O modo remoto de operação no contexto do auto-isolamento universal pode levar a consequências muito ruins. E desgaste emocional - ainda é para onde quer que vá: afinal, não está longe do telhado. Nesse sentido, como muitos, ele tentou se acalmar alocando tempo para outras aulas - e começou a traduzir os artigos mais interessantes do inglês para o russo: "Você dá aprendizado de máquina às massas!".) Devemos prestar homenagem: é uma grande distração. Se você tiver sugestões para o conteúdo semântico e a tradução deste texto para um leitor de língua russa, participe da discussão. Então, aqui está uma tradução da página de previsão de séries temporais da seção manual do tensorflow: link . Minhas adições, juntamente com ilustrações para a tradução, visam ajudar a entender as idéias básicas em uma das áreas mais interessantes de ML e econometria em séries gerais de previsão.Uma pequena introdução antes da tradução.O manual é uma descrição da previsão da temperatura do ar com base em séries temporais unidimensionais ( séries temporais univariadas) e séries temporais multivariadas ( séries temporais multivariadas) . Para cada parte, insira dadosdeve ser preparado em conformidade. Levando em consideração o conjunto de dados meteorológicos considerado neste guia, a separação é a seguinte:
Então, aqui está uma tradução da página de previsão de séries temporais da seção manual do tensorflow: link . Minhas adições, juntamente com ilustrações para a tradução, visam ajudar a entender as idéias básicas em uma das áreas mais interessantes de ML e econometria em séries gerais de previsão.Uma pequena introdução antes da tradução.O manual é uma descrição da previsão da temperatura do ar com base em séries temporais unidimensionais ( séries temporais univariadas) e séries temporais multivariadas ( séries temporais multivariadas) . Para cada parte, insira dadosdeve ser preparado em conformidade. Levando em consideração o conjunto de dados meteorológicos considerado neste guia, a separação é a seguinte: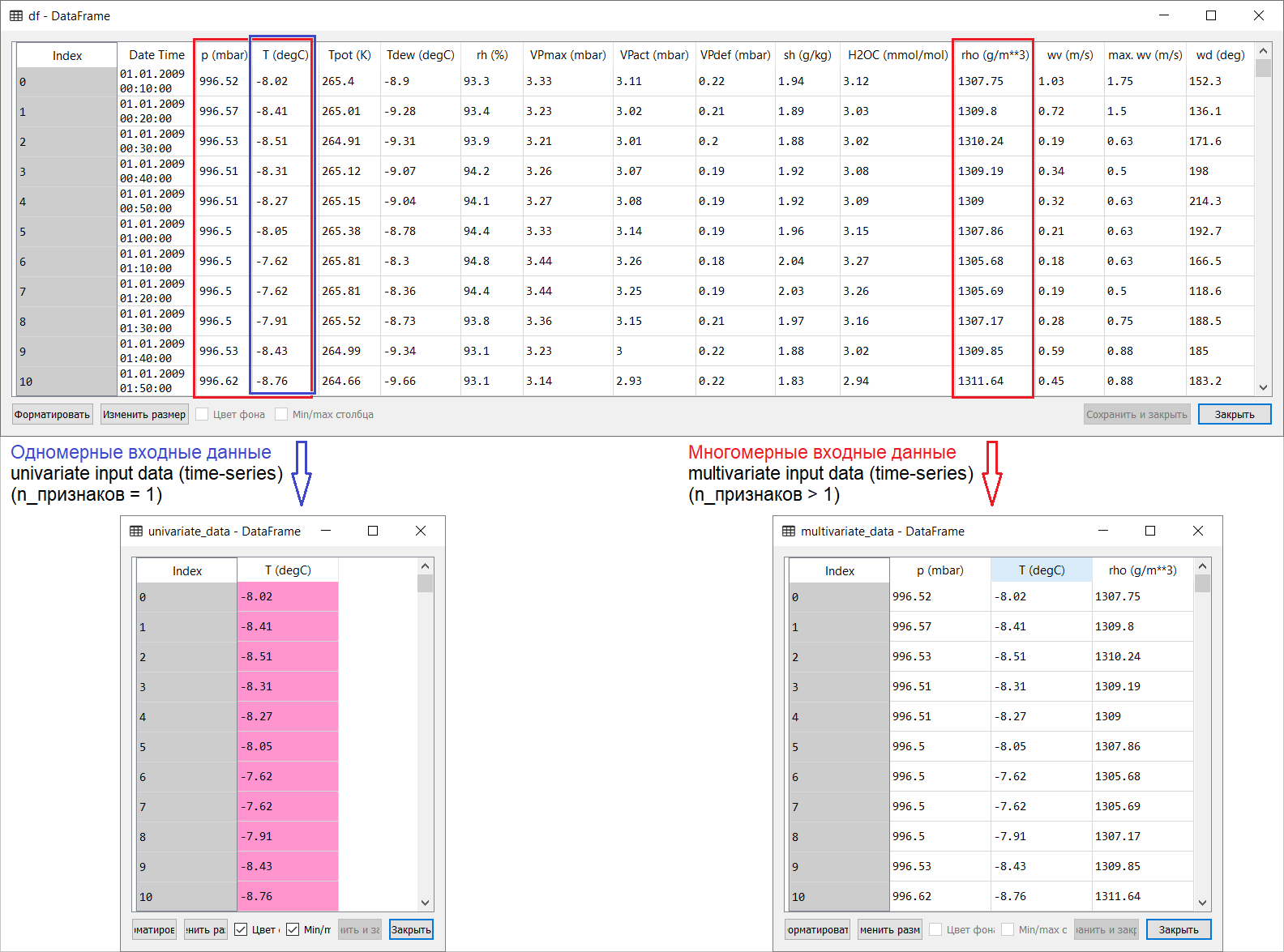 Para perguntas sobre o que levar para X e o que para Y , ou seja, como preparar dados para a classe de treinamento supervisionado, ficará claro nas ilustrações a seguir. Observo apenas que a formação do vetor alvo (Y) para trabalhar com séries temporais unidimensionais e multidimensionais é a mesma: o vetor alvo é compilado com base no sinal T (degC)(temperatura do ar). A diferença entre eles é "enterrada" na formação de um conjunto de recursos que são alimentados à entrada do modelo: no caso de uma série temporal unidimensional para prever a temperatura no futuro, o vetor de entrada (X) consiste em uma característica: na verdade, temperatura do ar; e para multidimensional - mais de um: além da temperatura do ar, p (mbar) (pressão atmosférica) e rho (g / m ** 3) (umidade) são usados no exemplo do manual em questão .A princípio, um exemplo muito raso, com previsão de temperatura, parece pouco convincente do ponto de vista do uso de uma entrada multidimensional: para previsão de temperatura, o sinal mais relevante será a temperatura. No entanto, este não é absolutamente o caso: para desenvolver uma previsão qualitativa da temperatura do ar, muitos fatores devem ser levados em consideração, até a fricção do ar na superfície da terra, etc. Além disso, na prática, algumas coisas estão longe de serem óbvias, e o vetor alvo pode estar na forma dessa mistura (ou borsch). Nesse sentido, a análise exploratória de dados com a seleção dos recursos mais relevantes para a formação subsequente de uma entrada multidimensional é a única decisão correta.Portanto, a tradução do manual é apresentada abaixo. Texto adicional estará em itálico .
