Centenas, milhares e, em alguns serviços, milhões de filas, pelas quais passa uma enorme quantidade de dados, estão girando sob o capô do nosso produto. Tudo isso deve ser processado de alguma maneira mágica e não ser filmado. Neste post, mostrarei quais abordagens arquiteturais usamos em casa, com uma pilha de tecnologia bastante modesta e sem um pequeno centro de dados em nossa “despensa”.
O que nós temos?
Então, por um lado, temos uma pilha de tecnologia bem conhecida: Nginx, PHP, PostgreSQL, Redis. Por outro lado, dezenas de milhares de eventos ocorrem em nosso sistema a cada minuto e, no pico, pode atingir centenas de milhares de eventos. Para deixar claro quais são esses eventos e como devemos reagir a eles, farei uma pequena digressão no produto, após o qual explicarei como desenvolvemos o sistema de automação baseado em eventos.ManyChat é uma plataforma para automação de marketing. O proprietário da página do Facebook pode conectá-lo à nossa plataforma e configurar a automação da interação com seus assinantes (em outras palavras, criar um bot de bate-papo). A automação geralmente consiste em muitas cadeias de interações que podem não estar interconectadas. Dentro dessas cadeias de automação, certas ações podem ocorrer com o assinante, por exemplo, atribuindo uma etiqueta específica no sistema ou atribuindo / alterando o valor de um campo no cartão de um assinante. Esses dados ainda permitem segmentar o público e criar uma interação mais relevante com os assinantes da página.Nossos clientes realmente queriam a automação baseada em eventos - a capacidade de personalizar a execução de uma ação quando um evento específico é acionado dentro do assinante (por exemplo, marcação).Como um evento acionador pode funcionar a partir de diferentes cadeias de automação, é importante que exista um único ponto de configuração para todas as ações baseadas em eventos no lado do cliente e, no lado do processamento, deve haver um único barramento que processe a alteração no contexto do assinante a partir de diferentes pontos de automação.Em nosso sistema, há um barramento comum através do qual todos os eventos que ocorrem com os assinantes passam. São mais de 500 milhões de eventos por dia. O processamento deles é bastante delicado - esse é um registro no data warehouse, para que o proprietário da página tenha a oportunidade de ver historicamente tudo o que aconteceu com seus assinantes.Parece que, para implementar um sistema baseado em eventos, já temos tudo, e basta integrar nossa lógica de negócios ao processamento de um barramento de eventos comum. Mas temos certos requisitos para o nosso novo sistema:- Não queremos obter desempenho degradado no processamento do barramento de evento principal
- É importante mantermos a ordem de processamento de mensagens no novo sistema, pois isso pode estar vinculado à lógica de negócios do cliente que configura a automação.
- Evite o efeito de vizinhos barulhentos quando páginas ativas com um grande número de assinantes obstruem a fila e bloqueiam o processamento de eventos de páginas "pequenas"
Se integrarmos o processamento de nossa lógica ao processamento de um barramento de eventos comum, obteremos uma degradação séria no desempenho, pois teremos que verificar cada evento quanto à conformidade com a automação configurada. Como parte da configuração da automação, certos filtros podem ser aplicados (por exemplo, inicie a automação quando um evento é acionado apenas para clientes do sexo feminino com mais de 30 anos). Ou seja, ao processar eventos no barramento principal, uma enorme quantidade de solicitações extras para o banco de dados será processada, e também uma lógica bastante pesada começará a comparar o contexto atual do assinante com as configurações de automação. Esta opção não nos convém, então pensamos mais.
