Este artigo será útil para aqueles que acabaram de se familiarizar com a arquitetura de microsserviços e com o serviço Apache Kafka. O material não pretende ser um tutorial detalhado, mas ajudará você a começar rapidamente com essa tecnologia. Falarei sobre como instalar e configurar o Kafka no Windows 10. Também criaremos um projeto usando o Intellij IDEA e o Spring Boot.Pelo que?
Dificuldades no entendimento de várias ferramentas estão frequentemente associadas ao fato de o desenvolvedor nunca encontrar situações nas quais essas ferramentas possam ser necessárias. Com Kafka, isso é exatamente o mesmo. Descrevemos a situação em que essa tecnologia será útil. Se você possui uma arquitetura monolítica de aplicativos, é claro que não precisa de nenhum Kafka. Tudo muda com a transição para microsserviços. De fato, cada microsserviço é um programa separado que executa uma ou outra função e que pode ser iniciado independentemente de outros microsserviços. Os microsserviços podem ser comparados com os funcionários do escritório, que se sentam em mesas separadas e resolvem seus problemas de maneira independente. O trabalho de uma equipe assim distribuída é impensável sem coordenação central.Os funcionários devem poder trocar mensagens e resultados do trabalho entre si. O Apache Kafka para microsserviços foi projetado para resolver esse problema.O Apache Kafka é um intermediário de mensagens. Com isso, os microsserviços podem interagir entre si, enviando e recebendo informações importantes. Surge a pergunta: por que não usar o pedido normal de POST para esses fins, no corpo do qual você pode transferir os dados necessários e obter a resposta da mesma maneira? Essa abordagem tem várias desvantagens óbvias. Por exemplo, um produtor (um serviço que envia uma mensagem) pode enviar dados apenas na forma de uma resposta em resposta a uma solicitação de um consumidor (um serviço que recebe dados). Suponha que um consumidor envie uma solicitação POST e o produtor atenda. No momento, por algum motivo, o consumidor não pode aceitar a resposta. O que acontecerá com os dados? Eles estarão perdidos. O consumidor precisará novamente enviar uma solicitação e esperar que os dados que ele desejava receber não tenham sido alterados durante esse período,e o produtor ainda está pronto para aceitar a solicitação.O Apache Kafka resolve esse e muitos outros problemas que surgem ao trocar mensagens entre microsserviços. Não será errado lembrar que a troca ininterrupta e conveniente de dados é um dos principais problemas que devem ser resolvidos para garantir a operação estável da arquitetura de microsserviços.Instale e configure o ZooKeeper e o Apache Kafka no Windows 10
