Olá a todos. Antes do início do curso Python Neural Networks, preparamos para você uma tradução de outro material interessante.
Temos o prazer de apresentar o PyCaret , uma biblioteca de aprendizado de máquina Python de código aberto para aprender e implantar modelos com e sem um professor em um ambiente de código baixo. O PyCaret permite que você passe da preparação dos dados para a implantação do modelo em alguns segundos no ambiente de notebook que você escolher.Comparado a outras bibliotecas abertas de aprendizado de máquina, o PyCaret é uma alternativa de código baixo que pode substituir centenas de linhas de código por apenas algumas palavras. A velocidade de experimentos mais eficientes aumentará exponencialmente. O PyCaret é essencialmente um shell Python em várias bibliotecas de aprendizado de máquina, como scikit-learn , XGBoost , Microsoft LightGBM , spaCye muitos outros.PyCaret é simples e fácil de usar. Todas as operações executadas pelo PyCaret são armazenadas seqüencialmente em um pipeline totalmente pronto para implantação. Seja adicionando valores ausentes, convertendo dados categóricos, recursos de engenharia ou otimizando hiperparâmetros, o PyCaret pode automatizar tudo isso. Para aprender um pouco mais sobre o PyCaret, confira este pequeno vídeo .Introdução ao PyCaret
A primeira versão estável do PyCaret versão 1.0.0 pode ser instalada usando o pip. Use a interface da linha de comandos ou o ambiente do notebook e execute o comando abaixo para instalar o PyCaret.pip install pycaret
