Olá, habrozhiteli! Enquanto nossas notícias são impressas na gráfica e o escritório fica em um local remoto, decidimos compartilhar um trecho do livro de Paul e Harvey Daytel, “Python: Inteligência Artificial, Big Data e Computação em Nuvem”Estudo de caso: Aprendizado de máquina sem professor, parte 2 - K Clustering médio
Nesta seção, talvez seja apresentado o mais simples dos algoritmos de aprendizado de máquina sem um professor - agrupando usando o método k average. O algoritmo analisa amostras não identificadas e tenta combiná-las em clusters. Vamos explicar que k no "método k significa" representa o número de clusters nos quais os dados devem ser divididos.O algoritmo distribui as amostras para um número predeterminado de clusters usando métricas de distância semelhantes às do algoritmo de cluster de k vizinhos mais próximos. Cada cluster está agrupado em torno de um centróide - o ponto central do cluster. Inicialmente, o algoritmo seleciona k centróides aleatórios dentre as amostras do conjunto de dados, após o qual as amostras restantes são distribuídas entre os clusters com o centróide mais próximo. Em seguida, é realizado um recálculo iterativo de centróides, e as amostras são redistribuídas entre os clusters, até que para todos os clusters a distância do centróide fornecido às amostras incluídas em seu cluster seja minimizada. Como resultado do algoritmo, é criada uma matriz unidimensional de rótulos que designa o cluster ao qual cada amostra pertence, bem como uma matriz bidimensional de centróides representando o centro de cada cluster.Conjunto de dados Iris
Trabalharemos com o popular conjunto de dados Iris incluído no scikit-learn. Esse conjunto é frequentemente analisado durante a classificação e o agrupamento. Embora o conjunto de dados esteja rotulado, não usaremos esses rótulos para demonstrar o agrupamento. Os rótulos serão usados para determinar quão bem o algoritmo k-average agrupa as amostras.O conjunto de dados Iris é um conjunto de dados de brinquedo, pois consiste em apenas 150 amostras e quatro atributos. O conjunto de dados descreve 50 amostras de três tipos de flores de íris - Iris setosa, Iris versicolor e Iris virginica (veja fotos abaixo). Características das amostras: comprimento do lóbulo do perianto externo (comprimento da sépala), largura do lóbulo do perianto externo (largura da sépala), comprimento do lobo do perianto interno (comprimento da pétala) e largura do lóbulo do perianto interno (largura da pétala), medido em centímetros.14.7.1 Download do conjunto de dados Iris
Inicie o IPython com o comando ipython --matplotlib e use a função load_iris do módulo sklearn.datasets para obter o objeto Bunch com o conjunto de dados:In [1]: from sklearn.datasets import load_iris
In [2]: iris = load_iris()
O atributo DESCR de um objeto Bunch indica que o conjunto de dados consiste em 150 amostras de Number of Instances, cada uma das quais com quatro Number of Attributes. Não há valores ausentes no conjunto de dados. As amostras são classificadas com números inteiros 0, 1 e 2, representando Iris setosa, Iris versicolor e Iris virginica, respectivamente. Ignoramos os rótulos e confiamos a determinação das classes de amostras ao algoritmo de agrupamento usando o método k means. Informações principais da DESCR em negrito:In [3]: print(iris.DESCR)
.. _iris_dataset:
Iris plants dataset
--------------------
**Data Set Characteristics:**
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, predictive attributes and the class
:Attribute Information:
- sepal length in cm
- sepal width in cm
- petal length in cm
- petal width in cm
- class:
- Iris-Setosa
- Iris-Versicolour
- Iris-Virginica
:Summary Statistics:
============== ==== ==== ======= ===== ====================
Min Max Mean SD Class Correlation
============== ==== ==== ======= ===== ====================
sepal length: 4.3 7.9 5.84 0.83 0.7826
sepal width: 2.0 4.4 3.05 0.43 -0.4194
petal length: 1.0 6.9 3.76 1.76 0.9490 (high!)
petal width: 0.1 2.5 1.20 0.76 0.9565 (high!)
============== ==== ==== ======= ===== ====================
:Missing Attribute Values: None
:Class Distribution: 33.3% for each of 3 classes.
:Creator: R.A. Fisher
:Donor: Michael Marshall (MARSHALL%PLU@io.arc.nasa.gov)
:Date: July, 1988
...
