O que dizemos ao deus da morte? - Hoje nao.
Sirio Trout, série de TV Game of Thrones.Quão perigoso é o coronavírus COVID-19? Quantas pessoas morrerão de coronavírus no mundo? E quanto - na Rússia? São necessárias medidas difíceis para combater o coronavírus na maioria dos países do mundo? O que causará mais danos: morte de pessoas por coronavírus ou declínio econômico causado por medidas restritivas?Para responder a essas perguntas urgentes, é necessário realizar modelagem matemática e prever os danos do coronavírus para cada país e para o mundo como um todo. A construção de tais previsões é dedicada a este artigo.Para tornar o material acessível a todos os leitores, no início do artigo, nos concentraremos na análise qualitativa e nas belas imagens. E no final, para os interessados, forneceremos o código fonte para os cálculos realizados no Python.
Minuto de Cuidados com OVNI
A pandemia de COVID-19, uma infecção respiratória aguda potencialmente grave causada pelo coronavírus SARS-CoV-2 (2019-nCoV), foi anunciada oficialmente no mundo. Há muitas informações sobre Habré sobre esse tópico - lembre-se sempre de que pode ser confiável / útil e vice-versa.
Pedimos que você seja crítico com qualquer informação publicada.
Lave as mãos, cuide de seus entes queridos, fique em casa sempre que possível e trabalhe remotamente.
Leia publicações sobre: coronavírus | trabalho remoto
Contando apenas a morte
Observe que avaliaremos o dano do COVID-19 no número de mortes humanas associadas a esta doença. Grande parte do artigo será dedicada à previsão do número de mortes por coronavírus. Geralmente, recusamos considerar o número de pacientes com coronavírus e prever seu número. Há várias razões para isso. O principal é que é impossível comparar estatísticas sobre o número de casos de COVID-19 em diferentes países. Em alguns países, os métodos de teste rápido estão disponíveis muito mais do que em outros. Em alguns países, é realizada uma triagem quase universal da população, enquanto em outros apenas pessoas com sintomas graves são verificadas. Dado que, em um número significativo de casos, a doença é quase assintomática, vemos uma enorme disseminação no número de mortes entre os pacientes: de menos de 0,5% a mais de 3,5%.Muito provavelmente, a dispersão nos dados de mortalidade se deve em grande parte à detecção de casos de COVID-19.As estatísticas de mortalidade neste caso parecem muito mais confiáveis. Naturalmente, podemos encontrar uma subestimação do número de mortes, quando a causa da morte não é indicada como um coronavírus, mas uma doença concomitante e vice-versa, superestimação, quando o COVID-19 é diagnosticado incorretamente e uma pessoa morre, por exemplo, de gripe sazonal. No entanto, podemos esperar que as estatísticas de mortes sejam mais confiáveis, porque uma doença assintomática com um alto grau de probabilidade geralmente pode passar pela atenção de especialistas, e os médicos são forçados a analisar todos os casos de morte.Também observamos que o dano real à sociedade é causado pela morte de seus membros, e não por uma doença leve que passa relativamente rapidamente.Você achou que o mundo é governado por um expositor? E não!
Assim que começamos a prever o número de mortes, encontramos imediatamente o primeiro mito: dezenas ou mesmo centenas de milhões de pessoas morrerão pelo coronavírus. Este mito é baseado na crença de que o mundo é governado por um expositor. Dê uma olhada no gráfico.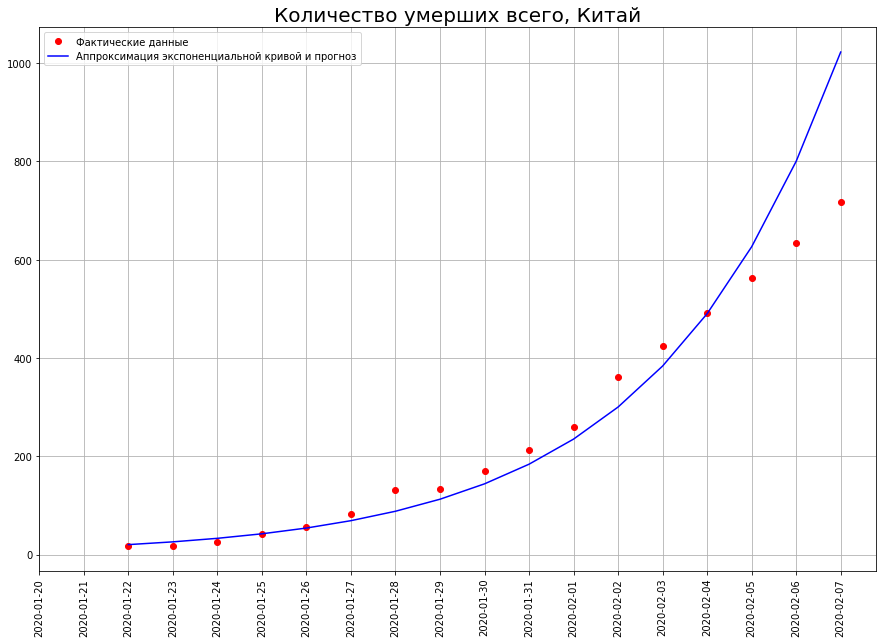 Ele mostra o número de mortes por COVID-19 na China a partir de 7 de fevereiro. Se construirmos uma previsão com base neste gráfico usando uma função exponencial, obtemos que até 29 de fevereiro, 50 milhões de pessoas deveriam ter morrido na China!
Ele mostra o número de mortes por COVID-19 na China a partir de 7 de fevereiro. Se construirmos uma previsão com base neste gráfico usando uma função exponencial, obtemos que até 29 de fevereiro, 50 milhões de pessoas deveriam ter morrido na China! E quantos realmente morreram? 2837 pessoas. Por que uma diferença tão colossal?O fato é que o mundo é governado não por um expositor, mas por uma curva logística.Ao contrário do expositor, a curva logística não passa não apenas na escola, mas também nas principais universidades técnicas (por exemplo, no Departamento de Física da Universidade Estadual de Moscou e na PhysTech). Portanto, físicos e técnicos em geral geralmente não têm idéia sobre isso.No entanto, um grande número de fenômenos em economia, biologia, sociologia, ciência e tecnologia está se desenvolvendo em total conformidade com esse modelo matemático. Vamos dar uma olhada mais de perto. Aqui está ela. O tempo é plotado no eixo x, e em y o número que caracteriza os fenômenos estudados por nós (no nosso caso, o número de mortes por coronavírus).
