Muitas vezes, nos meus 15 anos de experiência como desenvolvedor de software e líder de equipe, me deparo com a mesma coisa. A programação se transforma em religião - raramente alguém tenta introduzir tecnologia com base em uma escolha razoável, razoavelmente, levando em consideração restrições, portabilidade, avaliando o grau de vinculação ao fornecedor, o preço real, as perspectivas da tecnologia e a liberdade de licenças. Os desenvolvedores vão a conferências ou leem posts - iniciam o hype, e seus diretores e gerentes de TI são alimentados não apenas com histórias de um futuro ágil brilhante em eventos, vários visionários, vendas e consultores. E acontece que as tecnologias estavam no projeto, não levando em consideração a conveniência do desenvolvimento e implementação, requisitos não funcionais do projeto, mas porque é exagero e o Google se usa,a amazon recomenda (embora suas vagas digam que elas próprias não o usam com frequência) ou a mais alta decisão foi tomada pela gerência da empresa para implementar "isso".
O que afeta a escolha do banco de dados
Do meu ponto de vista, ao escolher um banco de dados, tenho que resolver pelo menos as seguintes compensações:- processamento de transações em tempo real ou processamento analítico online
- escalável vertical ou horizontalmente
- no caso de uma base distribuída - consistência / disponibilidade / resistência à separação dos dados (teorema da PAC)
- um esquema de dados específico e restrições no banco de dados ou armazenamento que não requer um esquema de dados
- modelo de dados - valor-chave, hierárquico, gráfico, documento ou relacional
- lógica de processamento o mais próximo possível dos dados ou todo o processamento no aplicativo
- funciona principalmente em RAM ou com um subsistema de disco
- solução universal ou especializada
- usamos a experiência existente em um banco de dados que não é particularmente adequado para os requisitos do projeto ou desenvolvemos um novo em treinamento adequado, mas não familiar, “sangue e suor” (o mesmo se aplica não apenas ao desenvolvimento, mas também à operação)
- embutido ou em outro processo / rede
- hipster ou retrógrado
Muitas vezes, recebemos um "presente" para a solução implementada:- Linguagem de consulta "alienígena"
- a única API nativa para trabalhar com o banco de dados, o que complicará a transição para outros bancos de dados (tempo, esforço da equipe e orçamento do projeto)
