Olá de novo! Antecipando o início do curso “Arquiteto de Software”, preparamos uma tradução de outro material interessante.
Nos últimos anos, houve um aumento na popularidade da arquitetura de microsserviços. Existem muitos recursos que ensinam como implementá-lo corretamente, mas muitas vezes as pessoas falam sobre isso como um pool de prata. Existem muitos argumentos contra o uso de microsserviços, mas o mais significativo deles é que esse tipo de arquitetura é repleto de complexidade incerta, cujo nível depende de como você gerencia o relacionamento entre seus serviços e equipes. Você pode encontrar muita literatura que explica por que (talvez) no seu caso, os microsserviços não serão a melhor opção.No letgo, migramos de um monólito para microsserviços para satisfazer a necessidade de escalabilidade e imediatamente nos convencemos de seu efeito benéfico no trabalho das equipes. Quando usados corretamente, os microsserviços nos deram várias vantagens, a saber:- : , . ( ..) . ( ) Users.
- : , . . , , , , . .
-
Nem todas as arquiteturas de microsserviço são orientadas a eventos. Algumas pessoas defendem a comunicação síncrona entre serviços nessa arquitetura usando HTTP (gRPC, REST etc.). De início, tentamos não seguir esse padrão e associar nossos serviços de forma assíncrona a eventos de domínio . Aqui estão as razões pelas quais fazemos isso:- : . , DDoS . , DDoS . , . .
(bulkheads) – , , .- : . , , , , . , , API, , , , . Users , Chat.
Com base nisso, tentamos aderir à comunicação assíncrona entre serviços e a síncrona só funciona em casos excepcionais como o MVP de recursos. Fazemos isso porque queremos que cada serviço gere suas próprias entidades com base em eventos de domínio publicados por outros serviços em nosso barramento de mensagens.Em nossa opinião, o sucesso ou fracasso na implementação de uma arquitetura de microsserviço depende de como você lida com a complexidade inerente e como seus serviços interagem entre si. Dividir o código sem transferir a infraestrutura de comunicação para assíncrona transformará seu aplicativo em um monólito distribuído.
Arquitetura orientada a eventos em letgo
Hoje, quero compartilhar um exemplo de como usamos eventos de domínio e comunicação assíncrona no letgo: nossa entidade Usuário existe em muitos serviços, mas sua criação e edição são processadas inicialmente pelo serviço Usuários. No banco de dados do serviço Usuários, armazenamos muitos dados, como nome, endereço de email, avatar, país etc. Em nosso serviço de bate-papo, também temos um conceito de usuário, mas não precisamos dos dados que a entidade Usuário do serviço Usuários possui. O nome do usuário, avatar e ID (link para o perfil) são exibidos na lista de caixas de diálogo. Dizemos que em um bate-papo há apenas uma projeção da entidade Usuário, que contém dados parciais. De fato, no Chat, não estamos falando de usuários, os chamamos de "conversadores". Essa projeção se refere ao serviço de bate-papo e baseia-se nos eventos que o bate-papo recebe do serviço de usuários.Fazemos o mesmo com as listagens. No serviço Produtos, armazenamos n imagens de cada listagem, mas na exibição de lista das caixas de diálogo, mostramos uma imagem principal; portanto, nossa projeção de Produtos para Bate-papo requer apenas uma imagem em vez de n.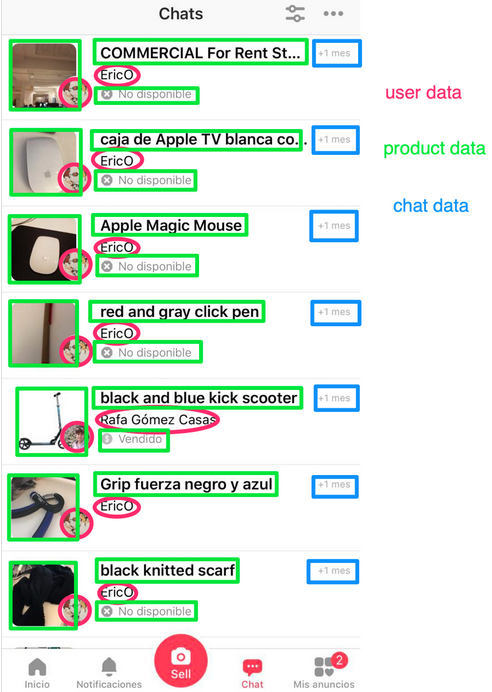 Veja uma lista de diálogos em nosso bate-papo. Ele mostra qual serviço específico no back-end fornece informações.Se você olhar a lista de diálogos novamente, verá que quase todos os dados que mostramos não são criados pelo serviço de Chat, mas pertencem a ele, porque as projeções de Usuário e Chat pertencem ao Chat. Há uma troca entre acessibilidade e consistência das projeções, que não discutiremos neste artigo, mas apenas direi que é claramente mais fácil dimensionar muitos bancos de dados pequenos do que um grande.