Organização de uma cascata de filas
Como nossa lógica de negócios associada ao sistema baseado em eventos é muito bem separável da lógica para processar eventos do barramento principal, decidimos colocar os tipos de eventos que precisamos do barramento compartilhado em uma fila separada para processamento adicional em um fluxo de dados separado. Assim, removemos o problema associado à degradação do desempenho no processamento do barramento de evento principal.No mesmo estágio, decidimos o que seria legal transferir eventos para a próxima fila em cascata para colocar esses eventos em filas separadas para cada bot. Assim, isolando a atividade de cada bot com a estrutura de sua vez, o que nos permite resolver o problema associado ao efeito de vizinhos barulhentos.Nosso diagrama de fluxo de dados agora se parece com o seguinte: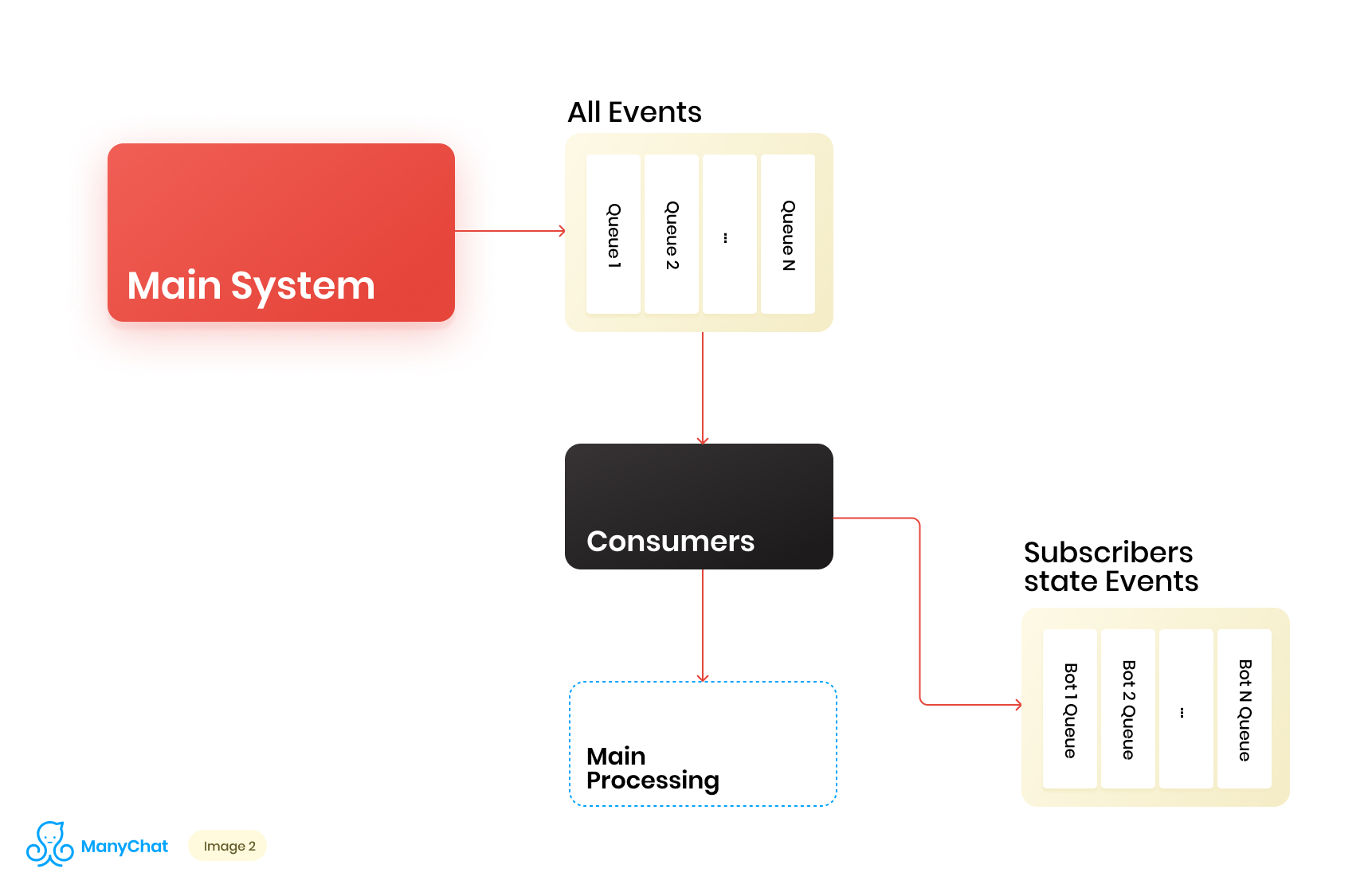 No entanto, para que esse esquema funcione, precisamos resolver o problema do processamento de novas filas.Existem mais de 1 milhão de páginas conectadas (bots) em nossa plataforma, o que significa que potencialmente podemos obter ~ 1 milhão de filas em nosso esquema, apenas no nível da camada baseada em eventos. Do ponto de vista técnico, isso não é assustador para nós. Como servidor de filas, usamos o Redis com seus tipos de dados padrão, como LIST, SORTED SET e outros. Isso significa que cada fila é a estrutura de dados padrão para Redis na RAM, que pode ser criada ou excluída em tempo real, o que nos permite operar com facilidade e flexibilidade um grande número de filas em nosso sistema. Falarei mais profundamente sobre o uso do Redis como um servidor de filas com detalhes técnicos em uma postagem separada, mas, por enquanto, vamos voltar à nossa arquitetura.É claro que cada bot tem uma atividade diferente e que a probabilidade de obter 1 milhão de filas no estado "precisa processar agora" é extremamente pequena. Mas, a certa altura, é bem possível que tenhamos dezenas de milhares de filas ativas que requerem processamento. O número dessas filas está mudando constantemente. Essas filas também são alteradas, algumas são subtraídas completamente e excluídas, outras são criadas dinamicamente e preenchidas com eventos para processamento. Portanto, precisamos encontrar uma maneira eficaz de lidar com eles.
