Olá Habr!Neste artigo, gostaríamos de falar sobre automação da infraestrutura de rede. Um diagrama de rede em funcionamento será apresentado, que opera em uma empresa pequena, mas muito orgulhosa. Todas as correspondências com o hardware de rede real são aleatórias. Consideraremos um caso que ocorreu nesta rede, o que pode levar a um desligamento dos negócios por um longo tempo e a graves perdas financeiras. A solução deste caso se encaixa muito bem no conceito de "Automação da infraestrutura de rede". Usando ferramentas de automação, mostraremos como você pode efetivamente resolver problemas complexos em um curto espaço de tempo e refletiremos sobre o motivo pelo qual essas tarefas são mais promissoras para serem resolvidas dessa maneira e não de outra forma (através do console) .aviso Legal
Nossas principais ferramentas de automação são o Ansible (como uma ferramenta de automação) e o Git (como um repositório do Ansible playbook). Quero imediatamente fazer uma reserva de que este não é um artigo de apuração de fatos, em que falamos sobre a lógica do Ansible ou do Git e explico coisas básicas (por exemplo, o que são funções \ tarefas \ módulos \ arquivos de inventário \ variáveis no Ansible ou o que acontece quando você insere comandos git push ou git commit). Esta história não é sobre como você pode praticar no Ansible, configurá-lo em equipamentos NTP ou SMTP. Esta é uma história sobre como você pode rapidamente e de preferência sem erros resolver um problema de rede. Também é desejável ter uma boa idéia de como a rede funciona, em particular, qual é a pilha de protocolos TCP / IP, OSPF, BGP. A escolha de Ansible e Git também está fora de questão. Se você ainda tem a opção de escolher uma solução específica,é altamente recomendável ler o livro Programabilidade e automação de rede. Habilidades para o engenheiro de rede de última geração ”de Jason Edelman, Scott S. Lowe e Matt Oswalt.Agora ao ponto.Formulação do problema
Imagine uma situação: às 3 da manhã, você dorme profundamente e sonha. A ligação para o telefone. O diretor técnicoestá ligando: - Sim?- ###, ####, #####, o cluster de firewalls caiu e não aumenta !!!Você esfrega os olhos, tenta perceber o que está acontecendo e imagina como isso poderia ter acontecido. No tubo, você pode ouvir os cabelos arrancando a cabeça do diretor, e ele pede para ligar de volta, porque o general liga para ele na segunda linha.Depois de meia hora, você coletou as primeiras notas introdutórias do turno de plantão e acordou todo mundo com quem podia acordar. Como resultado, o diretor técnico não mentiu, tudo está correto, o principal cluster de firewalls caiu e nenhum gesto básico o levou a um juízo. Todos os serviços que a empresa oferece não funcionam.Escolha um problema para o seu gosto, todos se lembrarão de algo diferente. Por exemplo, após uma atualização noturna, na ausência de uma carga pesada, tudo funcionou bem e todos os satisfeitos foram para a cama. O tráfego foi passando e os buffers da interface começaram a transbordar devido a um erro no driver da placa de rede.A situação pode muito bem descrever Jackie Chan. Obrigado, Jackie.A situação não é muito agradável, é?Vamos sair para o tempo da nossa rede mano com seus pensamentos tristes.Discutiremos como os eventos se desenvolverão ainda mais.Oferecemos a seguinte ordem de apresentação do material
Obrigado, Jackie.A situação não é muito agradável, é?Vamos sair para o tempo da nossa rede mano com seus pensamentos tristes.Discutiremos como os eventos se desenvolverão ainda mais.Oferecemos a seguinte ordem de apresentação do material- Considere o diagrama de rede e analise como ele funciona;
- Vamos descrever como transferimos as configurações de um roteador para outro usando o Ansible;
- Vamos falar sobre a automação da infraestrutura de TI em geral.
