Agora a programação penetra cada vez mais profundamente em todas as áreas da vida. E talvez tenha se tornado graças ao python muito popular agora. Se há cinco anos, para análise de dados, você tinha que usar um pacote inteiro de várias ferramentas: C # para descarregar (ou canetas), Excel, MatLab, SQL e constantemente "pular" para lá, limpar, verificar e reconciliar dados. Agora, python, graças a um grande número de excelentes bibliotecas e módulos, na primeira aproximação substitui com segurança todas essas ferramentas e, em conjunto com o SQL, em geral, “montanhas podem ser montadas”.Então o que estou fazendo? Fiquei interessado em aprender um python tão popular. E a melhor maneira de aprender algo, como você sabe, é praticar. E também estou interessado em imóveis. E me deparei com um problema interessante sobre imóveis em Moscou: classificar os distritos de Moscou pelo custo médio de aluguel de uma odnushka média? Pais, pensei, aqui você tem geolocalização, upload do site e análise de dados - uma ótima tarefa prática.Inspirados nos maravilhosos artigos aqui no Habré (no final do artigo, adicionarei links), vamos começar!A tarefa para nós é percorrer as ferramentas existentes no python, desmontar a técnica - como resolver esses problemas e passar tempo com prazer, e não apenas com benefícios.- Raspando ciano
- Quadro de dados único
- Processamento de quadros de dados
- resultados
- Um pouco sobre como trabalhar com dados geográficos
Raspando ciano
Em meados de março de 2020, foi possível coletar quase 9 mil propostas para alugar um apartamento de um quarto em Moscou em ciano, o site exibe 54 páginas. Trabalharemos com o jupyter-notebook 6.0.1, python 3.7. Carregamos dados do site e os salvamos em arquivos usando a biblioteca de solicitações .Para que o site não nos proíba, nos disfarçaremos como pessoa adicionando um atraso nas solicitações e definindo um cabeçalho para que, na lateral do site, pareçamos uma pessoa muito inteligente fazendo solicitações por meio de um navegador. Não se esqueça de verificar a resposta do site toda vez, caso contrário, de repente somos descobertos e já banidos. Você pode ler mais e mais detalhadamente sobre a raspagem de site, por exemplo, aqui: raspagem da Web usando python .Também é conveniente adicionar decoradores para avaliar a velocidade de nossas funções e registro. Configurando level = logging.INFO permite especificar o tipo de mensagens exibidas no log. Você também pode configurar o módulo para enviar o log para um arquivo de texto, para nós isso é desnecessário.O códigodef timer(f):
def wrap_timer(*args, **kwargs):
start = time.time()
result = f(*args, **kwargs)
delta = time.time() - start
print (f' {f.__name__} {delta} ')
return result
return wrap_timer
def log(f):
def wrap_log(*args, **kwargs):
logging.info(f" {f.__doc__}")
result = f(*args, **kwargs)
logging.info(f": {result}")
return result
return wrap_log
logging.basicConfig(level=logging.INFO)
@timer
@log
def requests_site(N):
headers = ({'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.5 Safari/605.1.15'})
pages = [106 + i for i in range(N)]
n = 0
for i in pages:
s = f"https://www.cian.ru/cat.php?deal_type=rent&engine_version=2&page={i}&offer_type=flat®ion=1&room1=1&type=-2"
response = requests.get(s, headers = headers)
if response.status_code == 200:
name = f'sheets/sheet_{i}.txt'
with open(name, 'w') as f:
f.write(response.text)
n += 1
logging.info(f" {i}")
else:
print(f" {i} response.status_code = {response.status_code}")
time.sleep(np.random.randint(7,13))
return f" {n} "
requests_site(300)
Quadro de dados único
Para raspar páginas, escolha BeautifulSoup e lxml . Usamos "sopa bonita" simplesmente por seu nome legal, embora eles digam que o lxml é mais rápido.Você pode fazer isso lindamente, pegar uma lista de arquivos de uma pasta usando a biblioteca do sistema operacional , filtrar as extensões de que precisamos e passar por elas. Mas facilitaremos, pois sabemos o número exato de arquivos e seus nomes exatos. A menos que adicionemos decoração na forma de uma barra de progresso, usando a biblioteca tqdmO código
from bs4 import BeautifulSoup
import re
import pandas as pd
from dateutil.parser import parse
from datetime import datetime, date, time
def read_file(filename):
with open(filename) as input_file:
text = input_file.read()
return text
import tqdm
site_texts = []
pages = [1 + i for i in range(309)]
for i in tqdm.tqdm(pages):
name = f'sheets/sheet_{i}.txt'
site_texts.append(read_file(name))
print(f" {len(site_texts)} .")
