 A foto que você vê é tirada do site DeepMind e mostra 57 jogos nos quais seu mais recente desenvolvimento Agent57 ( revisão do artigo sobre Habré ) alcançou sucesso. O número 57 em si não foi retirado do teto - exatamente tantos jogos foram escolhidos em 2012 para se tornar uma espécie de referência entre os desenvolvedores de IA para jogos da Atari, após os quais vários pesquisadores medem suas realizações nesse conjunto de dados em particular.Neste post, tentarei analisar essas realizações de diferentes ângulos, a fim de avaliar seu valor para as tarefas aplicadas e justificar por que não acredito que este seja o futuro. Bem, sim, haverá muitas fotos sob o corte, eu avisei.No link acima, os desenvolvedores escrevem as coisas certas, dizendo que
A foto que você vê é tirada do site DeepMind e mostra 57 jogos nos quais seu mais recente desenvolvimento Agent57 ( revisão do artigo sobre Habré ) alcançou sucesso. O número 57 em si não foi retirado do teto - exatamente tantos jogos foram escolhidos em 2012 para se tornar uma espécie de referência entre os desenvolvedores de IA para jogos da Atari, após os quais vários pesquisadores medem suas realizações nesse conjunto de dados em particular.Neste post, tentarei analisar essas realizações de diferentes ângulos, a fim de avaliar seu valor para as tarefas aplicadas e justificar por que não acredito que este seja o futuro. Bem, sim, haverá muitas fotos sob o corte, eu avisei.No link acima, os desenvolvedores escrevem as coisas certas, dizendo queSo although average scores have increased, until now, the number of above human games has not. As an illustrative example, consider a benchmark consisting of twenty tasks. Suppose agent A obtains a score of 500% on eight tasks, 200% on four tasks, and 0% on eight tasks (mean = 240%, median = 200%), while agent B obtains a score of 150% on all tasks (mean = median = 150%). On average, agent A performs better than agent B. However, agent B possesses a more general ability: it obtains human-level performance on more tasks than agent A.
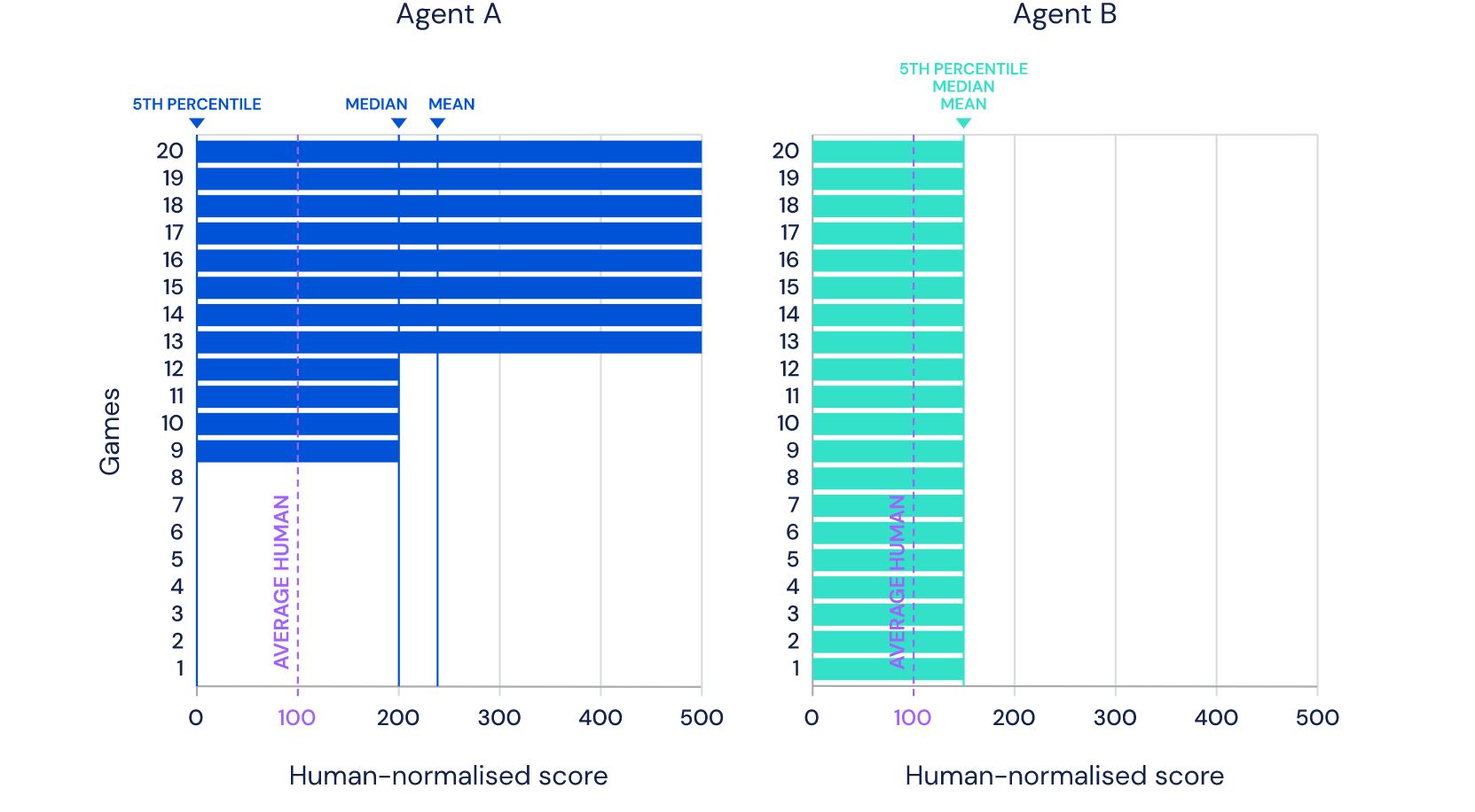 O que, nos dedos, significa que antes que todos fossem medidos na classificação "média", descartando os casos difíceis para um computador, mas agora eles assumiram apenas eles. E assim, eles alcançaram uma superioridade real sobre o homem, e não super-resultados em casos compatíveis com o computador.Mas vamos analisar o problema de maneira mais global para entender se é assim. Qual é a interação da DeepMind AI com um videogameA seguir, um asterisco indicará entidades obtidas por um algoritmo criado não com a ajuda da IA, mas com a ajuda da opinião de especialistas.Antes de desmontar o circuito, vejamos uma abordagem alternativa:
