Nos modernos processadores Intel x86, o pipeline pode ser dividido em 2 partes: Front End e Back End.O Front End é responsável por carregar o código da memória e decodificá-lo em micro-operações.O Back-End é responsável por realizar micro-operações no Front-End. Como essas micro-operações podem ser executadas pelo kernel fora de ordem, o Back-end também garante que o resultado dessas micro-operações corresponda estritamente à ordem na qual elas são inseridas no código.Na maioria dos casos, o uso ineficiente do Front End'a não tem um efeito perceptível no desempenho. O pico de largura de banda na maioria dos processadores Intel é de 4 micro operações por ciclo; portanto, por exemplo, para um código ligado à memória / L3, a CPU não poderá utilizá-lo completamente.Pro relativamente novo Ice Lake, Ice Lake 4 5 . , , .
No entanto, em alguns casos, a diferença no desempenho pode ser bastante significativa. Sob o corte está uma análise do impacto do cache de microoperação no desempenho.O conteúdo do artigo
- Meio Ambiente
- Visão geral dos processadores Front-End Intel
- Análise de pico de largura de banda µop cache -> IDQ
- Exemplo
Meio Ambiente
Para todas as medições neste artigo serão usadas i7-8550U Kaby Lake, HT ativado / Ubuntu 18.04/Linux Kernel 5.3.0-45-generic. Nesse caso, esse ambiente pode ser significativo, porque cada modelo de CPU possui seu próprio evento de desempenho. Em particular, para microarquiteturas mais antigas que Sandy Bridge, alguns dos eventos usados no futuro simplesmente não fazem sentido.Visão geral dos processadores Front-End Intel
A organização de alto nível da linha de montagem é uma informação publicamente disponível e é publicada na documentação oficial da Intel sobre otimização de software . Uma descrição mais detalhada de alguns dos recursos omitidos na documentação oficial pode ser encontrada em outras fontes respeitáveis, como Agner Fog ou Travis Downs . Então, por exemplo, o esquema de montagem de dutos para a Skylake na documentação da Intel se parece com: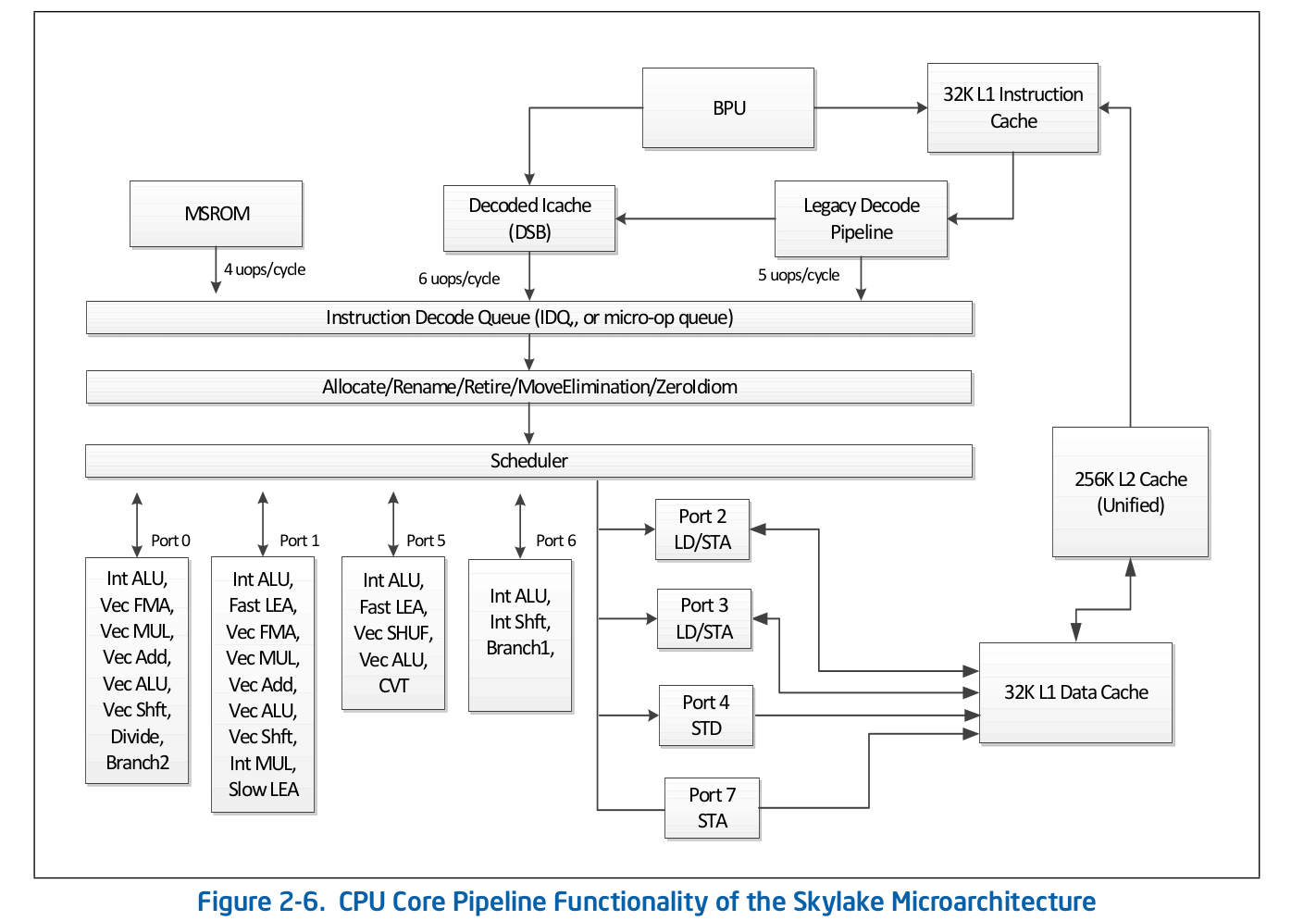 Vamos dar uma olhada mais de perto no topo desse esquema - Front End.
Vamos dar uma olhada mais de perto no topo desse esquema - Front End. O pipeline de decodificação herdado é responsável por decodificar o código em micro-operações. Consiste nos seguintes componentes:
O pipeline de decodificação herdado é responsável por decodificar o código em micro-operações. Consiste nos seguintes componentes:- Unidade de busca de instruções - IFU
- Cache de instruções de primeiro nível - L1i
- Cache de Endereço de Tradução de Log de Instrução - ITLB
- Prefeito do Instrutor
- Instruções de pré-decodificador
- Fila de instruções pré-decodificadas
- Decodificadores de instruções pré-decodificados para micro-operação
