A compactação de cabeçalhos padrão apareceu no HTTP / 2, mas o corpo dos valores de URI, Cookie e User-Agent ainda pode ser dezenas de kilobytes e requer tokenização, pesquisa e comparação de substrings. A tarefa se torna crítica se um analisador HTTP precisar lidar com tráfego malicioso pesado. As bibliotecas padrão fornecem extensas ferramentas de processamento de strings, mas as strings HTTP têm suas próprias especificidades. É por essa especificidade que o analisador HTTP Tempesta FW foi desenvolvido. Seu desempenho é várias vezes maior em comparação às soluções modernas de código aberto e supera as mais rápidas delas.Alexander Krizhanovsky (krizhanovsky) fundador e arquiteto do sistema Tempesta Technologies, especialista em computação de alto desempenho no Linux / x86-64. Alexander falará sobre as peculiaridades da estrutura das seqüências HTTP, explicará por que as bibliotecas padrão são pouco adequadas para processá-las e apresentará a solução Tempesta FW.Sob o comando: como o HTTP Flood transforma seu analisador HTTP em um gargalo, problemas x86-64 com erros de previsão de ramificação, armazenamento em cache e memória insuficiente em tarefas típicas do analisador HTTP, comparando o FSM com saltos diretos, otimização GCC, vetorização automática, strspn () - e algoritmos do tipo strcasecmp () para seqüências de HTTP, SSE, AVX2 e ataques de injeção de filtragem usando o AVX2.Na Tempesta Technologies, desenvolvemos software personalizado: nos especializamos em áreas complexas relacionadas ao alto desempenho. Estamos especialmente orgulhosos do desenvolvimento do núcleo da primeira versão WAF da Positive Technologies. O Web Application Firewall (WAF) é um proxy HTTP: lida com uma análise muito profunda do tráfego HTTP para ataques (Web e DDoS). Nós escrevemos o primeiro núcleo para isso.Além da consultoria, estamos desenvolvendo o Tempesta FW - este é o Application Delivery Controller (ADC). Nós vamos falar sobre ele.Controlador de Entrega de Aplicativos
O Application Delivery Controller é um proxy HTTP com funcionalidade aprimorada. Mas falarei sobre um recurso relacionado à segurança - sobre a filtragem de ataques DDoS e Web. Mencionarei também limitações e mostrarei o trabalho e as funções com exemplos de código.
atuação
O Tempesta FW está embutido no kernel Linux TCP / IP Stack. Graças a isso e a várias outras otimizações, é muito rápido - ele pode processar 1,8 milhão de solicitações por segundo em hardware barato. Isso é 3 vezes mais rápido que o Nginx na carga máxima e também é rápido quando comparado com a abordagem de desvio de kernel.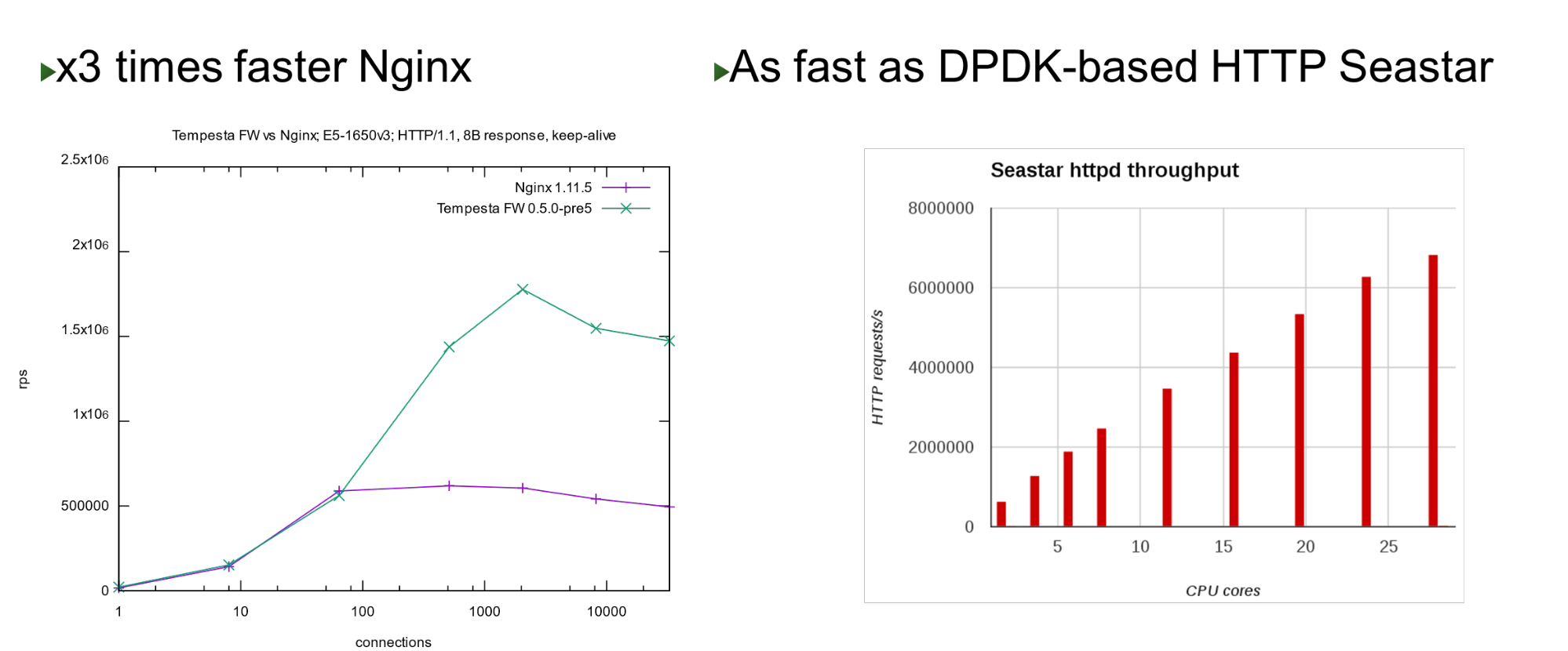 Em um pequeno número de núcleos, ele mostra desempenho semelhante ao projeto Seastar, usado no ScyllaDB (escrito em DPDK).
Em um pequeno número de núcleos, ele mostra desempenho semelhante ao projeto Seastar, usado no ScyllaDB (escrito em DPDK).Problema
O projeto nasceu quando começamos a trabalhar no PT AF - em 2013. Este WAF foi baseado em um popular acelerador HTTP de código aberto. Nginx, HAProxy, Varnish ou Apache Traffic são bons aceleradores HTTP: eles fornecem conteúdo fino, armazenam em cache, modificam, mas nenhum deles foi projetado para processamento e filtragem de tráfego em massa .Portanto, pensamos que, se houver um firewall no nível da rede, por que não continuar com essa idéia e integrar-se à pilha TCP / IP como um firewall no nível do aplicativo? Na verdade, descobriu-se Tempesta FW - um híbrido de acelerador HTTP e firewall .Nota: O Nginx será usado como exemplo no relatório porque é um servidor da web simples e popular. Em vez disso, poderia haver qualquer outro servidor HTTP de código aberto.HTTP
Vejamos nossa solicitação de HTTP (HTTP / (1, ~ 2)).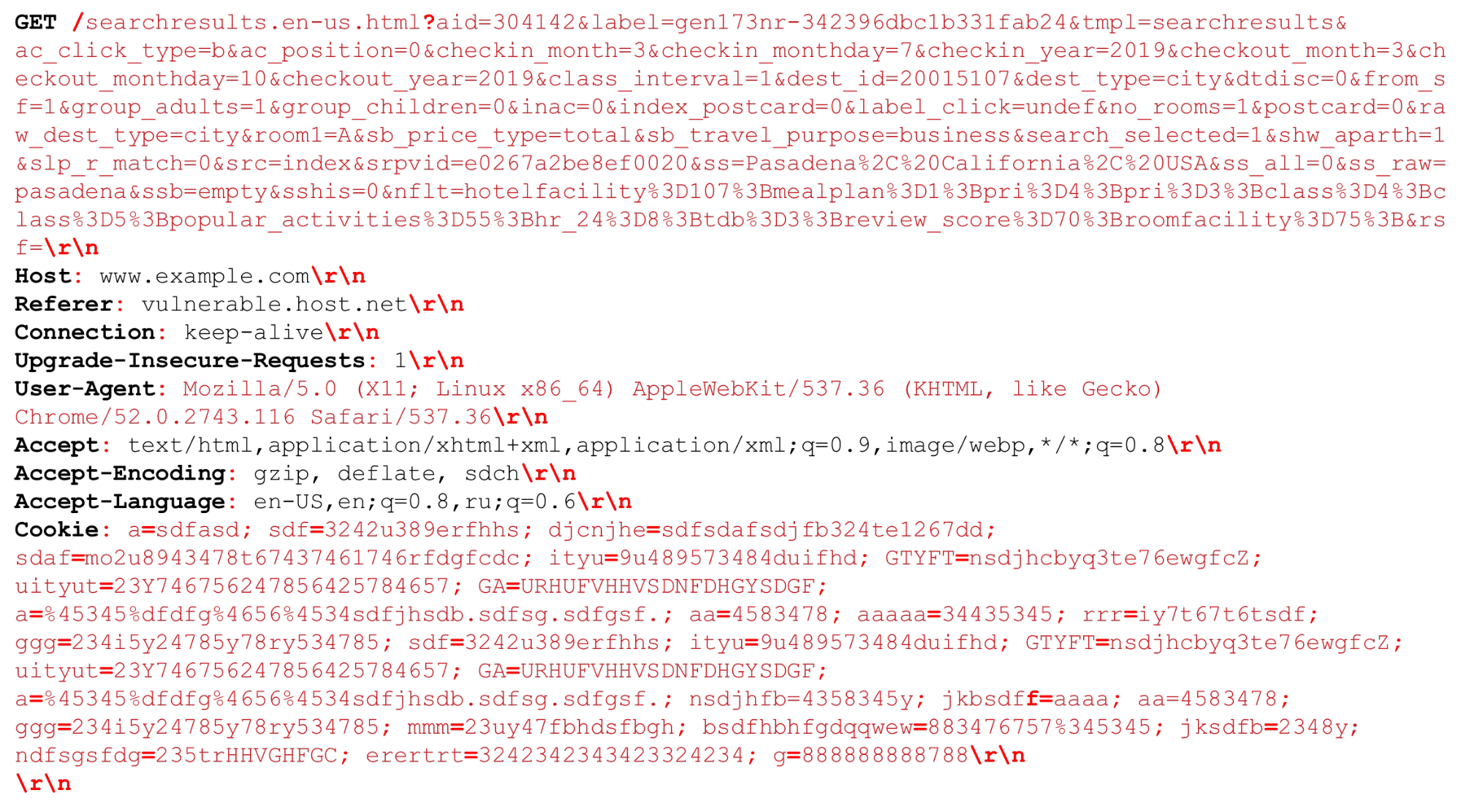 Podemos ter um URI muito grande. Os separadores importantes no momento da análise do HTTP são destacados em vermelho e negrito . Destacarei os recursos: cadeias grandes de vários kilobytes, bem como delimitadores diferentes, por exemplo, "ponto e vírgula" adicionais que precisamos analisar, ou a sequência "\ r \ n".Um pouco sobre o HTTP / 2 também precisa ser dito.
Podemos ter um URI muito grande. Os separadores importantes no momento da análise do HTTP são destacados em vermelho e negrito . Destacarei os recursos: cadeias grandes de vários kilobytes, bem como delimitadores diferentes, por exemplo, "ponto e vírgula" adicionais que precisamos analisar, ou a sequência "\ r \ n".Um pouco sobre o HTTP / 2 também precisa ser dito.Recursos HTTP / 2
HTTP / 2 é uma mistura de seqüências de caracteres e dados binários . Esse mix tem mais a ver com otimizar a largura de banda de uma conexão do que economizar recursos do servidor.O HTTP / 2 no HPACK usa uma tabela dinâmica . A primeira solicitação do cliente não é otimizada, não está na tabela. Você deve analisá-lo para que seja adicionado à tabela. Se o HTTP / 2 DDoS chegar até você, será esse o caso. No caso normal, o HTTP / 2 é um protocolo binário, mas você ainda precisa analisar o texto: nomes de cabeçalho de texto, dados.Codificação Huffman. Essa é uma codificação simples, mas o Huffman é monstruosamente difícil de programar rapidamente para a compactação: a codificação do Huffman cruza o limite de bytes, você não pode usar extensões de vetor e precisa usar bytes. Você não poderá processar dados rapidamente em 32 ou 16 bytes.Cookies, User-Agent, Referer, URIs podem ser muito grandes . Primeiro, remova o Huffman e envie-o para um analisador HTTP normal, o mesmo que no HTTP / 1. Embora seja permitido pelo RFC, não é recomendável compactar os cookies, porque são dados confidenciais - você não deve fornecer ao invasor informações sobre seu tamanho.Processamento HTTP lento . Todos os servidores HTTP primeiro decodificam o HTTP / 2 e depois enviam essas linhas para o analisador HTTP / 1 que o HTTP / 1 já usa.Qual é o problema com a análise HTTP / 1?- Você precisa programar rapidamente a máquina de estado.
- Você precisa processar rapidamente linhas consecutivas.
O tráfego malicioso tem como alvo a parte mais lenta (mais fraca) do processo. Portanto, se queremos fazer um filtro, devemos prestar atenção às partes lentas, para que elas também trabalhem rapidamente.Perfil do Nginx
Vejamos o perfil nginx sob o fluxo HTTP. Desative o log de acesso para que o sistema de arquivos não fique lento. Quando mesmo uma página de índice regular é solicitada, o analisador sobe na parte superior.Esquerda - "Perfil plano". Curiosamente, o ponto mais quente não é muito mais pesado que o outro, e depois o perfil desce suavemente. Isso significa, por exemplo, que otimizar a primeira função duas vezes não ajudará a melhorar significativamente o desempenho. Por isso, não otimizamos o mesmo Nginx, mas fizemos um novo projeto que melhorará o desempenho de toda a cauda do perfil.Como os analisadores HTTP regulares são codificados
Normalmente, temos um loop ( while) que é executado ao longo da linha e duas variáveis: state ( state) e data atual ( str_ptr).Entramos no ciclo (1) e olhamos para o estado atual (estado de verificação). Passamos para os dados recebidos (símbolo 'b') e implementamos alguma lógica. Passamos para o segundo estado (2). Vá para o final
Vá para o final switch(3) - esta é a segunda transição em relação ao início do nosso código e, possivelmente, a segunda falha no cache de instruções. Então vamos para o começo while(4), comemos o próximo caractere ... ... e novamente procuramos o estado nas instruções internas
... e novamente procuramos o estado nas instruções internas case 2:.Quando uma variável já foi atribuída a um statevalor2, poderíamos simplesmente ir para a próxima instrução. Mas, em vez disso, subiram novamente e desceram novamente. Nós "cortamos círculos" por código, em vez de simplesmente diminuir. Analisadores normais não, por exemplo, Ragel gera um analisador com transições diretas.
Analisador HTTP Nginx
Algumas palavras sobre o analisador nginx e seu ambiente.O Nginx funciona com a API de soquete normal - os dados que vão para o adaptador são copiados para o espaço do usuário. Como resultado, temos um grande bloco de dados no qual estamos procurando o que precisamos.O Nginx usa um algoritmo que funciona em duas passagens: primeiro ele procura por comprimento e depois verifica. Na primeira etapa, ele verifica a sequência de tokens, pesquisa o primeiro token ("trial"). No segundo, tokens, verifica o final da solicitação ( Get) e inicia switch, de acordo com o tamanho do token.for (p = b->pos; p < b->last; p++) {
...
switch (state) {
...
case sw_method:
if (ch == ' ') {
m = r->request_start;
switch (p - m) {
case 3:
if (ngx_str3_cmp(m, 'G', 'E', 'T', ' ')) {
...
}
if ((ch < 'A' || ch > 'Z') && ch != '_' && ch != '-')
return NGX_HTTP_PARSE_INVALID_METHOD;
break;
...