A primeira coisa que você precisa saber para começar é que o Apache Kafka é executado em cima do serviço ZooKeeper. O ZooKeeper é um serviço distribuído de configuração e sincronização, e é tudo o que precisamos saber sobre isso neste contexto. Precisamos fazer o download, configurar e executá-lo antes de começarmos com o Kafka. Antes de começar a trabalhar com o ZooKeeper, verifique se o JRE está instalado e configurado.Você pode baixar a versão mais recente do ZooKeeper no site oficial .Extraímos os arquivos do arquivo morto do ZooKeeper baixado para uma pasta no disco.Na pasta zookeeper com o número da versão, encontramos a pasta conf e nela o arquivo “zoo_sample.cfg”. Copie-o e altere o nome da cópia para "zoo.cfg". Abra o arquivo de cópia e encontre a linha dataDir = / tmp / zookeeper. Nesta linha, escrevemos o caminho completo para nossa pasta zookeeper-x.x.x. Parece-me assim: dataDir = C: \\ ZooKeeper \\ zookeeper-3.6.0
Copie-o e altere o nome da cópia para "zoo.cfg". Abra o arquivo de cópia e encontre a linha dataDir = / tmp / zookeeper. Nesta linha, escrevemos o caminho completo para nossa pasta zookeeper-x.x.x. Parece-me assim: dataDir = C: \\ ZooKeeper \\ zookeeper-3.6.0 Agora, adicionamos a variável de ambiente do sistema: ZOOKEEPER_HOME = C: \ ZooKeeper \ zookeeper-3.4.9 e no final da variável de sistema Path, adicione a entrada:;% ZOOKEEPER_HOME % \ bin;Execute a linha de comando e escreva o comando:
Agora, adicionamos a variável de ambiente do sistema: ZOOKEEPER_HOME = C: \ ZooKeeper \ zookeeper-3.4.9 e no final da variável de sistema Path, adicione a entrada:;% ZOOKEEPER_HOME % \ bin;Execute a linha de comando e escreva o comando:zkserver
Se tudo for feito corretamente, você verá algo como o seguinte.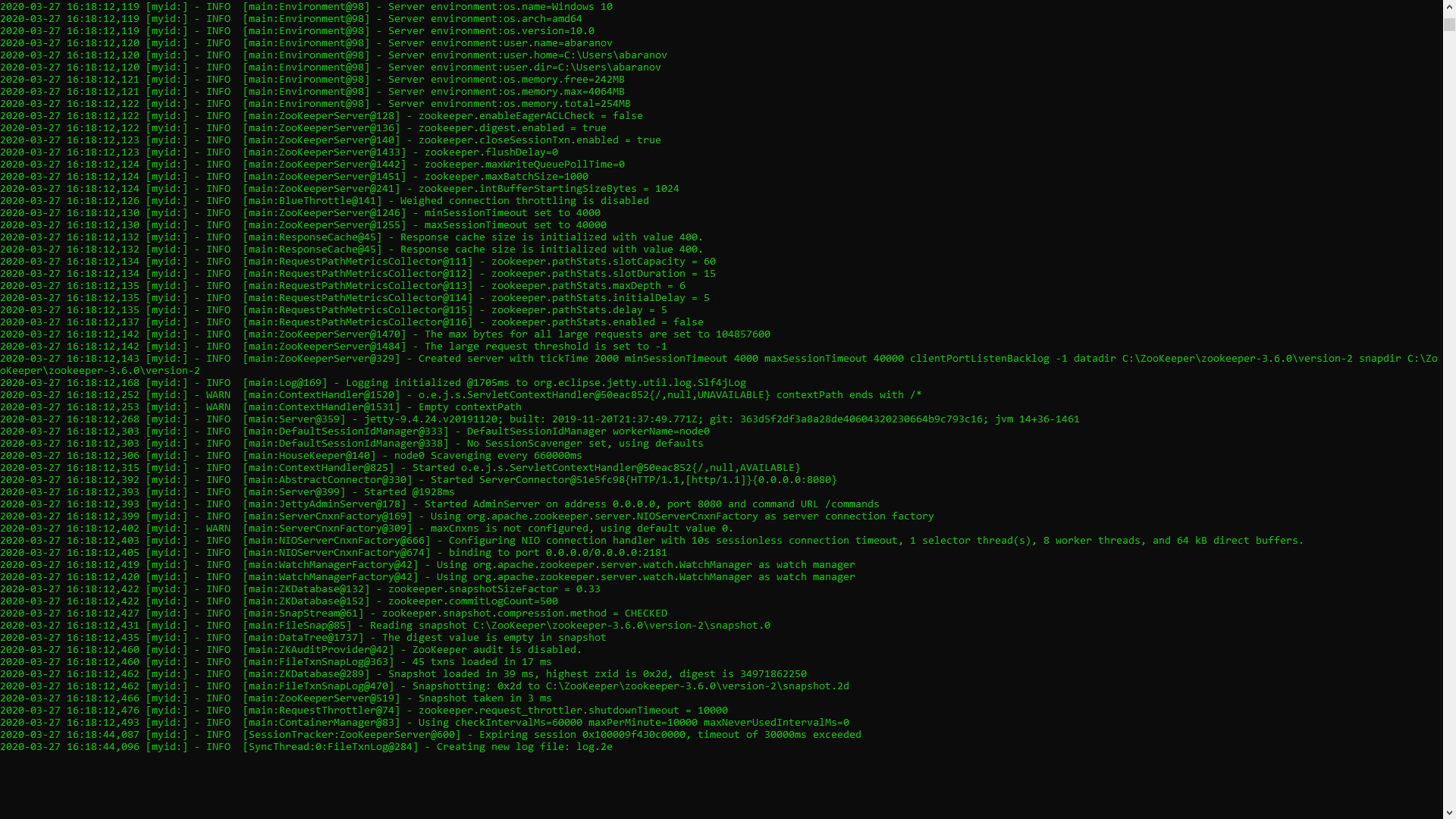 Isso significa que o ZooKeeper iniciou normalmente. Prosseguimos diretamente para a instalação e configuração do servidor Apache Kafka. Faça o download da versão mais recente do site oficial e extraia o conteúdo do arquivo: kafka.apache.org/downloadsNa pasta com Kafka, encontramos a pasta config, nela encontramos o arquivo server.properties e o abrimos.
Isso significa que o ZooKeeper iniciou normalmente. Prosseguimos diretamente para a instalação e configuração do servidor Apache Kafka. Faça o download da versão mais recente do site oficial e extraia o conteúdo do arquivo: kafka.apache.org/downloadsNa pasta com Kafka, encontramos a pasta config, nela encontramos o arquivo server.properties e o abrimos. Nós encontramos a linha log.dirs = / tmp / kafka-logs e indicamos nele o caminho onde o Kafka salvará os logs: log.dirs = c: / kafka / kafka-logs.