Diagrama de rede e sua descrição
Esquema
 Considere a lógica da nossa organização. Não nomearemos fabricantes específicos de equipamentos, isso não importa no artigo (o próprio leitor atento vai adivinhar que tipo de equipamento é usado) . Essa é apenas uma das boas vantagens de trabalhar com a Ansible, ao configurar, em geral, não nos importamos com o tipo de equipamento. Só para entender, este equipamento é conhecido por fornecedores como Cisco, Juniper, Check Point, Fortinet, Palo Alto ... você pode substituir sua própria versão.Temos duas tarefas principais para mover o tráfego:
Considere a lógica da nossa organização. Não nomearemos fabricantes específicos de equipamentos, isso não importa no artigo (o próprio leitor atento vai adivinhar que tipo de equipamento é usado) . Essa é apenas uma das boas vantagens de trabalhar com a Ansible, ao configurar, em geral, não nos importamos com o tipo de equipamento. Só para entender, este equipamento é conhecido por fornecedores como Cisco, Juniper, Check Point, Fortinet, Palo Alto ... você pode substituir sua própria versão.Temos duas tarefas principais para mover o tráfego:- Garantir a publicação de nossos serviços, que são os negócios da empresa;
- Forneça comunicação com filiais, um data center remoto e organizações de terceiros (parceiros e clientes), bem como acesso à Internet através do escritório central.
Vamos começar com os elementos básicos:- Dois roteadores de borda (BRD-01, BRD-02);
- Cluster de firewall (FW-CLUSTER);
- Chave do Kernel (L3-CORE);
- Um roteador que se tornará uma tábua de salvação (no processo de solução do problema, transferiremos as configurações de rede do FW-CLUSTER para EMERGENCY) (EMERGENCY);
- Switches para gerenciamento de infraestrutura de rede (L2-MGMT);
- Máquina virtual com Git e Ansible (VM-AUTOMATION);
- Um laptop que testa e desenvolve manuais para o Ansible (automação de laptops).
Um protocolo de roteamento OSPF dinâmico é configurado na rede com as seguintes áreas:- Área 0 - a área na qual estão incluídos os roteadores responsáveis pela movimentação de tráfego na zona de INTERCÂMBIO;
- Área 1 - a área na qual estão incluídos os roteadores responsáveis pelo trabalho dos serviços da empresa;
- Área 2 - a área na qual os roteadores responsáveis pelo roteamento do tráfego de gerenciamento estão incluídos;
- Área N - áreas da rede de agências.
Nos roteadores de borda, ele é criado em um roteador virtual (VRF-INTERNET), no qual a visualização completa do eBGP com o AS atribuído correspondente é aumentada. Entre os VRFs, o iBGP está configurado. A empresa possui um conjunto de endereços brancos publicados nessas VRF-INTERNETs. Alguns dos endereços brancos são roteados diretamente para o FW-CLUSTER (endereços nos quais os serviços da empresa operam), outros são roteados pela zona EXCHANGE (serviços internos da empresa que exigem endereços IP externos e endereços NAT externos para escritórios). Além disso, o tráfego chega aos roteadores virtuais criados no L3-CORE com endereços branco e cinza (zonas de segurança).As redes de gerenciamento usam comutadores dedicados e são uma rede fisicamente dedicada. A rede de gerenciamento também é dividida em zonas de segurança.O roteador de EMERGÊNCIA duplica física e logicamente o FW-CLUSTER. Todas as interfaces estão desabilitadas, exceto aquelas que examinam a rede de gerenciamento.Automação e sua descrição
Nós descobrimos como a rede funciona. Agora, vamos dar uma olhada nas etapas, o que faremos para transferir o tráfego do FW-CLUSTER para EMERGENCY:- Desative as interfaces no comutador do kernel (L3-CORE) que o conectam ao FW-CLUSTER;
- Desative as interfaces no switch principal L2-MGMT que o conectam ao FW-CLUSTER;
- Configure o roteador EMERGENCY (por padrão, todas as interfaces estão desabilitadas nele, exceto aquelas associadas ao L2-MGMT):
- Nós incluímos interfaces em EMERGÊNCIA;
- Configure o endereço IP externo (para NAT), que estava no FW-Cluster;
- Geramos solicitações de gARP para que, nas tabelas arp L3-CORE, os endereços de papoula mudem de FW-Cluster para EMERGENCY;
- BRD-01, BRD-02;
- NAT;
- EMERGENCY OSPF Area 1;
- EMERGENCY OSPF Area 2;
- Area 1 10;
- Area 1 10;
- ip-, L2-MGMT ( , FW-CLUSTER);
- gARP , arp- L2-MGMT - FW-CLUSTER EMERGENCY.