Se você estiver usando os Cadernos de anotações do Azure ou o Google Colab , execute o seguinte comando:!pip install pycaret
Quando você instala o PyCaret, todas as dependências serão instaladas automaticamente. Você pode ver a lista de dependências aqui .Não poderia ser mais fácil
Passo a passo
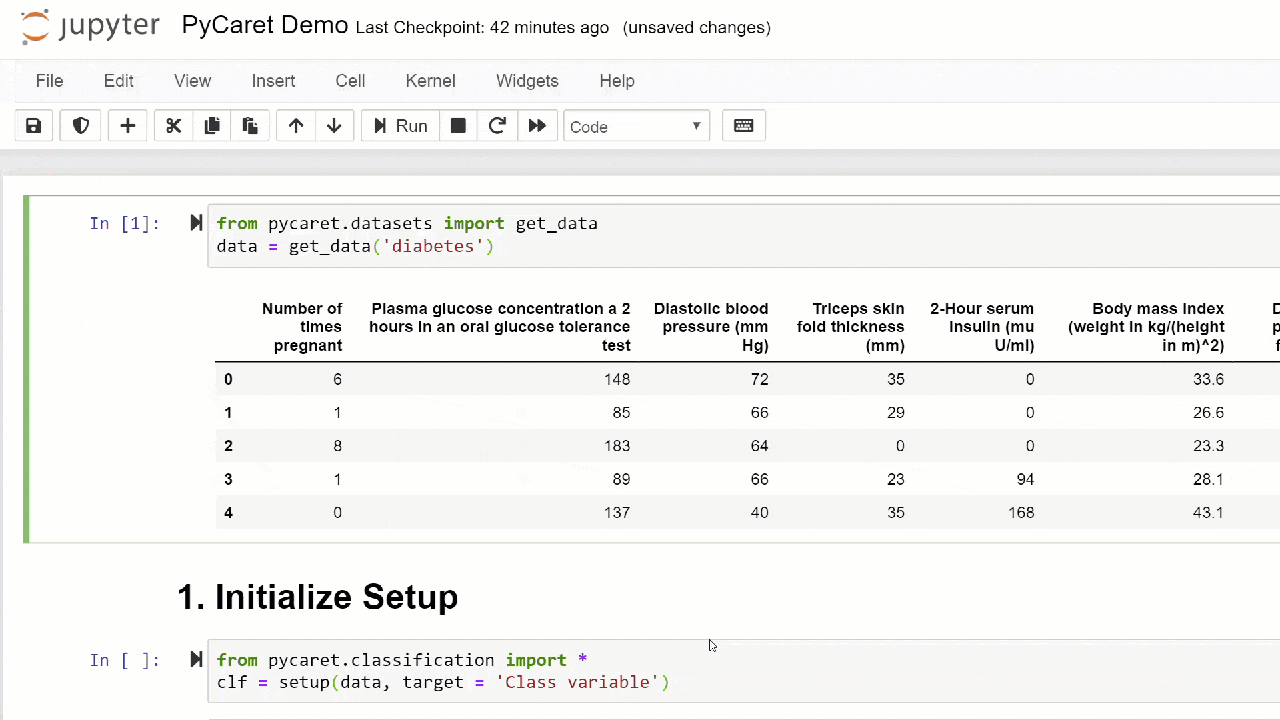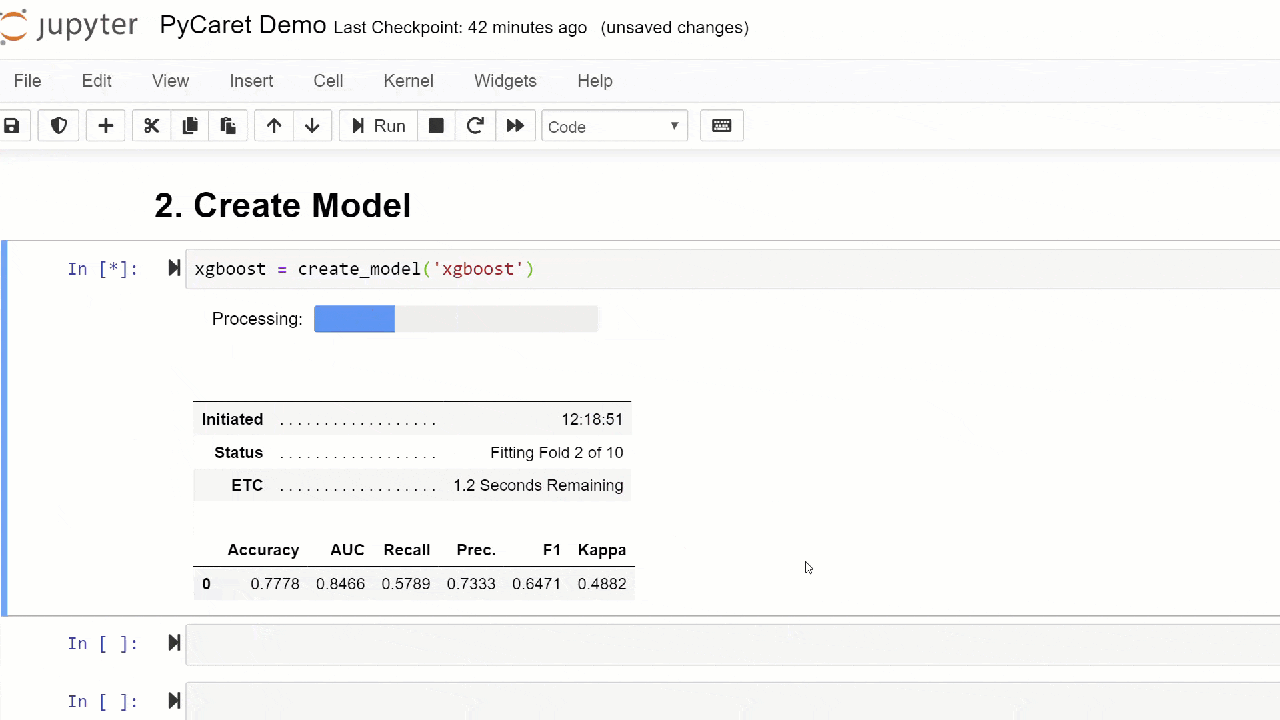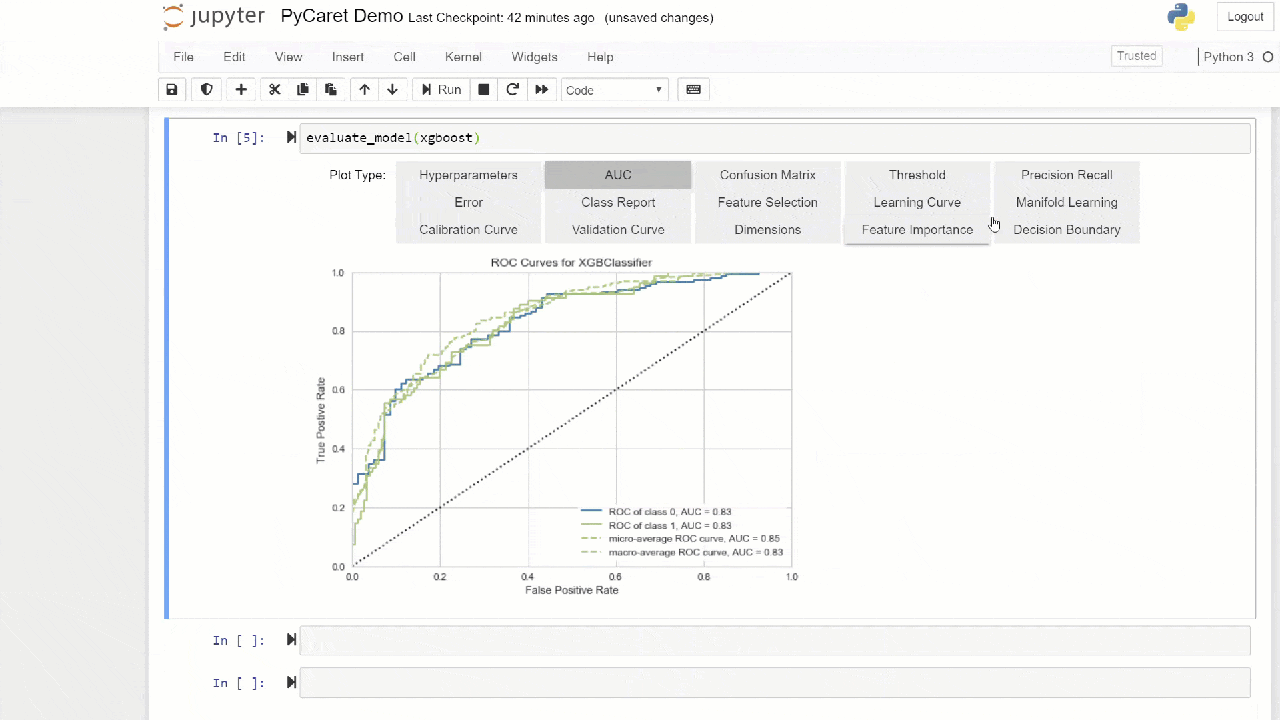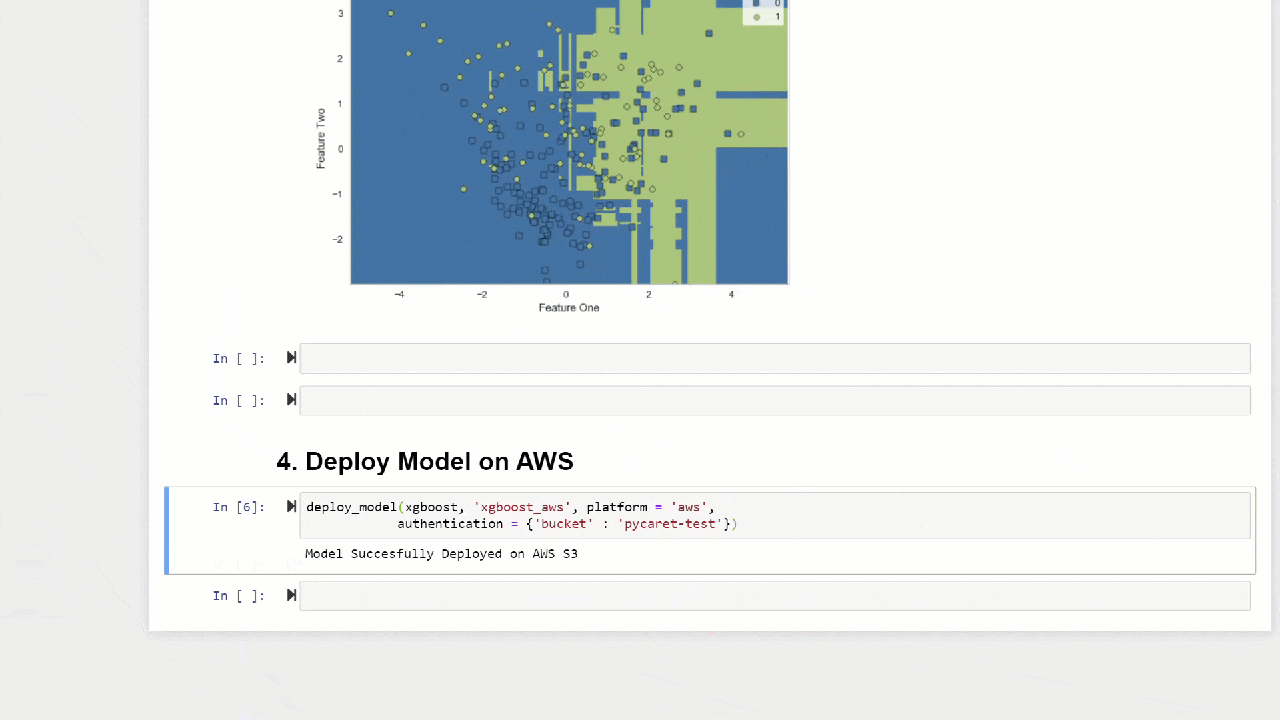
1. Aquisição de dadosNeste passo a passo, usaremos um conjunto de dados para diabéticos, nosso objetivo é prever o resultado do paciente (em 0 ou 1 binário) com base em vários fatores, como pressão, nível de insulina no sangue, idade etc. . Este conjunto de dados está disponível no repositório PyCaret GitHub . A maneira mais fácil de importar o conjunto de dados diretamente do repositório é usar a função get_datados módulos pycaret.datasets.from pycaret.datasets import get_data
diabetes = get_data('diabetes')
 O PyCaret pode trabalhar diretamente com os quadros de dados do pandas2. Configurando o ambienteQualquer experimento com aprendizado de máquina no PyCaret começa com a configuração do ambiente, importando o módulo necessário e inicializando
O PyCaret pode trabalhar diretamente com os quadros de dados do pandas2. Configurando o ambienteQualquer experimento com aprendizado de máquina no PyCaret começa com a configuração do ambiente, importando o módulo necessário e inicializando setup(). O módulo que será usado neste exemplo é pycaret.classification .Após importar o módulo, ele é setup()inicializado definindo um quadro de dados ( 'diabetes' ) e uma variável de destino ( 'variável de classe' ).from pycaret.classification import *
