Prelúdio
Este é o segundo dos quatro artigos de uma série que fornecerá informações sobre a mecânica e o design de ponteiros, pilhas, pilhas, análise de escape e semântica de Go / Value. Este post é sobre pilhas e análise de escape.Índice:- Mecânica da linguagem em pilhas e ponteiros ( tradução )
- Mecânica da linguagem na análise de escape
- Mecânica da linguagem no perfil de memória
- Filosofia de Design em Dados e Semântica
Introdução
No primeiro post desta série, falei sobre o básico da mecânica de ponteiros usando um exemplo em que o valor é distribuído na pilha entre goroutines. Não mostrei o que acontece quando você divide o valor na pilha. Para entender isso, você precisa descobrir sobre outra área da memória onde os valores podem estar: sobre a "pilha". Com esse conhecimento, você pode começar a estudar "análise de escape".A análise de escape é um processo que o compilador usa para determinar o posicionamento dos valores criados pelo seu programa. Em particular, o compilador executa análise de código estático para determinar se o valor pode ser colocado no quadro da pilha para a função que o cria ou se o valor deve ser "escapado" para o heap. Não existe uma única palavra-chave ou função no Go que você possa usar para informar ao compilador qual decisão tomar. Somente a maneira como você escreve seu código condicionalmente permite influenciar essa decisão.Montões
Um heap é uma segunda área de memória, além da pilha, usada para armazenar valores. A pilha não é auto-limpante como pilhas, portanto, usar essa memória é mais caro. Antes de tudo, os custos estão associados ao coletor de lixo (GC), que deve manter essa área limpa. Quando o GC iniciar, ele usará 25% da energia disponível do seu processador. Além disso, pode potencialmente criar microssegundos de atrasos do tipo "pare o mundo". A vantagem de ter um GC é que você não precisa se preocupar em gerenciar a memória heap que historicamente é complexa e propensa a erros.Valores no heap provocam alocações de memória no Go. Essas alocações pressionam o GC porque todos os valores no heap aos quais o ponteiro não se refere mais devem ser excluídos. Quanto mais valores você precisar verificar e excluir, mais trabalho o GC deve realizar a cada início. Portanto, o algoritmo de estimulação trabalha constantemente para equilibrar o tamanho da pilha e a velocidade de execução.Compartilhamento de pilha
No Go, nenhuma goroutine pode ter um ponteiro apontando para uma memória na pilha de outra goroutine. Isso se deve ao fato de que a memória da pilha para goroutines pode ser substituída por um novo bloco de memória, quando a pilha deve aumentar ou diminuir. Se, em tempo de execução, você tivesse que rastrear os ponteiros da pilha em outra goroutine, teria que gerenciar demais, e o atraso "pare o mundo" ao atualizar os ponteiros para essas pilhas seria impressionante.Aqui está um exemplo de uma pilha que é substituída várias vezes devido ao crescimento. Observe a saída nas linhas 2 e 6. Você verá duas vezes as alterações de endereço do valor da string dentro do quadro principal da pilha.play.golang.org/p/pxn5u4EBSIMecânica de escape
Sempre que um valor é compartilhado fora da região do quadro de pilha de uma função, ele é colocado (ou alocado) em um heap. A tarefa dos algoritmos de análise de escape é encontrar essas situações e manter o nível de integridade no programa. Integridade é garantir que o acesso a qualquer valor seja sempre preciso, consistente e eficiente.Dê uma olhada neste exemplo para aprender os mecanismos básicos da análise de escape.play.golang.org/p/Y_VZxYteKOListagem 101 package main
02
03 type user struct {
04 name string
05 email string
06 }
07
08 func main() {
09 u1 := createUserV1()
10 u2 := createUserV2()
11
12 println("u1", &u1, "u2", &u2)
13 }
14
15
16 func createUserV1() user {
17 u := user{
18 name: "Bill",