E quantos realmente morreram? 2837 pessoas. Por que uma diferença tão colossal?O fato é que o mundo é governado não por um expositor, mas por uma curva logística.Ao contrário do expositor, a curva logística não passa não apenas na escola, mas também nas principais universidades técnicas (por exemplo, no Departamento de Física da Universidade Estadual de Moscou e na PhysTech). Portanto, físicos e técnicos em geral geralmente não têm idéia sobre isso.No entanto, um grande número de fenômenos em economia, biologia, sociologia, ciência e tecnologia está se desenvolvendo em total conformidade com esse modelo matemático. Vamos dar uma olhada mais de perto. Aqui está ela. O tempo é plotado no eixo x, e em y o número que caracteriza os fenômenos estudados por nós (no nosso caso, o número de mortes por coronavírus).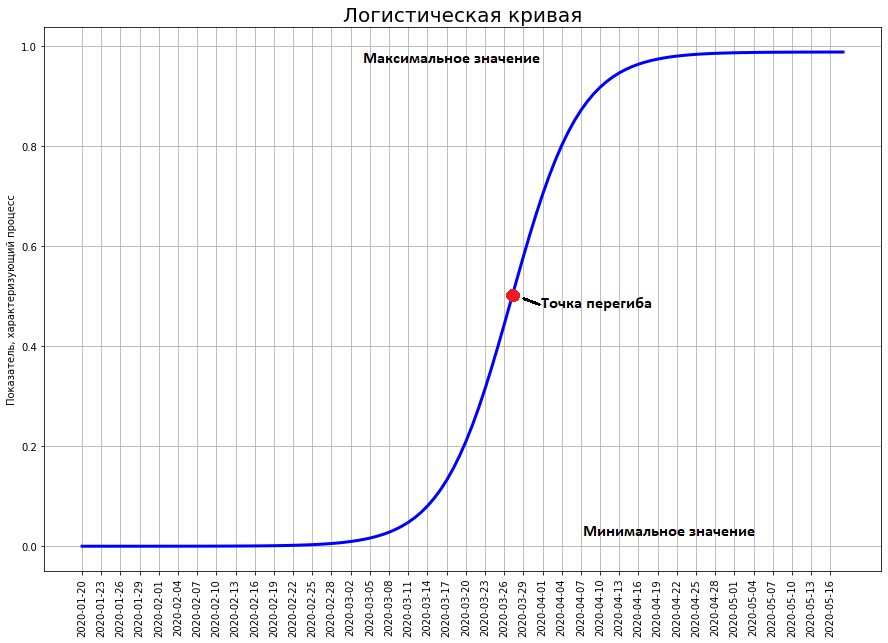
Curva insidiosa que interrompe todo o hype
A curva logística mostra a transição entre dois estados estáveis. O estado inferior é tradicionalmente considerado igual a zero. O estado superior é o máximo que, em princípio, o fenômeno investigado pode alcançar. A curva se aproxima arbitrariamente, mas nunca atinge seu valor máximo.O ponto mais importante na curva é o ponto de inflexão. Ele está localizado exatamente no meio entre o mínimo e o máximo. É nesse ponto que a taxa máxima de crescimento da curva. Mas uma inflexão ocorre nele. Até este ponto, o crescimento da curva apenas acelera. Depois - apenas desaparece.Geralmente, no início, ninguém percebe um certo fenômeno (como o coronavírus não foi notado até o final de janeiro). Nesse ponto, o valor da curva está próximo de zero. Gradualmente, o fenômeno está crescendo, eles começam a perceber, um hype surge em torno dele. O hype pode ser positivo (como, por exemplo, no momento do voo de Gagarin, pessoas em todo o mundo ficaram doentes com espaço) e negativo (a situação com o atual coronavírus). No momento do hype, todo mundo prediz que o fenômeno irá adquirir proporções incríveis e virar o mundo de cabeça para baixo. Então, na época do voo de Gagarin, até os profissionais pensavam que a conquista do sistema solar ocorreria no século XX. E eles não esperavam que todos os sucessos da astronáutica terminassem em 1969 com o desembarque de um homem na lua.É no momento do hype máximo que a curva atinge metade do seu máximo futuro. Então o crescimento desaparece e o fenômeno não justifica completamente as esperanças depositadas nele (assim como os medos).Curva logística chinesa
Vamos ver o que aconteceu na China.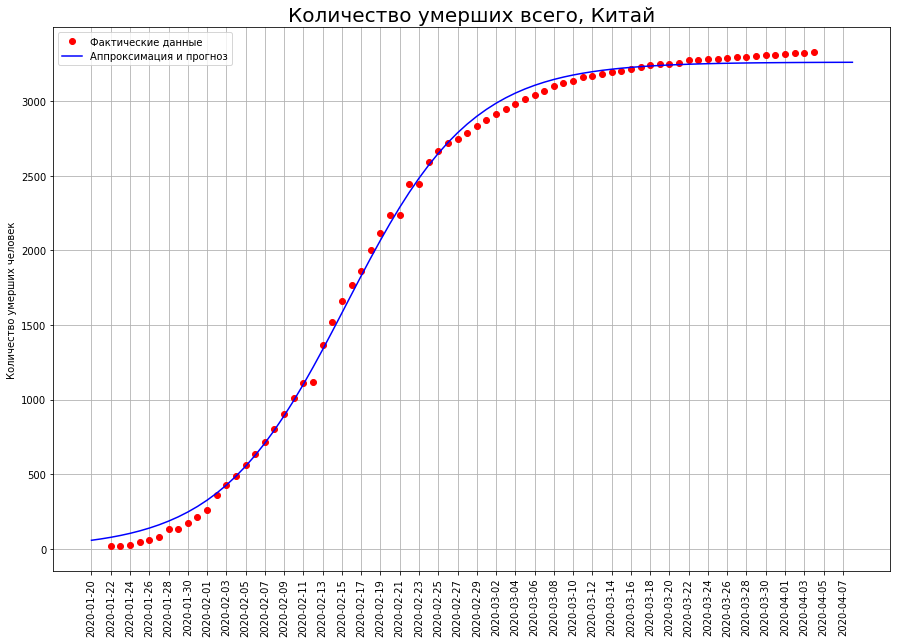 No gráfico abaixo, os pontos vermelhos indicam o número de mortes pelo vírus em uma determinada data. A curva azul é uma curva logística aproximando dados reais. Vemos que os dados caem quase perfeitamente. O gráfico abaixo mostra o número de mortes que ocorreram em uma data específica. De fato, essa é a diferença entre os valores da curva logística de hoje e de ontem. Do ponto de vista matemático, essa é a primeira derivada da curva logística.
No gráfico abaixo, os pontos vermelhos indicam o número de mortes pelo vírus em uma determinada data. A curva azul é uma curva logística aproximando dados reais. Vemos que os dados caem quase perfeitamente. O gráfico abaixo mostra o número de mortes que ocorreram em uma data específica. De fato, essa é a diferença entre os valores da curva logística de hoje e de ontem. Do ponto de vista matemático, essa é a primeira derivada da curva logística.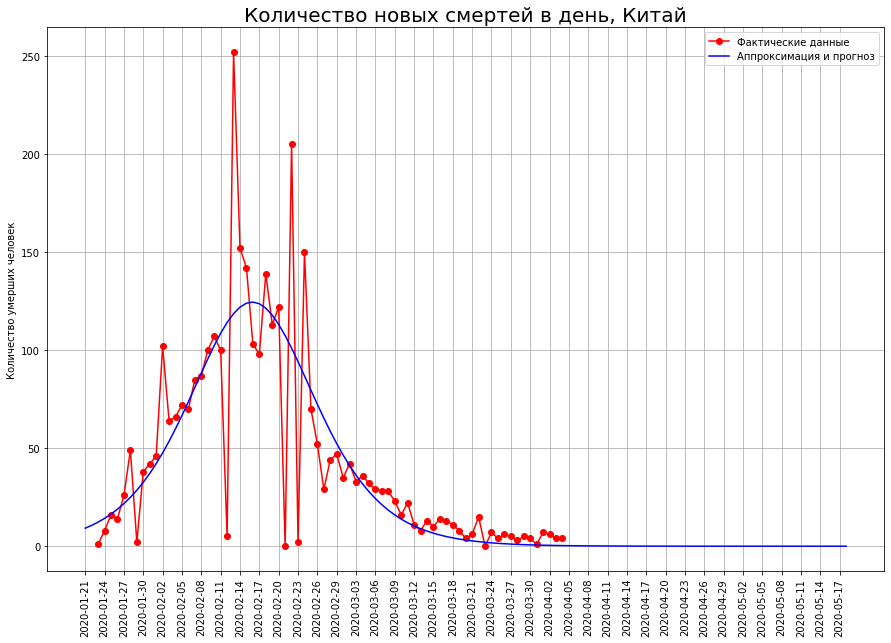 Vemos que, a princípio, o número de novas mortes está crescendo quase exponencialmente. Então o crescimento começa a desacelerar, a curva de novas mortes atinge o máximo no ponto de inflexão, quando a curva logística atinge metade do seu valor máximo. Então o número de novas mortes diminui e corre para zero. Pontos vermelhos indicam novas mortes, a curva azul é a derivada da curva logística que os aproxima.Observe que a curva logística é simétrica em relação ao ponto de sua inflexão e sua primeira derivada é relativa à linha vertical que passa por esse ponto. Também observamos que os dados reais estão idealmente na curva logística, mas eles "dançam" em relação à sua primeira derivada. O fato é que a taxa de mortalidade em um ponto está sujeita a alta dispersão e a taxa total de mortalidade é a soma desses indicadores. É suavizado de acordo com o teorema do limite central.Portanto, vemos que a curva logística pode ser efetivamente usada para prever mortes por coronavírus. Uma propriedade importante aqui é sua simetria. Quando o ponto de inflexão é atingido, podemos restaurar a outra metade com alta precisão a partir da metade da curva.Por sua vez, para determinar se o ponto de inflexão é atingido, basta olhar para o gráfico da primeira derivada. Assim que ele caiu - o ponto correspondente foi alcançado.