Nós encontramos a linha log.dirs = / tmp / kafka-logs e indicamos nele o caminho onde o Kafka salvará os logs: log.dirs = c: / kafka / kafka-logs.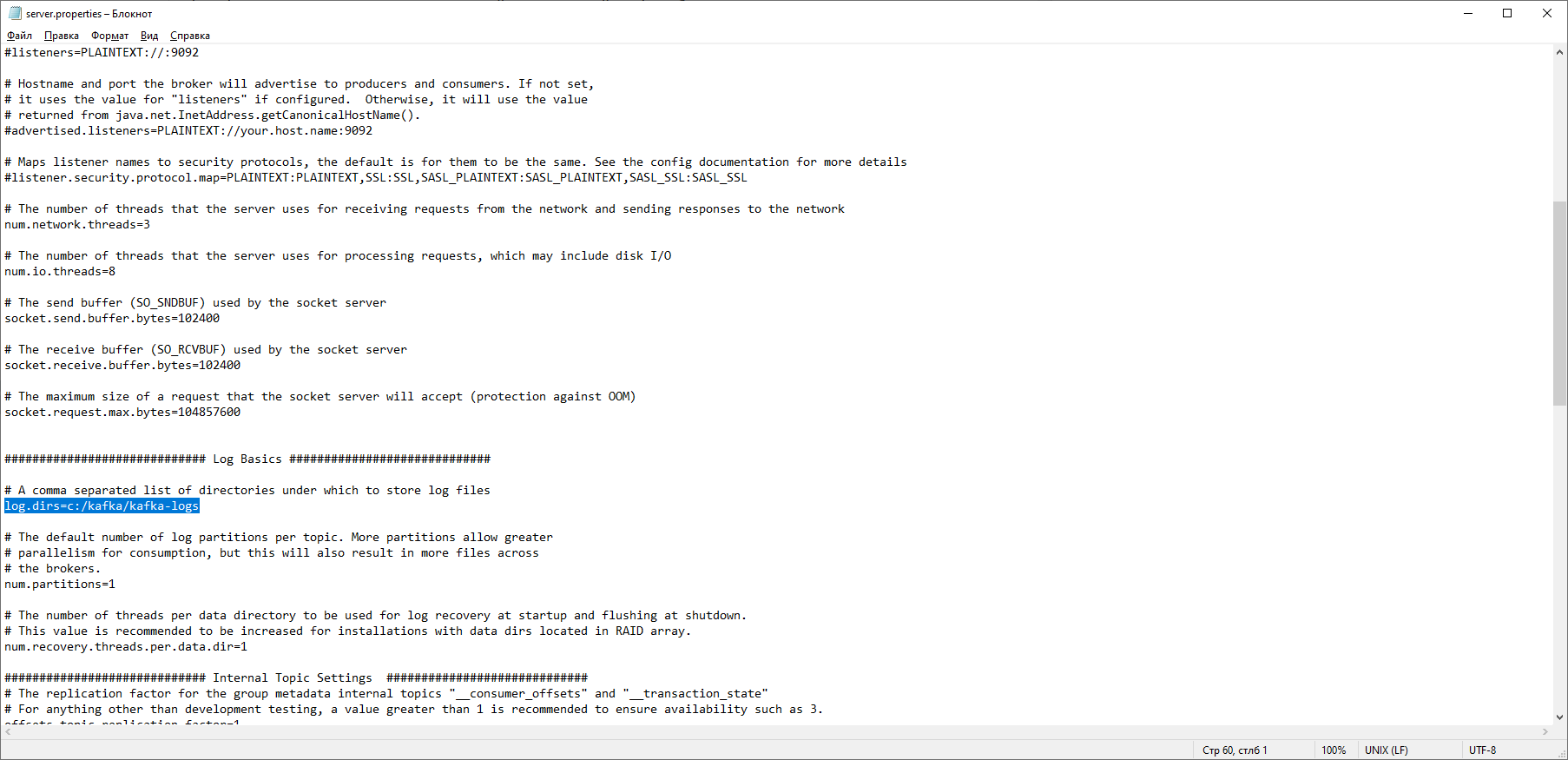 Na mesma pasta, edite o arquivo zookeeper.properties. Alteramos a linha dataDir = / tmp / zookeeper para dataDir = c: / kafka / zookeeper-data, sem esquecer de indicar o caminho para sua pasta Kafka após o nome do disco. Se você fez tudo certo, pode executar o ZooKeeper e o Kafka.
Na mesma pasta, edite o arquivo zookeeper.properties. Alteramos a linha dataDir = / tmp / zookeeper para dataDir = c: / kafka / zookeeper-data, sem esquecer de indicar o caminho para sua pasta Kafka após o nome do disco. Se você fez tudo certo, pode executar o ZooKeeper e o Kafka. Para alguns, pode ser uma surpresa desagradável que não exista uma GUI para controlar o Kafka. Talvez isso ocorra porque o serviço foi projetado para nerds duros que trabalham exclusivamente com o console. De uma forma ou de outra, para executar o Kafka, precisamos de uma linha de comando.Primeiro você precisa iniciar o ZooKeeper. Na pasta com o kafka, encontramos a pasta bin / windows, na qual encontramos o arquivo para iniciar o serviço zookeeper-server-start.bat, clique nele. Nada acontece? Deveria ser assim. Abra o console nesta pasta e escreva:
Para alguns, pode ser uma surpresa desagradável que não exista uma GUI para controlar o Kafka. Talvez isso ocorra porque o serviço foi projetado para nerds duros que trabalham exclusivamente com o console. De uma forma ou de outra, para executar o Kafka, precisamos de uma linha de comando.Primeiro você precisa iniciar o ZooKeeper. Na pasta com o kafka, encontramos a pasta bin / windows, na qual encontramos o arquivo para iniciar o serviço zookeeper-server-start.bat, clique nele. Nada acontece? Deveria ser assim. Abra o console nesta pasta e escreva: start zookeeper-server-start.bat
Não funciona de novo? Essa é a norma. Isso ocorre porque o zookeeper-server-start.bat requer os parâmetros especificados no arquivo zookeeper.properties, que, como lembramos, está na pasta de configuração para seu trabalho. Escrevemos para o console:start zookeeper-server-start.bat c:\kafka\config\zookeeper.properties
Agora tudo deve começar normalmente. Mais uma vez, abra o console nesta pasta (não feche o ZooKeeper!) E execute o kafka:
Mais uma vez, abra o console nesta pasta (não feche o ZooKeeper!) E execute o kafka:start kafka-server-start.bat c:\kafka\config\server.properties
Para não gravar comandos toda vez na linha de comando, você pode usar o antigo método comprovado e criar um arquivo em lotes com o seguinte conteúdo:start C:\kafka\bin\windows\zookeeper-server-start.bat C:\kafka\config\zookeeper.properties
timeout 10
start C:\kafka\bin\windows\kafka-server-start.bat C:\kafka\config\server.properties
O tempo limite da linha 10 é necessário para definir uma pausa entre o zookeeper inicial e o kafka. Se você fez tudo certo, ao clicar no arquivo em lotes, dois consoles devem abrir com o zookeeper e o kafka em execução.Agora podemos criar um produtor de mensagens e um consumidor com os parâmetros necessários diretamente na linha de comando. Mas, na prática, pode ser necessário, a menos que seja para testar o serviço. Estaremos muito mais interessados em como trabalhar com kafka da IDEA.Trabalhar com kafka da IDEA
Escreveremos o aplicativo mais simples possível, que será simultaneamente o produtor e consumidor da mensagem e, em seguida, adicionaremos recursos úteis a ela. Crie um novo projeto de primavera. Isso é feito de maneira mais conveniente usando um inicializador de mola. Adicione as dependências org.springframework.kafka e spring-boot-starter-web
 Como resultado, o arquivo pom.xml deve se parecer com o seguinte:
Como resultado, o arquivo pom.xml deve se parecer com o seguinte: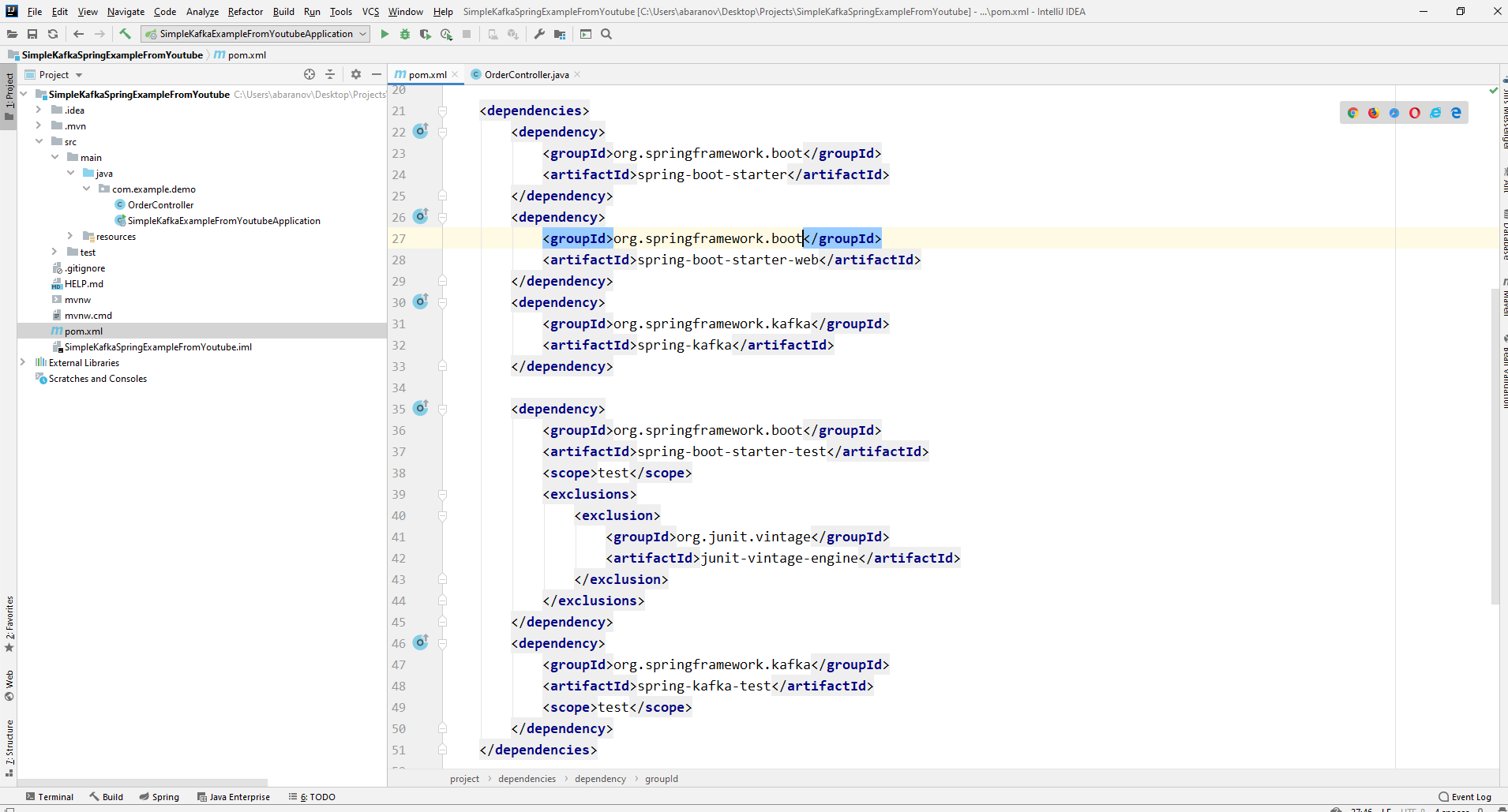 Para enviar mensagens, precisamos do objeto KafkaTemplate <K, V>. Como vemos, o objeto é digitado. O primeiro parâmetro é o tipo de chave, o segundo é a própria mensagem. Por enquanto, indicaremos os dois parâmetros como String. Vamos criar o objeto no controlador de classe. Declare o KafkaTemplate e peça ao Spring para inicializá-lo anotandoLigado automaticamente.