exp1 = setup(diabetes, target = 'Class variable')
 Todo o pré-processamento ocorre em
Todo o pré-processamento ocorre em setup(). Usando mais de 20 funções para preparar dados antes do aprendizado de máquina, o PyCaret cria um pipeline de transformações com base nos parâmetros definidos na função setup(). Ele cria automaticamente todas as dependências no pipeline, para que você não precise controlar manualmente a execução seqüencial de transformações em um teste ou em um novo conjunto de dados (invisível).O pipeline do PyCaret pode ser facilmente transferido de um ambiente para outro ou implantado na produção. Abaixo, você pode se familiarizar com os recursos de pré-processamento que estão disponíveis no PyCaret desde o primeiro lançamento.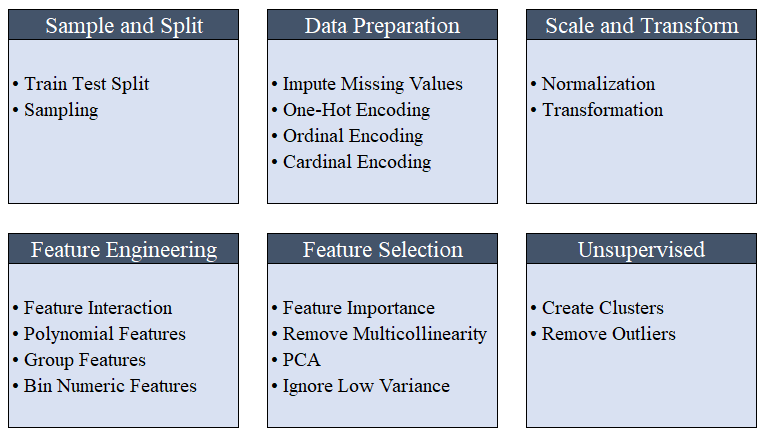 As etapas de pré-processamento de dados são obrigatórias para o aprendizado de máquina, como adicionar valores ausentes, variáveis de qualidade de codificação, etiquetas de codificação (sim ou não a 1 ou 0) e divisão de teste de trem, são executadas automaticamente durante a inicialização
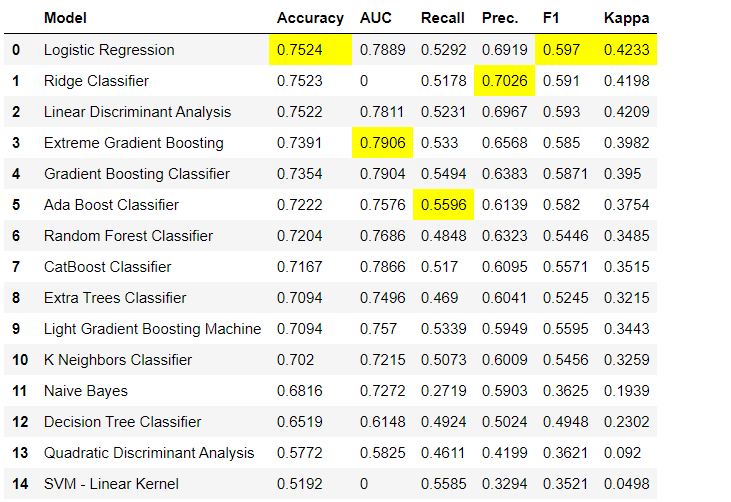
As etapas de pré-processamento de dados são obrigatórias para o aprendizado de máquina, como adicionar valores ausentes, variáveis de qualidade de codificação, etiquetas de codificação (sim ou não a 1 ou 0) e divisão de teste de trem, são executadas automaticamente durante a inicialização setup(). Você pode aprender mais sobre os recursos de pré-processamento