O Flant possui vários desenvolvimentos de código aberto, principalmente para o Kubernetes, e o loghouse é um dos mais populares. Esta é a nossa ferramenta de registro central no K8s, que foi introduzida há mais de 2 anos. Como mencionamos em um artigo recente sobre os logs , ele exigia refinamentos e sua relevância só aumentou com o tempo. Hoje temos o prazer de apresentar uma nova versão do loghouse - v0.3.0 . Detalhes sobre ela - sob o corte.
Como mencionamos em um artigo recente sobre os logs , ele exigia refinamentos e sua relevância só aumentou com o tempo. Hoje temos o prazer de apresentar uma nova versão do loghouse - v0.3.0 . Detalhes sobre ela - sob o corte.desvantagens
Temos usado o loghouse em muitos clusters do Kubernetes esse tempo todo e, em geral, essa solução se adapta a nós mesmos e aos vários clientes aos quais também fornecemos acesso.Suas principais vantagens são a interface simples e intuitiva, a capacidade de executar consultas SQL, boa compactação e baixo consumo de recursos ao inserir dados no banco de dados, bem como a baixa sobrecarga durante o armazenamento.Os problemas mais dolorosos no loghouse durante a operação:- uso de tabelas de partição unidas por uma tabela de mesclagem;
- falta de um buffer que suavizasse rajadas de logs;
- Painel desatualizado e potencialmente vulnerável
- fluent desatualizado ( loghouse-fluentd: o mais recente não foi iniciado devido a um conjunto de gemas problemático).
Além disso, um número significativo de problemas se acumulou no GitHub , que eu também gostaria de resolver.Principais mudanças no loghouse 0.3.0
De fato, acumulamos mudanças suficientes, mas destacaremos as mais importantes. Eles podem ser divididos em 3 grupos principais:- aprimorando o armazenamento de log e o esquema do banco de dados;
- coleção aprimorada de logs;
- a aparência do monitoramento.
1. Melhorias no armazenamento de log e no design do banco de dados
Principais inovações:- Os esquemas de armazenamento de log foram alterados, a transição para trabalhar com uma única tabela e a rejeição das tabelas de partição foi concluída .
