 Olá, meu nome é Andrey Schukin, ajudo grandes empresas a migrar serviços e sistemas para a CROC Cloud. Juntamente com colegas de Southbridge, que ministram cursos de Kubernetes no centro de treinamento Slerm, recentemente realizamos um webinar para nossos clientes.Decidi pegar os materiais de uma excelente palestra de Pavel Selivanov e escrever um post para aqueles que estão começando a trabalhar com ferramentas de provisionamento em nuvem e não sabem por onde começar. Portanto, falarei sobre a pilha de tecnologias usadas em nosso treinamento e produção do CROC Cloud. Vamos falar sobre abordagens modernas para gerenciamento de infraestrutura, sobre o pacote de componentes Packer, Terraform e Ansible, bem como sobre a ferramenta Kubeadm com a qual executaremos a instalação.Sob o corte, haverá muito texto e configurações. Há muito material, então eu adicionei a navegação pós. Também preparamos um pequeno repositório onde colocamos tudo o que precisamos para nossa implantação de treinamento.Não dê nomes às galinhas.Bolos assados são mais saudáveis que fritos.Começamos o forno. PackerTerraform - infraestrutura como códigoIniciar aestrutura do Terraform Cluster Repositório KubernetesKubeadmcom todos os arquivos
Olá, meu nome é Andrey Schukin, ajudo grandes empresas a migrar serviços e sistemas para a CROC Cloud. Juntamente com colegas de Southbridge, que ministram cursos de Kubernetes no centro de treinamento Slerm, recentemente realizamos um webinar para nossos clientes.Decidi pegar os materiais de uma excelente palestra de Pavel Selivanov e escrever um post para aqueles que estão começando a trabalhar com ferramentas de provisionamento em nuvem e não sabem por onde começar. Portanto, falarei sobre a pilha de tecnologias usadas em nosso treinamento e produção do CROC Cloud. Vamos falar sobre abordagens modernas para gerenciamento de infraestrutura, sobre o pacote de componentes Packer, Terraform e Ansible, bem como sobre a ferramenta Kubeadm com a qual executaremos a instalação.Sob o corte, haverá muito texto e configurações. Há muito material, então eu adicionei a navegação pós. Também preparamos um pequeno repositório onde colocamos tudo o que precisamos para nossa implantação de treinamento.Não dê nomes às galinhas.Bolos assados são mais saudáveis que fritos.Começamos o forno. PackerTerraform - infraestrutura como códigoIniciar aestrutura do Terraform Cluster Repositório KubernetesKubeadmcom todos os arquivosNão dê nomes a galinhas
 Existem muitos conceitos diferentes de gerenciamento de infraestrutura. Um deles é chamado Pets vs. Gado, isto é, "animais de estimação contra animais". Este conceito descreve duas abordagens opostas à infraestrutura.Imagine que temos um cachorro favorito. Nós cuidamos dela, o levamos ao veterinário, penteamos o pêlo e, em geral, é único para nós entre muitos outros cães.Em outro caso, temos um galinheiro. Também cuidamos de galinhas, alimentamos, aquecemos e tentamos criar as condições mais confortáveis. No entanto, as galinhas são um recurso sem rosto para nós, que cumpre sua função de pôr ovos, e, na melhor das hipóteses, as designamos como “aquele preto em pó que sempre bica cimento”. Se a galinha parar de pôr ovos ou quebrar a pata, provavelmente fornecerá um delicioso caldo para o almoço. De fato, não nos importamos com o destino de uma galinha individual, mas com o galinheiro como um todo como uma linha de produção.Na área de TI, uma abordagem semelhante começou a ser aplicada assim que as ferramentas apareceram, reduzindo o limite de entrada para os engenheiros e possibilitando implantar e manter clusters complexos em um modo totalmente automático.Anteriormente, tínhamos um pequeno número de servidores que eram monitorados, ajustados manualmente e tratados de todas as maneiras possíveis. No monitoramento, os logs dos servidores Cthulhu, Aylith e Dagon piscaram. Tradições.Então a virtualização entrou firmemente em nossas vidas, e os nomes das obras de Lovecraft e Star Trek deram lugar ao mais vantajoso "vlg-vlt-vault01.company.ru". Existem muitos servidores, mas ainda aumentamos os serviços mais ou menos manualmente, eliminando os problemas em cada máquina, se necessário.Agora, a abordagem para manter a infraestrutura coincide completamente com a programação. Adicionamos outro nível de abstração e paramos de nos preocupar com nós individuais. Cada um tem um índice sem rosto em vez de um nome e, no caso de um problema, a máquina virtual simplesmente mata e sobe a partir do instantâneo de trabalho. Existem ferramentas que permitem implementar essa abordagem. No nosso caso, a primeira ferramenta é a nuvem CROC, a segunda é a Terraform.