no PyCaret aqui .3. Comparação de modelosEste é o primeiro passo recomendado quando se trabalha com a formação de professores ( classificação ou regressão ). Essa função treina todos os modelos na biblioteca de modelos e compara o indicador estimado usando validação cruzada para blocos K (10 blocos por padrão). Os indicadores estimados são usados da seguinte forma:- Para classificação: Precisão, AUC, Rechamada, Precisão, F1, Kappa
- Para regressão: MAE, MSE, RMSE, R2, RMSLE, MAPE
 Por padrão, as métricas são avaliadas usando a validação cruzada em 10 blocos. O número de blocos pode ser alterado alterando o valor do parâmetro
Por padrão, as métricas são avaliadas usando a validação cruzada em 10 blocos. O número de blocos pode ser alterado alterando o valor do parâmetro fold.A tabela padrão é classificada por "Precisão" do valor mais alto para o mais baixo. Ordem de classificação também pode ser alterado usando a opção sort.4. Criando um modelo Acriação de um modelo em qualquer módulo PyCaret é tão simples que você só precisa escrevê-lo create_model. A função recebe um parâmetro na entrada, ou seja, nome do modelo passado como uma sequência. Essa função retorna uma tabela com pontuações com validação cruzada e um objeto de modelo treinado.adaboost = create_model('ada')
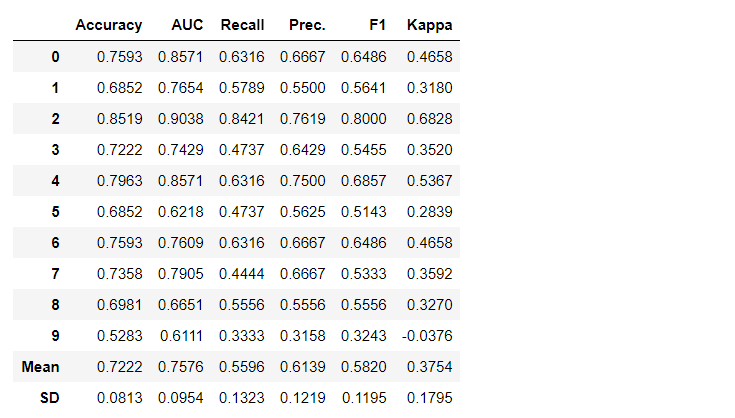 A variável "adaboost" armazena o objeto do modelo treinado, que retorna uma função
