Olá Habr! Quero contar como escrevemos e implementamos um serviço para monitorar a qualidade dos dados. Temos muitas fontes de dados: dados dos mercados financeiros, atividades comerciais de nossos clientes, cotações e muito mais. Tudo isso gera bilhões de registros por dia em nossos processos. A integridade e consistência dos dados comerciais são um componente crítico dos negócios da Exness.Se você está próximo de problemas de garantia da qualidade dos dados e está interessado em como resolvemos esse problema em casa, seja bem-vindo ao gato. Meu nome é Dmitry, trabalho em uma equipe que armazena dados brutos e a transformação, agregação e fornecimento de todos os dados processados em todos os departamentos da empresa. Nossos dados são consumidos por muitas equipes da empresa, como Business Intelligence, Antifraude, Finanças, e também os fornecemos aos nossos parceiros B2B.Trabalhar com dados é uma missão responsável e difícil, porque interromper um processo de ETL pode levar à paralisia de parte dos negócios da Exness. Para resolver problemas de ETL, usamos uma variedade de ferramentas:
Meu nome é Dmitry, trabalho em uma equipe que armazena dados brutos e a transformação, agregação e fornecimento de todos os dados processados em todos os departamentos da empresa. Nossos dados são consumidos por muitas equipes da empresa, como Business Intelligence, Antifraude, Finanças, e também os fornecemos aos nossos parceiros B2B.Trabalhar com dados é uma missão responsável e difícil, porque interromper um processo de ETL pode levar à paralisia de parte dos negócios da Exness. Para resolver problemas de ETL, usamos uma variedade de ferramentas: Desafios que enfrentamos todos os dias:
Desafios que enfrentamos todos os dias:- Dezenas de milhões de registros de transações diariamente;
- Bilhões de entradas no mercado diariamente (cotações, etc.);
- A heterogeneidade das fontes de dados (como fontes externas de Dados de Mercado, diferentes plataformas de negociação);
- Fornecer exatamente uma vez a semântica para dados importantes (transações financeiras);
- Garantir a integridade e integridade dos dados;
- Fornecendo garantias de que, durante o tempo estipulado, a transação será adicionada a todas as tabelas e agregados necessários.
Para fornecer tais garantias, foi necessário aprender a rastrear, medir e responder proativamente a desvios na qualidade dos dados.Dada a complexidade de nossos processos de coleta e processamento de dados, dada a alta velocidade de desenvolvimento e modificação dos processos ETL, torna-se necessário monitorar a qualidade dos dados já no ponto final. Normalmente, temos um banco de dados Clickhouse ou PostgreSQL. Essas métricas nos dirão com que rapidez nossos processos funcionam:SELECT server,
avg(updated - close_time)
FROM trades
WHERE close_time > subtractHours(Now(), 2)
GROUP BY server
Eles ajudarão a encontrar duplicatas nos dados (não há restrições exclusivas no Clickhouse):SELECT SUM(count) FROM (
SELECT
COUNT(*) AS count
FROM trades
GROUP BY order_id
HAVING count > 1
)
Você pode criar várias consultas (muitas das quais já usamos) que ajudam a monitorar a qualidade dos dados: comparando o número de linhas na tabela de origem e a tabela de destino, o tempo da última inserção na tabela, comparando o conteúdo de duas consultas e muito mais.As métricas são sintomas. Sozinhos, eles não indicam a causa do problema, mas nos permitem mostrar que há um problema. Isso será um gatilho para o engenheiro prestar atenção ao problema e identificar a causa raiz. Analogia: se uma pessoa está com temperatura, algo está quebrado em seu corpo. A temperatura é um sintoma suficiente para começar a entender e encontrar a causa do colapso.Procuramos uma solução pronta para coletar essas métricas de sintomas para nós. Nossas exigências:- Suporte para várias fontes de dados (bancos de dados, filas, solicitações de http);
- ;
- ( , );
- .
No começo do artigo, listei as tecnologias que usamos no ETL. Como você pode ver, somos apoiadores de soluções de código aberto! Um exemplo: usamos o banco de dados Clickhouse orientado a colunas como o principal data warehouse. Nossa equipe fez alterações no código fonte do Clickhouse várias vezes (principalmente corrigindo bugs). Como ferramentas para trabalhar com métricas e séries temporais, usamos: influxdb de ecossistema, métricas de prometheus e victoria, zabbix.Para nossa surpresa, verificou-se que não existe uma ferramenta pronta e conveniente para monitorar a qualidade dos dados que se encaixa nas tecnologias que escolhemos. Ou estávamos parecendo mal?Sim, o zabbix pode executar scripts personalizados e telegrafVocê pode ensinar como executar consultas SQL e transformar seus resultados em métricas. Mas isso exigiu um acabamento sério e não funcionou da maneira que desejávamos. Portanto, criamos nosso próprio serviço (daemon) para monitorar a qualidade dos dados. Conheça o nervo!Recursos nervosos
Ideologicamente, nervo pode ser descrito com a seguinte frase:Este é um serviço que, em um cronograma, executa tarefas personalizadas e heterogêneas para coletar valores numéricos e apresenta os resultados como métricas para diferentes sistemas de coleta de métricas.
Principais recursos do programa:- Suporte para diferentes tipos de tarefas: Consulta, CompareQueries, etc;
- A capacidade de escrever seus tipos de tarefas no Python como um plug-in de tempo de execução;
- Trabalhe com diferentes tipos de recursos: Clickhouse, Postgres, etc;
- Modelar métricas de dados, como no prometheus
metric_name{label="value"} 123.3 ;
- pull prometheus;
- : crontab-style;
- WEB UI ;
- yaml ;
- Twelve-Factor App.
Tarefa e Recurso são as entidades básicas para configurar e trabalhar com o nervo. Tarefa - uma ação periódica digitada, como resultado da qual obtemos métricas. Recurso - um objeto que contém configuração e lógica específicas para trabalhar com uma fonte de dados específica. Vamos ver como o nervo funciona com um exemplo.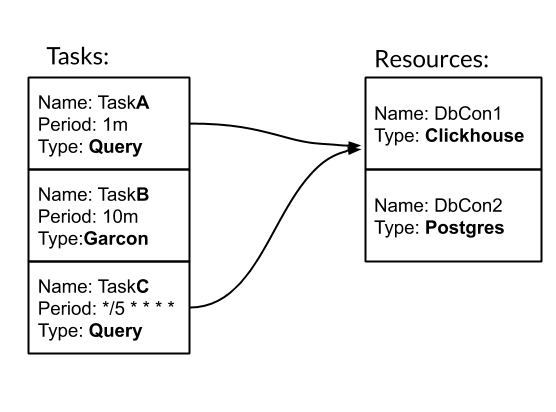 Temos três tarefas. Dois deles são do tipo Consulta - consulta SQL. Um é do tipo Garcon - esta é uma tarefa personalizada que vai para um de nossos serviços. A frequência da tarefa pode ser definida por um período de tempo. Por exemplo, 10m significa uma vez a cada dez minutos. Ou no estilo crontab "* / 5 * * * *" - a cada quinto minuto completo. Tarefas TaskA e TaskC estão associadas ao recurso DbCon1, que é do tipo Clickhouse. Vamos ver como a configuração ficará:
Temos três tarefas. Dois deles são do tipo Consulta - consulta SQL. Um é do tipo Garcon - esta é uma tarefa personalizada que vai para um de nossos serviços. A frequência da tarefa pode ser definida por um período de tempo. Por exemplo, 10m significa uma vez a cada dez minutos. Ou no estilo crontab "* / 5 * * * *" - a cada quinto minuto completo. Tarefas TaskA e TaskC estão associadas ao recurso DbCon1, que é do tipo Clickhouse. Vamos ver como a configuração ficará:tasks:
- name: TaskA
type: Query
resources: DbCon1
period: 1m
config:
query: SELECT COUNT(*) FROM ticks
gauge: metric_count{table="ticks"}
- name: TaskB
type: Garcon
period: 10m
config:
url: "http://hostname:9003/api/v1/orders/backups/"
gauge: backup_ago
- name: TaskC
type: Query
period: "*/5 * * * *"
resources: DbCon1
config:
query: SELECT now() - toDateTime(time_msc/1000)
FROM deals WHERE trade_server= 'Real'
ORDER BY deal DESC LIMIT 1
gauge: orders_lag
resources:
- name: DbCon1
type: Clickhouse
config:
host: clickhouse.env
port: 9000
user: readonly
password: "***"
database: data
results:
common_labels:
env="prod"
task_types_paths:
- "./tasks"
O caminho "./tasks" é o caminho para tarefas personalizadas. Em particular, o tipo de tarefa Garcon é definido lá. Neste artigo, omitirei o momento de criar meus tipos de tarefas.Como resultado do lançamento do serviço nervoso com essa configuração, na interface da Web WEB será possível monitorar como as tarefas são cumpridas: E as métricas / métricas para coleta estarão disponíveis:
E as métricas / métricas para coleta estarão disponíveis: Tipo de tarefa de consulta mais usado em nossa equipe. Portanto, expandimos seus recursos para trabalhar com o GROUP BY e os modelos. Esses mecanismos tornam possível coletar muitas informações sobre dados com uma solicitação de cada vez:
Tipo de tarefa de consulta mais usado em nossa equipe. Portanto, expandimos seus recursos para trabalhar com o GROUP BY e os modelos. Esses mecanismos tornam possível coletar muitas informações sobre dados com uma solicitação de cada vez: a tarefa TradesLag coletará o atraso máximo para cada servidor de negociação obter um pedido fechado na tabela de negociações a cada cinco minutos, levando em conta apenas os pedidos fechados nas últimas duas horas.Algumas palavras sobre a implementação. O Nerve é um aplicativo LoC python3 ~ 3k multiencadeado que é fácil de executar no Docker, complementando-o com uma configuração de tarefas.
a tarefa TradesLag coletará o atraso máximo para cada servidor de negociação obter um pedido fechado na tabela de negociações a cada cinco minutos, levando em conta apenas os pedidos fechados nas últimas duas horas.Algumas palavras sobre a implementação. O Nerve é um aplicativo LoC python3 ~ 3k multiencadeado que é fácil de executar no Docker, complementando-o com uma configuração de tarefas.O que aconteceu
Com coragem, conseguimos o que queríamos. No momento, além da nossa equipe, outras equipes da Exness demonstraram interesse nele. Ele roda cerca de 40 tarefas com uma frequência de 30 segundos a um dia. O Nerve coleta cerca de 500 métricas sobre nossos dados. Adicionar novas métricas é uma questão de 5 a 10 minutos. O fluxo completo de trabalho com métricas é semelhante a: nervo → prometheus → Victoria Metrics → painéis Grafana → Alertas no PagerDuty.Com coragem, também começamos a coletar métricas de negócios: periodicamente selecionamos eventos brutos no sistema de negociação para avaliar as condições de negociação.Obrigado, cidadão de Khabrovsk, por ler meu artigo até o fim. Prevejo sua pergunta: onde está o link para o github? A resposta é esta: ainda não publicamos coragem em código aberto. Isso requer trabalho adicional de nossa parte para melhorar a documentação e concluir alguns recursos. Se este artigo for bem recebido pela comunidade, isso nos dará um incentivo adicional para compartilhar nosso desenvolvimento com você!Bom para todos!