O canário é um pequeno pássaro que canta constantemente. Essas aves são sensíveis ao metano e monóxido de carbono. Mesmo com uma pequena concentração de excesso de gases no ar, eles perdem a consciência ou morrem. Garimpeiros e garimpeiros pegavam pássaros como presas: enquanto os canários cantam, você pode trabalhar, se calar a boca, há gás na mina e é hora de partir. Os mineiros sacrificaram um pequeno pássaro para sair vivo das minas. Uma prática semelhante se encontrou em TI. Por exemplo, na tarefa padrão de implantar uma nova versão de um serviço ou aplicativo na produção com teste antes disso. O ambiente de teste pode ser muito caro, os testes automatizados não cobrem tudo o que gostaríamos e é arriscado testar e sacrificar a qualidade. Nesses casos, a abordagem Canary Deployment ajuda quando um pouco de tráfego real de produção é lançado em uma nova versão. A abordagem ajuda a testar com segurança a nova versão para produção, sacrificando pequenas coisas para um grande objetivo. Mais detalhadamente, como a abordagem funciona, o que é útil e como implementá-la, informará Andrey Markelov (Andrey_V_Markelov), usando um exemplo de implementação na Infobip.Andrey Markelov , um engenheiro de software líder da Infobip, desenvolve aplicativos Java em finanças e telecomunicações há 11 anos. Ele desenvolve produtos Open Source, participa ativamente da Comunidade Atlassian e escreve plugins para produtos Atlassian. Evangelista Prometeu, Docker e Redis.
Uma prática semelhante se encontrou em TI. Por exemplo, na tarefa padrão de implantar uma nova versão de um serviço ou aplicativo na produção com teste antes disso. O ambiente de teste pode ser muito caro, os testes automatizados não cobrem tudo o que gostaríamos e é arriscado testar e sacrificar a qualidade. Nesses casos, a abordagem Canary Deployment ajuda quando um pouco de tráfego real de produção é lançado em uma nova versão. A abordagem ajuda a testar com segurança a nova versão para produção, sacrificando pequenas coisas para um grande objetivo. Mais detalhadamente, como a abordagem funciona, o que é útil e como implementá-la, informará Andrey Markelov (Andrey_V_Markelov), usando um exemplo de implementação na Infobip.Andrey Markelov , um engenheiro de software líder da Infobip, desenvolve aplicativos Java em finanças e telecomunicações há 11 anos. Ele desenvolve produtos Open Source, participa ativamente da Comunidade Atlassian e escreve plugins para produtos Atlassian. Evangelista Prometeu, Docker e Redis.Sobre a Infobip
Essa é uma plataforma global de telecomunicações que permite que bancos, varejistas, lojas on-line e empresas de transporte enviem mensagens para seus clientes usando SMS, push, cartas e mensagens de voz. Nesse negócio, a estabilidade e a confiabilidade são importantes para que os clientes recebam mensagens no prazo.Infobip Infraestrutura de TI em números:- 15 centros de dados em todo o mundo;
- 500 serviços exclusivos em operação;
- 2500 instâncias de serviços, que são muito mais que equipes;
- 4,5 TB de tráfego mensal;
- 4,5 bilhões de números de telefone;
O negócio está crescendo e, com ele, o número de lançamentos. Realizamos 60 lançamentos por dia , porque os clientes desejam mais recursos e capacidades. Mas isso é difícil - há muitos serviços, mas poucas equipes. Você precisa escrever rapidamente um código que funcione na produção sem erros.Lançamentos
Um lançamento típico conosco é assim. Por exemplo, existem serviços A, B, C, D e E, cada um deles desenvolvido por uma equipe separada.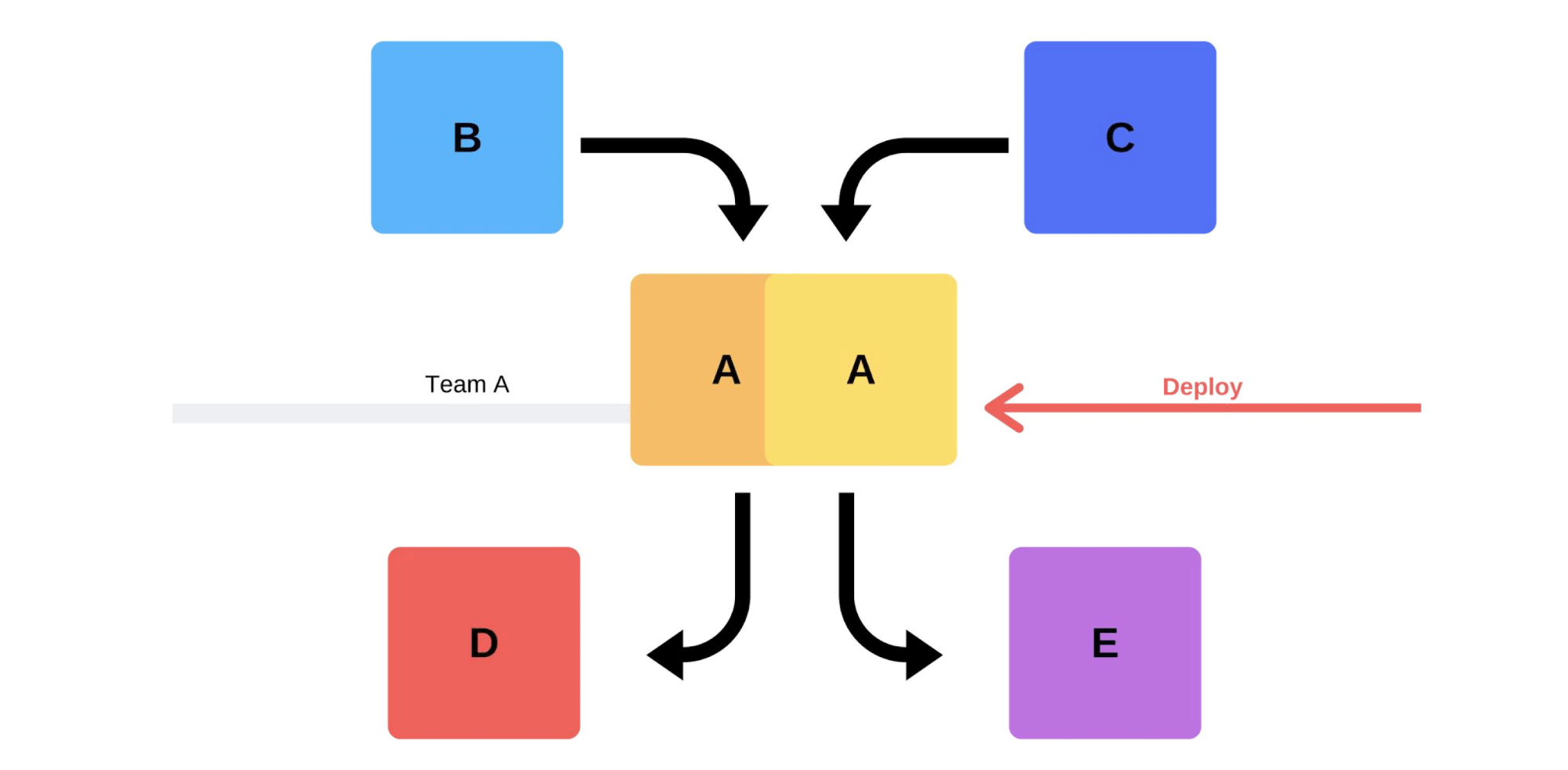 Em algum momento, a equipe de serviço A decide implantar uma nova versão, mas as equipes de serviço B, C, D e E não têm conhecimento disso. Existem duas opções para a chegada da equipe de serviço A.Realizará um lançamento incremental: primeiro ele substituirá uma versão e depois a segunda.
Em algum momento, a equipe de serviço A decide implantar uma nova versão, mas as equipes de serviço B, C, D e E não têm conhecimento disso. Existem duas opções para a chegada da equipe de serviço A.Realizará um lançamento incremental: primeiro ele substituirá uma versão e depois a segunda. Mas há uma segunda opção: a equipe encontrará capacidades e máquinas adicionais , implantará uma nova versão e depois trocará o roteador, e a versão começará a trabalhar na produção.