Vemos que, a princípio, o número de novas mortes está crescendo quase exponencialmente. Então o crescimento começa a desacelerar, a curva de novas mortes atinge o máximo no ponto de inflexão, quando a curva logística atinge metade do seu valor máximo. Então o número de novas mortes diminui e corre para zero. Pontos vermelhos indicam novas mortes, a curva azul é a derivada da curva logística que os aproxima.Observe que a curva logística é simétrica em relação ao ponto de sua inflexão e sua primeira derivada é relativa à linha vertical que passa por esse ponto. Também observamos que os dados reais estão idealmente na curva logística, mas eles "dançam" em relação à sua primeira derivada. O fato é que a taxa de mortalidade em um ponto está sujeita a alta dispersão e a taxa total de mortalidade é a soma desses indicadores. É suavizado de acordo com o teorema do limite central.Portanto, vemos que a curva logística pode ser efetivamente usada para prever mortes por coronavírus. Uma propriedade importante aqui é sua simetria. Quando o ponto de inflexão é atingido, podemos restaurar a outra metade com alta precisão a partir da metade da curva.Por sua vez, para determinar se o ponto de inflexão é atingido, basta olhar para o gráfico da primeira derivada. Assim que ele caiu - o ponto correspondente foi alcançado.Como terminará a catástrofe italiana?
Vamos transformar nossa visão dos três países na letra "I": Itália, Irã e Espanha. Observando as curvas da morte em uma data específica, vemos que, muito provavelmente, o pico da catástrofe foi passado por lá, e é hora de fazer um balanço.

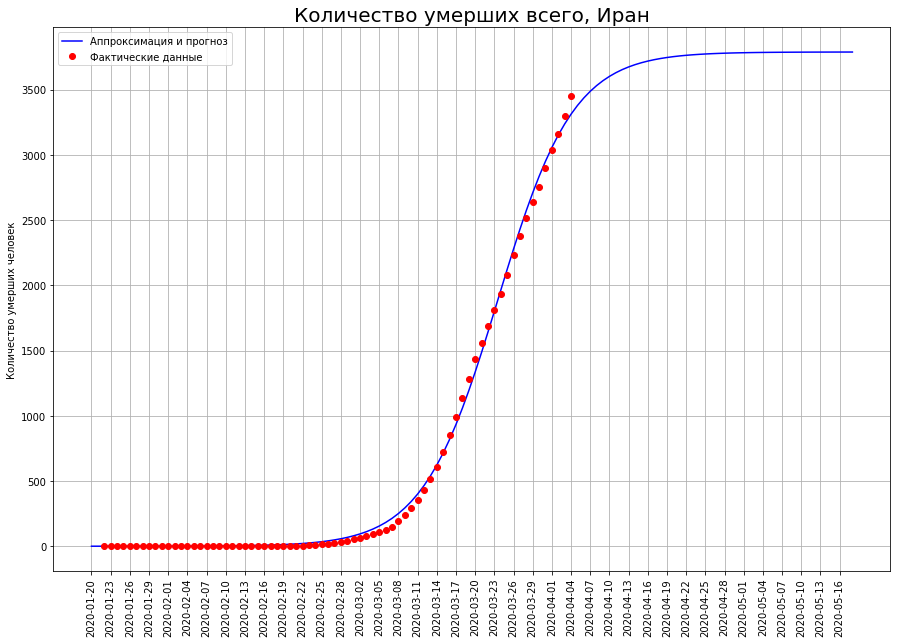
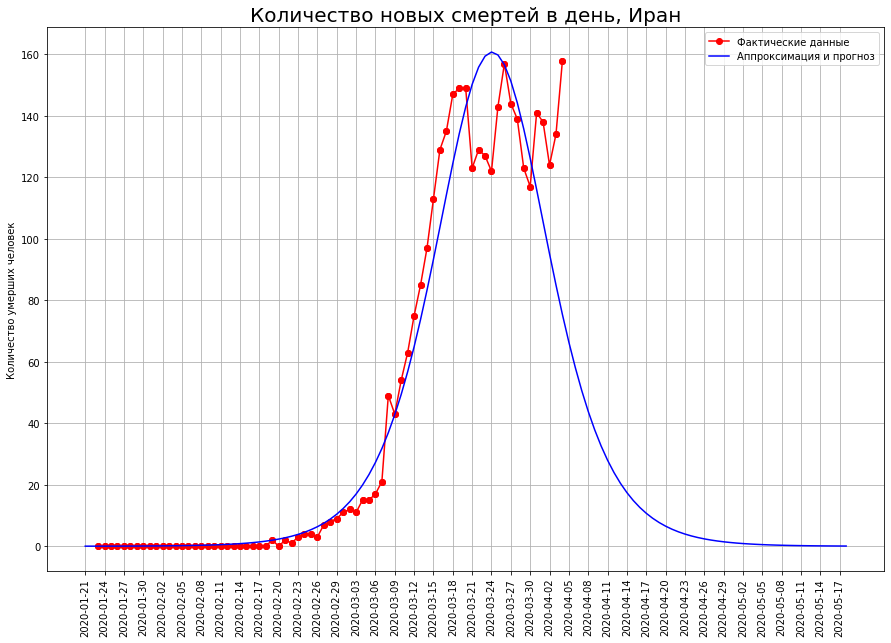
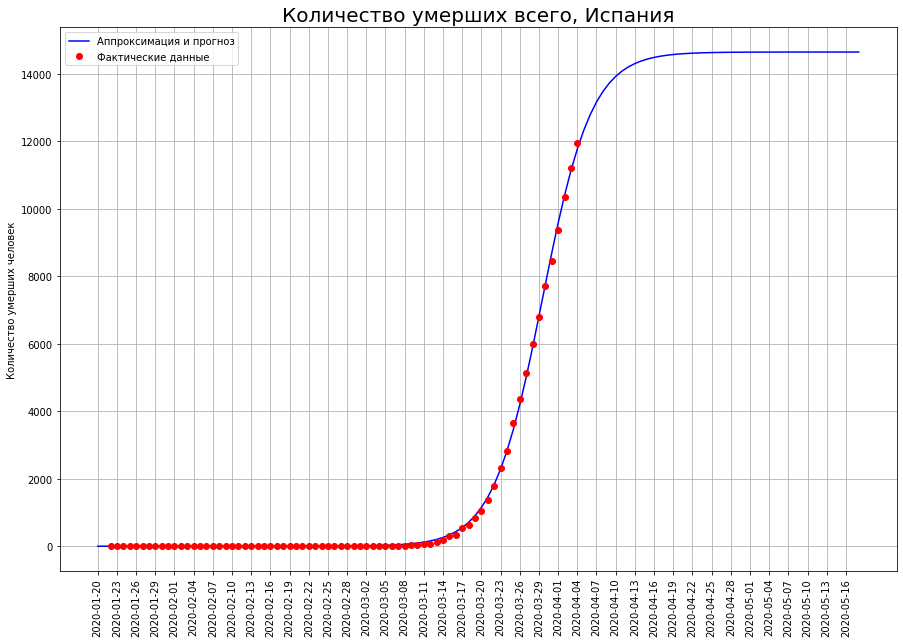
 Segundo nossas previsões, apenas o COVID-19 morrerá:na Itália - cerca de 19 mil pessoas,no Irã - cerca de 4 mil pessoas,na Espanha - cerca de 15 mil pessoas.