Verificando o número de amostras, recursos e valores-alvo
O número de padrões e atributos pode ser encontrado no atributo shape da matriz de dados e o número de valores de destino pode ser encontrado no atributo shape da matriz de destino:In [4]: iris.data.shape
Out[4]: (150, 4)
In [5]: iris.target.shape
Out[5]: (150,)
A matriz target_names contém os nomes dos rótulos numéricos da matriz. A expressão target - dtype = '<U10' significa que seus elementos são cadeias de caracteres com um comprimento máximo de 10 caracteres:In [6]: iris.target_names
Out[6]: array(['setosa', 'versicolor', 'virginica'], dtype='<U10')
A matriz feature_names contém uma lista de nomes de cadeias para cada coluna na matriz de dados:In [7]: iris.feature_names
Out[7]:
['sepal length (cm)',
'sepal width (cm)',
'petal length (cm)',
'petal width (cm)']
14.7.2 Pesquisa de conjuntos de dados Iris: estatística descritiva em pandas
Usamos a coleção DataFrame para examinar o conjunto de dados Iris. Como no conjunto de dados California Housing, definimos os parâmetros do pandas para formatar a saída da coluna:In [8]: import pandas as pd
In [9]: pd.set_option('max_columns', 5)
In [10]: pd.set_option('display.width', None)
Crie uma coleção DataFrame com o conteúdo da matriz de dados, usando o conteúdo da matriz feature_names como nomes de colunas:In [11]: iris_df = pd.DataFrame(iris.data, columns=iris.feature_names)
Em seguida, adicione uma coluna com o nome da visualização para cada uma das amostras. A transformação da lista no seguinte snippet usa cada valor na matriz de destino para procurar o nome correspondente na matriz target_names:In [12]: iris_df['species'] = [iris.target_names[i] for i in iris.target]
Usaremos pandas para identificar várias amostras. Como antes, se o pandas exibir \ à direita do nome da coluna, isso significa que as colunas que serão exibidas abaixo permanecem na saída:In [13]: iris_df.head()
Out[13]:
sepal length (cm) sepal width (cm) petal length (cm) \
0 5.1 3.5 1.4
1 4.9 3.0 1.4
2 4.7 3.2 1.3
3 4.6 3.1 1.5
4 5.0 3.6 1.4
petal width (cm) species
0 0.2 setosa
1 0.2 setosa
2 0.2 setosa
3 0.2 setosa
4 0.2 setosa
Calculamos alguns indicadores de estatística descritiva para colunas numéricas:In [14]: pd.set_option('precision', 2)
In [15]: iris_df.describe()
Out[15]:
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm)
count 150.00 150.00 150.00 150.00
mean 5.84 3.06 3.76 1.20
std 0.83 0.44 1.77 0.76
min 4.30 2.00 1.00 0.10
25% 5.10 2.80 1.60 0.30
50% 5.80 3.00 4.35 1.30
75% 6.40 3.30 5.10 1.80
max 7.90 4.40 6.90 2.50
Chamar o método de descrição na coluna 'espécie' confirma que ele contém três valores exclusivos. Sabemos de antemão que os dados consistem em três classes, às quais as amostras pertencem, embora no aprendizado de máquina sem professor nem sempre seja esse o caso.In [16]: iris_df['species'].describe()
Out[16]:
count 150
unique 3
top setosa
freq 50
Name: species, dtype: object
14.7.3 Visualização do conjunto de dados em pares
Vamos visualizar as características neste conjunto de dados. Uma maneira de extrair informações sobre seus dados é ver como os atributos estão relacionados entre si. Um conjunto de dados possui quatro atributos. Não conseguiremos construir um diagrama de correspondência de um atributo com outros três em um diagrama. No entanto, é possível construir um diagrama no qual a correspondência entre os dois recursos será apresentada. O fragmento [20] usa a função pairplot da biblioteca Seaborn para criar uma tabela de diagramas em que cada recurso é mapeado para um dos outros recursos:In [17]: import seaborn as sns
In [18]: sns.set(font_scale=1.1)
In [19]: sns.set_style('whitegrid')
In [20]: grid = sns.pairplot(data=iris_df, vars=iris_df.columns[0:4],
...: hue='species')
...:
Argumentos principais:- uma coleção DataFrame com um conjunto de dados plotado em um gráfico;
- vars - uma sequência com os nomes das variáveis plotadas no gráfico. Para uma coleção DataFrame, ela contém nomes de colunas. Nesse caso, as quatro primeiras colunas do DataFrame são usadas, representando o comprimento (largura) do perianto externo e o comprimento (largura) do perianto interno, respectivamente;
- hue é uma coluna da coleção DataFrame usada para determinar as cores dos dados plotados no gráfico. Nesse caso, os dados são coloridos dependendo do tipo de íris.