Existem muitos conceitos diferentes de gerenciamento de infraestrutura. Um deles é chamado Pets vs. Gado, isto é, "animais de estimação contra animais". Este conceito descreve duas abordagens opostas à infraestrutura.Imagine que temos um cachorro favorito. Nós cuidamos dela, o levamos ao veterinário, penteamos o pêlo e, em geral, é único para nós entre muitos outros cães.Em outro caso, temos um galinheiro. Também cuidamos de galinhas, alimentamos, aquecemos e tentamos criar as condições mais confortáveis. No entanto, as galinhas são um recurso sem rosto para nós, que cumpre sua função de pôr ovos, e, na melhor das hipóteses, as designamos como “aquele preto em pó que sempre bica cimento”. Se a galinha parar de pôr ovos ou quebrar a pata, provavelmente fornecerá um delicioso caldo para o almoço. De fato, não nos importamos com o destino de uma galinha individual, mas com o galinheiro como um todo como uma linha de produção.Na área de TI, uma abordagem semelhante começou a ser aplicada assim que as ferramentas apareceram, reduzindo o limite de entrada para os engenheiros e possibilitando implantar e manter clusters complexos em um modo totalmente automático.Anteriormente, tínhamos um pequeno número de servidores que eram monitorados, ajustados manualmente e tratados de todas as maneiras possíveis. No monitoramento, os logs dos servidores Cthulhu, Aylith e Dagon piscaram. Tradições.Então a virtualização entrou firmemente em nossas vidas, e os nomes das obras de Lovecraft e Star Trek deram lugar ao mais vantajoso "vlg-vlt-vault01.company.ru". Existem muitos servidores, mas ainda aumentamos os serviços mais ou menos manualmente, eliminando os problemas em cada máquina, se necessário.Agora, a abordagem para manter a infraestrutura coincide completamente com a programação. Adicionamos outro nível de abstração e paramos de nos preocupar com nós individuais. Cada um tem um índice sem rosto em vez de um nome e, no caso de um problema, a máquina virtual simplesmente mata e sobe a partir do instantâneo de trabalho. Existem ferramentas que permitem implementar essa abordagem. No nosso caso, a primeira ferramenta é a nuvem CROC, a segunda é a Terraform.Bolos assados são mais saudáveis que fritos
 No gerenciamento de infraestrutura, há um contraste entre as duas abordagens Fried vs. Assado, ou seja, "frito contra assado".A abordagem Fried implica que você tem uma imagem do SO baunilha, por exemplo, CentOS 7. Depois de implantar o SO, usamos o sistema de gerenciamento de configuração para trazer o sistema ao estado de destino. Por exemplo, usando Ansible, Chef, Puppet ou SaltStack.Tudo funciona bem, especialmente quando não há muitos servidores. Quando há necessidade de uma implantação maciça, nos deparamos com problemas de desempenho. Centenas de servidores começam a consumir sincronicamente recursos de rede, CPU, RAM e IOPS no processo de lançamento de muitos pacotes novos. Além disso, esse processo pode ser adiado por um longo tempo. Em resumo, o circuito é absolutamente operacional, mas não tão interessante do ponto de vista de minimizar o tempo de inatividade durante acidentes.A abordagem Baked implica que você possui imagens de SO prontas em que já instalou todos os pacotes necessários, configurou a configuração e tudo mais. Na saída, temos um modelo de instantâneo abstrato, aprimorado para o desempenho de alguma função. A implantação da infraestrutura a partir dessas imagens processadas leva muito menos tempo e reduz ao mínimo o tempo de inatividade. Uma ideologia muito semelhante é usada nas imagens Docker de várias camadas, nas quais ninguém aperta as mãos desnecessariamente. Pregou o recipiente - pegou um novo.
