Alguns meses atrás, anunciamos o explan.tensor.ru , um serviço público para analisar e visualizar os planos de consulta do PostgreSQL.Nos últimos tempos, você já o usou mais de 6.000 vezes, mas uma das funções convenientes pode passar despercebida - essas são dicas estruturais que se parecem com isso: Ouça-as e seus pedidos “ficarão suaves e sedosos”. :)Mas, falando sério, muitas das situações que tornam a solicitação lenta e "gulosa" em termos de recursos são típicas e podem ser reconhecidas pela estrutura e pelos dados do plano .Nesse caso, cada desenvolvedor individual não precisará procurar uma opção de otimização por conta própria, contando apenas com sua experiência - podemos dizer a ele o que está acontecendo aqui, qual poderia ser o motivo e como abordar a solução . O que nós fizemos.
Ouça-as e seus pedidos “ficarão suaves e sedosos”. :)Mas, falando sério, muitas das situações que tornam a solicitação lenta e "gulosa" em termos de recursos são típicas e podem ser reconhecidas pela estrutura e pelos dados do plano .Nesse caso, cada desenvolvedor individual não precisará procurar uma opção de otimização por conta própria, contando apenas com sua experiência - podemos dizer a ele o que está acontecendo aqui, qual poderia ser o motivo e como abordar a solução . O que nós fizemos. Vamos dar uma olhada mais de perto nesses casos - como eles são determinados e a quais recomendações eles levam.Para uma melhor compreensão do tópico, você pode primeiro ouvir o bloco correspondente do meu relatório sobre o PGConf.Russia 2020 e só então prosseguir para uma análise detalhada de cada exemplo:
Vamos dar uma olhada mais de perto nesses casos - como eles são determinados e a quais recomendações eles levam.Para uma melhor compreensão do tópico, você pode primeiro ouvir o bloco correspondente do meu relatório sobre o PGConf.Russia 2020 e só então prosseguir para uma análise detalhada de cada exemplo:# 1: índice "undersorting"
Quando surge
Mostrar a última fatura do cliente "LLC Bell".Como reconhecer
-> Limit
-> Sort
-> Index [Only] Scan [Backward] | Bitmap Heap Scan
Recomendações
Use o índice usado para classificar os campos .Exemplo:CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk
, (random() * 1000)::integer fk_cli;
CREATE INDEX ON tbl(fk_cli);
SELECT
*
FROM
tbl
WHERE
fk_cli = 1
ORDER BY
pk DESC
LIMIT 1;
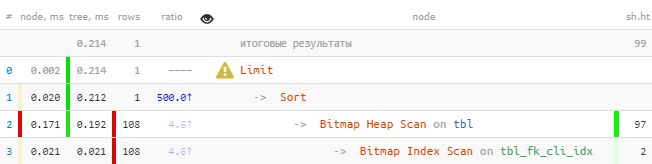 [veja explan.tensor.ru] Vocêpode perceber imediatamente que o índice subtraiu mais de 100 entradas, que foram classificadas e a única que restou.Nós consertamos:
[veja explan.tensor.ru] Vocêpode perceber imediatamente que o índice subtraiu mais de 100 entradas, que foram classificadas e a única que restou.Nós consertamos:DROP INDEX tbl_fk_cli_idx;
CREATE INDEX ON tbl(fk_cli, pk DESC);
 [veja explan.tensor.ru]Mesmo com uma amostra tão primitiva - 8,5 vezes mais rápido e 33 vezes menos leituras . O efeito será mais visível quanto mais "fatos" você tiver para cada valor
[veja explan.tensor.ru]Mesmo com uma amostra tão primitiva - 8,5 vezes mais rápido e 33 vezes menos leituras . O efeito será mais visível quanto mais "fatos" você tiver para cada valor fk.Observo que esse índice funcionará como "prefixo" não pior que o anterior para outras consultas com fk, onde pknão houve classificação e nenhuma classificação (mais sobre isso pode ser encontrado no meu artigo sobre como encontrar índices ineficientes ). Em particular, ele fornecerá suporte normal para uma chave estrangeira explícita nesse campo.# 2: interseção de índice (BitmapAnd)
Quando surge
Mostre todos os contratos para o cliente LLC Kolokolchik concluído em nome do NAO Buttercup.Como reconhecer
-> BitmapAnd
-> Bitmap Index Scan
-> Bitmap Index Scan
Recomendações
Crie um índice composto para os campos da origem ou expanda um dos campos existentes a partir do segundo.Exemplo:CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk
, (random() * 100)::integer fk_org
, (random() * 1000)::integer fk_cli;
CREATE INDEX ON tbl(fk_org);
CREATE INDEX ON tbl(fk_cli);
SELECT
*
FROM
tbl
WHERE
(fk_org, fk_cli) = (1, 999);
 [veja explan.tensor.ru]Correto:
[veja explan.tensor.ru]Correto:DROP INDEX tbl_fk_org_idx;
CREATE INDEX ON tbl(fk_org, fk_cli);
 [olhada explain.tensor.ru]Aqui o ganho é menor, porque Bitmap Heap Scan é bastante eficaz em si. Mas ainda é 7 vezes mais rápido e 2,5 vezes menos leituras .