- indisponibilidade de drivers para outras plataformas / idiomas / sistemas operacionais
- falta de códigos-fonte, descrições do formato dos dados no disco (ou proibição de licenças de engenharia reversa, especialmente Oracle com o bhery Coherence)
- crescimento do custo da licença ano a ano
- ecossistema próprio e dificuldade em encontrar especialistas
- , ,
A escala horizontal dos sistemas é bastante complexa e requer conhecimento da equipe. Desenvolvedores experientes são muito caros no mercado, aplicativos distribuídos são mais difíceis de desenvolver, depurar e testar. Portanto, se é possível alterar o servidor para um servidor mais poderoso e a quantidade de dados que o sistema permite, eles geralmente o fazem. Agora, os servidores podem ter terabytes de RAM e centenas de núcleos de processador. Portanto, como nunca antes, torna-se importante maximizar o uso de todos os recursos do servidor. O custo das licenças de banco de dados também é importante e, se forem vendidas por núcleos de processador, o orçamento operacional, mesmo com escala vertical, pode custar tanto quanto um programa espacial de superpotência. Portanto, é importante manter isso em mente, para não conseguir dimensionar o desempenho do banco de dados devido às licenças.É claro que, com a ajuda do marketing, eles tentarão convencê-lo de que apenas a solução de uma determinada empresa resolverá todos os seus problemas (mas eles ficam calados sobre quantos novos aparecerão). Não existe um banco de dados ideal para todos os gostos e adequado para tudo.Portanto, no futuro previsível, ainda ofereceremos suporte a vários bancos de dados diferentes para processar os mesmos dados para diferentes tipos de consultas em diferentes sistemas. Sem soluções para o Data Fabric sem armazenamento em cache de dados, o Data Lake ainda não pode ser comparado com bancos de dados com arquitetura paralela em massa em termos de desempenho e otimização da consulta. Os dados transacionais ainda serão armazenados no PostgreSQL, Oracle, MS Sql Server, consultas analíticas no Citus, Greenplum, Snowflake, Redshift, Vertica, Impala, Teradata e swamps de dados brutos no HDFS / S3 / ADLS (Azure) serão gerenciados pelo Dremio , Redshift Spectrum, Apache Spark, Presto.Mas as soluções listadas acima são pouco adequadas para analisar dados de séries temporais com um tempo de resposta baixo. De acordo com sua popularidade no trabalho com dados de séries temporais, agora está nos favoritos do InfluxDB. No nicho do banco de dados na memória, o kdb + e o memSQL mantêm seus lugares.QuestDB