A variável "adaboost" armazena o objeto do modelo treinado, que retorna uma função create_modelque, sob o capô, é um avaliador do scikit-learn. O acesso aos atributos de origem do objeto treinado pode ser obtido usando a função period ( . )após a variável Você pode encontrar um exemplo de uso abaixo. O PyCaret possui mais de 60 algoritmos prontos para uso de código aberto. Uma lista completa de avaliadores / modelos disponíveis no PyCaret pode ser encontrada aqui .5. Configuração do modeloA função é
O PyCaret possui mais de 60 algoritmos prontos para uso de código aberto. Uma lista completa de avaliadores / modelos disponíveis no PyCaret pode ser encontrada aqui .5. Configuração do modeloA função é tune_modelusada para configurar automaticamente os hiperparâmetros do modelo de aprendizado de máquina. PyCaret usarandom grid searchem um espaço de pesquisa específico. A função retorna uma tabela com estimativas validadas cruzadas e um objeto de um modelo treinado.tuned_adaboost = tune_model('ada')
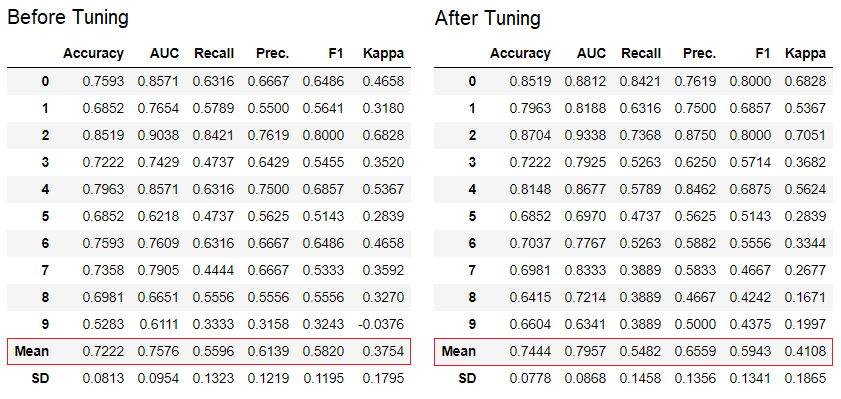 A função
A função tune_modelem módulos de aprendizagem para não professores, como pycaret.nlp , pycaret.clustering e pycaret.anomaly, pode ser usada em conjunto com os módulos de aprendizagem de professores. Por exemplo, o módulo PNL no PyCaret pode ser usado para ajustar um parâmetro number of topics, avaliando uma função objetivo ou uma função de perda de um modelo com um professor, como "Precisão" ou "R2".6. Conjunto de modelosA função é ensemble_modelusada para criar um conjunto de modelos treinados. Na entrada, é necessário um parâmetro - o objeto do modelo treinado. A função retorna uma tabela com estimativas validadas cruzadas e um objeto de um modelo treinado.
