Ao longo dos 10 anos de existência do ivi, construímos um banco de dados de 90.000 vídeos de vários comprimentos, tamanhos e qualidade. Centenas de novos aparecem toda semana. Temos gigabytes de metadados, que são úteis para recomendações, simplificam a navegação do serviço e configuram a publicidade. Mas começamos a extrair informações diretamente do vídeo apenas dois anos atrás.Neste artigo, mostrarei como analisamos os filmes em elementos estruturais e por que precisamos dele. No final, há um link para o repositório do Github com código e exemplos de algoritmos.
Em que consiste um vídeo?
O videoclipe possui uma estrutura hierárquica. É sobre vídeo digital, portanto, no nível mais baixo, estão pixels , pontos coloridos que compõem uma imagem estática.As imagens estáticas são chamadas de quadros - elas se substituem e criam o efeito do movimento. Na instalação, os quadros são cortados em grupos que, conforme orientação do diretor, são trocados e colados de volta. A sequência de quadros de uma montagem colada a outra em inglês é chamada de termo shot. Infelizmente, a terminologia russa não é bem-sucedida, porque nela esses grupos também são chamados de quadros. Para não ficar confuso, vamos usar o termo em inglês. Basta digitar a versão em russo: "shot" .As fotos são agrupadas por significado, são chamadas de cenas.A cena é caracterizada pela unidade de lugar, tempo e personagens.Podemos facilmente obter quadros individuais e até pixels desses quadros, porque os algoritmos de codificação de vídeo digital são organizados de maneira muito clara. Esta informação é necessária para a reprodução.Fronteiras de fotos e cenas são muito mais difíceis de obter. Fontes de programas de instalação podem ajudar, mas não estão disponíveis para nós.Felizmente, os algoritmos podem fazer isso, embora não perfeitamente perfeitamente. Vou falar sobre o algoritmo para dividir em cenas.
Na instalação, os quadros são cortados em grupos que, conforme orientação do diretor, são trocados e colados de volta. A sequência de quadros de uma montagem colada a outra em inglês é chamada de termo shot. Infelizmente, a terminologia russa não é bem-sucedida, porque nela esses grupos também são chamados de quadros. Para não ficar confuso, vamos usar o termo em inglês. Basta digitar a versão em russo: "shot" .As fotos são agrupadas por significado, são chamadas de cenas.A cena é caracterizada pela unidade de lugar, tempo e personagens.Podemos facilmente obter quadros individuais e até pixels desses quadros, porque os algoritmos de codificação de vídeo digital são organizados de maneira muito clara. Esta informação é necessária para a reprodução.Fronteiras de fotos e cenas são muito mais difíceis de obter. Fontes de programas de instalação podem ajudar, mas não estão disponíveis para nós.Felizmente, os algoritmos podem fazer isso, embora não perfeitamente perfeitamente. Vou falar sobre o algoritmo para dividir em cenas.Por que nós precisamos disso?
Resolvemos o problema de pesquisa dentro do vídeo e queremos testar automaticamente todas as cenas de todos os filmes no ivi. Dividir em cenas é uma parte importante desse pipeline.Para saber onde as cenas começam e terminam, você precisa criar trailers sintéticos. Já temos um algoritmo que os gera, mas até agora a detecção de cena não é usada lá.O sistema de recomendação também é útil para dividir em cenas. A partir deles, são obtidos sinais que descrevem quais filmes os usuários gostam em estrutura.Quais são as abordagens para resolver o problema?
O problema é resolvido de dois lados:- Eles pegam o vídeo inteiro e procuram os limites das cenas.
- Primeiro, eles dividem o vídeo em fotos e depois os combinam em cenas.