Considere cada uma das partes do pipeline de decodificação herdada individualmente.Unidade de busca de instruções.Ele é responsável por carregar o código, pré-codificar (determinar o comprimento da instrução e propriedades como "se a instrução é uma ramificação") e fornecer instruções pré-decodificadas para a fila.Cache de instruções de primeiro nível - L1iPara baixar o código, o IFU usa L1i, o cache de instruções de primeiro nível, e L2 / LLC, o cache de segundo nível e o cache offcore de nível superior, comuns a códigos e dados. O download é realizado em partes de 16 bytes, também alinhadas em 16 bytes. Quando o próximo trecho de código de 16 bytes é carregado em ordem, é feita uma chamada para L1i e, se a linha correspondente não for encontrada, uma pesquisa é realizada em L2 e, em caso de falha, em LLC e memória. Antes da Skylake LLC, o cache era inclusivo - cada linha em L1 (i / d) e L2 deveria estar contida na LLC. Assim, a LLC “sabia” sobre todas as linhas em todos os núcleos e, no caso de um deslizamento da LLC, era sabido se os caches em outros núcleos continham a linha necessária no estado Modificado, o que significa que essa linha poderia ser carregada de outro núcleo. O Skylake LLC se tornou um cache não inclusivo de vítima de L2, mas o tamanho de L2 foi aumentado 4 vezes. Eu não seise L2 é inclusivo em relação a L1i. L2não inclui em relação a L1d.Tradução de endereços lógicos de instruções - ITLBAntes de baixar dados do cache, você deve procurar a linha correspondente. Para ncaches associativos , cada linha pode estar em nlugares diferentes no próprio cache. Para determinar as posições possíveis no cache, um índice é usado (geralmente alguns bits mais baixos do endereço). Para determinar se a linha corresponde ao endereço que precisamos, uma tag é usada (o restante do endereço). Quais endereços usar: físico ou lógico - depende da implementação do cache. O uso de endereços físicos requer tradução de endereços. Para conversão de endereço, é usado um buffer TLB, que armazena em cache os resultados de percursos de página, reduzindo assim o atraso no recebimento de um endereço físico de um endereço lógico nas chamadas subsequentes. Para obter instruções, existe seu próprio buffer TLB de instrução, localizado separadamente do Data TLB. O núcleo da CPU também possui um TLB de segundo nível comum para código e dados - STLB. Não sei se o STLB é inclusivo para mim (há rumores de que não é um cache de vítima inclusivo em relação ao D / I TLB). Usando instruções de pré-busca de softwareprefetcht1você pode puxar a linha com o código em L2; no entanto, o registro TLB correspondente será puxado apenas em DTLB. Se o STLB não for inclusivo, quando você procurar esta linha com o código nos caches, receberá ITLB miss -> STLB miss -> page walk (na verdade, não é tão simples, porque o kernel pode iniciar uma página especulativa antes que isso aconteça Falta de TLB). A documentação da Intel também desencoraja o uso de prefets de SW para código, Intel Software Optimization Manual / 2.5.5.4:A pré-busca controlada por software destina-se à pré-busca de dados, mas não ao código de pré-busca.
No entanto, Travis D. mencionou que essa pré-busca pode ser muito eficaz (e provavelmente é), mas por enquanto isso não é óbvio para mim e, para ter certeza, precisarei examinar separadamente esse problema.Prefeito do InstrutorO carregamento de dados no cache (L1d / i, L2, etc) ocorre ao acessar um local de memória não armazenada em cache. No entanto, se isso acontecesse apenas sob essas condições, como resultado, obteríamos um uso ineficiente da largura de banda do cache. Por exemplo, no Sandy Bridge para operações de leitura L1d - 2, 1 grava 16 bytes por ciclo; para a operação de leitura L1i - 1 de 16 bytes, a taxa de transferência de gravação não está especificada na documentação, o Agner Fog também não foi encontrado. Para resolver esse problema, existem pré-buscadores de hardware que podem determinar o padrão de acesso à memória e puxar as linhas necessárias para o cache antes que o código realmente as resolva. A documentação da Intel define 4 pré-buscadores: 2 para L1d, 2 para L2:- L1 DCU - Prefixa linhas de cache serial. Encaminhar somente leitura
- L1 IP — (. 0x5555555545a0, 0x5555555545b0, 0x5555555545c0, ...), , ,
- L2 Spatial — L2 -, 128-. LLC
- L2 Streamer — . L1 DCU «». LLC
A documentação da Intel não descreve o princípio do prefeito L1i. Tudo o que se sabe é que a Unidade de Previsão de Filial (BPU) está envolvida nesse processo, Manual de Otimização de Software Intel / 2.6.2: O Agner Fog também não vê nenhum detalhe.A pré-busca de código no L2 / LLC é explicitamente definida apenas para o Streamer. Manual de otimização / 2.5.5.4 Prefectching de dados:
Agner Fog também não vê nenhum detalhe.A pré-busca de código no L2 / LLC é explicitamente definida apenas para o Streamer. Manual de otimização / 2.5.5.4 Prefectching de dados:Streamer : esse pré-buscador monitora solicitações de leitura do cache L1 para sequências ascendentes e descendentes de endereços. As solicitações de leitura monitorada incluem solicitações L1 DCache iniciadas por operações de carregamento e armazenamento e pelos pré-buscadores de hardware e solicitações L1 ICache para busca de código.
Para o pré-buscador espacial, isso claramente não está explicitado:Pré-buscador espacial: esse pré-buscador se esforça para concluir todas as linhas de cache buscadas no cache L2 com a linha de pares que o completa em um bloco alinhado de 128 bytes.