A chamada do pairplot anterior cria a seguinte tabela de diagrama 4 × 4: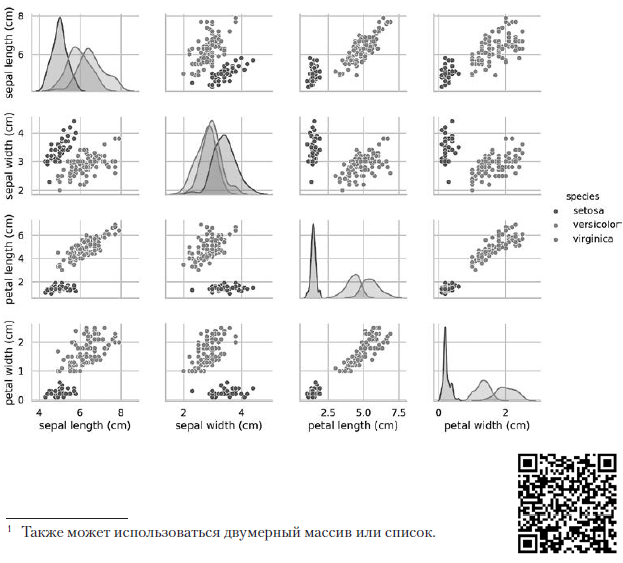 Os diagramas na diagonal que antecede do canto superior esquerdo ao canto inferior direito mostram a distribuição do atributo exibido nesta coluna com um intervalo de valores (da esquerda para a direita) e o número de amostras com esses valores (de cima para baixo) . Tome a distribuição do comprimento do perianto externo:
Os diagramas na diagonal que antecede do canto superior esquerdo ao canto inferior direito mostram a distribuição do atributo exibido nesta coluna com um intervalo de valores (da esquerda para a direita) e o número de amostras com esses valores (de cima para baixo) . Tome a distribuição do comprimento do perianto externo: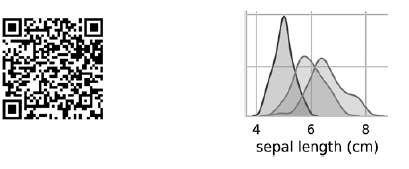 A área sombreada mais alta indica que o intervalo do comprimento do lobo perianto externo (ao longo do eixo x) para a espécie Iris setosa é de aproximadamente 4-6 cm e, para a maioria das amostras de Iris setosa, os valores estão no meio desse intervalo (aproximadamente 5 cm). A área sombreada à direita indica que o intervalo do comprimento do lobo perianto externo (ao longo do eixo x) para a espécie Iris virginica é de aproximadamente 4 a 8,5 cm, e para a maioria das amostras de Iris virginica, os valores estão entre 6 e 7 cm.Em outros diagramas, a coluna apresenta diagramas de dispersão de dados de outras características relativas à característica ao longo do eixo x. Na primeira coluna, nos três primeiros diagramas, o eixo y mostra a largura do perianto externo, o comprimento do perianto interno e a largura do perianto interno, respectivamente, e o eixo x mostra o comprimento do perianto externo.Quando esse código é executado, uma imagem colorida aparece na tela, mostrando a relação entre diferentes tipos de íris no nível de caracteres individuais. Curiosamente, em todos os diagramas, os pontos azuis de Iris setosa são claramente separados dos pontos laranja e verde de outras espécies; isso sugere que Iris setosa é de fato uma classe separada. Você também pode notar que as outras duas espécies podem às vezes ser confundidas, como indicado pela sobreposição de pontos laranja e verdes. Por exemplo, o diagrama da largura e comprimento do lóbulo do perianto externo mostra que os pontos de Iris versicolor e Iris virginica se misturam. Isso sugere que, se apenas as medidas do lobo perianto externo estiverem disponíveis, será difícil distinguir entre essas duas espécies.