Veja uma lista de diálogos em nosso bate-papo. Ele mostra qual serviço específico no back-end fornece informações.Se você olhar a lista de diálogos novamente, verá que quase todos os dados que mostramos não são criados pelo serviço de Chat, mas pertencem a ele, porque as projeções de Usuário e Chat pertencem ao Chat. Há uma troca entre acessibilidade e consistência das projeções, que não discutiremos neste artigo, mas apenas direi que é claramente mais fácil dimensionar muitos bancos de dados pequenos do que um grande.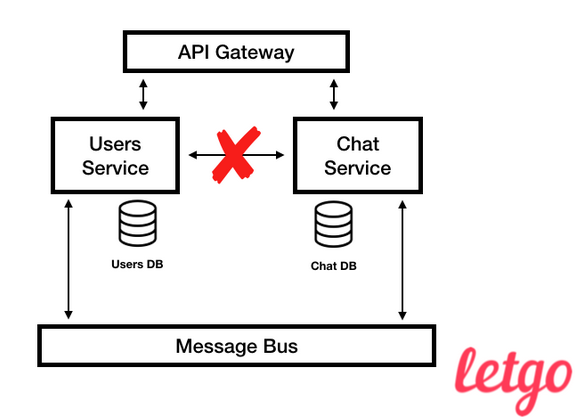 Visão simplificada da arquitetura letgo
Visão simplificada da arquitetura letgoAntipatterns
Algumas soluções intuitivas frequentemente se tornaram erros. Aqui está uma lista dos antipadrões mais importantes que encontramos em nossa arquitetura relacionada ao domínio.1. Eventos densosTentamos tornar os eventos do domínio o mais pequenos possível, sem perder o valor do domínio. Deveríamos ter cuidado ao refatorar as bases de código herdadas com grandes entidades e mudar para a arquitetura de eventos. Tais entidades podem nos levar a eventos fatais, mas, como nossos eventos de domínio se transformaram em um contrato público, precisamos torná-los o mais simples possível. Nesse caso, a refatoração é melhor visualizada de lado. Para começar, projetamos nossos eventos usando a técnica de tempestade de eventose refatorar o código de serviço para adaptá-lo aos nossos eventos.Também devemos ter mais cuidado com o problema "produto e usuário": muitos sistemas usam entidades de produto e usuário, e essas entidades, em regra, puxam toda a lógica por trás delas, e isso significa que todos os eventos do domínio estão associados a elas.2. Eventos como intenções Umevento de domínio, por definição, é um evento que já ocorreu. Se você publicar algo no barramento de mensagens para solicitar o que aconteceu em algum outro serviço, provavelmente estará executando um comando assíncrono em vez de criar um evento de domínio. Como regra, nos referimos a eventos de domínio anteriores: ser_registered , product_publishedetc. Quanto menos um serviço souber sobre o outro, melhor. O uso de eventos como comandos vincula serviços e aumenta a probabilidade de uma alteração em um serviço afetar outros serviços.3. Falta de serialização ou compactação independente.Ossistemas de serialização e compactação de eventos em nossa área de assunto não devem depender da linguagem de programação. Você nem precisa saber em que idioma os serviços ao consumidor são escritos. É por isso que podemos usar serializadores Java ou PHP, por exemplo. Deixe sua equipe gastar tempo discutindo e escolhendo um serializador, pois alterá-lo no futuro será difícil e demorado. No letgo, usamos JSON, no entanto, existem muitos outros formatos de serialização com bom desempenho.4. Falta de estrutura padrãoQuando começamos a portar o back-end da letgo para uma arquitetura orientada a eventos, concordamos em uma estrutura comum para eventos de domínio. Parece algo como isto:{
“data”: {
“id”: [uuid], // event id.
