Há algum tempo, iniciei uma jornada incrível no mundo do compilador JIT, a fim de encontrar lugares onde você pode colocar as mãos e acelerar algo, como No decorrer do trabalho principal, uma pequena quantidade de conhecimento em LLVM e suas otimizações se acumulou. Neste artigo, gostaria de compartilhar uma lista de minhas melhorias no JIT (no .NET é chamado RyuJIT em homenagem a algum dragão ou anime - não descobri), a maioria das quais já alcançou o master e estará disponível no .NET (Core) 5 Minhas otimizações afetam diferentes fases do JIT, que podem ser mostradas esquematicamente da seguinte maneira: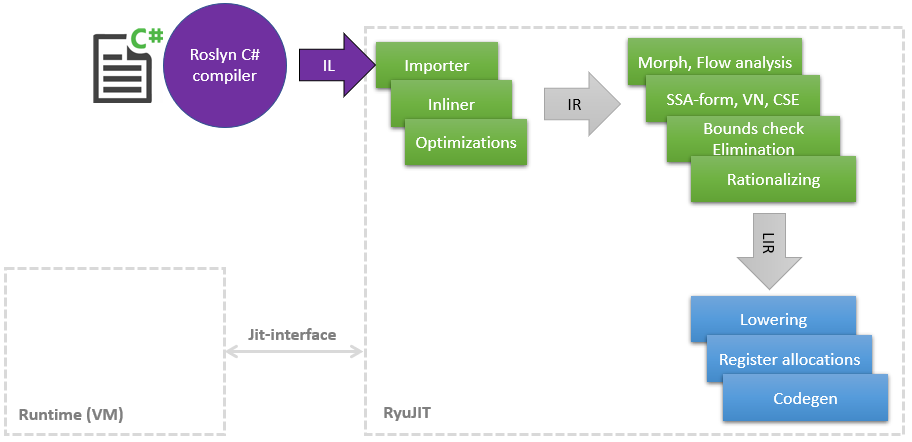 Como pode ser visto no diagrama, o JIT é um módulo separado relacionado à interface Jit estreita , pela qual o JIT consulta algumas coisas, por exemplo, é possívellançar uma classe para outra. Quanto mais tarde o JIT compila o método na Camada1, mais informações o tempo de execução pode fornecer, por exemplo, que os
Como pode ser visto no diagrama, o JIT é um módulo separado relacionado à interface Jit estreita , pela qual o JIT consulta algumas coisas, por exemplo, é possívellançar uma classe para outra. Quanto mais tarde o JIT compila o método na Camada1, mais informações o tempo de execução pode fornecer, por exemplo, que os static readonlycampos podem ser substituídos por uma constante, porque a classe já está inicializada estaticamente.Então, vamos começar com a lista.PR # 1817 : Otimizações de boxe / unboxing na correspondência de padrões
Fase: ImportadorMuitos dos novos recursos do C # geralmente pecam ao inserir os códigos de caixa / unbox do CIL . Essa é uma operação muito cara, que é essencialmente a alocação de um novo objeto no heap, copiando o valor da pilha para ele e, em seguida, também carrega o GC no final. Já há várias otimizações no JIT para este caso, mas eu encontrei a correspondência de padrões ausente no C # 8, por exemplo:public static int Case1<T>(T o)
{
if (o is int x)
return x;
return 0;
}
public static int Case2<T>(T o) => o is int n ? n : 42;
public static int Case3<T>(T o)
{
return o switch
{
int n => n,
string str => str.Length,
_ => 0
};
}
E vamos ver o asm-codegen antes da minha otimização (por exemplo, para a especialização int) para todos os três métodos: E agora, depois da minha melhoria:
E agora, depois da minha melhoria: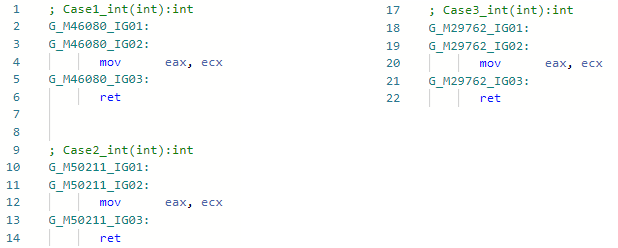 o fato é que a otimização encontrou padrões de código IL
o fato é que a otimização encontrou padrões de código ILbox !!T
isinst Type1
unbox.any Type2
ao importar e ter informações sobre tipos, pude simplesmente ignorar esses opcodes e não inserir boxing-anboxing. A propósito, eu implementei a mesma otimização no Mono também. A seguir, um link para solicitação de recebimento está contido no cabeçalho da descrição da otimização.PR # 1157 typeof (T) .IsValueType ⇨ verdadeiro / falso
Fase: ImportadorAqui eu treinei o JIT para substituir imediatamente Type.IsValueType por uma constante, se possível. Isso é menos o desafio e a capacidade de eliminar condições e ramos inteiros no futuro, um exemplo:void Foo<T>()
{
if (!typeof(T).IsValueType)
Console.WriteLine("not a valuetype");
}
E vamos ver o codegen da especialização Foo <int> antes da melhoria: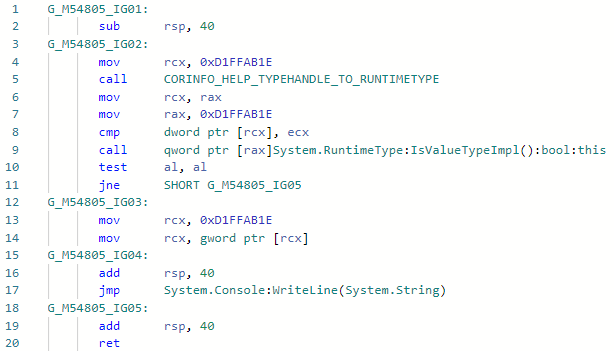 E após a melhoria: O
E após a melhoria: O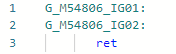 mesmo pode ser feito com outras propriedades de Tipo, se necessário.
mesmo pode ser feito com outras propriedades de Tipo, se necessário.PR # 1157 typeof(T1).IsAssignableFrom(typeof(T2)) ⇨ true/false
Fase: ImportadorQuase a mesma coisa - agora você pode verificar a hierarquia em métodos genéricos sem medo de que isso não seja otimizado, por exemplo:void Foo<T1, T2>()
{
if (!typeof(T1).IsAssignableFrom(typeof(T2)))
Console.WriteLine("T1 is not assignable from T2");
}
Da mesma forma, ele será substituído por uma constante true/falsee a condição poderá ser excluída completamente. Nessas otimizações, é claro, não é sem esquinas que você deve sempre se lembrar: Sistema. __ Canon compartilhava genéricos, matrizes, variabilidade de co (ntr), valores nulos, objetos COM, etc.PR # 1378 "Hello".Length ⇨ 5
Fase: ImportadorApesar de a otimização ser tão óbvia e simples quanto possível, tive que suar muito para implementá-la no JIT-e. O fato é que o JIT não sabia sobre o conteúdo da string, ele viu literais da string ( GT_CNS_STR ), mas não sabia nada sobre o conteúdo específico das strings. Eu tive que ajudá-lo entrando em contato com a VM (para expandir a interface JIT acima mencionada), e a otimização em si é essencialmente algumas linhas de código . Existem muitos casos de usuários, além dos óbvios, como: str.IndexOf("foo") + "foo".Lengthos não óbvios nos quais o inlining está envolvido (lembre-se: Roslyn não lida com o inlining, portanto, essa otimização seria ineficaz nele, além disso, como todos os outros), por exemplo:bool Validate(string str) => str.Length > 0 && str.Length <= 100;
bool Test() => Validate("Hello");
Vejamos o codegen para Teste ( Validar está em linha):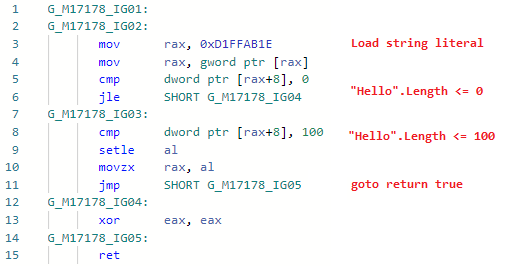 e agora o codegen após adicionar a otimização:
e agora o codegen após adicionar a otimização: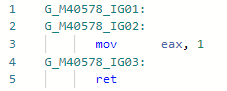 ou seja, inline o método, substitua as variáveis por literais de seqüência de caracteres, substitua .Length de literais por comprimentos de seqüência de caracteres reais, dobre as constantes e exclua o código morto. A propósito, como o JIT agora pode verificar o conteúdo de uma sequência, as portas foram abertas para outras otimizações relacionadas aos literais da sequência. A otimização propriamente dita foi mencionada no anúncio da primeira visualização do .NET 5.0: devblogs.microsoft.com/dotnet/announcing-net-5-0-preview-1 na seção Melhorias na qualidade do código no RyuJIT .
ou seja, inline o método, substitua as variáveis por literais de seqüência de caracteres, substitua .Length de literais por comprimentos de seqüência de caracteres reais, dobre as constantes e exclua o código morto. A propósito, como o JIT agora pode verificar o conteúdo de uma sequência, as portas foram abertas para outras otimizações relacionadas aos literais da sequência. A otimização propriamente dita foi mencionada no anúncio da primeira visualização do .NET 5.0: devblogs.microsoft.com/dotnet/announcing-net-5-0-preview-1 na seção Melhorias na qualidade do código no RyuJIT .PR # 1644: Otimizando verificações vinculadas.
Fase: eliminação da verificação de limitesPara muitos, não será segredo que toda vez que você acessa uma matriz por índice, o JIT insere uma verificação para você de que a matriz não vai além e gera uma exceção se isso acontecer - no caso de lógica incorreta, você não pode para ler memória aleatória, obtenha algum valor e continue.int Foo(int[] array, int index)
{
return array[index];
}
Essa verificação é útil, mas pode afetar bastante o desempenho: em primeiro lugar, ela adiciona uma operação de comparação e torna seu código sem ramificação e, em segundo lugar, adiciona um código de exceção ao seu método com todas as consequências. No entanto, em muitos casos, o JIT pode remover essas verificações se provar que o índice nunca vai além disso ou que já existe outra verificação e você não precisa adicionar mais uma - Eliminação de verificação de limites (intervalo). Encontrei vários casos em que ele não conseguiu lidar com eles e os corrigiu (e no futuro planejo mais algumas melhorias nessa fase).var item = array[index & mask];
Aqui neste código, digo ao JIT que & maskessencialmente limita o índice de cima para um valor mask, ou seja, se o valor maske o comprimento da matriz forem conhecidos pelo JIT , você não poderá inserir uma verificação vinculada. O mesmo vale para operações%, (& x >> y). Um exemplo de uso dessa otimização no aspnetcore .Além disso, se soubermos que em nossa matriz, por exemplo, existem 256 elementos ou mais, se nosso indexador desconhecido for do tipo byte, não importa o quanto tente, nunca conseguirá sair dos limites. PR: github.com/dotnet/coreclr/pull/25912PR # 24584: x / 2 ⇨ x * 0.5
Fase: MorphC deste PR e comecei meu mergulho incrível no mundo das otimizações de JIT. A operação "divisão" é mais lenta que a operação "multiplicação" (e se for para números inteiros e, em geral - uma ordem de magnitude). Funciona para constantes apenas iguais à potência de dois, por exemplo:static float DivideBy2(float x) => x / 2;
Codegen antes da otimização: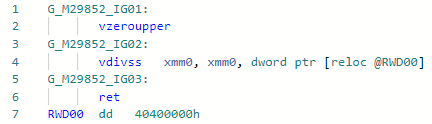 e depois:
e depois: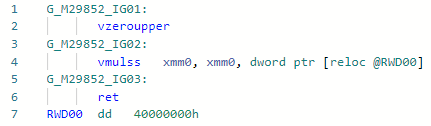 Se compararmos essas duas instruções para Haswell, tudo ficará claro:
Se compararmos essas duas instruções para Haswell, tudo ficará claro:vdivss (Latency: 10-20, R.Throughput: 7-14)
vmulss (Latency: 5, R.Throughput: 0.5)
Isso será seguido por otimizações que ainda estão no estágio de revisão de código e não pelo fato de que serão aceitas.PR # 31978: Math.Pow(x, 2) ⇨ x * x
Fase: ImportadorTudo é simples aqui: em vez de chamar pow (f) para um caso bastante popular, quando o grau é constante 2 (bem, também é gratuito para 1, -1, 0), você pode expandi-lo para um simples x * x. Você pode expandir outros graus, mas, para isso, é necessário aguardar a implementação do modo "matemática rápida" no .NET, no qual a especificação IEEE-754 pode ser negligenciada por questão de desempenho. Exemplo:static float Pow2(float x) => MathF.Pow(x, 2);