O que pode se opor a todas essas soluções QuestDB de código aberto com uma licença Apache?- Uma tentativa de tirar o máximo proveito do hardware para realizar consultas analíticas - vetorização de funções de agregação, trabalhando com dados através de arquivos mapeados na memória
- SQL como o idioma das consultas DML e operações DDL para gerenciar a estrutura do banco de dados
- suporte para tabelas de junção específicas ao banco de dados de séries temporais
- suporte para funções de janela e agregação em SQL
- a capacidade de incorporar um banco de dados em um aplicativo na JVM
- JVM, ServiceLoader
- Influx DB line protocol (ILP) UDP Telegraf. «What makes QuestDB faster than InfluxDB»
- PostgreSql 11 PostgreSQL: JDBC, ODBC psql
- web - REST endpoint , SQL json
- ,
- zero-GC API, .
- ( )
- 64 Windows, Linux, OSX, ARM Linux FreeBSD
- , open source,
Quando esse banco de dados pode ser útil para você - se você estiver desenvolvendo sistemas financeiros na JVM com uma baixa latência e precisar de uma solução para análise de dados na RAM. Como substituto do kdb + devido ao custo das licenças. Se você coletar métricas de acordo com o protocolo Influx / Telegraf, mas o desempenho e a usabilidade de trabalhar com o InfluxDB não serão satisfatórios. Se o seu projeto estiver em execução na JVM e você precisar de um banco de dados interno para armazenar métricas ou dados de aplicativos adicionados apenas e não atualizados.A nova versão 4.2.0, com suporte para instruções SIMD, causou uma onda de comentários no Reddit . Para que os fãs participem da competição de conhecimento de hardware moderno e sua programação efetiva, recomendo conversar com o autor do banco de dados (bluestreak01) nos comentários!Operações SIMD
A equipe do projeto realizou um teste em dados sintéticos e comparou o QuestDB 4.2.0 com o kdb 4.0 para agregar um bilhão de valores, aproveitando as instruções SIMD dos processadores.Na plataforma Intel 8850H: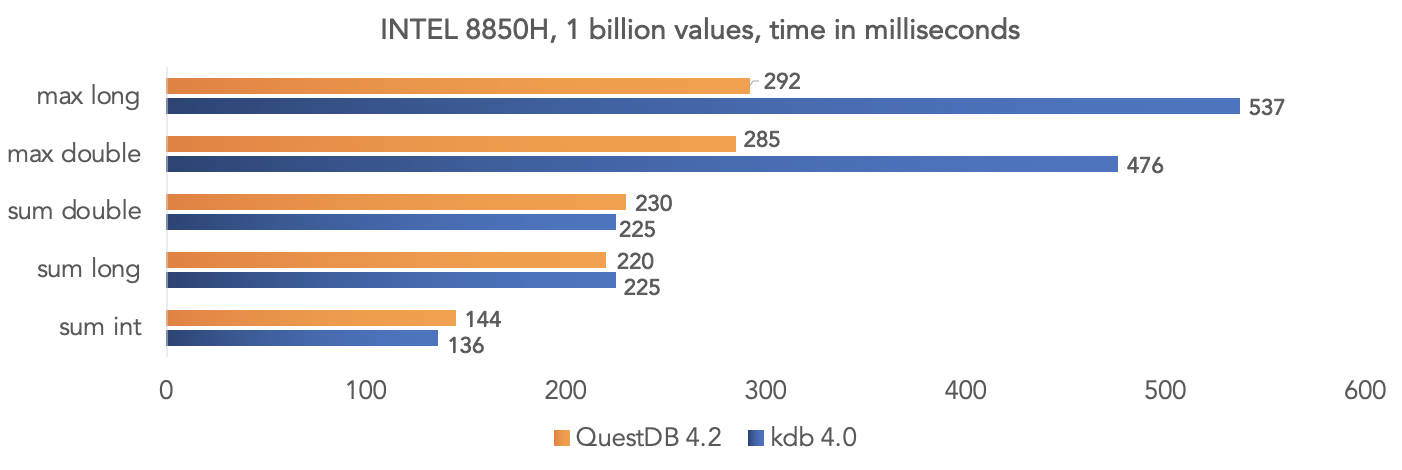 Na plataforma AMD Ryzen 3900X:
Na plataforma AMD Ryzen 3900X: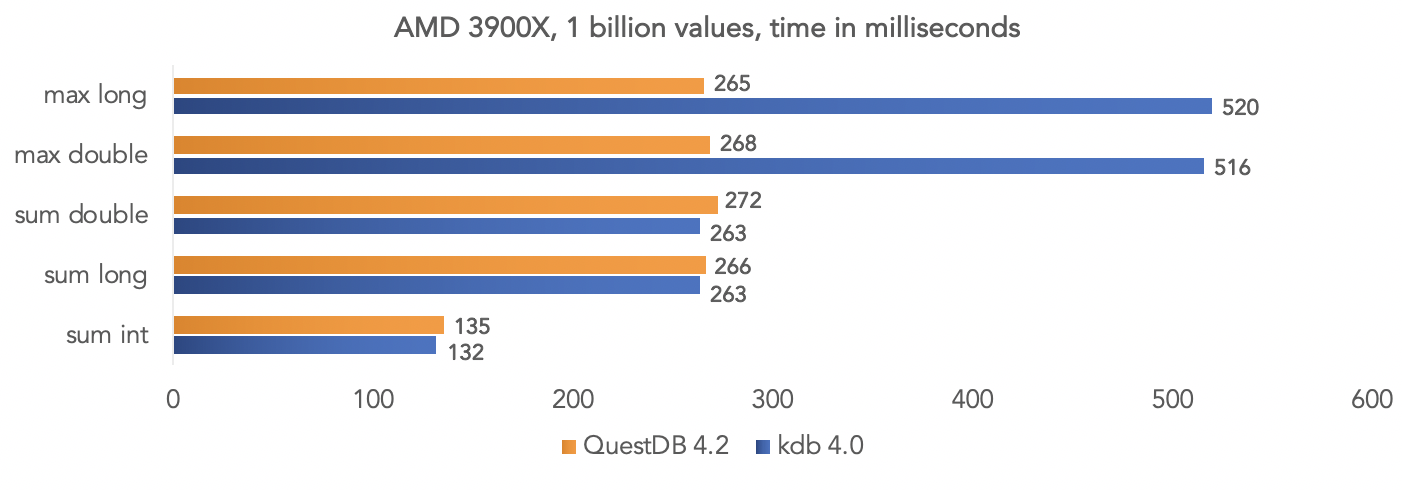 é claro que todos são testes no vácuo, mas você pode comparar seus dados se o seu projeto usa kdb e compartilhar os resultados com a comunidade.