Novamente, voltamos à formulação original do problema. Três da manhã, um estresse enorme, um erro em qualquer estágio pode levar a novos problemas. Pronto para digitar comandos através da CLI? Sim? Ok, vá pelo menos lavar o rosto, tomar café e reunir sua vontade em um punho.Bruce, por favor ajude os caras. Bem, continuamos cortando nossa automação.Abaixo está um diagrama da pasta de trabalho em termos de Ansible. Este diagrama reflete o que descrevemos logo acima, apenas uma implementação concreta no Ansible.
Bem, continuamos cortando nossa automação.Abaixo está um diagrama da pasta de trabalho em termos de Ansible. Este diagrama reflete o que descrevemos logo acima, apenas uma implementação concreta no Ansible.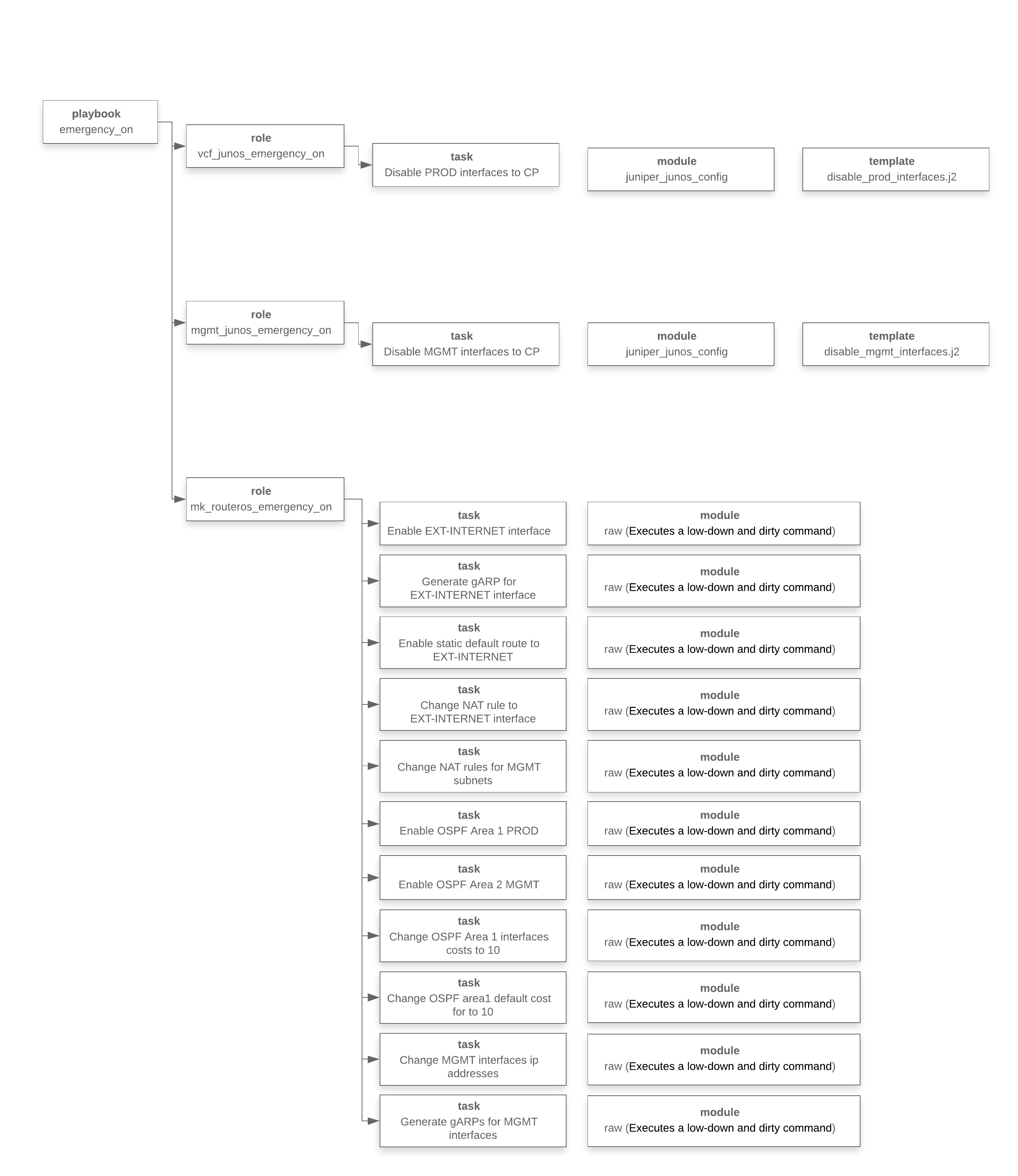 Nesse estágio, percebemos o que precisava ser feito, desenvolvemos um manual, realizamos testes, agora estamos prontos para lançá-lo.Outra pequena digressão. A facilidade da narração não deve enganá-lo. O processo de escrever playbooks não foi tão simples e rápido quanto parece. Os testes levaram bastante tempo, um suporte virtual foi criado, a solução foi lançada várias vezes e foram realizados cerca de 100 testes.Começamos ... Há uma sensação de que tudo acontece muito lentamente, em algum lugar há um erro, algo não funcionará no final. A sensação de um salto de pára-quedas, e o pára-quedas não quer abrir de uma vez ... isso é normal.Em seguida, lemos o resultado das operações do manual do Ansible (substituímos os endereços IP para fins de conspiração):
Nesse estágio, percebemos o que precisava ser feito, desenvolvemos um manual, realizamos testes, agora estamos prontos para lançá-lo.Outra pequena digressão. A facilidade da narração não deve enganá-lo. O processo de escrever playbooks não foi tão simples e rápido quanto parece. Os testes levaram bastante tempo, um suporte virtual foi criado, a solução foi lançada várias vezes e foram realizados cerca de 100 testes.Começamos ... Há uma sensação de que tudo acontece muito lentamente, em algum lugar há um erro, algo não funcionará no final. A sensação de um salto de pára-quedas, e o pára-quedas não quer abrir de uma vez ... isso é normal.Em seguida, lemos o resultado das operações do manual do Ansible (substituímos os endereços IP para fins de conspiração):[xxx@emergency ansible]$ ansible-playbook -i /etc/ansible/inventories/prod_inventory.ini /etc/ansible/playbooks/emergency_on.yml
PLAY [------->Emergency on VCF] ********************************************************
TASK [vcf_junos_emergency_on : Disable PROD interfaces to FW-CLUSTER] *********************
changed: [vcf]
PLAY [------->Emergency on MGMT-CORE] ************************************************
TASK [mgmt_junos_emergency_on : Disable MGMT interfaces to FW-CLUSTER] ******************
changed: [m9-03-sw-03-mgmt-core]
PLAY [------->Emergency on] ****************************************************
TASK [mk_routeros_emergency_on : Enable EXT-INTERNET interface] **************************
changed: [m9-04-r-04]
TASK [mk_routeros_emergency_on : Generate gARP for EXT-INTERNET interface] ****************
changed: [m9-04-r-04]
TASK [mk_routeros_emergency_on : Enable static default route to EXT-INTERNET] ****************
changed: [m9-04-r-04]
TASK [mk_routeros_emergency_on : Change NAT rule to EXT-INTERNET interface] ****************
changed: [m9-04-r-04] => (item=12)
changed: [m9-04-r-04] => (item=14)
changed: [m9-04-r-04] => (item=15)
changed: [m9-04-r-04] => (item=16)
changed: [m9-04-r-04] => (item=17)
TASK [mk_routeros_emergency_on : Enable OSPF Area 1 PROD] ******************************
changed: [m9-04-r-04]
TASK [mk_routeros_emergency_on : Enable OSPF Area 2 MGMT] *****************************
changed: [m9-04-r-04]
TASK [mk_routeros_emergency_on : Change OSPF Area 1 interfaces costs to 10] *****************
changed: [m9-04-r-04] => (item=VLAN-1001)
changed: [m9-04-r-04] => (item=VLAN-1002)
changed: [m9-04-r-04] => (item=VLAN-1003)
changed: [m9-04-r-04] => (item=VLAN-1004)
changed: [m9-04-r-04] => (item=VLAN-1005)
changed: [m9-04-r-04] => (item=VLAN-1006)
changed: [m9-04-r-04] => (item=VLAN-1007)
changed: [m9-04-r-04] => (item=VLAN-1008)
changed: [m9-04-r-04] => (item=VLAN-1009)
changed: [m9-04-r-04] => (item=VLAN-1010)
changed: [m9-04-r-04] => (item=VLAN-1011)
changed: [m9-04-r-04] => (item=VLAN-1012)
changed: [m9-04-r-04] => (item=VLAN-1013)
changed: [m9-04-r-04] => (item=VLAN-1100)
TASK [mk_routeros_emergency_on : Change OSPF area1 default cost for to 10] ******************
changed: [m9-04-r-04]
TASK [mk_routeros_emergency_on : Change MGMT interfaces ip addresses] ********************
changed: [m9-04-r-04] => (item={u'ip': u'..n.254', u'name': u'VLAN-803'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+1.254', u'name': u'VLAN-805'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+2.254', u'name': u'VLAN-807'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+3.254', u'name': u'VLAN-809'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+4.254', u'name': u'VLAN-820'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+5.254', u'name': u'VLAN-822'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+6.254', u'name': u'VLAN-823'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+7.254', u'name': u'VLAN-824'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+8.254', u'name': u'VLAN-850'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+9.254', u'name': u'VLAN-851'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+10.254', u'name': u'VLAN-852'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+11.254', u'name': u'VLAN-853'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+12.254', u'name': u'VLAN-870'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+13.254', u'name': u'VLAN-898'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+14.254', u'name': u'VLAN-899'})
TASK [mk_routeros_emergency_on : Generate gARPs for MGMT interfaces] *********************
changed: [m9-04-r-04] => (item={u'ip': u'..n.254', u'name': u'VLAN-803'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+1.254', u'name': u'VLAN-805'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+2.254', u'name': u'VLAN-807'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+3.254', u'name': u'VLAN-809'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+4.254', u'name': u'VLAN-820'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+5.254', u'name': u'VLAN-822'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+6.254', u'name': u'VLAN-823'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+7.254', u'name': u'VLAN-824'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+8.254', u'name': u'VLAN-850'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+9.254', u'name': u'VLAN-851'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+10.254', u'name': u'VLAN-852'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+11.254', u'name': u'VLAN-853'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+12.254', u'name': u'VLAN-870'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+13.254', u'name': u'VLAN-898'})
changed: [m9-04-r-04] => (item={u'ip': u'..n+14.254', u'name': u'VLAN-899'})
PLAY RECAP ************************************************************************
Feito!Na verdade, ele não está totalmente pronto, não se esqueça da convergência de protocolos de roteamento dinâmico e do carregamento de um grande número de rotas no FIB. Não podemos influenciar isso de forma alguma. Nós esperamos. Isso veio junto. Agora está pronto.E na vila de Vilabaggio (que não deseja automatizar a configuração da rede), eles continuam lavando a louça. Bruce (embora já seja diferente, mas não menos legal) está tentando descobrir quanto mais deve reconfigurar manualmente o equipamento. Eu também gostaria de me debruçar sobre um ponto importante. Como recuperamos tudo? Depois de algum tempo, daremos vida ao nosso FW-CLUSTER. Este é o equipamento principal, não o backup, a rede deve trabalhar nele.Sinta-se como começar a queimar em redes? O diretor técnico ouvirá mil argumentos por que isso não é necessário, por que isso pode ser feito posteriormente. Infelizmente, é assim que a rede funciona com um monte de patches, peças e restos de ex-luxo. Acontece uma colcha. Nossa tarefa como um todo, não nessa situação específica, mas geralmente, em princípio, como especialistas em TI, é levar a rede à bela palavra em inglês "consistência", é muito multifacetada, pode ser traduzida como: consistência, consistência, consistência, coerência, consistência, comparabilidade, conectividade. Isso é tudo sobre ele. Somente nesse estado a rede é gerenciável, entendemos claramente o que e como funciona, entendemos claramente o que precisa ser alterado, se necessário, sabemos claramente onde procurar em caso de problemas.E somente nessa rede você pode fazer truques como os que acabamos de descrever.Na verdade, outro manual foi preparado, que retornou as configurações ao seu estado original. A lógica de seu trabalho é a mesma (é importante lembrar, a ordem das tarefas é muito importante). Para não estender o artigo já extenso, decidimos não publicar a listagem do manual. Após a realização desses exercícios, você se sentirá muito mais calmo e confiante no futuro; além disso, todas as muletas que você empilhou lá se encontrarão imediatamente.Todos podem escrever para nós e obter o código fonte de todo o código escrito, junto com todos os livros da paly. Contatos no perfil.