dt = create_model('dt')
dt_bagged = ensemble_model(dt)
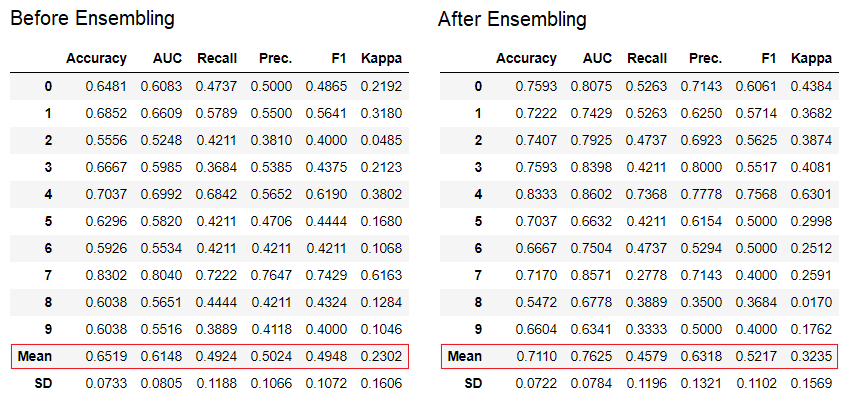 O método "ensacamento" é usado ao criar o conjunto por padrão, ele pode ser alterado para "impulsionar" usando o parâmetro
O método "ensacamento" é usado ao criar o conjunto por padrão, ele pode ser alterado para "impulsionar" usando o parâmetro methodna função ensemble_model.O PyCaret também fornece funções blend_modelse modelos de pilha para combinar vários modelos treinados.7. Modelo visualização.Você pode avaliar o desempenho e diagnosticar um modelo de aprendizagem de máquina treinado usando a função plot_model. Ele pega o objeto do modelo treinado e o tipo de gráfico na forma de uma string.
adaboost = create_model('ada')
plot_model(adaboost, plot = 'auc')
plot_model(adaboost, plot = 'boundary')
plot_model(adaboost, plot = 'pr')
plot_model(adaboost, plot = 'vc')
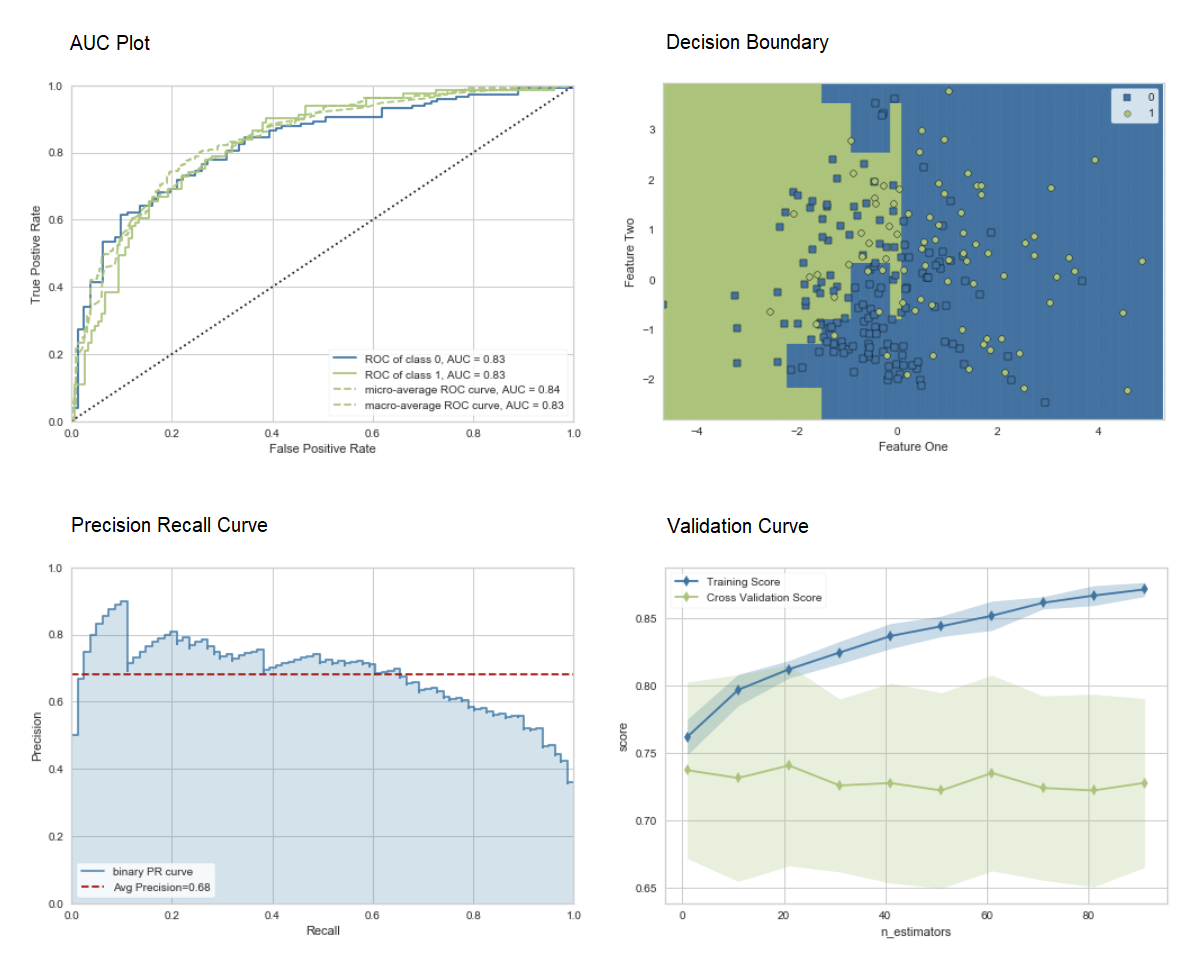 Aqui você pode aprender mais sobre visualização no PyCaret.Você também pode usar a função
