Recentemente, falei sobre como usar as receitas padrão para aumentar o desempenho das consultas de "leitura" do SQL de um banco de dados PostgreSQL. Hoje falaremos sobre como você pode tornar a gravação no banco de dados mais eficiente sem usar nenhuma “reviravolta” na configuração - simplesmente organizando corretamente os fluxos de dados.# 1 Particionamento
Um artigo sobre como e por que vale a pena organizar o particionamento aplicado “em teoria” já foi, aqui vamos nos concentrar na prática de usar algumas abordagens na estrutura do nosso serviço de monitoramento para centenas de servidores PostgreSQL ."Casos de dias passados ..."
Inicialmente, como qualquer MVP, nosso projeto começou com uma carga bastante pequena - o monitoramento foi realizado apenas para os dez servidores mais críticos, todas as tabelas eram relativamente compactas ... Mas o tempo passou, havia mais e mais hosts monitorados e mais uma vez tentamos fazer algo com uma das tabelas com um tamanho de 1,5 TB , percebemos que, embora seja possível viver assim, é muito inconveniente.Os tempos eram quase épicos, diferentes variantes do PostgreSQL 9.x eram relevantes, portanto todas as partições tinham que ser feitas manualmente - por meio da herança de tabelas e gatilhos de roteamento dinâmico EXECUTE.A solução resultante acabou por ser universal o suficiente para poder traduzi-la em todas as tabelas:PG10:
Mas o particionamento por herança não tem sido historicamente adequado para trabalhar com um fluxo de gravação ativo ou com um grande número de seções filho. Por exemplo, você deve se lembrar que o algoritmo para selecionar a seção desejada tinha complexidade quadrática , que funciona com mais de 100 seções, você entende como ...Na PG10, essa situação foi bastante otimizada ao implementar o suporte ao particionamento nativo . Portanto, tentamos aplicá-lo imediatamente após a migração do armazenamento, mas ...Como se descobriu após a escavação do manual, a tabela particionada nativamente nesta versão:- não suporta a descrição de índices