Segundo nossas previsões, apenas o COVID-19 morrerá:na Itália - cerca de 19 mil pessoas,no Irã - cerca de 4 mil pessoas,na Espanha - cerca de 15 mil pessoas.A meio caminho da mortalidade final
A epidemia na Alemanha parece ter atingido o seu pico e o número total de mortes por coronavírus neste país será de cerca de 2,6 mil pessoas.
 Em países como Holanda, Suíça e Bélgica, a modelagem matemática mostra que a epidemia está em um ponto de inflexão. Se é assim, então o número esperado de mortes neles:na Holanda - cerca de 2,5 mil pessoas,na Suíça - cerca de 1,1 mil pessoas,na Bélgica - cerca de 2,2 mil pessoas.
Em países como Holanda, Suíça e Bélgica, a modelagem matemática mostra que a epidemia está em um ponto de inflexão. Se é assim, então o número esperado de mortes neles:na Holanda - cerca de 2,5 mil pessoas,na Suíça - cerca de 1,1 mil pessoas,na Bélgica - cerca de 2,2 mil pessoas.



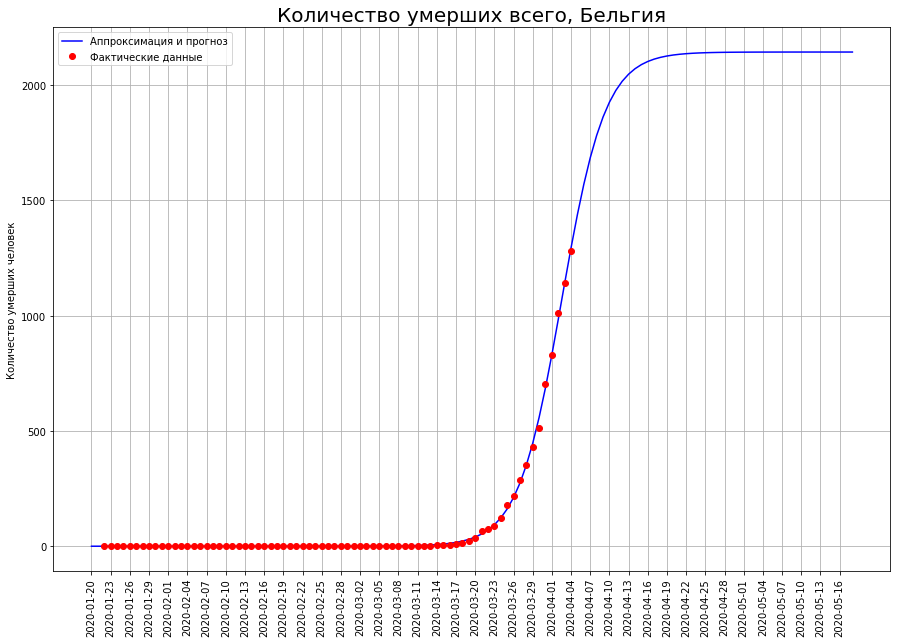
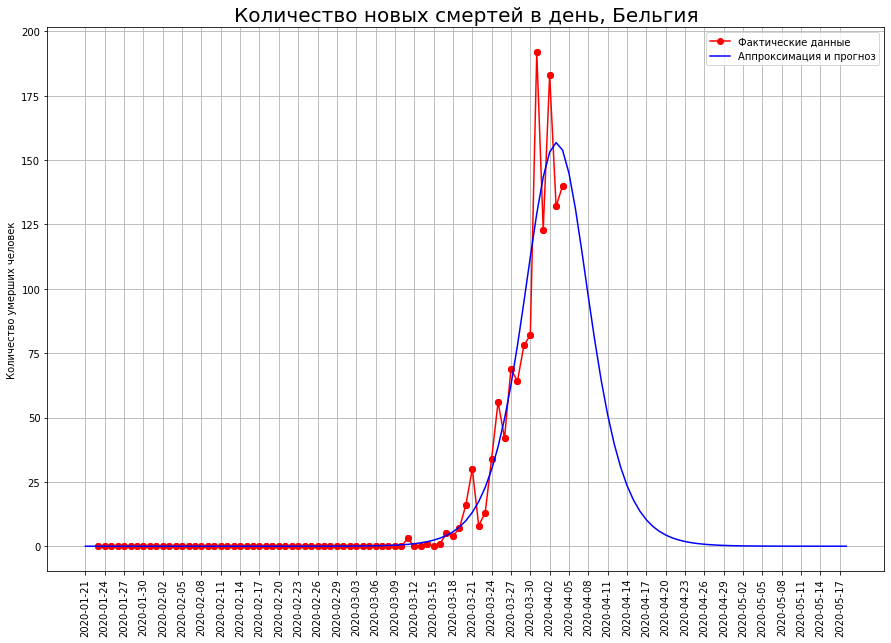
Para alguém, é apenas o começo
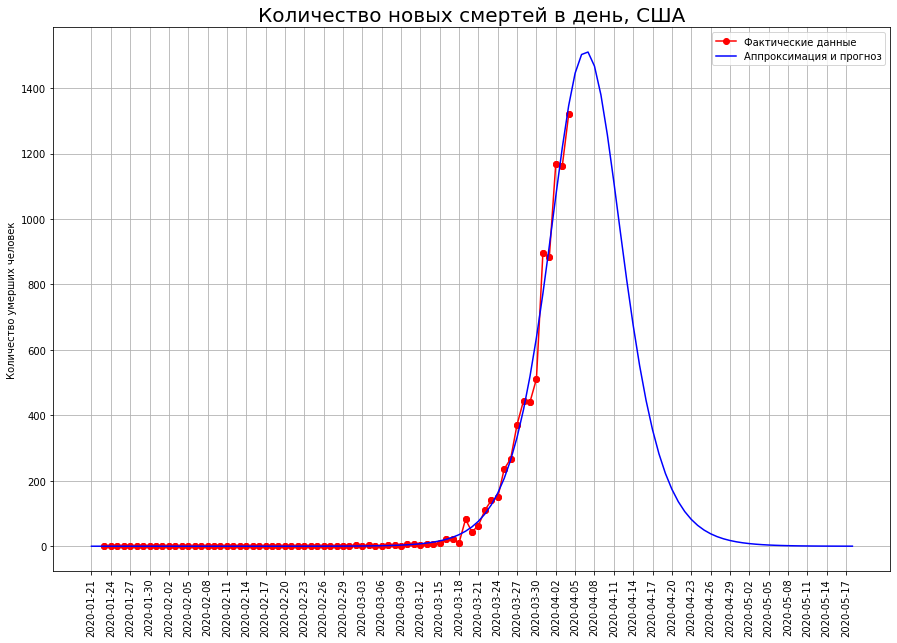
Nos EUA, o ponto de inflexão ainda não foi ultrapassado, portanto a previsão para eles pode ser ajustada significativamente. Atualmente, são 23 mil pessoas.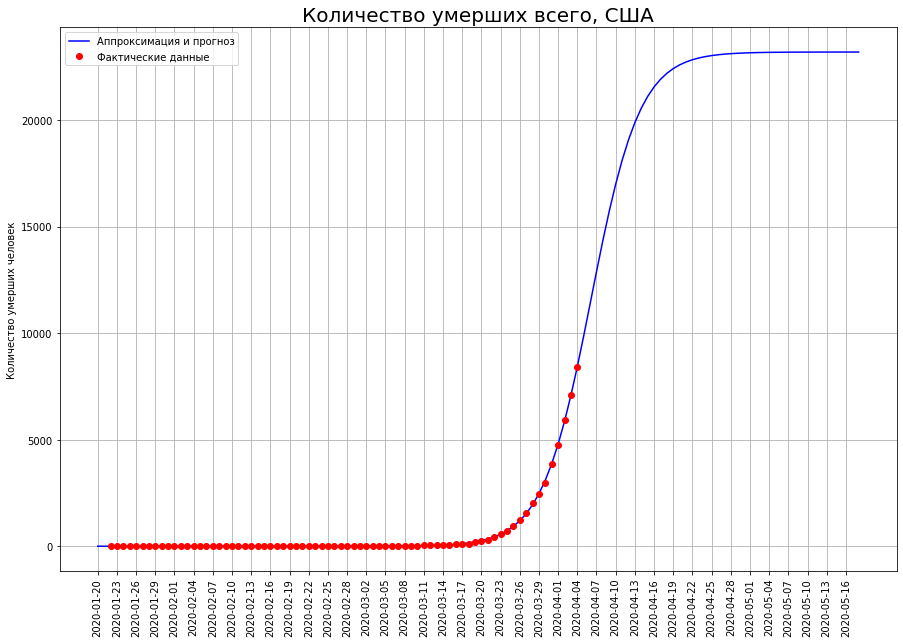
O Reino Unido é um novo epicentro da tragédia?