No gerenciamento de infraestrutura, há um contraste entre as duas abordagens Fried vs. Assado, ou seja, "frito contra assado".A abordagem Fried implica que você tem uma imagem do SO baunilha, por exemplo, CentOS 7. Depois de implantar o SO, usamos o sistema de gerenciamento de configuração para trazer o sistema ao estado de destino. Por exemplo, usando Ansible, Chef, Puppet ou SaltStack.Tudo funciona bem, especialmente quando não há muitos servidores. Quando há necessidade de uma implantação maciça, nos deparamos com problemas de desempenho. Centenas de servidores começam a consumir sincronicamente recursos de rede, CPU, RAM e IOPS no processo de lançamento de muitos pacotes novos. Além disso, esse processo pode ser adiado por um longo tempo. Em resumo, o circuito é absolutamente operacional, mas não tão interessante do ponto de vista de minimizar o tempo de inatividade durante acidentes.A abordagem Baked implica que você possui imagens de SO prontas em que já instalou todos os pacotes necessários, configurou a configuração e tudo mais. Na saída, temos um modelo de instantâneo abstrato, aprimorado para o desempenho de alguma função. A implantação da infraestrutura a partir dessas imagens processadas leva muito menos tempo e reduz ao mínimo o tempo de inatividade. Uma ideologia muito semelhante é usada nas imagens Docker de várias camadas, nas quais ninguém aperta as mãos desnecessariamente. Pregou o recipiente - pegou um novo.Começamos o forno. Packer
 Em nossa infraestrutura, usamos vários produtos Hashicorp, alguns dos quais se mostraram extremamente bem-sucedidos. Vamos começar nossa mágica com a preparação e o cozimento de uma imagem usando a ferramenta Packer.O Packer usa um modelo JSON, ou seja, arquivos de modelo que contêm uma descrição do que precisa ser obtido como uma máquina virtual "VM". Após criar o modelo, o arquivo é transferido para o Packer e as permissões necessárias para criar o servidor na nuvem são configuradas.O Packer permite que você crie VMs localmente no KVM, VirtualBox, Vagrant, AWS, GCP, Alibaba Cloud, OpenStack etc. É conveniente trabalhar com o Packer na CROC Cloud, pois implementa interfaces da AWS, ou seja, todas as ferramentas criadas para AWS, trabalhe com a CROC Cloud.Após definir os modelos necessários, o Packer eleva o VM CROC na nuvem, aguarda o início e, em seguida, o "provedor" entra no fornecedor de trabalho: um utilitário que deve concluir a preparação da imagem. No nosso caso, isso é Ansible, embora o Packer possa trabalhar com outras opções.Quando a VM está pronta, o Packer cria sua imagem e a coloca na nuvem CROC para que outras VMs possam ser iniciadas a partir da mesma imagem.
Em nossa infraestrutura, usamos vários produtos Hashicorp, alguns dos quais se mostraram extremamente bem-sucedidos. Vamos começar nossa mágica com a preparação e o cozimento de uma imagem usando a ferramenta Packer.O Packer usa um modelo JSON, ou seja, arquivos de modelo que contêm uma descrição do que precisa ser obtido como uma máquina virtual "VM". Após criar o modelo, o arquivo é transferido para o Packer e as permissões necessárias para criar o servidor na nuvem são configuradas.O Packer permite que você crie VMs localmente no KVM, VirtualBox, Vagrant, AWS, GCP, Alibaba Cloud, OpenStack etc. É conveniente trabalhar com o Packer na CROC Cloud, pois implementa interfaces da AWS, ou seja, todas as ferramentas criadas para AWS, trabalhe com a CROC Cloud.Após definir os modelos necessários, o Packer eleva o VM CROC na nuvem, aguarda o início e, em seguida, o "provedor" entra no fornecedor de trabalho: um utilitário que deve concluir a preparação da imagem. No nosso caso, isso é Ansible, embora o Packer possa trabalhar com outras opções.Quando a VM está pronta, o Packer cria sua imagem e a coloca na nuvem CROC para que outras VMs possam ser iniciadas a partir da mesma imagem.Estrutura Base.json
No início do arquivo, há uma seção na qual as variáveis são declaradas:Spoiler"variables" : {
"source_ami_name": "{{env SOURCE_AMI_NAME}}",
"ami_name": "{{env AMI_NAME}}",
"instance_type": "{{env INSTANCE_TYPE}}",
"kubernetes_version": "{{env KUBERNETES_VERSION}}",
"docker_version": "{{env DOCKER_VERSION}}",
"subnet_id": "",
"availability_zone": "",
},
O conjunto principal dessas variáveis será definido no arquivo settings.json. E aquelas variáveis que mudam com frequência são mais convenientes de serem definidas no console ao iniciar o Packer e criar uma nova imagem.A seguir está a seção Construtores:Spoiler"builders" : [
{
"type": "amazon-ebs",
"region": "croc",
"skip_region_validation": true,
"custom_endpoint_ec2": "https://api.cloud.croc.ru",
"source_ami": "",
"source_ami_filter": {
"filters": {
"name": "{{user `source_ami_name`}}"
"state": "available",
"virtualization-type": "kvm-virtio"
},
...