Para perguntas sobre o que levar para X e o que para Y , ou seja, como preparar dados para a classe de treinamento supervisionado, ficará claro nas ilustrações a seguir. Observo apenas que a formação do vetor alvo (Y) para trabalhar com séries temporais unidimensionais e multidimensionais é a mesma: o vetor alvo é compilado com base no sinal T (degC)(temperatura do ar). A diferença entre eles é "enterrada" na formação de um conjunto de recursos que são alimentados à entrada do modelo: no caso de uma série temporal unidimensional para prever a temperatura no futuro, o vetor de entrada (X) consiste em uma característica: na verdade, temperatura do ar; e para multidimensional - mais de um: além da temperatura do ar, p (mbar) (pressão atmosférica) e rho (g / m ** 3) (umidade) são usados no exemplo do manual em questão .A princípio, um exemplo muito raso, com previsão de temperatura, parece pouco convincente do ponto de vista do uso de uma entrada multidimensional: para previsão de temperatura, o sinal mais relevante será a temperatura. No entanto, este não é absolutamente o caso: para desenvolver uma previsão qualitativa da temperatura do ar, muitos fatores devem ser levados em consideração, até a fricção do ar na superfície da terra, etc. Além disso, na prática, algumas coisas estão longe de serem óbvias, e o vetor alvo pode estar na forma dessa mistura (ou borsch). Nesse sentido, a análise exploratória de dados com a seleção dos recursos mais relevantes para a formação subsequente de uma entrada multidimensional é a única decisão correta.Portanto, a tradução do manual é apresentada abaixo. Texto adicional estará em itálico .Previsão de Séries Temporais
Este guia é uma introdução à previsão de séries temporais usando redes neurais recorrentes (RNS, da Rede Neural Recorrente em Inglês , RNN ). Consiste em duas partes: a primeira descreve a previsão da temperatura do ar com base em uma série temporal unidimensional e a segunda - com base em uma série temporal multidimensional.import tensorflow as tf
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
import os
import pandas as pd
mpl.rcParams['figure.figsize'] = (8, 6)
mpl.rcParams['axes.grid'] = False
Um conjunto de dados meteorológicosTodos os exemplos do manual usam seqüências temporais de dados meteorológicos gravados em uma estação hidrometeorológica no Instituto de Biogeoquímica com o nome de Max Planck .Esse conjunto de dados inclui medições de 14 indicadores meteorológicos diferentes (como temperatura do ar, pressão atmosférica, umidade), realizados a cada 10 minutos desde 2003. Para economizar tempo e uso de memória, o manual utilizará dados que abrangem o período de 2009 a 2016. Esta seção do conjunto de dados foi preparada por François Chollet para seu livro Deep Learning with Python .zip_path = tf.keras.utils.get_file(
origin='https://storage.googleapis.com/tensorflow/tf-keras-datasets/jena_climate_2009_2016.csv.zip',
fname='jena_climate_2009_2016.csv.zip',
extract=True)
csv_path, _ = os.path.splitext(zip_path)
df = pd.read_csv(csv_path)
Vamos ver o que temos.df.head()
 O fato de o período de gravação da observação ser de 10 minutos pode ser verificado na tabela acima. Assim, em uma hora você terá 6 observações. Por sua vez, 144 (6x24) observações são acumuladas por dia.Digamos que você queira prever a temperatura, que será em 6 horas no futuro. Você faz essa previsão com base nos dados que possui por um determinado período: por exemplo, decide usar 5 dias de observação. Portanto, para treinar o modelo, você deve criar um intervalo de tempo contendo as últimas observações de 720 (5x144) (uma vez que são possíveis configurações diferentes, esse conjunto de dados é uma boa base para experiências).A função abaixo retorna os intervalos de tempo acima para treinar o modelo. Argumento
O fato de o período de gravação da observação ser de 10 minutos pode ser verificado na tabela acima. Assim, em uma hora você terá 6 observações. Por sua vez, 144 (6x24) observações são acumuladas por dia.Digamos que você queira prever a temperatura, que será em 6 horas no futuro. Você faz essa previsão com base nos dados que possui por um determinado período: por exemplo, decide usar 5 dias de observação. Portanto, para treinar o modelo, você deve criar um intervalo de tempo contendo as últimas observações de 720 (5x144) (uma vez que são possíveis configurações diferentes, esse conjunto de dados é uma boa base para experiências).A função abaixo retorna os intervalos de tempo acima para treinar o modelo. Argumentohistory_size- este é o tamanho do último intervalo de tempo target_size- , um argumento que determina até que ponto o modelo o futuro deve aprender a prever. Em outras palavras, target_sizeé o vetor de destino que precisa ser previsto.def univariate_data(dataset, start_index, end_index, history_size, target_size):
data = []
labels = []
start_index = start_index + history_size
if end_index is None:
end_index = len(dataset) - target_size
for i in range(start_index, end_index):
indices = range(i-history_size, i)
data.append(np.reshape(dataset[indices], (history_size, 1)))
labels.append(dataset[i+target_size])
return np.array(data), np.array(labels)
Nas duas partes do manual, as primeiras 300.000 linhas de dados serão usadas para treinar o modelo, e as demais para validá-lo (validar). Nesse caso, a quantidade de dados de treinamento é de aproximadamente 2100 dias.TRAIN_SPLIT = 300000
Para garantir resultados reproduzíveis, a função de semente está definida.tf.random.set_seed(13)
Parte 1. Previsão baseada em uma série temporal unidimensional
Na primeira parte, você treinará o modelo usando apenas um atributo - temperatura; o modelo treinado será usado para prever temperaturas futuras.Para começar, extraímos apenas a temperatura do conjunto de dados.uni_data = df['T (degC)']
uni_data.index = df['Date Time']
uni_data.head()
Date Time
01.01.2009 00:10:00 -8.02
01.01.2009 00:20:00 -8.41