Eu também gostaria de me debruçar sobre um ponto importante. Como recuperamos tudo? Depois de algum tempo, daremos vida ao nosso FW-CLUSTER. Este é o equipamento principal, não o backup, a rede deve trabalhar nele.Sinta-se como começar a queimar em redes? O diretor técnico ouvirá mil argumentos por que isso não é necessário, por que isso pode ser feito posteriormente. Infelizmente, é assim que a rede funciona com um monte de patches, peças e restos de ex-luxo. Acontece uma colcha. Nossa tarefa como um todo, não nessa situação específica, mas geralmente, em princípio, como especialistas em TI, é levar a rede à bela palavra em inglês "consistência", é muito multifacetada, pode ser traduzida como: consistência, consistência, consistência, coerência, consistência, comparabilidade, conectividade. Isso é tudo sobre ele. Somente nesse estado a rede é gerenciável, entendemos claramente o que e como funciona, entendemos claramente o que precisa ser alterado, se necessário, sabemos claramente onde procurar em caso de problemas.E somente nessa rede você pode fazer truques como os que acabamos de descrever.Na verdade, outro manual foi preparado, que retornou as configurações ao seu estado original. A lógica de seu trabalho é a mesma (é importante lembrar, a ordem das tarefas é muito importante). Para não estender o artigo já extenso, decidimos não publicar a listagem do manual. Após a realização desses exercícios, você se sentirá muito mais calmo e confiante no futuro; além disso, todas as muletas que você empilhou lá se encontrarão imediatamente.Todos podem escrever para nós e obter o código fonte de todo o código escrito, junto com todos os livros da paly. Contatos no perfil.achados
Em nossa opinião, processos que podem ser automatizados ainda não se cristalizaram. Com base no que encontramos e no que nossos colegas ocidentais estão discutindo, os seguintes tópicos ainda são visíveis:- Provisionamento de dispositivos;
- Coleção de dados;
- Comunicando
- Solução de problemas;
- Conformidade
Se houver interesse, podemos continuar a discussão sobre um dos tópicos indicados.Eu também quero especular um pouco sobre automação. O que deveria ser em nosso entendimento:- O sistema deve viver sem um homem, enquanto melhora o homem. O sistema não deve depender da pessoa;
- A operação deve ser especialista. Não há classe de especialistas que realizam tarefas de rotina. Existem especialistas que automatizaram toda a rotina e resolvem apenas problemas complexos;
- Rotina \ tarefas padrão são feitas automaticamente "por botão", os recursos não são desperdiçados. O resultado de tais tarefas é sempre previsível e compreensível.
E o que esses pontos devem levar a:- Transparência da infraestrutura de TI (menos riscos de operação, modernização, implementação. Menos tempo de inatividade por ano);
- A capacidade de planejar recursos de TI (sistema de planejamento de capacidade - você pode ver quanto é consumido, pode ver quantos recursos são necessários em um único sistema, e não por cartas e visitas aos principais departamentos);
- Capacidade de reduzir o número de funcionários de TI.
Autores do artigo: Alexander Manov (CCIE RS, CCIE SP) e Pavel Kirillov. Estamos interessados em discutir e propor soluções sobre o tópico de automação da infraestrutura de TI.