Nuvens de destino e o método de inicialização da VM são descritos aqui. Observe que, neste caso, o tipo amazon-ebs é declarado, mas para a operação do Packer com a nuvem CROC, o endereço correspondente em custom_endpoint_ec2 é definido. Nossa infraestrutura possui uma API que é quase completamente compatível com o Amazon Web Services; portanto, se você tiver desenvolvimentos prontos para esta plataforma, na maioria das vezes precisará especificar apenas um ponto de entrada da API personalizado - api.cloud.croc.ru em nosso exemplo.Vale a pena notar a seção source_ami_filter separadamente. Aqui é definida a imagem inicial da VM, na qual as alterações necessárias serão feitas. No entanto, o Packer requer uma AMI para esta imagem, ou seja, seu identificador aleatório. Como esse identificador raramente é conhecido com antecedência e muda a cada atualização, a AMI de origem é definida não como um valor específico, mas como uma variável source_ami_filter. Nesse caso, o parâmetro determinante do filtro é o nome da imagem. Este nome é definido nas variáveis através do arquivo settings.json.Em seguida, as configurações da VM são definidas: o tipo de instância, processador, tamanho da memória, espaço alocado etc. são especificados:Spoiler"instance_type": "{{user `instance_type`}}",
"launch_block_device_mappings": [
{
"device_name": "disk1",
"volume_type": "io1",
"volume_size": "8",
"iops": "1000",
"delete_on_termination": "true"
}
],
A seguir, em base.json estão os parâmetros para conectar-se a esta VM:Spoiler"availability_zone": "{{user `availability_zone`}}",
"subnet_id": "{{user `subnet_id`}}",
"associate_public_ip_address": true,
"ssh_username": "ec2-user",
"ami_name": "{{user `ami_name`}}"
É importante observar o parâmetro subnet_id aqui. Ele deve ser definido manualmente, porque sem especificar a sub-rede da VM na nuvem CROC, é impossível criar.Outro parâmetro que requer preparação prévia é o endereço_public_ip_administrativo. Você precisa selecionar um endereço IP branco, porque depois de criar o VM Packer começará a aplicar as configurações necessárias através do Ansible. Nesse caso, o Ansible se conecta à VM via SSH, o que requer um endereço IP ou VPN branco.A última seção é dos Provisioners:Spoiler"provisioners": [
{
"type": "ansible",
"playbook_file": "playbook.yml",
"extra_arguments": [
"--extra-vars",
"kubernetes_version={{user `kubernetes_version`}}",
"--extra-vars",
"docker_version={{user `docker_version`}}"
]
}
]
Esses são os provedores, ou seja, os utilitários com os quais o Packer configura o servidor. Nesse caso, o provedor do tipo ansible é usado. A seguir, é apresentado o parâmetro playbook_file, que define as funções Ansible e os hosts nos quais as funções especificadas serão aplicadas. Opções adicionais extra_arguments são apresentadas abaixo, as quais, ao iniciar o Ansible, transmitem versões do Kubernetes e Docker.Preparação para a nuvem CROC
 Além dos nossos arquivos de configuração, precisamos fazer algumas coisas na lateral do painel de controle da nuvem para que toda a mágica funcione. Precisamos selecionar um IP branco e criar uma sub-rede funcional, que usaremos ao implantar.
Além dos nossos arquivos de configuração, precisamos fazer algumas coisas na lateral do painel de controle da nuvem para que toda a mágica funcione. Precisamos selecionar um IP branco e criar uma sub-rede funcional, que usaremos ao implantar.- Clique em Realçar endereço. O Packer encontrará o endereço IP branco desejado por conta própria.
- Clique em Criar sub-rede e especifique uma sub-rede e uma máscara.
- Copie o ID da sub-rede.
- Insira esse valor no parâmetro subnet_id do comando de inicialização do Packer.
 Em seguida, execute o Packer. Ele encontra a imagem original da VM, a implanta na nuvem CROC e executa a função Ansible nela. A nova VM pode ser vista na nuvem CROC na seção "Instâncias".
