Uma vez que se tornou interessante quais tópicos o LDA (colocação latente de Dirichlet) destacaria nos materiais do "Live Journal". Como se costuma dizer, há interesse - não há problema.Para iniciantes, um pouco sobre o LDA nos dedos, não entraremos em detalhes matemáticos (qualquer pessoa interessada - lê). Portanto, o LDA - é um dos algoritmos mais comuns para modelagem de tópicos. Cada documento (seja um artigo, um livro ou qualquer outra fonte de dados textuais) é uma mistura de tópicos e cada tópico é uma mistura de palavras.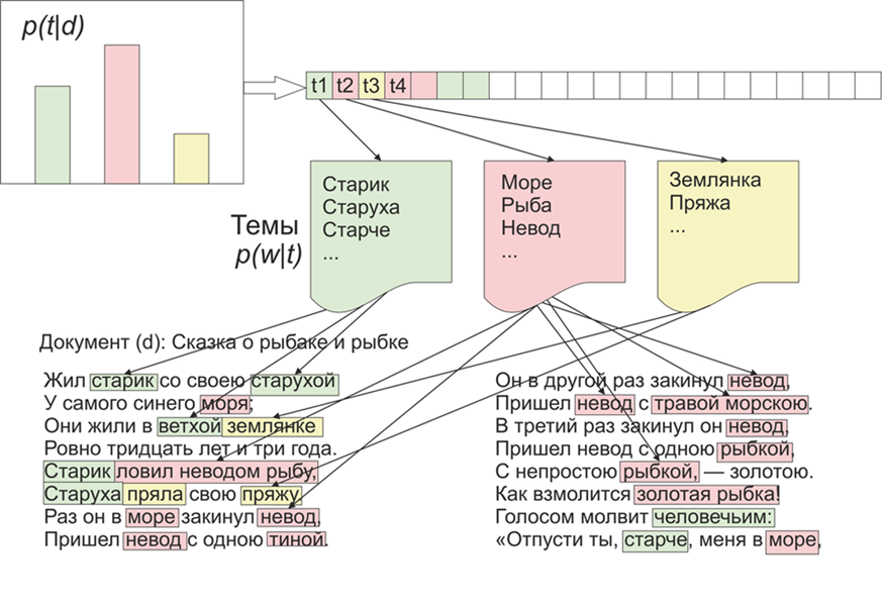 Imagem retirada da WikipediaAssim, a tarefa da LDA é encontrar grupos de palavras que formam tópicos de uma coleção de documentos. Em seguida, com base em tópicos, você pode agrupar textos ou simplesmente destacar palavras-chave.Cerca de 1800 artigos foram recebidos do site LifeJournal, todos eles foram convertidos para o formato jsonl.Deixareios artigos não limpos no disco Yandex . Faremos uma limpeza e normalização dos dados: jogue fora os comentários, exclua as palavras de parada (a lista junto com o código fonte está disponível no github), traremos todas as palavras para ortografia minúscula, removeremos pontuação e palavras que contenham 3 letras ou menos. Mas uma das principais operações de pré-processamento: a exclusão de palavras que ocorrem com frequência, em princípio, pode ser limitada à exclusão de apenas palavras de parada, mas as palavras usadas com frequência serão incluídas em quase todos os tópicos com alta probabilidade. Nesse caso, será possível pós-processar e excluir essas palavras. A escolha é sua.
Imagem retirada da WikipediaAssim, a tarefa da LDA é encontrar grupos de palavras que formam tópicos de uma coleção de documentos. Em seguida, com base em tópicos, você pode agrupar textos ou simplesmente destacar palavras-chave.Cerca de 1800 artigos foram recebidos do site LifeJournal, todos eles foram convertidos para o formato jsonl.Deixareios artigos não limpos no disco Yandex . Faremos uma limpeza e normalização dos dados: jogue fora os comentários, exclua as palavras de parada (a lista junto com o código fonte está disponível no github), traremos todas as palavras para ortografia minúscula, removeremos pontuação e palavras que contenham 3 letras ou menos. Mas uma das principais operações de pré-processamento: a exclusão de palavras que ocorrem com frequência, em princípio, pode ser limitada à exclusão de apenas palavras de parada, mas as palavras usadas com frequência serão incluídas em quase todos os tópicos com alta probabilidade. Nesse caso, será possível pós-processar e excluir essas palavras. A escolha é sua.stop=open('stop.txt')
stop_words=[]
for line in stop:
stop_words.append(line)
for i in range(0,len(stop_words)):
stop_words[i]=stop_words[i][:-1]
texts=[re.split( r' [\w\.\&\?!,_\-#)(:;*%$№"\@]* ' ,texts[i])[0].replace("\n","") for i in range(0,len(texts))]
texts=[test_re(line) for line in texts]
texts=[t.lower() for t in texts]
texts = [[word for word in document.split() if word not in stop_words] for document in texts]
texts=[[word for word in document if len(word)>=3]for document in texts]
A seguir, trazemos todas as palavras para a forma normal: para isso, usamos a biblioteca pymorphy2, que pode ser instalada via pip.morph = pymorphy2.MorphAnalyzer()
for i in range(0,len(texts)):
for j in range(0,len(texts[i])):
texts[i][j] = morph.parse(texts[i][j])[0].normal_form
Sim, perderemos informações sobre a forma das palavras, mas, neste contexto, estamos mais interessados na compatibilidade das palavras entre si. É aqui que nosso pré-processamento é concluído, não está completo, mas é suficiente para ver como o algoritmo LDA funciona.Além disso, o ponto mencionado acima, em princípio, pode ser omitido, mas, na minha opinião, os resultados são mais adequados, novamente, qual será o limite, você decide, por exemplo, que pode criar uma função que depende do tamanho médio dos documentos e do número deles :counter = collections.Counter()
for t in texts:
for r in t:
counter[r]+=1
limit = len(texts)/5
too_common = [w for w in counter if counter[w] > limit]
too_common=set(too_common)
texts = [[word for word in document if word not in too_common] for document in texts]
Vamos prosseguir diretamente para o treinamento do modelo, para isso precisamos instalar a biblioteca gensim, que contém vários pães legais. Primeiro você precisa codificar todas as palavras, a função Dicionário fará isso por nós, depois substituiremos as palavras pelos seus equivalentes numéricos. A versão comentada da chamada LDA é mais longa, pois é atualizada após cada documento, você pode brincar com as configurações e selecionar a opção apropriada.texts=preposition_text_for_lda(my_r)
dictionary = gensim.corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
lda = gensim.models.ldamodel.LdaModel(corpus=corpus, id2word=dictionary, num_topics=10)
Após o trabalho do programa, os tópicos podem ser visualizados usando o comandolda.show_topic(i,topn=30)
, em que i é o número do tópico e topn é o número de palavras no tópico a ser exibido.Agora, um pequeno bônus para a visualização de temas; para isso, você precisa instalar a biblioteca do wordcloud (como utilitários semelhantes também estão no matplotlib). Esse código visualiza os temas e os salva na pasta atual.from wordcloud import WordCloud, STOPWORDS
for i in range(0,10):
a=lda.show_topic(i,topn=30)
wordcloud = WordCloud(
relative_scaling = 1.0,
stopwords = too_common
).generate_from_frequencies(dict(a))
wordcloud.to_file('society'+str(i)+'.png')
E, finalmente, alguns exemplos dos tópicos que obtive:
 Experimente e você poderá obter resultados ainda mais significativos.
Experimente e você poderá obter resultados ainda mais significativos.