Por fim, permanece alta a incerteza para os dois países em alcançar o ponto de inflexão. Estes são o Reino Unido e a França.

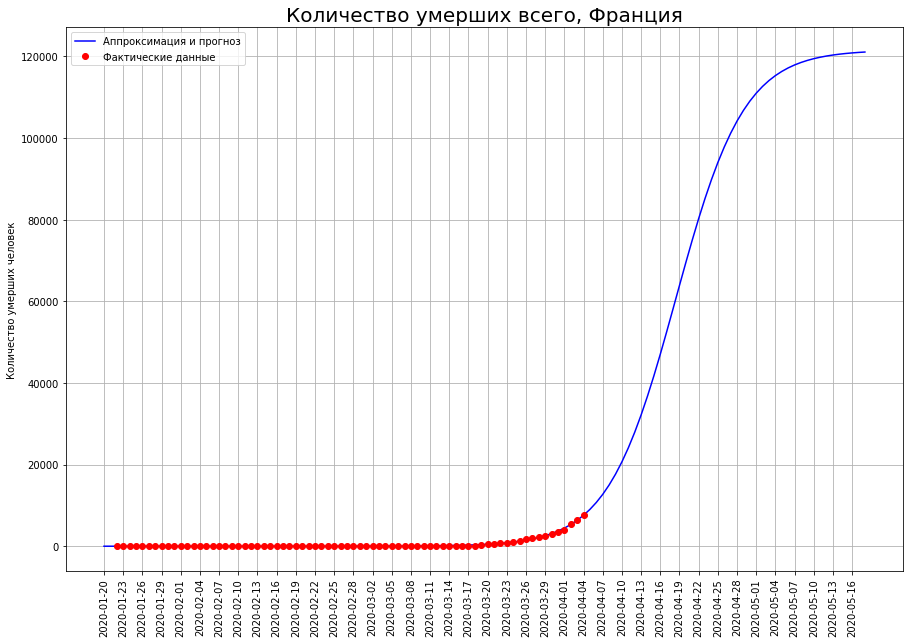
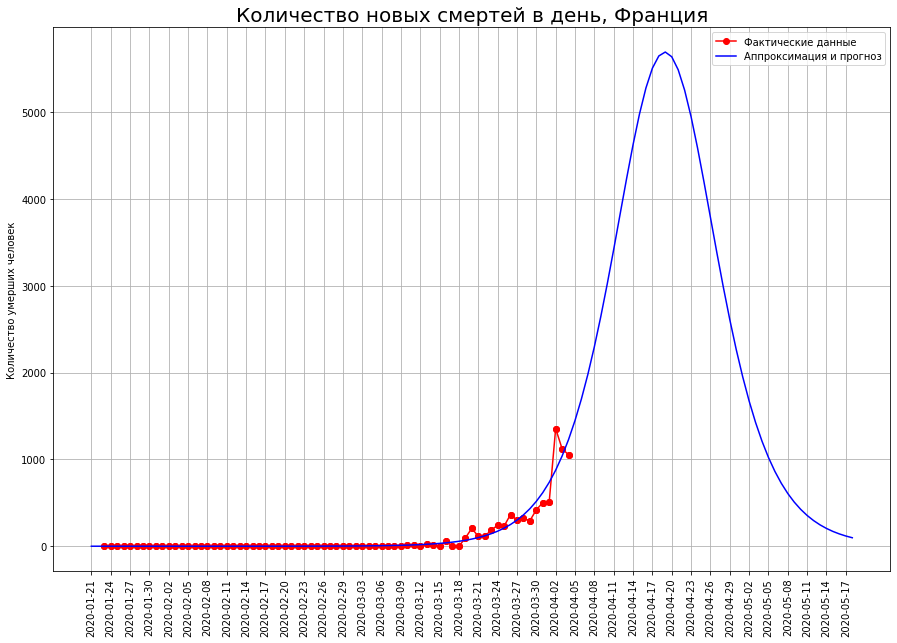 As previsões do número final de mortes sobre eles estão aumentando constantemente. Atualmente, eles incluem:
As previsões do número final de mortes sobre eles estão aumentando constantemente. Atualmente, eles incluem:- no Reino Unido - cerca de 33 mil pessoas
- na França - cerca de 12 mil pessoas.
O autor espera que essas previsões sejam o resultado de flutuações aleatórias e que, nos próximos dias, sejam ajustadas para baixo.De particular preocupação para o autor é o Reino Unido. Segundo dados de 25 de março, o autor previu mortalidade neste país no nível de mil pessoas, segundo dados de 01.04 - no nível de 8 mil, agora a previsão já mostra 33 mil. As previsões para nenhum outro país têm essa volatilidade.Talvez o epicentro da tragédia das mortes por coronavírus esteja gradualmente se movendo para a Grã-Bretanha. Também é possível que o desenvolvimento da situação no país esteja relacionado à política inicialmente irresponsável de Boris Johnson, que até recentemente se recusava a impor restrições estritas e esperava "imunização do rebanho". Nesse caso, o autor espera que os cidadãos, a quem Johnson expressou tão desrespeitosamente, lembrem-se dessa política nas próximas eleições, mas sim - extraordinárias.Previsão para a Rússia
Como a epidemia na Rússia está apenas começando, não será possível prever o número de mortes usando a curva logística. Abaixo, usaremos um método de previsão diferente.E o que em uma escala global?
É hora de fazer uma previsão para o mundo inteiro.