- não suporta gatilhos nele
- não pode ser ele próprio "descendente"
- não suporta
INSERT ... ON CONFLICT - não pode gerar seção automaticamente
Dolorosamente enfiando uma testa na nossa testa, percebemos que não podíamos ficar sem modificar o aplicativo e adiamos mais pesquisas por seis meses.PG10: Segunda Chance
Então, começamos a resolver os problemas, por sua vez:- Como os gatilhos
ON CONFLICTforam necessários em alguns lugares, criamos uma tabela intermediária de proxy para resolvê-los . - Nós nos livramos do "roteamento" nos gatilhos - isto é, de
EXECUTE. - Eles tiraram uma tabela de modelo separada com todos os índices para que nem estivessem presentes na tabela de proxy.
Finalmente, depois de tudo isso, a tabela principal já foi particionada nativamente. A criação de uma nova seção permaneceu na consciência do aplicativo.Dicionários "Serrar"
Como em qualquer sistema analítico, também tínhamos “fatos” e “cortes” (dicionários). No nosso caso, nessa capacidade estavam, por exemplo, o corpo do “modelo” do mesmo tipo de consultas lentas ou o texto da própria consulta.Os "fatos" foram particionados por dias por um longo tempo; portanto, excluímos calmamente as seções obsoletas e elas não nos incomodaram (os logs!). Mas com os dicionários o problemaacabou ... Não quer dizer que houvesse muitos deles, mas cerca de 100 TB de “fatos” acabaram sendo um dicionário para 2,5 TB . Você não pode excluir convenientemente nada de uma tabela, não apertá-la em tempo adequado, e escrever nela gradualmente se torna mais lento.Parece um dicionário ... nele, cada entrada deve ser apresentada exatamente uma vez ... e isso mesmo, mas ... Ninguém nos incomoda ter um dicionário separado para todos os dias ! Sim, isso traz uma certa redundância, mas permite:- gravação / leitura mais rápida devido ao tamanho menor da seção
- consuma menos memória trabalhando com índices mais compactos
- armazene menos dados devido à capacidade de remover rapidamente dados obsoletos