Em seguida, execute o Packer. Ele encontra a imagem original da VM, a implanta na nuvem CROC e executa a função Ansible nela. A nova VM pode ser vista na nuvem CROC na seção "Instâncias".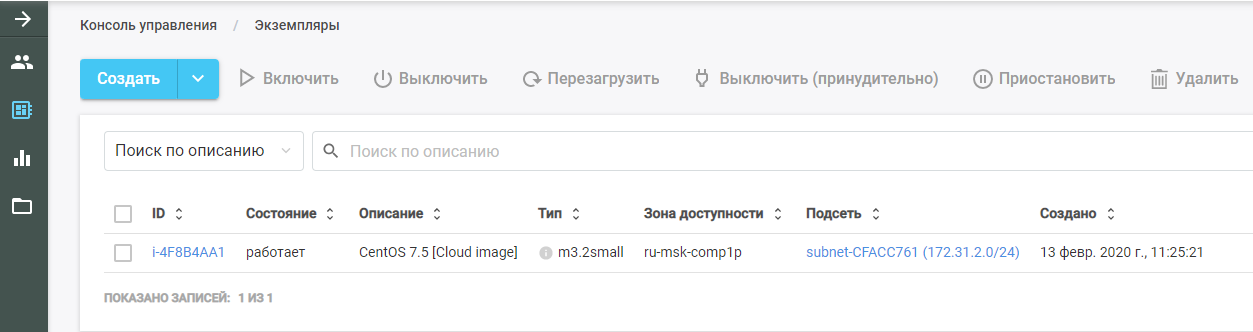
 Após concluir o trabalho, o Packer remove a VM da nuvem e deixa uma imagem pronta em seu lugar, que pode ser encontrada na seção "Modelos". Toda a infraestrutura do Kubernetes será criada a partir desta imagem.
Após concluir o trabalho, o Packer remove a VM da nuvem e deixa uma imagem pronta em seu lugar, que pode ser encontrada na seção "Modelos". Toda a infraestrutura do Kubernetes será criada a partir desta imagem.Ansible
Como mencionado anteriormente, o parâmetro playbook é passado nos parâmetros do provedor Ansible. O arquivo playbook.yml se parece com o seguinte:- hosts: all
become: true
roles:
| - base
O arquivo é transferido para o Ansible que em todos os hosts é necessário cumprir a função de base. Se houver outras funções, você poderá adicioná-las ao mesmo arquivo que uma lista.A função base permite que você obtenha um cluster pronto com um único comando. O arquivo main.yml mostra o que exatamente essa função faz:- Adiciona um repositório do Docker ao modelo do sistema.
- Adiciona o repositório Kubernetes ao modelo do sistema.
- Instala os pacotes necessários.
- Cria um diretório para configurar o daemon do Docker.
- Configura a máquina de acordo com o arquivo de configuração daemon.json.j2.
- Carrega o kernel br_netfilter.
- Inclui as opções necessárias para br_netfilter.
- Inclui componentes Docker e Kubelet.
- Executa o Docker na VM.
- Executa um comando que baixa as imagens do Docker necessárias para o Kubernetes funcionar.
Nesse caso, os pacotes instalados são configurados no arquivo main.yml no diretório vars. No nosso caso, instalamos o pacote docker-ce, bem como os três pacotes necessários para o Kubernetes funcionar: kubelet, kubeadm e kubectl.Terraform - infraestrutura como código
 Terraform é uma ferramenta muito funcional da HashiCorp para orquestração de nuvens. Ele possui seu próprio idioma HCL específico, que é frequentemente usado em outros produtos da empresa, por exemplo, no HashiCorp Vault e Consul.O princípio básico é semelhante a todos os sistemas de gerenciamento de configuração. Você simplesmente indica o estado de destino no formato desejado e o sistema calcula o algoritmo de como conseguir isso. Outra coisa é que, ao contrário do mesmo Ansible, que funciona como uma caixa preta em playbooks complexos, o Terraform pode fornecer um plano de ações futuras de uma forma conveniente para análise. Isso é importante ao planejar alterações complexas na infraestrutura. Após planejar as ações necessárias, execute o comando terraform apply e o Terraform implementará a infraestrutura descrita nos arquivos.Como o Packer, essa ferramenta oferece suporte à AWS, GCP, Alibaba Cloud, Azure, OpenStack, VMware, etc.
