Artigos de tradução especialmente preparados para os alunos do curso "Banco de Dados" .
O que você pode não saber sobre a geração de números aleatórios sysbench OSysbench é uma ferramenta popular de teste de desempenho. Foi originalmente escrito por Peter Zaitsev no início dos anos 2000 e se tornou o padrão de fato para testes e benchmarking. Atualmente, ele é suportado por Alexei Kopytov e está publicado no Github em .No entanto, notei que, apesar de sua ampla distribuição, há momentos desconhecidos para muitos no sysbench. Por exemplo, a capacidade de modificar facilmente os testes do MySQL usando Lua ou de configurar os parâmetros do gerador de números aleatórios embutido.Sobre o que é este artigo?
Eu escrevi este artigo para mostrar como é fácil personalizar o sysbench de acordo com seus requisitos. Há muitas maneiras de estender a funcionalidade do sysbench e uma delas é configurar a geração de identificadores aleatórios (IDs).Por padrão, o sysbench vem com cinco opções diferentes para gerar números aleatórios. Mas muitas vezes (na verdade, quase nunca), nenhum deles é explicitamente indicado e, com menos frequência, você pode ver os parâmetros de geração (para opções onde eles estão disponíveis).Se você tiver uma pergunta: “E por que eu deveria estar interessado nisso? Afinal, os valores padrão são bastante adequados ”, então esta postagem foi criada para ajudar você a entender por que esse nem sempre é o caso.vamos começar
Quais são as maneiras de gerar números aleatórios no sysbench? No momento, estão implementados (você pode vê-los facilmente através da opção --help):- Especial (distribuição especial)
- Gaussiano (distribuição gaussiana)
- Pareto (distribuição Pareto)
- Zipfian (distribuição Zipf)
- Uniforme (distribuição uniforme)
Por padrão, Especial é usado com os seguintes parâmetros:rand-spec-iter = 12 - número de iterações para uma distribuição especialrand-spec-pct = 1 - porcentagem de todo o intervalo no qual os valores "especiais" se enquadram em uma distribuição especialrand-spec-res = 75 - porcentagem de valores "especiais" para uso em uma distribuição especial
Como eu gosto de testes e scripts simples e fáceis de reproduzir, todos os dados subsequentes serão coletados usando os seguintes comandos sysbench:- sysbench ./src/lua/oltp_read.lua -mysql_storage_engine = innodb –db-driver = mysql –tables = 10 –table_size = 100 prepare
- sysbench ./src/lua/oltp_read_write.lua –db-driver=mysql –tables=10 –table_size=100 –skip_trx=off –report-interval=1 –mysql-ignore-errors=all –mysql_storage_engine=innodb –auto_inc=on –histogram –stats_format=csv –db-ps-mode=disable –threads=10 –time=60 –rand-type=XXX run
Sinta-se livre para experimentar a si mesmo. A descrição e os dados do script podem ser encontrados aqui .Por que o sysbench usa um gerador de números aleatórios? Um dos propósitos é gerar IDs que serão usados nas consultas. Portanto, em nosso exemplo, serão gerados números entre 1 e 100, levando em consideração a criação de 10 tabelas com 100 linhas em cada uma.E se você executar o sysbench como descrito acima e alterar apenas o tipo -rand?Eu executei esse script e usei o log geral para coletar e analisar a frequência dos valores de ID gerados. Aqui está o resultado: UniformeEspecial Zipfian Pareto Gaussian
Pode ser visto que esse parâmetro é importante, certo? Afinal, o sysbench faz exatamente o que esperávamos dele.



 Vamos dar uma olhada em cada uma das distribuições.
Vamos dar uma olhada em cada uma das distribuições.Especial
Special é usado por padrão, portanto, se você NÃO especificar o tipo de rand, o sysbench usará special. Special usa um número muito limitado de valores de ID. Em nosso exemplo, podemos ver que os valores 50-51 são usados principalmente, os valores restantes entre 44-56 são extremamente raros, enquanto outros praticamente não são usados. Observe que os valores selecionados estão no meio do intervalo disponível de 1 a 100.Nesse caso, o pico é de aproximadamente dois IDs, representando 2% da amostra. Se eu aumentar o número de registros para um milhão, o pico permanecerá, mas será de 7493, ou seja, 0,74% da amostra. Como isso será mais restritivo, é provável que o número de páginas seja mais de uma.Uniforme (distribuição uniforme)
Como o nome diz, se usarmos Uniform, todos os valores serão usados para o ID e a distribuição será ... uniforme.Zipfian (distribuição Zipf)
A distribuição Zipf, às vezes chamada de distribuição zeta, é uma distribuição discreta comumente usada em linguística, seguros e modelagem de eventos raros. Nesse caso, o sysbench usará números começando com o menor (1) e reduzirá muito rapidamente a frequência de uso, passando para números maiores.Pareto (Pareto)
Pareto aplica a regra “80-20” . Nesse caso, os IDs gerados serão manchados ainda menos e serão mais concentrados em um pequeno segmento. No nosso exemplo, 52% de todos os IDs tinham um valor de 1 e 73% dos valores estavam nos 10 primeiros números.Gaussiano (distribuição gaussiana)
A distribuição gaussiana (distribuição normal) é bem conhecida e familiar . É usado principalmente em estatísticas e previsões em torno de um fator central. Nesse caso, os IDs usados são distribuídos ao longo da curva em forma de sino, começando com o valor médio e diminuindo lentamente para as bordas.Qual o sentido disso?
Cada uma das opções acima tem seu próprio uso e pode ser agrupada por finalidade. Pareto e foco especial em pontos quentes. Nesse caso, o aplicativo usa a mesma página / dados repetidamente. Pode ser o que precisamos, mas devemos entender o que estamos fazendo e não cometer erros aqui.Por exemplo, se testarmos o desempenho da compactação de página do InnoDB durante a leitura, devemos evitar o uso do valor padrão Special ou Pareto. Se tivermos um conjunto de dados de 1 TB e um buffer pool de 30 GB e solicitarmos a mesma página várias vezes, essa página já será lida do disco e estará disponível descompactada na memória.Em suma, esse teste é uma perda de tempo e esforço.O mesmo se precisarmos verificar o desempenho da gravação. Escrever a mesma página repetidamente não é a melhor opção.E quanto ao teste de desempenho?Novamente, queremos testar o desempenho, mas para que caso? É importante entender que o método de geração de números aleatórios afeta muito os resultados do teste. E seus “padrões suficientes” podem levar a conclusões errôneas.Os gráficos a seguir mostram latências diferentes, dependendo do tipo de rand (tipo de teste, hora, parâmetros adicionais e o número de threads são iguais em todos os lugares).De um tipo para outro, os atrasos são significativamente diferentes: aqui eu estava lendo e escrevendo, e os dados foram retirados do Esquema de Desempenho (
aqui eu estava lendo e escrevendo, e os dados foram retirados do Esquema de Desempenho (sys.schema_table_statistics) Como esperado, Pareto e Special demoram muito mais que os outros, fazendo com que o sistema (MySQL-InnoDB) sofra artificialmente com a concorrência em um "hot spot".A alteração do tipo de margem afeta não apenas o atraso, mas também o número de linhas processadas, conforme indicado pelo esquema de desempenho.
 Dado todo o exposto, é importante entender o que estamos tentando avaliar e testar.Se meu objetivo é testar o desempenho do sistema em todos os níveis, talvez prefira usar o Uniform, que carregará igualmente o conjunto de dados / servidor / sistema de banco de dados e terá maior probabilidade de distribuir a leitura / carga / gravação uniformemente.Se meu trabalho é trabalhar com pontos quentes, Pareto e Special provavelmente são a escolha certa.Mas não use os valores padrão às cegas. Eles podem ser adequados para você, mas geralmente são destinados a casos extremos. Na minha experiência, muitas vezes você pode ajustar as configurações para obter o resultado necessário.Por exemplo, você deseja usar os valores no meio ampliando o intervalo para que não haja pico agudo (Especial por padrão) ou campainha (Gaussiana).Você pode configurar o Special para obter algo assim:
Dado todo o exposto, é importante entender o que estamos tentando avaliar e testar.Se meu objetivo é testar o desempenho do sistema em todos os níveis, talvez prefira usar o Uniform, que carregará igualmente o conjunto de dados / servidor / sistema de banco de dados e terá maior probabilidade de distribuir a leitura / carga / gravação uniformemente.Se meu trabalho é trabalhar com pontos quentes, Pareto e Special provavelmente são a escolha certa.Mas não use os valores padrão às cegas. Eles podem ser adequados para você, mas geralmente são destinados a casos extremos. Na minha experiência, muitas vezes você pode ajustar as configurações para obter o resultado necessário.Por exemplo, você deseja usar os valores no meio ampliando o intervalo para que não haja pico agudo (Especial por padrão) ou campainha (Gaussiana).Você pode configurar o Special para obter algo assim: Nesse caso, os IDs ainda estão próximos e há concorrência. Mas a influência de um "ponto de acesso" é menor, portanto, possíveis conflitos serão agora com vários IDs, que, dependendo do número de registros em uma página, podem estar em várias páginas.Outro exemplo é o particionamento. Por exemplo, como verificar como o sistema funciona com partições, concentrando-se nos dados mais recentes, arquivando os antigos?Fácil! Lembre-se do gráfico de distribuição de Pareto? Você pode alterá-lo de acordo com suas necessidades.
