Enquanto dezenas e até centenas de arquiteturas comprovadas de redes neurais artificiais (RNAs) são treinadas no mundo do reconhecimento de objetos, aquecendo o planeta com poderosas placas de vídeo e criando uma "panacéia" para todas as tarefas de visão computacional, estamos seguindo firmemente o caminho de pesquisa nos Smart Engines, oferecendo novas arquiteturas eficazes de RNA para resolver problemas específicos. Hoje falaremos sobre o HafNet - uma nova maneira de procurar pontos de fuga nas imagens.
Hough transformação e sua rápida implementação
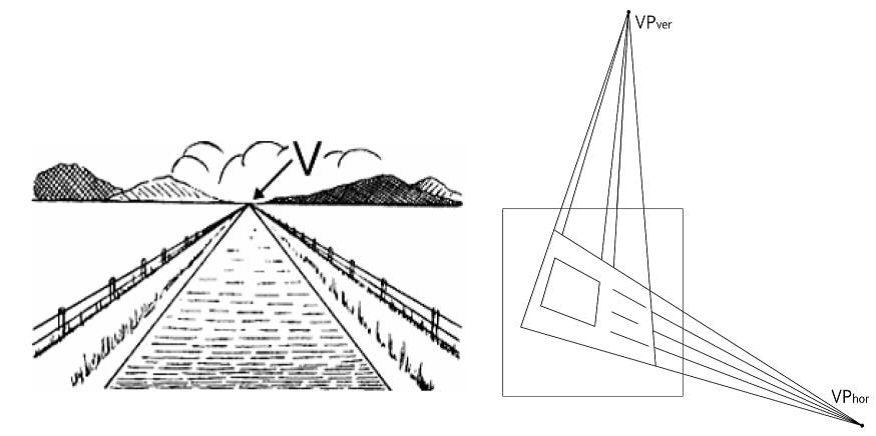
. , , , , . ( ). () : , , , .. , , , , , .
(xi,yi). , yi=xia+b a b. b=-xia+yi ab, , (xi,yi) . : , , , . : , . ( – , ).
, , , – .
, . .

, , : – O(n3), n – .
() – , , () . O(n2 log(n)), . , , , [5]. , : : « » ( H1), « » ( H2), « » ( H3) « » ( H4). , H12 H34 , .
( , ). , , . .
. , , - , : ( , , ), – . , . . , - . , H12 , . , , H34 , . , , H12 , , , . ( , H12 ).

( ). , ( – ).
, , : ? , … , !
HoughNet
, , - (, – , – ). «» ( , ). «» . «» , , ?
, ( HoughNet), , - . , , – , , . , ( [1]).
: «» , «» . .
. MIDV-500 [6]. , . 50 . ( , 30 ) , – .
, , ICDAR 2011 dewarping contest dataset ( 100 - , ) .

«» ( ), state-of-the-art [7] [8].
[1] Sheshkus A. et al. HoughNet: neural network architecture for vanishing points detection // 2019 International Conference on Document Analysis and Recognition (ICDAR). – 2020. doi: 10.1109/ICDAR.2019.00140.
[2] . ., . ., . . // . – 2014. – . 64. – №. 3. – . 25-34.
[3] .. : . … . . .-. . – ., 2019. – 24 .
[4] [ ]: . . – : https://ru.wikipedia.org/wiki/_/ ( : 13.03.2020).
[5] Nikolaev D. P., Karpenko S. M., Nikolaev I. P., Nikolayev P. P. Hough Transform: Underestimated Tool in the Computer Vision Field // 22st European Conference on Modelling and Simulation, ECMS 2008. – Nicosia, Cyprys, 2008. – P. 238–243.
[6] Arlazarov V. V. et al. MIDV-500: a dataset for identity document analysis and recognition on mobile devices in video stream // . – 2019. – . 43. – №. 5.
[7] Y. Takezawa, M. Hasegawa, and S. Tabbone, “Cameracaptured document image perspective distortion correction using vanishing point detection based on radon transform,” in Pattern Recognition (ICPR), 2016 23rd International Conference on. IEEE, 2016, pp. 3968–3974.
[8] Y. Takezawa, M. Hasegawa, and S. Tabbone, “Robust perspective rectification of camera-captured document images,” in Document Analysis and Recognition (ICDAR), 2017 14th IAPR International Conference on, vol. 6. IEEE, 2017, pp. 27–32.