19 email: "bill@ardanlabs.com",
20 }
21
22 println("V1", &u)
23 return u
24 }
25
26
27 func createUserV2() *user {
28 u := user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", &u)
34 return &u
35 }
Eu uso a diretiva go: noinline para que o compilador não incorpore o código para essas funções diretamente no main. A incorporação removerá chamadas de função e complicará este exemplo. Vou falar sobre os efeitos colaterais da incorporação no próximo post.A Listagem 1 mostra um programa com duas funções diferentes que criam um valor do tipo usuário e o devolvem ao chamador. A primeira versão da função usa a semântica do valor ao retornar.Listagem 216 func createUserV1() user {
17 u := user{
18 name: "Bill",
19 email: "bill@ardanlabs.com",
20 }
21
22 println("V1", &u)
23 return u
24 }
Eu disse que a função usa a semântica de valores ao retornar, porque um valor do tipo usuário criado por essa função é copiado e passado para a pilha de chamadas. Isso significa que a função de chamada recebe uma cópia do próprio valor.Você pode ver a criação de um valor do tipo usuário, executado nas linhas 17 a 20. Em seguida, na linha 23, uma cópia do valor é passada para a pilha de chamadas e retornada ao chamador. Depois de retornar a função, a pilha fica da seguinte maneira.Imagem 1 Na Figura 1, você pode ver que existe um valor do tipo user nos dois quadros após chamar createUserV1. Na segunda versão da função, a semântica do ponteiro é usada para retornar.Listagem 3
Na Figura 1, você pode ver que existe um valor do tipo user nos dois quadros após chamar createUserV1. Na segunda versão da função, a semântica do ponteiro é usada para retornar.Listagem 327 func createUserV2() *user {
28 u := user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", &u)
34 return &u
35 }
Eu disse que uma função usa semântica de ponteiro ao retornar, porque um valor do tipo usuário criado por essa função é compartilhado pela pilha de chamadas. Isso significa que a função de chamada recebe uma cópia do endereço onde os valores estão localizados.Você pode ver o mesmo literal estrutural usado nas linhas 28 a 31 para criar um valor do tipo user, mas na linha 34 o retorno da função é diferente. Em vez de passar uma cópia do valor de volta para a pilha de chamadas, uma cópia do endereço para o valor é passada. Com base nisso, você pode pensar que após a chamada a pilha fica assim.Imagem 2 Se o que você vê na Figura 2 realmente estiver acontecendo, você terá um problema de integridade. Um ponteiro aponta para uma pilha de chamadas para a memória que não são mais válidas. Na próxima vez que a função for chamada, a memória indicada será reformatada e reinicializada.É aqui que a análise de escape começa a manter a integridade. Nesse caso, o compilador determinará que não é seguro criar um valor do tipo user dentro do quadro de pilha createUserV2, portanto, em vez disso, criará um valor no heap. Isso acontecerá imediatamente durante a construção na linha 28.
Se o que você vê na Figura 2 realmente estiver acontecendo, você terá um problema de integridade. Um ponteiro aponta para uma pilha de chamadas para a memória que não são mais válidas. Na próxima vez que a função for chamada, a memória indicada será reformatada e reinicializada.É aqui que a análise de escape começa a manter a integridade. Nesse caso, o compilador determinará que não é seguro criar um valor do tipo user dentro do quadro de pilha createUserV2, portanto, em vez disso, criará um valor no heap. Isso acontecerá imediatamente durante a construção na linha 28.Legibilidade
Como você aprendeu em uma postagem anterior, uma função tem acesso direto à memória dentro de seu quadro através do ponteiro do quadro, mas o acesso à memória fora do quadro requer acesso indireto. Isso significa que o acesso aos valores que caem no heap também deve ser feito indiretamente por meio de um ponteiro.Lembre-se da aparência do código createUserV2.Listagem 427 func createUserV2() *user {
28 u := user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", &u)
34 return &u
35 }
A sintaxe oculta o que realmente acontece neste código. A variável u declarada na linha 28 representa um valor do tipo usuário. A construção em Go não informa exatamente onde o valor está armazenado na memória; portanto, antes da declaração de retorno na linha 34, você não sabe que o valor será empilhado. Isso significa que, embora u represente um valor do tipo usuário, o acesso a esse valor deve ser por meio de um ponteiro.Você pode visualizar uma pilha que se parece com isso após uma chamada de função.Imagem 3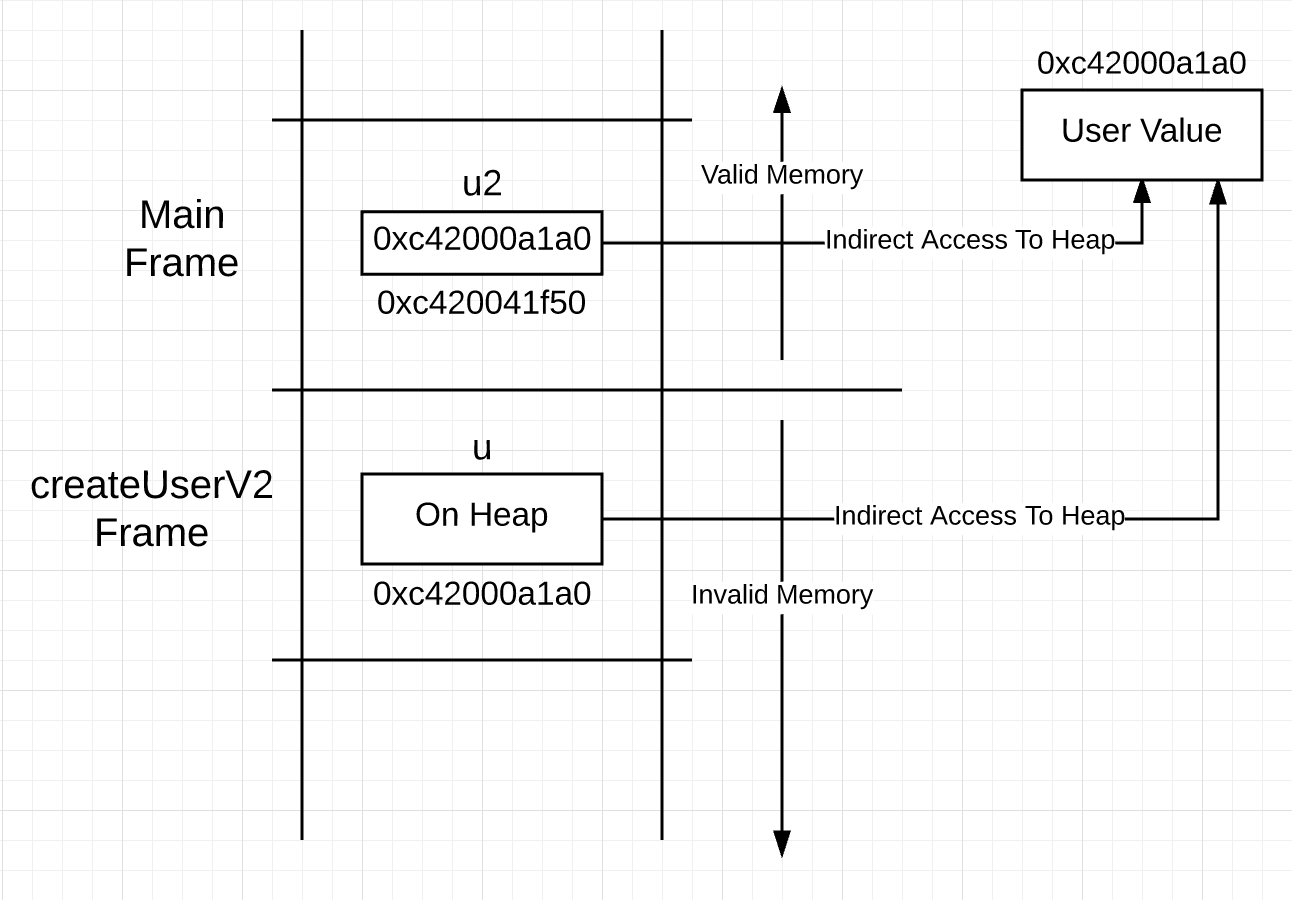 A variável u no quadro da pilha para createUserV2 representa o valor na pilha, não na pilha. Isso significa que usar u para acessar um valor requer acesso a um ponteiro, não o acesso direto sugerido pela sintaxe. Você pode pensar, por que não fazer um ponteiro imediatamente, já que acessar o valor que ele representa ainda requer o uso de um ponteiro?Listagem 5
A variável u no quadro da pilha para createUserV2 representa o valor na pilha, não na pilha. Isso significa que usar u para acessar um valor requer acesso a um ponteiro, não o acesso direto sugerido pela sintaxe. Você pode pensar, por que não fazer um ponteiro imediatamente, já que acessar o valor que ele representa ainda requer o uso de um ponteiro?Listagem 527 func createUserV2() *user {
28 u := &user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", u)
34 return u
35 }
Se você fizer isso, perderá a legibilidade, que não poderia ser perdida em seu código. Afaste-se do corpo da função por um segundo e concentre-se apenas no retorno.Listagem 634 return u
35 }
Sobre o que esse retorno está falando? Tudo o que ele diz é que uma cópia de você é colocada na pilha de chamadas. Enquanto isso, o que return indica quando você usa o operador &?Listagem 734 return &u
35 }
Graças ao operador & return, ele agora informa que você está compartilhando a pilha de chamadas e, portanto, sai para a pilha. Lembre-se de que os ponteiros devem ser usados juntos e, ao ler o código, eles substituem o operador & pela frase "compartilhamento". É muito poderoso em termos de legibilidade. Isso é algo que eu não gostaria de perder.Aqui está outro exemplo em que a construção de valores usando a semântica de ponteiros diminui a legibilidade.Listagem 801 var u *user
02 err := json.Unmarshal([]byte(r), &u)
03 return u, err
Para que esse código funcione, quando você chama json.Unmarshal na linha 02, deve passar um ponteiro para uma variável de ponteiro. Uma chamada json.Unmarshal criará um valor do tipo usuário e atribuirá seu endereço a uma variável de ponteiro. play.golang.org/p/koI8EjpeIxO que este código diz:01: Crie um ponteiro do tipo usuário com um valor nulo.02: Compartilhe u variável com a função json.Unmarshal.03: Retorne uma cópia da variável u para o chamador.Não é totalmente óbvio que um valor do tipo usuário criado pela função json.Unmarshal seja passado para o chamador.Como a legibilidade muda ao usar a semântica de valores durante a declaração de variável?Listagem 901 var u user
02 err := json.Unmarshal([]byte(r), &u)
03 return &u, err
O que este código diz:01: Crie um valor do tipo user com um valor nulo.02: Compartilhe u variável com a função json.Unmarshal.03: Compartilhe a variável u com o chamador.Tudo está muito claro. A linha 02 divide o valor do usuário do tipo na pilha de chamadas em json.Unmarshal e a linha 03 divide o valor da pilha de chamadas de volta para o chamador. Esse compartilhamento fará com que o valor seja movido para o heap.Use a semântica dos valores ao criar valores e aproveite a legibilidade do operador & para esclarecer como os valores são separados.Relatórios do compilador