Seguimos o segundo caminho, porque é mais fácil formalizar, e há artigos científicos sobre esse assunto. Já sabemos como dividir o vídeo em fotos. Resta coletar essas fotos em cenas.A primeira coisa que você deseja tentar é agrupar. Tire as fotos, transforme-as em vetores e, em seguida, divida os vetores em grupos clássicos usando algoritmos de agrupamento clássicos. A principal desvantagem dessa abordagem: não leva em conta que os disparos e as cenas se seguem. Uma foto de outra cena não pode ficar entre duas fotos de uma cena e, com o agrupamento, isso é possível.Em 2016, Daniel Rothman e seus colegas da IBM propuseram um algoritmo que leva em conta a estrutura temporal e formularam a combinação de disparos em cenas como uma tarefa de Agrupamento Sequencial Ideal:
A principal desvantagem dessa abordagem: não leva em conta que os disparos e as cenas se seguem. Uma foto de outra cena não pode ficar entre duas fotos de uma cena e, com o agrupamento, isso é possível.Em 2016, Daniel Rothman e seus colegas da IBM propuseram um algoritmo que leva em conta a estrutura temporal e formularam a combinação de disparos em cenas como uma tarefa de Agrupamento Sequencial Ideal:- dada uma sequência de tiros
- precisa dividi-lo em Segmentos K para que essa separação seja ótima.
O que é a separação ideal?
Por enquanto, assumimos que é dado, isto é, o número de cenas é conhecido. Apenas suas fronteiras são desconhecidas.Obviamente, é necessário algum tipo de métrica. Foram inventadas três métricas, baseadas na idéia de distâncias entre pares entre as tomadas.As etapas preparatórias são as seguintes:- Transformamos tiros em vetores (um histograma ou saídas da penúltima camada de uma rede neural)
- Encontre as distâncias aos pares entre os vetores (euclidiano, cosseno ou outro)
- Temos uma matriz quadrada , onde cada elemento é a distância entre os disparos e .
 Essa matriz é simétrica e, na diagonal principal, sempre terá zeros, porque a distância do vetor a si mesmo é zero.Quadrados escuros são traçados ao longo da diagonal - áreas em que os disparos vizinhos são semelhantes entre si, correspondentemente menor distância.Se escolhermos boas combinações que refletem a semântica das tomadas e escolher uma boa função de distância, esses quadrados são as cenas. Encontre as bordas dos quadrados - vamos encontrar as bordas das cenas.Olhando para a matriz, os colegas israelenses formularam três critérios para o particionamento ideal:
Essa matriz é simétrica e, na diagonal principal, sempre terá zeros, porque a distância do vetor a si mesmo é zero.Quadrados escuros são traçados ao longo da diagonal - áreas em que os disparos vizinhos são semelhantes entre si, correspondentemente menor distância.Se escolhermos boas combinações que refletem a semântica das tomadas e escolher uma boa função de distância, esses quadrados são as cenas. Encontre as bordas dos quadrados - vamos encontrar as bordas das cenas.Olhando para a matriz, os colegas israelenses formularam três critérios para o particionamento ideal:
é o vetor de borda da cena.Qual dos critérios para o particionamento ideal escolher?
Uma boa função de perda para uma tarefa de Agrupamento Sequencial Ótimo tem duas propriedades:- Se o filme consistir em uma cena, sempre que tentarmos dividi-lo em duas partes, o valor da função será sempre o mesmo.
- Se corretamente dividido em cenas, o valor será menor do que se não estiver corretamente.
Acontece que e não lida com esses requisitos e enfrentamento. Para ilustrar isso, realizaremos dois experimentos.No primeiro experimento, faremos uma matriz sintética de distâncias aos pares, preenchendo-a com ruído uniforme. Se tentarmos dividir em duas cenas, obtemos a seguinte imagem: diz que no meio do vídeo há uma mudança de cenas, que na verdade não é verdade. At saltos anormais se colocar a partição no início ou no final do vídeo. Somente se comporta conforme necessário.No segundo experimento, criaremos a mesma matriz com ruído uniforme, mas subtrairemos dois quadrados dela, como se tivéssemos duas cenas um pouco diferentes uma da outra.