Mas há uma segunda opção: a equipe encontrará capacidades e máquinas adicionais , implantará uma nova versão e depois trocará o roteador, e a versão começará a trabalhar na produção. De qualquer forma, quase sempre haverá problemas após a implantação, mesmo se a versão for testada. Você pode testá-lo com as mãos, pode ser automatizado, não pode testá-lo - problemas surgirão em qualquer caso. A maneira mais fácil e correta de resolvê-los é reverter para a versão de trabalho. Só então você poderá lidar com o dano, com as causas e corrigi-las.Então o que nós queremos?Não precisamos de problemas. Se os clientes os encontrarem mais rápido que nós, isso afetará nossa reputação. Portanto, devemos encontrar problemas mais rapidamente que os clientes . Por ser proativo, minimizamos os danos.Ao mesmo tempo, queremos acelerar a implantaçãopara que isso aconteça de forma rápida, fácil, por si só e sem estresse da equipe. Engenheiros, engenheiros de DevOps e programadores devem ser protegidos - o lançamento da nova versão é estressante. Uma equipe não é consumível; nós nos esforçamos para usar racionalmente os recursos humanos .
De qualquer forma, quase sempre haverá problemas após a implantação, mesmo se a versão for testada. Você pode testá-lo com as mãos, pode ser automatizado, não pode testá-lo - problemas surgirão em qualquer caso. A maneira mais fácil e correta de resolvê-los é reverter para a versão de trabalho. Só então você poderá lidar com o dano, com as causas e corrigi-las.Então o que nós queremos?Não precisamos de problemas. Se os clientes os encontrarem mais rápido que nós, isso afetará nossa reputação. Portanto, devemos encontrar problemas mais rapidamente que os clientes . Por ser proativo, minimizamos os danos.Ao mesmo tempo, queremos acelerar a implantaçãopara que isso aconteça de forma rápida, fácil, por si só e sem estresse da equipe. Engenheiros, engenheiros de DevOps e programadores devem ser protegidos - o lançamento da nova versão é estressante. Uma equipe não é consumível; nós nos esforçamos para usar racionalmente os recursos humanos .Problemas de implantação
O tráfego do cliente é imprevisível . É impossível prever quando o tráfego do cliente será mínimo. Não sabemos onde e quando os clientes iniciarão suas campanhas - talvez hoje à noite na Índia e amanhã em Hong Kong. Dada a grande diferença de tempo, uma implantação mesmo às duas da manhã não garante que os clientes não sofrerão.Problemas do provedor . Mensageiros e provedores são nossos parceiros. Às vezes, eles apresentam falhas que causam erros durante a implantação de novas versões.Equipes distribuídas . As equipes que desenvolvem o lado do cliente e o back-end estão em fusos horários diferentes. Por esse motivo, muitas vezes não conseguem concordar entre si.Os data centers não podem ser repetidos no palco. Existem 200 racks em um data center - repetir isso na caixa de areia nem dá certo.Os períodos de inatividade não são permitidos! Temos um nível aceitável de acessibilidade (orçamento de erro) quando trabalhamos 99,99% do tempo, por exemplo, e o percentual restante é o “direito de cometer erros”. É impossível alcançar 100% de confiabilidade, mas é importante monitorar constantemente o tempo de inatividade e o tempo de inatividade.Soluções clássicas
Escreva código sem erros . Quando eu era um jovem desenvolvedor, os gerentes me abordaram com uma solicitação de lançamento sem erros, mas isso nem sempre é possível.Escreva testes . Os testes funcionam, mas às vezes não é exatamente o que a empresa deseja. Ganhar dinheiro não é uma tarefa de teste.Teste no palco . Nos 3,5 anos de meu trabalho na Infobip, nunca vi um estado de estágio coincidir pelo menos parcialmente com a produção. Tentamos até desenvolver essa idéia: primeiro tivemos um estágio, depois a pré-produção e depois a pré-produção. Mas isso também não ajudou - eles nem coincidiram em termos de poder. Com o estágio, podemos garantir a funcionalidade básica, mas não sabemos como ele funcionará sob cargas.A liberação é feita pelo desenvolvedor.Essa é uma boa prática: mesmo que alguém mude o nome de um comentário, ele o adiciona imediatamente à produção. Isso ajuda a desenvolver a responsabilidade e a não esquecer as alterações feitas.Existem dificuldades adicionais também. Para um desenvolvedor, isso é estressante - gaste muito tempo para verificar tudo manualmente.Versões acordadas . Essa opção geralmente oferece gerenciamento: "Vamos concordar que você testará e adicionará novas versões todos os dias". Isso não funciona: sempre há uma equipe que espera por todos os outros ou vice-versa.