- O mecanismo de limpeza da base incorporado ao ClickHouse das versões mais recentes começou a ser aplicado .
- Agora você pode usar uma instalação externa do ClickHouse , mesmo no modo de cluster.
Compare o desempenho dos circuitos antigos e novos em um projeto real. Aqui está um exemplo de pesquisa de URLs exclusivos nos logs de aplicativos do popular recurso online dtf.ru :SELECT
string_fields.values[indexOf(string_fields.names, 'path')] AS path,
count(*) AS count
FROM logs
WHERE (namespace = 'kube-nginx-ingress') AND ((string_fields.values[indexOf(string_fields.names, 'vhost')]) LIKE '%foobar.baz%') AND (date = '2020-02-29')
GROUP BY string_fields.values[indexOf(string_fields.names, 'path')]
ORDER BY count DESC
LIMIT 20
A seleção ocorre em dezenas de milhões de registros. O esquema antigo funcionou em 20 segundos: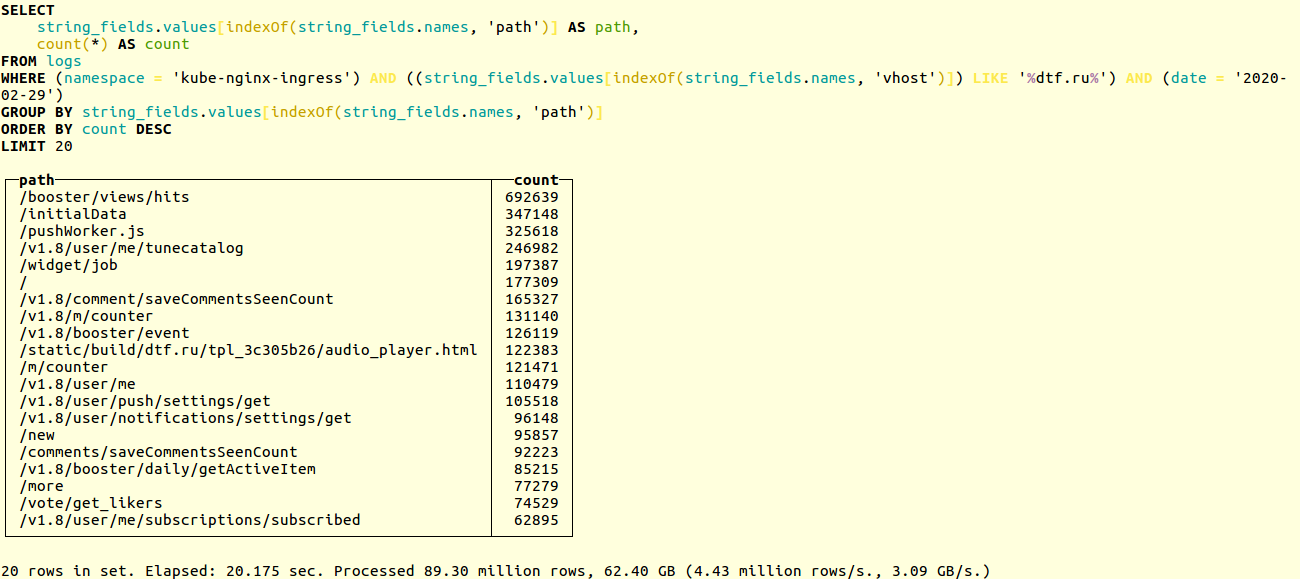 Novo - em 14:
Novo - em 14: Se você usar o nosso Helm-chart , ao atualizar o loghouse, o banco de dados será automaticamente migrado para o novo formato. Caso contrário, você terá que fazer a migração manualmente. O processo está descrito na documentação . Em resumo, basta executar:
Se você usar o nosso Helm-chart , ao atualizar o loghouse, o banco de dados será automaticamente migrado para o novo formato. Caso contrário, você terá que fazer a migração manualmente. O processo está descrito na documentação . Em resumo, basta executar:DO_DB_DEPLOY=true rake create_logs_tables
Além disso, começamos a usar TTL para tabelas ClickHouse . Isso permite excluir automaticamente os dados do banco de dados anteriores ao intervalo de tempo especificado:CREATE TABLE logs
(
....
)
ENGINE = MergeTree()
PARTITION BY (date)
ORDER BY (timestamp, nsec, namespace, container_name)
TTL date + toIntervalDay(14)
SETTINGS index_granularity = 32768;
Exemplos de esquemas e configurações de banco de dados para ClickHouse, incluindo um exemplo de trabalho com o cluster CH, podem ser encontrados na documentação .Coleção de logs aprimorada
Principais inovações:- Foi adicionado um buffer projetado para suavizar as rajadas quando um grande número de logs aparece.
- Implementada a capacidade de enviar logs para o loghouse diretamente do aplicativo: via TCP e UDP, no formato JSON.