01.01.2009 00:30:00 -8.51
01.01.2009 00:40:00 -8.31
01.01.2009 00:50:00 -8.27
Name: T (degC), dtype: float64
E vamos ver como esses dados mudam com o tempo.uni_data.plot(subplots=True)

uni_data = uni_data.values
Antes de treinar uma rede neural artificial (doravante - RNA), uma etapa importante é a escala de dados. Uma das maneiras comuns de executar o dimensionamento é a padronização ( padronização ), realizada subtraindo a média e dividindo pelo desvio padrão para cada característica. Você também pode usar um método tf.keras.utils.normalizeque dimensiona valores para o intervalo [0,1].Nota : a padronização deve ser realizada apenas com dados de treinamento.uni_train_mean = uni_data[:TRAIN_SPLIT].mean()
uni_train_std = uni_data[:TRAIN_SPLIT].std()
Realizamos padronização de dados.uni_data = (uni_data-uni_train_mean)/uni_train_std
Em seguida, prepararemos os dados para o modelo com uma entrada unidimensional. As últimas 20 observações registradas da temperatura serão alimentadas na entrada do modelo, e o modelo deve ser treinado para prever a temperatura no próximo passo.univariate_past_history = 20
univariate_future_target = 0
x_train_uni, y_train_uni = univariate_data(uni_data, 0, TRAIN_SPLIT,
univariate_past_history,
univariate_future_target)
x_val_uni, y_val_uni = univariate_data(uni_data, TRAIN_SPLIT, None,
univariate_past_history,
univariate_future_target)
Os resultados da aplicação da função univariate_data.print ('Single window of past history')
print (x_train_uni[0])
print ('\n Target temperature to predict')
print (y_train_uni[0])
Single window of past history
[[-1.99766294]
[-2.04281897]
[-2.05439744]
[-2.0312405 ]
[-2.02660912]
[-2.00113649]
[-1.95134907]
[-1.95134907]
[-1.98492663]
[-2.04513467]
[-2.08334362]
[-2.09723778]
[-2.09376424]
[-2.09144854]
[-2.07176515]
[-2.07176515]
[-2.07639653]
[-2.08913285]
[-2.09260639]
[-2.10418486]]
Target temperature to predict
-2.1041848598100876
Além disso: a preparação de dados para um modelo com uma entrada unidimensional é mostrada esquematicamente na figura a seguir (por conveniência, nesta e nas figuras subseqüentes, os dados são apresentados em forma "bruta", antes da padronização e também sem o atributo 'Data e hora' como índice): Agora que os dados adequadamente preparado, considere um exemplo concreto. As informações transmitidas à RNA são destacadas em azul; uma cruz vermelha indica o valor futuro que a RNA deve prever.
Agora que os dados adequadamente preparado, considere um exemplo concreto. As informações transmitidas à RNA são destacadas em azul; uma cruz vermelha indica o valor futuro que a RNA deve prever.def create_time_steps(length):
return list(range(-length, 0))
def show_plot(plot_data, delta, title):
labels = ['History', 'True Future', 'Model Prediction']
marker = ['.-', 'rx', 'go']
time_steps = create_time_steps(plot_data[0].shape[0])
if delta:
future = delta
else:
future = 0
plt.title(title)
for i, x in enumerate(plot_data):
if i:
plt.plot(future, plot_data[i], marker[i], markersize=10,
label=labels[i])
else:
plt.plot(time_steps, plot_data[i].flatten(), marker[i], label=labels[i])
plt.legend()
plt.xlim([time_steps[0], (future+5)*2])
plt.xlabel('Time-Step')
return plt
show_plot([x_train_uni[0], y_train_uni[0]], 0, 'Sample Example')
 Solução básica (sem envolver o aprendizado de máquina)Antes de iniciar o treinamento do modelo, instalaremos uma solução básica simples ( linha de base ). Ele consiste no seguinte: para um determinado vetor de entrada, o método básico da solução “varre” o histórico inteiro e prediz o próximo valor como a média das últimas 20 observações.
Solução básica (sem envolver o aprendizado de máquina)Antes de iniciar o treinamento do modelo, instalaremos uma solução básica simples ( linha de base ). Ele consiste no seguinte: para um determinado vetor de entrada, o método básico da solução “varre” o histórico inteiro e prediz o próximo valor como a média das últimas 20 observações.def baseline(history):
return np.mean(history)
show_plot([x_train_uni[0], y_train_uni[0], baseline(x_train_uni[0])], 0,
'Baseline Prediction Example')
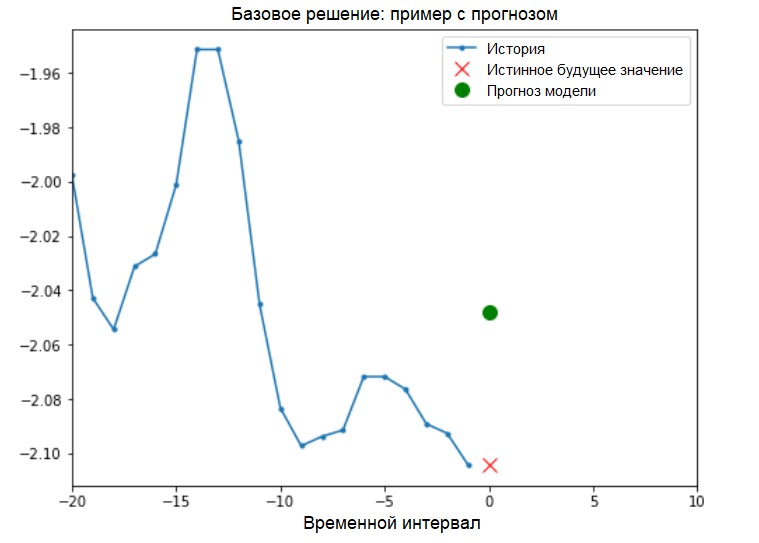 Vamos ver se podemos superar o resultado da "média" usando uma rede neural recorrente.Rede Neural Recorrente Umarede neural recorrente (RNS) é um tipo de RNA que é adequada para resolver problemas de séries temporais. O RNS processa passo a passo a sequência temporal dos dados, classificando seus elementos e preservando o estado interno obtido pelo processamento dos elementos anteriores. Você pode encontrar mais informações sobre o RNS no seguinte guia . Este guia utilizará uma camada especializada de RNC chamada Long Short-Term Memory ( LSTM ).Uso adicional
Vamos ver se podemos superar o resultado da "média" usando uma rede neural recorrente.Rede Neural Recorrente Umarede neural recorrente (RNS) é um tipo de RNA que é adequada para resolver problemas de séries temporais. O RNS processa passo a passo a sequência temporal dos dados, classificando seus elementos e preservando o estado interno obtido pelo processamento dos elementos anteriores. Você pode encontrar mais informações sobre o RNS no seguinte guia . Este guia utilizará uma camada especializada de RNC chamada Long Short-Term Memory ( LSTM ).Uso adicionaltf.dataAleatório, lote e cache do conjunto de dados.Adição:
Mais sobre os métodos de shuffle, batch e cache na página tensorflow :BATCH_SIZE = 256
BUFFER_SIZE = 10000
train_univariate = tf.data.Dataset.from_tensor_slices((x_train_uni, y_train_uni))
train_univariate = train_univariate.cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE).repeat()
val_univariate = tf.data.Dataset.from_tensor_slices((x_val_uni, y_val_uni))
val_univariate = val_univariate.batch(BATCH_SIZE).repeat()
A visualização a seguir deve ajudá-lo a entender como são os dados após o processamento em lote. Pode-se observar que o LSTM requer uma certa forma de entrada de dados, que é fornecida a ele.