é claro que todos são testes no vácuo, mas você pode comparar seus dados se o seu projeto usa kdb e compartilhar os resultados com a comunidade.Executando a imagem do banco de dados do Docker
O banco de dados é publicado no dockerhub a cada versão. Mais detalhes são descritos na documentação do projeto .Obtenha a imagem do QuestDB:docker pull questdb/questdb
Lançamos:docker run --rm -it -p 9000:9000 -p 8812:8812 questdb/questdb
Depois disso, você pode se conectar usando o protocolo PostgreSQL à porta 8812, o console da Web estará disponível na porta 9000.Acesso Jdbc
Dependendo do nosso projeto, adicionamos o driver jdbc do PostrgreSQL org.postgresql: postgresql: 42.2.12 . Para esse teste, uso o módulo QuestDB para contêineres de teste . O teste está disponível no github junto com o script de construção:import org.junit.jupiter.api.Test;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
import static org.assertj.core.api.Assertions.*;
public class QuestDbDriverTest {
@Test
void containerIsUpTestByJdbcInvocation() throws Exception {
try (Connection connection = DriverManager.getConnection("jdbc:tc:questdb:///?user=admin&password=quest")){
try (Statement statement = connection.createStatement()){
try (ResultSet resultSet = statement.executeQuery("select 42 from long_sequence(1)")){
resultSet.next();
assertThat(resultSet.getInt(1)).isEqualTo(42);
}
}
}
}
}
A execução do docker gera sobrecarga adicional, e isso pode ser evitado simplesmente implementando org.questdb: core: jar: 4.2.0 como uma dependência do projeto e executando io.questdb.ServerMain:import io.questdb.ServerMain;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.io.TempDir;
import java.nio.file.Path;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.Statement;
public class QuestDbJdbcTest {
@Test
void embeddedServerStartTest(@TempDir Path tempDir) throws Exception{
ServerMain.main(new String[]{"-d", tempDir.toString()});
try (DriverManager.getConnection("jdbc:postgresql://localhost:8812/", "admin", "quest")){
try (Statement statement = connection.createStatement()){
try (ResultSet resultSet = statement.executeQuery("select 42 from long_sequence(1)")){
resultSet.next();
assertThat(resultSet.getInt(1)).isEqualTo(42);
}
}
}
}
}
Incorporando no aplicativo java
Mas esta é a maneira mais rápida de trabalhar com o banco de dados usando a API java em processo:import io.questdb.cairo.CairoEngine;
import io.questdb.cairo.DefaultCairoConfiguration;
import io.questdb.griffin.CompiledQuery;