Como resultado de todo o complexo de medidas , a carga da CPU diminuiu em ~ 30% e em disco - em ~ 50% :Ao mesmo tempo, continuamos a escrever exatamente a mesma coisa no banco de dados, apenas com menos carga.# 2 Evolução e refatoração de banco de dados
Então, decidimos que, para cada dia, temos nossa própria seção com dados. Na verdade, essa CHECK (dt = '2018-10-12'::date)é a chave de particionamento e a condição para o registro cair em uma seção específica.Como todos os relatórios em nosso serviço são criados de acordo com uma data específica, os índices dos "horários não particionados" eram todos os tipos (servidor, data , modelo de plano) , (servidor, data , nó do plano) , ( data , classe de erro, Servidor) , ...Mas agora cada seção tem suas próprias instâncias de cada um desses índices ... E dentro de cada seção a data é constante ... Acontece que agora estamos em cada um desses índicesinserimos trivialmente uma constante como um dos campos, o que aumenta tanto o volume quanto o tempo de pesquisa, mas não gera nenhum resultado. Eles deixaram um ancinho, oops ...A direção da otimização é óbvia - basta remover o campo de data de todos os índices nas tabelas particionadas. Com nossos volumes, o ganho é de cerca de 1 TB / semana !E agora vamos notar que esse terabyte ainda precisava ser anotado de alguma forma. Ou seja, também precisamos carregar menos disco agora ! Nesta imagem, o efeito obtido com a limpeza, a que dedicamos uma semana, é claramente visível: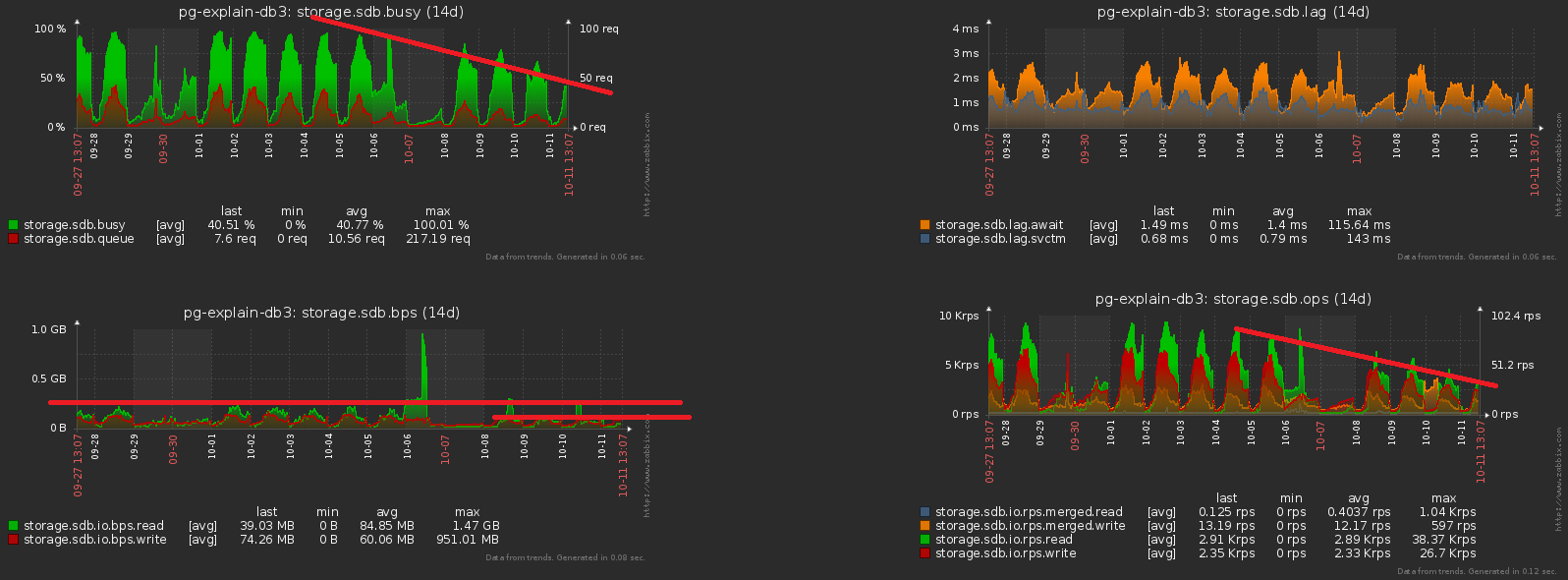
# 3 "Mancha" o pico de carga
Um dos grandes problemas dos sistemas carregados é a sincronização excessiva de algumas operações que não exigem isso. Às vezes "porque eles não perceberam", às vezes "era mais fácil", mas mais cedo ou mais tarde você precisa se livrar dele.Aproximamos a imagem anterior - e vemos que o disco "treme" com uma carga com dupla amplitude entre amostras adjacentes, o que obviamente não deve ser "estatisticamente" com tantas operações: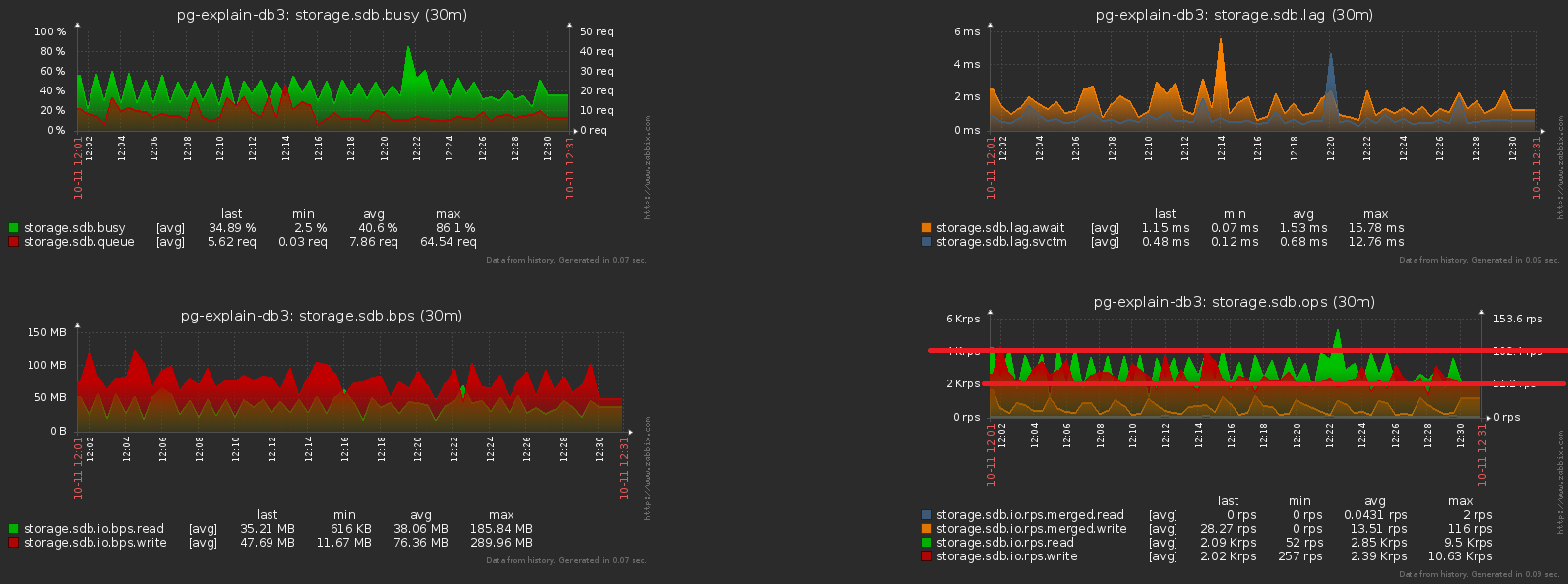 conseguir isso é bastante simples. Quase 1000 servidores já foram iniciados para monitoramento , cada um é processado por um fluxo lógico separado e cada fluxo despeja as informações acumuladas para enviar ao banco de dados com uma certa frequência, algo como isto:
