Após todos os cálculos apresentados nesta e nesta publicação, podemos nos aprofundar na análise estatística e considerar o método dos mínimos quadrados. A biblioteca statsmodels é usada para essa finalidade, que permite aos usuários examinar dados, avaliar modelos estatísticos e executar testes estatísticos. Este artigo e este artigo foram tomados como base . A descrição da função usada em inglês está disponível no seguinte link .Primeiro, um pouco de teoria:Sobre regressão linear
A regressão linear é usada como modelo preditivo quando é assumida uma relação linear entre a variável dependente (a variável que estamos tentando prever) e a variável independente (a variável e / ou variáveis usadas para a previsão).No caso mais simples, ao considerar, uma variável é usada com base na qual estamos tentando prever outra. A fórmula neste caso é a seguinte:Y = C + M * X- Y = variável dependente (resultado / previsão / estimativa)
- C = Constante (interceptação em Y)
- M = Inclinação da linha de regressão (inclinação ou gradiente da linha estimada; é a quantidade pela qual Y aumenta em média se aumentarmos X em uma unidade)
- X = variável independente (preditor usado na previsão Y)
De fato, também pode haver uma relação entre a variável dependente e várias variáveis independentes. Para esses tipos de modelos (assumindo linearidade), podemos usar regressão linear múltipla da seguinte forma:Y = C + M1X1 + M2X2 + ...Taxa Beta
Muito já foi escrito sobre este coeficiente, por exemplo, no presente . Páginaresumo, se você não entrar em detalhes, você pode descrevê-lo como segue:Stocks com um coeficiente beta:- zero indica que não há correlação entre ações e índice
- a unidade indica que a ação tem a mesma volatilidade que o índice
- mais de um - indica uma maior lucratividade (e, portanto, riscos) das ações do que o índice
- menos de um - menos ações voláteis que o índice
Em outras palavras, se o estoque aumentar 14%, enquanto o mercado crescer apenas 10%, o coeficiente beta do estoque será 1,4. Normalmente, os mercados com beta mais alto podem oferecer melhores condições de recompensa (e, portanto, risco).
Prática
O código Python a seguir inclui um exemplo de regressão linear, em que a variável de entrada é o rendimento no Moscow Exchange Index e a variável estimada é o rendimento nos estoques da Aeroflot.Para evitar a necessidade de lembrar como fazer o download de dados e trazê-los para a forma necessária para o cálculo, o código é fornecido a partir do momento em que os dados são baixados para os resultados obtidos. Aqui está a sintaxe completa para fazer regressão linear no Python usando o statsmodels:
import pandas as pd
import yfinance as yf
import numpy as np
import matplotlib.pyplot as plt
import statsmodels.api as sm
ticker = ['AFLT.ME','IMOEX.ME']
stock = yf.download(ticker)
all_adj_close = stock[['Adj Close']]
all_returns = np.log(all_adj_close / all_adj_close.shift(1))
aflt_returns = all_returns['Adj Close'][['AFLT.ME']].fillna(0)
moex_returns = all_returns['Adj Close'][['IMOEX.ME']].fillna(0)
return_data = pd.concat([aflt_returns, moex_returns], axis=1)[1:]
return_data.columns = ['AFLT.ME', 'IMOEX.ME']
X = sm.add_constant(return_data['IMOEX.ME'])
y = return_data['AFLT.ME']
model_moex = sm.OLS(y,X).fit()
print(model_moex.summary())
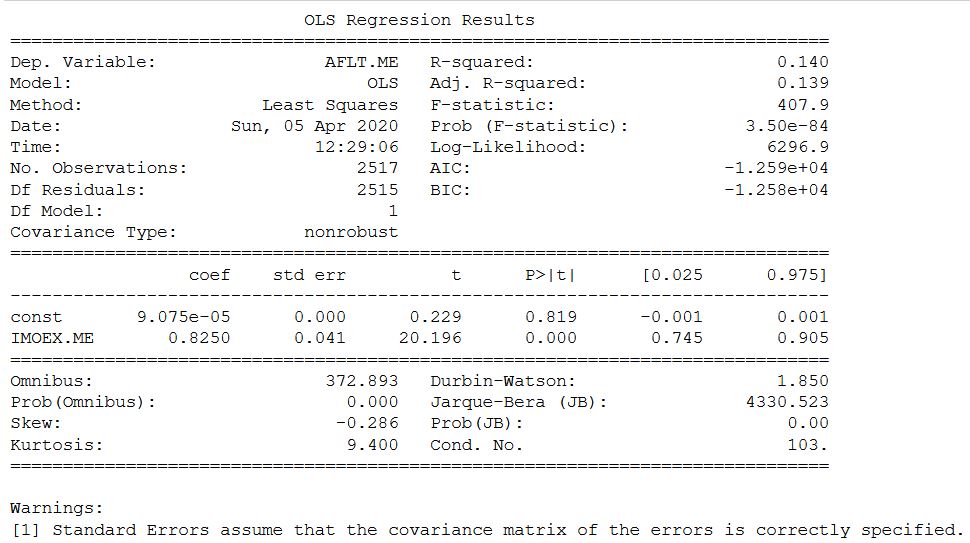 No site yahoo e o coeficiente beta Mosbirzhi difere ligeiramente para cima. Mas devo honestamente admitir que o cálculo para algumas outras ações da bolsa de valores russa mostrou diferenças mais significativas, mas dentro do intervalo.
