O Pandas não precisa de introdução: hoje é a principal ferramenta para analisar dados em Python. Trabalho como especialista em análise de dados e, apesar de usar pandas todos os dias, nunca deixo de me surpreender com a diversidade de funcionalidades desta biblioteca. Neste artigo, quero falar sobre cinco funções pandas pouco conhecidas que aprendi recentemente e que agora uso produtivamente.Para iniciantes: O Pandas é um kit de ferramentas de alto desempenho para análise de dados em Python com estruturas de dados simples e convenientes. O nome deriva do conceito de "dados em painel", um termo econométrico que se refere a dados sobre observações dos mesmos sujeitos em diferentes períodos de tempo.Aqui você pode baixar o Notebook Jupyter com exemplos do artigo.1. Faixas de datas [Faixas de datas]
Geralmente, você precisa especificar períodos ao solicitar dados de uma API ou banco de dados externo. Os pandas não nos deixarão com problemas. Apenas nesses casos, existe a função intervalo_de_dados , que retorna uma matriz de datas aumentada por dias, meses, anos etc.Digamos que precisamos de um período por dia:date_from = "2019-01-01"
date_to = "2019-01-12"
date_range = pd.date_range(date_from, date_to, freq="D")
date_range
 Transformaremos o gerado de
Transformaremos o gerado de date_rangeem pares de datas "de" e "para", que podem ser transferidos para a função correspondente.for i, (date_from, date_to) in enumerate(zip(date_range[:-1], date_range[1:]), 1):