O que, nos dedos, significa que antes que todos fossem medidos na classificação "média", descartando os casos difíceis para um computador, mas agora eles assumiram apenas eles. E assim, eles alcançaram uma superioridade real sobre o homem, e não super-resultados em casos compatíveis com o computador.Mas vamos analisar o problema de maneira mais global para entender se é assim. Qual é a interação da DeepMind AI com um videogameA seguir, um asterisco indicará entidades obtidas por um algoritmo criado não com a ajuda da IA, mas com a ajuda da opinião de especialistas.Antes de desmontar o circuito, vejamos uma abordagem alternativa:Resumo do vídeo- + ,

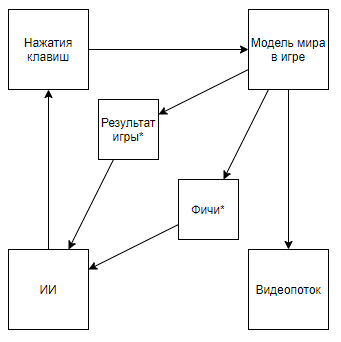 O esquema se torna assim. E se você subir no canal do autor, poderá encontrar sua aplicação em jogos retrô. Alterando o esquema para este, chegamos à conclusão de que a velocidade e a eficácia do treinamento estão crescendo em ordens de magnitude, mas o valor científico e de engenharia das realizações de uma viagem dessas se aproxima de 0 (e sim, não levo em conta o valor da popularização).Podemos supor que o ponto principal é que o vídeo é lançado do pipeline, mas considere o seguinte esquema (tenho certeza que alguém implementou algo semelhante, mas não há nenhum link em mãos):Isso é implementado quando um especialista que conhece os recursos necessários grava um analisador de fluxo de vídeo que calcula os recursos usando os pixels principais.Ou mesmo esse esquema:Onde primeiro, o AI1 é treinado para extrair recursos selecionados por um especialista do vídeo.E então o AI2 é ensinado a reproduzir por recursos extraídos do fluxo de vídeo usando o AI1. Então, nós temos um esquema que:
O esquema se torna assim. E se você subir no canal do autor, poderá encontrar sua aplicação em jogos retrô. Alterando o esquema para este, chegamos à conclusão de que a velocidade e a eficácia do treinamento estão crescendo em ordens de magnitude, mas o valor científico e de engenharia das realizações de uma viagem dessas se aproxima de 0 (e sim, não levo em conta o valor da popularização).Podemos supor que o ponto principal é que o vídeo é lançado do pipeline, mas considere o seguinte esquema (tenho certeza que alguém implementou algo semelhante, mas não há nenhum link em mãos):Isso é implementado quando um especialista que conhece os recursos necessários grava um analisador de fluxo de vídeo que calcula os recursos usando os pixels principais.Ou mesmo esse esquema:Onde primeiro, o AI1 é treinado para extrair recursos selecionados por um especialista do vídeo.E então o AI2 é ensinado a reproduzir por recursos extraídos do fluxo de vídeo usando o AI1. Então, nós temos um esquema que:- Usa um fluxo de vídeo e não tem acesso direto ao modelo do mundo.