Para ver as decisões tomadas pelo compilador, você pode solicitar ao compilador que forneça um relatório. Tudo o que você precisa fazer é usar a opção -gcflags com a opção -m ao chamar go build.De fato, você pode usar 4 níveis de -m, mas após 2 níveis de informação, isso se torna demais. Vou usar 2 níveis -m.Listagem 10$ go build -gcflags "-m -m"
./main.go:16: cannot inline createUserV1: marked go:noinline
./main.go:27: cannot inline createUserV2: marked go:noinline
./main.go:8: cannot inline main: non-leaf function
./main.go:22: createUserV1 &u does not escape
./main.go:34: &u escapes to heap
./main.go:34: from ~r0 (return) at ./main.go:34
./main.go:31: moved to heap: u
./main.go:33: createUserV2 &u does not escape
./main.go:12: main &u1 does not escape
./main.go:12: main &u2 does not escape
Você pode ver que o compilador está relatando decisões para despejar o valor no heap. O que o compilador diz? Primeiro, observe novamente as funções createUserV1 e createUserV2 para atualizá-las na memória.Listagem 1316 func createUserV1() user {
17 u := user{
18 name: "Bill",
19 email: "bill@ardanlabs.com",
20 }
21
22 println("V1", &u)
23 return u
24 }
27 func createUserV2() *user {
28 u := user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", &u)
34 return &u
35 }
Vamos começar com esta linha no relatório.Listagem 14./main.go:22: createUserV1 &u does not escape
Isso sugere que a chamada para a função println dentro da função createUserV1 não faz com que o tipo de usuário seja despejado no heap. Este caso teve que ser verificado porque é usado em conjunto com a função println.Em seguida, observe estas linhas no relatório.Listagem 15./main.go:34: &u escapes to heap
./main.go:34: from ~r0 (return) at ./main.go:34
./main.go:31: moved to heap: u
./main.go:33: createUserV2 &u does not escape
Essas linhas dizem que o valor do tipo de usuário associado à variável u, que tem o tipo de usuário nomeado e é criado na linha 31, é despejado no heap devido ao retorno na linha 34. A última linha diz o mesmo de antes, println call na linha 33 não redefine o tipo de usuário.A leitura desses relatórios pode ser confusa e pode variar um pouco, dependendo se o tipo da variável em questão é baseado em um tipo nomeado ou literal.Modifique a variável u para ser o usuário do tipo literal * em vez do usuário do tipo nomeado, como era antes.Listagem 1627 func createUserV2() *user {
28 u := &user{
29 name: "Bill",
30 email: "bill@ardanlabs.com",
31 }
32
33 println("V2", u)
34 return u
35 }
Execute o relatório novamente.Listagem 17./main.go:30: &user literal escapes to heap
./main.go:30: from u (assigned) at ./main.go:28
./main.go:30: from ~r0 (return) at ./main.go:34
Agora, o relatório diz que o valor do tipo de usuário referenciado pela variável u, que possui o tipo literal * user e criado na linha 28, é despejado no heap devido ao retorno na linha 34.Conclusão
Criar um valor não determina onde ele está localizado. Somente como o valor é dividido determinará o que o compilador fará com esse valor. Cada vez que você compartilha um valor na pilha de chamadas, ele é despejado no heap. Há outras razões pelas quais um valor pode escapar da pilha. Vou falar sobre eles no próximo post.O objetivo dessas postagens é fornecer orientações sobre como escolher usar semântica de valor ou semântica de ponteiro para qualquer tipo. Cada semântica é combinada com lucro e valor. A semântica dos valores armazena os valores na pilha, o que reduz a carga no GC. No entanto, existem cópias diferentes do mesmo valor que devem ser armazenadas, rastreadas e mantidas. A semântica do ponteiro coloca valores em uma pilha, o que pode pressionar o GC. No entanto, eles são eficazes porque existe apenas um valor que precisa ser armazenado, rastreado e mantido. O ponto principal é o uso de cada semântica de maneira correta, consistente e equilibrada.