def parse_tag(tag, tag_value, item):
key = tag
value = "None"
if item.find('div', {'class': tag_value}):
if key == 'link':
value = item.find('div', {'class': tag_value}).find('a').get('href')
elif (key == 'price' or key == 'price_meter'):
value = parse_digits(item.find('div', {'class': tag_value}).text, key)
elif key == 'pub_datetime':
value = parse_date(item.find('div', {'class': tag_value}).text)
else:
value = item.find('div', {'class': tag_value}).text
return key, value
def parse_digits(string, type_digit):
digit = 0
try:
if type_digit == 'flats_counts':
digit = int(re.sub(r" ", "", string[:string.find("")]))
elif type_digit == 'price':
digit = re.sub(r" ", "", re.sub(r"₽", "", string))
elif type_digit == 'price_meter':
digit = re.sub(r" ", "", re.sub(r"₽/²", "", string))
except:
return -1
return digit
def parse_date(string):
now = datetime.strptime("15.03.20 00:00", "%d.%m.%y %H:%M")
s = string
if string.find('') >= 0:
s = "{} {}".format(now.day, now.strftime("%b"))
s = string.replace('', s)
elif string.find('') >= 0:
s = "{} {}".format(now.day - 1, now.strftime("%b"))
s = string.replace('',s)
if (s.find('') > 0):
s = s.replace('','mar')
if (s.find('') > 0):
s = s.replace('','feb')
if (s.find('') > 0):
s = s.replace('','jan')
return parse(s).strftime('%Y-%m-%d %H:%M:%S')
def parse_text(text, index):
tag_table = '_93444fe79c--wrapper--E9jWb'
tag_items = ['_93444fe79c--card--_yguQ', '_93444fe79c--card--_yguQ']
tag_flats_counts = '_93444fe79c--totalOffers--22-FL'
tags = {
'link':('c6e8ba5398--info-section--Sfnx- c6e8ba5398--main-info--oWcMk','undefined c6e8ba5398--main-info--oWcMk'),
'desc': ('c6e8ba5398--title--2CW78','c6e8ba5398--single_title--22TGT', 'c6e8ba5398--subtitle--UTwbQ'),
'price': ('c6e8ba5398--header--1df-X', 'c6e8ba5398--header--1dF9r'),
'price_meter': 'c6e8ba5398--term--3kvtJ',
'metro': 'c6e8ba5398--underground-name--1efZ3',
'pub_datetime': 'c6e8ba5398--absolute--9uFLj',
'address': 'c6e8ba5398--address-links--1tfGW',
'square': ''
}
res = []
flats_counts = 0
soup = BeautifulSoup(text)
if soup.find('div', {'class': tag_flats_counts}):
flats_counts = parse_digits(soup.find('div', {'class': tag_flats_counts}).text, 'flats_counts')
flats_list = soup.find('div', {'class': tag_table})
if flats_list:
items = flats_list.find_all('div', {'class': tag_items})
for i, item in enumerate(items):
d = {'index': index}
index += 1
for tag in tags.keys():
tag_value = tags[tag]
key, value = parse_tag(tag, tag_value, item)
d[key] = value
results[index] = d
return flats_counts, index
from IPython.display import clear_output
sum_flats = 0
index = 0
results = {}
for i, text in enumerate(site_texts):
flats_counts, index = parse_text(text, index)
sum_flats = len(results)
clear_output(wait=True)
print(f" {i + 1} flats = {flats_counts}, {sum_flats} ")
print(f" sum_flats ({sum_flats}) = flats_counts({flats_counts})")
Uma nuance interessante foi que a figura indicada na parte superior da página e indicando o número total de apartamentos encontrados a pedido difere de página para página. Portanto, em nosso exemplo, essas 5.402 ofertas são classificadas por padrão, variando de 5343 a 5402, diminuindo gradualmente com o aumento do número de páginas da solicitação (mas não pelo número de anúncios exibidos). Além disso, foi possível continuar descarregando páginas além dos limites do número de páginas indicado no site. No nosso caso, apenas 54 páginas foram oferecidas no site, mas conseguimos descarregar 309 páginas, apenas com anúncios mais antigos, para um total de 8640 anúncios de aluguel de apartamentos.Uma investigação desse fato ficará fora do escopo deste artigo.Processamento de quadros de dados
Portanto, temos um único quadro de dados com dados brutos nas ofertas 8640. Realizaremos uma análise superficial dos preços médios e medianos nos distritos, calcularemos o preço médio do aluguel por metro quadrado do apartamento e o custo do apartamento no distrito "em média".Continuaremos com as seguintes premissas para o nosso estudo:- Falta de repetições: todos os apartamentos encontrados são realmente existentes. No primeiro estágio, eliminamos apartamentos repetidos no endereço e na quadratura, mas se o apartamento tiver uma quadratura ou endereço um pouco diferente, consideramos essas opções como apartamentos diferentes.
- — .
— «» ? ( ) , , , , . , , , . «» : . «» ( ) , .
Vamos precisar de:price_per_month - preço mensal do aluguel em rublosquadrados - áreaokrug - distrito, neste estudo todo o endereço não é interessante para nósprice_meter - preço do aluguel por 1 metro quadradoO códigodf['price_per_month'] = df['price'].str.strip('/.').astype(int)
new_desc = df["desc"].str.split(",", n = 3, expand = True)
df["square"]= new_desc[1].str.strip(' ²').astype(int)
df["floor"]= new_desc[2]
new_address = df['address'].str.split(',', n = 3, expand = True)
df['okrug'] = new_address[1].str.strip(" ")
df['price_per_meter'] = (df['price_per_month'] / df['square']).round(2)
df = df.drop(['index','metro', 'price_meter','link', 'price','desc','address','pub_datetime','floor'], axis='columns')
Agora, "cuidaremos" das emissões manualmente, de acordo com os cronogramas. Para visualizar os dados, Vamos olhar três bibliotecas: matplotlib , Seaborn e plotly .Histogramas de dados . O Matplotlib permite exibir rápida e facilmente todos os gráficos dos grupos de dados que nos interessam, não precisamos de mais. A figura abaixo, segundo a qual apenas uma proposta em Mitino não pode servir como uma avaliação qualitativa do apartamento médio, é excluída. Outra imagem interessante no Okrug administrativo do sul: a maioria das ofertas (mais de 500 unidades) com valor de aluguel abaixo de 1000 rublos e um aumento nas ofertas (quase 300 unidades) em 1700 rublos por metro quadrado. No futuro, você poderá ver por que isso acontece - remexendo em outros indicadores para esses apartamentos.Apenas uma linha de código fornece histogramas para conjuntos de dados agrupados:hists = df['price_per_meter'].hist(by=df['okrug'], figsize=(16, 14), color = "tab:blue", grid = True)