Pode-se observar que o LSTM requer uma certa forma de entrada de dados, que é fornecida a ele.simple_lstm_model = tf.keras.models.Sequential([
tf.keras.layers.LSTM(8, input_shape=x_train_uni.shape[-2:]),
tf.keras.layers.Dense(1)
])
simple_lstm_model.compile(optimizer='adam', loss='mae')
Verifique a saída do modelo.for x, y in val_univariate.take(1):
print(simple_lstm_model.predict(x).shape)
(256, 1)
Adição:
em termos gerais, os RNSs trabalham com sequências. Isso significa que os dados fornecidos para a entrada do modelo devem ter o seguinte formato:
[, , - ]
A forma dos dados de treinamento para o modelo com uma entrada unidimensional possui o seguinte formato:print(x_train_uni.shape)
(299980, 20, 1)A seguir, estudaremos o modelo. Devido ao grande tamanho do conjunto de dados e para economizar tempo, cada época passará apenas por 200 etapas ( steps_per_epoch = 200 ) em vez dos dados completos do treinamento, como geralmente é feito.EVALUATION_INTERVAL = 200
EPOCHS = 10
simple_lstm_model.fit(train_univariate, epochs=EPOCHS,
steps_per_epoch=EVALUATION_INTERVAL,
validation_data=val_univariate, validation_steps=50)
Train for 200 steps, validate for 50 steps
Epoch 1/10
200/200 [==============================] - 2s 11ms/step - loss: 0.4075 - val_loss: 0.1351
Epoch 2/10
200/200 [==============================] - 1s 4ms/step - loss: 0.1118 - val_loss: 0.0360
Epoch 3/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0490 - val_loss: 0.0289
Epoch 4/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0444 - val_loss: 0.0257
Epoch 5/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0299 - val_loss: 0.0235
Epoch 6/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0317 - val_loss: 0.0224
Epoch 7/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0287 - val_loss: 0.0206
Epoch 8/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0263 - val_loss: 0.0200
Epoch 9/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0254 - val_loss: 0.0182
Epoch 10/10
200/200 [==============================] - 1s 4ms/step - loss: 0.0228 - val_loss: 0.0174
Previsão usando um modelo LSTM simplesApós concluir a preparação de um modelo LSTM simples, faremos várias previsões.for x, y in val_univariate.take(3):
plot = show_plot([x[0].numpy(), y[0].numpy(),
simple_lstm_model.predict(x)[0]], 0, 'Simple LSTM model')
plot.show()
 Parece melhor que o nível base.Agora que você se familiarizou com o básico, vamos para a segunda parte, que descreve o trabalho com uma série temporal multidimensional.
Parece melhor que o nível base.Agora que você se familiarizou com o básico, vamos para a segunda parte, que descreve o trabalho com uma série temporal multidimensional.Parte 2: Previsão multidimensional de séries temporais
Como afirmado, o conjunto de dados original contém 14 indicadores meteorológicos diferentes. Por simplicidade e conveniência, na segunda parte, apenas três são considerados - temperatura do ar, pressão atmosférica e densidade do ar.Para usar mais recursos, seus nomes devem ser adicionados à lista feature_considered .features_considered = ['p (mbar)', 'T (degC)', 'rho (g/m**3)']
features = df[features_considered]
features.index = df['Date Time']
features.head()
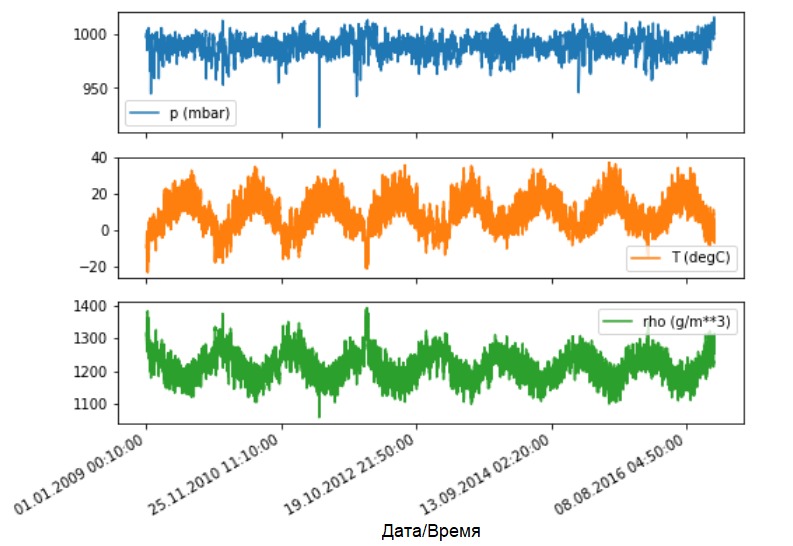
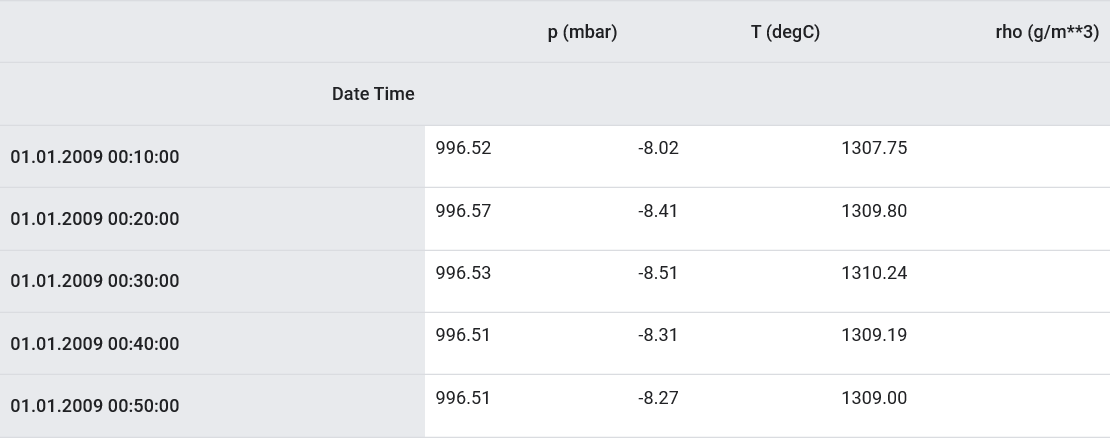 Vamos ver como esses indicadores mudam com o tempo.