date_from = date_from.date().isoformat()
date_to = date_to.date().isoformat()
print("%d. date_from: %s, date_to: %s" % (i, date_from, date_to))
1. date_from: 2019-01-01, date_to: 2019-01-02
2. date_from: 2019-01-02, date_to: 2019-01-03
3. date_from: 2019-01-03, date_to: 2019-01-04
4. date_from: 2019-01-04, date_to: 2019-01-05
5. date_from: 2019-01-05, date_to: 2019-01-06
6. date_from: 2019-01-06, date_to: 2019-01-07
7. date_from: 2019-01-07, date_to: 2019-01-08
8. date_from: 2019-01-08, date_to: 2019-01-09
9. date_from: 2019-01-09, date_to: 2019-01-10
10. date_from: 2019-01-10, date_to: 2019-01-11
11. date_from: 2019-01-11, date_to: 2019-01-12
2. Mesclar com o indicador de fonte [Mesclar com o indicador]
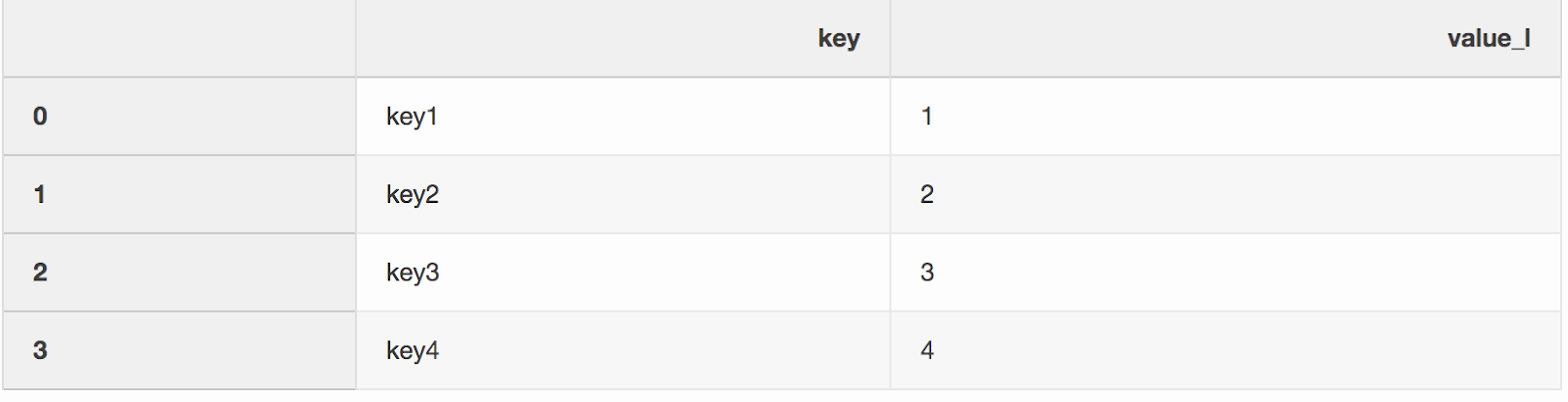
Mesclar dois conjuntos de dados é, curiosamente, o processo de combinar dois conjuntos de dados em um cujas linhas são mapeadas com base em colunas ou propriedades comuns.Um dos dois argumentos para a função de mesclagem, que de alguma forma eu perdi, é indicator. O "Indicador" adiciona uma coluna _mergeao DataFrame que mostra de onde a linha veio, da esquerda, direita ou de ambos os DataFrames. Uma coluna _mergepode ser muito útil ao trabalhar com grandes conjuntos de dados para verificar se a mesclagem está correta.left = pd.DataFrame({"key": ["key1", "key2", "key3", "key4"], "value_l": [1, 2, 3, 4]})
