Olá queridos Khabrovites, neste pequeno exemplo, quero mostrar como você pode analisar uma página, cujos dados são carregados usando widgets javascript. Além disso, mesmo que seja fácil salvar a página neste exemplo, você ainda não poderá analisar todas as fotos necessárias por causa desses widgets. Nesse caso, eu uso o cian.ru como exemplo , que possui sua própria API , que não usarei; em vez disso, utilizarei o Selenium. Eu não trabalho no cian.ru, apenas uso este site como exemplo. O código no analisador é simples e projetado para iniciantes.
Uma breve introdução - quando, à minha vontade, observei exemplos de reparos no cian.ru, achei que seria bom salvar as fotos que eu gostava, mas salvá-las manualmente seria um longo tempo, além de esse não ser o nosso método, então decidi escrever isso analisador.
O analisador é escrito em python3 a partir da distribuição do binário Anaconda , Selenium e chromedriver que eu instalei separadamente desses links. (E, claro, o navegador Google Chrome deve estar instalado no sistema )
Abaixo está o código do analisador completo, então analisarei os pontos principais separadamente.
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.common.exceptions import NoSuchElementException
import chromedriver_binary
import urllib
import time
print('start...')
site = "https://www.cian.ru/sale/flat/222059642/"
chrome_options = Options()
chrome_options.add_argument("--headless")
driver = webdriver.Chrome(options=chrome_options)
driver.get(site)
i = 0
while True:
try:
url = driver.find_element_by_xpath("//div[contains(@class, 'fotorama__active')]/img").get_attribute('src')
except NoSuchElementException:
break
i += 1
print(i, url)
driver.find_element_by_xpath("//div[@class='fotorama__arr fotorama__arr--next']").click()
name = url.split('/')[-1]
urllib.request.urlretrieve(url, name)
time.sleep(2)
print('done.')
https://www.cian.ru/sale/flat/222059642/ . driver get. , Headless Chrome, .. webdriver.Chrome() --headless, , , chrome_options , .
site = "https://www.cian.ru/sale/flat/222059642/"
chrome_options = Options()
chrome_options.add_argument("--headless")
driver = webdriver.Chrome(options=chrome_options)
driver.get(site)
, , , .. "next".
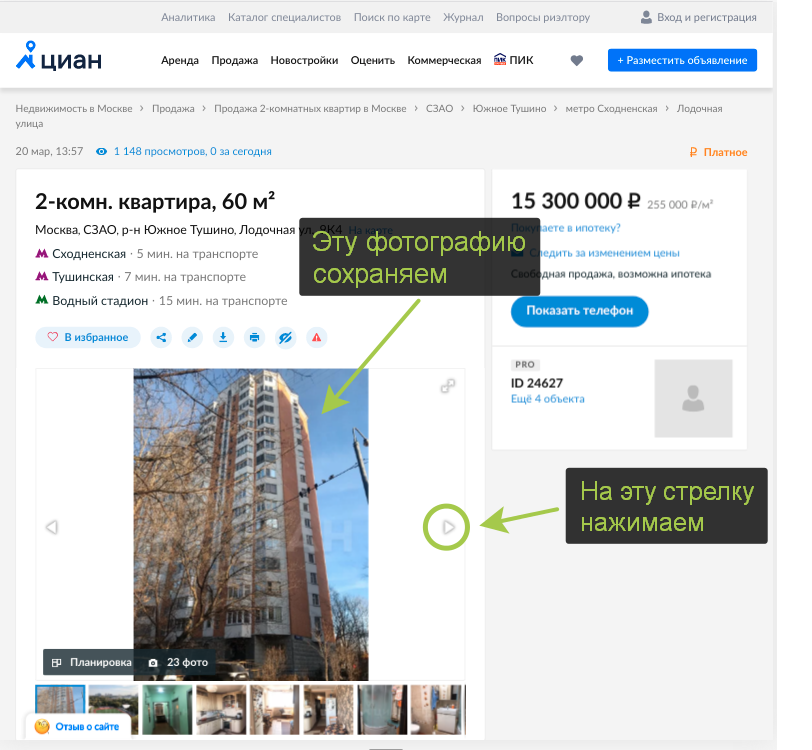
url , try/except NoSuchElementException, , Selenium .
try:
url = driver.find_element_by_xpath("//div[contains(@class, 'fotorama__active')]/img").get_attribute('src')
except NoSuchElementException:
break
.
driver.find_element_by_xpath("//div[@class='fotorama__arr fotorama__arr--next']").click()
urllib.
name = url.split('/')[-1]
urllib.request.urlretrieve(url, name)
, . ( Selenium)
time.sleep(2)
Selenium, , , - .
.