Mas isso pode ser verificado. Cada um desses pré-buscadores pode ser desativado usando MSR 0x1A4, conforme descrito no manual Registradores Específicos do Modelo.Sobre MSR 0x1A4MSR L2 Spatial L1i. . , LLC. L2 Streamer 2.5 .
Linux msr , msr . $ sudo wrmsr -p 1 0x1a4 1 L2 Streamer 1.
Instruções de pré-decodificadorDepois que o próximo código de 16 bytes é carregado, eles se enquadram nas instruções de pré-decodificador. Sua tarefa é determinar o comprimento da instrução, decodificar os prefixos e marcar se a instrução correspondente é uma ramificação (provavelmente ainda existem muitas propriedades diferentes, mas a documentação sobre elas é silenciosa). Manual de otimização de software Intel / 2.6.2.2:The predecode unit accepts the sixteen bytes from the instruction cache or prefetch buffers and carries out the following tasks:
- Determine the length of the instructions
- Decode all prefixes associated with instructions
- Mark various properties of instructions for the decoders (for example, “is branch.”)
Uma linha de instruções pré-decodificadas.No IFU, as instruções são adicionadas à fila de instruções pré-codificadas. Essa fila aparece desde a Nehalem, de acordo com a documentação da Intel, seu tamanho é 18 instruções. Agner Fog também menciona que essa fila não contém mais que 64 bytes.Também no Core2, essa fila foi usada como um cache de loop. Se todas as microoperações do ciclo estiverem na fila, em alguns casos, o custo de carregamento e pré-codificação poderá ser evitado. O LSD (Loop Stream Detector) pode fornecer instruções que já estão na fila até a BPU sinalizar que o ciclo terminou. Agner Fog tem várias notas interessantes sobre o LSD no Core2:- Consiste em 4 linhas de 16 bytes
- Taxa de transferência máxima de até 32 bytes de código por ciclo
Começando com o Sandy Bridge, esse cache de loop foi movido da fila de instruções pré-decodificada de volta para o IDQ.Decodificadores de instruções pré-decodificadas em microoperaçãoNa fila de instruções pré-decodificadas, o código é enviado para decodificação em microoperação. Os decodificadores são responsáveis pela decodificação - existem 4. No total, de acordo com a documentação da Intel, um dos decodificadores pode decodificar instruções que consistem em 4 micro-operações ou menos. O restante decodifica instruções que consistem em uma microoperação (micro / macro fundida), Intel Software Optimization Manual / 2.5.2.1:There are four decoding units that decode instruction into micro-ops. The first can decode all IA-32 and Intel 64 instructions up to four micro-ops in size. The remaining three decoding units handle single-micro-op instructions. All four decoding units support the common cases of single micro-op flows including micro-fusion and macro-fusion.
As instruções decodificadas em um grande número de micro-operações (por exemplo, rep movsb usadas na implementação do memcpy in libc em certos tamanhos de memória copiada) são fornecidas pelo Microcode Sequencer (MS ROM). A largura de banda de pico do seqüenciador é de 4 micro-operações por ciclo.Como você pode ver no diagrama da linha de montagem, o Legacy Decode Pipeline pode decodificar até 5 micro operações por ciclo no Skylake. Em Broadwell e mais antigos, o pico de produtividade do Legacy Decode Pipeline era de 4 micro-operações por ciclo.Cache de microoperaçãoDepois que as instruções são decodificadas nas microoperações, no pipeline de decodificação herdado, elas caem na fila de microoperações especial - fila de decodificação de instruções (IDQ), bem como no chamado cache de microoperação (ICache decodificado, cache µop). O cache de microoperação foi originalmente introduzido no Sandy Bridge e é usado para evitar instruções de busca e decodificação em microoperações, aumentando assim a taxa de transferência para a entrega de microoperações em IDQ - até 6 por ciclo. Depois de entrar no IDQ, as microoperações vão para o Back-end para execução com uma taxa de transferência máxima de 4 micro-operações por ciclo.De acordo com a documentação da Intel, o cache de microoperação consiste em 32 conjuntos, cada conjunto contém 8 linhas, cada linha pode armazenar em cache até 6 micro operações (micro / macro fundida), permitindo um cache total de até 32 * 8 * 6 = 1536 micro operações . O cache de microoperação ocorre com uma granularidade de 32 bytes, ou seja, as micro-operações que seguem instruções de diferentes regiões de 32 bytes não podem cair em uma linha. No entanto, até 3 linhas de cache diferentes podem corresponder a uma região de 32 bytes. Assim, até 18 microoperações no cache µop podem corresponder a cada região de 32 bytes.Manual de otimização de software Intel / 2.5.5.2The Decoded ICache consists of 32 sets. Each set contains eight Ways. Each Way can hold up to six micro-ops. The Decoded ICache can ideally hold up to 1536 micro-ops. The following are some of the rules how the Decoded ICache is filled with micro-ops:
- ll micro-ops in a Way represent instructions which are statically contiguous in the code and have their EIPs within the same aligned 32-byte region.