conseguir isso é bastante simples. Quase 1000 servidores já foram iniciados para monitoramento , cada um é processado por um fluxo lógico separado e cada fluxo despeja as informações acumuladas para enviar ao banco de dados com uma certa frequência, algo como isto:setInterval(sendToDB, interval)
O problema aqui reside precisamente no fato de que todos os threads iniciam aproximadamente ao mesmo tempo , portanto os tempos de envio para eles quase sempre coincidem "ao ponto". Ops, número 2 ...Felizmente, isso é corrigido facilmente adicionando um intervalo de tempo "aleatório" :setInterval(sendToDB, interval * (1 + 0.1 * (Math.random() - 0.5)))
# 4 Armazenamento em cache, essa necessidade pode ser
O terceiro problema tradicional de alta carga é a falta de cache onde poderia estar.Por exemplo, tornamos possível analisar o detalhamento dos nós do plano (todos esses Seq Scan on users), mas imediatamente pensamos que eles eram, em geral, o mesmo - esqueci.Não, é claro, nada é gravado no banco de dados repetidamente, isso interrompe o gatilho com INSERT ... ON CONFLICT DO NOTHING. Mas os dados não chegam à base e você precisa fazer uma leitura extra para verificar o conflito . Ops, número 3 ...A diferença no número de registros enviados ao banco de dados antes / depois da ativação do cache é óbvia: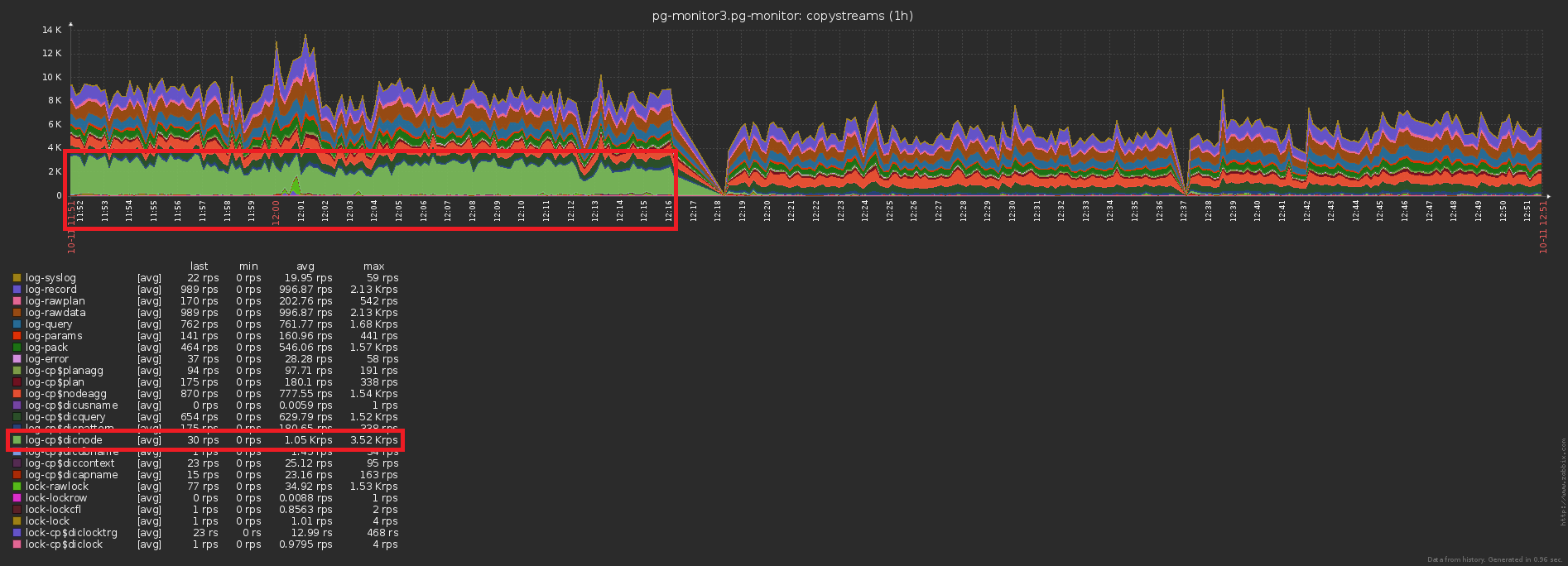 E isso é uma queda concomitante na carga de armazenamento:
E isso é uma queda concomitante na carga de armazenamento:
Total
Terabyte por dia parece assustador. Se você fizer tudo certo, serão apenas 2 ^ 40 bytes / 86400 segundos = ~ 12,5MB / s , que até os parafusos IDE da área de trabalho mantêm. :)Mas, falando sério, mesmo com uma inclinação dez vezes maior da carga durante o dia, você pode facilmente encontrar as possibilidades dos SSDs modernos.