A área sombreada mais alta indica que o intervalo do comprimento do lobo perianto externo (ao longo do eixo x) para a espécie Iris setosa é de aproximadamente 4-6 cm e, para a maioria das amostras de Iris setosa, os valores estão no meio desse intervalo (aproximadamente 5 cm). A área sombreada à direita indica que o intervalo do comprimento do lobo perianto externo (ao longo do eixo x) para a espécie Iris virginica é de aproximadamente 4 a 8,5 cm, e para a maioria das amostras de Iris virginica, os valores estão entre 6 e 7 cm.Em outros diagramas, a coluna apresenta diagramas de dispersão de dados de outras características relativas à característica ao longo do eixo x. Na primeira coluna, nos três primeiros diagramas, o eixo y mostra a largura do perianto externo, o comprimento do perianto interno e a largura do perianto interno, respectivamente, e o eixo x mostra o comprimento do perianto externo.Quando esse código é executado, uma imagem colorida aparece na tela, mostrando a relação entre diferentes tipos de íris no nível de caracteres individuais. Curiosamente, em todos os diagramas, os pontos azuis de Iris setosa são claramente separados dos pontos laranja e verde de outras espécies; isso sugere que Iris setosa é de fato uma classe separada. Você também pode notar que as outras duas espécies podem às vezes ser confundidas, como indicado pela sobreposição de pontos laranja e verdes. Por exemplo, o diagrama da largura e comprimento do lóbulo do perianto externo mostra que os pontos de Iris versicolor e Iris virginica se misturam. Isso sugere que, se apenas as medidas do lobo perianto externo estiverem disponíveis, será difícil distinguir entre essas duas espécies.O gráfico de pares de saída resulta em uma cor
Se você remover o argumento da tecla hue, a função pairplot usará apenas uma cor para gerar todos os dados, porque não sabe distinguir entre as visualizações na saída:In [21]: grid = sns.pairplot(data=iris_df, vars=iris_df.columns[0:4])
Como pode ser visto no diagrama a seguir, neste caso, os diagramas na diagonal são histogramas com as distribuições de todos os valores desse atributo, independentemente do tipo. Ao estudar diagramas, pode parecer que existem apenas dois clusters, embora saibamos que o conjunto de dados contém três tipos. Se o número de clusters não for conhecido antecipadamente, você poderá entrar em contato com um especialista na área de assunto que esteja familiarizado com os dados. Um especialista pode saber que existem três tipos de dados em um conjunto de dados; essas informações podem ser úteis ao realizar o aprendizado de máquina com dados.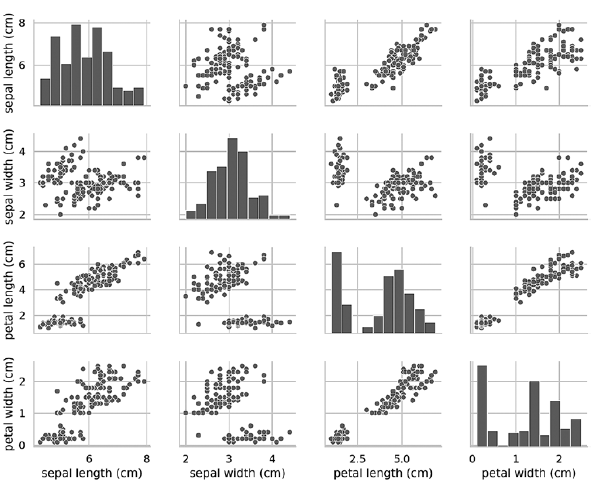 Os diagramas de diagrama de pares funcionam bem com um pequeno número de recursos ou um subconjunto de recursos, para que o número de linhas e colunas seja limitado e com um número relativamente pequeno de padrões, para que os pontos de dados fiquem visíveis. À medida que o número de recursos e padrões aumenta, os diagramas de dispersão de dados se tornam muito pequenos para a leitura dos dados. Em conjuntos de dados grandes, é possível plotar um subconjunto de recursos no gráfico e, opcionalmente, um subconjunto de padrões selecionado aleatoriamente para ter uma idéia dos dados.»Mais informações sobre o livro podem ser encontradas e adquiridas no site do editor
Os diagramas de diagrama de pares funcionam bem com um pequeno número de recursos ou um subconjunto de recursos, para que o número de linhas e colunas seja limitado e com um número relativamente pequeno de padrões, para que os pontos de dados fiquem visíveis. À medida que o número de recursos e padrões aumenta, os diagramas de dispersão de dados se tornam muito pequenos para a leitura dos dados. Em conjuntos de dados grandes, é possível plotar um subconjunto de recursos no gráfico e, opcionalmente, um subconjunto de padrões selecionado aleatoriamente para ter uma idéia dos dados.»Mais informações sobre o livro podem ser encontradas e adquiridas no site do editor