Ao escrever aplicativos em Python, os mapeadores objeto-relacionais (ORMs) são frequentemente usados para trabalhar com bancos de dados. Exemplos de ORMs são SQLALchemy, PonyORM e o mapeador objeto-relacional incluído no Django. Ao escolher o ORM, seu desempenho desempenha um papel bastante importante.
No Habr e na Internet como um todo, é possível encontrar nenhum teste de desempenho. Como um exemplo de benchmark ORM python de qualidade, você pode usar o benchmark Tortoise ORM ( link para o repositório ). Este benchmark analisa a velocidade de seis ORMs para onze tipos diferentes de consultas SQL.
Em geral, o benchmark da tartaruga torna possível avaliar a velocidade de execução da consulta usando ORMs diferentes, mas vejo um problema com essa abordagem de teste. Os ORMs geralmente são usados em aplicativos da Web em que vários usuários podem enviar solicitações diferentes ao mesmo tempo, mas não encontrei uma única referência que avalie o desempenho do ORM nessas condições. Como resultado disso, decidi escrever meu benchmark e comparar o PonyORM e o SQLAlchemy com ele. Como base, tomei o benchmark TPC-C.
Empresa TPC desde 1988, desenvolve testes, visando o processamento de dados. Eles se tornaram há muito tempo um padrão da indústria e são usados por quase todos os fornecedores de equipamentos em várias amostras de hardware e software. A principal característica desses testes é que eles visam testar sob uma carga enorme em condições o mais próximo possível dos reais.
O TPC-C simula uma rede de armazém. Inclui uma combinação de cinco transações executadas simultaneamente de vários tipos e complexidade. O banco de dados consiste em nove tabelas com um grande número de registros. O desempenho no teste TPC-C é medido em transações por minuto.
Decidi testar dois ORMs Python (SQLALchemy e PonyORM) usando o método de teste TPC-C adaptado para esta tarefa. O objetivo do teste é avaliar a velocidade do processamento de transações quando vários usuários virtuais acessam o banco de dados ao mesmo tempo.
Descrição de teste
No teste que escrevi, um banco de dados é primeiro criado e preenchido, que é um banco de dados de uma rede de armazéns. O esquema do banco de dados tem esta aparência :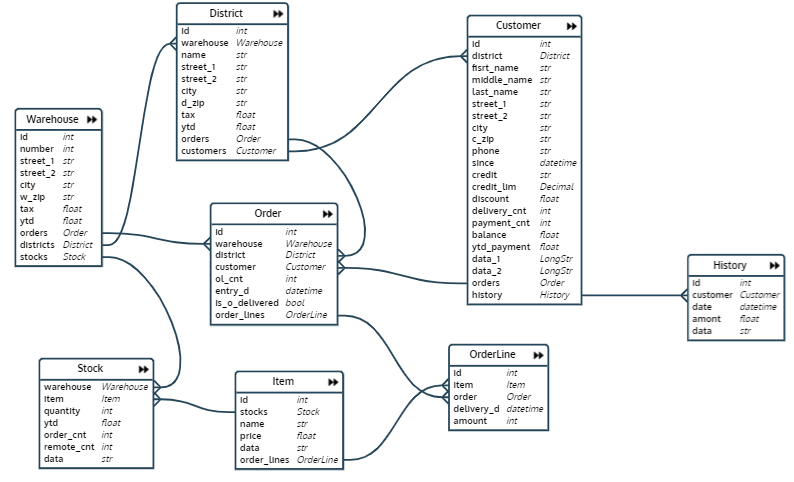
O banco de dados consiste em oito relacionamentos:
- Armazém - armazém
- Distrito - área do armazém
- Order - Order
- OrderLine - linha do pedido (item do pedido)
- Estoque - quantidade de um determinado produto em um armazém específico
- Item - item
- Cliente - cliente
- Histórico - histórico de pagamentos do cliente
, e . . , :
- new_order ( ) — 45%
- payment ( ) — 43%
- order_status ( ) — 4%
- delivery ( ) — 4%
- stock_level ( ) — 4%
, TPC-C.
TPC-C , , ORM, . 64+ , .