Aqui você pode aprender mais sobre visualização no PyCaret.Você também pode usar a função evaluate_modelpara ver gráficos usando a interface do usuário do notebook. A função
A função plot_modelno módulo pycaret.nlppode ser usada para visualizar o corpo dos textos e modelos temáticos semânticos. Aqui você pode aprender mais sobre eles.8. Interpretação do modeloQuando os dados são não lineares, o que acontece com frequência na vida real, sempre vemos que os modelos em forma de árvore funcionam muito melhor do que os modelos gaussianos simples. No entanto, isso ocorre devido a uma perda de interpretabilidade, pois os modelos em árvore não fornecem coeficientes simples, como os modelos lineares. PyCaret implementa SHAP (Explicações do aditivo SHapley ) usando uma função interpret_model.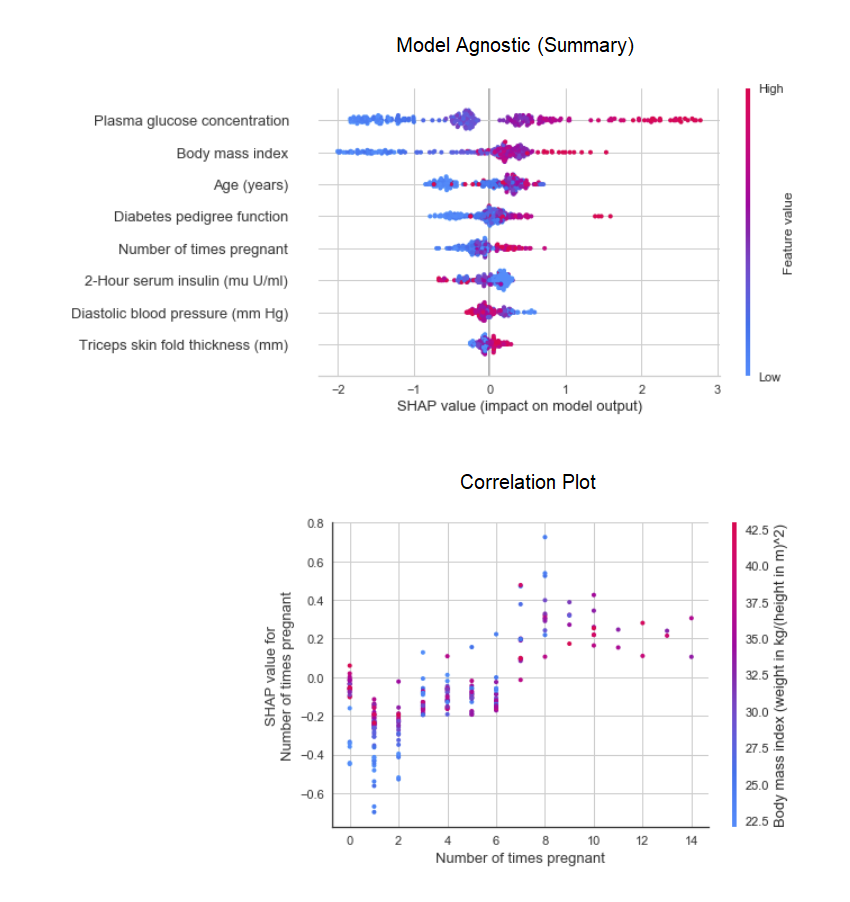 A interpretação de um ponto de dados específico em um conjunto de dados de teste pode ser estimada usando o gráfico "motivo". No exemplo abaixo, testamos a primeira instância no conjunto de dados de teste.