- Não depende de analisadores de fluxo de vídeo escritos por um especialista
- Às vezes, ele será treinado com mais facilidade e eficiência do que o desenvolvimento do DeepMind
Mas ... chegamos à mesma coisa. Tal implementação, novamente, não terá valor científico nem de engenharia no contexto da aplicação a jogos retrô, já que o AI1 é uma tarefa muito antiga e resolvida por algoritmos modernos de processamento de imagens, e o AI2 também é criado de maneira rápida e simples, o que confirma o autor do vídeo acima .Então, qual é o valor dos algoritmos DeepMind para os jogos da Atari? Vou tentar resumir: o valor é esseOs algoritmos DeepMind são capazes de encontrar a estratégia de comportamento ideal para jogos com um modelo primitivo do mundo MM em condições em que o modelo do estado do mundo S (MM, t) é representado com distorções significativas por uma determinada função de distorção F (S (MM, t)), apenas a qualidade das decisões tomadas pode ser avaliada uma função que recebe uma sequência de valores F (S (MM, t)) e reações de algoritmo, e essa sequência é de tamanho desconhecido (o jogo pode terminar em um número diferente de etapas), mas você pode repetir o experimento um número infinito de vezes .Antecipando problemas, . S(MM, t) , , . F(S(MM, t)) , .
Agora, vamos tentar avaliar a aplicabilidade de tal valor para resolver problemas do mundo real que de alguma forma se correlacionam com as ferramentas, ou seja, eles representam um estado real com distorções significativas, implicam que o ambiente responde às ações do agente, faz uma avaliação apenas após uma longa sequência de decisões, e no entanto, eles permitem que o experimento seja realizado várias vezes.À primeira vista, uma aplicação interessante parece ser um jogo na bolsa. Até as dicas do Google, que a traem como a única dica para o uso no mundo real, sugerem que o assunto é interessante.Apontarei imediatamente um ponto importante - quase todas as abordagens à análise de mercado (sem contar as abordagens que analisam objetos do mundo real, como estacionamentos em frente a supermercados, notícias, menções a ações no Twitter) podem ser divididas em dois tipos. O primeiro tipo é abordagens que representam o mercado como uma série temporal. Segundo, como um fluxo de aplicativos.De alguma forma, os defensores das abordagens do primeiro tipo veem o mercado Mas a diferença fundamental não está nos dados utilizados, mas no fato de que, regra geral, aqueles que analisam o mercado, como uma série temporal, negligenciam sua influência no mercado, acreditando que, condicionalmente, no intervalo diário, suas transações não afetarão a dinâmica adicional do mercado. Embora os apoiadores da segunda abordagem possam negligenciar, acreditando que seu volume seja insignificante em relação à liquidez do mercado, e considerem o mercado como um sistema de feedback, acreditando que suas ações afetam o comportamento de outros players (por exemplo, pesquisas e abordagens relacionadas à execução ótima de grandes encomendas, criação de mercado e negociação de alta frequência).Depois de examinar os resultados da pesquisa, fica claro que todos os artigos e postagens dedicados à negociação usando treinamento de reforço (o tópico mais próximo dos sucessos do DeepMind) são dedicados à primeira abordagem. Mas surge uma pergunta razoável sobre a proporcionalidade da abordagem do problema.Primeiro, vamos desenhar um diagrama semelhante aos jogos da Atari.Realidade objetiva, . , , , , — . , , . , , , , , . , .