"Obter" está sempre no mesmo bloco de dados . O Tempesta FW funciona com cópia zero. Isso significa que os dados podem vir com um tamanho completamente arbitrário: 1 byte ou 1000 bytes cada. Este "mecanismo" não nos convém.Vamos ver como isso funciona switchno GCC.Gcc
Tabela de pesquisa . À esquerda, está um exemplo típico de enum: comece com 0, depois rótulos consecutivos, 26 constantes e, em seguida, algum código que processe tudo. À direita está o código que o compilador gera. Primeiro, compare a variável
Primeiro, compare a variável stateno registro EAX com uma constante. A seguir, apresentamos todos os rótulos na forma de uma matriz seqüencial de ponteiros de 8 bytes (tabela de pesquisa). Nesta instrução, repassamos o deslocamento nesta matriz - é uma dupla desreferenciação de ponteiros. Em baixo à direita está o código para o qual trocamos desta tabela.Acontece uma desreferenciação dupla da memória: se recebemos dados secretos, então, por bytes, encontramos o endereço na matriz e vamos para esse ponteiro. É importante saber que na vida ainda é pior do que no exemplo - para tabela de consulta, o compilador gerao código é mais complicado no caso de um script para um ataque Spectre.Pesquisa binária . O próximo caso switchnão é com constantes sequenciais, mas com arbitrárias. O código é o mesmo, mas agora o GCC não pode compilar uma matriz tão grande e usar constantes como o índice da matriz. Ele muda para a pesquisa binária. À direita, vemos uma comparação seqüencial, a transição para o endereço e a continuação da comparação - a pesquisa binária é por código.Analisador HTTP Nginx. Vamos ver o que é a máquina de estado nginx. Possui 9 kilobytes de código - isso é três vezes menor que o cache de primeiro nível na máquina na qual os benchmarks foram lançados (como na maioria dos processadores x86-64).
À direita, vemos uma comparação seqüencial, a transição para o endereço e a continuação da comparação - a pesquisa binária é por código.Analisador HTTP Nginx. Vamos ver o que é a máquina de estado nginx. Possui 9 kilobytes de código - isso é três vezes menor que o cache de primeiro nível na máquina na qual os benchmarks foram lançados (como na maioria dos processadores x86-64).$ nm -S /opt/nginx-1.11.5/sbin/nginx
| grep http_parse | cut -d' ' -f 2
| perl -le '$a += hex($_) while (<>); print $a'
9220
$ getconf LEVEL1_ICACHE_SIZE
32768
$ grep -c 'case sw_' src/http/ngx_http_parse.c
84
O analisador de cabeçalho nginx ngx_http_parse_header_line ()é um tokenizador simples. Ele não faz nada com os valores dos cabeçalhos e seus nomes, mas simplesmente coloca os tokens dos cabeçalhos HTTP em um hash. Se você precisar de qualquer valor de cabeçalho, verifique a tabela de cabeçalho e repita a análise.Devemos verificar rigorosamente os nomes e valores dos cabeçalhos por razões de segurança .Tempesta FW: validação de strings HTTP
Nossa máquina de estado é uma ordem de magnitude mais poderosa: fazemos a validação do cabeçalho RFC e imediatamente, no analisador, processamos quase tudo. Se nginx tem 80 estados, temos 520, e há mais deles. Se seguíssemos em frente switch, seria 10 vezes maior.Temos E / S de cópia zero - pedaços de tamanhos diferentes podem cortar dados em lugares diferentes. pedaços diferentes podem cortar nossos dados. Na E / S de cópia zero, por exemplo, "GET" pode (raramente) ocorrer como "GET", "GE" e "T" ou "G", "E" e "T", portanto, é necessário armazenar o estado entre partes de dados . Nós praticamente removemos os custos de E / S, mas no perfil ele aumenta - tudo está ruim. O analisador HTTP grande é um dos locais mais críticos no projeto.$ grep -c '__FSM_STATE\|__FSM_TX\|__FSM_METH_MOVE\|__TFW_HTTP_PARSE_' http_parser.c
520
7.64% [tempesta_fw] [k] tfw_http_parse_req
2.79% [e1000] [k] e1000_xmit_frame
2.32% [tempesta_fw] [k] __tfw_strspn_simd
2.31% [tempesta_fw] [k] __tfw_http_msg_add_str_data
1.60% [tempesta_fw] [k] __new_pgfrag
1.58% [kernel] [k] skb_release_data
1.55% [tempesta_fw] [k] __str_grow_tree
1.41% [kernel] [k] __inet_lookup_established
1.35% [tempesta_fw] [k] tfw_cache_do_action
1.35% [tempesta_fw] [k] __tfw_strcmpspn
O que fazer para melhorar esta situação?Referências diretas do FSM
A primeira coisa que fazemos é usar não um loop, mas transições diretas por labels ( go to) . Geradores de analisadores normais como Ragel fazem isso. Codificamos cada um de nossos estados com um rótulo
Codificamos cada um de nossos estados com um rótulo switche um rótulo em C com o mesmo nome . Toda vez que queremos ir, encontramos um rótulo switchou acessamos o mesmo estado diretamente do código. A primeira vez que passamos switch, e depois dentro dela, vamos diretamente para o rótulo desejado.Desvantagem : quando queremos mudar para o próximo estado, devemos avaliar imediatamente se ainda temos dados disponíveis (porque E / S de cópia zero). Corpo da condiçãoforEle é copiado para cada estado: em vez de uma condição em um FSM regular acionado por comutador, temos 500 deles de acordo com o número de estados. Gerar código para cada estado não é bom.No caso de grandes máquinas de estado, pois forcom um switchinterior grande , o GTC também repete a condição forvárias vezes dentro do código.Substitua por switchtransições diretas. A próxima otimização é que não a usamos switche mudamos para direcionar saltos para os meta endereços salvos. Queremos ir imediatamente para o ponto desejado assim que entrarmos na função. O GCC permite que você faça isso. O GCC tem uma extensão padrão que pode ajudar. Pegamos o nome do rótulo (aqui está
O GCC tem uma extensão padrão que pode ajudar. Pegamos o nome do rótulo (aqui está from) e atribuímos seu endereço a alguma variável C via duplo e comercial (&&). Agora podemos fazer uma instrução de salto diretojmppara o endereço desta etiqueta com goto.Vamos ver o que vem disso.Desempenho de conversão direta
Em um pequeno número de estados, o gerador de código de transição direta é ainda um pouco mais lento que o normal switch. Mas para grandes máquinas estaduais, a produtividade dobra. Se a máquina de estado for pequena, é melhor usar a máquina usual switch.$ grep -m 2 'model name\|bugs' /proc/cpuinfo
model name : Intel(R) Core(TM) i7-6500U CPU @ 2.50GHz
bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf
$ gcc --version|head -1
gcc (GCC) 8.2.1 20181105 (Red Hat 8.2.1-5)
States Switch-driven automaton Goto-driven automaton
7 header_line: 139ms header_line: 156ms
27 request_line: 210ms request_line: 186ms
406 big_header_line: 1406ms goto_big_header_line: 727ms
Nota: O código Tempesta é mais complicado que os exemplos. O GitHub tem todos os benchmarks para que você possa ver tudo em detalhes. O código do analisador original está disponível no link (analisador HTTP principal). Além disso, no Tempesta FW, existem analisadores menores que usam o FSM mais facilmente.Por que as transições diretas podem ser mais lentas
Na máquina de estado, passamos por muito código, portanto (esperado) haverá muitas previsões erradas de ramificação. Vamos executar "criação de perfil" de acordo com a previsão de desvio de ramificação:perf record -e branch-misses -g ./http_benchmark
406 states: switch - 38% on switch(),
direct jumps - 13% on header value parsing
7,27 states: switch - <18% switch(), up to 40% for()
direct jumps – up to 46% on header & URI parsing
Em uma grande máquina de estado com 406 estados, gastamos 38% do tempo processando transições switch. Em uma máquina de estado com transições diretas, os pontos ativos são análise de linha. A análise de uma sequência em cada estado inclui a verificação da condição do final da sequência: a condição forna máquina de estados ativada switch.perf stat -e L1-icache-load-misses ./http_benchmark
Switch-driven automaton Goto-driven automaton
big FSM code size: 29156 49202
L1-icache-load-misses: 4M 2M
A seguir, vejamos a criação de perfil de ambos os tipos de máquina de estado pelos erros de cache de instruções L1 de eventos - quase 30 kilobytes por switche 50 kilobytes por saltos diretos (mais do que o cache das instruções de primeiro nível).Parece que, se não cabermos no cache, deve haver muitas falhas de cache para essa máquina de estado. Mas não, eles são 2 vezes menos. Isso ocorre porque o cache funciona melhor: trabalhamos com o código sequencialmente e conseguimos extrair dados dos caches mais antigos.O compilador altera a ordem do código
Quando programamos o código da máquina de estados go to, primeiro temos os estados que serão chamados primeiro quando os dados forem recebidos: o método HTTP, URI e, em seguida, os cabeçalhos HTTP. Parece lógico que o código seja carregado no cache do processador sequencialmente, de cima para baixo, assim como analisamos os dados. Mas isso está completamente errado. Se você olhar o código do assembler, verá coisas incríveis. À esquerda está o que programamos: primeiro analisamos os métodos
À esquerda está o que programamos: primeiro analisamos os métodos GETe POSTdepois em algum lugar muito abaixo do método improvável UNLOCK. Portanto, esperamos ver a análise GETe no início do montador POST, e então UNLOCK. Mas tudo é exatamente o oposto: GETno meio, POSTno final e UNLOCKacima.Isso ocorre porque o compilador não entende como os dados chegam até nós. Ele distribui o código de acordo com sua imagem do belo código. Para que ele organize o código na ordem correta, devemos usar a barreira do compilador .A barreira do compilador é um manequim de montagem através do qual o compilador não reordenará. Simplesmente colocando essas barreiras, melhoramos a produtividade em 4% .STATE(sw_method) {
...
MATCH(NGX_HTTP_GET, "GET ");
MATCH(NGX_HTTP_POST, "POST");
__asm__ __volatile__("": : :"memory");
...
METH_MOVE(Req_MethU, 'N', Req_MethUn);
METH_MOVE(Req_MethUn, 'L', Req_MethUnl);
METH_MOVE(Req_MethUnl, 'O', Req_MethUnlo);
METH_MOVE(Req_MethUnlo, 'C', Req_MethUnloc);
METH_MOVE_finish(Req_MethUnloc, 'K', NGX_HTTP_UNLOCK)
Componha o código à sua maneira
Como o compilador não organiza os dados como desejamos, faremos a otimização guiada pelo criador de perfil (otimização sob o controle do criador de perfil). A otimização guiada por perfilador (PGO) é o número total de amostras, não uma sequência de chamadas. Por exemplo, um URI recebe mais amostras que uma análise de método, portanto, posicionará o código de processamento do URI antes de processar o método.Como funciona? Escreveremos o código, executaremos benchmarks nele, forneceremos o resultado da criação de perfil para o compilador e ele gerará o código ideal para nossas cargas. Mas o problema é que ele simplesmente compila as seções mais quentes do código, mas não controla a dependência de tempo. Se o maior URI da carga, esse será o local mais quente. O URI subirá para o topo da função e o PGO não mostrará que o nome do método está sempre antes do URI. Por conseguinte, o PGO não funciona.Req_Method: {
if (likely(PI(p) == CHAR4_INT('G', 'E', 'T', ' '))) {
...
goto Req_Uri;
}
if (likely(PI(p) == CHAR4_INT('P', 'O', 'S', 'T'))) {
...
goto Req_UriSpace;
}
goto Req_Meth_SlowPath;
}
...
Req_Uri:
...
Req_Meth_SlowPath:
...
O que funciona?likely/ unlikely macros (para código do kernel do Linux, os intrínsecos do GCC estão disponíveis no espaço do usuário __builtin_expect()). Eles dizem qual código colocar mais perto. Por exemplo, os relatórios prováveis de que o corpo da solicitação deve ficar imediatamente para trás if. A pré-busca do código (pré-busca do processador) selecionará esse código e tudo será rápido. A imagem mostra o início do método de análise, o fim e a barreira. Não esperávamos ver o código por trás da barreira. Parece que não deveria ser - nós colocamos uma barreira.Mas o que acontece na realidade? O compilador vê a
A imagem mostra o início do método de análise, o fim e a barreira. Não esperávamos ver o código por trás da barreira. Parece que não deveria ser - nós colocamos uma barreira.Mas o que acontece na realidade? O compilador vê a likelycondição - é mais provável que entremos no corpo da condição e lá mudaremos para um salto incondicional no rótuloReq_Uri. Acontece que o código que está após a nossa condição não é processado no "caminho quente". O compilador move o código sob o rótulo para trás if, apesar da barreira, porque a condição de código quente é atendida.Para isso não, o GCC tem uma extensão: os atributos hote coldpara os rótulos. Eles dizem que etiqueta está quente (provavelmente) e qual está fria (menos provável). Aqui concordamos com o que é
Aqui concordamos com o que é GETmais provável POSTe deixamos para ele likely. Sob essa condição, o processamento de URI aumenta e POSTfica abaixo. Todo o outro código para a máquina de estado menos provável fica abaixo porque a etiqueta está fria.-O3 ambíguo
Vamos dar uma olhada na otimização do compilador. A primeira coisa que vem à mente é usar não o O2, mas o O3 - deve ser mais rápido. Mas isso não é verdade - o O3 às vezes gera código pior. O3 é uma coleção de algumas otimizações . Se os adicionarmos ao O2 separadamente, obteremos diferentes opções: algumas otimizações ajudam, outras interferem. Para o nosso código específico, selecionamos apenas as otimizações que geram melhor o código. Deixamos o melhor resultado - aqui estão 1.820 segundos em relação a 1.838 e 1.858.Algumas opções são destacadas em verde - é a vetorização automática.
O3 é uma coleção de algumas otimizações . Se os adicionarmos ao O2 separadamente, obteremos diferentes opções: algumas otimizações ajudam, outras interferem. Para o nosso código específico, selecionamos apenas as otimizações que geram melhor o código. Deixamos o melhor resultado - aqui estão 1.820 segundos em relação a 1.838 e 1.858.Algumas opções são destacadas em verde - é a vetorização automática.Autovectorização
Um exemplo de ciclo do guia do GCC .int a[256], b[256], c[256];
void foo () {
for (int i = 0; i < 256; i++)
a[i] = b[i] + c[i];
}
Se tivermos uma matriz variável que se repita, podemos otimizar o ciclo - decompor em vetores. Por padrão, a auto- vetorização é ativada no terceiro nível de otimização -O3 : o GCC gera código vetorial onde puder. Mas nem todo código pode ser vetorizado automaticamente (mesmo se for vetorizado em princípio).Podemos ativar a opção GCC -fopt-info-vec-all, que mostra o que foi vetorizado e o que não é. Entendemos que, para nosso benchmark, nada é vetorizado, mas o código ainda é gerado pior. Portanto, a vetorização nem sempre funciona: às vezes atrasa o código. Mas sempre podemos ver o que foi vetorizado e o que não é e desativar a vetorização, se necessário.Alinhamento: como comparar uma string com GET?
Fazemos um pequeno hack, como no nginx: não analisamos linhas por bytes, mas calculamos inte comparamos as linhas com eles.#define CHAR4_INT(a, b, c, d) ((d << 24) | (c << 16) | (b << 8) | a)
if (p == CHAR4_INT('G', 'E', 'T', ' ')))
Sabemos que, se não estiver intalinhado, diminui de 2 a 3 vezes. Escrevemos uma pequena referência que comprova isso.$ ./int_align
Unaligned access = 6.20482
Aligned access = 2.87012
Read four bytes = 2.45249
Então tente alinhar int. Vamos procurar, se o endereço estiver intalinhado, comparar por int, se não, bytes. (((long)(p) & 3)
? ((unsigned int)((p)[0]) | ((unsigned int)((p)[1]) << 8)
| ((unsigned int)((p)[2]) << 16) | ((unsigned int)((p)[3]) << 24))
: *(unsigned int *)(p));
Mas acontece que essa abordagem funciona pior:full request line: no difference
method only: unaligned - 214ms
aligned - 231ms
bytes - 216ms
Em resumo: existe uma diferença entre o código de referência isolado e não otimizável e o código analisador embutido, que perde sua otimização devido à grande quantidade de código. Não houve penalidade no perfil.Nota: uma discussão detalhada de por que isso está acontecendo em nossa tarefa pode ser lida no GitHub .Por que as strings HTTP são importantes para nós?
Por exemplo, este é um URI normal: se você for exigente o suficiente sobre o hotel, vá para Reservas e defina alguns filtros, obtenha um URI de mais de um kilobyte.O Nginx possui uma máquina de análise bastante massiva em
se você for exigente o suficiente sobre o hotel, vá para Reservas e defina alguns filtros, obtenha um URI de mais de um kilobyte.O Nginx possui uma máquina de análise bastante massiva em switch/ case. Não funciona muito rápido. Além disso, no caso do Tempesta FW, precisamos não apenas analisar o URI, mas também verificá-lo quanto a injeções.case sw_check_uri:
if (usual[ch >> 5] & (1U << (ch & 0x1f)))
break;
switch (ch) {
case '/':
r->uri_ext = NULL;
state = sw_after_slash_in_uri;
break;
case '.':
r->uri_ext = p + 1;
break;
case ' ':
r->uri_end = p;
state = sw_check_uri_http_09;
break;
case CR:
r->uri_end = p;
r->http_minor = 9;
state = sw_almost_done;
break;
case LF:
r->uri_end = p;
r->http_minor = 9;
goto done;
case '%':
r->quoted_uri = 1;
...
Outro URI: /redir_lang.jsp?lang=foobar%0d%0aContent-Length :% 200 %0d% 0a% 0d% 0aHTTP / 1.1% 20200% 20OK% 0d% 0aContent-Type:% 20text /html% 0d% 0aContent -Length:% 2019% 0d% 0a% 0d% 0aShazam </html>.Parece o primeiro, mas tem uma injeção. Você terá que cavar fundo o suficiente para entender isso.Vamos executar um teste : faça o primeiro URI, alimente o wrk, configure-o para nginx e veja se a análise do nginx fica muito quente. Se na consulta de índice regular anterior ficou claro que o analisador já está no topo, aqui fica ainda mais quente.
Se na consulta de índice regular anterior ficou claro que o analisador já está no topo, aqui fica ainda mais quente.8.62% nginx [.] ngx_http_parse_request_line
2.52% nginx [.] ngx_http_parse_header_line
1.42% nginx [.] ngx_palloc
0.90% [kernel] [k] copy_user_enhanced_fast_string
0.85% nginx [.] ngx_strstrn
0.78% libc-2.24.so [.] _int_malloc
0.69% nginx [.] ngx_hash_find
0.66% [kernel] [k] tcp_recvmsg
O que há de especial nas seqüências HTTP? Existem diferentes separadores ' : 'e ' , ', e até o final das linhas, que podem ser de byte duplo \r\nou de byte único \n, discutidos no início. Não há terminação 0 das linhas C - por razões de segurança, queremos verificar com mais precisão o que nos chega. Temos duas funções padrão que ajudam no analisador.strspn: verifica o alfabeto, os caracteres disponíveis em uma sequência de caracteres, compila dinamicamente um alfabeto válido, embora seja conhecido no estágio de compilação do programa.strcasecmp(). Não há necessidade de caso convertido para comparar xcom Foo:. Na maioria dos casos strcasecmp(), apenas a conformidade / não conformidade é necessária e você não precisa conhecer a posição na linha.
Eles trabalham devagar. Vamos ver os benchmarks e entender o que há de errado com eles.Analisadores rápidos
Existem vários analisadores.O Nginx é o analisador mais simples, que analisa rigorosamente a conformidade com RFC. Também existem analisadores PicoHTTPParser (H2O) e Cloudflare. Eles processam dados mais rapidamente, mas podem pular caracteres que não são permitidos pelo RFC.PCMESTRI. Os analisadores usam várias abordagens diferentes. A primeira é a instrução PCMESTRI, que é usada no analisador Pico.Definimos intervalos nas instruções. Infelizmente, podemos carregar 16 caracteres ou 8 intervalos. Se o intervalo consistir em apenas um caractere - basta repetir. Devido a essa limitação, o analisador Pico não pode verificar completamente a conformidade com a RFC, porque a RFC possui mais de 8 intervalos nesse local. Carregamos o alfabeto no registrador, carregamos a string, executamos a instrução. Na saída, vemos rapidamente se há uma coincidência ou não.AVX2 - Abordagem CloudFlare. O analisador CloudFlare, usando o AVX2, processa 32 bytes de uma string por vez, em vez de 16 bytes com um analisador Pico. A análise é melhor no CloudFlare porque foi transferida para o AVX2.
Carregamos o alfabeto no registrador, carregamos a string, executamos a instrução. Na saída, vemos rapidamente se há uma coincidência ou não.AVX2 - Abordagem CloudFlare. O analisador CloudFlare, usando o AVX2, processa 32 bytes de uma string por vez, em vez de 16 bytes com um analisador Pico. A análise é melhor no CloudFlare porque foi transferida para o AVX2. Verificamos todos os caracteres em um espaço na tabela ASCII, todos os caracteres são maiores que 128 e atingimos o intervalo entre eles. Código simples é rápido.Compare PCMESTRI e AVX2. Para nós, o limite atual é de 1500. Esse é o tamanho máximo do pacote que chega até nós. Vemos que o código AVX2 no big data é muito mais rápido que o analisador Pico. Mas funciona mais lentamente em pequenos dados, porque as instruções são mais pesadas no AVX2.
Verificamos todos os caracteres em um espaço na tabela ASCII, todos os caracteres são maiores que 128 e atingimos o intervalo entre eles. Código simples é rápido.Compare PCMESTRI e AVX2. Para nós, o limite atual é de 1500. Esse é o tamanho máximo do pacote que chega até nós. Vemos que o código AVX2 no big data é muito mais rápido que o analisador Pico. Mas funciona mais lentamente em pequenos dados, porque as instruções são mais pesadas no AVX2. Comparável a
Comparável astrspn. Se decidirmos usar strspn, as coisas pioram, especialmente em big data. No analisador "combate" não pode ser usado strspn.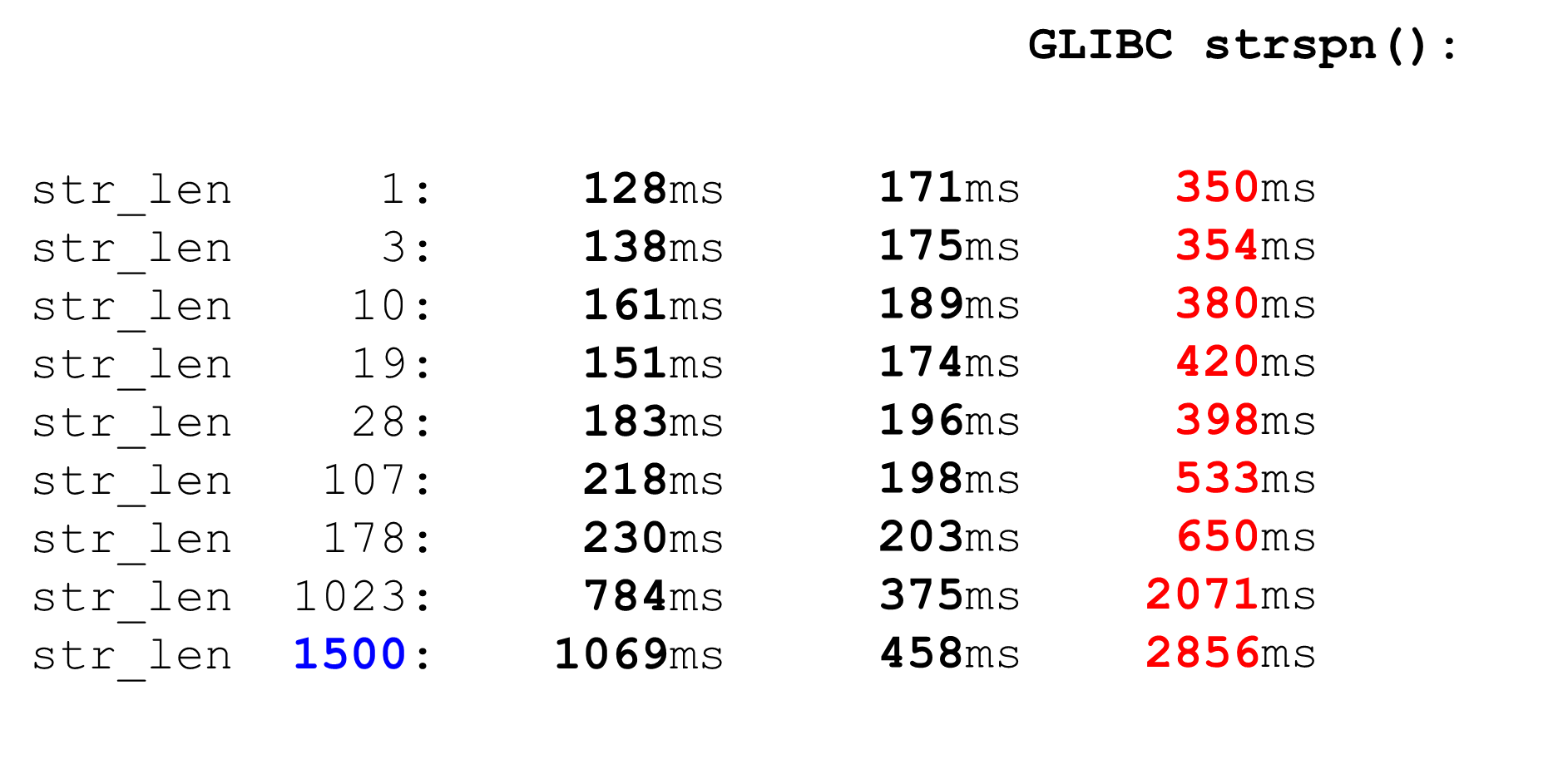
O Tempesta matcher é mais rápido e preciso
Nosso analisador de velocidade é como esses dois. Em dados pequenos, é tão rápido quanto um analisador Pico, em grandes, como o CloudFlare. No entanto, ele não ignora caracteres inválidos. Como o analisador é organizado? Nós, como nginx, definimos uma matriz de bytes e verificamos os dados de entrada por ela - este é o prólogo da função. Aqui, trabalhamos apenas com prazos curtos, usamos
Como o analisador é organizado? Nós, como nginx, definimos uma matriz de bytes e verificamos os dados de entrada por ela - este é o prólogo da função. Aqui, trabalhamos apenas com prazos curtos, usamos likelyporque a predição incorreta de ramificação é mais dolorosa para linhas curtas do que para linhas longas. Nós pegamos esse código. Temos um limite de 4 por causa da última linha - devemos escrever uma condição bastante poderosa. Se processarmos mais de 4 bytes, a condição será mais difícil e o código mais lento.static const unsigned char uri_a[] __attribute__((aligned(64))) = {
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
...
if (likely(len <= 4)) {
switch (len) {
case 0:
return 0;
case 4:
c3 = uri_a[s[3]];
case 3:
c2 = uri_a[s[2]];
case 2:
c1 = uri_a[s[1]];
case 1:
c0 = uri_a[s[0]];
}
return (c0 & c1) == 0 ? c0 : 2 + (c2 ? c2 + c3 : 0);
}
Laço principal e cauda grande. No ciclo de processamento principal, dividimos os dados: se for longo o suficiente, processamos 128, 64, 32 ou 16 bytes cada. Faz sentido processar 128 cada: paralelamente, usamos vários canais de processador (vários pipeline) e um processador superescalar.for ( ; unlikely(s + 128 <= end); s += 128) {
n = match_symbols_mask128_c(__C.URI_BM, s);
if (n < 128)
return s - (unsigned char *)str + n;
}
if (unlikely(s + 64 <= end)) {
n = match_symbols_mask64_c(__C.URI_BM, s);
if (n < 64)
return s - (unsigned char *)str + n;
s += 64;
}
if (unlikely(s + 32 <= end)) {
n = match_symbols_mask32_c(__C.URI_BM, s);
if (n < 32)
return s - (unsigned char *)str + n;
s += 32;
}
if (unlikely(s + 16 <= end)) {
n = match_symbols_mask16_c(__C.URI_BM128, s);
if (n < 16)
return s - (unsigned char *)str + n;
s += 16;
}
Rabo. O final da função é semelhante ao início. Se tivermos menos de 16 bytes, processaremos 4 bytes em um loop e não mais que 3 bytes no final.while (s + 4 <= end) {
c0 = uri_a[s[0]];
c1 = uri_a[s[1]];
c2 = uri_a[s[2]];
c3 = uri_a[s[3]];
if (!(c0 & c1 & c2 & c3)) {
n = s - (unsigned char *)str;
return !(c0 & c1) ? n + c0 : n + 2 + (c2 ? c2 + c3 : 0);
}
s += 4;
}
c0 = c1 = c2 = 0;
switch (end - s) {
case 3:
c2 = uri_a[s[2]];
case 2:
c1 = uri_a[s[1]];
case 1:
c0 = uri_a[s[0]];
}
n = s - (unsigned char *)str;
return !(c0 & c1) ? n + c0 : n + 2 + c2;
Carregamos máscaras e dados de bits - este é o algoritmo principal do corpo principal da função. Apresentamos uma tabela ASCII (como na figura) com 16 linhas e 8 colunas. Primeiro, codificamos nossas linhas da tabela no primeiro registro do BM URI: a primeira e a segunda linha.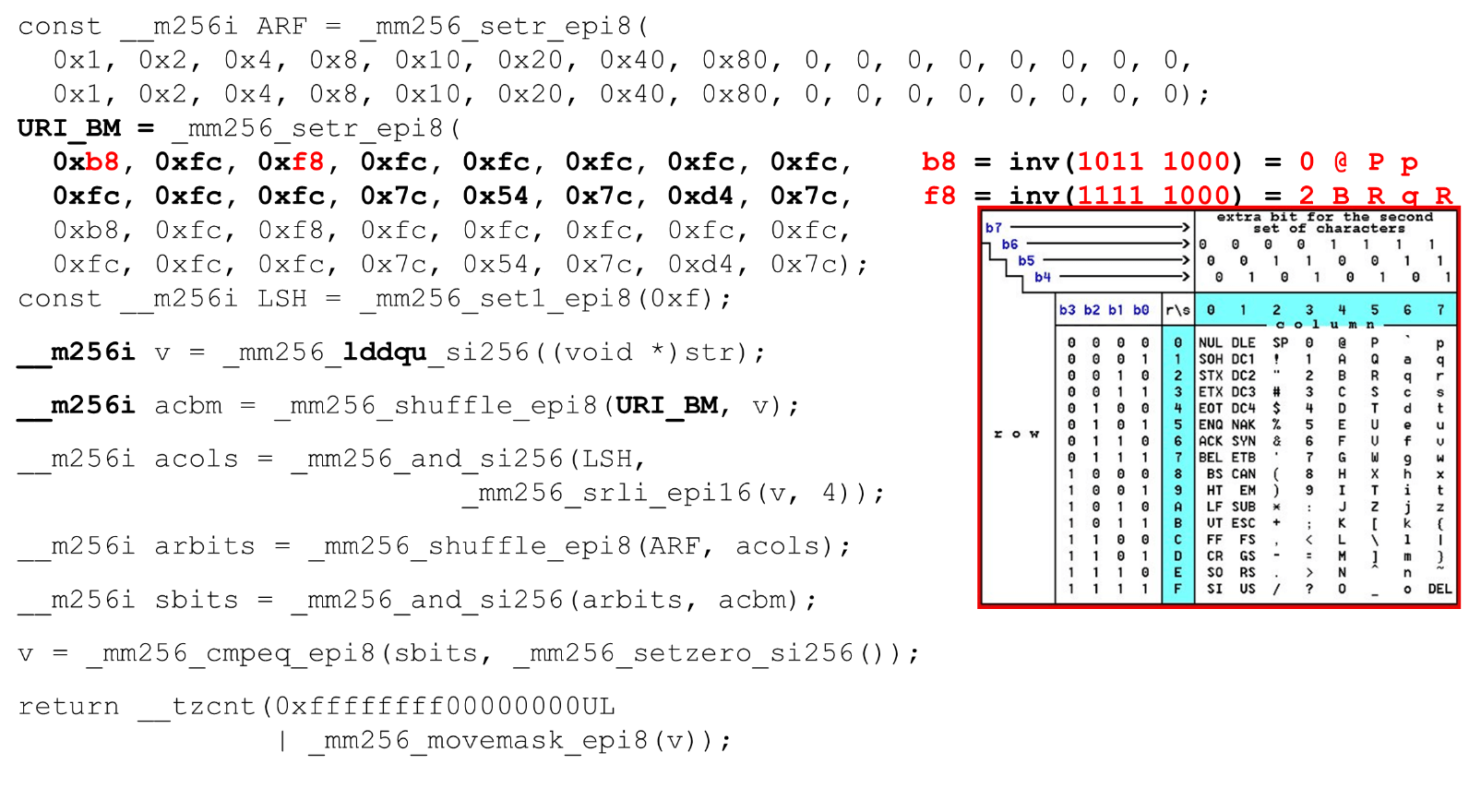 Os símbolos reais que permitimos são
Os símbolos reais que permitimos são 0 @ P pe 2 B R q R. Eles são codificados da seguinte forma: b8 = inv(1011 1000) = 0 @ P p, f8 = inv(1111 1000) = 2 B R q R.Codificamos na ordem inversa: começamos com 0, o primeiro caractere de serviço não é permitido e, em seguida, as unidades são permitidas.Defina as máscaras de bits ASCII. Por exemplo, aparece uma linha "pr": o primeiro caractere da primeira linha é ASCII, o segundo da segunda linha. Executamos a instrução shuffle, que embaralha nossas linhas de tabela codificadas de acordo com a ordem desses caracteres na entrada. ID da coluna para entrada. Em seguida, colocamos as colunas da tabela ASCII em um registro diferente. Depois, cruzamos os registros de colunas e linhas e obtemos uma correspondência: nosso caráter ou não.Como as colunas são os 4 bits mais significativos do byte, mudamos para a esquerda. O AVX possui um deslocamento de apenas 2 bytes; primeiro, mude o byte e depois n com nossa máscara para obter apenas bits significativos.
ID da coluna para entrada. Em seguida, colocamos as colunas da tabela ASCII em um registro diferente. Depois, cruzamos os registros de colunas e linhas e obtemos uma correspondência: nosso caráter ou não.Como as colunas são os 4 bits mais significativos do byte, mudamos para a esquerda. O AVX possui um deslocamento de apenas 2 bytes; primeiro, mude o byte e depois n com nossa máscara para obter apenas bits significativos. Organizando colunas ASCII Execute o segundo shuffle, mova a coluna para as posições desejadas. Nos dois casos, o byte de entrada da última coluna, portanto, na primeira e na segunda posição, obtemos a mesma coluna.
Organizando colunas ASCII Execute o segundo shuffle, mova a coluna para as posições desejadas. Nos dois casos, o byte de entrada da última coluna, portanto, na primeira e na segunda posição, obtemos a mesma coluna.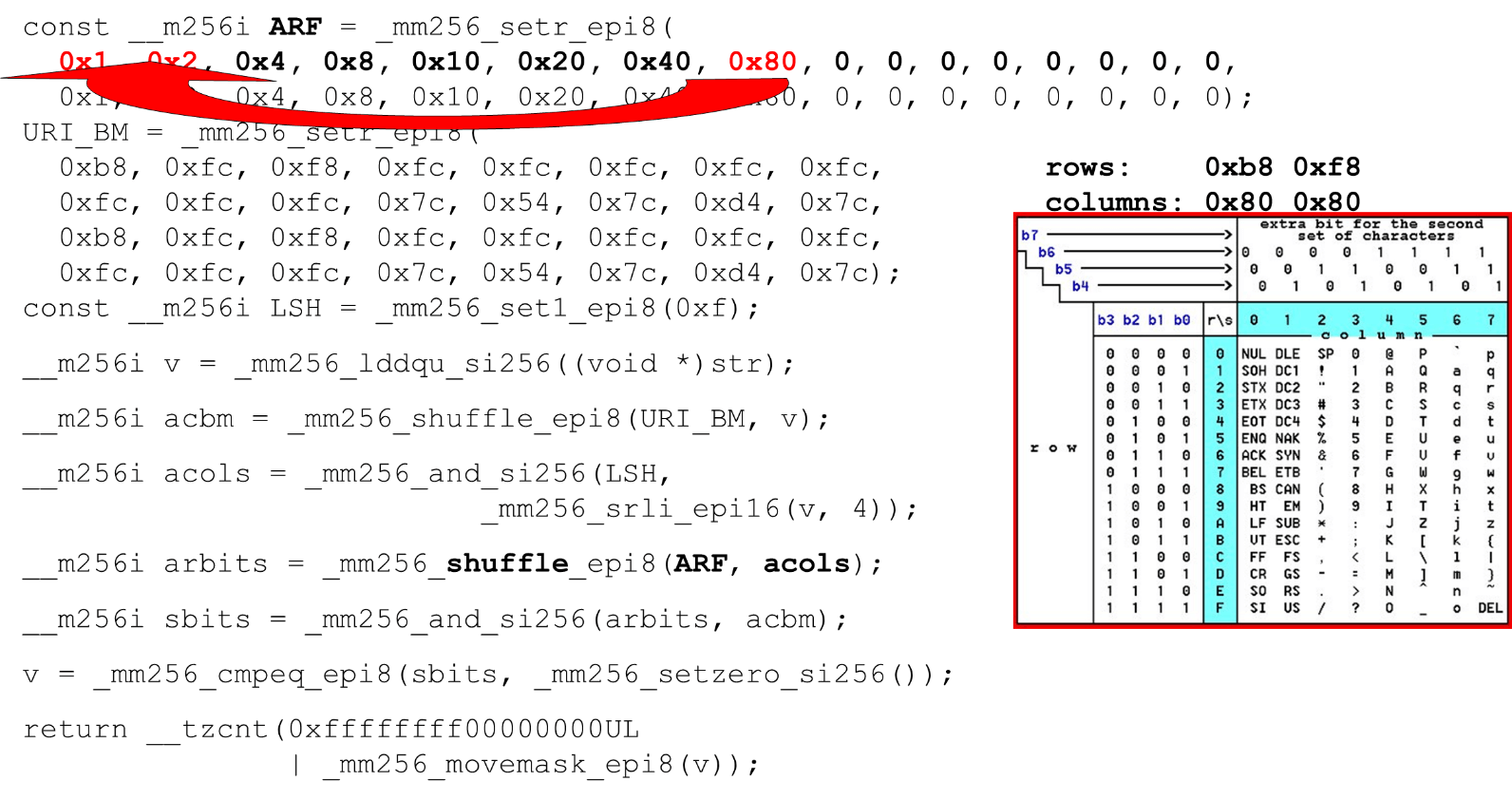 Interseção de colunas e linhas de máscaras . Fazemos
Interseção de colunas e linhas de máscaras . Fazemos and("cruzamos" as colunas com as colunas) e obtemos que os dados de entrada são válidos - o resultadoandda interseção de colunas e linhas não é zero. Conte o número de zeros no final. Coletamos tudo do vetor
Conte o número de zeros no final. Coletamos tudo do vetor inte o devolvemos à saída - de maneira simples. Personalize os alfabetos. Trabalhando com a tabela ASCII, obtemos um recurso barato: usamos tabelas estáticas, mas nada impede de perguntar ao usuário qual alfabeto está disponível para URIs, nomes e valores de cabeçalhos diferentes. A solicitação HTTP URI e o cabeçalho usam 8 alfabetos (mais ou menos) para analisar uma solicitação HTTP. Essas tabelas podem ser carregadas no mesmo código e comparadas em um único alfabeto especificado pelo usuário, um URI válido. Caso contrário, é diferente.