A bateria do loghouse no loghouse é uma nova tabela logs_bufferadicionada ao esquema do banco de dados. Esta tabela está na memória, ou seja, armazenado na RAM (possui um tipo especial de buffer ); é ela quem deve suavizar a carga na base. Obrigado pela dica de adicioná-lo.Sovigod!Os logs de envio implementados diretamente para o loghouse a partir do aplicativo permitem fazer isso mesmo através do netcat:echo '{"log": {"level": "info", "msg": "hello world"}}' | nc fluentd.loghouse 5170
Esses logs podem ser visualizados no espaço para nome em que o loghouse está instalado no fluxo net: Os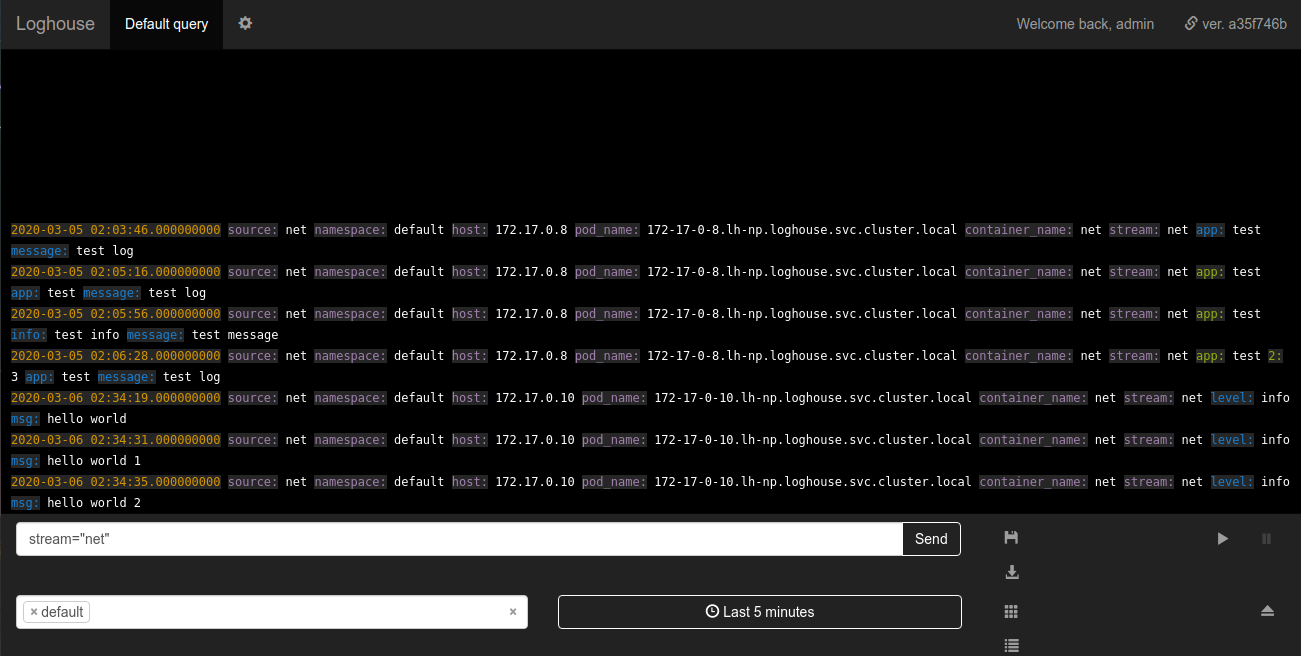 requisitos para os dados a serem enviados são mínimos: a mensagem deve ser um JSON válido com um campo
requisitos para os dados a serem enviados são mínimos: a mensagem deve ser um JSON válido com um campo log. O campo log, por sua vez, pode ser uma sequência ou JSON aninhado.Subsistema de Log de Monitoramento
Uma melhoria importante foi o monitoramento de fluentes através do Prometheus. Agora, o loghouse vem com um painel para Grafana, que exibe todas as métricas básicas, como:- número de trabalhadores fluentes;
- número de eventos enviados para ClickHouse;
- tamanho do buffer livre em porcentagem.
O código do painel para o Grafana pode ser visto na documentação .O painel para ClickHouse é feito com base em um produto pronto - da f1yegor , pelo qual muito obrigado ao autor.Como você pode ver, o painel exibe o número de conexões com o ClickHouse, o uso do buffer, a atividade de tarefas em segundo plano e o número de mesclagens. Isso é suficiente para entender o estado do sistema: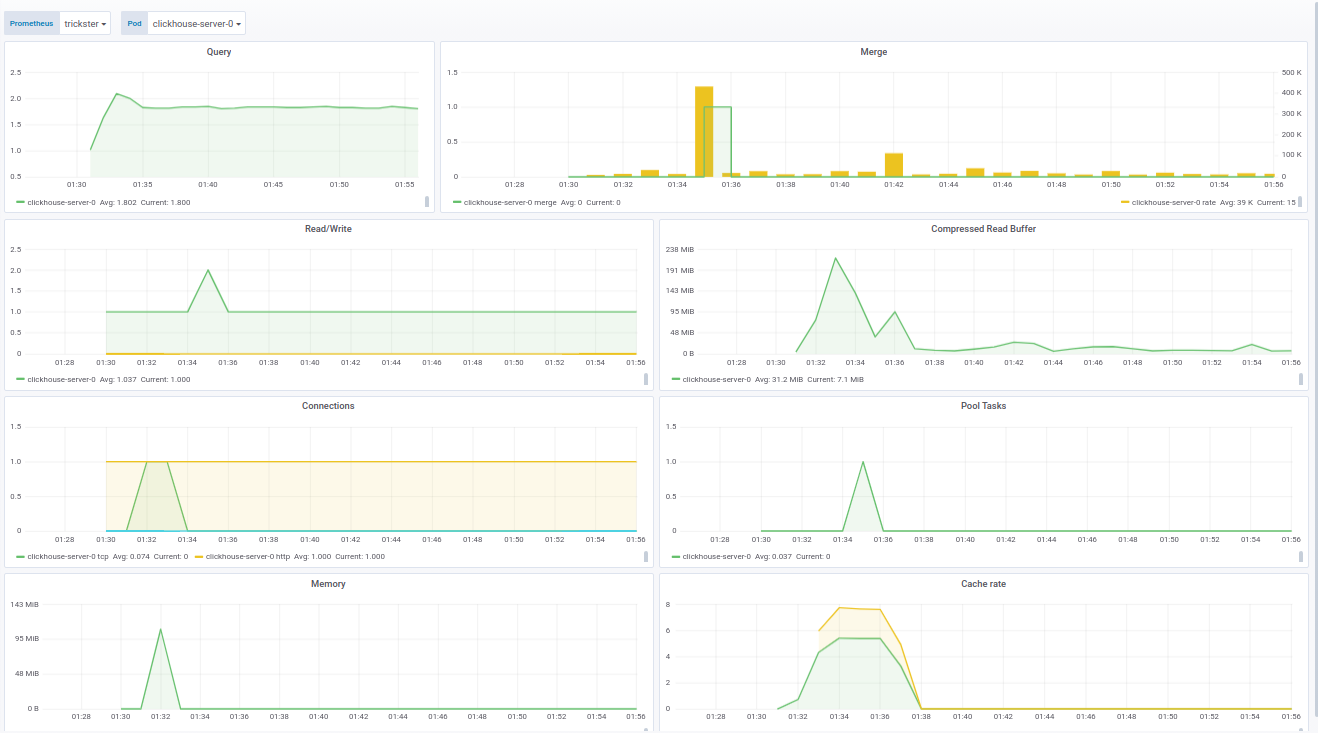 O painel para fluentd mostra as instâncias ativas do fluentd. Isso é especialmente crítico para quem não deseja / não pode perder logs:
