Vamos nos familiarizar com um dos ataques à rede neural, o que leva a erros de classificação com o mínimo de influências externas. Imagine por um momento que a rede neural é você. E, no momento, enquanto bebe uma xícara de café aromático, você classifica as imagens de gatos com uma precisão de mais de 90%, sem sequer suspeitar que o "ataque de um pixel" transformou todos os seus "gatos" em caminhões.E agora vamos fazer uma pausa, afastar o café, importar todas as bibliotecas necessárias e analisar como esses ataques de um pixel funcionam.O objetivo deste ataque é fazer com que o algoritmo (rede neural) dê uma resposta incorreta. Abaixo, veremos isso com vários modelos diferentes de redes neurais convolucionais. Usando um dos métodos de otimização matemática multidimensional - evolução diferencial, encontramos um pixel especial que pode alterar a imagem para que a rede neural comece a classificá-la incorretamente (apesar do fato de que anteriormente o algoritmo "reconheceu" a mesma imagem corretamente e com alta precisão).Importe as bibliotecas:
%matplotlib inline
import pickle
import numpy as np
import pandas as pd
import matplotlib
from keras.datasets import cifar10
from keras import backend as K
from networks.lenet import LeNet
from networks.pure_cnn import PureCnn
from networks.network_in_network import NetworkInNetwork
from networks.resnet import ResNet
from networks.densenet import DenseNet
from networks.wide_resnet import WideResNet
from networks.capsnet import CapsNet
from differential_evolution import differential_evolution
import helper
matplotlib.style.use('ggplot')
Para nosso experimento, carregaremos o conjunto de dados CIFAR-10 contendo imagens do mundo real divididas em 10 classes.(x_train, y_train), (x_test, y_test) = cifar10.load_data()
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
Vamos olhar para qualquer imagem pelo seu índice. Por exemplo, aqui neste cavalo.image_id = 99
helper.plot_image(x_test[image_id])
 Teremos que procurar o pixel muito poderoso que pode alterar a resposta da rede neural, o que significa que é hora de escrever uma função para alterar um ou mais pixels da imagem.
Teremos que procurar o pixel muito poderoso que pode alterar a resposta da rede neural, o que significa que é hora de escrever uma função para alterar um ou mais pixels da imagem.def perturb_image(xs, img):
if xs.ndim < 2:
xs = np.array([xs])
tile = [len(xs)] + [1]*(xs.ndim+1)
imgs = np.tile(img, tile)
xs = xs.astype(int)
for x,img in zip(xs, imgs):
pixels = np.split(x, len(x) // 5)
for pixel in pixels:
x_pos, y_pos, *rgb = pixel
img[x_pos, y_pos] = rgb
return imgs
Confira ?! Mude um pixel do nosso cavalo com coordenadas (16, 16) para amarelo.image_id = 99
pixel = np.array([16, 16, 255, 255, 0])
image_perturbed = perturb_image(pixel, x_test[image_id])[0]
helper.plot_image(image_perturbed)
 Para demonstrar o ataque, você precisa fazer o download de modelos pré-treinados de redes neurais em nosso conjunto de dados CIFAR-10. Usaremos dois modelos lenet e resnet, mas você pode usar outros para seus experimentos descomentando as linhas de código correspondentes.
Para demonstrar o ataque, você precisa fazer o download de modelos pré-treinados de redes neurais em nosso conjunto de dados CIFAR-10. Usaremos dois modelos lenet e resnet, mas você pode usar outros para seus experimentos descomentando as linhas de código correspondentes.lenet = LeNet()
resnet = ResNet()
models = [lenet, resnet]
Depois de carregar os modelos, é necessário avaliar as imagens de teste de cada modelo para garantir que atacemos apenas imagens classificadas corretamente. O código abaixo exibe a precisão e o número de parâmetros para cada modelo.network_stats, correct_imgs = helper.evaluate_models(models, x_test, y_test)
correct_imgs = pd.DataFrame(correct_imgs, columns=['name', 'img', 'label', 'confidence', 'pred'])
network_stats = pd.DataFrame(network_stats, columns=['name', 'accuracy', 'param_count'])
network_stats
Evaluating lenet
Evaluating resnet
Out[11]:
name accuracy param_count
0 lenet 0.748 62006
1 resnet 0.9231 470218
Todos esses ataques podem ser divididos em duas classes: WhiteBox e BlackBox. A diferença entre eles é que, no primeiro caso, todos sabemos com segurança sobre o algoritmo, o modelo com o qual estamos lidando. No caso do BlackBox, tudo o que precisamos é de entrada (imagem) e saída (probabilidade de ser atribuída a uma das classes). Um ataque de pixel refere-se ao BlackBox.Neste artigo, consideramos duas opções para atacar um único pixel: não segmentado e direcionado. No primeiro caso, não importará absolutamente a que classe a rede neural de nosso gato pertencerá, mais importante, não à classe de gatos. O ataque direcionado é aplicável quando queremos que nosso gato se torne um caminhão e apenas um caminhão.Mas como encontrar os próprios pixels cuja mudança levará a uma mudança na classe da imagem? Como encontrar um pixel alterando qual ataque de um pixel se torna possível e bem-sucedido? Vamos tentar formular esse problema como um problema de otimização, mas apenas com palavras muito simples: com um ataque não direcionado, devemos minimizar a confiança na classe desejada e, com o objetivo, maximizar a confiança na classe de destino.Ao realizar esses ataques, é difícil otimizar a função usando um gradiente. Deve-se usar um algoritmo de otimização que não dependa da suavidade da função.Lembre-se de que, para nosso experimento, usamos o conjunto de dados CIFAR-10, que contém imagens do mundo real, tamanho 32 x 32 pixels, dividido em 10 classes. E isso significa que temos valores inteiros discretos de 0 a 31 e intensidades de cores de 0 a 255, e não se espera que a função seja suave, mas sim irregular, como mostrado abaixo: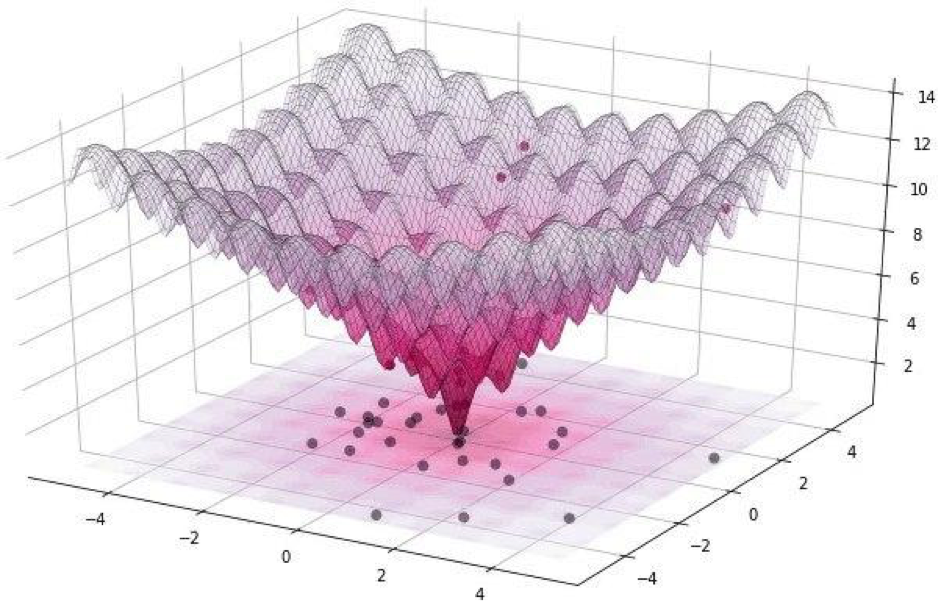 É por isso que usamos o algoritmo de evolução diferencial.Mas voltando ao código e escreva uma função que retorne a probabilidade da confiabilidade do modelo. Se a classe de destino estiver correta, queremos minimizar essa função para que o modelo tenha certeza de outra classe (o que não é verdade).
É por isso que usamos o algoritmo de evolução diferencial.Mas voltando ao código e escreva uma função que retorne a probabilidade da confiabilidade do modelo. Se a classe de destino estiver correta, queremos minimizar essa função para que o modelo tenha certeza de outra classe (o que não é verdade).def predict_classes(xs, img, target_class, model, minimize=True):
imgs_perturbed = perturb_image(xs, img)
predictions = model.predict(imgs_perturbed)[:,target_class]
return predictions if minimize else 1 - predictions
image_id = 384
pixel = np.array([16, 13, 25, 48, 156])
model = resnet
true_class = y_test[image_id, 0]
prior_confidence = model.predict_one(x_test[image_id])[true_class]
confidence = predict_classes(pixel, x_test[image_id], true_class, model)[0]
print('Confidence in true class', class_names[true_class], 'is', confidence)
print('Prior confidence was', prior_confidence)
helper.plot_image(perturb_image(pixel, x_test[image_id])[0])
Confidence in true class bird is 0.00018887444
Prior confidence was 0.70661753
 Nós precisaremos da próxima função para confirmar o critério para o sucesso do ataque, ele retornará True quando a alteração foi suficiente para enganar o modelo.
Nós precisaremos da próxima função para confirmar o critério para o sucesso do ataque, ele retornará True quando a alteração foi suficiente para enganar o modelo.def attack_success(x, img, target_class, model, targeted_attack=False, verbose=False):
attack_image = perturb_image(x, img)
confidence = model.predict(attack_image)[0]
predicted_class = np.argmax(confidence)
if verbose:
print('Confidence:', confidence[target_class])
if ((targeted_attack and predicted_class == target_class) or
(not targeted_attack and predicted_class != target_class)):
return True
Vejamos o trabalho da função de critério de sucesso. Para demonstrar, assumimos um ataque não-alvo.image_id = 541
pixel = np.array([17, 18, 185, 36, 215])
model = resnet
true_class = y_test[image_id, 0]
prior_confidence = model.predict_one(x_test[image_id])[true_class]
success = attack_success(pixel, x_test[image_id], true_class, model, verbose=True)
print('Prior confidence', prior_confidence)
print('Attack success:', success == True)
helper.plot_image(perturb_image(pixel, x_test[image_id])[0])
Confidence: 0.07460087
Prior confidence 0.50054216
Attack success: True
 É hora de coletar todos os quebra-cabeças em uma imagem. Usaremos uma pequena modificação na implementação da evolução diferencial no Scipy.
É hora de coletar todos os quebra-cabeças em uma imagem. Usaremos uma pequena modificação na implementação da evolução diferencial no Scipy.def attack(img_id, model, target=None, pixel_count=1,
maxiter=75, popsize=400, verbose=False):
targeted_attack = target is not None
target_class = target if targeted_attack else y_test[img_id, 0]
bounds = [(0,32), (0,32), (0,256), (0,256), (0,256)] * pixel_count
popmul = max(1, popsize // len(bounds))
def predict_fn(xs):
return predict_classes(xs, x_test[img_id], target_class,
model, target is None)
def callback_fn(x, convergence):
return attack_success(x, x_test[img_id], target_class,
model, targeted_attack, verbose)
attack_result = differential_evolution(
predict_fn, bounds, maxiter=maxiter, popsize=popmul,
recombination=1, atol=-1, callback=callback_fn, polish=False)
attack_image = perturb_image(attack_result.x, x_test[img_id])[0]
prior_probs = model.predict_one(x_test[img_id])
predicted_probs = model.predict_one(attack_image)
predicted_class = np.argmax(predicted_probs)
actual_class = y_test[img_id, 0]
success = predicted_class != actual_class
cdiff = prior_probs[actual_class] - predicted_probs[actual_class]
helper.plot_image(attack_image, actual_class, class_names, predicted_class)
return [model.name, pixel_count, img_id, actual_class, predicted_class, success, cdiff, prior_probs, predicted_probs, attack_result.x]
É hora de compartilhar os resultados do estudo (o ataque) e ver como mudar apenas um pixel transformará um sapo em cachorro, um gato em sapo e um carro em avião. Porém, quanto mais pontos da imagem puderem mudar, maior a probabilidade de um ataque bem-sucedido a qualquer imagem.

 Demonstre um ataque bem-sucedido a uma imagem de sapo usando o modelo de re-rede. Deveríamos ver confiança no verdadeiro declínio da classe após várias iterações.
Demonstre um ataque bem-sucedido a uma imagem de sapo usando o modelo de re-rede. Deveríamos ver confiança no verdadeiro declínio da classe após várias iterações.image_id = 102
pixels = 1
model = resnet
_ = attack(image_id, model, pixel_count=pixels, verbose=True)
Confidence: 0.9938618
Confidence: 0.77454716
Confidence: 0.77454716
Confidence: 0.77454716
Confidence: 0.77454716
Confidence: 0.77454716
Confidence: 0.53226393
Confidence: 0.53226393
Confidence: 0.53226393
Confidence: 0.53226393
Confidence: 0.4211318
 Estes foram exemplos de um ataque não direcionado e agora vamos realizar um ataque direcionado e escolher para qual classe gostaríamos que o modelo classificasse a imagem. A tarefa é muito mais complicada do que a anterior, porque faremos com que a rede neural classifique a imagem de um navio como um carro e um cavalo como um gato.
Estes foram exemplos de um ataque não direcionado e agora vamos realizar um ataque direcionado e escolher para qual classe gostaríamos que o modelo classificasse a imagem. A tarefa é muito mais complicada do que a anterior, porque faremos com que a rede neural classifique a imagem de um navio como um carro e um cavalo como um gato.
 Abaixo tentaremos obter lenet para classificar a imagem do navio como um carro.
Abaixo tentaremos obter lenet para classificar a imagem do navio como um carro.image_id = 108
target_class = 1
pixels = 3
model = lenet
print('Attacking with target', class_names[target_class])
_ = attack(image_id, model, target_class, pixel_count=pixels, verbose=True)
Attacking with target automobile
Confidence: 0.044409167
Confidence: 0.044409167
Confidence: 0.044409167
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.054611664
Confidence: 0.081972085
Confidence: 0.081972085
Confidence: 0.081972085
Confidence: 0.081972085
Confidence: 0.1537778
Confidence: 0.1537778
Confidence: 0.1537778
Confidence: 0.22246778
Confidence: 0.23916133
Confidence: 0.25238588
Confidence: 0.25238588
Confidence: 0.25238588
Confidence: 0.44560355
Confidence: 0.44560355
Confidence: 0.44560355
Confidence: 0.5711696
 Tendo lidado com casos únicos de ataques, coletaremos estatísticas usando a arquitetura das redes neurais convolucionais ResNet, passando por cada modelo, alterando 1, 3 ou 5 pixels de cada imagem. Neste artigo, mostramos as conclusões finais sem incomodar o leitor a se familiarizar com cada iteração, uma vez que leva muito tempo e recursos computacionais.
Tendo lidado com casos únicos de ataques, coletaremos estatísticas usando a arquitetura das redes neurais convolucionais ResNet, passando por cada modelo, alterando 1, 3 ou 5 pixels de cada imagem. Neste artigo, mostramos as conclusões finais sem incomodar o leitor a se familiarizar com cada iteração, uma vez que leva muito tempo e recursos computacionais.def attack_all(models, samples=500, pixels=(1,3,5), targeted=False,
maxiter=75, popsize=400, verbose=False):
results = []
for model in models:
model_results = []
valid_imgs = correct_imgs[correct_imgs.name == model.name].img
img_samples = np.random.choice(valid_imgs, samples, replace=False)
for pixel_count in pixels:
for i, img_id in enumerate(img_samples):
print('\n', model.name, '- image', img_id, '-', i+1, '/', len(img_samples))
targets = [None] if not targeted else range(10)
for target in targets:
if targeted:
print('Attacking with target', class_names[target])
if target == y_test[img, 0]:
continue
result = attack(img_id, model, target, pixel_count,
maxiter=maxiter, popsize=popsize,
verbose=verbose)
model_results.append(result)
results += model_results
helper.checkpoint(results, targeted)
return results
untargeted = attack_all(models, samples=100, targeted=False)
targeted = attack_all(models, samples=10, targeted=False)
Para testar a possibilidade de desacreditar a rede, um algoritmo foi desenvolvido e seu efeito na qualidade prevista da solução de reconhecimento de padrões foi medido.Vamos ver os resultados finais.untargeted, targeted = helper.load_results()
columns = ['model', 'pixels', 'image', 'true', 'predicted', 'success', 'cdiff', 'prior_probs', 'predicted_probs', 'perturbation']
untargeted_results = pd.DataFrame(untargeted, columns=columns)
targeted_results = pd.DataFrame(targeted, columns=columns)
A tabela abaixo mostra que, usando a rede neural ResNet com precisão de 0,9231, alterando vários pixels da imagem, obtivemos uma porcentagem muito boa de imagens atacadas com sucesso (attack_success_rate).helper.attack_stats(targeted_results, models, network_stats)
Out[26]:
model accuracy pixels attack_success_rate
0 resnet 0.9231 1 0.144444
1 resnet 0.9231 3 0.211111
2 resnet 0.9231 5 0.222222
helper.attack_stats(untargeted_results, models, network_stats)
Out[27]:
model accuracy pixels attack_success_rate
0 resnet 0.9231 1 0.34
1 resnet 0.9231 3 0.79
2 resnet 0.9231 5 0.79
Em seus experimentos, você é livre para usar outras arquiteturas de redes neurais artificiais, pois atualmente existem muitas delas. As redes neurais envolveram o mundo moderno com fios invisíveis. Por um longo tempo, serviços foram inventados onde, usando IA (inteligência artificial), os usuários recebem fotos processadas estilisticamente semelhantes às de grandes artistas, e hoje os algoritmos podem desenhar, criar obras de arte musicais, escrever livros e até roteiros para filmes.Áreas como visão computacional, reconhecimento facial, veículos não tripulados, diagnóstico de doenças - tomam decisões importantes e não têm o direito de cometer erros, e a interferência na operação dos algoritmos levará a conseqüências desastrosas.Um ataque de pixel é uma maneira de falsificar ataques. Para testar a possibilidade de desacreditar a rede, um algoritmo foi desenvolvido e seu efeito na qualidade prevista da solução de reconhecimento de padrões foi medido. O resultado mostrou que as arquiteturas de redes neurais convolucionais usadas são vulneráveis ao algoritmo de ataque de Um pixel especialmente treinado, que substitui um pixel, para desacreditar o algoritmo de reconhecimento.O artigo foi preparado por Alexander Andronic e Adrey Cherny-Tkach como parte de um estágio no Data4 .
As redes neurais envolveram o mundo moderno com fios invisíveis. Por um longo tempo, serviços foram inventados onde, usando IA (inteligência artificial), os usuários recebem fotos processadas estilisticamente semelhantes às de grandes artistas, e hoje os algoritmos podem desenhar, criar obras de arte musicais, escrever livros e até roteiros para filmes.Áreas como visão computacional, reconhecimento facial, veículos não tripulados, diagnóstico de doenças - tomam decisões importantes e não têm o direito de cometer erros, e a interferência na operação dos algoritmos levará a conseqüências desastrosas.Um ataque de pixel é uma maneira de falsificar ataques. Para testar a possibilidade de desacreditar a rede, um algoritmo foi desenvolvido e seu efeito na qualidade prevista da solução de reconhecimento de padrões foi medido. O resultado mostrou que as arquiteturas de redes neurais convolucionais usadas são vulneráveis ao algoritmo de ataque de Um pixel especialmente treinado, que substitui um pixel, para desacreditar o algoritmo de reconhecimento.O artigo foi preparado por Alexander Andronic e Adrey Cherny-Tkach como parte de um estágio no Data4 .