Tentamos até desenvolver essa idéia: primeiro tivemos um estágio, depois a pré-produção e depois a pré-produção. Mas isso também não ajudou - eles nem coincidiram em termos de poder. Com o estágio, podemos garantir a funcionalidade básica, mas não sabemos como ele funcionará sob cargas.A liberação é feita pelo desenvolvedor.Essa é uma boa prática: mesmo que alguém mude o nome de um comentário, ele o adiciona imediatamente à produção. Isso ajuda a desenvolver a responsabilidade e a não esquecer as alterações feitas.Existem dificuldades adicionais também. Para um desenvolvedor, isso é estressante - gaste muito tempo para verificar tudo manualmente.Versões acordadas . Essa opção geralmente oferece gerenciamento: "Vamos concordar que você testará e adicionará novas versões todos os dias". Isso não funciona: sempre há uma equipe que espera por todos os outros ou vice-versa.Testes de fumaça
Outra maneira de resolver nossos problemas de implantação. Vamos ver como os testes de fumaça funcionam no exemplo anterior, quando a equipe A deseja implantar uma nova versão.Primeiro, a equipe implementa uma instância na produção. As mensagens para a instância de simulações simulam tráfego real para que ele corresponda ao tráfego diário normal. Se tudo estiver bem, a equipe muda a nova versão para o tráfego do usuário.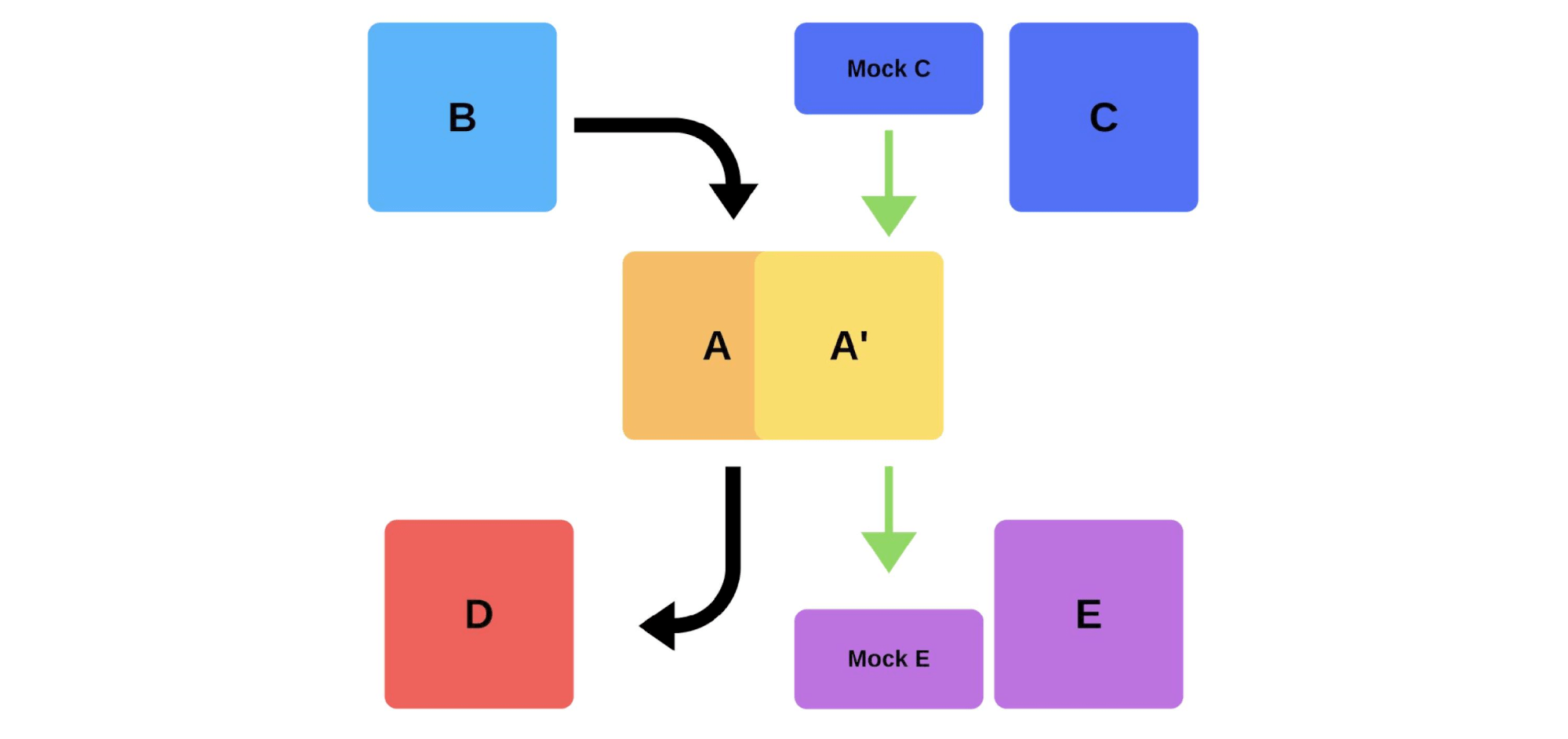 A segunda opção é implantar com ferro adicional. A equipe testa a produção, depois muda, e tudo funciona.