[olhada explain.tensor.ru]Aqui o ganho é menor, porque Bitmap Heap Scan é bastante eficaz em si. Mas ainda é 7 vezes mais rápido e 2,5 vezes menos leituras .# 3: pool de índices (BitmapOr)
Quando surge
Mostre os 20 primeiros aplicativos "próprios" ou não atribuídos mais antigos para processamento e sua prioridade.Como reconhecer
-> BitmapOr
-> Bitmap Index Scan
-> Bitmap Index Scan
Recomendações
Use UNION [ALL] para combinar subconsultas para cada um dos blocos de condições OR.Exemplo:CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk
, CASE
WHEN random() < 1::real/16 THEN NULL
ELSE (random() * 100)::integer
END fk_own;
CREATE INDEX ON tbl(fk_own, pk);
SELECT
*
FROM
tbl
WHERE
fk_own = 1 OR
fk_own IS NULL
ORDER BY
pk
, (fk_own = 1) DESC
LIMIT 20;
 [veja explan.tensor.ru]Correto:
[veja explan.tensor.ru]Correto:(
SELECT
*
FROM
tbl
WHERE
fk_own = 1
ORDER BY
pk
LIMIT 20
)
UNION ALL
(
SELECT
*
FROM
tbl
WHERE
fk_own IS NULL
ORDER BY
pk
LIMIT 20
)
LIMIT 20;
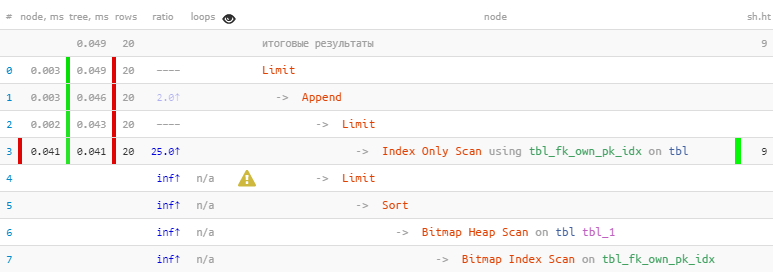 [veja em explan.tensor.ru]Aproveitamos o fato de que todos os 20 registros necessários foram recebidos imediatamente no primeiro bloco; portanto, o segundo, com o Bitmap Heap Scan mais "caro", nem foi executado - como resultado , 22 vezes mais rápido, em 44 vezes menos leituras !
[veja em explan.tensor.ru]Aproveitamos o fato de que todos os 20 registros necessários foram recebidos imediatamente no primeiro bloco; portanto, o segundo, com o Bitmap Heap Scan mais "caro", nem foi executado - como resultado , 22 vezes mais rápido, em 44 vezes menos leituras !Uma história mais detalhada sobre esse método de otimização usando exemplos específicos pode ser encontrada nos artigos dos Antipatterns do PostgreSQL: prejudiciais JOIN e OR e Antipatterns do PostgreSQL: uma história sobre o refinamento iterativo da pesquisa por nome ou “Otimização lá e volta” .