Terraform é uma ferramenta muito funcional da HashiCorp para orquestração de nuvens. Ele possui seu próprio idioma HCL específico, que é frequentemente usado em outros produtos da empresa, por exemplo, no HashiCorp Vault e Consul.O princípio básico é semelhante a todos os sistemas de gerenciamento de configuração. Você simplesmente indica o estado de destino no formato desejado e o sistema calcula o algoritmo de como conseguir isso. Outra coisa é que, ao contrário do mesmo Ansible, que funciona como uma caixa preta em playbooks complexos, o Terraform pode fornecer um plano de ações futuras de uma forma conveniente para análise. Isso é importante ao planejar alterações complexas na infraestrutura. Após planejar as ações necessárias, execute o comando terraform apply e o Terraform implementará a infraestrutura descrita nos arquivos.Como o Packer, essa ferramenta oferece suporte à AWS, GCP, Alibaba Cloud, Azure, OpenStack, VMware, etc.Nós descrevemos o projeto
O diretório Terraform possui um conjunto de arquivos com a extensão .tf. Esses arquivos descrevem os componentes da infraestrutura com a qual trabalharemos. Divida o projeto em módulos funcionais. Essa estrutura facilita o controle de versão e a montagem de cada projeto a partir de blocos práticos prontos. Para nossa opção, a seguinte estrutura é adequada:- main.tf
- network.tf
- security_groups.tf
- master.tf
- master.tpl
Estrutura do arquivo Main.tf
Vamos começar com o arquivo main.tf, no qual o acesso à nuvem está configurado. Em particular, são anunciados vários parâmetros que configuram o Terraform para funcionar com a nuvem CROC:provider "aws" {
endpoints {
ec2 = "https://api.cloud.croc.ru"
}
Além disso, o arquivo descreve que o Terraform deve criar independentemente uma chave privada e fazer upload de sua parte pública para todos os servidores. A própria chave privada é emitida no final do Terraform:resource "tls_private_key" "ssh" {
algorithm = "RSA"
}
resource "aws_key_pair" "kube" {
key_name = "terraform"
public_key = "${tls_private_key.ssh.public_key_openssh}"
}
output "ssh" {
value = "${tls_private_key.ssh.private_key_pem}"
}
A estrutura do arquivo network.tf
Este arquivo descreve os componentes de rede necessários para iniciar a VM:Spoilerdata "aws_availability_zones" "az" {
state = "available"
}
resource "aws_vpc" "kube" {
cidr_block = "${var.vpc_cidr}"
}
resource "aws_eip" "master" {
count = "1"
vpc = true
}
resource "aws_subnet" "private" {
vpc_id = "${aws_vpc.kube.id}"
count = "${length(data.aws_availability_zones.az.names)}"
cidr_block = "${var.private_subnet_cidr_list[count.index]}"
availability_zone = "${data.aws_availability_zones.az.names[count.index]}"
}
O Terraform usa dois tipos de componentes:- recurso - o que precisa ser criado;
- dados - o que você precisa obter.
Nesse caso, o parâmetro data indica que o Terraform deve receber as zonas de disponibilidade da nuvem especificada, que estão no estado disponível.O primeiro recurso de parâmetro descreve a criação de uma nuvem privada virtual e o próximo parâmetro descreve a criação de Endereço IP Elástico. Para o cluster Kubernetes, solicitamos esse endereço IP através do Terraform.Além disso, em cada uma das zonas de acessibilidade e, no momento, o CROC possui dois serviços em nuvem, sua própria sub-rede é criada. Um recurso do tipo aws_subnet é declarado e o ID do aws_vpc gerado é passado como parte desse parâmetro. Mas, como o ID desse recurso ainda é desconhecido, especificamos o parâmetro aws_vpc.kube.id, que se refere ao recurso criado e substitui o valor do campo ID.Como o número de sub-redes criadas é determinado pelo número de zonas de disponibilidade da nuvem e esse número pode mudar com o tempo, esse parâmetro é definido através da variável length (data.aws_availability_zones.az.names), ou seja, o comprimento da lista de zonas de acesso recebidas por meio do parâmetro data.Os dois últimos parâmetros são cidr_block (a sub-rede alocada) e a zona de disponibilidade na qual essa sub-rede é criada. O último parâmetro também é definido por meio de uma variável que obtém um valor da lista de dados de acordo com o índice do loop declarado por [count.index] .Estrutura do arquivo Security_groups.tf
Grupos de segurança são um tipo de firewall para nuvens, que pode ser criado não dentro da própria VM, mas pela nuvem. Nesse caso, o firewall descreve duas regras.A primeira regra cria um grupo de segurança chamado kube. Esse grupo de segurança é necessário para permitir todo o tráfego de saída dos nós do Kubernetes, permitindo que os nós acessem livremente a Internet. O tráfego de entrada para nós Kubernetes das sub-redes dos próprios nós também é permitido. Assim, os nós do Kubernetes podem trabalhar entre si sem restrições.A segunda regra cria o grupo de segurança ssh. Ele permite a conexão SSH de qualquer endereço IP à porta 22 da VM do cluster Kubernetes:Spoilerresource "aws_security_group" "kube" {