Parece que tudo cai lindamente. E suspeito que essa semelhança também esquente o hype. Mas, e se esclarecermos um pouco o esquema: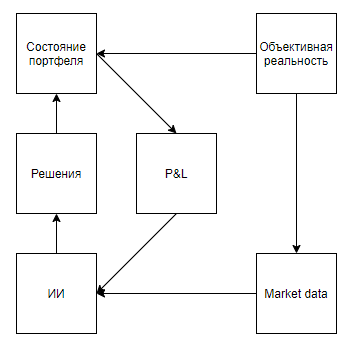
Antecipando a questão das amostras autogeradas, , , . , , . , , . , , , , , .
A segunda abordagem (com um fluxo de aplicativos) parece mais promissora. O chamado vidroé frequentemente preenchido com aplicativos de robôs que buscam frações de um percentual do preço, competindo em um lugar na fila e criando aplicativos apenas para fazer aparecer a demanda ou a oferta e provocam outros bots para ações desvantajosas. Parece que, se você fantasia, se criar um emulador de troca e colocar bots de HFT nele, os quais, tomando bilhões de decisões, aprenderão por conta própria, jogando com os clones de si mesmos e, assim, desenvolverão uma estratégia ideal que levará em consideração todas as contra-estratégias ideais ... É uma pena que, se algo assim acontecer, cerca de 5 pessoas em todo o mundo descubram o assunto - os princípios de negócios de comerciantes de alta frequência implicam sigilo absoluto e se recusam a publicar resultados sem êxito, deixando aos inimigos a chance de pisar no mesmo rake.Eu acho que não vale a pena focar na impossibilidade de aplicar essas abordagens em marketing, RH, vendas, gerenciamento e outras áreas em que o objeto é uma pessoa, porque, para a aplicação correta, é necessário permitir que a IA faça milhões, ou até bilhões de experiências. E, mesmo que muitas empresas tenham um milhão de interações com um objeto em que a IA possa tomar uma decisão (escolhendo um banner para mostrar um cliente em potencial com base em seu perfil, a decisão de demitir um funcionário), ninguém receberá um milhão de experiências com o mesmo objeto, exatamente o que é necessário para aplicativos de alta qualidade. Mas vale a pena focar no antifraude e na cibersegurança.Felizmente ou infelizmente, eu não sei, mas no mundo moderno muitas relações econômicas são baseadas em fornecer pequeno valor sem obrigações em troca de esperar um grande valor no futuro, o que dá origem a inúmeras fontes gratuitas e potencial de fraude.Exemplos:- O primeiro passeio gratuito em agregadores de táxi
- Pagamentos de US $ 70,00 por CPA em jogos de azar, para um jogador que comprou US $ 5,00
- Teste $ 300 de provedores de nuvem e períodos de teste
Além disso, o potencial de fraude do sistema econômico moderno é suportado por um baixo grau de proteção para transações com cartão de crédito, porque os comerciantes geralmente recusam propositalmente o mesmo 3D seguro para simplificar a experiência do usuário. Assim, para compradores de cartões roubados por uma pequena porcentagem de seu saldo, essa lista pode ser complementada quase indefinidamente.O principal problema na luta contra esses casos reside na incapacidade de coletar um conjunto de dados de um volume suficiente -% de operações de fraude são de 1 a 6 ordens de magnitude inferiores à porcentagem de boas operações, dependendo do negócio. Há também um problema na flexibilidade dos fraudadores, que ignoram facilmente os algoritmos estáticos, adaptando-se a sistemas antifraude treinados em experiências anteriores.E, ao que parece, aqui está. Algoritmos como o Agent57 lançado na caixa de areia permitirão que você crie o fraudador ideal, atualize constantemente suas habilidades e, ao mesmo tempo, resolva o problema inverso - mantenha o algoritmo para identificá-lo atualizado. Mas há uma ressalva. Ganhar contra o modelo do mundo incorporado nos jogos da Atari não é o mesmo que ganhar de um sistema antifraude já treinado com base no comportamento de milhões de jogadores, e muitas ações com fraude são desproporcionais às muitas ações de um jogador em um jogo retro. Por exemplo, mesmo uma ação tão simples como inserir um login no formulário de registro já traz bilhões de opções para isso. Iniciando a partir de qual agente do usuário transferir para o servidor e terminando com quantos milissegundos para aguardar entre a inserção do segundo e terceiro caracteres de login ...Em geral, eu vejo tudo de alguma forma. Muito sombrio. E realmente espero que esteja errado e que em algum lugar não tenha levado em consideração algo no modelo. Ficaria muito grato se vir contra-exemplos nos comentários.