Vamos ver como esses indicadores mudam com o tempo.features.plot(subplots=True)
 Como antes, o primeiro passo é padronizar o conjunto de dados com o cálculo do valor médio e desvio padrão dos dados de treinamento.
Como antes, o primeiro passo é padronizar o conjunto de dados com o cálculo do valor médio e desvio padrão dos dados de treinamento.dataset = features.values
data_mean = dataset[:TRAIN_SPLIT].mean(axis=0)
data_std = dataset[:TRAIN_SPLIT].std(axis=0)
dataset = (dataset-data_mean)/data_std
Adição:
Mais adiante neste manual, falaremos sobre previsão de pontos e intervalos.
A linha inferior é a seguinte. Se você precisar que o modelo preveja um valor no futuro (por exemplo, o valor da temperatura após 12 horas) (modelo de uma etapa / etapa única), será necessário treinar o modelo para que ele preveja apenas um valor no futuro. Se a tarefa é prever o intervalo de valores no futuro (por exemplo, temperaturas por hora nas próximas 12 horas) (modelo de várias etapas), o modelo também deve ser treinado para prever o intervalo de valores no futuro. Previsão de pontosNesse caso, o modelo é treinado para prever um valor no futuro com base em algum histórico disponível.A função abaixo executa a mesma tarefa de organizar intervalos de tempo apenas com a diferença de que aqui ela seleciona as observações mais recentes com base em um determinado tamanho de etapa.
Previsão de pontosNesse caso, o modelo é treinado para prever um valor no futuro com base em algum histórico disponível.A função abaixo executa a mesma tarefa de organizar intervalos de tempo apenas com a diferença de que aqui ela seleciona as observações mais recentes com base em um determinado tamanho de etapa.def multivariate_data(dataset, target, start_index, end_index, history_size,
target_size, step, single_step=False):
data = []
labels = []
start_index = start_index + history_size
if end_index is None:
end_index = len(dataset) - target_size
for i in range(start_index, end_index):
indices = range(i-history_size, i, step)
data.append(dataset[indices])
if single_step:
labels.append(target[i+target_size])
else:
labels.append(target[i:i+target_size])
return np.array(data), np.array(labels)
Neste guia, a ANN opera com dados dos últimos cinco (5) dias, ou seja, 720 observações (6x24x5). Suponha que a seleção dos dados seja realizada não a cada 10 minutos, mas a cada hora: em 60 minutos, não são esperadas mudanças bruscas. Portanto, a história dos últimos cinco dias consiste em 120 observações (720/6). Para um modelo que realiza previsão de pontos, o objetivo é ler a temperatura após 12 horas no futuro. Nesse caso, o vetor alvo será a temperatura após 72 (12x6) observações ( consulte a seguinte adição. - Tradutor aprox. ).past_history = 720
future_target = 72
STEP = 6
x_train_single, y_train_single = multivariate_data(dataset, dataset[:, 1], 0,
TRAIN_SPLIT, past_history,
future_target, STEP,
single_step=True)
x_val_single, y_val_single = multivariate_data(dataset, dataset[:, 1],
TRAIN_SPLIT, None, past_history,
future_target, STEP,
single_step=True)
Verifique o intervalo de tempo.print ('Single window of past history : {}'.format(x_train_single[0].shape))
Single window of past history : (120, 3)
train_data_single = tf.data.Dataset.from_tensor_slices((x_train_single, y_train_single))
train_data_single = train_data_single.cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE).repeat()
val_data_single = tf.data.Dataset.from_tensor_slices((x_val_single, y_val_single))
val_data_single = val_data_single.batch(BATCH_SIZE).repeat()
single_step_model = tf.keras.models.Sequential()
single_step_model.add(tf.keras.layers.LSTM(32,
input_shape=x_train_single.shape[-2:]))
single_step_model.add(tf.keras.layers.Dense(1))
single_step_model.compile(optimizer=tf.keras.optimizers.RMSprop(), loss='mae')