No entanto, para que esse esquema funcione, precisamos resolver o problema do processamento de novas filas.Existem mais de 1 milhão de páginas conectadas (bots) em nossa plataforma, o que significa que potencialmente podemos obter ~ 1 milhão de filas em nosso esquema, apenas no nível da camada baseada em eventos. Do ponto de vista técnico, isso não é assustador para nós. Como servidor de filas, usamos o Redis com seus tipos de dados padrão, como LIST, SORTED SET e outros. Isso significa que cada fila é a estrutura de dados padrão para Redis na RAM, que pode ser criada ou excluída em tempo real, o que nos permite operar com facilidade e flexibilidade um grande número de filas em nosso sistema. Falarei mais profundamente sobre o uso do Redis como um servidor de filas com detalhes técnicos em uma postagem separada, mas, por enquanto, vamos voltar à nossa arquitetura.É claro que cada bot tem uma atividade diferente e que a probabilidade de obter 1 milhão de filas no estado "precisa processar agora" é extremamente pequena. Mas, a certa altura, é bem possível que tenhamos dezenas de milhares de filas ativas que requerem processamento. O número dessas filas está mudando constantemente. Essas filas também são alteradas, algumas são subtraídas completamente e excluídas, outras são criadas dinamicamente e preenchidas com eventos para processamento. Portanto, precisamos encontrar uma maneira eficaz de lidar com eles.Processando um enorme pool de filas
Então, temos um monte de filas. A cada momento, pode haver uma quantidade aleatória. Uma condição importante para o processamento de cada fila, mencionada no início de sua postagem, é que os eventos em cada página sejam processados estritamente em sequência. Isso significa que, em um determinado momento, cada fila não pode ser processada por mais de um trabalhador, a fim de evitar problemas competitivos.Mas fazer a proporção de filas para manipuladores 1: 1 é uma tarefa duvidosa. O número de filas está mudando constantemente, tanto para cima quanto para baixo. O número de manipuladores em execução também não é infinito, pelo menos temos uma limitação por parte do sistema operacional e do hardware e não queremos que os trabalhadores permaneçam ociosos nas filas vazias. Para resolver o problema de interação entre manipuladores e filas, implementamos um sistema round robin para processar nosso conjunto de filas.E aqui a linha de controle veio em nosso auxílio. Quando o evento é encaminhado do barramento compartilhado para a fila baseada em eventos de um bot específico, também colocamos o identificador dessa fila de bot na fila de controle. A fila de controle armazena apenas os identificadores das filas que estão no pool e precisam ser processadas. Somente