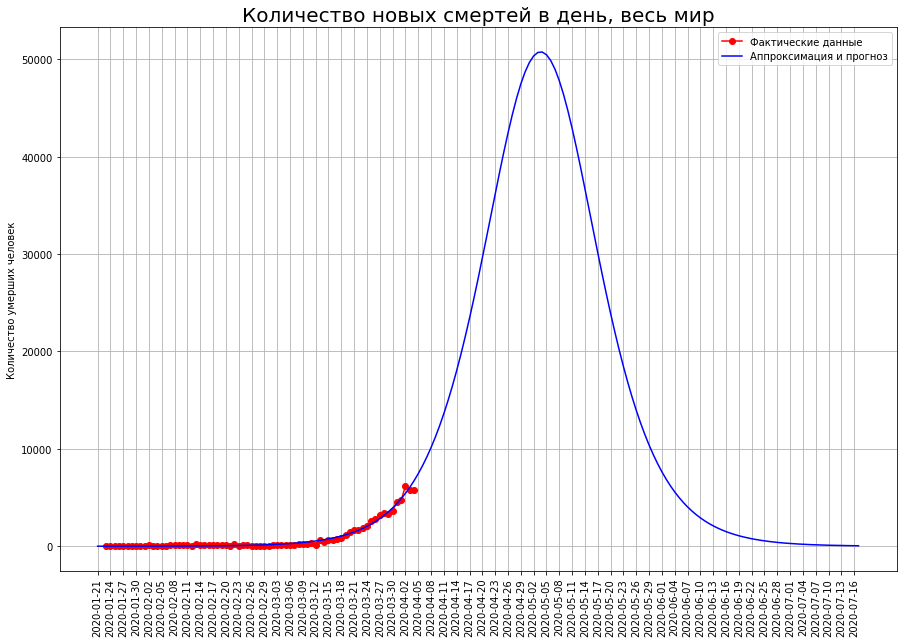 A curva logística que construímos fornece os seguintes resultados: o pico da crise ocorrerá na primeira década de maio, a epidemia terminará em meados de julho. Matará cerca de 1 milhão e 800 mil pessoas.Como a epidemia em escala global está apenas aumentando, uma previsão baseada em uma curva logística pode dar um resultado incorreto, portanto, usaremos um método de previsão alternativo.Considere os países para os quais fizemos previsões.
A curva logística que construímos fornece os seguintes resultados: o pico da crise ocorrerá na primeira década de maio, a epidemia terminará em meados de julho. Matará cerca de 1 milhão e 800 mil pessoas.Como a epidemia em escala global está apenas aumentando, uma previsão baseada em uma curva logística pode dar um resultado incorreto, portanto, usaremos um método de previsão alternativo.Considere os países para os quais fizemos previsões.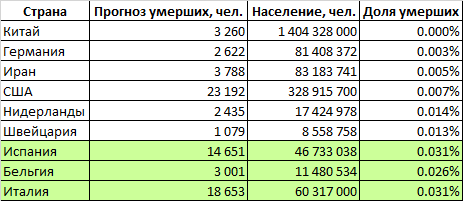 A tabela define a proporção da população desses países que morrerão de coronavírus (a Grã-Bretanha e a França são temporariamente excluídas devido à alta incerteza das previsões). Vemos que os dois grupos de países são significativamente diferentes. Em países como Itália, Espanha e Bélgica, a mortalidade é projetada em 0,029% da população. Em um grupo mais próspero de países (China, Alemanha, Irã, EUA, Holanda e Suíça), a taxa de mortalidade deverá ser de cerca de 0,007% - 4 vezes menor.Pode-se supor que o mundo como um todo será caracterizado por uma maior taxa de mortalidade. O fato é que, em nossa análise, examinamos países relativamente ricos com governos capazes que possuem recursos financeiros e organizacionais para lidar com a epidemia. Mas na Terra existem muitos estados que têm capacidades muito mais modestas, tanto financeira quanto organizacionalmente. Muitos desses países são muito densamente povoados. Pode-se supor que nesses países a epidemia colete uma porcentagem ainda maior de vítimas do que na rica Itália, Espanha e Bélgica. Por outro lado, a proporção da população idosa nesses países é menor, o que reduz a mortalidade potencial.Se estimarmos a mortalidade mundial no nível do pior grupo de países, cerca de 2 milhões e 100 mil pessoas morrerão no mundo. Se você usar valores médios - então cerca de 900 mil.Nossa previsão pessimista para o número de mortes no mundo, calculada com base na parcela da população falecida, foi surpreendentemente próxima da previsão calculada com base na curva logística.Assim, 1-2 milhões de pessoas morrerão no mundo, e o número de 2 milhões é mais provável.
A tabela define a proporção da população desses países que morrerão de coronavírus (a Grã-Bretanha e a França são temporariamente excluídas devido à alta incerteza das previsões). Vemos que os dois grupos de países são significativamente diferentes. Em países como Itália, Espanha e Bélgica, a mortalidade é projetada em 0,029% da população. Em um grupo mais próspero de países (China, Alemanha, Irã, EUA, Holanda e Suíça), a taxa de mortalidade deverá ser de cerca de 0,007% - 4 vezes menor.Pode-se supor que o mundo como um todo será caracterizado por uma maior taxa de mortalidade. O fato é que, em nossa análise, examinamos países relativamente ricos com governos capazes que possuem recursos financeiros e organizacionais para lidar com a epidemia. Mas na Terra existem muitos estados que têm capacidades muito mais modestas, tanto financeira quanto organizacionalmente. Muitos desses países são muito densamente povoados. Pode-se supor que nesses países a epidemia colete uma porcentagem ainda maior de vítimas do que na rica Itália, Espanha e Bélgica. Por outro lado, a proporção da população idosa nesses países é menor, o que reduz a mortalidade potencial.Se estimarmos a mortalidade mundial no nível do pior grupo de países, cerca de 2 milhões e 100 mil pessoas morrerão no mundo. Se você usar valores médios - então cerca de 900 mil.Nossa previsão pessimista para o número de mortes no mundo, calculada com base na parcela da população falecida, foi surpreendentemente próxima da previsão calculada com base na curva logística.Assim, 1-2 milhões de pessoas morrerão no mundo, e o número de 2 milhões é mais provável.O que acontecerá com a pátria e conosco?
Quanto à Rússia, com uma população de 148 milhões de pessoas, a previsão otimista (baseada na média de todos os países, exceto os três principais forasteiros) é de 10 mil pessoas. E pessimista (com base na mortalidade no nível da Itália, Espanha e Bélgica) - 40 mil.A cifra de 10 mil é muito mais provável. O fato é que a Rússia possui vários fatores favoráveis: baixa densidade populacional, grandes distâncias entre grandes cidades, fluxos migratórios relativamente baixos entre as regiões (excluindo a região metropolitana), determinação, adequação e pontualidade das ações das autoridades para combater a epidemia. Esses fatores dão esperança de evitar o desenvolvimento da situação de acordo com a versão italiano-espanhola-belga.Quanto ao momento da conclusão da epidemia na Rússia, passamos ao gráfico abaixo. Nele, descrevemos as curvas logísticas para diferentes países em um gráfico. Nesse caso, normalizamos todas as curvas em altura para que o valor máximo fosse um e combinamos o ponto de inflexão, colocando-o em zero.O gráfico mostra que a epidemia termina em 40 a 60 dias. Se tomarmos o dia 30 de março como ponto de partida, na Rússia a epidemia terá de terminar entre os dias 10 e 30 de maio.As vítimas são justificadas?