diz que no meio do vídeo há uma mudança de cenas, que na verdade não é verdade. At saltos anormais se colocar a partição no início ou no final do vídeo. Somente se comporta conforme necessário.No segundo experimento, criaremos a mesma matriz com ruído uniforme, mas subtrairemos dois quadrados dela, como se tivéssemos duas cenas um pouco diferentes uma da outra.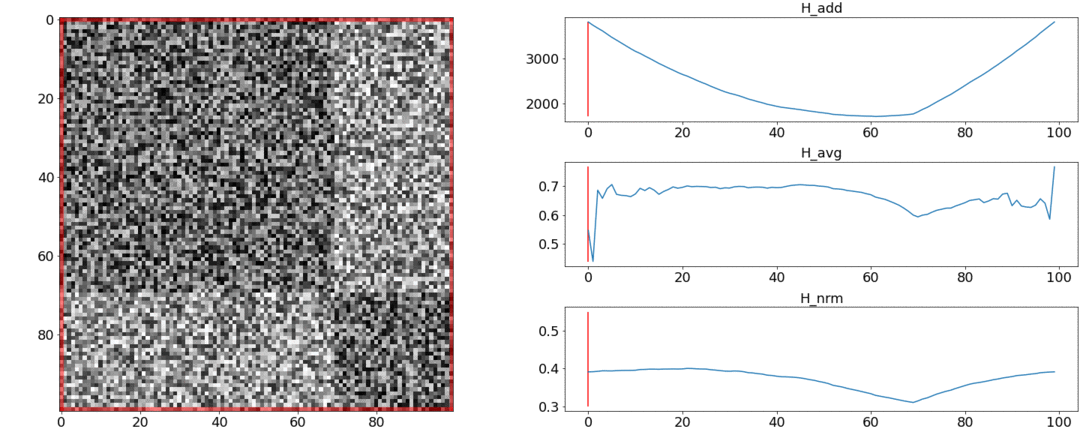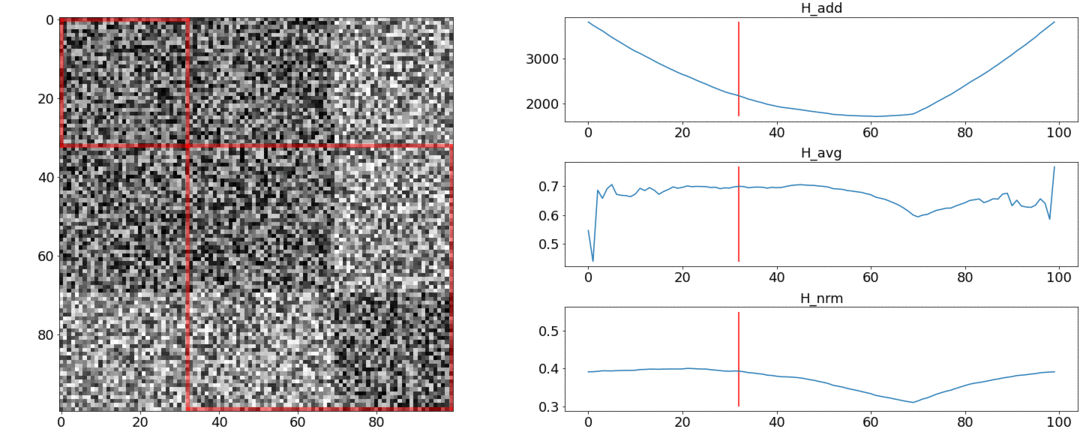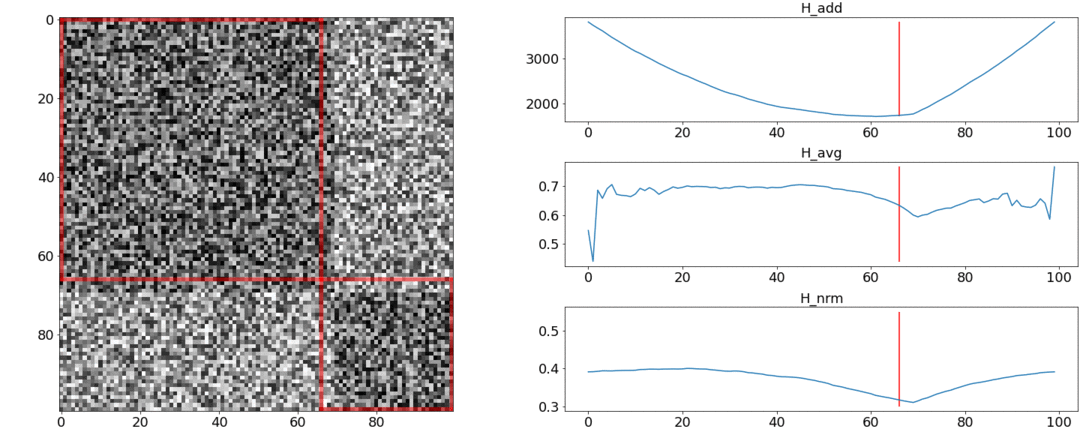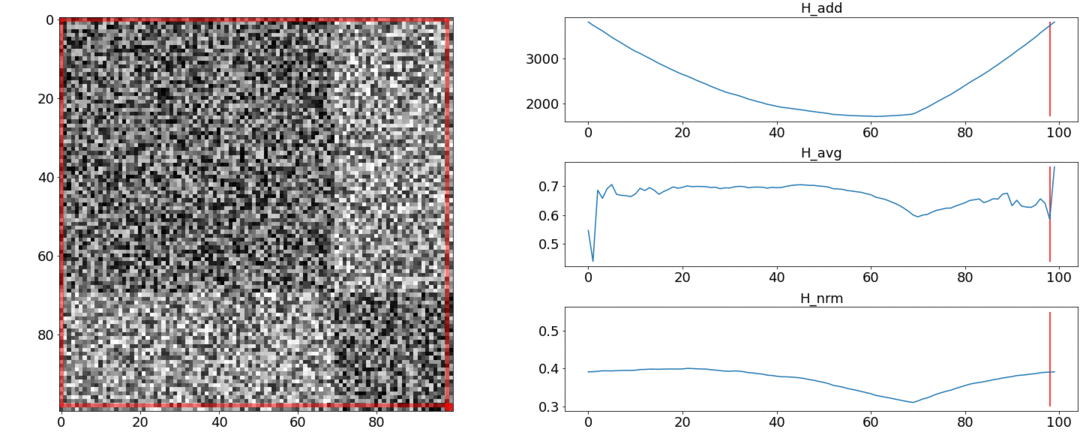 Para detectar essa colagem, a função deve ter um valor mínimo quando . Mas um mínimo ainda mais próxima é a do meio do segmento, enquanto - até o começo. At um mínimo claro é visto em .Os testes também mostram que a divisão mais precisa é obtida usando . Parece que você precisa tomá-lo, e tudo ficará bem. Mas vamos primeiro olhar para a complexidade do algoritmo de otimização. Daniel Rothman e seu grupo sugeriram a busca de particionamento ideal usandoprogramação dinâmica. A tarefa é dividida em subtarefas de maneira recursiva e resolvida por sua vez. Esse método fornece um ótimo global, mas, para encontrá-lo, você precisa iterar a cadatodas as combinações de partições da 0ª à Nª fotos e selecione a melhor. Aqui é o número de cenas e é o número de fotos. Sem ajustes e otimizações de aceleraçãovai trabalhar em tempo. ATHá mais um parâmetro para enumeração - a área da partição e, em cada etapa, é necessário verificar todos os seus valores. Consequentemente, o tempo aumenta para.Conseguimos fazer algumas melhorias e acelerar a otimização usando a técnica de Memorização - armazenando em cache os resultados da recursão na memória para não ler a mesma coisa várias vezes. Mas, como mostram os testes abaixo, um forte aumento na velocidade não foi alcançado.
Para detectar essa colagem, a função deve ter um valor mínimo quando . Mas um mínimo ainda mais próxima é a do meio do segmento, enquanto - até o começo. At um mínimo claro é visto em .Os testes também mostram que a divisão mais precisa é obtida usando . Parece que você precisa tomá-lo, e tudo ficará bem. Mas vamos primeiro olhar para a complexidade do algoritmo de otimização. Daniel Rothman e seu grupo sugeriram a busca de particionamento ideal usandoprogramação dinâmica. A tarefa é dividida em subtarefas de maneira recursiva e resolvida por sua vez. Esse método fornece um ótimo global, mas, para encontrá-lo, você precisa iterar a cadatodas as combinações de partições da 0ª à Nª fotos e selecione a melhor. Aqui é o número de cenas e é o número de fotos. Sem ajustes e otimizações de aceleraçãovai trabalhar em tempo. ATHá mais um parâmetro para enumeração - a área da partição e, em cada etapa, é necessário verificar todos os seus valores. Consequentemente, o tempo aumenta para.Conseguimos fazer algumas melhorias e acelerar a otimização usando a técnica de Memorização - armazenando em cache os resultados da recursão na memória para não ler a mesma coisa várias vezes. Mas, como mostram os testes abaixo, um forte aumento na velocidade não foi alcançado.Como estimar o número de cenas?
Um grupo da IBM sugeriu que, como muitas linhas da matriz são linearmente dependentes, o número de clusters quadrados ao longo da diagonal será aproximadamente igual à classificação da matriz.Para obtê-lo e ao mesmo tempo filtrar o ruído, você precisa de uma decomposição singular da matriz.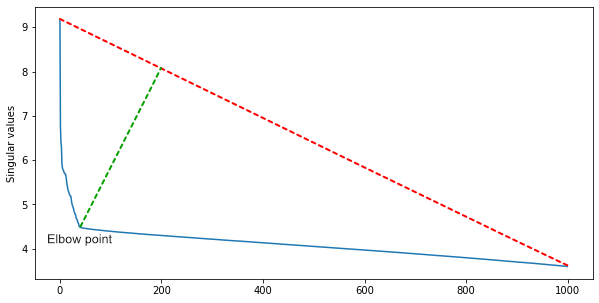 Entre os valores singulares, classificados em ordem decrescente, encontramos o ponto do cotovelo - aquele a partir do qual a diminuição nos valores desacelera acentuadamente. O índice do ponto do cotovelo é o número aproximado de cenas em um filme.Para uma primeira aproximação, isso é suficiente, mas você pode complementar o algoritmo com heurísticas para diferentes gêneros de cinema. Nos filmes de ação, há mais cenas, e em uma câmara - menos.
Entre os valores singulares, classificados em ordem decrescente, encontramos o ponto do cotovelo - aquele a partir do qual a diminuição nos valores desacelera acentuadamente. O índice do ponto do cotovelo é o número aproximado de cenas em um filme.Para uma primeira aproximação, isso é suficiente, mas você pode complementar o algoritmo com heurísticas para diferentes gêneros de cinema. Nos filmes de ação, há mais cenas, e em uma câmara - menos.Testes
Queríamos entender duas coisas:- A diferença de velocidade é tão dramática?
- Quanta precisão sofre ao usar um algoritmo mais rápido?