Para enviar mensagens, precisamos do objeto KafkaTemplate <K, V>. Como vemos, o objeto é digitado. O primeiro parâmetro é o tipo de chave, o segundo é a própria mensagem. Por enquanto, indicaremos os dois parâmetros como String. Vamos criar o objeto no controlador de classe. Declare o KafkaTemplate e peça ao Spring para inicializá-lo anotandoLigado automaticamente.@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
Em princípio, nosso produtor está pronto. Tudo o que falta fazer é chamar o método send (). Existem várias versões sobrecarregadas desse método. Utilizamos em nosso projeto uma opção com 3 parâmetros - send (Tópico de string, chave K, dados V). Como o KafkaTemplate é digitado por String, a chave e os dados no método send serão uma string. O primeiro parâmetro indica o tópico, ou seja, o tópico para o qual as mensagens serão enviadas e quais consumidores podem se inscrever para recebê-las. Se o tópico especificado no método de envio não existir, ele será criado automaticamente. O texto da classe completa é assim.@RestController
@RequestMapping("msg")
public class MsgController {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@PostMapping
public void sendOrder(String msgId, String msg){
kafkaTemplate.send("msg", msgId, msg);
}
}
O controlador mapeia para localhost : 8080 / msg, a chave e a própria mensagem são transmitidas no corpo da solicitação.O remetente da mensagem está pronto, agora crie um ouvinte. A primavera também permite que você faça isso sem muito esforço. Basta criar um método e marcá-lo com a anotação @KafkaListener, nos parâmetros nos quais você pode especificar apenas o tópico a ser ouvido. No nosso caso, é assim.@KafkaListener(topics="msg")
O próprio método, marcado com anotação, pode especificar um parâmetro aceito, que possui o tipo de mensagem transmitida pelo produtor.A classe na qual o consumidor será criado deve ser marcada com a anotação @EnableKafka.@EnableKafka
@SpringBootApplication
public class SimpleKafkaExampleApplication {
@KafkaListener(topics="msg")
public void msgListener(String msg){
System.out.println(msg);
}
public static void main(String[] args) {
SpringApplication.run(SimpleKafkaExampleApplication.class, args);
}
}
Além disso, no arquivo de configurações application.property, você deve especificar o parâmetro de concierge groupe-id. Se isso não for feito, o aplicativo não será iniciado. O parâmetro é do tipo String e pode ser qualquer coisa.spring.kafka.consumer.group-id=app.1
Nosso projeto kafka mais simples está pronto. Temos um remetente e um destinatário de mensagens. Resta apenas correr. Primeiro, inicie o ZooKeeper e Kafka usando o arquivo em lotes que escrevemos anteriormente e, em seguida, inicie nosso aplicativo. É mais conveniente enviar uma solicitação usando o Postman. No corpo da solicitação, não se esqueça de especificar os parâmetros msgId e msg. Se virmos essa imagem na IDEA, tudo funcionará: o produtor enviou uma mensagem, o consumidor a recebeu e a exibiu no console.