A segunda opção é implantar com ferro adicional. A equipe testa a produção, depois muda, e tudo funciona. Desvantagens dos testes de fumaça:
Desvantagens dos testes de fumaça:- Os testes não podem ser confiáveis. Onde obter o mesmo tráfego da produção? Você pode usar ontem ou uma semana atrás, mas nem sempre coincide com o atual.
- É difícil de manter. Você terá que dar suporte às contas de teste, redefini-las constantemente antes de cada implantação, quando os registros ativos forem enviados ao repositório. Isso é mais difícil do que escrever um teste na sua caixa de areia.
O único bônus aqui é que você pode verificar o desempenho .Liberações de canário
Devido às falhas dos testes de fumaça, começamos a usar lançamentos de canários.Uma prática semelhante à maneira como os mineradores usavam canários para indicar os níveis de gás encontrados na TI. Estamos lançando um pouco de tráfego real de produção para a nova versão , enquanto tentamos cumprir o SLA (Service Level Agreement). O SLA é nosso "direito de cometer erros", que podemos usar uma vez por ano (ou por algum outro período de tempo). Se tudo correr bem, adicione mais tráfego. Caso contrário, retornaremos as versões anteriores.
Implementação e nuances
Como implementamos lançamentos de canários? Por exemplo, um grupo de clientes envia mensagens através do nosso serviço.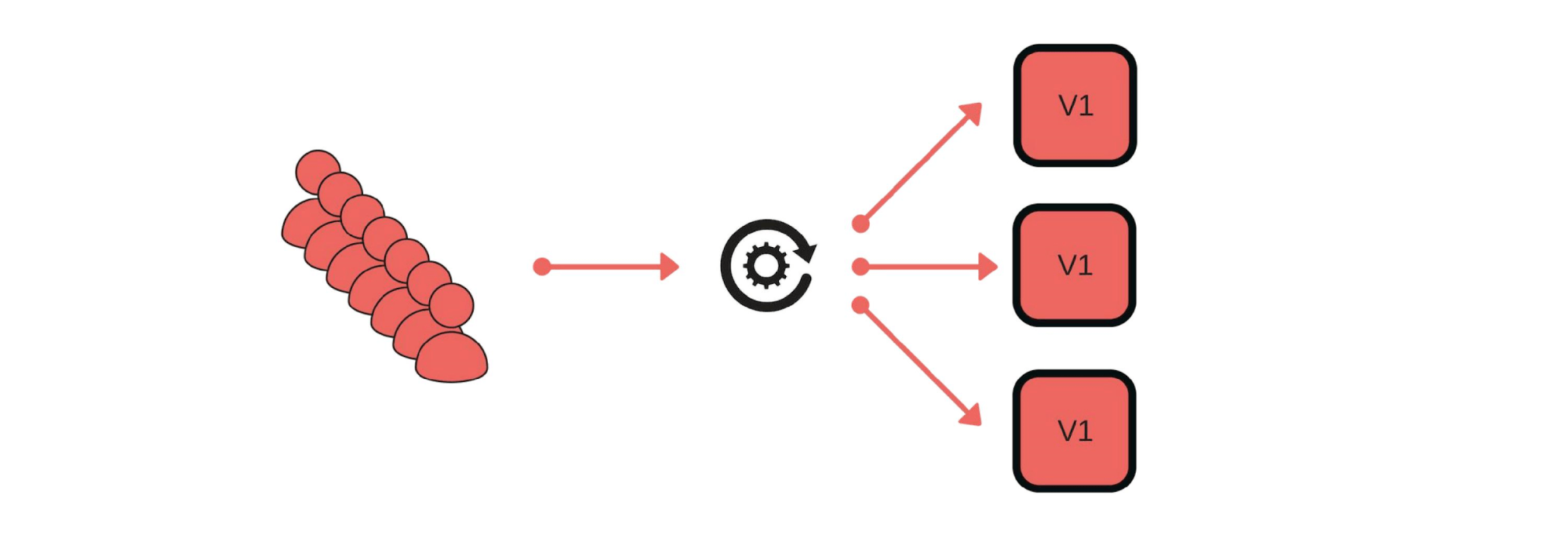 A implantação é assim: remova um nó do balanceador (1), altere a versão (2) e inicie algum tráfego separadamente (3).
A implantação é assim: remova um nó do balanceador (1), altere a versão (2) e inicie algum tráfego separadamente (3). Em geral, todos no grupo ficarão felizes, mesmo que um usuário não esteja feliz. Se tudo estiver bem - altere todas as versões.