Personalize os alfabetos. Trabalhando com a tabela ASCII, obtemos um recurso barato: usamos tabelas estáticas, mas nada impede de perguntar ao usuário qual alfabeto está disponível para URIs, nomes e valores de cabeçalhos diferentes. A solicitação HTTP URI e o cabeçalho usam 8 alfabetos (mais ou menos) para analisar uma solicitação HTTP. Essas tabelas podem ser carregadas no mesmo código e comparadas em um único alfabeto especificado pelo usuário, um URI válido. Caso contrário, é diferente.Ataques
Alguns casos em que isso pode ser útil.Ataque do SSRF com o BlackHat'17 (“Uma Nova Era do SSRF”): http://foo@evil.com:80@google.com/- um símbolo improvável de e comercial. Em algumas aplicações, é usado, em outras não. Mas se você não o estiver usando, poderá excluí-lo do alfabeto válido e o ataque será bloqueado.RCE-ataque: «eficaz é a executar ataques de injeção de comando como», BSides'16: User-Agent: ...;echo NAELBD$((26+58))$echo(echo NAELBD)NAELBD.... O User-Agent é um cabeçalho estático, mas há casos de um ataque RCE quando alguns vêm shellcom caracteres atípicos para o User-Agent. Nós nos protegemos, exceto pelo cifrão.Substituição de caminho relativo . O último caso é o que o Google teve em 2016. Aparelhos cacheados, dois pontos, chegaram ao URI .../gallery?q=%0a{}*{background:red}/..//apis/howto_guide.html. Esses são caracteres improváveis que podem ser excluídos do alfabeto.strcasecmp ()
Este é um código bastante trivial. Também comparamos cadeias de caracteres de 32 bytes, duas matrizes cada.__m256i CASE = _mm256_set1_epi8(0x20);
__m256i A = _mm256_set1_epi8('A' – 0x80);
__m256i D = _mm256_set1_epi8('Z' - 'A' + 1 – 0x80);
__m256i sub = _mm256_sub_epi8(str1, A);
__m256i cmp_r = _mm256_cmpgt_epi8(D, sub);
__m256i lc = _mm256_and_si256(cmp_r, CASE);
__m256i vl = _mm256_or_si256(str1, lc);
__m256i eq = _mm256_cmpeq_epi8(vl, str2);
return ~_mm256_movemask_epi8(eq);
Damos ao registro apenas uma linha, porque no segundo programamos as constantes em nosso analisador em minúsculas. Como temos comparações significativas, subtraímos 128 de cada byte (um truque do Hacker's Delight).Também comparamos o intervalo de um caractere válido: se podemos registrar para essa sequência ou não, é uma letra ou não. No momento de verificar isso, em vez de duas comparações de a a z, podemos usar apenas uma comparação (um truque do Hacker's Delight) e passar para uma constante.Desempenho strcasecmp ()
Tempesta é muito mais rápido que GLIBC, mesmo a nova versão (18 ou 19). O código strcasecmp()também usa o AVX, mas não a segunda versão. O AVX2 é mais rápido, portanto, o Tempesta possui um código mais rápido.
FPU do kernel Linux
Usamos extensões de processador de vetores - elas estão disponíveis no kernel. As instruções do vetor são processadas pelo módulo do processador FPU. Este não é o módulo principal do processador, não os principais registradores, mas bastante volumoso.Portanto, há otimização no Linux. Se formos do kernel para o espaço do usuário e voltarmos, não salvaremos o contexto dos registros da FPU (XMM, YMM, ZMM): alteramos o contexto apenas dos registros do módulo do processador principal. Supõe-se que o kernel do SO não funcione com a extensão vetorial do processador. Mas se você precisar, por exemplo, a criptografia pode fazê-lo, mas precisa usar fpu_begine fpu_endsalvar e restaurar o contexto do registro da FPU:__kernel_fpu_begin_bh();
memcpy_avx(dst, src, n);
__kernel_fpu_end_bh();
Essas são macros nativas que salvam e restauram o estado do módulo do processador , responsável pelos registros de vetores. Estes são recursos bastante lentos.AVX e SSE
Antes dos parâmetros de referência para salvar e restaurar o contexto da FPU, algumas palavras sobre operações vetoriais. Por que às vezes faz sentido trabalhar com assembler? Às vezes, o GCC gera código abaixo do ideal. O problema é que, nos modelos mais antigos de processador, há uma penalidade significativa na transição do SSE para o AVX. O GCC possui uma nova chave vzeroupper- use-a para que não gere essa instrução vzeroupper, que limpa os registros e remove essa penalidade.Você precisará usar esta instrução apenas se estiver trabalhando com código antigo que foi compilado para SSE por terceiros. Este não é o nosso caso e podemos jogar essas instruções com segurança.FPU
Temos auto-vetorização no processador. Isso significa que em qualquer código de espaço do usuário haverá operações de vetor. Quaisquer dois processos no sistema usam extensões de processador de vetor. Quando seu processo vai para o kernel e vice-versa, você não perde tempo economizando e restaurando o estado vetorial do processador. Mas se você alternar de um espaço do usuário para outro (alternância de contexto), além do fato de os caches de primeiro nível estarem desabilitados lá, o módulo de alternância de contexto no início / fim da FPU também funcionará mal. A operação é bastante cara - uma marca de microbench.Nas marcas de micropontos, tudo é sempre dramático, mas a operação é muito cara. Portanto, no espaço do usuário, alterne o contexto por um longo tempo. No kernel, não temos troca de contexto, então tudo é rápido. Salvamos e restauramos o processador vetorial apenas uma vez para um conjunto de pacotes suficientemente grande.
Quaisquer dois processos no sistema usam extensões de processador de vetor. Quando seu processo vai para o kernel e vice-versa, você não perde tempo economizando e restaurando o estado vetorial do processador. Mas se você alternar de um espaço do usuário para outro (alternância de contexto), além do fato de os caches de primeiro nível estarem desabilitados lá, o módulo de alternância de contexto no início / fim da FPU também funcionará mal. A operação é bastante cara - uma marca de microbench.Nas marcas de micropontos, tudo é sempre dramático, mas a operação é muito cara. Portanto, no espaço do usuário, alterne o contexto por um longo tempo. No kernel, não temos troca de contexto, então tudo é rápido. Salvamos e restauramos o processador vetorial apenas uma vez para um conjunto de pacotes suficientemente grande.Intelpocalypse
No começo, mostrei uma opção da tabela de pesquisa para otimizar o código do comutador: um processo longo, enum, compila a tabela do comutador em uma matriz e segue a desreferenciação dupla do ponteiro que salta sobre essa matriz. Este é um cenário para um ataque Spectre que explora a execução especulativa.O Google tem um bom artigo sobre como a dupla desreferenciação de ponteiros em compiladores modernos é organizada agora (desde o início de 2018). Não funciona muito bem. Se no início do registro algum endereço foi armazenado e fomos para esse endereço, agora temos um código diferente.jmp *%r11
call l1
l0: pause
lfence
jmp l0
l1: mov %r11, (%rsp)
ret
Como funciona? Nós chamamos a função em l1, o processo vai para esse rótulo e fazemos um hack: como se estivesse retornando da função (o que não é), mas reescrevesse o endereço de retorno. Quando fazemos a instrução call, colocamos o endereço de retorno, o endereço atual na pilha, reescrevemos-o com o conteúdo necessário do registro e vamos para l1. Mas o processador, quando seu pré-buscador está em execução, vê que existe uma função e depois uma barreira. Consequentemente, tudo será lento - ele libera a pré-busca e nos livramos da vulnerabilidade Spectre. O código é lento, o desempenho cai 15%.O próximo ataque relativamente novo é o Meltdown.. É específico apenas para processos de espaço do usuário. Muito doloroso é ler a memória do kernel do espaço do usuário. O ataque é evitado pelo KPTI (Kernel Pate Table Isolation), que é compilado em novos kernels por padrão. Mas o KPTI é muito caro, até 30-40% de degradação do desempenho ( conforme medido pelo MariaDB ).Isso se deve ao fato de você não ter mais a otimização lenta do TLB: o espaço de endereço do kernel e o processador são completamente separados em diferentes tabelas de páginas (antes, o TLB lento fazia o mapeamento do espaço do kernel para a tabela de páginas de cada processo). Isso é doloroso para o espaço do usuário, mas não para o Tempesta FW, que funciona completamente no kernel.Alguns links úteis:Saint HighLoad++ . , 6 -- ( , Saint HighLoad++) , web .
PHP Russia: 13 , . — KnowledgeConf, ++ TechLead Conf — . , , .