A interpretação de um ponto de dados específico em um conjunto de dados de teste pode ser estimada usando o gráfico "motivo". No exemplo abaixo, testamos a primeira instância no conjunto de dados de teste. 9. Modelo preditivoAté o momento, os resultados obtidos foram baseados na validação cruzada em blocos K em um conjunto de dados de treinamento (70% por padrão). Para ver as previsões e o desempenho do modelo no conjunto de dados de teste / espera, uma função é usada
9. Modelo preditivoAté o momento, os resultados obtidos foram baseados na validação cruzada em blocos K em um conjunto de dados de treinamento (70% por padrão). Para ver as previsões e o desempenho do modelo no conjunto de dados de teste / espera, uma função é usada predict_model.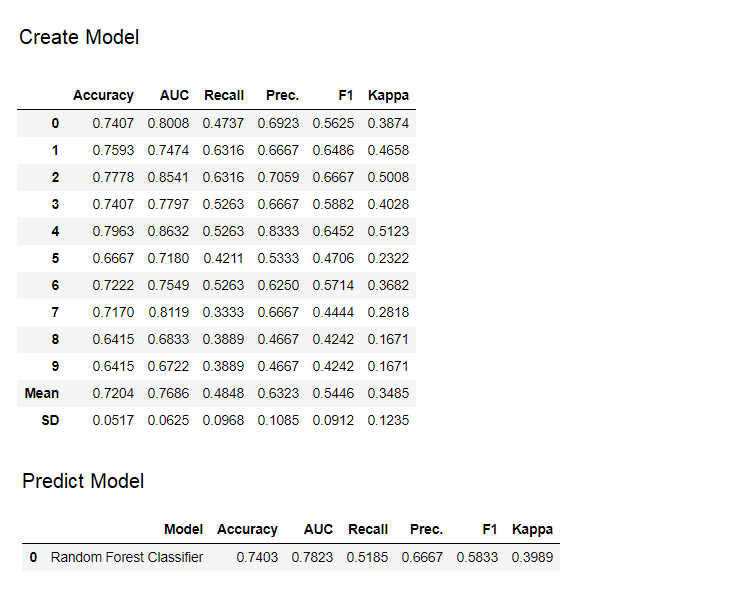 A função é
A função é predict_modelusada para prever um conjunto de dados invisível. Agora, usaremos o mesmo conjunto de dados que usamos para o treinamento, como um proxy para o novo conjunto de dados invisível. Na prática, a funçãopredict_modelserá usado iterativamente, sempre em um novo conjunto de dados invisível. A função
A função predict_modeltambém pode fazer previsões para uma cadeia seqüencial de modelos que pode ser criada usando as funções stack_models e create_stacknet .A função predict_modeltambém pode fazer previsões diretamente para modelos hospedados no AWS S3 usando a função deploy_model .10. Implantando um modeloUma das maneiras de usar modelos treinados para criar previsões para um novo conjunto de dados é usar a funçãopredict_modelno mesmo notebook / IDE em que o modelo foi treinado. No entanto, gerar uma previsão para um novo conjunto de dados (invisível) é um processo iterativo. Dependendo do caso de uso, a frequência das previsões pode variar de previsões em tempo real a previsões de lotes. A função deploy_modelno PyCaret permite implantar todo o pipeline, incluindo o modelo treinado na nuvem a partir do ambiente do notebook.deploy_model(model = rf, model_name = 'rf_aws', platform = 'aws',
authentication = {'bucket' : 'pycaret-test'})
11. Salve o modelo / salve o experimento
Após o treinamento, todo o pipeline contendo todas as transformações de pré-processamento e o objeto do modelo treinado pode ser salvo em um arquivo de pickle binário.
adaboost = create_model('ada')
save_model(adaboost, model_name = 'ada_for_deployment')
 Você também pode salvar a experiência inteira, contendo toda a saída intermediária, como um único arquivo binário.save_experiment (experiment_name = 'my_first_experiment')
Você também pode salvar a experiência inteira, contendo toda a saída intermediária, como um único arquivo binário.save_experiment (experiment_name = 'my_first_experiment') Você pode carregar modelos e experiências salvos usando as funções
Você pode carregar modelos e experiências salvos usando as funções load_modele load_experimentdisponíveis em todos os módulos PyCaret.12. Próximo guiaNo próximo guia, mostraremos como usar o modelo treinado de aprendizado de máquina no Power BI para gerar previsões de lote em um ambiente de produção real.Você também pode ler blocos de notas para iniciantes nos seguintes módulos:O que é um pipeline de desenvolvimento?
Estamos trabalhando ativamente para melhorar o PyCaret. Nosso próximo pipeline de desenvolvimento inclui um novo módulo de previsão de séries temporais, integração com o TensorFlow e grandes melhorias na escalabilidade do PyCaret. Se você deseja compartilhar seus comentários e nos ajudar a melhorar, preencha um formulário no site ou deixe um comentário em nossa página no GitHub ou LinkedIn .Deseja saber mais sobre um módulo específico?
A partir do primeiro lançamento, o PyCaret 1.0.0 possui os seguintes módulos disponíveis para uso. Siga os links abaixo para se familiarizar com a documentação e exemplos de trabalho.ClassificaçãoRegressãoClusteringAnomaly Search Treinamento de regras associativas deprocessamento de texto natural (PNL)Links importantes
Se você gostou do PyCaret, coloque-nos ️ no GitHub.Para saber mais sobre o PyCaret, siga-nos no LinkedIn e no Youtube .
Saiba mais sobre o curso.