:
- ,
- . : Stock 100 000 * W, W — , : 100 * W
- 5 . Payment ID, . ID,
- NewOrder. , , Order, NewOrder. , NewOrder. , , , , , . Order bool “is_o_delivered”, False, ,
, .
New Order
- : id id
- id
- ()
- . Item.
- , .
Payment
- : id id
- id
- .
- 1
- , ,
- .
Status do pedido
- Transações atendidas pelo ID do cliente
- O cliente e seu último pedido são retirados do banco de dados
- O status é retirado do pedido (entregue ou não) e dos itens do pedido
Entrega
- Transações atendidas pelo ID do armazém
- O armazém é solicitado no banco de dados por id e todas as suas seções
- Para cada site, o mais antigo dos pedidos não entregues é recebido. Em cada um deles, o status da entrega muda para True
- Do banco de dados são extraídos usuários cujos pedidos foram entregues durante esta transação e cada um deles aumenta o contador de entrega
Nível de estoque
- Transações atendidas pelo ID do armazém
- O armazém é solicitado no banco de dados por id
- Os últimos 20 pedidos deste armazém são solicitados no banco de dados
- Para cada item desses pedidos do banco de dados, a quantidade de mercadorias restantes no depósito é solicitada
Resultado dos testes
Dois ORMs estão envolvidos nos testes:- SQLAlchemy Os gráficos são representados por uma linha azul.
- PonyORM. Os gráficos são representados pela linha amarela.
10 2 , . multiprocessing.
—
—
PostgreSQL
, TPC-C. Pony .

:
Pony — 2543 /
SQLAlchemy — 1353.4 /
ORM . .
“New Order”

Velocidade média:
Pônei - 3349,2 trans / min
SQLAlchemy - 1415,3 trans / min
Transação "Pagamento"
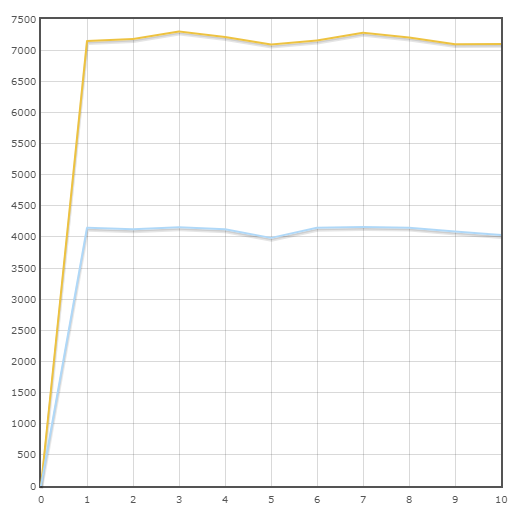
Velocidade média:
Pônei - 7175,3 trans / min
SQLAlchemy - 4110,6 trans / min
Transação "Status do pedido"
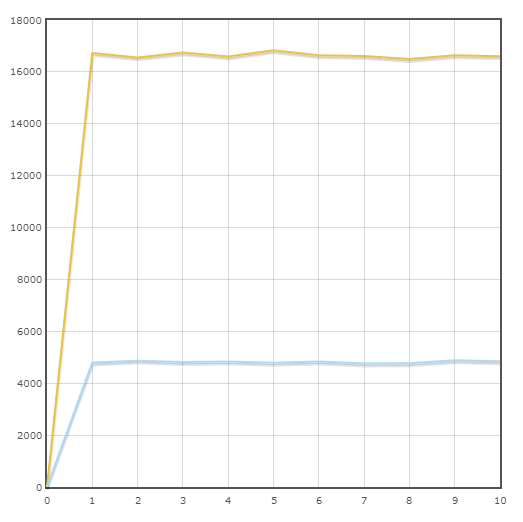
Velocidade média:
Pônei - 16645,6 trans / min
SQLAlchemy - 4820,8 trans / min
Transação "Entrega"
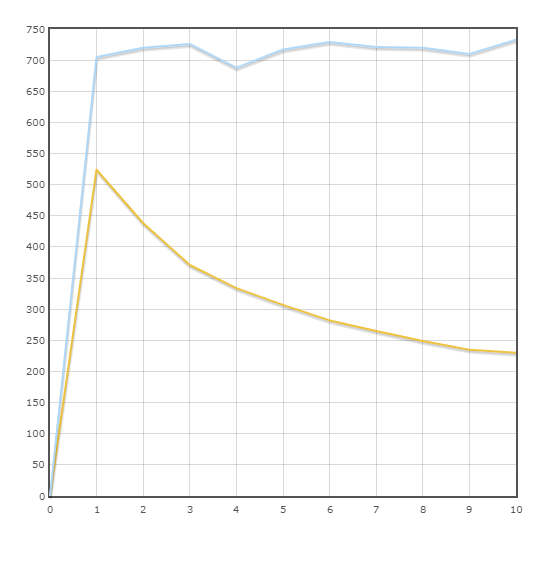
Velocidade média:
SQLAlchemy - 716,9 trans / min
Pony - 323,5 trans / min