Codegen antes da otimização: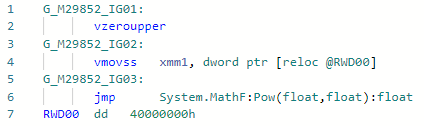 e depois:
e depois: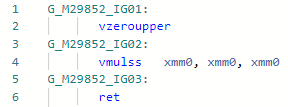
PR # 33024: x * 2 ⇨ x + x
Fase: BaixandoTambém a otimização bastante simples de micro (nano) canal, permite multiplicar por 2 sem carregar a constante no registro.static float MultiplyBy2(float x) => x * 2;
Codegen antes da otimização: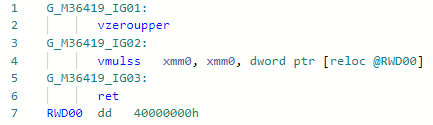 Depois:
Depois: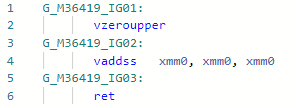 Em geral, a instrução é a
Em geral, a instrução é a mul(ss/sd/ps/pd)mesma em latência e taxa de transferência que add(ss/sd/ps/pd), mas a necessidade de carregar a constante “2” pode atrasar um pouco o trabalho. Aqui, no exemplo do codegen acima, eu vaddssfiz tudo dentro da estrutura de um registro.PR # 32368: Otimização de Array.Length / c (ou% s)
Fase: MorphAcontece que o campo Comprimento da matriz é um tipo assinado, e a divisão e o restante por uma constante são muito mais eficientes de um tipo não assinado (e não apenas um poder de dois), basta comparar este codegen: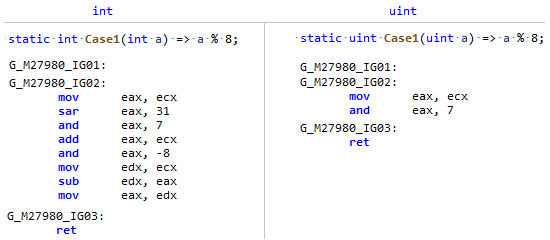 Meu PR apenas lembra ao JIT que
Meu PR apenas lembra ao JIT que Array.Lengthembora significativo, mas de fato, o comprimento da matriz NUNCA (a menos que você seja um anarquista ) pode ser menor que zero, o que significa que você pode vê-lo como um número não assinado e aplicar algumas otimizações como para uint.PR # 32716: Otimização de comparações simples em código sem ramificação
Fase: Análise de fluxoEssa é outra classe de otimizações que opera com blocos básicos em vez de expressões em um. Aqui, o JIT é um pouco conservador e tem espaço para melhorias, por exemplo, cmove inserções sempre que possível. Comecei com uma otimização simples para este caso:x = condition ? A : B;
se A e B são constantes e a diferença entre elas é a unidade, por exemplo, condition ? 1 : 2então, sabendo que a operação de comparação em si retorna 0 ou 1, podemos substituir jump por add. Em termos de RyuJIT, é algo parecido com isto: eu recomendo ver a descrição do PR, espero que tudo esteja claramente descrito lá.
recomendo ver a descrição do PR, espero que tudo esteja claramente descrito lá.Nem todas as otimizações são igualmente úteis.
As otimizações exigem uma taxa bastante alta:* Aumento = complexidade do código existente para suporte e leitura* Bugs em potencial: testar otimizações do compilador é incrivelmente difícil e fácil de perder algo e obter algum tipo de falha padrão dos usuários.* Compilação lenta* Aumentando o tamanho do binário JITComo você já entendeu, nem todas as idéias e protótipos de otimizações são aceitos e é necessário provar que eles têm direito à vida. Uma das maneiras aceitas de provar isso no .NET é executar o utilitário jit-utils, que irá compilar um conjunto de bibliotecas (todas BCL e corelib) e comparar o código do assembler para todos os métodos antes e depois das otimizações; é assim que este relatório procura otimização"str".Length. Além do relatório, ainda há um certo círculo de pessoas (como jkotas ) que, de relance, podem avaliar a utilidade e hackear tudo, desde o ponto mais alto de sua experiência e compreensão de quais locais do .NET podem ser um gargalo e quais não. E mais uma coisa: não julgue a otimização com o argumento “ninguém escreve”, “seria melhor apenas mostrar um aviso em Roslyn” - você nunca sabe como o seu código cuidará do JIT alinha tudo o que é possível e preenche constantes.