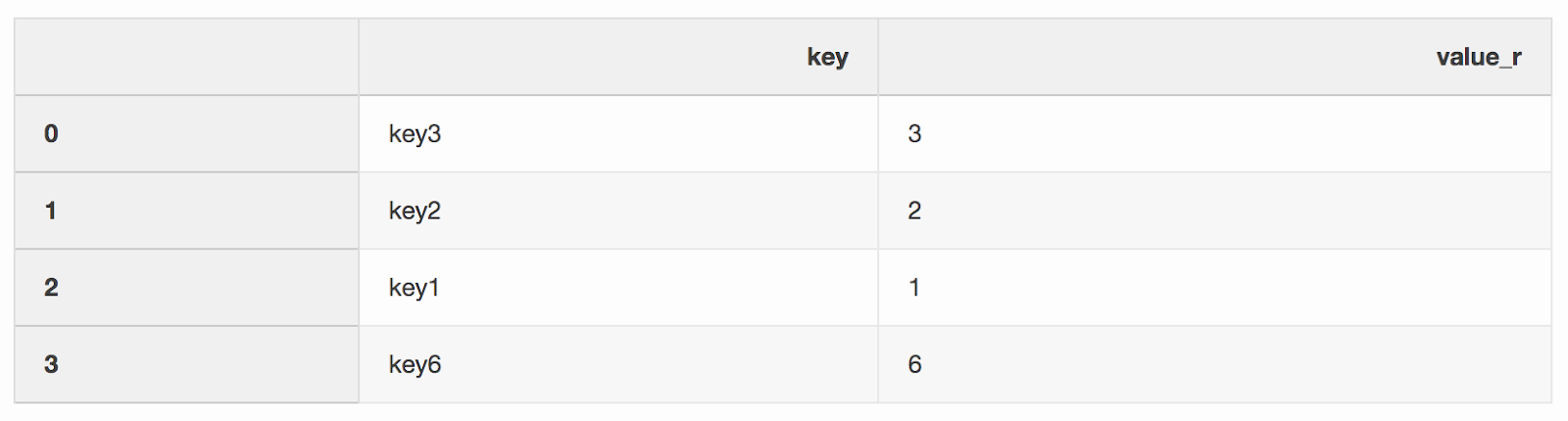
right = pd.DataFrame({"key": ["key3", "key2", "key1", "key6"], "value_r": [3, 2, 1, 6]})
df_merge = left.merge(right, on='key', how='left', indicator=True)
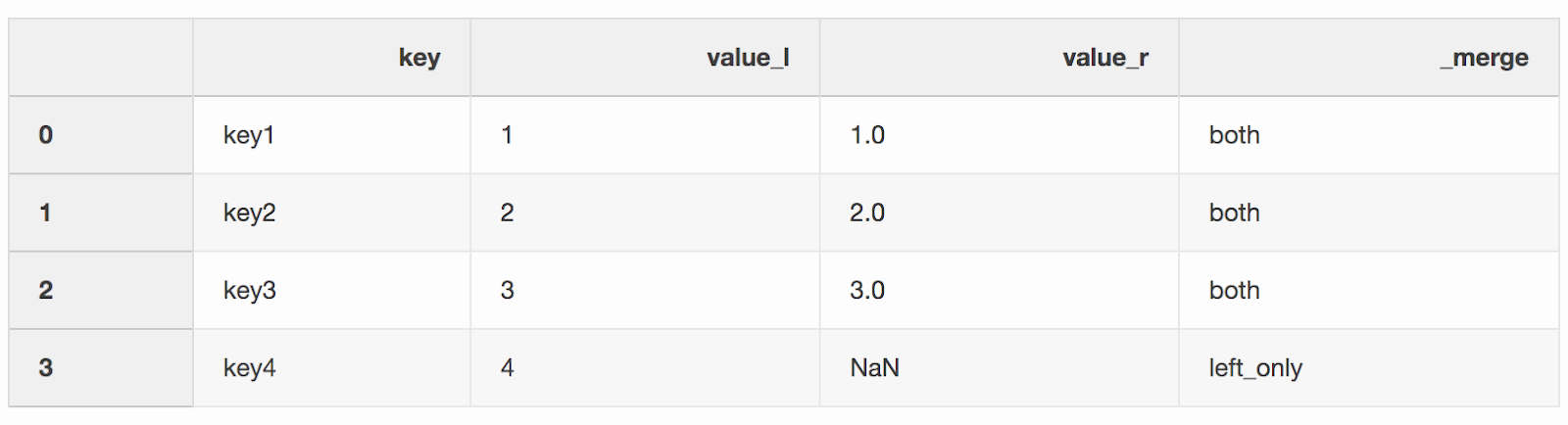 A coluna
A coluna _mergepode ser usada para verificar se o número correto de linhas com dados foi obtido dos dois DataFrames.df_merge._merge.value_counts()
both 3
left_only 1
right_only 0
Name: _merge, dtype: int64
3. Mesclar pelo valor mais próximo [Mesclagem mais próxima]
Ao trabalhar com dados financeiros, como criptomoedas e valores mobiliários, pode ser necessário comparar cotações (alterações de preço) com transações. Digamos que queremos combinar todas as negociações com uma cotação atualizada alguns milissegundos antes da negociação. O Pandas possui uma função merge_asofdevido à qual é possível combinar DataFrames pelo valor da chave mais próximo ( timestampno nosso caso). Conjuntos de dados com cotações e acordos são retirados do exemplo dos pandas .O DataFrame quotes("cotações") contém alterações de preço para diferentes ações. Como regra, há muito mais cotações do que ofertas.quotes = pd.DataFrame(
[
["2016-05-25 13:30:00.023", "GOOG", 720.50, 720.93],
["2016-05-25 13:30:00.023", "MSFT", 51.95, 51.96],
["2016-05-25 13:30:00.030", "MSFT", 51.97, 51.98],
["2016-05-25 13:30:00.041", "MSFT", 51.99, 52.00],
["2016-05-25 13:30:00.048", "GOOG", 720.50, 720.93],