Se virmos essa imagem na IDEA, tudo funcionará: o produtor enviou uma mensagem, o consumidor a recebeu e a exibiu no console.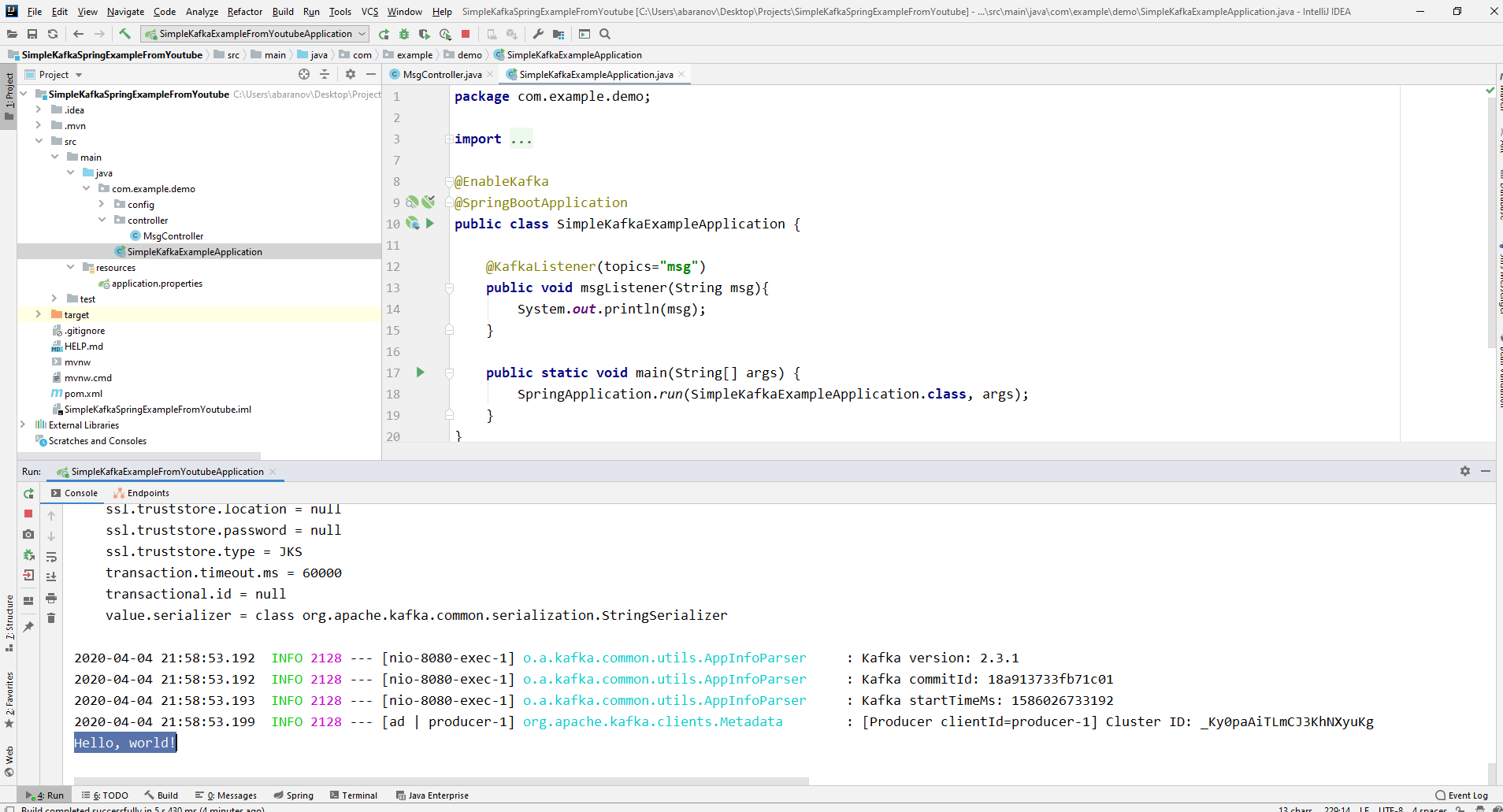
Nós complicamos o projeto
Projetos reais usando Kafka são certamente mais complicados do que o que criamos. Agora que descobrimos as funções básicas do serviço, considere quais recursos adicionais ele oferece. Para começar, melhoraremos o produtor.Se você abriu o método send (), poderá observar que todas as suas variantes têm um valor de retorno ListenableFuture <SendResult <K, V >>. Agora, não consideraremos em detalhes os recursos dessa interface. Aqui basta dizer que é necessário visualizar o resultado do envio de uma mensagem.@PostMapping
public void sendMsg(String msgId, String msg){
ListenableFuture<SendResult<String, String>> future = kafkaTemplate.send("msg", msgId, msg);
future.addCallback(System.out::println, System.err::println);
kafkaTemplate.flush();
}
O método addCallback () aceita dois parâmetros - SuccessCallback e FailureCallback. Ambos são interfaces funcionais. Pelo nome, você pode entender que o método do primeiro será chamado como resultado do envio bem-sucedido da mensagem, o segundo - como resultado de um erro.Agora, se executarmos o projeto, veremos algo como o seguinte no console:SendResult [producerRecord=ProducerRecord(topic=msg, partition=null, headers=RecordHeaders(headers = [], isReadOnly = true), key=1, value=Hello, world!, timestamp=null), recordMetadata=msg-0@6]
Vamos olhar atentamente para o nosso produtor novamente. Curiosamente, o que acontece se a chave não for String, mas, digamos, Long, mas como a mensagem transmitida, ainda pior - algum tipo de DTO complicado? Primeiro, vamos tentar alterar a chave para um valor numérico ... Se especificarmos Long como a chave no produtor, o aplicativo iniciará normalmente, mas quando você tentar enviar uma mensagem, uma ClassCastException será lançada e será relatado que a classe Long não pode ser convertida na classe String.
vamos tentar alterar a chave para um valor numérico ... Se especificarmos Long como a chave no produtor, o aplicativo iniciará normalmente, mas quando você tentar enviar uma mensagem, uma ClassCastException será lançada e será relatado que a classe Long não pode ser convertida na classe String. Se tentarmos criar manualmente o objeto KafkaTemplate, veremos que o objeto de interface ProducerFactory <K, V>, por exemplo, DefaultKafkaProducerFactory <>, é passado ao construtor como parâmetro. Para criar um DefaultKafkaProducerFactory, precisamos passar um mapa contendo suas configurações de produtor para o construtor. Todo o código para a configuração e criação do produtor será colocado em uma classe separada. Para fazer isso, crie o pacote de configuração e nele a classe KafkaProducerConfig.