 A dispersão de valores . A seguir, apresentamos os gráficos usando as três bibliotecas. O seaborn por padrão é mais bonito e brilhante, mas com plotagem permite exibir valores imediatamente quando você passa o mouse, o que é muito conveniente para selecionar os valores de "outliers" que excluiremos.matplotlib
A dispersão de valores . A seguir, apresentamos os gráficos usando as três bibliotecas. O seaborn por padrão é mais bonito e brilhante, mas com plotagem permite exibir valores imediatamente quando você passa o mouse, o que é muito conveniente para selecionar os valores de "outliers" que excluiremos.matplotlibfig, axes = plt.subplots(nrows=4,ncols=3,figsize=(15,15))
for i, (name, group) in enumerate(df_copy.groupby('okrug')):
axes = axes.flatten()
axes[i].scatter(group['price_per_meter'],group['square'], color ='blue')
axes[i].set_title(name)
axes[i].set(xlabel=' 1 ..', ylabel=', 2')
fig.tight_layout()
 seaboarn
seaboarnsns.pairplot(vars=["price_per_meter","square"], data=df_copy, hue="okrug", height=5)
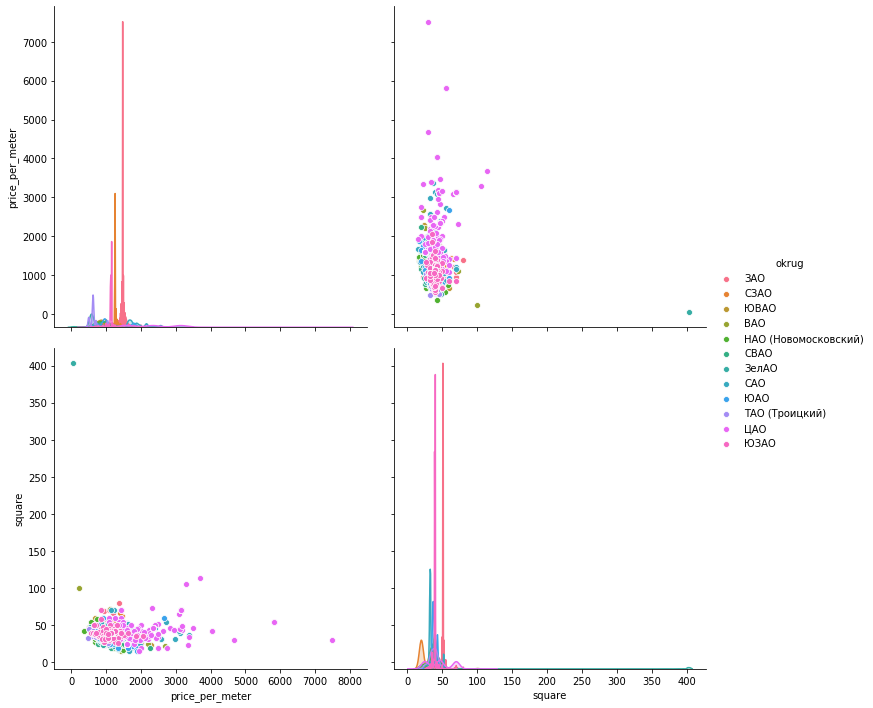 plotlyeu acho que haverá suficiente exemplo para um distrito.
plotlyeu acho que haverá suficiente exemplo para um distrito.import plotly.express as px
for i, (name, group) in enumerate(df_copy.groupby('okrug')):
fig = px.scatter(group, x="price_per_meter", y="square", facet_col="okrug",
width=400, height=400)
fig.update_layout(
margin=dict(l=20, r=20, t=20, b=20),
paper_bgcolor="LightSteelBlue",
)
fig.show()
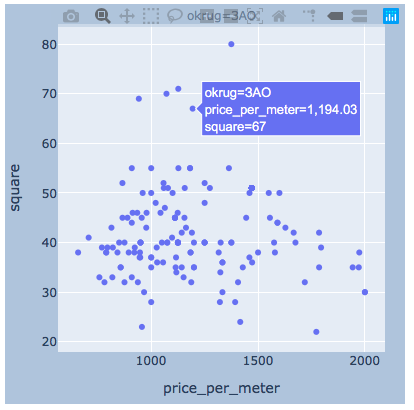
resultados