["2016-05-25 13:30:00.049", "AAPL", 97.99, 98.01],
["2016-05-25 13:30:00.072", "GOOG", 720.50, 720.88],
["2016-05-25 13:30:00.075", "MSFT", 52.01, 52.03],
],
columns=["timestamp", "ticker", "bid", "ask"],
)
quotes['timestamp'] = pd.to_datetime(quotes['timestamp'])
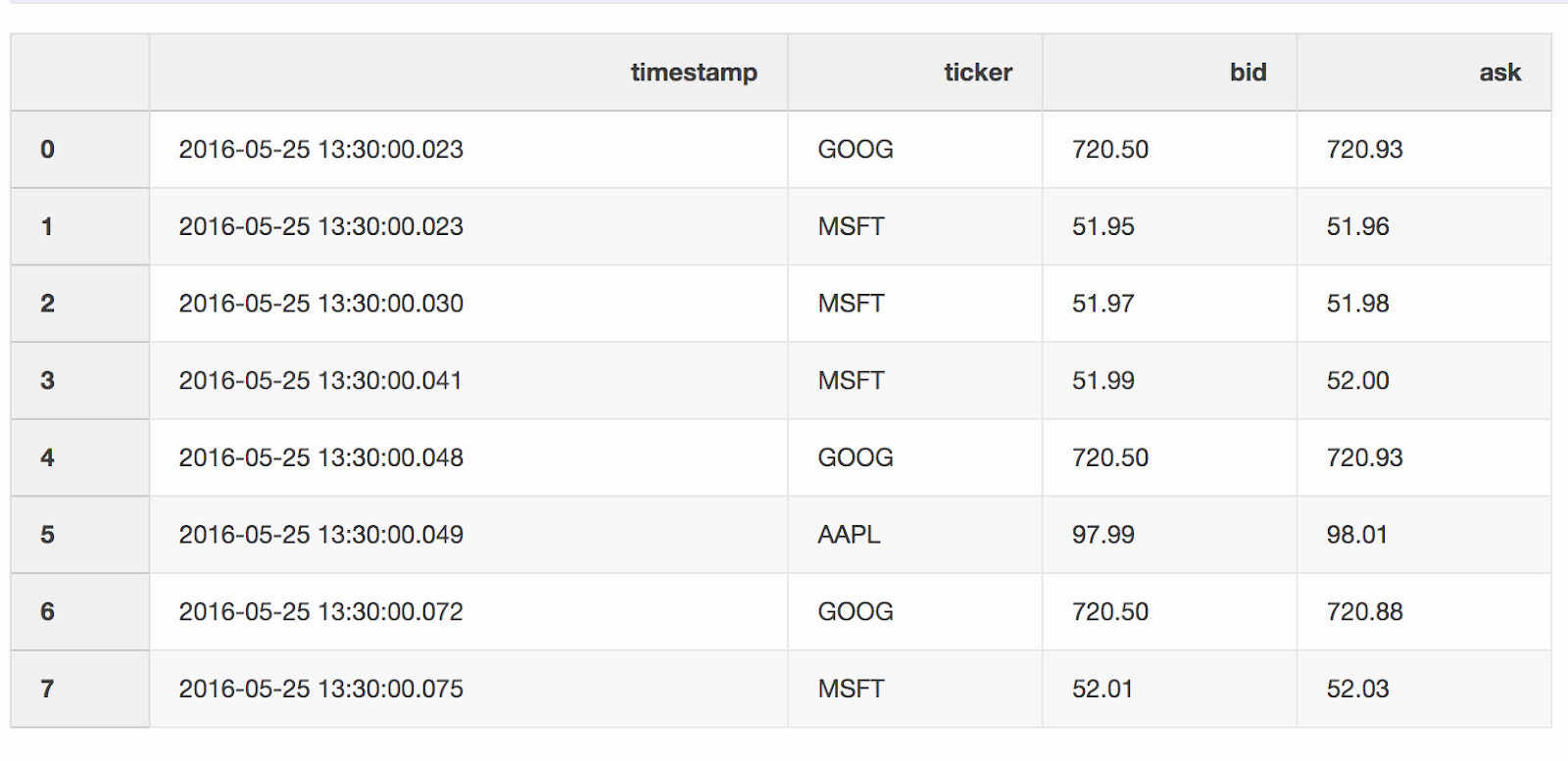 O DataFrame
O DataFrame tradescontém ofertas para diferentes estoques.trades = pd.DataFrame(
[
["2016-05-25 13:30:00.023", "MSFT", 51.95, 75],
["2016-05-25 13:30:00.038", "MSFT", 51.95, 155],
["2016-05-25 13:30:00.048", "GOOG", 720.77, 100],
["2016-05-25 13:30:00.048", "GOOG", 720.92, 100],
["2016-05-25 13:30:00.048", "AAPL", 98.00, 100],
],
columns=["timestamp", "ticker", "price", "quantity"],
)
trades['timestamp'] = pd.to_datetime(trades['timestamp'])
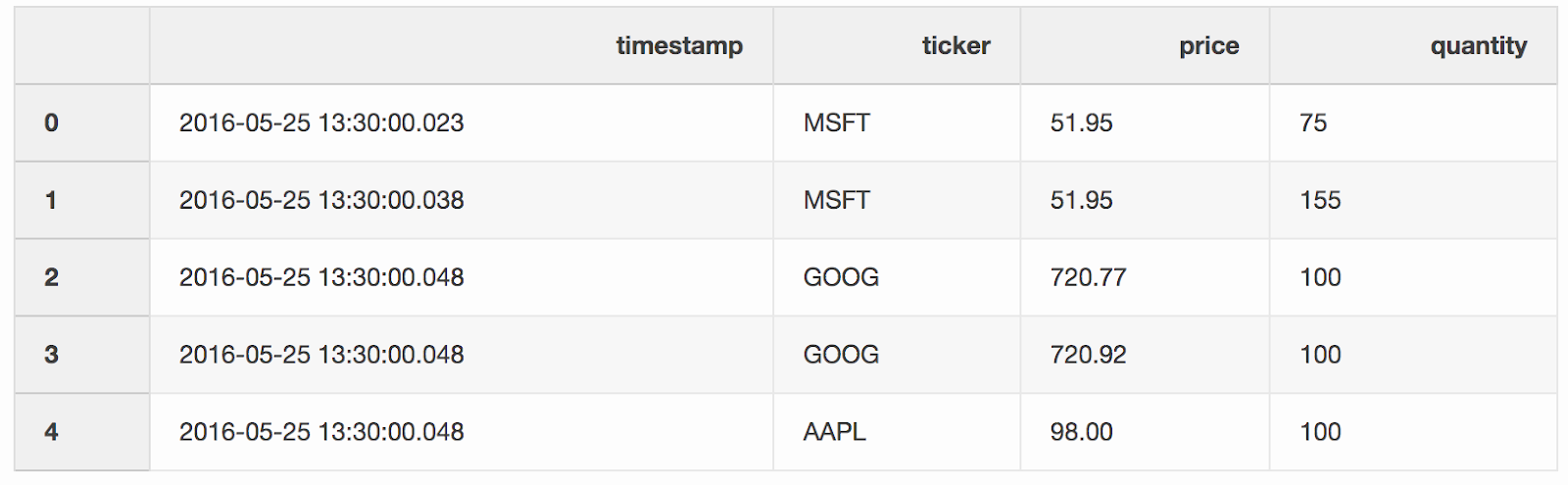 Mesclamos transações e cotações por tickers (um instrumento cotado, como ações), desde que a
Mesclamos transações e cotações por tickers (um instrumento cotado, como ações), desde que a timestampúltima cotação possa ser 10 ms a menos que a transação. Se a cotação aparecer antes da transação por mais de 10 ms, a oferta (o preço que o comprador está pronto para pagar) e a solicitação (o preço pelo qual o vendedor está pronto para vender) para essa cotação será null(cotação da AAPL neste exemplo).pd.merge_asof(trades, quotes, on="timestamp", by='ticker', tolerance=pd.Timedelta('10ms'), direction='backward')

4. Criando um relatório do Excel