No site yahoo e o coeficiente beta Mosbirzhi difere ligeiramente para cima. Mas devo honestamente admitir que o cálculo para algumas outras ações da bolsa de valores russa mostrou diferenças mais significativas, mas dentro do intervalo.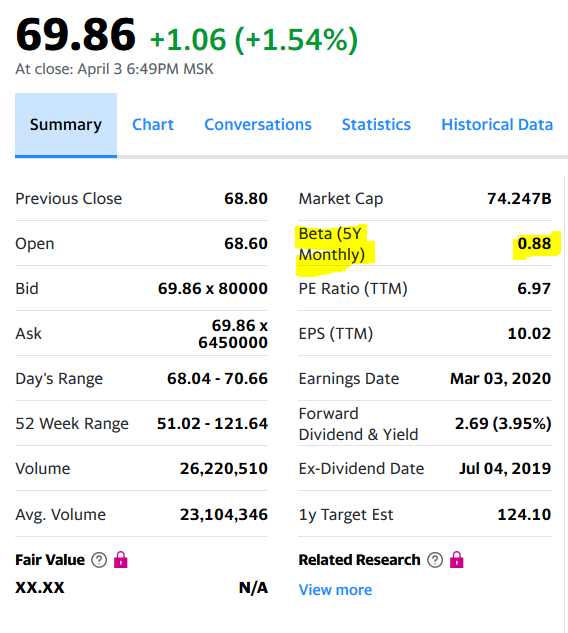 A mesma análise para as ações FB e o índice SP500. Aqui, o cálculo, como no original, é realizado através do rendimento mensal.
A mesma análise para as ações FB e o índice SP500. Aqui, o cálculo, como no original, é realizado através do rendimento mensal.sp_500 = yf.download('^GSPC')
fb = yf.download('FB')
fb = fb.resample('BM').apply(lambda x: x[-1])
sp_500 = sp_500.resample('BM').apply(lambda x: x[-1])
monthly_prices = pd.concat([fb['Close'], sp_500['Close']], axis=1)
monthly_prices.columns = ['FB', '^GSPC']
monthly_returns = monthly_prices.pct_change(1)
clean_monthly_returns = monthly_returns.dropna(axis=0)
X = clean_monthly_returns['^GSPC']
y = clean_monthly_returns['FB']
X1 = sm.add_constant(X)
model_fb_sp_500 = sm.OLS(y, X1)
results_fb_sp_500 = model_fb_sp_500.fit()
print(results_fb_sp_500.summary())
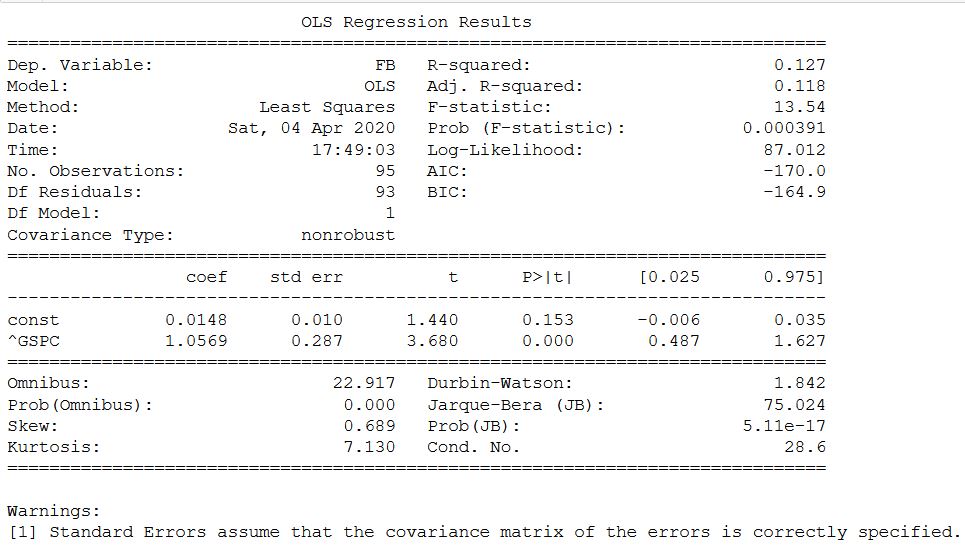
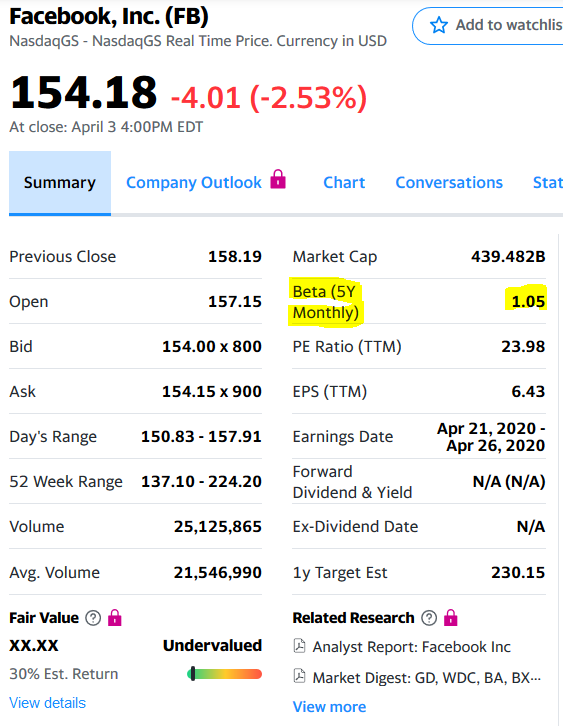 Nesse caso, tudo coincidiu e confirmou a possibilidade de usar modelos estatísticos para determinar o coeficiente beta.Bem, e como um bônus - se você deseja obter apenas beta - você deseja deixar o coeficiente e o restante das estatísticas de lado, então outro código é proposto para calculá-lo:
