da função g estarão em pontos.Teste 3 Este exemplo confirma e ilustra todas as observações acima.
Este exemplo confirma e ilustra todas as observações acima.Atualização de algoritmo genético
Então, no momento, a função de mutação é composta muito primitivamente: adiciona valores aleatórios a partir do intervalopara o gene mutado. Essa invariância às mutações às vezes interfere na operação correta do algoritmo, mas existe uma maneira eficaz de corrigir esse defeito.Introduzimos um novo parâmetro, que chamaremos de "faixa de mutação" e que mostrará em qual intervalo de tempo o gene sofrerá mutação. Vamos fazer com que esse coeficiente de mutação seja inversamente proporcional ao número de geração. Essa. quanto maior o número de geração, mais fracos os genes sofrem mutação. Esta solução permite que você personalize a área inicial e melhore a precisão dos cálculos, se necessário.Teste 1
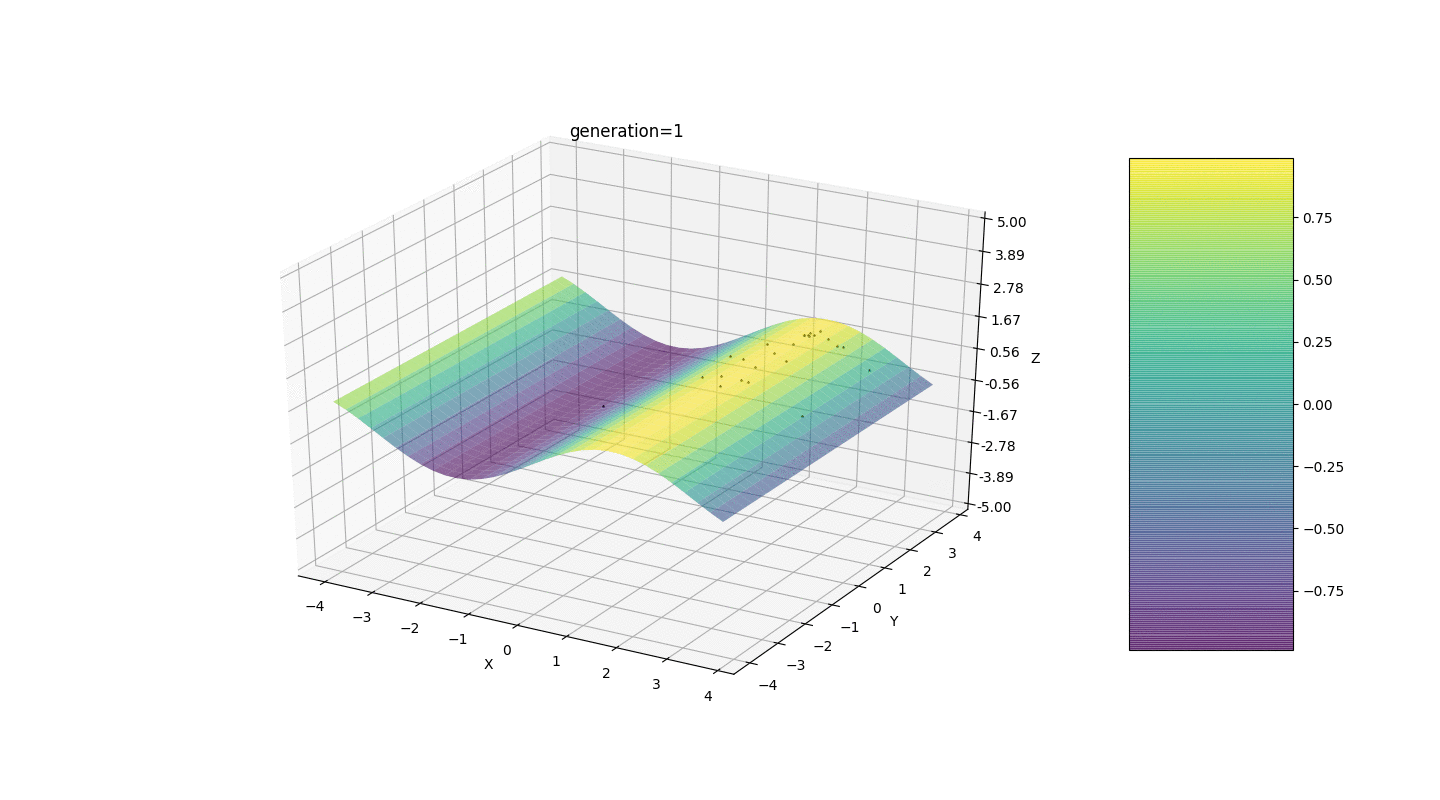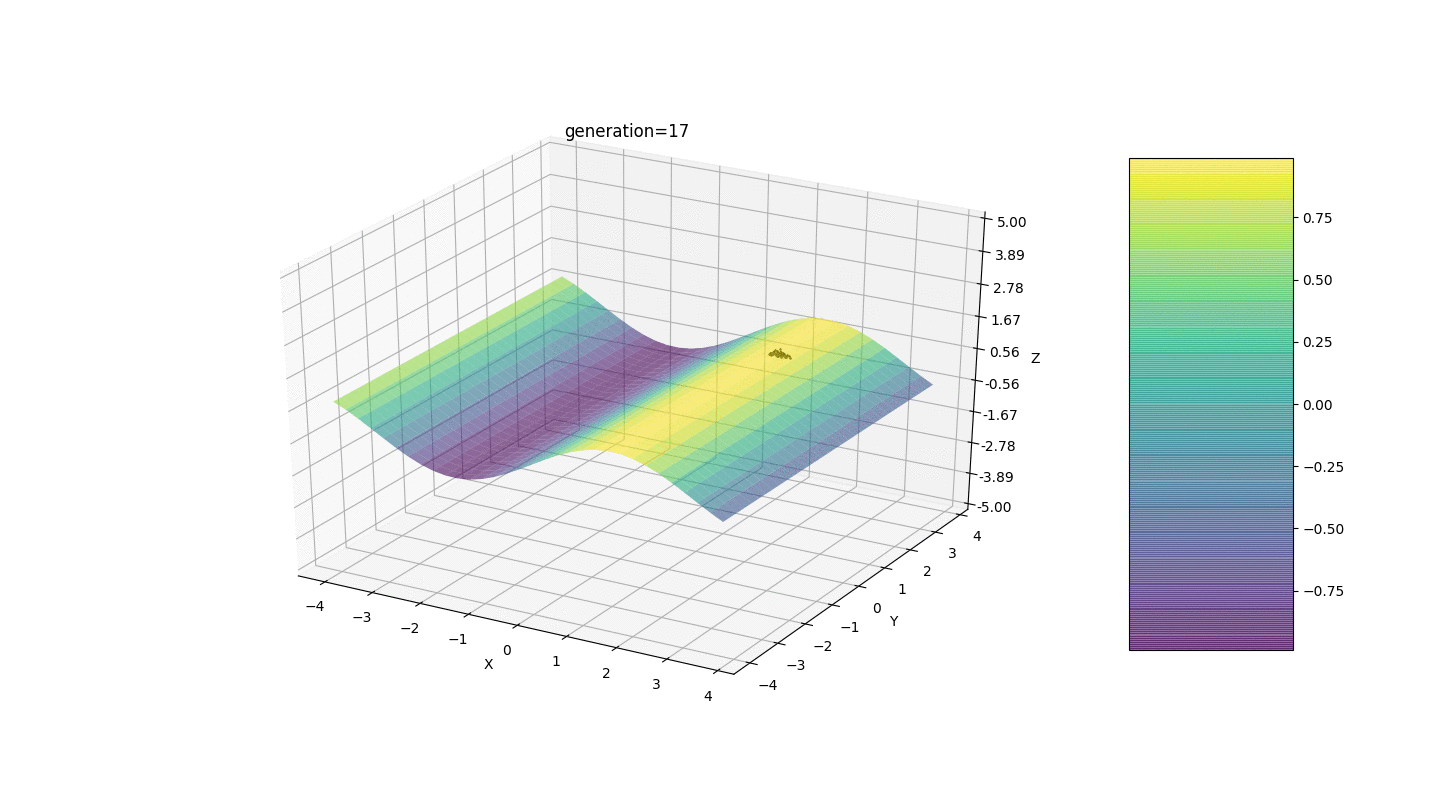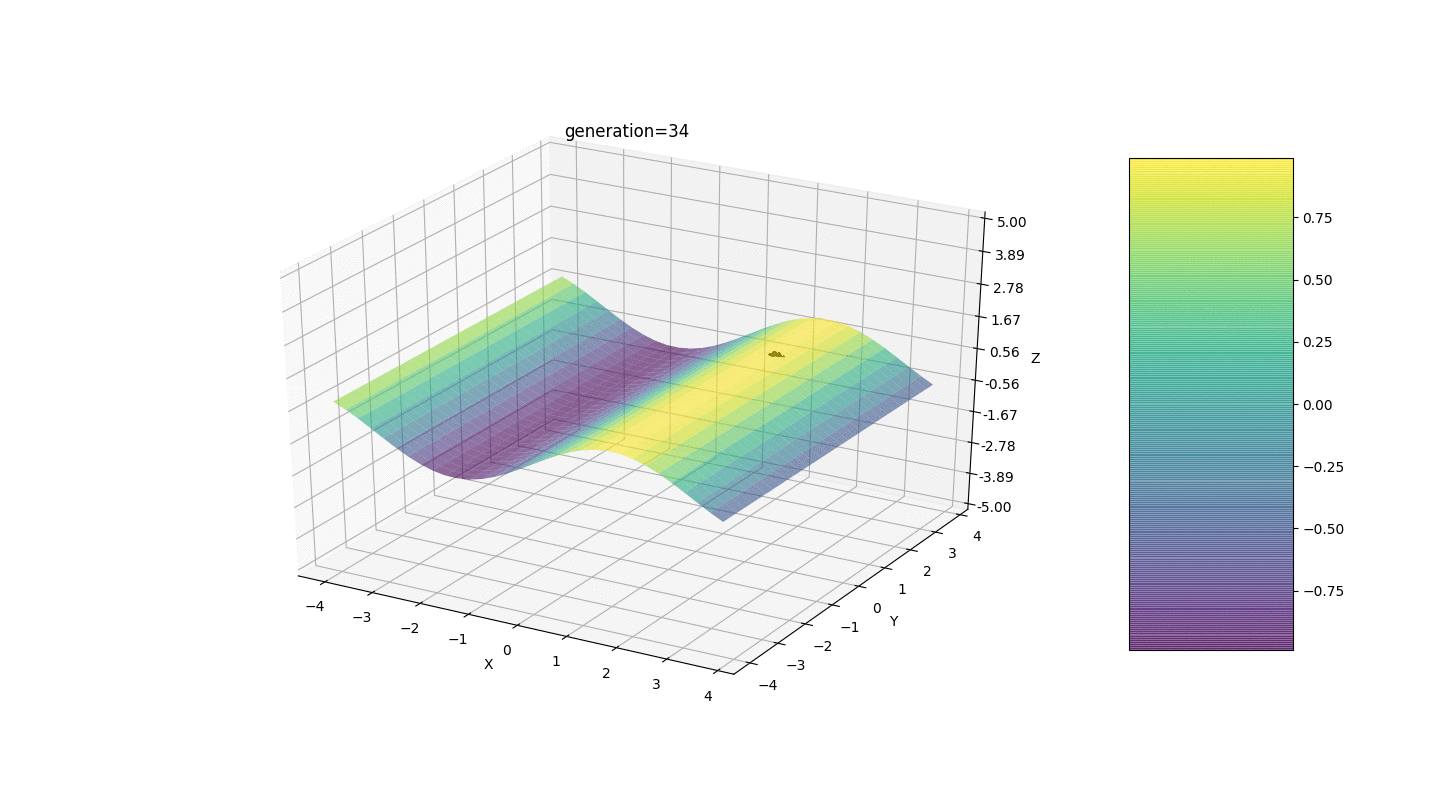