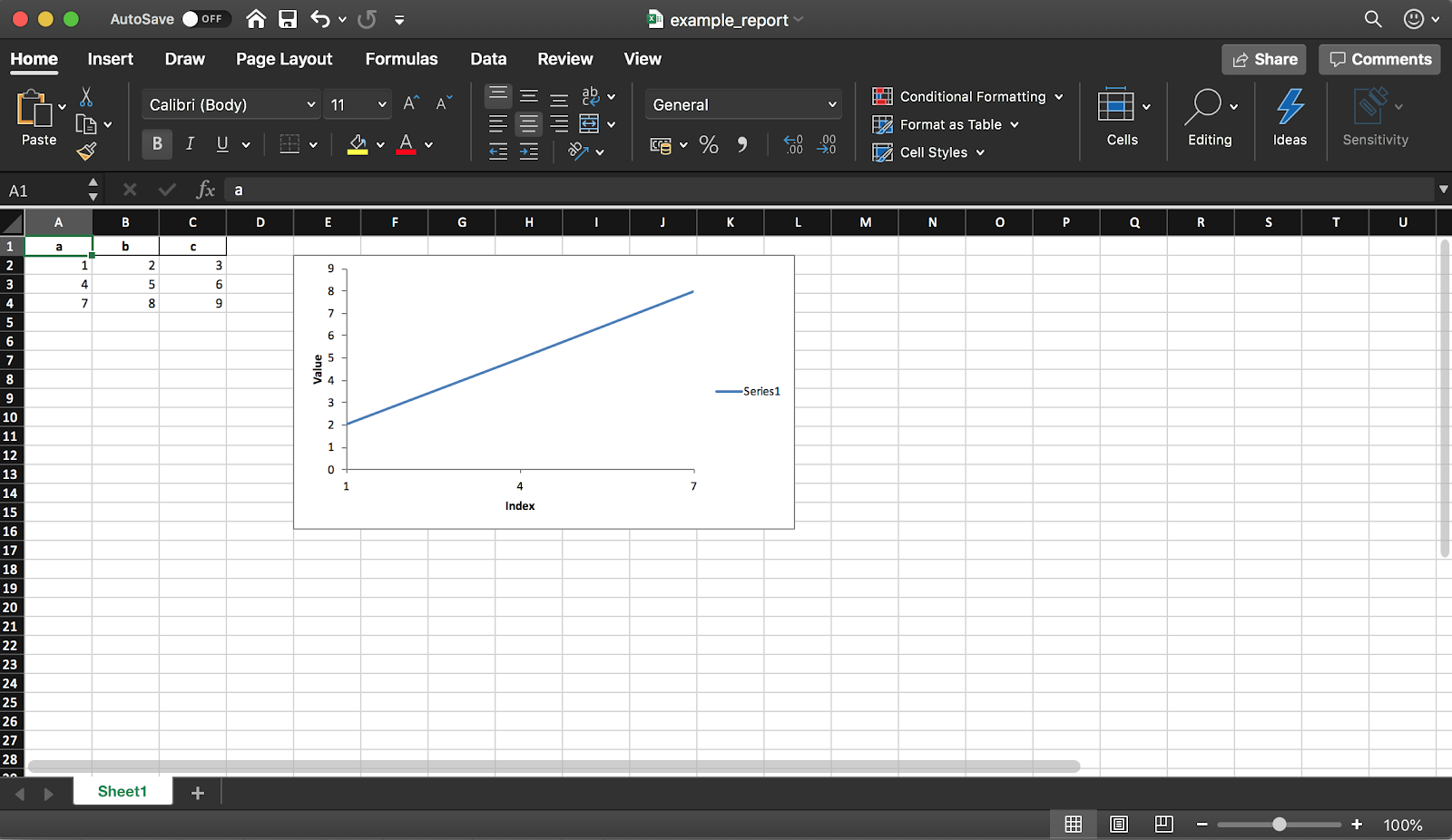 O Pandas (com a biblioteca XlsxWriter) permite criar um relatório do Excel a partir de um DataFrame. Isso economiza muito tempo - não é mais necessário exportar um DataFrame para CSV e formatar manualmente para o Excel. Todos os tipos de diagramas etc. também estão disponíveis .
O Pandas (com a biblioteca XlsxWriter) permite criar um relatório do Excel a partir de um DataFrame. Isso economiza muito tempo - não é mais necessário exportar um DataFrame para CSV e formatar manualmente para o Excel. Todos os tipos de diagramas etc. também estão disponíveis .df = pd.DataFrame(pd.np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]), columns=["a", "b", "c"])
O trecho de código abaixo cria uma tabela no formato Excel. Descomente a linha para salvá-la em um arquivo writer.save().report_name = 'example_report.xlsx'
sheet_name = 'Sheet1'
writer = pd.ExcelWriter(report_name, engine='xlsxwriter')
df.to_excel(writer, sheet_name=sheet_name, index=False)
Como mencionado anteriormente, usando a biblioteca, você também pode adicionar gráficos ao relatório. Você precisa definir o tipo de gráfico (linear em nosso exemplo) e o intervalo de dados para ele (o intervalo de dados deve estar na tabela do Excel).
workbook = writer.book
worksheet = writer.sheets[sheet_name]
chart = workbook.add_chart({'type': 'line'})
chart.add_series({
'categories': [sheet_name, 1, 0, 3, 0],