Verificaremos nossa amostra e derivaremos as curvas de perda nas etapas de treinamento e verificação.for x, y in val_data_single.take(1):
print(single_step_model.predict(x).shape)
(256, 1)
single_step_history = single_step_model.fit(train_data_single, epochs=EPOCHS,
steps_per_epoch=EVALUATION_INTERVAL,
validation_data=val_data_single,
validation_steps=50)
Train for 200 steps, validate for 50 steps
Epoch 1/10
200/200 [==============================] - 4s 18ms/step - loss: 0.3090 - val_loss: 0.2646
Epoch 2/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2624 - val_loss: 0.2435
Epoch 3/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2616 - val_loss: 0.2472
Epoch 4/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2567 - val_loss: 0.2442
Epoch 5/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2263 - val_loss: 0.2346
Epoch 6/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2416 - val_loss: 0.2643
Epoch 7/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2411 - val_loss: 0.2577
Epoch 8/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2410 - val_loss: 0.2388
Epoch 9/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2447 - val_loss: 0.2485
Epoch 10/10
200/200 [==============================] - 2s 9ms/step - loss: 0.2388 - val_loss: 0.2422
def plot_train_history(history, title):
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(loss))
plt.figure()
plt.plot(epochs, loss, 'b', label='Training loss')
plt.plot(epochs, val_loss, 'r', label='Validation loss')
plt.title(title)
plt.legend()
plt.show()
plot_train_history(single_step_history,
'Single Step Training and validation loss')
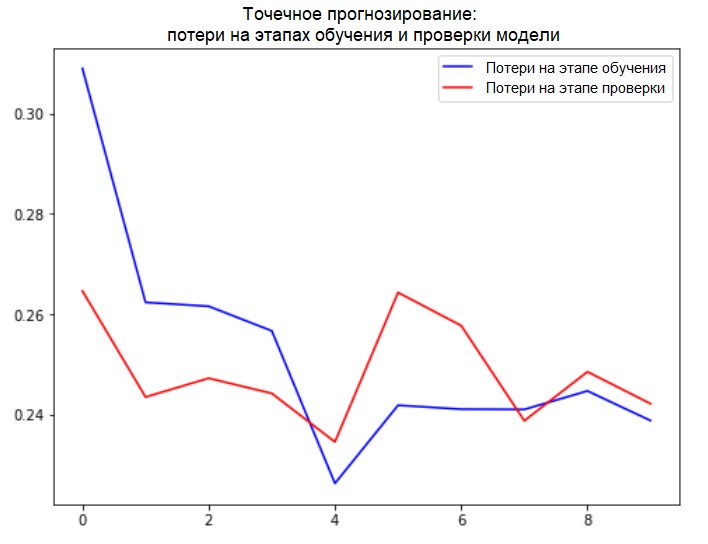 Adição:
Adição:
A preparação de dados para um modelo com uma entrada multidimensional executando a previsão de pontos é mostrada esquematicamente na figura a seguir. Por conveniência e uma representação mais visual da preparação dos dados, o argumento STEPé 1. Observe que nas funções geradoras fornecidas, o argumento é STEP destinado apenas à formação da história e não ao vetor de destino.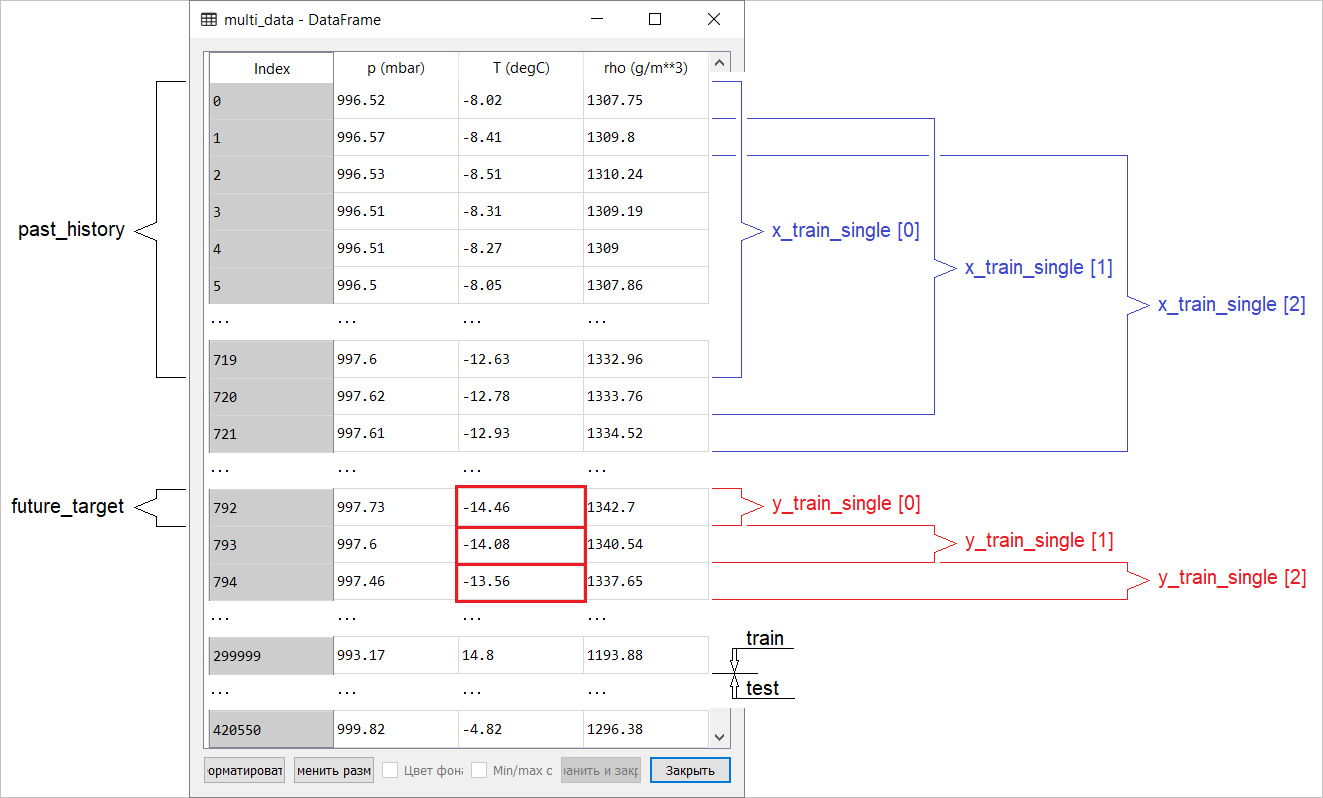 Neste caso, ele
Neste caso, ele x_train_singletem a forma (299280, 720, 3).
Quando STEP=6, o formulário assumirá o seguinte formato: (299280, 120, 3)e a velocidade da função aumentará significativamente. Em geral, você precisa dar crédito ao programador: os geradores apresentados no manual são muito vorazes em termos de consumo de memória.Executando uma previsão de pontoAgora que o modelo foi treinado, executaremos várias previsões de teste. O histórico de observações de três sinais nos últimos cinco dias, selecionado a cada hora (intervalo de tempo = 120), é alimentado na entrada do modelo. Como nosso objetivo é prever apenas a temperatura, os valores anteriores da temperatura ( histórico ) são exibidos em azul no gráfico . A previsão foi feita meio dia no futuro (daí a diferença entre a história e o valor previsto).for x, y in val_data_single.take(3):
plot = show_plot([x[0][:, 1].numpy(), y[0].numpy(),
single_step_model.predict(x)[0]], 12,
'Single Step Prediction')
plot.show()
 Previsão de intervaloNesse caso, com base em algum histórico disponível, o modelo é treinado para prever o intervalo de valores futuros. Assim, ao contrário de um modelo que prevê apenas um valor no futuro, esse modelo prevê uma sequência de valores no futuro.Suponha que, como no caso do modelo que executa a previsão de pontos, os dados de treinamento sejam as medidas horárias dos últimos cinco dias (720/6). No entanto, nesse caso, o modelo deve ser treinado para prever a temperatura pelas próximas 12 horas. Como as observações são registradas a cada 10 minutos, a saída do modelo deve consistir em 72 previsões. Para concluir esta tarefa, é necessário preparar o conjunto de dados novamente, mas com um intervalo de destino diferente.