“type”: “user_registered”,
“attributes”: {
“id”: [uuid], // aggregate/entity id, in this case user_id
“user_name”: “John Doe”,
…
}
},
“meta” : {
“created_at”: timestamp, // when was the event created?
“host”: “users-service” // where was the event created?
…
}
}
Ter uma estrutura comum para nossos eventos de domínio nos permite integrar serviços rapidamente e implementar algumas bibliotecas com abstrações.5. Falta de validação de esquemaDurante a serialização, tivemos problemas com linguagens de programação sem digitação forte.
{
“null_value_one”: null, // thank god
“null_value_two”: “null”,
“null_value_three”: “”,
}
Uma cultura de teste bem estabelecida que garante a serialização de nossos eventos e um entendimento de como a biblioteca de serialização funciona, ajuda a lidar com isso. No momento, estamos migrando para o Avro e o Confluent Schema Registry, que nos fornece um único ponto de determinação da estrutura de eventos em nosso domínio e evita erros desse tipo, além de documentação obsoleta.6. Eventos de domínio anêmicosComo eu disse antes, e como o nome indica, os eventos do domínio devem ter um valor no nível do domínio. Assim como tentamos evitar a inconsistência de estados em nossas entidades, devemos evitar isso em eventos de domínio. Vamos ilustrar isso com o seguinte exemplo: o produto em nosso sistema possui geolocalização com latitude e longitude, que são armazenadas em dois campos diferentes da tabela de produtos do serviço Produtos. Todos os produtos podem ser "movidos", portanto, teremos eventos de domínio para apresentar esta atualização. Anteriormente, para isso, tínhamos dois eventos: product_latitude_updated e product_longitude_updated , que não faziam muito sentido se você não fosse uma torre no tabuleiro de xadrez. Nesse caso, os eventos product_location_updated farão mais sentido.ou product_moved . Uma torre é uma peça de xadrez. Costumava ser chamado de tour. Uma torre só pode se mover na vertical ou na horizontal por qualquer número de campos desocupados.7. Falta de ferramentas de depuraçãoNós da letgo produzimos milhares de eventos de domínio por minuto. Todos esses eventos se tornam um recurso extremamente útil para entender o que está acontecendo em nosso sistema, registrar a atividade do usuário ou até reconstruir o estado de um sistema em um momento específico usando a pesquisa de eventos. Precisamos usar habilmente esse recurso e, para isso, precisamos de ferramentas para verificar e depurar nossos eventos. Pedidos como "mostre-me todos os eventos gerados por John Doe nas últimas 3 horas" também podem ser úteis na detecção de fraudes. Para esses fins, desenvolvemos algumas ferramentas no ElasticSearch, Kibana e S3.8. Falta de monitoramento de eventosPodemos usar eventos de domínio para testar a integridade do sistema. Quando implantamos algo (o que acontece várias vezes ao dia, dependendo do serviço), precisamos de ferramentas para verificar rapidamente a operação correta. Por exemplo, se implantarmos uma nova versão do serviço Produtos em produção e vermos uma diminuição no número de eventos product_published20%, é seguro dizer que quebramos alguma coisa. Atualmente, estamos usando o InfluxDB, Grafana e Prometheus para conseguir isso com funções derivadas. Se você recordar o curso da matemática, entenderá que a derivada da função f (x) no ponto x é igual à tangente do ângulo tangente traçado ao gráfico da função nesse ponto. Se você tem uma função para publicar a velocidade de um evento específico em uma área de assunto e usa um derivado, verá os picos dessa função e poderá definir notificações com base neles. Usando essas notificações, você pode evitar frases como "me avise se publicarmos menos de 200 eventos por segundo por 5 minutos" e foque em uma mudança significativa na velocidade da publicação.