Os testes foram divididos em dois grupos: dados sintéticos e reais. Nos testes sintéticos, a qualidade e a velocidade de ambos os algoritmos foram comparadas e, nos reais, eles mediram a qualidade do algoritmo mais rápido. Os testes de velocidade foram realizados no MacBook Pro 2017, 2,3 GHz Intel Core i5, 16 GB 2133 MHz LPDDR3.Testes de qualidade sintética
Geramos 999 matrizes de distâncias aos pares, variando em tamanho de 12 a 122 fotos, dividindo-as aleatoriamente em 2 a 10 cenas e adicionando ruído normal de cima.Para cada matriz, as partições ótimas foram encontradas em termos de e e contou as métricas de precisão, rechamada, F1 e IoU.Consideramos Precisão e Recuperação para o intervalo usando as seguintes fórmulas:
Consideramos F1 como de costume, substituindo o intervalo Precision and Recall:
Para comparar os segmentos previsto e verdadeiro dentro do filme, para cada previsto, encontramos o segmento verdadeiro com a maior interseção e consideramos a métrica para esse par.Aqui estão os resultados: Otimização de função ganhou em todas as métricas, como nos testes dos autores do algoritmo.
Otimização de função ganhou em todas as métricas, como nos testes dos autores do algoritmo.Ensaios de velocidade sintéticos
Para testar a velocidade, realizamos outros testes sintéticos. O primeiro é como o tempo de execução do algoritmo depende do número de disparos.com um número fixo de cenas: O teste confirmou uma avaliação teórica: tempo de otimização cresce polinomialmente com o crescimento comparado ao tempo linear às .Se você fixar o número de fotos e aumentar gradualmente o número de cenas , temos uma imagem mais interessante. A princípio, espera-se que o tempo cresça, mas depois começa a despencar. O fato é que o número de possíveis valores do denominador (fórmula) que precisamos verificar proporcionalmente ao número de maneiras que podemos quebrar segmentos em . É calculado usando a combinação de de :
O teste confirmou uma avaliação teórica: tempo de otimização cresce polinomialmente com o crescimento comparado ao tempo linear às .Se você fixar o número de fotos e aumentar gradualmente o número de cenas , temos uma imagem mais interessante. A princípio, espera-se que o tempo cresça, mas depois começa a despencar. O fato é que o número de possíveis valores do denominador (fórmula) que precisamos verificar proporcionalmente ao número de maneiras que podemos quebrar segmentos em . É calculado usando a combinação de de :
Com crescimento o número de combinações cresce primeiro e depois cai quando você se aproxima . Parece legal, mas o número de cenas raramente será igual ao número de fotos e sempre terá um valor tão grande que existem muitas combinações. Nos já mencionados "Vingadores" 2700 fotos e 105 cenas. Número de combinações:
Parece legal, mas o número de cenas raramente será igual ao número de fotos e sempre terá um valor tão grande que existem muitas combinações. Nos já mencionados "Vingadores" 2700 fotos e 105 cenas. Número de combinações:
Para ter certeza de que tudo foi entendido corretamente e não emaranhado na notação dos artigos originais, escrevemos uma carta a Daniel Rothman. Ele confirmou que muito lento para otimizar e não é adequado para vídeos com mais de 10 minutos e na prática, dá resultados aceitáveis.Testes de dados reais
Então, escolhemos uma métrica , que, embora um pouco menos preciso, funciona muito mais rápido. Agora precisamos de métricas, a partir das quais basearemos a busca por um algoritmo melhor.Para o teste, marcamos 20 filmes de diferentes gêneros e anos. A marcação foi realizada em cinco etapas:- Materiais preparados para corte:
- números de quadro renderizados no vídeo
- storyboards impressos com números de quadros, para que você possa capturar imediatamente dezenas de quadros e ver as bordas das colas de montagem.
- Usando os materiais preparados, o marcador anotou os números dos quadros no arquivo de texto que correspondem às bordas das fotos.
- Então ele dividiu as cenas em cenas. Os critérios para combinar tomadas em cenas estão descritos acima na seção "Em que consiste o vídeo?"