Em geral, todos no grupo ficarão felizes, mesmo que um usuário não esteja feliz. Se tudo estiver bem - altere todas as versões. Mostrarei esquematicamente como ele procura microsserviços na maioria dos casos.Há Service Discovery e mais dois serviços: S1N1 e S2. O primeiro serviço (S1N1) notifica o Service Discovery quando é iniciado e o Service Discovery se lembra dele. O segundo serviço com dois nós (S2N1 e S2N2) também notifica o Service Discovery na inicialização.
Mostrarei esquematicamente como ele procura microsserviços na maioria dos casos.Há Service Discovery e mais dois serviços: S1N1 e S2. O primeiro serviço (S1N1) notifica o Service Discovery quando é iniciado e o Service Discovery se lembra dele. O segundo serviço com dois nós (S2N1 e S2N2) também notifica o Service Discovery na inicialização.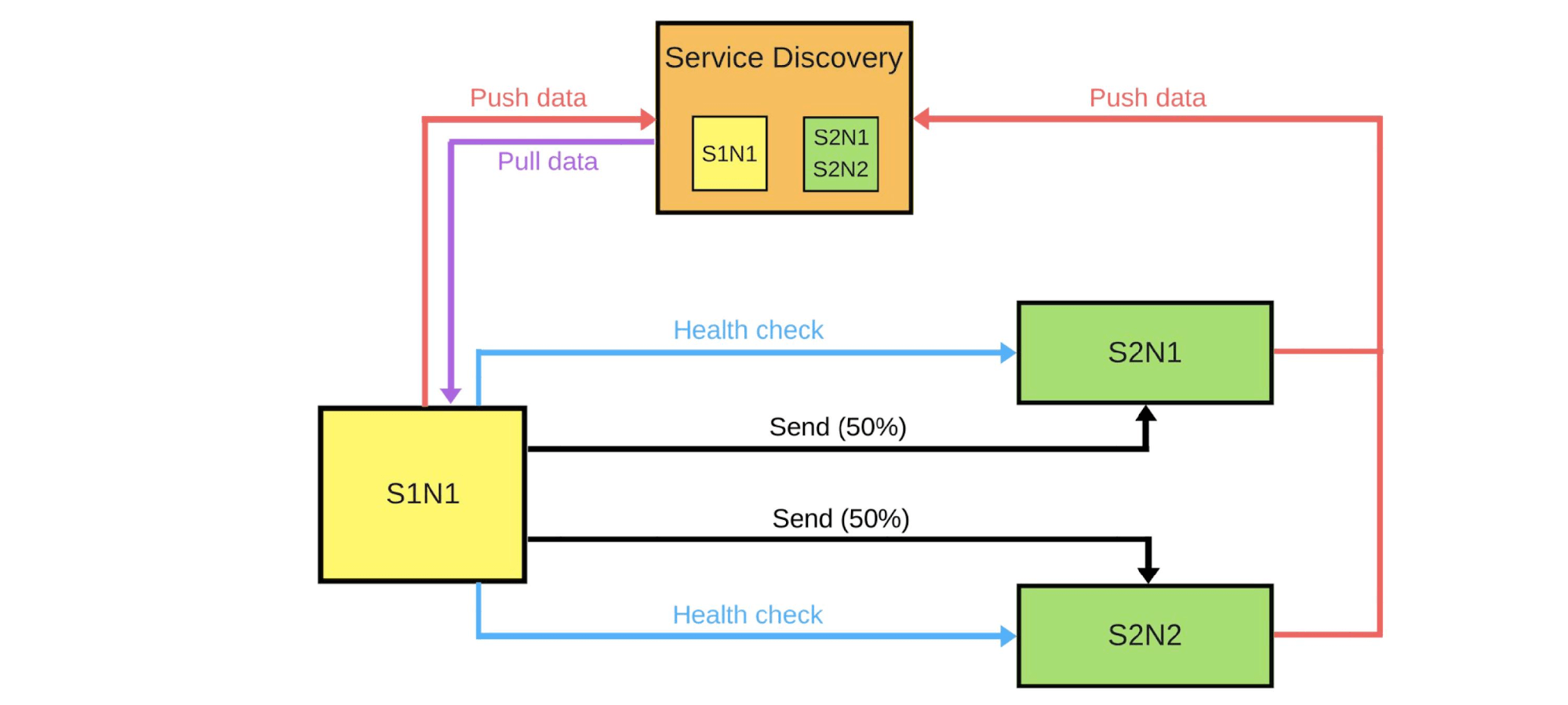 O segundo serviço para o primeiro funciona como um servidor. O primeiro solicita informações sobre seus servidores ao Service Discovery e, quando o recebe, as procura e verifica ("verificação de integridade"). Quando ele verificar, ele lhes enviará mensagens.Quando alguém deseja implantar uma nova versão do segundo serviço, ele diz ao Service Discovery que o segundo nó será um canário: menos tráfego será enviado a ele, porque será implantado agora. Removemos o nó canário do balanceador e o primeiro serviço não envia tráfego para ele.
O segundo serviço para o primeiro funciona como um servidor. O primeiro solicita informações sobre seus servidores ao Service Discovery e, quando o recebe, as procura e verifica ("verificação de integridade"). Quando ele verificar, ele lhes enviará mensagens.Quando alguém deseja implantar uma nova versão do segundo serviço, ele diz ao Service Discovery que o segundo nó será um canário: menos tráfego será enviado a ele, porque será implantado agora. Removemos o nó canário do balanceador e o primeiro serviço não envia tráfego para ele.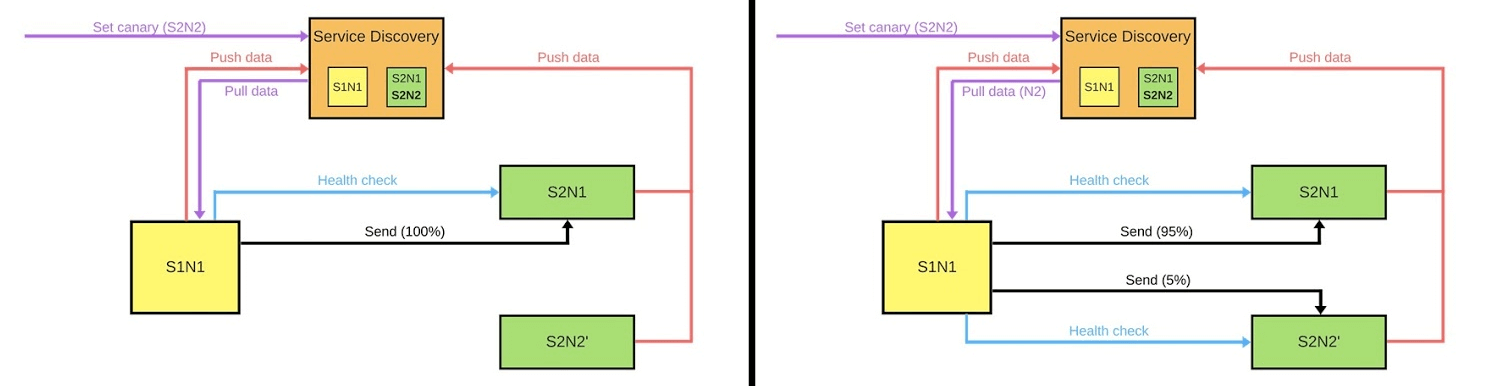 Mudamos a versão e o Service Discovery sabe que o segundo nó agora é canário - você pode oferecer menos carga (5%). Se tudo estiver bem, altere a versão, retorne a carga e continue.Para implementar tudo isso, precisamos:
Mudamos a versão e o Service Discovery sabe que o segundo nó agora é canário - você pode oferecer menos carga (5%). Se tudo estiver bem, altere a versão, retorne a carga e continue.Para implementar tudo isso, precisamos:- balanceamento;
- , , , ;
- , , ;
- — (deployment pipeline).
 Esta é a primeira coisa que devemos pensar. Existem duas estratégias de balanceamento.A opção mais simples é quando um nó é sempre canário . Esse nó sempre recebe menos tráfego e começamos a implantar a partir dele. Em caso de problemas, compararemos o trabalho dela com a implantação e durante o mesmo. Por exemplo, se houver 2 vezes mais erros, o dano aumentará 2 vezes.O nó Canary é definido durante o processo de implantação . Quando a implantação terminar e removermos o status do nó canário, o saldo do tráfego será restaurado. Com menos carros, temos uma distribuição honesta.
Esta é a primeira coisa que devemos pensar. Existem duas estratégias de balanceamento.A opção mais simples é quando um nó é sempre canário . Esse nó sempre recebe menos tráfego e começamos a implantar a partir dele. Em caso de problemas, compararemos o trabalho dela com a implantação e durante o mesmo. Por exemplo, se houver 2 vezes mais erros, o dano aumentará 2 vezes.O nó Canary é definido durante o processo de implantação . Quando a implantação terminar e removermos o status do nó canário, o saldo do tráfego será restaurado. Com menos carros, temos uma distribuição honesta.Monitoramento
A pedra angular dos lançamentos de canários. Precisamos entender exatamente por que estamos fazendo isso e quais métricas queremos coletar.Exemplos de métricas que coletamos de nossos serviços.- , . , . , .
- (latency). , .
- (throughput).
- .
- 95% .
- -: . , , .
Exemplos de métricas nos sistemas de monitoramento mais populares.Contador Esse é um valor crescente, por exemplo, o número de erros. É fácil interpolar essa métrica e estudar o gráfico: ontem houve 2 erros e hoje 500, depois algo deu errado.O número de erros por minuto ou por segundo é o indicador mais importante que pode ser calculado usando o Contador. Esses dados dão uma idéia clara da operação do sistema à distância. Vejamos um exemplo de um gráfico do número de erros por segundo para duas versões de um sistema de produção. Houve poucos erros na primeira versão; a auditoria pode não ter funcionado. Na segunda versão, tudo é muito pior. Podemos dizer com certeza que há problemas, portanto, devemos reverter esta versão.Calibre.As métricas são semelhantes às do contador, mas registramos valores que podem aumentar ou diminuir. Por exemplo, tempo de execução da consulta ou tamanho da fila.O gráfico mostra um exemplo de tempo de resposta (latência). O gráfico mostra que as versões são semelhantes, você pode trabalhar com elas. Mas se você olhar de perto, é notável como a quantidade muda. Se o tempo de execução das solicitações aumentar quando os usuários forem adicionados, é imediatamente claro que há problemas - esse não era o caso antes.
Houve poucos erros na primeira versão; a auditoria pode não ter funcionado. Na segunda versão, tudo é muito pior. Podemos dizer com certeza que há problemas, portanto, devemos reverter esta versão.Calibre.As métricas são semelhantes às do contador, mas registramos valores que podem aumentar ou diminuir. Por exemplo, tempo de execução da consulta ou tamanho da fila.O gráfico mostra um exemplo de tempo de resposta (latência). O gráfico mostra que as versões são semelhantes, você pode trabalhar com elas. Mas se você olhar de perto, é notável como a quantidade muda. Se o tempo de execução das solicitações aumentar quando os usuários forem adicionados, é imediatamente claro que há problemas - esse não era o caso antes. Sumário Um dos indicadores mais importantes para os negócios são os percentis. A métrica mostra que, em 95% dos casos, nosso sistema funciona da maneira que queremos. Podemos chegar a um acordo se houver problemas em algum lugar, porque entendemos a tendência geral de como tudo é bom ou ruim.
Sumário Um dos indicadores mais importantes para os negócios são os percentis. A métrica mostra que, em 95% dos casos, nosso sistema funciona da maneira que queremos. Podemos chegar a um acordo se houver problemas em algum lugar, porque entendemos a tendência geral de como tudo é bom ou ruim.Ferramentas
Pilha ELK . Você pode implementar o canary usando o Elasticsearch - escrevemos erros quando ocorrem eventos. Simplesmente chamar a API, você pode obter erros a qualquer momento, e compará-lo com os segmentos anteriores: GET /applg/_cunt?q=level:errr.Prometeu. Ele se mostrou bem no Infobip. Permite implementar métricas multidimensionais porque etiquetas são usadas.Podemos usar level, instance, service, combiná-los em um único sistema. Usando offset-o, você pode ver, por exemplo, o valor de uma semana atrás com apenas um comando GET /api/v1/query?query={query}, onde {query}:rate(logback_appender_total{
level="error",
instance=~"$instance"
}[5m] offset $offset_value)
Análise de versão
Existem várias estratégias de versão.Veja métricas apenas de nós canários. Uma das opções mais simples: implantou uma nova versão e estuda apenas o trabalho. Mas se o engenheiro nesse momento começar a estudar os logs, constantemente recarregando as páginas nervosamente, essa solução não será diferente do resto.Um nó canário é comparado a qualquer outro nó . Esta é uma comparação com outras instâncias executadas no tráfego total. Por exemplo, se com tráfego pequeno as coisas são piores, ou não melhores do que em instâncias reais, algo está errado.Um nó canário é comparado a si mesmo no passado. Os nós alocados para canários podem ser comparados com dados históricos. Por exemplo, se há uma semana tudo estava bem, podemos nos concentrar nesses dados para entender a situação atual.Automação
Queremos libertar os engenheiros das comparações manuais, por isso é importante implementar a automação. O processo de pipeline de implantação geralmente se parece com isso:- nós começamos;
- remova o nó do balanceador;
- defina o nó canário;
- ligue o balanceador já com uma quantidade limitada de tráfego;
- comparar.
 Neste ponto, implementamos uma comparação automática . Como pode parecer e por que é melhor do que verificar após a implantação, consideraremos o exemplo de Jenkins.Este é o pipeline para o Groovy.
Neste ponto, implementamos uma comparação automática . Como pode parecer e por que é melhor do que verificar após a implantação, consideraremos o exemplo de Jenkins.Este é o pipeline para o Groovy.while (System.currentTimeMillis() < endCanaryTs) {
def isOk = compare(srv, canary, time, base, offset, metrics)
if (isOk) {
sleep DEFAULT SLEEP
} else {
echo "Canary failed, need to revert"
return false
}
}
Aqui no ciclo, definimos que compararemos o novo nó por uma hora. Se o processo canário ainda não tiver concluído o processo, chamamos a função Ela relata que tudo está bem ou não: def isOk = compare(srv, canary, time, base, offset, metrics).Se tudo estiver bem - sleep DEFAULT SLEEPpor exemplo, por um segundo, e continue. Caso contrário, sairemos - a implantação falhou.Descrição da métrica. Vamos ver como uma função pode parecer compareno exemplo do DSL.metric(
'errorCounts',
'rate(errorCounts{node=~"$canaryInst"}[5m] offset $offset)',
{ baseValue, canaryValue ->
if (canaryValue > baseValue * 1.3) return false
return true
}
)
Suponha que comparemos o número de erros e queremos saber o número de erros por segundo nos últimos 5 minutos.Temos dois valores: nós base e canários. O valor do nó canário é o atual. Básico - baseValueé o valor de qualquer outro nó não canário. Comparamos os valores entre si de acordo com a fórmula, que estabelecemos com base em nossa experiência e observações. Se o valor estiver canaryValueruim, a implantação falhou e nós revertemos.Por que tudo isso é necessário?O homem não pode verificar centenas e milhares de métricasespecialmente para fazê-lo rapidamente. Uma comparação automática ajuda a verificar todas as métricas e alerta rapidamente para problemas. O tempo de notificação é crítico: se algo aconteceu nos últimos 2 segundos, o dano não será tão grande como se tivesse acontecido 15 minutos atrás. Até que alguém perceba um problema, escreva suporte e possamos perder clientes para reverter o suporte.Se o processo correu bem e está tudo bem, implantaremos todos os outros nós automaticamente. Os engenheiros não estão fazendo nada no momento. Somente quando executam o canary eles decidem quais métricas tomar, quanto tempo fazer a comparação, qual estratégia usar. Se houver problemas, reverteremos automaticamente o nó canário, trabalharemos nas versões anteriores e corrigiremos os erros que encontramos. Por métricas, eles são fáceis de encontrar e ver os danos da nova versão.