vpc_id = "${aws_vpc.kube.id}"
name = "kubernetes"
# Allow all outbound
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
# Allow all internal
ingress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["${var.vpc_cidr}"]
}
}
resource "aws_security_group" "ssh" {
vpc_id = "${aws_vpc.kube.id}"
name = "ssh"
# Allow all inbound
ingress {
from_port = 22
to_port = 22
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
}
Nó mestre. Estrutura de arquivos Master.tf
O arquivo master.tf descreve a criação de vários modelos e instâncias. Em particular, uma instância principal do Kubernetes está sendo criada.A variável ami define a AMI da imagem de origem para a VM. A seguir, descreve o tipo de VM e a sub-rede na qual ela é criada. Ao definir uma sub-rede, um ciclo é novamente usado para criar VMs em cada zona de disponibilidade.Em seguida, os grupos de segurança usados e a chave especificada no arquivo main.tf são declarados. O campo user_data contém a execução de um conjunto de scripts cloud-init, cujos resultados serão implementados na VM:Spoilerresource "aws_instance" "master" {
count = "1"
ami = "${var.kubernetes_ami}"
instance_type = "c3.large"
disable_api_termination = false
instance_initiated_shutdown_behavior = "terminate"
source_dest_check = false
subnet_id = "${aws_subnet.private.*.id[count.index % length(data.aws_availability_zones.az.names)]}"
associate_public_ip_address = true
vpc_security_group_ids = [
"${aws_security_group.ssh.id}",
"${aws_security_group.kube.id}",
]
key_name = "${aws_key_pair.kube.key_name}"
user_data = "${data.template_cloudinit_config.master.rendered}"
monitoring = "true"
}
Nó mestre. Cloud init
O Cloud-init é uma ferramenta que a Canonical está desenvolvendo. Ele permite que você execute automaticamente em uma infraestrutura de nuvem um determinado conjunto de comandos após iniciar uma VM. O Terraform possui mecanismos para se integrar a ele usando modelos .Como é impossível “assar” tudo o que é necessário na VM, após iniciar, dependendo do seu tipo, ele deve ingressar no cluster Kubernetes ou inicializar o cluster Kubernetes. No modelo de arquivo cloud-init chamado master.tpl, várias ações são executadas.1. Os arquivos de configuração do Kubeadm são registrados:#cloud-config
write_files:
- path: etc/kubernetes/kubeadm.conf
owner: root:root
content:
...
2. Um conjunto de comandos é executado:- o endereço IP do assistente é gravado no arquivo de configuração gerado;
- o mestre no cluster Kubernetes é inicializado com o comando kubeadm init;
- no cluster Kubernetes, a rede de sobreposição Calico é instalada com o comando kubectl apply.
runcmd:
- sed -i "s/CONTROL_PLANE_IP/$(curl http://169.254.169.254/latest/meta-data-local-ipv4)/g" /etc/kubernetes/kubeadm.conf
- kubeadm init --config /etc/kubernetes/kubeadm.conf
- mkdir -p $HOME/.kube
- sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
- sudo chown $(id -u):$(id -g) $HOME/.kube/config
- kubectl apply -f https://docs.projectcalico.org/v3.8/manifests/calico.yaml
Depois de executar os comandos ao iniciar a VM, um cluster Kubernetes em funcionamento é obtido de um nó principal. Os nós restantes ingressarão neste nó principal.Nós comuns. node.tf
O arquivo node.tf é semelhante ao arquivo master.tf. Recursos também são criados aqui, que nesse caso são chamados de nó. A única diferença é que o nó principal é criado em uma única instância e o número de nós em funcionamento criados é definido através da variável nodes_count:resource "aws_instance" "node" {
count = "${var.nodes_count}"
ami = "${var.kubernetes_ami}"
instance_type = "c3.large"
O arquivo cloud-init para nós de trabalho executa apenas um comando - kubeadm join. Este comando anexa a máquina finalizada ao cluster Kubernetes usando o token de autorização que enviamos.Lançamento Terraform
Quando lançado, o Terraform usa vários módulos:- Módulo AWS
- módulo de modelo;
- Módulo TLS responsável pela geração de chaves.
Estes módulos devem ser instalados na máquina local:terraform init terraform/
Juntamente com este comando, é indicado o diretório em que todos os arquivos necessários estão localizados. Ao inicializar, o Terraform baixa todos os módulos especificados, após o qual você precisa executar o comando plano de terraform:terraform plan -var-file terraform/vars/dev.tfvars terraform/
Observe que, além do diretório com os arquivos do Terraform, é indicado o arquivo var, que contém os valores das variáveis usadas nos arquivos do Terraform. O diretório vars pode conter vários arquivos .tfvars, o que permite gerenciar diferentes tipos de infra-estruturas com um conjunto de arquivos Terraform.O próprio arquivo dev.tfvars contém as seguintes variáveis importantes:- Kubernetes_version (versão instalável do Kubernetes);
- Kubernetes_ami (imagem AMI criada pelo Packer).