import io.questdb.griffin.SqlCompiler;
import io.questdb.griffin.SqlExecutionContextImpl;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.io.TempDir;
import java.nio.file.Path;
public class TruncateExecuteTest {
@Test
void truncate(@TempDir Path tempDir) throws Exception{
SqlExecutionContextImpl executionContext = new SqlExecutionContextImpl();
DefaultCairoConfiguration configuration = new DefaultCairoConfiguration(tempDir.toAbsolutePath().toString());
try (CairoEngine engine = new CairoEngine(configuration)) {
try (SqlCompiler compiler = new SqlCompiler(engine)) {
CompiledQuery createTable = compiler.compile("create table tr_table(id long,name string)", executionContext);
compiler.compile("truncate table tr_table", executionContext);
}
}
}
}
Console da Web
O projeto inclui um console da web para consultar o QuestDB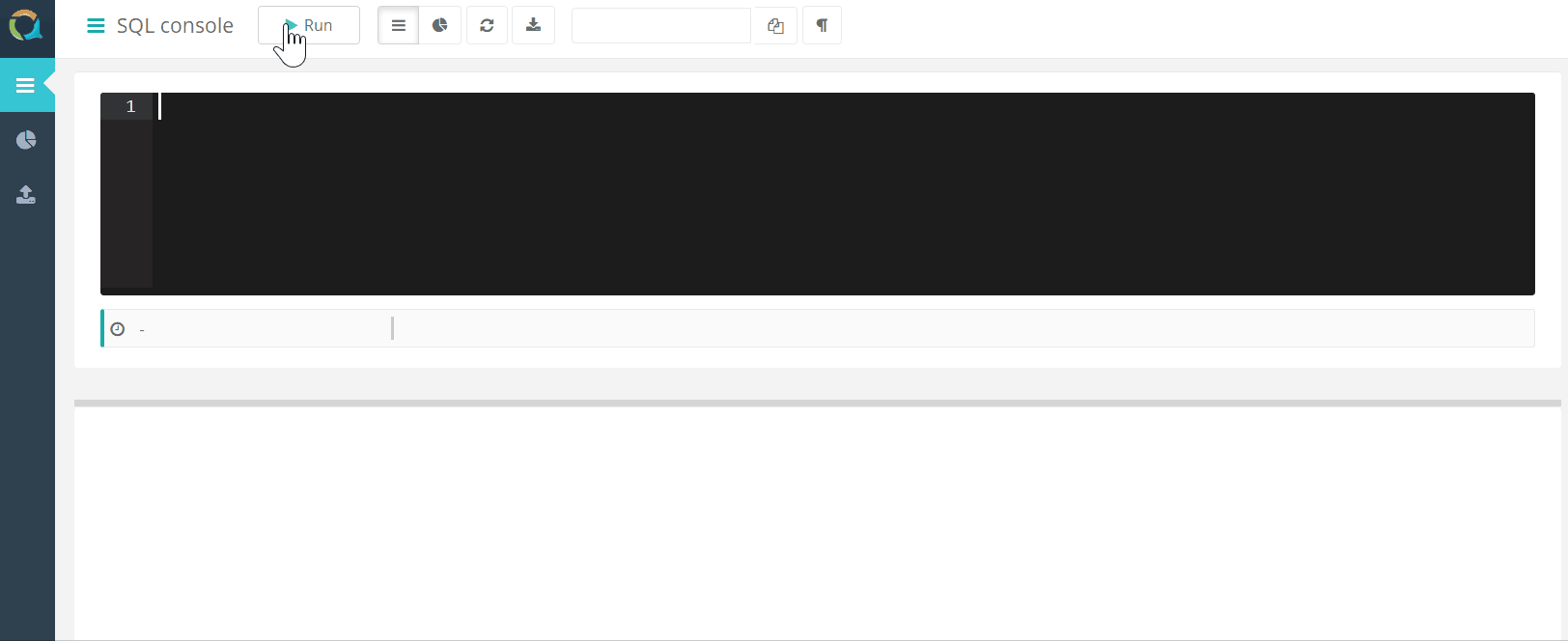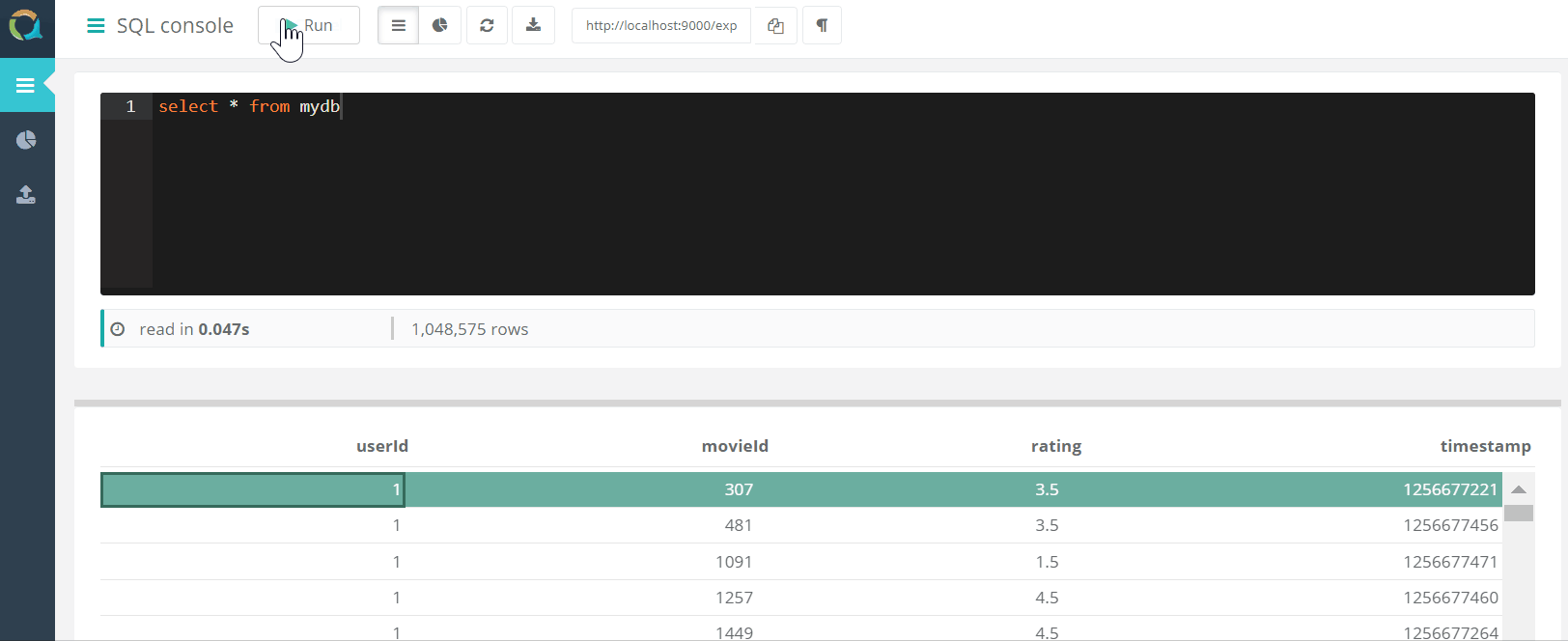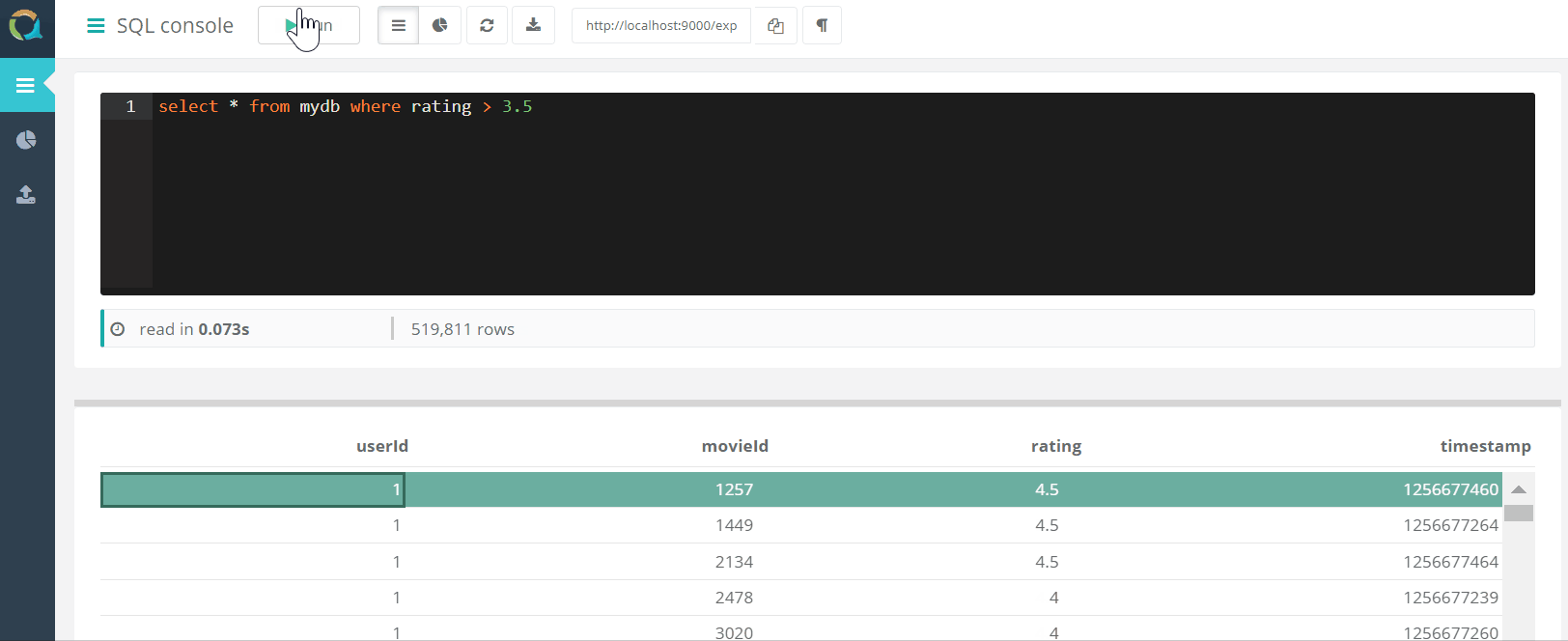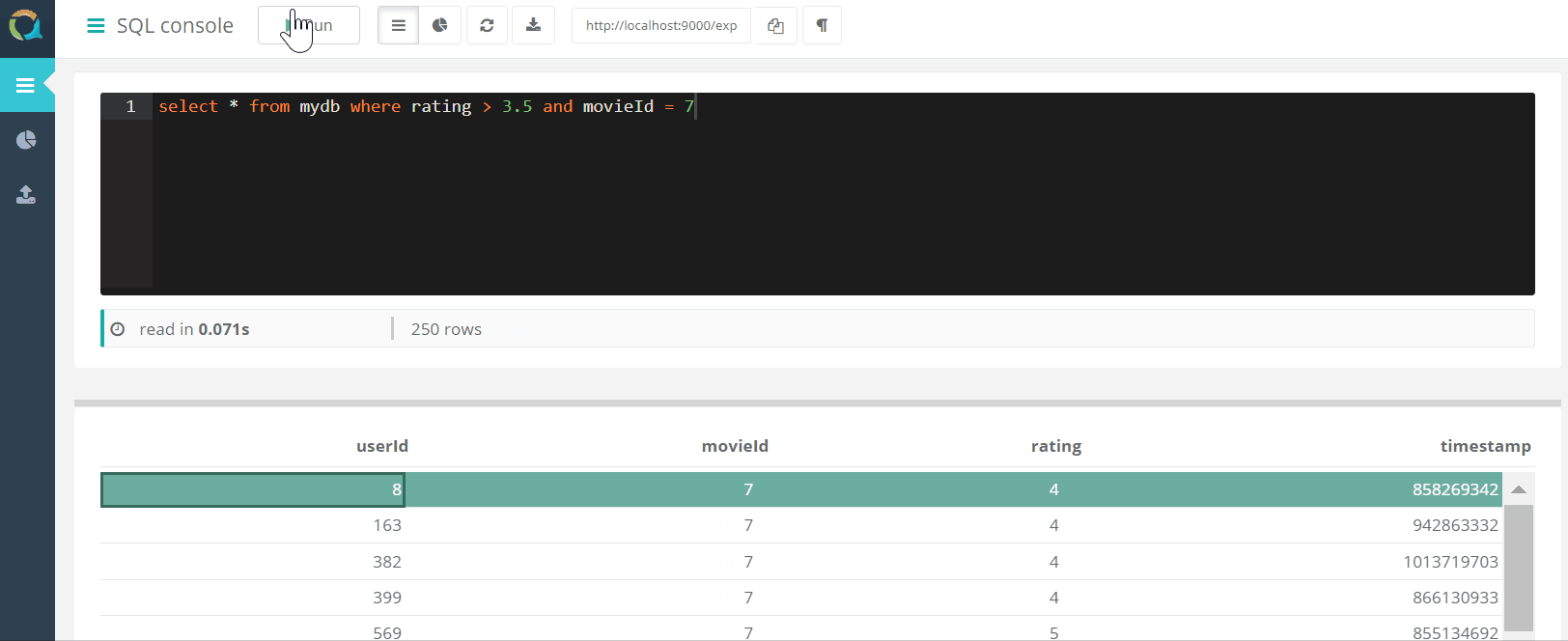 E baixar dados para um banco de dados no formato csv por meio de um navegador.
E baixar dados para um banco de dados no formato csv por meio de um navegador.
Você precisa de outro banco de dados?
Este projeto é jovem e ainda carece de alguns recursos corporativos, mas está se desenvolvendo rapidamente e vários colaboradores estão trabalhando ativamente no projeto. Eu acompanho o QuestDB desde agosto do ano passado e desenvolvi algumas extensões para este projeto ( função jdbc e osquery ), e também integrei esse projeto com testcontainers. Agora, estou tentando resolver meus problemas atuais no Dremio com upload incremental de dados, particionamento de dados e transações demoradas para fontes de dados em produção usando o QuestDB, complementando-o com funções de exportação de dados. Pretendo compartilhar minha experiência nas seguintes publicações. Me suborna especialmente que eu possa depurar minhas funções e banco de dados na plataforma que eu conheço, escrever testes de unidade que são executados na velocidade da luz.Você decide como um desenvolvedor experiente. Mais uma vez, o QuestDB não substitui os bancos de dados OLTP - PostgreSQL, Oracle, MS Sql Server, DB2 ou mesmo um substituto H2 para testesna JVM. Este é um poderoso banco de dados de código aberto especializado com suporte para os protocolos de rede PostgreSQL, Influx / Telegraf. Se o seu cenário de uso se encaixa nos recursos implementados nele e no cenário principal do uso de um banco de dados de colunas, a escolha é justificada!