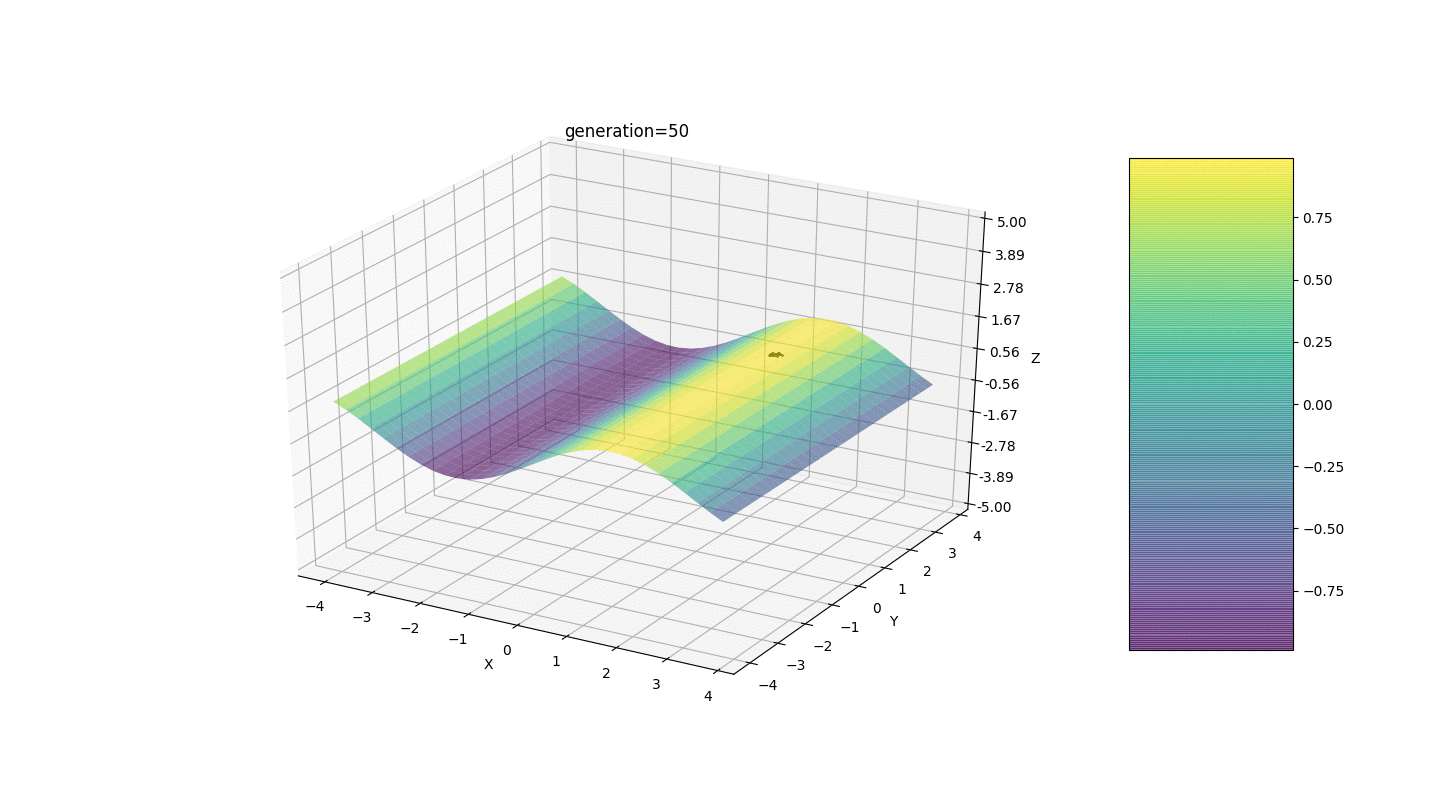
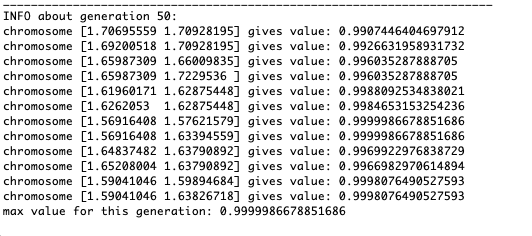 Como o exemplo mostra, agora, a cada geração, a população converge cada vez mais ao ponto extremo e calcula os valores mais precisos devido a flutuações fracas.Mas e o problema dos extremos locais? Considere um exemplo familiar.Teste 2