Uma versão generalizada da seleção ordenada por várias chaves (e não apenas pelo par const / NULL) foi considerada no artigo do SQL HowTo: escrevemos o loop while diretamente na consulta, ou “Três vias elementares” .
# 4: leia muitas coisas desnecessárias
Quando surge
Como regra, surge se você deseja "prender outro filtro" a uma solicitação existente."E você não tem o mesmo, mas com botões de pérola ?" filme "Mão de diamante"
Por exemplo, modificando a tarefa acima, mostre os 20 primeiros aplicativos "críticos" mais antigos para processamento, independentemente de sua finalidade.Como reconhecer
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& 5 × rows < RRbF -- >80%
&& loops × RRbF > 100 -- 100
Recomendações
Crie um índice [mais] personalizado com uma cláusula WHERE ou inclua campos adicionais no índice.Se a condição de filtragem for "estática" para suas tarefas - ou seja, não envolverá a expansão da lista de valores no futuro - é melhor usar um índice WHERE. Diferentes status booleanos / enum se encaixam bem nessa categoria.
Se a condição do filtro puder assumir valores diferentes , é melhor expandir o índice com esses campos - como na situação do Bitmap e acima.
Exemplo:CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk
, CASE
WHEN random() < 1::real/16 THEN NULL
ELSE (random() * 100)::integer
END fk_own
, (random() < 1::real/50) critical;
CREATE INDEX ON tbl(pk);
CREATE INDEX ON tbl(fk_own, pk);
SELECT
*
FROM
tbl
WHERE
critical
ORDER BY
pk
LIMIT 20;
 [veja explan.tensor.ru]Correto:
[veja explan.tensor.ru]Correto:CREATE INDEX ON tbl(pk)
WHERE critical;
 [veja explan.tensor.ru]Como você pode ver, a filtragem desapareceu completamente do plano e a solicitação tornou-se 5 vezes mais rápida .
[veja explan.tensor.ru]Como você pode ver, a filtragem desapareceu completamente do plano e a solicitação tornou-se 5 vezes mais rápida .# 5: mesa esparsa
Quando surge
Várias tentativas de criar sua própria fila de tarefas de processamento quando um grande número de atualizações / exclusões de registros na tabela leva a uma situação de um grande número de registros "mortos".Como reconhecer
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& loops × (rows + RRbF) < (shared hit + shared read) × 8
-- 1KB
&& shared hit + shared read > 64
Recomendações
Execute manualmente o VACUUM [CHEIO] manualmente ou realize testes de vácuo automáticos frequentes adequados , ajustando seus parâmetros, inclusive para uma tabela específica .Na maioria dos casos, esses problemas são causados por um layout de consulta ruim ao fazer chamadas da lógica de negócios, como as discutidas nos antipatterns do PostgreSQL: combatendo as hordas de “mortos” .
Mas você precisa entender que mesmo o VACUUM FULL nem sempre pode ajudar. Para esses casos, você deve se familiarizar com o algoritmo do artigo DBA: quando o VACUUM passa, limpamos a tabela manualmente .
# 6: lendo no meio do índice
Quando surge
Parece que eles não leram muito e tudo foi indexado e não filtraram mais ninguém - mas, de qualquer forma, foram lidas significativamente mais páginas do que gostaríamos.Como reconhecer
-> Index [Only] Scan [Backward]
&& loops × (rows + RRbF) < (shared hit + shared read) × 8
-- 1KB
&& shared hit + shared read > 64
Recomendações
Observe atentamente a estrutura do índice usado e os campos-chave especificados na solicitação - provavelmente, parte do índice não está especificada . Provavelmente, você precisará criar um índice semelhante, mas sem campos de prefixo ou aprender a iterar sobre seus valores .Exemplo:CREATE TABLE tbl AS
SELECT
generate_series(1, 100000) pk
, (random() * 100)::integer fk_org
, (random() * 1000)::integer fk_cli;
CREATE INDEX ON tbl(fk_org, fk_cli);
SELECT
*
FROM
tbl
WHERE
fk_cli = 999
LIMIT 20;
 [veja explan.tensor.ru] Tudoparece estar bem, mesmo pelo índice, mas de alguma forma suspeita - para cada um dos 20 registros de leitura que tive que subtrair 4 páginas de dados, 32 KB por registro - não é ousado? Sim, e o nome do índice é sugestivo. Nós consertamos:
[veja explan.tensor.ru] Tudoparece estar bem, mesmo pelo índice, mas de alguma forma suspeita - para cada um dos 20 registros de leitura que tive que subtrair 4 páginas de dados, 32 KB por registro - não é ousado? Sim, e o nome do índice é sugestivo. Nós consertamos:tbl_fk_org_fk_cli_idxCREATE INDEX ON tbl(fk_cli);
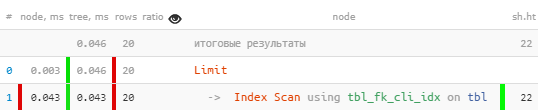 [veja o explic.tensor.ru]De repente - 10 vezes mais rápido e 4 vezes menos lido !