'values': [sheet_name, 1, 1, 3, 1],
})
chart.set_x_axis({'name': 'Index', 'position_axis': 'on_tick'})
chart.set_y_axis({'name': 'Value', 'major_gridlines': {'visible': False}})
worksheet.insert_chart('E2', chart)
writer.save()
5. Economize espaço em disco
O trabalho em um grande número de projetos de análise de dados geralmente deixa uma marca na forma de uma grande quantidade de dados processados de várias experiências. O SSD do laptop enche-se rapidamente. O Pandas permite compactar dados enquanto salva dados em disco e, em seguida, lê-los novamente em um formato compactado.Crie um DataFrame grande com números aleatórios.df = pd.DataFrame(pd.np.random.randn(50000,300))
 Se você salvá-lo como um CSV, o arquivo ocupará quase 300 MB no seu disco rígido.
Se você salvá-lo como um CSV, o arquivo ocupará quase 300 MB no seu disco rígido.df.to_csv('random_data.csv', index=False)
Um argumento compression='gzip'reduz o tamanho do arquivo para 136 MB.df.to_csv('random_data.gz', compression='gzip', index=False)
Um arquivo compactado é lido da mesma maneira que um arquivo normal, portanto, não perdemos nenhuma funcionalidade.df = pd.read_csv('random_data.gz')
Conclusão
Esses pequenos truques aumentaram a produtividade do meu trabalho diário com os pandas. Espero que você tenha aprendido com este artigo sobre algum recurso útil que o ajudará a se tornar mais produtivo também.Qual é o seu truque favorito com os pandas?