valores exclusivos são armazenados na fila de controle, ou seja, o mesmo identificador de fila bot será armazenado na fila de controle apenas uma vez, independentemente de quantas vezes ele for gravado lá. No Redis, isso é implementado usando a estrutura de dados SORTED SET.Além disso, podemos distinguir um certo número de trabalhadores, cada um dos quais receberá da fila de controle seu identificador da fila bot para processamento. Assim, cada trabalhador processará independentemente o pedaço da fila atribuída a ele, depois de processá-lo, retornará o identificador da fila processada ao controle, retornando-o ao nosso rodízio. O principal é não esquecer de fornecer bloqueios à coisa toda, para que dois trabalhadores não possam processar a mesma fila de bot em paralelo. Essa situação é possível se o identificador de bot entra na fila de controle quando já está sendo processado pelo trabalhador. Para bloqueios, também usamos Redis como a chave: armazenamento de valor com TTL.Quando executamos uma tarefa com um identificador de fila bot da fila de controle, colocamos um bloqueio TTL na fila executada e começamos a processá-lo. Se o outro consumidor executar a tarefa com a fila que já está sendo processada da fila de controle, ele não poderá bloquear, retorne a tarefa à fila de controle e receba a próxima tarefa. Depois de processar a fila de bot pelo consumidor, ele remove o bloqueio e vai para a fila de controle para a próxima tarefa.O esquema final é o seguinte:
Quando o evento é encaminhado do barramento compartilhado para a fila baseada em eventos de um bot específico, também colocamos o identificador dessa fila de bot na fila de controle. A fila de controle armazena apenas os identificadores das filas que estão no pool e precisam ser processadas. Somente valores exclusivos são armazenados na fila de controle, ou seja, o mesmo identificador de fila bot será armazenado na fila de controle apenas uma vez, independentemente de quantas vezes ele for gravado lá. No Redis, isso é implementado usando a estrutura de dados SORTED SET.Além disso, podemos distinguir um certo número de trabalhadores, cada um dos quais receberá da fila de controle seu identificador da fila bot para processamento. Assim, cada trabalhador processará independentemente o pedaço da fila atribuída a ele, depois de processá-lo, retornará o identificador da fila processada ao controle, retornando-o ao nosso rodízio. O principal é não esquecer de fornecer bloqueios à coisa toda, para que dois trabalhadores não