Nesse caso, os IDs ainda estão próximos e há concorrência. Mas a influência de um "ponto de acesso" é menor, portanto, possíveis conflitos serão agora com vários IDs, que, dependendo do número de registros em uma página, podem estar em várias páginas.Outro exemplo é o particionamento. Por exemplo, como verificar como o sistema funciona com partições, concentrando-se nos dados mais recentes, arquivando os antigos?Fácil! Lembre-se do gráfico de distribuição de Pareto? Você pode alterá-lo de acordo com suas necessidades. Ao especificar o valor -rand-pareto, é possível obter exatamente o que você queria forçando o sysbench a se concentrar em grandes valores de ID.O Zipfian também pode ser configurado e, embora você não possa obter uma inversão, como é o caso de Pareto, é possível alternar facilmente de um pico em um valor para uma distribuição mais uniforme. Um bom exemplo é o seguinte:
Ao especificar o valor -rand-pareto, é possível obter exatamente o que você queria forçando o sysbench a se concentrar em grandes valores de ID.O Zipfian também pode ser configurado e, embora você não possa obter uma inversão, como é o caso de Pareto, é possível alternar facilmente de um pico em um valor para uma distribuição mais uniforme. Um bom exemplo é o seguinte: A última coisa a ter em mente, e parece-me que essas são coisas óbvias, mas é melhor dizer do que não dizer que, ao alterar os parâmetros aleatórios de geração de números, o desempenho muda.Comparar latência:
A última coisa a ter em mente, e parece-me que essas são coisas óbvias, mas é melhor dizer do que não dizer que, ao alterar os parâmetros aleatórios de geração de números, o desempenho muda.Comparar latência: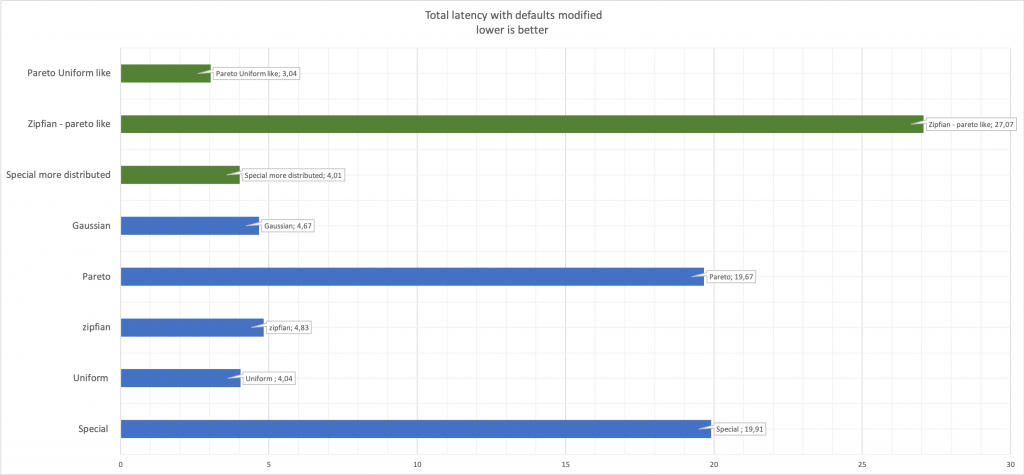 aqui, o verde mostra os valores alterados em comparação com o azul original.
aqui, o verde mostra os valores alterados em comparação com o azul original.
achados
Neste ponto, você já deve entender como é fácil configurar a geração aleatória de números no sysbench e como isso pode ser útil para você. Lembre-se de que o descrito acima se aplica a todas as chamadas, por exemplo, ao usar sysbench.rand.default:local function get_id()
return sysbench.rand.default(1, sysbench.opt.table_size)
End
Dado isso, não copie o código dos artigos de outras pessoas, mas pense e aprofunde o que você precisa e como conseguir isso.Antes de executar os testes, verifique as opções de geração de número aleatório para garantir que sejam apropriadas e adequadas às suas necessidades. Para simplificar minha vida, eu uso esse teste simples . Este teste exibe informações de distribuição de ID bastante claras.Meu conselho é que você entenda suas necessidades e realize testes / testes de desempenho corretamente.Referências
Primeiro de tudo, este é sysbench si .Artigos sobre Zipfian:Pareto:Artigo da Percona sobre como escrever seus scripts no sysbenchTodos os materiais usados para este artigo estão no GitHub .
→ Saiba mais sobre o curso