Uma torre é uma peça de xadrez. Costumava ser chamado de tour. Uma torre só pode se mover na vertical ou na horizontal por qualquer número de campos desocupados.7. Falta de ferramentas de depuraçãoNós da letgo produzimos milhares de eventos de domínio por minuto. Todos esses eventos se tornam um recurso extremamente útil para entender o que está acontecendo em nosso sistema, registrar a atividade do usuário ou até reconstruir o estado de um sistema em um momento específico usando a pesquisa de eventos. Precisamos usar habilmente esse recurso e, para isso, precisamos de ferramentas para verificar e depurar nossos eventos. Pedidos como "mostre-me todos os eventos gerados por John Doe nas últimas 3 horas" também podem ser úteis na detecção de fraudes. Para esses fins, desenvolvemos algumas ferramentas no ElasticSearch, Kibana e S3.8. Falta de monitoramento de eventosPodemos usar eventos de domínio para testar a integridade do sistema. Quando implantamos algo (o que acontece várias vezes ao dia, dependendo do serviço), precisamos de ferramentas para verificar rapidamente a operação correta. Por exemplo, se implantarmos uma nova versão do serviço Produtos em produção e vermos uma diminuição no número de eventos product_published20%, é seguro dizer que quebramos alguma coisa. Atualmente, estamos usando o InfluxDB, Grafana e Prometheus para conseguir isso com funções derivadas. Se você recordar o curso da matemática, entenderá que a derivada da função f (x) no ponto x é igual à tangente do ângulo tangente traçado ao gráfico da função nesse ponto. Se você tem uma função para publicar a velocidade de um evento específico em uma área de assunto e usa um derivado, verá os picos dessa função e poderá definir notificações com base neles. Usando essas notificações, você pode evitar frases como "me avise se publicarmos menos de 200 eventos por segundo por 5 minutos" e foque em uma mudança significativa na velocidade da publicação.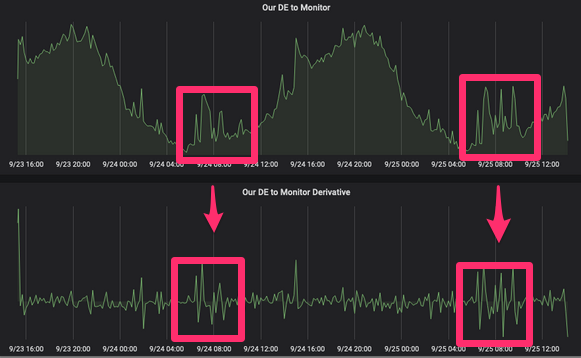 Algo estranho aconteceu aqui ... Ou talvez seja apenas uma campanha de marketing9. A esperança de que tudo corra bemEstamos tentando criar sistemas sustentáveis e reduzir o custo de sua restauração. Além dos problemas de infraestrutura e do fator humano, uma das coisas mais comuns que podem afetar a arquitetura de eventos é a perda de eventos. Precisamos de um plano com o qual possamos restaurar o estado correto do sistema reprocessando todos os eventos que foram perdidos. Aqui, nossa estratégia é baseada em dois pontos:
Algo estranho aconteceu aqui ... Ou talvez seja apenas uma campanha de marketing9. A esperança de que tudo corra bemEstamos tentando criar sistemas sustentáveis e reduzir o custo de sua restauração. Além dos problemas de infraestrutura e do fator humano, uma das coisas mais comuns que podem afetar a arquitetura de eventos é a perda de eventos. Precisamos de um plano com o qual possamos restaurar o estado correto do sistema reprocessando todos os eventos que foram perdidos. Aqui, nossa estratégia é baseada em dois pontos:- : , « , », - , . letgo Data, Backend.
- : - . , , , message bus . – , , . , user_registered Users, , MySQL, user_id . user_registered, , . , , - MySQL ( , 30 ). -, DynamoDB. , , , . , , , , .
10. Falta de documentação sobre eventos de domínioNossos eventos de domínio se tornaram nossa interface pública para todos os sistemas no back-end. Assim como documentamos nossas APIs REST, também precisamos documentar eventos de domínio. Qualquer funcionário da organização deve poder exibir a documentação atualizada para cada evento de domínio publicado por cada serviço. Se usarmos esquemas para verificar eventos de domínio, eles também podem ser usados como documentação.11. Resistência ao consumo de eventos própriosVocê tem permissão e até incentiva a usar seus próprios eventos de domínio para criar projeções em seu sistema, que, por exemplo, são otimizadas para leitura. Algumas equipes resistiram a esse conceito, porque estavam confinadas ao conceito de consumo dos eventos de outras pessoas.Vejo você no curso!