possam processar a mesma fila de bot em paralelo. Essa situação é possível se o identificador de bot entra na fila de controle quando já está sendo processado pelo trabalhador. Para bloqueios, também usamos Redis como a chave: armazenamento de valor com TTL.Quando executamos uma tarefa com um identificador de fila bot da fila de controle, colocamos um bloqueio TTL na fila executada e começamos a processá-lo. Se o outro consumidor executar a tarefa com a fila que já está sendo processada da fila de controle, ele não poderá bloquear, retorne a tarefa à fila de controle e receba a próxima tarefa. Depois de processar a fila de bot pelo consumidor, ele remove o bloqueio e vai para a fila de controle para a próxima tarefa.O esquema final é o seguinte: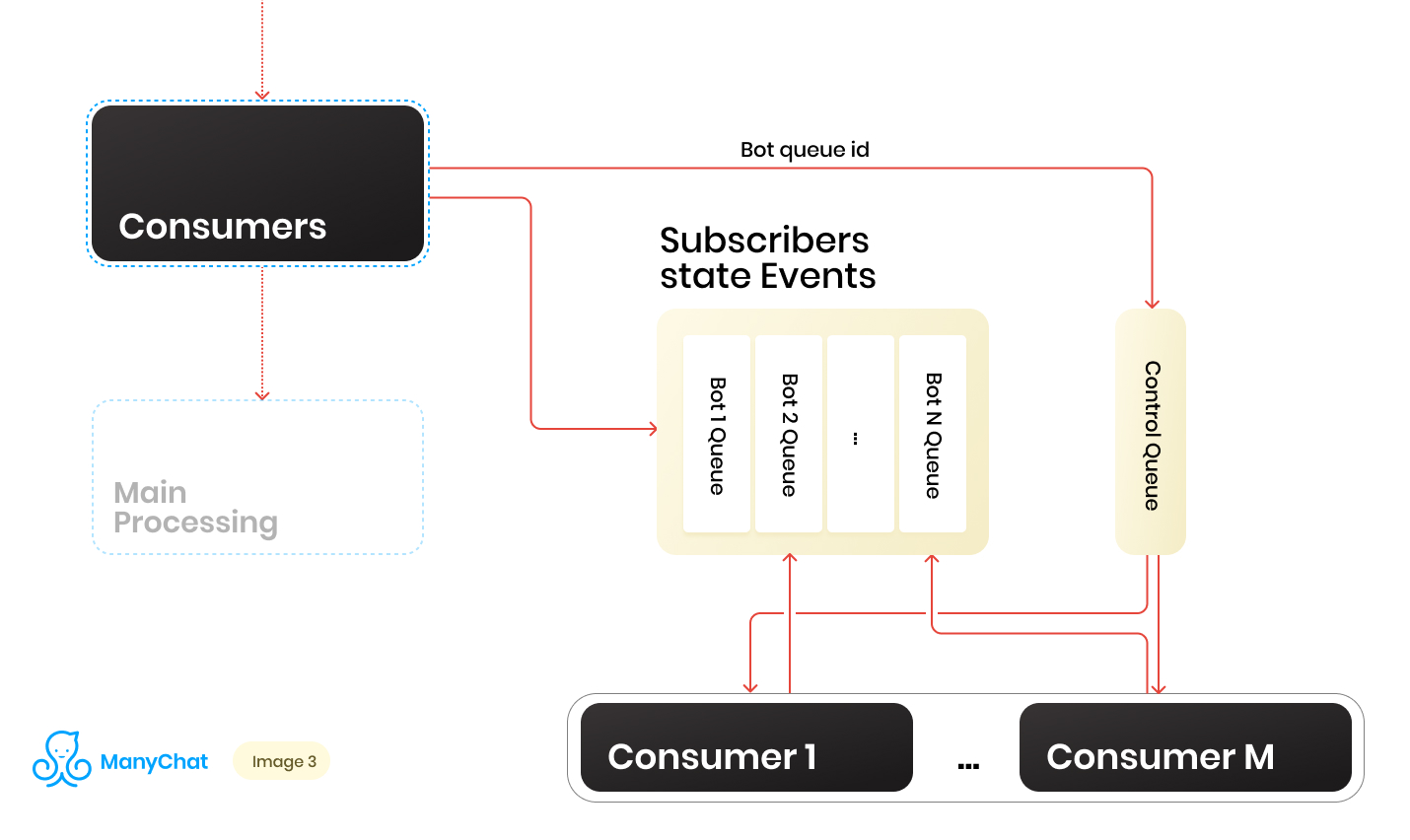 Como resultado, com o esquema atual, resolvemos os principais problemas identificados:
Como resultado, com o esquema atual, resolvemos os principais problemas identificados:- Degradação do desempenho no barramento de evento principal
- Violação de manipulação de eventos
- O efeito de vizinhos barulhentos
Como lidar com a carga dinâmica?
O esquema está funcionando, mas nele temos um número fixo de consumidores para um número dinâmico de filas. Obviamente, com essa abordagem, nos empenharemos no processamento das filas toda vez que seu número aumentar acentuadamente. Parece que seria bom para nossos trabalhadores iniciar ou extinguir dinamicamente quando necessário. Também seria bom se isso não complicasse muito o processo de lançamento de novo código. Nesses momentos, as mãos têm muita vontade de escrever seu gerente de processos. No futuro, fizemos exatamente isso, mas essa história é diferente.Pensando, decidimos, por que não usar mais uma vez todas as ferramentas familiares e familiares. Portanto, adquirimos nossa API interna, que funcionava em um pacote padrão de NGINX + PHP-FPM. Como resultado, podemos substituir nosso pool fixo de trabalhadores por APIs e permitir que o NGINX + PHP-FPM resolva e gerencie nós mesmos, e basta que tenhamos entre a fila de controle e nossa API interna apenas um consumidor de controle, que enviará identificadores de fila para nossa API para processamento e a própria fila será processada no trabalhador gerado pelo PHP-FPM.O novo esquema foi o seguinte: Parece bonito, mas nosso consumidor de controle trabalha em um thread e nossa API funciona de forma síncrona. Isso significa que o consumidor trava sempre que o PHP-FPM estiver moendo uma fila. Isso não nos convém.