- Up to three Ways may be dedicated to the same 32-byte aligned chunk, allowing a total of 18 micro-ops to be cached per 32-byte region of the original IA program.
- A multi micro-op instruction cannot be split across Ways.
- Up to two branches are allowed per Way.
- An instruction which turns on the MSROM consumes an entire Way.
- A non-conditional branch is the last micro-op in a Way.
- Micro-fused micro-ops (load+op and stores) are kept as one micro-op.
- A pair of macro-fused instructions is kept as one micro-op.
- Instructions with 64-bit immediate require two slots to hold the immediate.
Agner Fog também menciona que apenas micro-operações de linha única podem ser baixadas por ciclo (não explicitamente declarado na documentação da Intel, embora possa ser facilmente verificado manualmente).µop cache --> IDQ
Em alguns casos, é muito conveniente usar nopcomprimentos de 1 byte para estudar o comportamento do Front End . Ao mesmo tempo, podemos ter certeza de que estamos investigando o Front End, e não o Barramento de Recursos no Back End, por qualquer motivo. O fato é que nop, além de outras instruções, eles são decodificados no pipeline de decodificação herdado, misturados no cache µop e enviados ao IDQ. Além disso nop, assim como outras instruções, leva de volta ao final. A diferença significativa é que, dos recursos no back-end, ele nopusa apenas o buffer de reordenação e não requer um slot na estação de reserva (também conhecido como Scheduler). Assim, imediatamente após entrar no Reordenar Buffer, ele estará noppronto para a aposentadoria, o que será executado de acordo com a ordem no código do programa.Para testar a taxa de transferência, declare uma funçãovoid test_decoded_icache(size_t iteration_count);
com implementação em nasm:align 32
test_decoded_icache:
;nop', 0 23
dec rdi
ja test_decoded_icache
ret
jaNão foi escolhido por acaso. jae decusar diferentes bandeiras - jalê CFe ZF, decnão registrando na CF, de modo Macro fusão não se aplica. Isso é feito exclusivamente para a conveniência de contar as micro-operações em um ciclo - cada instrução corresponde a uma micro-operação.Para medições, precisamos dos seguintes eventos perf:1. uops_issued.any- Usado para contar as micro-operações que o Renamer realiza do IDQ.O Intel System Programming Guide documenta esse evento como o número de micro-operações que a Renamer coloca na estação de reserva:Conta o número de uops que a Tabela de Alocação de Recursos (RAT) emite para a Estação de Reserva (RS).
Esta descrição não se correlaciona completamente com os valores que podem ser obtidos em experimentos. Em particular, eles nopcaem nesse balcão, embora seja apenas um fato que eles não são necessários na Estação de Reserva.2. uops_retired.retire_slots- o número total de micro-operações aposentadas, levando em consideração a micro / macro-fusão3. uops_retired.stall_cycles- o número de ticks para os quais não houve uma única microoperação aposentada4. resource_stalls.any- o número de ticks do transportador inativo devido à inacessibilidade de qualquer um dos recursos Back EndNo Manual de otimização de software da Intel / B .4.1 existe um diagrama de conteúdo que caracteriza os eventos descritos acima: 5.
5. idq.all_dsb_cycles_4_uops- o número de ciclos de relógio para os quais 4 (ou mais) instruções foram entregues do µop cache.O fato de essa métrica levar em consideração a entrega de mais de 4 microoperações por ciclo não é descrito na documentação da Intel, mas concorda muito bem com os experimentos.6. idq.all_dsb_cycles_any_uops- o número de medidas para as quais foi entregue pelo menos uma micro operação.7. idq.dsb_cycles- O número total de medidas nas quais a entrega foi realizada no µop cache8. idq_uops_not_delivered.cycles_le_N_uop_deliv.core- O número de medidas pelas quais a Renamer realizou uma Nou menos microoperações e não houve tempo de inatividade no lado do back-end , N- 1, 2, 3.Fazemos pesquisas iteration_count = 1 << 31. Começamos a análise do que está acontecendo na CPU examinando o número de micro-operações e, primeiro, medindo a largura de banda média da aposentadoria, ou seja, uops_retired.retire_slots/uops_retired.total_cycle: O que imediatamente chama sua atenção é a subsidência do rendimento da aposentadoria em um tamanho de ciclo de 7 micro-operações. Para entender qual é o problema, vamos dar uma olhada em como a velocidade média de entrega do µop cache - muda
O que imediatamente chama sua atenção é a subsidência do rendimento da aposentadoria em um tamanho de ciclo de 7 micro-operações. Para entender qual é o problema, vamos dar uma olhada em como a velocidade média de entrega do µop cache - muda idq.all_dsb_cycles_any_uops / idq.dsb_cycles: e como estão o número total de medidas e medidas para o qual o µop cache entregue ao IDQ está relacionado:
e como estão o número total de medidas e medidas para o qual o µop cache entregue ao IDQ está relacionado: Assim, podemos ver que, com um ciclo de 6 micro operações, obtemos uma eficiência utilização da largura de banda do cache µop - 6 micro operações por ciclo. Devido ao fato de o Renamer não suportar tanto quanto o µop cache entrega, parte dos ciclos do µop cache não fornece nada, o que é claramente visível no gráfico anterior.Com um ciclo de 7 microoperações, obtemos uma queda acentuada na taxa de transferência do cache µop - 3,5 microoperações por ciclo. Ao mesmo tempo, como pode ser visto no gráfico anterior, o µop cache está constantemente em operação. Assim, com um ciclo de 7 microoperações, obtemos uma utilização ineficiente do cache de largura de banda µop. O fato é que, como observado anteriormente, o µop cache por ciclo pode oferecer microoperações a partir de apenas uma linha. No caso de microoperações 7 - as 6 primeiras caem em uma linha e as 7ª restantes - em outra. Dessa forma, obtemos 7 micro-operações por 2 ciclos ou 3,5 micro-operações por ciclo.Agora, vamos ver como a Renamer obtém micro-operações da IDQ. Para isso, precisamos
Assim, podemos ver que, com um ciclo de 6 micro operações, obtemos uma eficiência utilização da largura de banda do cache µop - 6 micro operações por ciclo. Devido ao fato de o Renamer não suportar tanto quanto o µop cache entrega, parte dos ciclos do µop cache não fornece nada, o que é claramente visível no gráfico anterior.Com um ciclo de 7 microoperações, obtemos uma queda acentuada na taxa de transferência do cache µop - 3,5 microoperações por ciclo. Ao mesmo tempo, como pode ser visto no gráfico anterior, o µop cache está constantemente em operação. Assim, com um ciclo de 7 microoperações, obtemos uma utilização ineficiente do cache de largura de banda µop. O fato é que, como observado anteriormente, o µop cache por ciclo pode oferecer microoperações a partir de apenas uma linha. No caso de microoperações 7 - as 6 primeiras caem em uma linha e as 7ª restantes - em outra. Dessa forma, obtemos 7 micro-operações por 2 ciclos ou 3,5 micro-operações por ciclo.Agora, vamos ver como a Renamer obtém micro-operações da IDQ. Para isso, precisamos idq_uops_not_delivered.coree idq_uops_not_delivered.cycles_le_N_uop_deliv.core: Você pode notar que, com 7 microoperações, apenas 3 microoperações por vez levam metade dos ciclos da Renamer. A partir daqui, obtemos um rendimento de aposentadoria de uma média de 3,5 micro-operações por ciclo.Outro ponto interessante relacionado a este exemplo pode ser visto se considerarmos o rendimento efetivo da aposentadoria. Essa. sem considerar
Você pode notar que, com 7 microoperações, apenas 3 microoperações por vez levam metade dos ciclos da Renamer. A partir daqui, obtemos um rendimento de aposentadoria de uma média de 3,5 micro-operações por ciclo.Outro ponto interessante relacionado a este exemplo pode ser visto se considerarmos o rendimento efetivo da aposentadoria. Essa. sem considerar uops_retired.stall_cycles: Pode-se notar que, com 7 microoperações, a cada 7 medidas de aposentadoria de 4 microoperações é executada e a cada 8 medidas é inativa sem microoperações aposentadas (estol de aposentadoria). Após a realização de uma série de experimentos, foi possível descobrir que esse comportamento sempre era observado durante 7 microoperações, independentemente do layout 1-6, 6-1, 2-5, 5-2, 3-4, 4-3. Não sei por que esse é exatamente o caso, e não, por exemplo, a retirada de três microoperações é realizada em um ciclo de relógio e quatro no seguinte. Agner Fog mencionou que as transições de ramificação só podem usar parte dos slots da estação de aposentadoria. Talvez essa restrição seja a razão desse comportamento de aposentadoria.
Pode-se notar que, com 7 microoperações, a cada 7 medidas de aposentadoria de 4 microoperações é executada e a cada 8 medidas é inativa sem microoperações aposentadas (estol de aposentadoria). Após a realização de uma série de experimentos, foi possível descobrir que esse comportamento sempre era observado durante 7 microoperações, independentemente do layout 1-6, 6-1, 2-5, 5-2, 3-4, 4-3. Não sei por que esse é exatamente o caso, e não, por exemplo, a retirada de três microoperações é realizada em um ciclo de relógio e quatro no seguinte. Agner Fog mencionou que as transições de ramificação só podem usar parte dos slots da estação de aposentadoria. Talvez essa restrição seja a razão desse comportamento de aposentadoria.Exemplo
Para entender se tudo isso tem efeito na prática, considere o seguinte exemplo um pouco mais prático do que com nops:Duas matrizes são fornecidas unsigned. É necessário acumular a soma das médias aritméticas de cada índice e gravá-la na terceira matriz.Um exemplo de implementação pode ser assim:
static unsigned arr1[] = { ... };
static unsigned arr2[] = { ... };
static void arithmetic_mean(unsigned *arr1, unsigned *arr2, unsigned *out, size_t sz){
unsigned sum = 0;
size_t idx = 0;
while(idx < sz){
sum += (arr1[idx] + arr2[idx]) >> 1;
out[idx] = sum;
idx++;
}
__asm__ __volatile__("" ::: "memory");
}
int main(void){
unsigned out[sizeof arr1 / sizeof(unsigned)];
for(size_t i = 0; i < 4096 * 4096; i++){
arithmetic_mean(arr1, arr2, out, sizeof arr1 / sizeof(unsigned));
}
}
Compilar com sinalizadores do gcc-Werror
-Wextra
-Wall
-pedantic
-Wno-stack-protector
-g3
-O3
-Wno-unused-result
-Wno-unused-parameter
É bastante óbvio que a função arithmetic_meannão estará presente no código e será inserida diretamente em main:(gdb) disas main
Dump of assembler code for function main:
#...
0x00000000000005dc <+60>: nop DWORD PTR [rax+0x0]
0x00000000000005e0 <+64>: mov edx,DWORD PTR [rdi+rax*4]
0x00000000000005e3 <+67>: add edx,DWORD PTR [r8+rax*4]
0x00000000000005e7 <+71>: shr edx,1
0x00000000000005e9 <+73>: add ecx,edx
0x00000000000005eb <+75>: mov DWORD PTR [rsi+rax*4],ecx
0x00000000000005ee <+78>: add rax,0x1
0x00000000000005f2 <+82>: cmp rax,0x80
0x00000000000005f8 <+88>: jne 0x5e0 <main+64>
0x00000000000005fa <+90>: sub r9,0x1
0x00000000000005fe <+94>: jne 0x5d8 <main+56>
#...
Observe que o compilador alinhou o código do loop a 32 bytes ( nop DWORD PTR [rax+0x0]), que é exatamente o que precisamos. Tendo assegurado que não há resource_stalls.anyBack-End (todas as medições são realizadas levando em consideração o cache L1d aquecido), podemos começar a considerar os contadores associados à entrega ao IDQ: Performance counter stats for './test_decoded_icache':
2 273 343 251 idq.all_dsb_cycles_4_uops (15,94%)
4 458 322 025 idq.all_dsb_cycles_any_uops (16,26%)
15 473 065 238 idq.dsb_uops (16,59%)
4 358 690 532 idq.dsb_cycles (16,91%)
2 528 373 243 idq_uops_not_delivered.core (16,93%)
73 728 040 idq_uops_not_delivered.cycles_0_uops_deliv.core (16,93%)
107 262 304 idq_uops_not_delivered.cycles_le_1_uop_deliv.core (16,93%)
108 454 043 idq_uops_not_delivered.cycles_le_2_uop_deliv.core (16,65%)
2 248 557 762 idq_uops_not_delivered.cycles_le_3_uop_deliv.core (16,32%)
2 385 493 805 idq_uops_not_delivered.cycles_fe_was_ok (16,00%)
15 147 004 678 uops_retired.retire_slots
4 724 790 623 uops_retired.total_cycles
1,228684264 seconds time elapsed
Observe que a largura da aposentadoria nesse caso = 15147004678/4724790623 = 3.20585733562 e também que apenas três microoperações levam metade dos relógios da Renamer.Agora adicione a promoção manual do loop à implementação:static void arithmetic_mean(unsigned *arr1, unsigned *arr2, unsigned *out, size_t sz){
unsigned sum = 0;
size_t idx = 0;
if(sz & 2){
sum += (arr1[idx] + arr2[idx]) >> 1;
out[idx] = sum;
idx++;
}
while(idx < sz){
sum += (arr1[idx] + arr2[idx]) >> 1;
out[idx] = sum;
idx++;
sum += (arr1[idx] + arr2[idx]) >> 1;
out[idx] = sum;
idx++;
}
__asm__ __volatile__("" ::: "memory");
}
Os contadores de desempenho resultantes são parecidos com:Performance counter stats for './test_decoded_icache':
2 152 818 549 idq.all_dsb_cycles_4_uops (14,79%)
3 207 203 856 idq.all_dsb_cycles_any_uops (15,25%)
12 855 932 240 idq.dsb_uops (15,70%)
3 184 814 613 idq.dsb_cycles (16,15%)
24 946 367 idq_uops_not_delivered.core (16,24%)
3 011 119 idq_uops_not_delivered.cycles_0_uops_deliv.core (16,24%)
5 239 222 idq_uops_not_delivered.cycles_le_1_uop_deliv.core (16,24%)
7 373 563 idq_uops_not_delivered.cycles_le_2_uop_deliv.core (16,24%)
7 837 764 idq_uops_not_delivered.cycles_le_3_uop_deliv.core (16,24%)
3 418 529 799 idq_uops_not_delivered.cycles_fe_was_ok (16,24%)
3 444 833 440 uops_retired.total_cycles (18,18%)
13 037 919 196 uops_retired.retire_slots (18,17%)
0,871040207 seconds time elapsed
Nesse caso, temos largura de banda de aposentadoria = 13037919196/3444833440 = 3.78477491672, além de utilização eficiente da largura de banda Renamer.Portanto, não apenas nos livramos de uma operação de ramificação e um incremento em um loop, mas também aumentamos a largura de banda de aposentadoria usando a utilização eficiente da taxa de transferência do cache de microoperação, o que proporcionou um aumento total de 28% no desempenho.Observe que apenas uma redução em uma operação de ramificação e incremento fornece um aumento de desempenho médio de 9%.Pequena observação
Na CPU usada para realizar essas experiências, o LSD está desativado. Parece que o LSD poderia lidar com essa situação. Para CPUs com LSD ativado, esses casos precisarão ser investigados separadamente.