E, finalmente, a última pergunta que foi levantada no início do artigo: quão justificadas são as rigorosas medidas de quarentena tomadas pelos governos da maioria dos países do mundo?Cerca de 58 milhões de pessoas morrem todos os anos no mundo. 2 milhões que, de acordo com uma previsão pessimista, morrerão de um coronavírus, aumentarão esse número em 3,5%. Por outro lado, a quarentena mundial em larga escala ameaça se transformar na maior crise econômica desde a Grande Depressão. Como resultado, dezenas ou mesmo centenas de milhões de pessoas permanecerão sem trabalho. A renda da população cairá e muitos morrerão de fome ou incapacidade de pagar pelos cuidados médicos.Muitas vezes são expressas opiniões, inclusive por alguns líderes mundiais, de que seria melhor deixar as pessoas à sua sorte e não arruinar a economia. No final, de 300 a 650 mil pessoas morrem de gripe sazonal todos os anos, mas ninguém toma medidas restritivas tão destrutivas para a economia.Nosso modelo nos permite afirmar o seguinte: O COVID-19 não é uma gripe sazonal. Este vírus é incomparavelmente mais perigoso. O fato é que o ponto de inflexão da curva logística não existe por si só. É muito afetado pelas condições da epidemia. O curso de qualquer epidemia é descrito por uma curva logística, mas as curvas logísticas são uma família inteira. Lembramos que o ponto de inflexão é exatamente metade da curva máxima. Portanto, quanto mais tarde o pico de mortalidade for ultrapassado, maior será o número final de mortes. Vimos que, perto do ponto de inflexão, a curva logística cresce o mais rápido possível. Portanto, se o pico da doença for passado 10 dias depois, o número de vítimas poderá aumentar várias vezes!As previsões que recebemos para os pontos de inflexão das curvas logísticas já incluem todas as medidas de quarentena tomadas pelos governos dos países do mundo. Se não houvesse tais medidas, os pontos de inflexão foram alcançados muito mais tarde. Nesse caso, a mortalidade pode atingir o nível de 0,4-0,5% de toda a população mundial.Por que estimamos a taxa de mortalidade de uma epidemia não controlada em 0,4-0,5% da população. Assumimos que, neste caso, de uma forma ou de outra, toda a população da Terra esteja doente com o vírus. No entanto, em um número significativo de pessoas, a doença será assintomática. Portanto, usamos estatísticas de países como Coréia do Sul e Alemanha, que conseguiram organizar o teste mais amplo possível da população para coronavírus e identificar a maioria dos casos reais. Em outros países, em nossa opinião, as estatísticas são distorcidas precisamente porque o número de casos é muito subestimado. Daí a super alta taxa de mortalidade de 3,5%.0,4-0,5% da população mundial é de 28 a 35 milhões de pessoas. Para todas as guerras que a humanidade travou em toda a sua história, apenas o número de perdas na Segunda Guerra Mundial excede esse número. O fato de os governos da grande maioria dos países do mundo fazerem sacrifícios econômicos sem precedentes em prol da salvação de pessoas mostra quanto o preço da vida humana aumentou no mundo. Quão difundidas as idéias do humanismo e a prioridade dos interesses do indivíduo. E isso inspira o autor com orgulho na humanidade e na esperança de um futuro melhor para toda a humanidade.A maior desvantagem deste artigo
E aqui está a maior desvantagem deste artigo. Infelizmente, as estatísticas clássicas não nos fornecem ferramentas para estimar erros de previsão com base em uma função logística. Isso ocorre devido à forma da função, que possui uma inflexão. Se essa inflexão não fosse e a curva fosse monotônica, nós, com a ajuda da transformação de Box-Cox, traríamos primeiro a função para uma forma linear. Depois disso, usando a equação de erro para regressão linear, construiríamos o limite superior e inferior dos erros e, usando a transformação inversa de Box-Cox, obteríamos limites de erro curvilíneos, com base nos quais construiríamos a previsão máxima e mínima para o número de mortes por coronavírus.Infelizmente, as ferramentas da estatística clássica tornam impossível construir limites de erro no caso de uma curva com uma inflexão. Mas os métodos de aprendizado de máquina podem vir em nosso auxílio. No próximo artigo, mostrarei como os limites dos erros são construídos nesse caso e elaborarei as previsões mínimas e máximas do número de mortes para cada país considerado acima separadamente e para o mundo inteiro.E agora muitos códigos e números
Bem, agora, de fato, matemática para quem quer entender como chegamos às conclusões mencionadas acima. Aqueles que não estão interessados em cálculos chatos não podem ler mais.Os cálculos foram feitos em Python no ambiente Jupiter usando bibliotecas adicionais scipy, numpy, pandas, data e hora. Para visualização, usamos o pacote matplotlib.pyplot. Os dados iniciais sobre o número de óbitos foram obtidos nesse link e pré-processados no Excel. Informações obtidas em 4 de abril. Aqui está um link para o arquivo com as informações de origem .Então, importamos as bibliotecas, que usaremos posteriormente:import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import pandas as pd
from IPython.display import display
import scipy as sp
from datetime import datetime
from scipy.optimize import minimize
Lemos os dados de origem e os convertemos em um objeto DataFrame. Os rótulos das variáveis são convertidos em um objeto Timestamp. Em princípio, poderíamos nos restringir a matrizes numpy simples, mas usamos um DataFrame para a conveniência de armazenar dados com a data correspondente e o Timestamp para visualização, para exibir essas datas nos gráficos.corona = pd.read_csv ('D: /coronavirus.csv',sep= ";")
corona.set_index (' Data ', local = True)
corona.index = pd.to_datetime (corona.index)
Em seguida, a partir de um único DataFrame, criamos variáveis do tipo Série que correspondem à mortalidade total em cada país. X é uma variável igual ao número do dia desde o início do ano. Nós precisaremos disso na previsão.X = corona['X']
chi = corona['China']
fr = corona['France']
ir = corona['Iran']
it = corona['Italy']
sp = corona['Spain']
uk = corona['UK']
us = corona['US']
bg = corona['Belgium']
gm = corona['Germany']
nt = corona['Netherlands']
sw = corona['Switzerland']
tot = corona['Total']
Depois disso, calculamos matrizes numpy simples para mortalidade em uma data específica. Observe que o comprimento dessa matriz é 1 menor que o comprimento da variável Series correspondente.dchi = chi[1:].values - chi[:-1].values
dfr = fr[1:].values - fr[:-1].values
dit = it[1:].values - it[:-1].values
diran = ir[1:].values - ir[:-1].values
dsp = sp[1:].values - sp[:-1].values
duk = uk[1:].values - uk[:-1].values
dus = us[1:].values - us[:-1].values
dbg = bg[1:].values - bg[:-1].values
dgm = gm[1:].values - gm[:-1].values
dnt = nt[1:].values - nt[:-1].values
dsw = sw[1:].values - sw[:-1].values
dtot = tot[1:].values - tot[:-1].values