Previsão de intervaloNesse caso, com base em algum histórico disponível, o modelo é treinado para prever o intervalo de valores futuros. Assim, ao contrário de um modelo que prevê apenas um valor no futuro, esse modelo prevê uma sequência de valores no futuro.Suponha que, como no caso do modelo que executa a previsão de pontos, os dados de treinamento sejam as medidas horárias dos últimos cinco dias (720/6). No entanto, nesse caso, o modelo deve ser treinado para prever a temperatura pelas próximas 12 horas. Como as observações são registradas a cada 10 minutos, a saída do modelo deve consistir em 72 previsões. Para concluir esta tarefa, é necessário preparar o conjunto de dados novamente, mas com um intervalo de destino diferente.future_target = 72
x_train_multi, y_train_multi = multivariate_data(dataset, dataset[:, 1], 0,
TRAIN_SPLIT, past_history,
future_target, STEP)
x_val_multi, y_val_multi = multivariate_data(dataset, dataset[:, 1],
TRAIN_SPLIT, None, past_history,
future_target, STEP)
Verifique a seleção.print ('Single window of past history : {}'.format(x_train_multi[0].shape))
print ('\n Target temperature to predict : {}'.format(y_train_multi[0].shape))
Single window of past history : (120, 3)
Target temperature to predict : (72,)
train_data_multi = tf.data.Dataset.from_tensor_slices((x_train_multi, y_train_multi))
train_data_multi = train_data_multi.cache().shuffle(BUFFER_SIZE).batch(BATCH_SIZE).repeat()
val_data_multi = tf.data.Dataset.from_tensor_slices((x_val_multi, y_val_multi))
val_data_multi = val_data_multi.batch(BATCH_SIZE).repeat()
Adição: a diferença na formação do vetor alvo para o "modelo de intervalo" do "modelo de ponto" é vista na figura a seguir. Vamos preparar a visualização.
Vamos preparar a visualização.def multi_step_plot(history, true_future, prediction):
plt.figure(figsize=(12, 6))
num_in = create_time_steps(len(history))
num_out = len(true_future)
plt.plot(num_in, np.array(history[:, 1]), label='History')
plt.plot(np.arange(num_out)/STEP, np.array(true_future), 'bo',
label='True Future')
if prediction.any():
plt.plot(np.arange(num_out)/STEP, np.array(prediction), 'ro',
label='Predicted Future')
plt.legend(loc='upper left')
plt.show()
Neste e em gráficos similares subsequentes, o histórico e os dados futuros são de hora em hora.for x, y in train_data_multi.take(1):
multi_step_plot(x[0], y[0], np.array([0]))
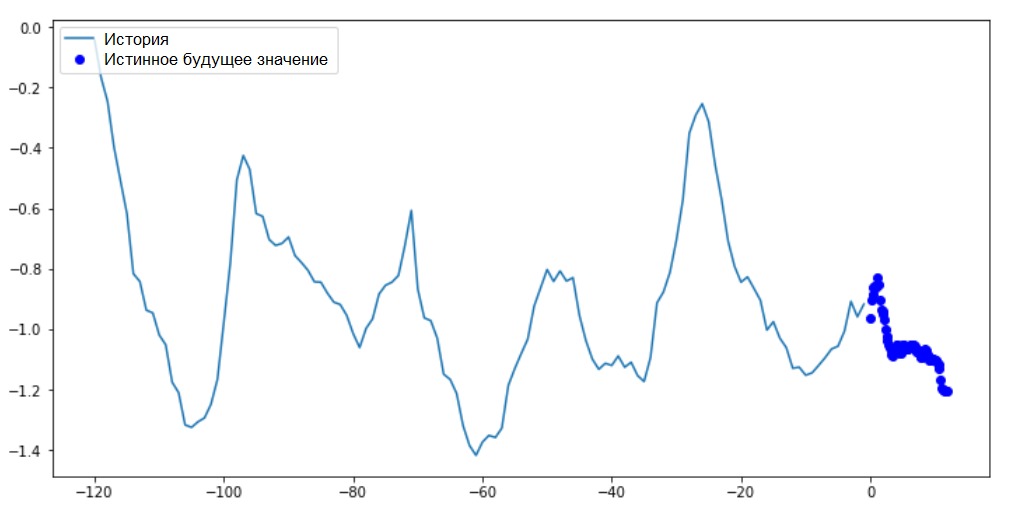 Como essa tarefa é um pouco mais complicada que a anterior, o modelo consistirá em duas camadas LSTM. Finalmente, uma vez que são realizadas 72 previsões, a camada de saída possui 72 neurônios.