Se tentarmos criar manualmente o objeto KafkaTemplate, veremos que o objeto de interface ProducerFactory <K, V>, por exemplo, DefaultKafkaProducerFactory <>, é passado ao construtor como parâmetro. Para criar um DefaultKafkaProducerFactory, precisamos passar um mapa contendo suas configurações de produtor para o construtor. Todo o código para a configuração e criação do produtor será colocado em uma classe separada. Para fazer isso, crie o pacote de configuração e nele a classe KafkaProducerConfig.@Configuration
public class KafkaProducerConfig {
private String kafkaServer="localhost:9092";
@Bean
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
kafkaServer);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
LongSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
StringSerializer.class);
return props;
}
@Bean
public ProducerFactory<Long, String> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public KafkaTemplate<Long, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
No método producerConfigs (), crie um mapa com as configurações e especifique LongSerializer.class como o serializador da chave. Começamos, enviamos uma solicitação do Postman e vemos que agora tudo funciona como deveria: o produtor envia uma mensagem e o consumidor a recebe.Agora vamos mudar o tipo do valor transmitido. E se não tivermos uma classe padrão da biblioteca Java, mas algum tipo de DTO personalizado. Vamos dizer isso.@Data
public class UserDto {
private Long age;
private String name;
private Address address;
}
@Data
@AllArgsConstructor
public class Address {
private String country;
private String city;
private String street;
private Long homeNumber;
private Long flatNumber;
}
Para enviar o DTO como uma mensagem, é necessário fazer algumas alterações na configuração do produtor. Especifique JsonSerializer.class como o serializador do valor da mensagem e não se esqueça de alterar o tipo String para UserDto em todos os lugares.@Configuration
public class KafkaProducerConfig {
private String kafkaServer="localhost:9092";
@Bean
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,
kafkaServer);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
LongSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
JsonSerializer.class);
return props;
}
@Bean
public ProducerFactory<Long, UserDto> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
@Bean
public KafkaTemplate<Long, UserDto> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
Envie uma mensagem. A seguinte linha será exibida no console: Agora vamos complicar o consumidor. Antes disso, nosso método public void msgListener (String msg), marcado com a anotação @KafkaListener (topics = "msg"), considerava String como parâmetro e a exibia no console. E se quisermos obter outros parâmetros da mensagem transmitida, por exemplo, uma chave ou uma partição? Nesse caso, o tipo do valor transmitido deve ser alterado.
Agora vamos complicar o consumidor. Antes disso, nosso método public void msgListener (String msg), marcado com a anotação @KafkaListener (topics = "msg"), considerava String como parâmetro e a exibia no console. E se quisermos obter outros parâmetros da mensagem transmitida, por exemplo, uma chave ou uma partição? Nesse caso, o tipo do valor transmitido deve ser alterado.@KafkaListener(topics="msg")
public void orderListener(ConsumerRecord<Long, UserDto> record){
System.out.println(record.partition());
System.out.println(record.key());
System.out.println(record.value());
}
No objeto ConsumerRecord, podemos obter todos os parâmetros nos quais estamos interessados.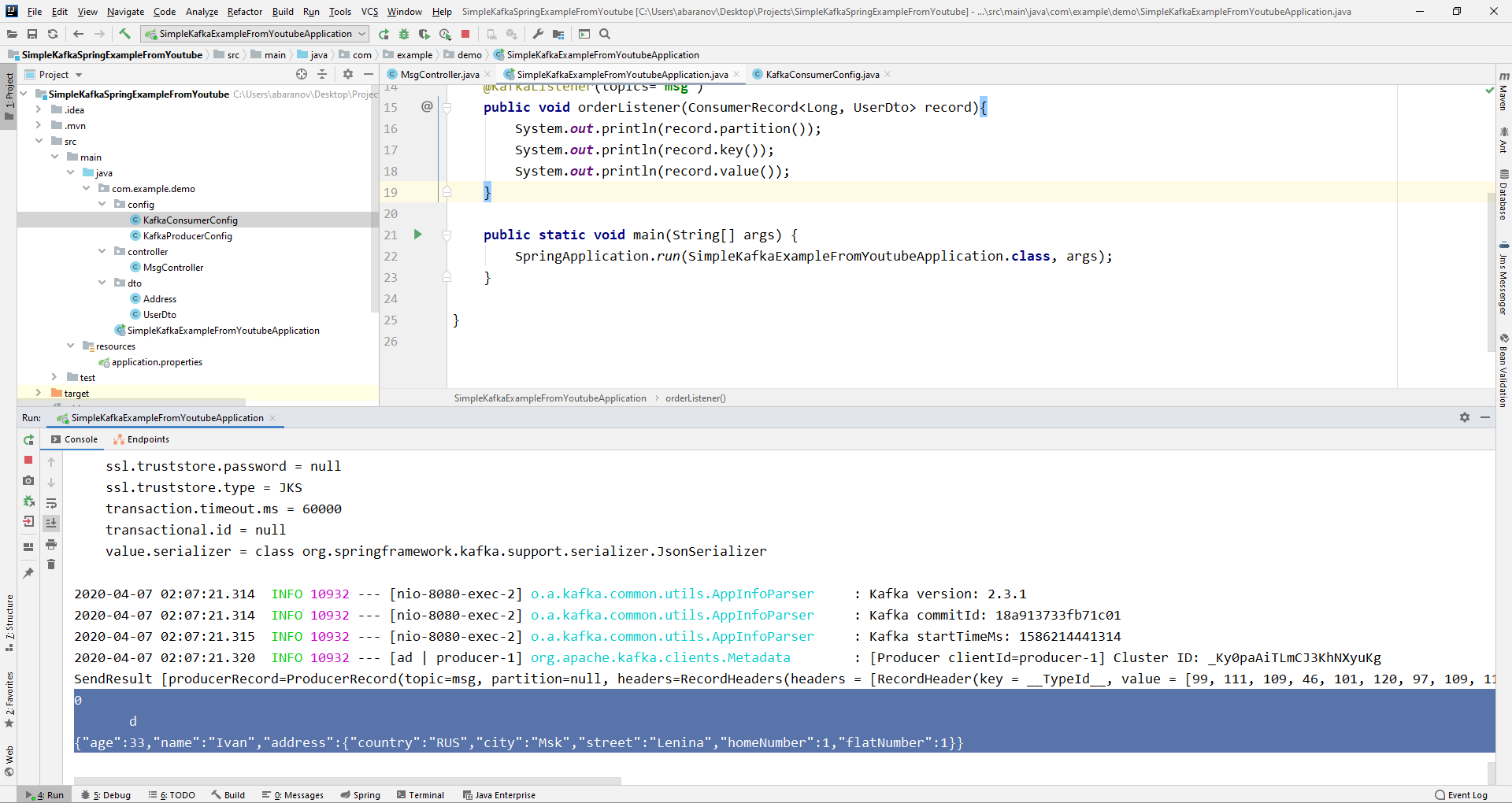 Vemos que, em vez da chave no console, algum tipo de krakozyabry é exibido. Isso ocorre porque o StringDeserializer é usado por padrão para desserializar a chave e, se queremos que a chave no formato inteiro seja exibida corretamente, devemos alterá-la para LongDeserializer. Para configurar o consumidor no pacote de configuração, crie a classe KafkaConsumerConfig.
Vemos que, em vez da chave no console, algum tipo de krakozyabry é exibido. Isso ocorre porque o StringDeserializer é usado por padrão para desserializar a chave e, se queremos que a chave no formato inteiro seja exibida corretamente, devemos alterá-la para LongDeserializer. Para configurar o consumidor no pacote de configuração, crie a classe KafkaConsumerConfig.@Configuration
public class KafkaConsumerConfig {
@Value("${spring.kafka.bootstrap-servers}")
private String kafkaServer;
@Value("${spring.kafka.consumer.group-id}")
private String kafkaGroupId;
@Bean
public Map<String, Object> consumerConfigs() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaServer);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, LongDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.GROUP_ID_CONFIG, kafkaGroupId);
return props;
}
@Bean
public KafkaListenerContainerFactory<?> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<Long, UserDto> factory =
new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
return factory;
}
@Bean
public ConsumerFactory<Long, UserDto> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
}
A classe KafkaConsumerConfig é muito semelhante à KafkaProducerConfig que criamos anteriormente. Há também um mapa que contém as configurações necessárias, por exemplo, como um desserializador para a chave e o valor. O mapa criado é usado para criar o ConsumerFactory <>, que, por sua vez, é necessário para criar o KafkaListenerContainerFactory <?>. Um detalhe importante: o método que retorna KafkaListenerContainerFactory <?> Deve ser chamado kafkaListenerContainerFactory (), caso contrário, o Spring não conseguirá encontrar o bean desejado e o projeto não será compilado. Nós começamos. Vemos que agora a chave é exibida como deveria, o que significa que tudo funciona. Obviamente, os recursos do Apache Kafka vão muito além dos descritos neste artigo, no entanto, espero que depois de lê-lo, você tenha uma idéia sobre esse serviço e, o mais importante, comece a trabalhar com ele.Lave as mãos com mais frequência, use máscaras, não saia sem necessidade e seja saudável.
Vemos que agora a chave é exibida como deveria, o que significa que tudo funciona. Obviamente, os recursos do Apache Kafka vão muito além dos descritos neste artigo, no entanto, espero que depois de lê-lo, você tenha uma idéia sobre esse serviço e, o mais importante, comece a trabalhar com ele.Lave as mãos com mais frequência, use máscaras, não saia sem necessidade e seja saudável.