Parece bonito, mas nosso consumidor de controle trabalha em um thread e nossa API funciona de forma síncrona. Isso significa que o consumidor trava sempre que o PHP-FPM estiver moendo uma fila. Isso não nos convém.Tornando nossa API assíncrona
Mas e se pudéssemos enviar uma tarefa para nossa API e deixá-la passar pela lógica de negócios lá, e nosso consumidor de controle seguirá a próxima tarefa na fila de controle, após a qual ela será puxada de volta para a API e assim por diante. Não antes de dizer que acabou.A implementação requer algumas linhas de código, e a Prova de Conceito é assim:class Api {
public function actionDoSomething()
{
$data = $_POST;
$this->dropFPMSession();
}
protected function dropFPMSession()
{
ignore_user_abort(true);
ob_end_flush();
flush();
@session_write_close();
fastcgi_finish_request();
}
}
No método dropFPMSession (), interrompemos a conexão com o cliente, dando uma resposta de 200, após o qual podemos executar qualquer lógica pesada no pós-processamento. O cliente em nosso caso é o consumidor de controle. É importante que ele espalhe rapidamente as tarefas da fila de controle para o processamento na API e saiba que a tarefa atingiu a API.Usando essa abordagem, tiramos muitas dores de cabeça associadas ao controle dinâmico dos consumidores e ao seu dimensionamento automático.Escalável ainda
Como resultado, a arquitetura do nosso subsistema começou a consistir em três camadas: camada de dados, processos e API interna. Ao mesmo tempo, as informações passam por todos os fluxos de dados sobre os quais o evento / tarefa processado pertence. Obviamente, podemos usar nosso identificador de chave / bot para fragmentar, enquanto continuamos a dimensionar nosso sistema horizontalmente.Se imaginarmos nossa arquitetura como uma única unidade, ela terá a seguinte aparência: tendo aumentado o número de tais unidades, podemos colocar um balaser fino na frente deles, que lançará nossos eventos / tarefas nas unidades necessárias, dependendo da chave de fragmentação.
tendo aumentado o número de tais unidades, podemos colocar um balaser fino na frente deles, que lançará nossos eventos / tarefas nas unidades necessárias, dependendo da chave de fragmentação. Assim, obtemos uma grande margem para o dimensionamento horizontal do nosso sistema.Ao implementar a lógica de negócios, você não deve esquecer o conceito de segurança do encadeamento; caso contrário, poderá obter resultados inesperados.Esse esquema com cascatas de filas e a remoção de lógica comercial pesada para processamento assíncrono tem sido usado em várias partes do sistema há mais de dois anos. A carga durante esse período para cada um dos subsistemas cresceu dezenas de vezes, e a implementação proposta nos permite escalar com facilidade e rapidez. Ao mesmo tempo, continuamos a trabalhar em nossa pilha principal, sem expandi-la com novas ferramentas / linguagens e sem aumentar, sobrecarregando assim a introdução e o suporte de novas ferramentas.
Assim, obtemos uma grande margem para o dimensionamento horizontal do nosso sistema.Ao implementar a lógica de negócios, você não deve esquecer o conceito de segurança do encadeamento; caso contrário, poderá obter resultados inesperados.Esse esquema com cascatas de filas e a remoção de lógica comercial pesada para processamento assíncrono tem sido usado em várias partes do sistema há mais de dois anos. A carga durante esse período para cada um dos subsistemas cresceu dezenas de vezes, e a implementação proposta nos permite escalar com facilidade e rapidez. Ao mesmo tempo, continuamos a trabalhar em nossa pilha principal, sem expandi-la com novas ferramentas / linguagens e sem aumentar, sobrecarregando assim a introdução e o suporte de novas ferramentas.