Como o exemplo mostra, agora, a cada geração, a população converge cada vez mais ao ponto extremo e calcula os valores mais precisos devido a flutuações fracas.Mas e o problema dos extremos locais? Considere um exemplo familiar.Teste 2

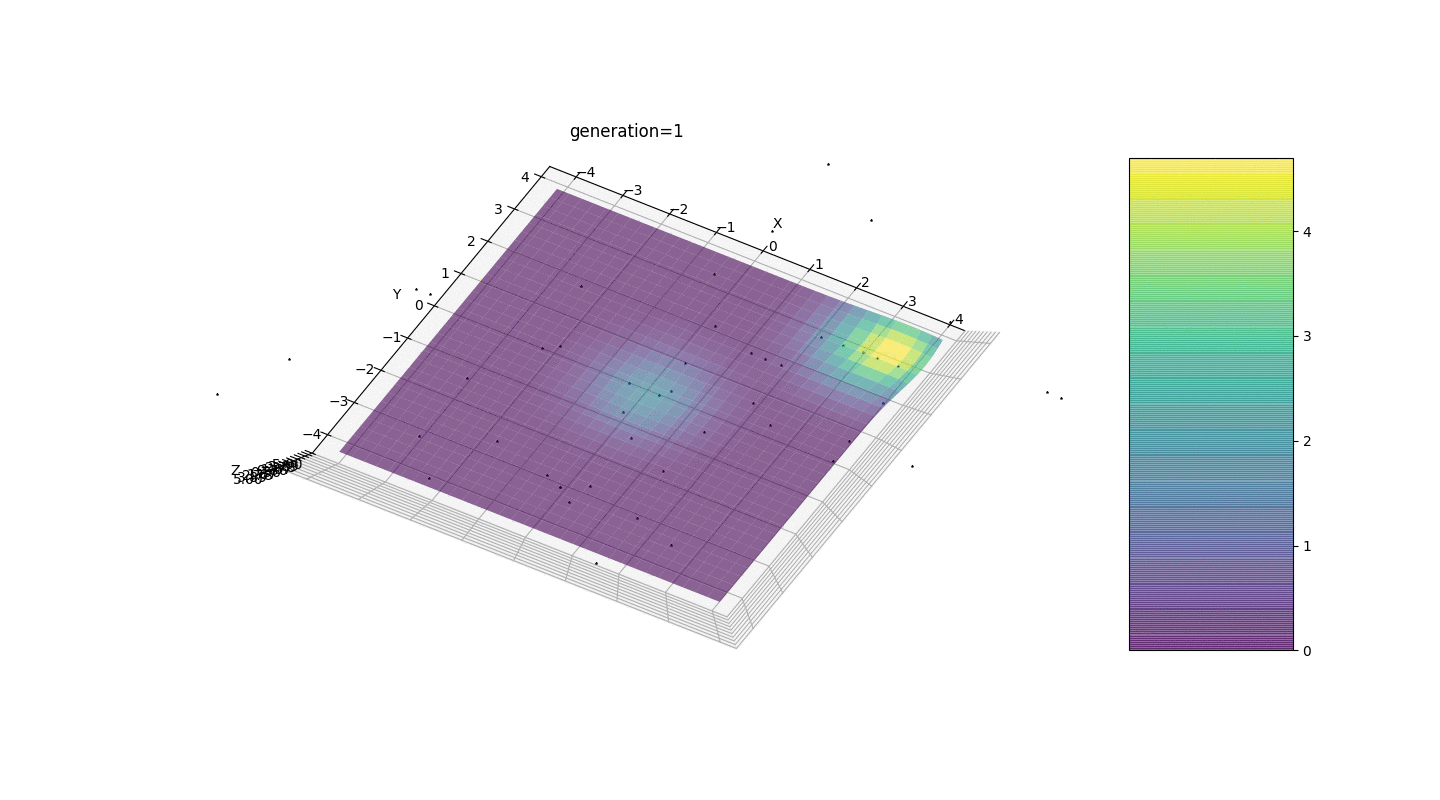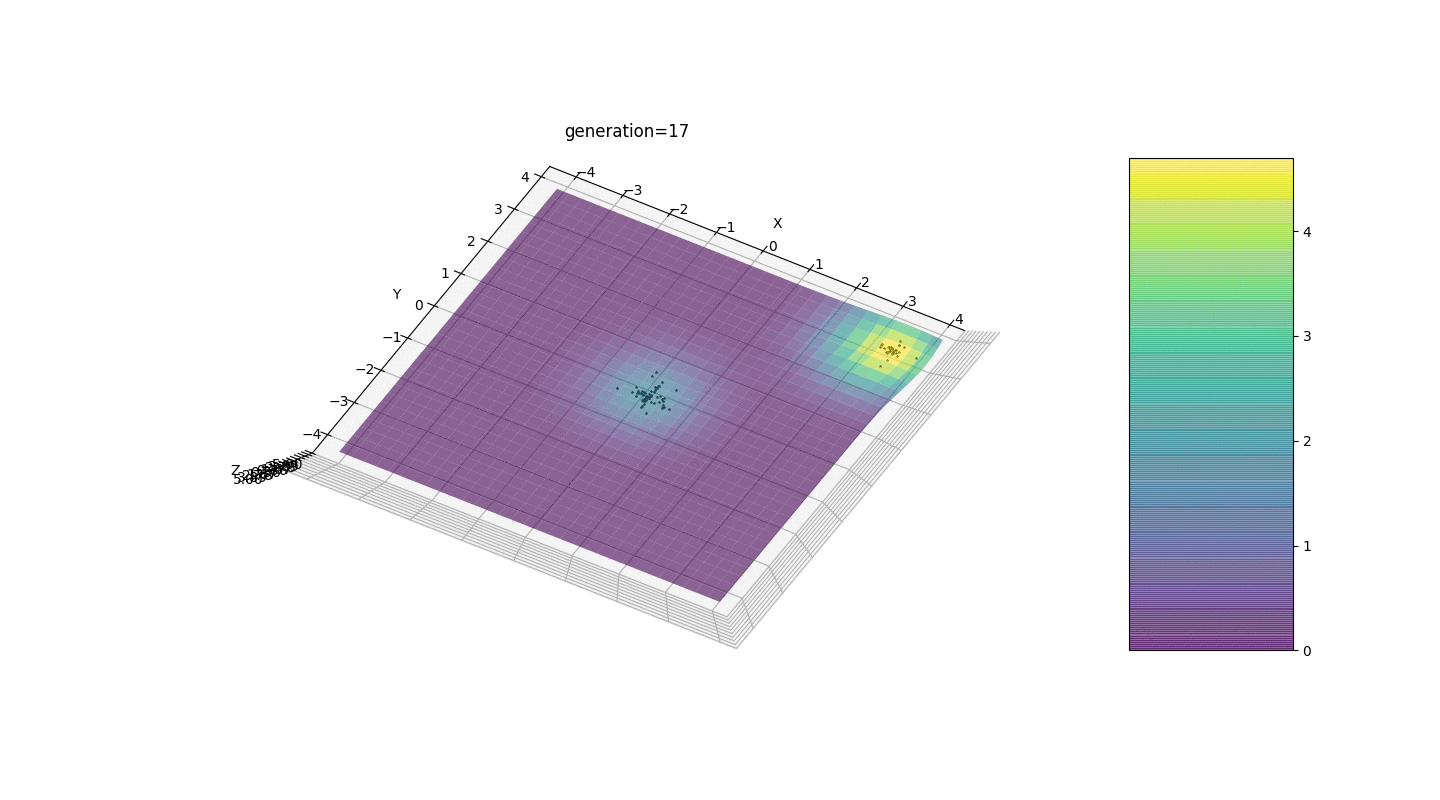