[veja o explic.tensor.ru]De repente - 10 vezes mais rápido e 4 vezes menos lido !Outros exemplos de situações de uso ineficiente de índices podem ser vistos no artigo do DBA: Localizar índices inúteis .
# 7: CTE × CTE
Quando surge
Na consulta, digitamos CTEs "gordos" de diferentes tabelas e decidimos fazer entre eles JOIN.O caso é relevante para versões abaixo da v12 ou solicitações de WITH MATERIALIZED.Como reconhecer
-> CTE Scan
&& loops > 10
&& loops × (rows + RRbF) > 10000
-- CTE
Recomendações
Analise cuidadosamente a solicitação - a CTE é necessária aqui ? Se for o mesmo, aplique “lacrimejamento” no hstore / json, de acordo com o modelo descrito nos Antipatterns do PostgreSQL: entre no dicionário com um forte JOIN .# 8: trocar para disco (temp escrito)
Quando surge
O processamento único (classificação ou exclusividade) de um grande número de registros não cabe na memória alocada para isso.Como reconhecer
-> *
&& temp written > 0
Recomendações
Se a quantidade de memória usada pela operação não exceder muito o valor definido do parâmetro work_mem , vale a pena ajustá-lo. Você pode imediatamente na configuração para todos, mas pode fazer SET [LOCAL]um pedido / transação específica.Exemplo:SHOW work_mem;
SELECT
random()
FROM
generate_series(1, 1000000)
ORDER BY
1;
 [veja explan.tensor.ru]Correto:
[veja explan.tensor.ru]Correto:SET work_mem = '128MB';
 [veja explan.tensor.ru]Por razões óbvias, se apenas a memória for usada, não um disco, a solicitação será executada muito mais rapidamente. Ao mesmo tempo, parte da carga do disco rígido também é removida.Mas você precisa entender que alocar muita memória também nem sempre funciona - não será suficiente para todos.
[veja explan.tensor.ru]Por razões óbvias, se apenas a memória for usada, não um disco, a solicitação será executada muito mais rapidamente. Ao mesmo tempo, parte da carga do disco rígido também é removida.Mas você precisa entender que alocar muita memória também nem sempre funciona - não será suficiente para todos.# 9: estatísticas irrelevantes
Quando surge
Eles derramaram muito ao mesmo tempo no banco de dados, mas não conseguiram afastá-los ANALYZE.Como reconhecer
-> Seq Scan | Bitmap Heap Scan | Index [Only] Scan [Backward]
&& ratio >> 10
Recomendações
Faça o mesmo ANALYZE.Essa situação é descrita em mais detalhes nos Antipatterns do PostgreSQL: as estatísticas estão em toda parte .
# 10: "algo deu errado"
Quando surge
Havia uma expectativa de um bloqueio imposto por uma solicitação concorrente ou não havia recursos suficientes de hardware de CPU / hipervisor.Como reconhecer
-> *
&& (shared hit / 8K) + (shared read / 1K) < time / 1000
-- RAM hit = 64MB/s, HDD read = 8MB/s
&& time > 100ms -- ,
Recomendações
Use um sistema externo para monitorar o servidor quanto a bloqueios ou consumo anormal de recursos. Sobre a nossa versão da organização desse processo para centenas de servidores, já conversamos aqui e aqui .