Assim, depois de limpar os dados e remover as emissões habilmente, temos 8602 ofertas "limpas".Em seguida, calculamos as principais estatísticas de acordo com os dados: média, mediana, desvio padrão, obtemos a seguinte classificação dos distritos de Moscou à medida que o custo médio de aluguel de um apartamento médio diminui: Você pode desenhar histogramas bonitos comparando, por exemplo, os preços médios e medianos no distrito:
Você pode desenhar histogramas bonitos comparando, por exemplo, os preços médios e medianos no distrito: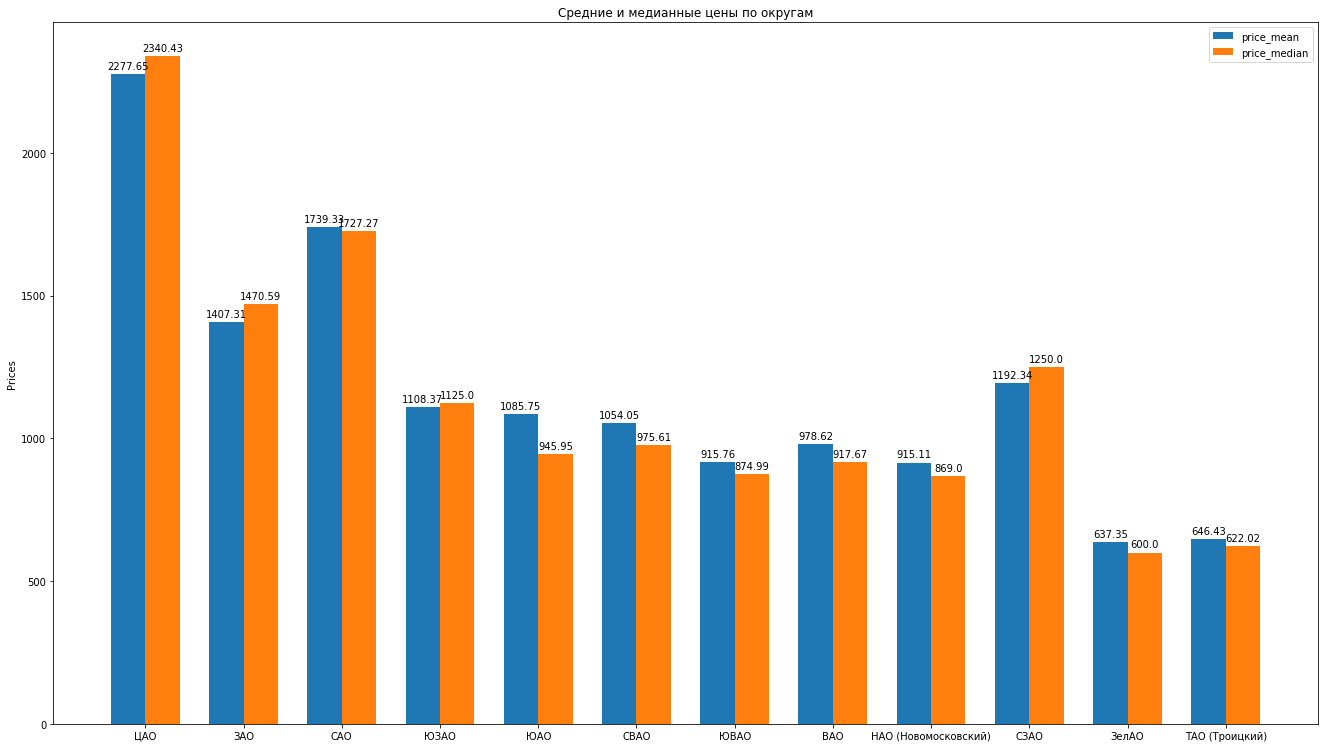 O que mais pode dizer sobre a estrutura das propostas para aluguel de apartamentos com base em dados:
O que mais pode dizer sobre a estrutura das propostas para aluguel de apartamentos com base em dados:- , , , . “” , ( ). , , , , , , “” . , , .
- . . « ». , «» — . . . , , , , , - , , . . .
- , “” , . , , — .
Um capítulo separado, incrivelmente interessante e bonito, é o tópico de geodados, a exibição de nossos dados em relação ao mapa. Você pode olhar com muito detalhes e detalhes, por exemplo, nos seguintes artigos:Visualização dos resultados das eleições em Moscou em um mapa em um Jupyter NotebookLikbez em projeções cartográficas com imagens doOpenStreetMap como fonte de geodadosResumidamente, o OpenStreetMap é tudo, ferramentas convenientes são: geopandas , cartoframes (eles dizem que já morreu?) e fólio , que usaremos.Veja como serão os nossos dados em um mapa interativo.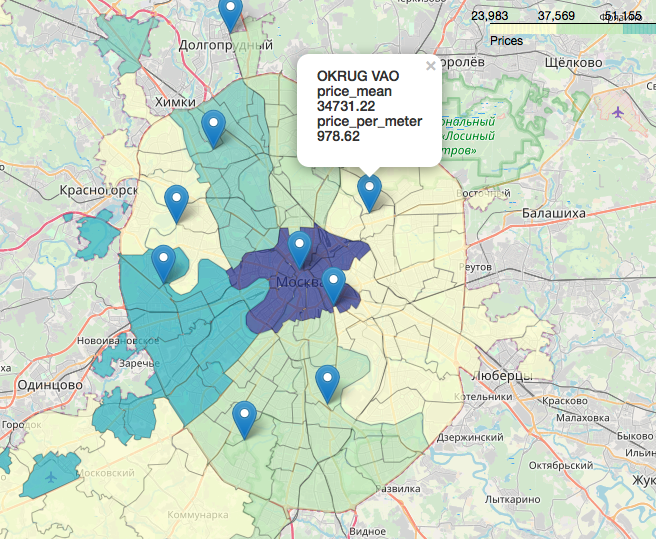 Materiais que se mostraram úteis no trabalho do artigo:Espero que você esteja interessado, como eu.Obrigado pela leitura. Críticas construtivas são bem-vindas.Fontes e conjuntos de dados são publicados no github aqui .
Materiais que se mostraram úteis no trabalho do artigo:Espero que você esteja interessado, como eu.Obrigado pela leitura. Críticas construtivas são bem-vindas.Fontes e conjuntos de dados são publicados no github aqui .