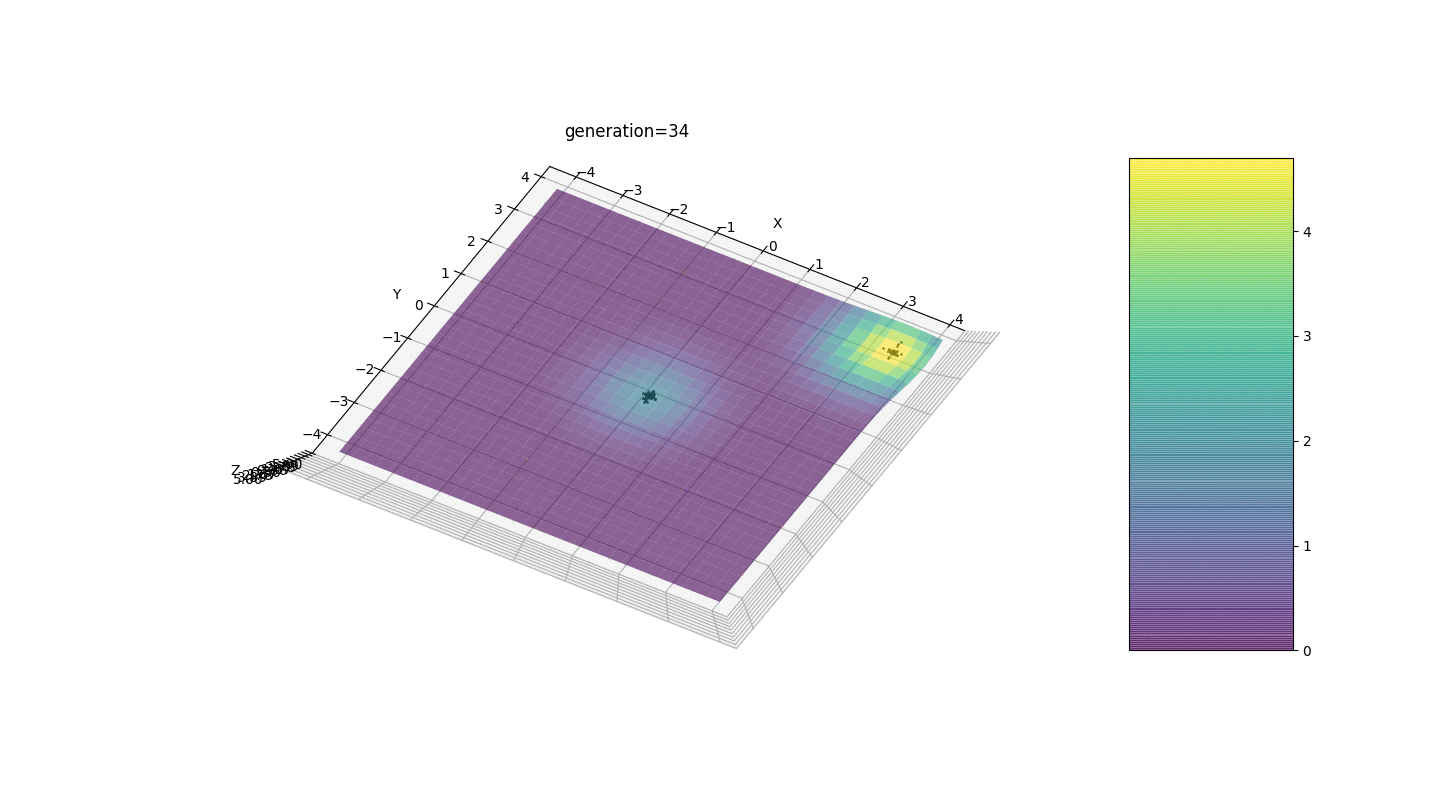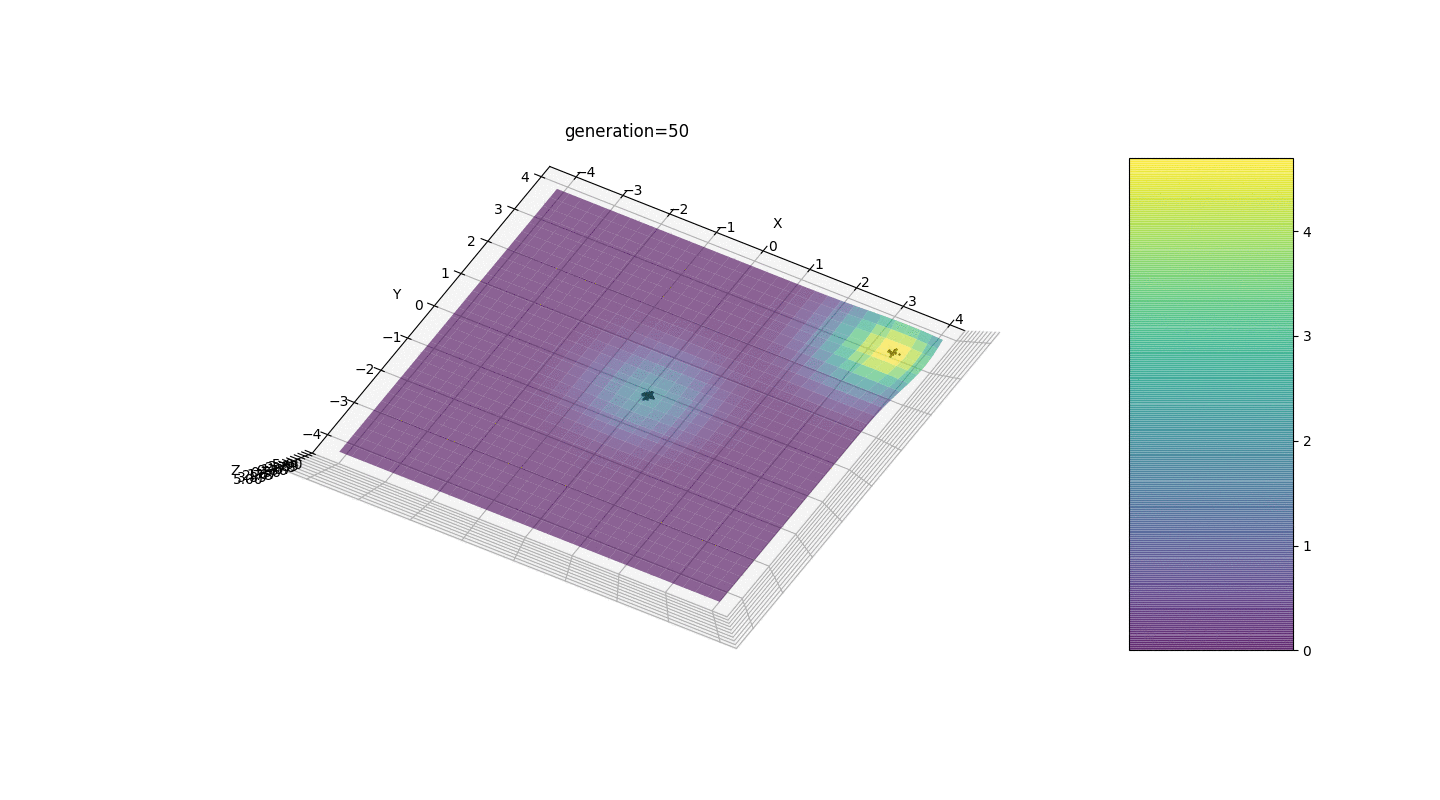
 Vemos que agora a ideia de dividir a população em partes funciona como pretendido. Sem essa segmentação, indivíduos de gerações anteriores poderiam revelar um genótipo falso dominante em um extremo local, o que levaria a uma resposta incorreta na tarefa. Também é perceptível uma melhoria qualitativa na precisão da resposta devido à dependência introduzida da mutação no número de geração.
Vemos que agora a ideia de dividir a população em partes funciona como pretendido. Sem essa segmentação, indivíduos de gerações anteriores poderiam revelar um genótipo falso dominante em um extremo local, o que levaria a uma resposta incorreta na tarefa. Também é perceptível uma melhoria qualitativa na precisão da resposta devido à dependência introduzida da mutação no número de geração.Sumário
Resumo o resultado:- O conjunto correto de parâmetros permite encontrar com precisão o extremo global de uma função de duas variáveis
- ,
- ,
...