- O arquivo de marcação final foi verificado pelos desenvolvedores da equipe do CV. A principal tarefa durante a verificação é verificar os limites das cenas, porque os critérios podem ser interpretados subjetivamente.
- A marcação verificada pela pessoa foi eliminada através de um script que encontrou erros de digitação e erros como "o quadro do final da cena é menor que o início da cena".
É assim que o rabiscador e a tela do inspetor se parecem: E é assim que as primeiras 300 cenas do filme "Vingadores: Guerra Infinita" são divididas em cenas. À esquerda, estão as cenas reais, e à direita, as previstas pelo algoritmo:
E é assim que as primeiras 300 cenas do filme "Vingadores: Guerra Infinita" são divididas em cenas. À esquerda, estão as cenas reais, e à direita, as previstas pelo algoritmo: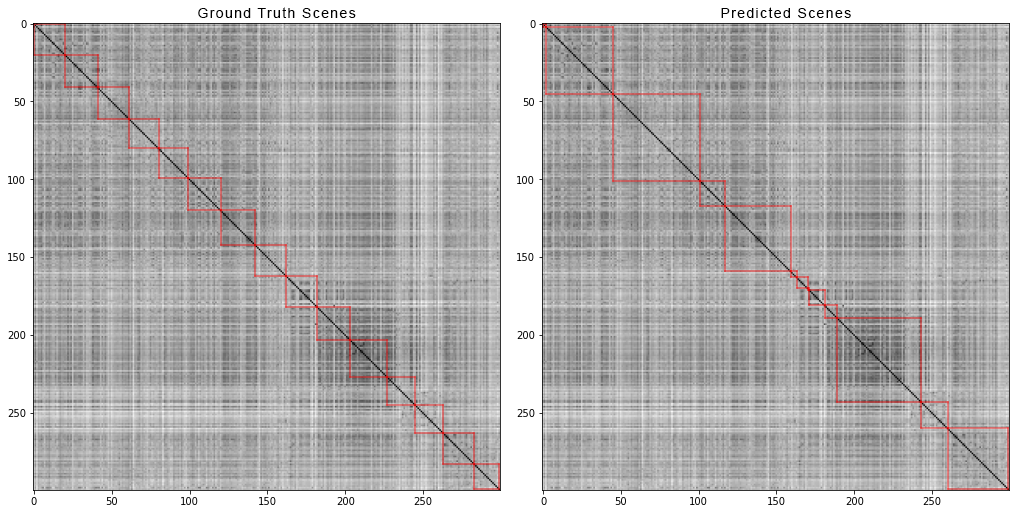 Para obter uma matriz de distâncias aos pares, fizemos o seguinte:Para cada vídeo do conjunto de dados, geramos matrizes de distâncias em pares e, assim como para os dados sintéticos, calculamos quatro métricas. Aqui estão os números que saíram:
Para obter uma matriz de distâncias aos pares, fizemos o seguinte:Para cada vídeo do conjunto de dados, geramos matrizes de distâncias em pares e, assim como para os dados sintéticos, calculamos quatro métricas. Aqui estão os números que saíram:- Precisão : 0.4861919030708739
- Lembre-se : 0,8225937459424839
- F1 : 0.513676858711775
- IoU : 0.37560909807842874
E daí?
Temos uma linha de base que não funciona perfeitamente, mas agora você pode desenvolvê-la enquanto procuramos métodos mais precisos.Alguns dos outros planos:- Experimente outras arquiteturas da CNN para extração de recursos.
- Tente outras métricas de distância entre as fotos.
- Experimente outros métodos de otimização , por exemplo, algoritmos genéticos.
- Tente reduzir a decomposição do filme inteiro em partes separadas nas quais cumpre em um prazo razoável e compara qual será a perda de qualidade.
O código dos métodos e das experiências com dados sintéticos foi publicado no Github . Você pode tocar e tentar acelerar a si mesmo. Gostos e solicitações pull são bem-vindos.Tchau pessoal, até o próximo artigo!