Após definir os valores necessários das variáveis, execute o comando do plano de terraform, após o qual o Terraform apresentará uma lista de ações necessárias para atingir o estado descrito nos arquivos do Terraform.Após verificar esta lista, aplique as alterações propostas:terraform apply -auto-approve -var-file terraform/vars/dev.tfvars terraform/No comando do plano de terraform, ele se distingue pela presença de uma chave - aprovação automática, que elimina a necessidade de confirmar as alterações feitas. Você pode omitir essa chave, mas cada ação precisará ser confirmada manualmente.Estrutura de Cluster Kubernetes
 O cluster Kubernetes consiste em um nó mestre que executa funções de gerenciamento e nós de trabalho que executam aplicativos instalados no cluster.Quatro componentes são instalados no nó principal que garantem a operação deste sistema:
O cluster Kubernetes consiste em um nó mestre que executa funções de gerenciamento e nós de trabalho que executam aplicativos instalados no cluster.Quatro componentes são instalados no nó principal que garantem a operação deste sistema:- ETCD, ou seja, banco de dados Kubernetes
- Servidor API, através do qual armazenamos informações no Kubernetes e obtemos informações dele;
- Controller Manager
- Agendador
Dois componentes adicionais são instalados nos nós de trabalho:- Kube-proxy (responsável por gerar regras de rede no cluster Kubernetes);
- Kubelet (responsável por enviar o comando ao daemon do Docker para executar aplicativos no cluster Kubernetes).
Entre os nós, o plug-in de rede Calico funciona.Diagrama de fluxo de trabalho de cluster
, Kubernetes replicaset.
- API-, ETCD. .
- API- .
- Controller-manager API- , «», .
- Scheduler . ETCD API-.
- Kubelet API- Docker .
- Docker .
- Kubelet API- , .
, Kubernetes , . , , YAML-. , , API-. .
Kubeadm
 O último elemento que vale a pena mencionar é o Kubeadm. A implantação de um novo cluster Kubernetes é sempre um processo minucioso. Em cada estágio, há riscos de erros devido ao fator humano, e muitas tarefas são simplesmente muito rotineiras e longas. Por exemplo, servindo certificados para criptografia TLS entre nós e mantendo-os atualizados. É aqui que os utilitários para automação básica de modelos são úteis. O truque do Kubeadm é que ele é oficialmente certificado para trabalhar com o Kubernetes.Ele permite que você:
O último elemento que vale a pena mencionar é o Kubeadm. A implantação de um novo cluster Kubernetes é sempre um processo minucioso. Em cada estágio, há riscos de erros devido ao fator humano, e muitas tarefas são simplesmente muito rotineiras e longas. Por exemplo, servindo certificados para criptografia TLS entre nós e mantendo-os atualizados. É aqui que os utilitários para automação básica de modelos são úteis. O truque do Kubeadm é que ele é oficialmente certificado para trabalhar com o Kubernetes.Ele permite que você:- Instale, configure e execute todos os principais componentes de cluster
- gerenciar certificados, incluindo rotacioná-los e redigir novos;
- gerenciar versões de componentes de cluster (atualização e downgrade).
Ao mesmo tempo, o Kubeadm não é um sistema completo de gerenciamento de cluster Kubernetes, mas é um tipo de componente básico que permite configurar o Kubernetes no nó no qual o utilitário Kubeadm está sendo executado. Isso significa que é necessário um sistema de orquestração que execute todas as VMs necessárias, configure-as e execute o Kubeadm em todos os nós. É para esses fins que o Terraform é usado.Repositório com todos os arquivos
Aqui , colocamos todos os arquivos e configurações em um único local, para que seja mais conveniente para você. Se você não possui uma nuvem privada em mãos, mas deseja executar todas essas etapas e testar a implantação na prática, escreva-nos para cloud@croc.ru.Forneceremos uma versão demo para testes e aconselharemos sobre todos os problemas.E em breve haverá um novo Slurm , onde você poderá criar seu próprio cluster. O código promocional CROC tem um desconto de 10%.Para quem já trabalha com o Kubernetes, há um curso avançado . O desconto é o mesmo.Colegas, Habraparser quebra a marcação do código. Por favor, pegue a fonte do GitHub no link acima.