Se houver problemas, reverteremos automaticamente o nó canário, trabalharemos nas versões anteriores e corrigiremos os erros que encontramos. Por métricas, eles são fáceis de encontrar e ver os danos da nova versão.Obstáculos
Implementar isso, é claro, não é fácil. Primeiro de tudo, precisamos de um sistema de monitoramento comum . Os engenheiros têm suas próprias métricas, o suporte e os analistas, diferentes, e os negócios, a terceira. Um sistema comum é um idioma comum falado pelos negócios e desenvolvimento.É necessário verificar na prática a estabilidade das métricas. A verificação ajuda a entender qual é o conjunto mínimo de métricas necessárias para garantir a qualidade .Como conseguir isso? Use o serviço canary não no momento da implantação . Adicionamos um determinado serviço à versão antiga, que a qualquer momento poderá receber qualquer nó alocado, reduzir o tráfego sem implantação. Depois de compararmos: estudamos os erros e procuramos essa linha quando obtemos qualidade.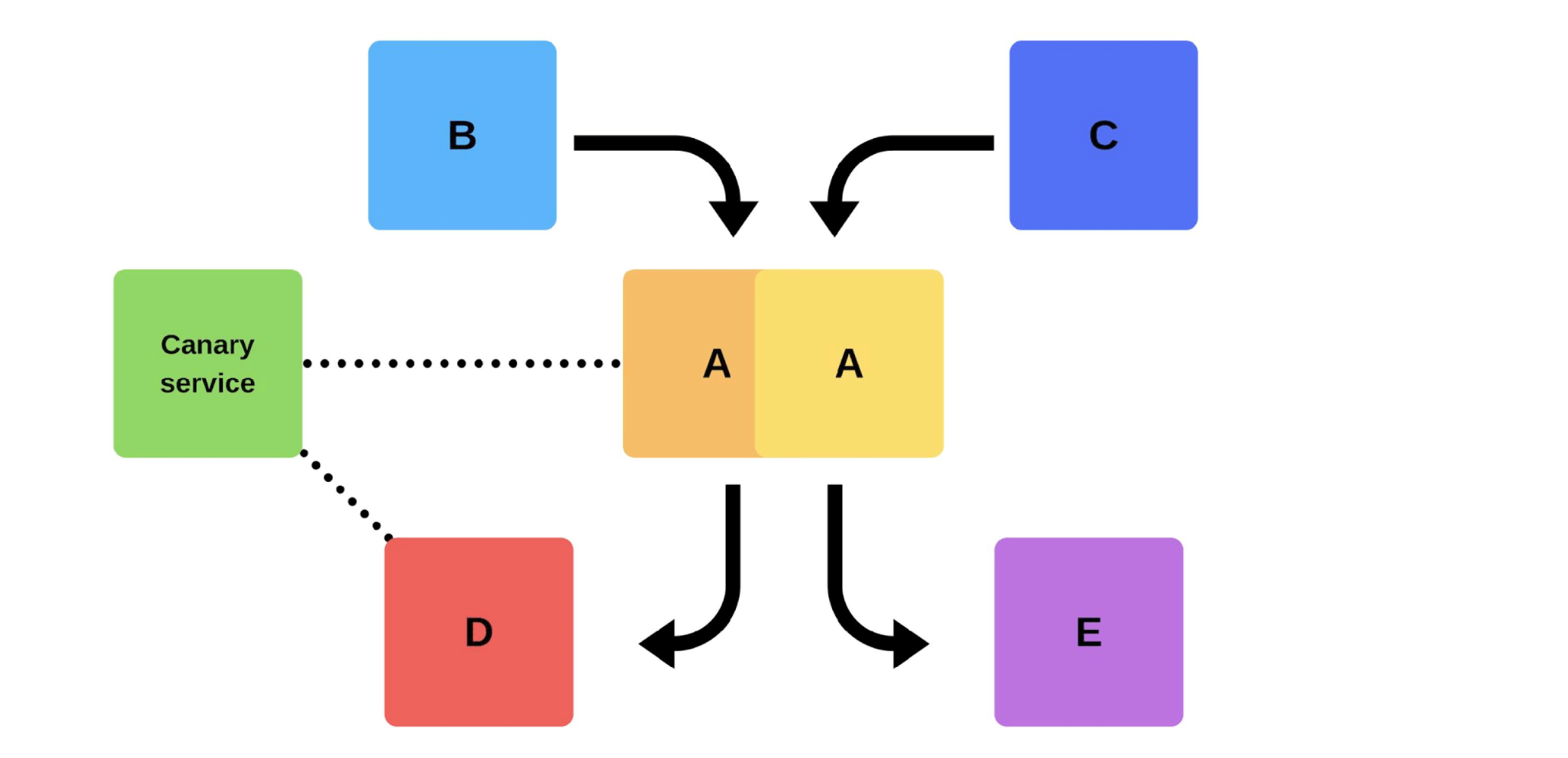
Que benefício temos das liberações de canários
Minimizou a porcentagem de danos causados por bugs. A maioria dos erros de implantação ocorre devido a inconsistência em alguns dados ou prioridade. Tais erros tornaram-se muito menores, porque podemos resolver o problema nos primeiros segundos.Otimizou o trabalho das equipes. Os iniciantes têm o “direito de cometer um erro”: eles podem implantar na produção sem medo de erros, uma iniciativa adicional aparece, um incentivo para o trabalho. Se eles quebrarem algo, não será crítico e a pessoa errada não será demitida.Implantação automatizada . Este não é mais um processo manual, como antes, mas sim um processo automatizado. Mas leva mais tempo.Métricas importantes destacadas. Toda a empresa, começando pelos negócios e engenheiros, entende o que é realmente importante em nosso produto, quais métricas, por exemplo, a vazão e o fluxo de usuários. Controlamos o processo: testamos métricas, apresentamos novas, vemos como as antigas funcionam para construir um sistema que tornará o dinheiro mais produtivo.Temos muitas práticas e sistemas interessantes que nos ajudam. Apesar disso, nos esforçamos para ser profissionais e fazer nosso trabalho com eficiência, independentemente de termos um sistema que nos ajude ou não.— TechLead Conf. , , — .
TechLead Conf 8 9 . , , — , .