Introduzimos uma variável adicional para previsão. Essa é uma matriz que começa em 20 de janeiro e termina em 180 dias em 17 de julho. Também criamos um objeto Timestamp correspondente a essa matriz para assinar os eixos.X_long = np.arange(20, 200)
time_long = pd.date_range('2020-01-20', periods=180)
Definimos a função resLogistic, cujo argumento de entrada é uma matriz de 3 dígitos e a saída é a soma dos quadrados da diferença entre os valores da curva logística e o número real de mortes pela epidemia na China.def resLogistic(coefficents):
A0 = coefficents[0]
A1 = coefficents[1]
A2 = coefficents[2]
teor = A0 / (1 + np.exp(A1 * (X.ravel() - A2)))
return np.sum((teor - chi) ** 2)
O número de mortes é calculado em cada data como um total acumulado. A curva logística é determinada por 3 componentes do vetor de entrada. Zero (a contagem de elementos da matriz em Python começa a partir de zero) do componente é responsável pelo valor máximo, o primeiro caracteriza a taxa de crescimento da função, o segundo - a posição do ponto de inflexão no eixo do tempo.teor - o número de mortes para cada dia, com base no vetor de parâmetro de entrada, chi - o número real de mortes na China. A função retorna a soma das diferenças quadráticas entre o valor teórico e o real.Agora, usando o método minimize da biblioteca scipy.optimize, encontramos um vetor que minimiza a soma dos desvios ao quadrado. A curva logística construída com base nesse vetor é a previsão de mortalidade desejada, feita com base no método dos quadrados mínimos.Acrescentamos que o método minimize requer um ponto de partida. Nós o selecionamos com base nas propriedades da função logística conhecidas por nós (o máximo deve ser maior que qualquer número empírico de mortes e o ponto de inflexão deve estar próximo do máximo da curva dtot que caracteriza o número de novas mortes por dia). Geralmente, os resultados do método minimize são independentes do ponto de partida, mas há exceções.mimim.x são os valores do vetor minimizador.minim = minimize(resLogistic, [3200, -.16, 46])
minim.x
Agora, exibimos no gráfico o número real de mortes, aproximando sua curva de previsão logística, e também assinamos o eixo do tempo com datas.plt.figure(figsize=(15,10))
teorChi = minim.x[0] / (1 + np.exp(minim.x[1] * (X_long - minim.x[2])))
plt.plot(X,chi,'ro', label=' ')
plt.plot(X_long[:80], teorChi[:80],'b', label=' ')
plt.xticks(X_long[:80][::2], time_long.date[:80][::2], rotation='90');
plt.title(' , ', Size=20);
plt.ylabel(' ')
plt.legend()
plt.grid()
No gráfico inferior, plotamos a primeira derivada da curva logística selecionada acima (linha azul), bem como a curva real de novas mortes (linha vermelha).plt.figure(figsize = (15,10))
plt.grid()
plt.title(' , ', Size=20);
plt.plot(X[1:], dchi, 'r', Marker='o', label=' ')
plt.xticks(X_long[1:120][::3], time_long.date[1:120][::3], rotation='90');
plt.plot(X_long[1:120], teorChi[1:120] - teorChi[:119],'b', label=' ')
plt.ylabel(' ')
plt.legend()
Realizamos cálculos semelhantes para cada um dos países mencionados no artigo.Então o autor escreveu um código não muito bonito. Era necessário escrever uma função para todos os países e passar o número de mortes reais para ela através dos parâmetros do método minimize. Mas o autor não teve tempo para lidar com esse mecanismo, por isso escreveu sua própria função para cada país e, dentro da função, apelou para uma variável que continha informações sobre o número de mortes em um determinado país.Abaixo estão os cálculos para o Irã, Itália, Espanha, EUA. Para restaurar os cálculos para outros países, acho que os leitores não serão difíceis.def resLogisticIr(coefficents):
A0 = coefficents[0]
A1 = coefficents[1]
A2 = coefficents[2]
teor = A0 / (1 + np.exp(A1 * (X.ravel() - A2)))
return np.sum((teor - ir) ** 2)
minim = minimize(resLogisticIr, [3200, -.16, 80])
minim.x
plt.figure(figsize=(15,10))
teorIr = minim.x[0] / (1 + np.exp(minim.x[1] * (X_long - minim.x[2])))
plt.plot(X_long[:120], teorIr[:120],'b', label=' ')
plt.xticks(X_long[:120][::3], time_long.date[:120][::3], rotation='90');
plt.title(' , ', Size=20);
plt.plot(X,ir,'ro', label=' ')
plt.grid()
plt.legend()
plt.ylabel(' ')
plt.figure(figsize = (15,10))
plt.grid()
plt.title(' , ', Size=20);
plt.plot(X[1:], diran, 'r', Marker='o', label=' ')
plt.plot(X[1:], diran, 'ro')
plt.xticks(X_long[1:120][::3], time_long.date[1:120][::3], rotation='90');
plt.plot(X_long[1:120], teorIr[1:120] - teorIr[:119],'b', label=' ')
plt.ylabel(' ')
plt.legend()
def resLogisticIt(coefficents):
A0 = coefficents[0]
A1 = coefficents[1]
A2 = coefficents[2]
teor = A0 / (1 + np.exp(A1 * (X.ravel() - A2)))
return np.sum((teor - it) ** 2)
minim = minimize(resLogisticIt, [3200, -.16, 46])
minim.x
plt.figure(figsize=(15,10))
teorIt = minim.x[0] / (1 + np.exp(minim.x[1] * (X_long - minim.x[2])))
plt.plot(X,it,'ro', label=' ')
plt.plot(X_long[:120], teorIt[:120],'b', label=' ')
plt.xticks(X_long[:120][::3], time_long.date[:120][::3], rotation='90');
plt.title(' , ', Size=20);
plt.ylabel(' ')
plt.grid()
plt.legend()
plt.figure(figsize = (15,10))
plt.grid()
plt.title(' , ', Size=20);
plt.plot(X[1:], dit, 'r', Marker='o', label=' ')
plt.xticks(X_long[1:120][::3], time_long.date[1:120][::3], rotation='90');
plt.plot(X_long[1:120], teorIt[1:120] - teorIt[:119],'b', label=' ')
plt.ylabel(' ')
plt.legend()
def resLogisticSp(coefficents):
A0 = coefficents[0]
A1 = coefficents[1]
A2 = coefficents[2]
teor = A0 / (1 + np.exp(A1 * (X.ravel() - A2)))
return np.sum((teor - sp) ** 2)
minim = minimize(resLogisticSp, [3200, -.16, 80])
minim.x
plt.figure(figsize=(15,10))
teorSp = minim.x[0] / (1 + np.exp(minim.x[1] * (X_long - minim.x[2])))
plt.plot(X_long[:120], teorSp[:120],'b', label=' ')
plt.xticks(X_long[:120][::3], time_long.date[:120][::3], rotation='90');
plt.title(' , ', Size=20);
plt.plot(X,sp,'ro', label=' ')
plt.grid()
plt.legend()
plt.ylabel(' ')
plt.figure(figsize = (15,10))
plt.grid()
plt.plot(X[1:], dsp, 'r', Marker='o', label=' ')
plt.plot(X[1:], dsp, 'ro')
plt.xticks(X_long[1:120][::3], time_long.date[1:120][::3], rotation='90');
plt.title(' , ', Size=20);
plt.plot(X_long[1:120], teorSp[1:120] - teorSp[:119],'b', label=' ')
plt.ylabel(' ')
plt.legend()
def resLogisticUs(coefficents):
A0 = coefficents[0]
A1 = coefficents[1]
A2 = coefficents[2]
teor = A0 / (1 + np.exp(A1 * (X.ravel() - A2)))
return np.sum((teor - us) ** 2)
minim = minimize(resLogisticUs, [3200, -.16, 100])
minim.x
plt.figure(figsize=(15,10))
teorUS = minim.x[0] / (1 + np.exp(minim.x[1] * (X_long - minim.x[2])))
plt.plot(X_long[:120], teorUS[:120],'b', label=' ')
plt.xticks(X_long[:120][::3], time_long.date[:120][::3], rotation='90');
plt.title(' , ', Size=20);
plt.plot(X,us,'ro', label=' ')
plt.grid()
plt.legend()
plt.ylabel(' ')
plt.figure(figsize = (15,10))
plt.grid()
plt.title(' , ', Size=20);
plt.plot(X[1:], dus, 'r', Marker='o', label=' ')
plt.plot(X[1:], dus, 'ro')
plt.xticks(X_long[1:120][::3], time_long.date[1:120][::3], rotation='90');
plt.plot(X_long[1:120], teorUS[1:120] - teorUS[:119],'b', label=' ')
plt.ylabel(' ')
plt.legend()