Como essa tarefa é um pouco mais complicada que a anterior, o modelo consistirá em duas camadas LSTM. Finalmente, uma vez que são realizadas 72 previsões, a camada de saída possui 72 neurônios.multi_step_model = tf.keras.models.Sequential()
multi_step_model.add(tf.keras.layers.LSTM(32,
return_sequences=True,
input_shape=x_train_multi.shape[-2:]))
multi_step_model.add(tf.keras.layers.LSTM(16, activation='relu'))
multi_step_model.add(tf.keras.layers.Dense(72))
multi_step_model.compile(optimizer=tf.keras.optimizers.RMSprop(clipvalue=1.0), loss='mae')
Verificaremos nossa amostra e derivaremos as curvas de perda nas etapas de treinamento e verificação.for x, y in val_data_multi.take(1):
print (multi_step_model.predict(x).shape)
(256, 72)
multi_step_history = multi_step_model.fit(train_data_multi, epochs=EPOCHS,
steps_per_epoch=EVALUATION_INTERVAL,
validation_data=val_data_multi,
validation_steps=50)
Train for 200 steps, validate for 50 steps
Epoch 1/10
200/200 [==============================] - 21s 103ms/step - loss: 0.4952 - val_loss: 0.3008
Epoch 2/10
200/200 [==============================] - 18s 89ms/step - loss: 0.3474 - val_loss: 0.2898
Epoch 3/10
200/200 [==============================] - 18s 89ms/step - loss: 0.3325 - val_loss: 0.2541
Epoch 4/10
200/200 [==============================] - 18s 89ms/step - loss: 0.2425 - val_loss: 0.2066
Epoch 5/10
200/200 [==============================] - 18s 89ms/step - loss: 0.1963 - val_loss: 0.1995
Epoch 6/10
200/200 [==============================] - 18s 90ms/step - loss: 0.2056 - val_loss: 0.2119
Epoch 7/10
200/200 [==============================] - 18s 91ms/step - loss: 0.1978 - val_loss: 0.2079
Epoch 8/10
200/200 [==============================] - 18s 89ms/step - loss: 0.1957 - val_loss: 0.2033
Epoch 9/10
200/200 [==============================] - 18s 90ms/step - loss: 0.1977 - val_loss: 0.1860
Epoch 10/10
200/200 [==============================] - 18s 88ms/step - loss: 0.1904 - val_loss: 0.1863
plot_train_history(multi_step_history, 'Multi-Step Training and validation loss')
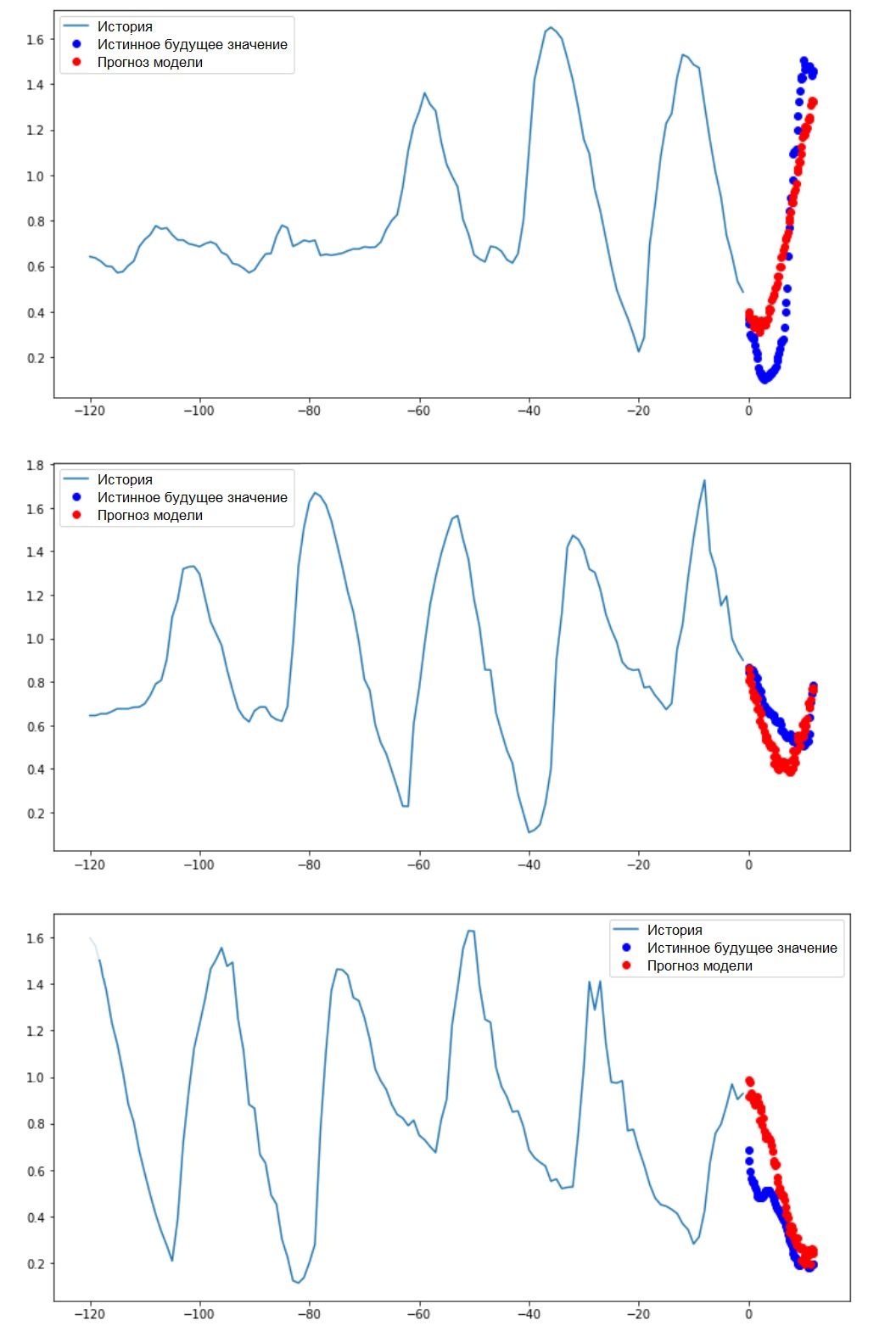
 Executando uma previsão de intervaloEntão, vamos descobrir com que êxito uma RNA treinada lida com previsões de valores futuros de temperatura.
Executando uma previsão de intervaloEntão, vamos descobrir com que êxito uma RNA treinada lida com previsões de valores futuros de temperatura.for x, y in val_data_multi.take(3):
multi_step_plot(x[0], y[0], multi_step_model.predict(x)[0])
Próximos passos
Este guia é uma breve introdução à previsão de séries temporais usando o RNS. Agora você pode tentar prever o mercado de ações e se tornar um bilionário (no original, exatamente assim :). - Nota tradutor) .Além disso, você pode escrever seu próprio gerador para preparar dados, em vez da função uni / multivariate_data , a fim de usar a memória com mais eficiência. Você também pode se familiarizar com o trabalho de “ janelas em série temporal ” e trazer suas idéias para este guia.Para um entendimento mais aprofundado, é recomendável que você leia o capítulo 15 do livro "Aprendizado de máquina aplicado com o Scikit-Learn, Keras e TensorFlow" (Aurelien Geron, 2ª edição) e o capítulo 6 do livro"Aprendizagem profunda em Python" (Francois Scholl).Adição final
Enquanto estiver em casa, cuide não apenas da sua saúde, mas também tenha pena do computador executando exemplos do manual em um conjunto de dados truncados. Por exemplo, levando em consideração a proporção de 70x30 (treinamento / teste), você pode limitar da seguinte forma:dataset = features[300000:].values
TRAIN_SPLIT = 85000