Transação "Nível de estoque"
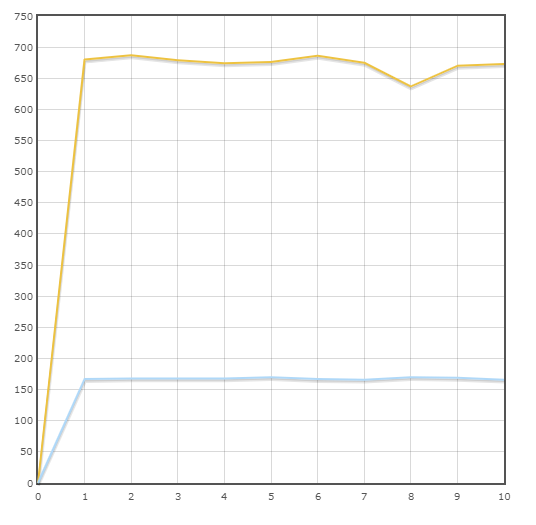
Velocidade média:
Pônei - 677,3 trans / min
SQLAlchemy - 167,9 trans / min
Análise dos Resultados do Teste
Após receber os resultados, analisei por que, em várias situações, um ORM é mais rápido que outro e cheguei às seguintes conclusões:4 5 PonyORM , , SQL PonyORM Python SQL, , SQLALchemy SQL . PonyORM:
stocks = select(stock for stock in Stock
if stock.warehouse == whouse
and stock.item in items).order_by(Stock.id).for_update()
SQLAlchemy:
stocks = session.query(Stock).filter(
Stock.warehouse == whouse, Stock.item.in_(items)).order_by(text("id")).with_for_update()
SQLAlchemy Delivery , UPDATE, , .
, SQLAlchemy:
INFO:sqlalchemy.engine.base.Engine:UPDATE order_line SET delivery_d=%(delivery_d)s WHERE order_line.id = %(order_line_id)s
INFO:sqlalchemy.engine.base.Engine:(
{'delivery_d': datetime.datetime(2020, 4, 6, 14, 33, 6, 922281), 'order_line_id': 316},
{'delivery_d': datetime.datetime(2020, 4, 6, 14, 33, 6, 922272), 'order_line_id': 317},
{'delivery_d': datetime.datetime(2020, 4, 6, 14, 33, 6, 922261))
Pony Update:
SELECT "id", "delivery_d", "item", "amount", "order"
FROM "orderline"
WHERE "order" = %(p1)s
{'p1':911}
UPDATE "orderline"
SET "delivery_d" = %(p1)s
WHERE "id" = %(p2)s
AND "order" = %(p3)s
{'p1':datetime.datetime(2020, 4, 7, 17, 48, 58, 585932), 'p2':5047, 'p3':911}
UPDATE "orderline"
SET "delivery_d" = %(p1)s
WHERE "id" = %(p2)s
AND "order" = %(p3)s
{'p1':datetime.datetime(2020, 4, 7, 17, 48, 58, 585990), 'p2':5048, 'p3':911}
Com base nos resultados desse teste, posso dizer que o Pony funciona muito mais rápido ao buscar em um banco de dados e, em alguns casos, o SQLAlchemy pode produzir consultas de atualização significativamente mais rápidas.No futuro, pretendo testar outros ORMs (Peewee, Django) dessa maneira.
Referências
Código de teste: link do repositório
SQLAlchemy: documentação , comunidade
Pony: documentação , comunidade