Nesse caso, tudo coincidiu e confirmou a possibilidade de usar modelos estatísticos para determinar o coeficiente beta.Bem, e como um bônus - se você deseja obter apenas beta - você deseja deixar o coeficiente e o restante das estatísticas de lado, então outro código é proposto para calculá-lo:from scipy import stats
slope, intercept, r_value, p_value, std_err = stats.linregress(X, y)
print(slope)
1.0568997978702754
É verdade que isso não significa que todos os outros valores obtidos devam ser ignorados, mas o conhecimento de estatística será necessário para compreendê-los. Vou dar um pequeno trecho dos valores obtidos:- R-quadrado, que é o coeficiente de determinação e leva valores de 0 a 1. Quanto mais próximo o valor do coeficiente de 1, maior a dependência;
- Adj. R-quadrado - R-quadrado ajustado com base no número de observações e no número de graus de liberdade;
- std err - erro padrão de estimativa de coeficiente;
- P> | t | - valor p Um valor menor que 0,05 é considerado estatisticamente significativo;
- 0,025 e 0,975 são os valores inferior e superior do intervalo de confiança.
- etc.
É tudo por agora. Obviamente, é interessante procurar um relacionamento entre valores diferentes para prever o outro através de um e obter lucro. Em uma das fontes estrangeiras, o índice foi previsto através da taxa de juros e taxa de desemprego. Mas se a alteração na taxa de juros na Rússia puder ser obtida no site do Banco Central, continuarei pesquisando outras. Infelizmente, o site da Rosstat não conseguiu encontrar os relevantes. Esta é a publicação final nos artigos da análise financeira geral.