O painel para fluentd mostra as instâncias ativas do fluentd. Isso é especialmente crítico para quem não deseja / não pode perder logs: Além do status dos pods, o painel mostra a carga na fila para enviar logs para o ClickHouse. Por sua vez, você pode entender se o ClickHouse está lidando com a carga ou não. Nos casos em que o log não pode ser perdido, esse parâmetro também se torna crítico.Exemplos de painéis são aprimorados para o fornecimento do Operador Prometheus, no entanto, eles são facilmente modificados através das variáveis nas configurações.Finalmente, como parte do trabalho de monitoramento da loghouse, reunimos uma imagem atualizada do Docker com o clickhouse_exporter 0.1.0 lançado pela Percona Labs, pois o autor do clickhouse_exporter original abandonou seu repositório.
Além do status dos pods, o painel mostra a carga na fila para enviar logs para o ClickHouse. Por sua vez, você pode entender se o ClickHouse está lidando com a carga ou não. Nos casos em que o log não pode ser perdido, esse parâmetro também se torna crítico.Exemplos de painéis são aprimorados para o fornecimento do Operador Prometheus, no entanto, eles são facilmente modificados através das variáveis nas configurações.Finalmente, como parte do trabalho de monitoramento da loghouse, reunimos uma imagem atualizada do Docker com o clickhouse_exporter 0.1.0 lançado pela Percona Labs, pois o autor do clickhouse_exporter original abandonou seu repositório.Planos futuros
- Torne possível implantar um cluster ClickHouse no Kubernetes.
- Trabalhe com a seleção de logs assíncronos e remova-o da parte Ruby do back-end.
- Ruby- , .
- , Go.
- .
É bom ver que o projeto de loghouse encontrou seu público, não apenas tendo conquistado estrelas no GitHub (mais de 600), mas também incentivando usuários reais a falar sobre seus sucessos e problemas.Tendo criado a casa de madeira há mais de 2 anos, não tínhamos certeza de suas perspectivas, esperando que o mercado e / ou a comunidade de código aberto oferecessem as melhores soluções. No entanto, hoje vemos que esse é um caminho viável, que nós mesmos ainda escolhemos e usamos nos muitos clusters Kubernetes com serviços.Estamos ansiosos por qualquer ajuda para melhorar e desenvolver a casa de madeira. Se estiver faltando alguma coisa na casa de madeira - escreva nos comentários. Além disso, é claro, teremos o maior prazer em ser ativo no GitHub .PS
Leia também no nosso blog: