Os relatórios de cobertura modernos são, em alguns casos, bastante inúteis, e os métodos para medi-los são principalmente adequados apenas para desenvolvedores. Você sempre pode descobrir a porcentagem de cobertura ou visualizar o código que não foi usado durante os testes, mas e se você deseja visibilidade, simplicidade e automação? Sob o corte - vídeo e transcrição de um relatório de Artem Eroshenko da Qameta Software da conferência Heisenbug . Ele apresentou várias soluções simples e elegantes desenvolvidas que ajudam a equipe da Yandex.Verticals a avaliar a cobertura dos testes escritos por engenheiros de automação de testes. O Artem lhe dirá como descobrir rapidamente o que é coberto, como coberto, quais testes foram aprovados e ver instantaneamente relatórios visuais.Meu nome é Artyom Eroshenko eroshenkoam, Faço automação de testes há mais de 10 anos. Eu era gerente de automação de testes, gerente de equipe de desenvolvimento de ferramentas, desenvolvedor de ferramentas.No momento em que sou consultor na área de automação de testes, trabalho com várias empresas com as quais construímos processos.Também sou desenvolvedor e gerente secreto do Allure Report. Recentemente, corrigimos uma coisa legal : agora no JUnit 5 existem equipamentos.
Sob o corte - vídeo e transcrição de um relatório de Artem Eroshenko da Qameta Software da conferência Heisenbug . Ele apresentou várias soluções simples e elegantes desenvolvidas que ajudam a equipe da Yandex.Verticals a avaliar a cobertura dos testes escritos por engenheiros de automação de testes. O Artem lhe dirá como descobrir rapidamente o que é coberto, como coberto, quais testes foram aprovados e ver instantaneamente relatórios visuais.Meu nome é Artyom Eroshenko eroshenkoam, Faço automação de testes há mais de 10 anos. Eu era gerente de automação de testes, gerente de equipe de desenvolvimento de ferramentas, desenvolvedor de ferramentas.No momento em que sou consultor na área de automação de testes, trabalho com várias empresas com as quais construímos processos.Também sou desenvolvedor e gerente secreto do Allure Report. Recentemente, corrigimos uma coisa legal : agora no JUnit 5 existem equipamentos.Atlas Framework
Meu desenvolvimento é o Atlas Framework . Se alguém começou a automatizar em 2012, quando os drivers da Web Java estavam apenas começando, naquele momento eu criei uma biblioteca de código aberto chamada HTML Elements .O Html Elements tem sua continuação e repensagem na biblioteca Atlas, que é construída sobre interfaces: não há classes como tais, nem campos, uma biblioteca muito conveniente, leve e facilmente extensível. Se você deseja entendê-lo, pode ler o artigo ou ver o relatório .Meu relatório é dedicado ao problema da automação de testes e principalmente aos revestimentos. Como pano de fundo, gostaria de me referir a como os processos de teste são organizados no Yandex.Verticals.Como a automação funciona nas verticais?
Existem apenas quatro pessoas na equipe de automação de testes da Yandex.Verticals que automatizam quatro serviços: Yandex.Avto, Trabalho, Imóveis e Peças. Ou seja, esta é uma pequena equipe de montadoras que faz muito. Automatizamos a API, interface da Web, aplicativos móveis e assim por diante. No total, temos cerca de 15,5 mil testes realizados em diferentes níveis.A estabilidade dos testes na equipe é de cerca de 97%, embora alguns de meus colegas digam cerca de 99%. Essa alta estabilidade é alcançada precisamente graças a testes curtos em tecnologias muito nativas. Como regra, nossos testes levam cerca de 15 minutos, o que é muito amplo, e os executamos em aproximadamente 800 threads. Ou seja, temos 800 navegadores começando ao mesmo tempo - um teste de estresse dos nossos testes. Como ferro, usamos Selenoid (Aerokube). Você pode aprender mais sobre a automação de testes no Yandex.Verticals assistindo ao meu relatório de 2017, que ainda é relevante.Outra característica da nossa equipe é que automatizamos tudo , incluindo testadores manuais, que dão uma grande contribuição ao desenvolvimento da automação de testes. Para eles, organizamos escolas, ensinamos a eles testes, ensinamos como escrever testes para a API, a interface da Web e, muitas vezes, ajudam a acompanhar os testes. Assim, os responsáveis pela liberação podem corrigir o teste imediatamente, se necessário.Na Verticals, os desenvolvedores de testes escrevem testes e estão tão interessados no desenvolvimento de testes que competem conosco. Você pode aprender mais sobre esse processo no relatório "O ciclo completo de teste dos aplicativos React", onde Alexei Androsov e Natalya Stus falam sobre como eles escrevem testes de unidade no Puppeteer em paralelo com nossos testes de ponta a ponta em Java.Os engenheiros de automação de testes também escrevem testes em nossa equipe. Mas frequentemente estamos desenvolvendo novas abordagens para otimizá-las. Por exemplo, implementamos testes de captura de tela, testes através do moki, redução de testes. Em geral, nossa área é principalmente desenvolvedora de software em teste (SDET), abordamos mais como escrever testes e a base de testes é parcialmente preenchida por nós e é suportada por testadores manuais.Os desenvolvedores também nos ajudam, e isso é legal.
O problema que surge dentro desses processos é que nem sempre entendemos o que já está coberto e o que não está. Analisando 15 mil testes, nem sempre é claro o que exatamente verificamos. Isso é especialmente verdade no contexto da comunicação com os gerentes, que, é claro, não testam, mas monitoram e fazem perguntas. Em particular, se surgir a questão de saber se um botão específico foi testado na interface ou no fluxo, é difícil responder, porque você precisa acessar o código de teste e examinar essas informações.O que é testado e o que não é?
Se você tem muitos testes em idiomas diferentes e é escrito por pessoas com diferentes graus de treinamento, mais cedo ou mais tarde surge a pergunta: esses testes não são interceptados? No contexto desse problema, a questão da cobertura está se tornando particularmente relevante. Vou descrever três tópicos principais:- Maneiras de medir efetivamente a cobertura.
- Cobertura para testes de API.
- Cobertura para testes na web.
Antes de tudo, vamos determinar que existem duas maneiras de cobrir: cobrindo requisitos e cobrindo o código do produto.Como a cobertura dos requisitos é medida
Considere a cobertura dos requisitos usando o auto.ru como exemplo. No lugar do testador auto.ru, eu faria o seguinte. Em primeiro lugar, eu pesquisaria no Google e encontraria imediatamente uma tabela de requisitos especiais. Essa é a base da cobertura dos requisitos.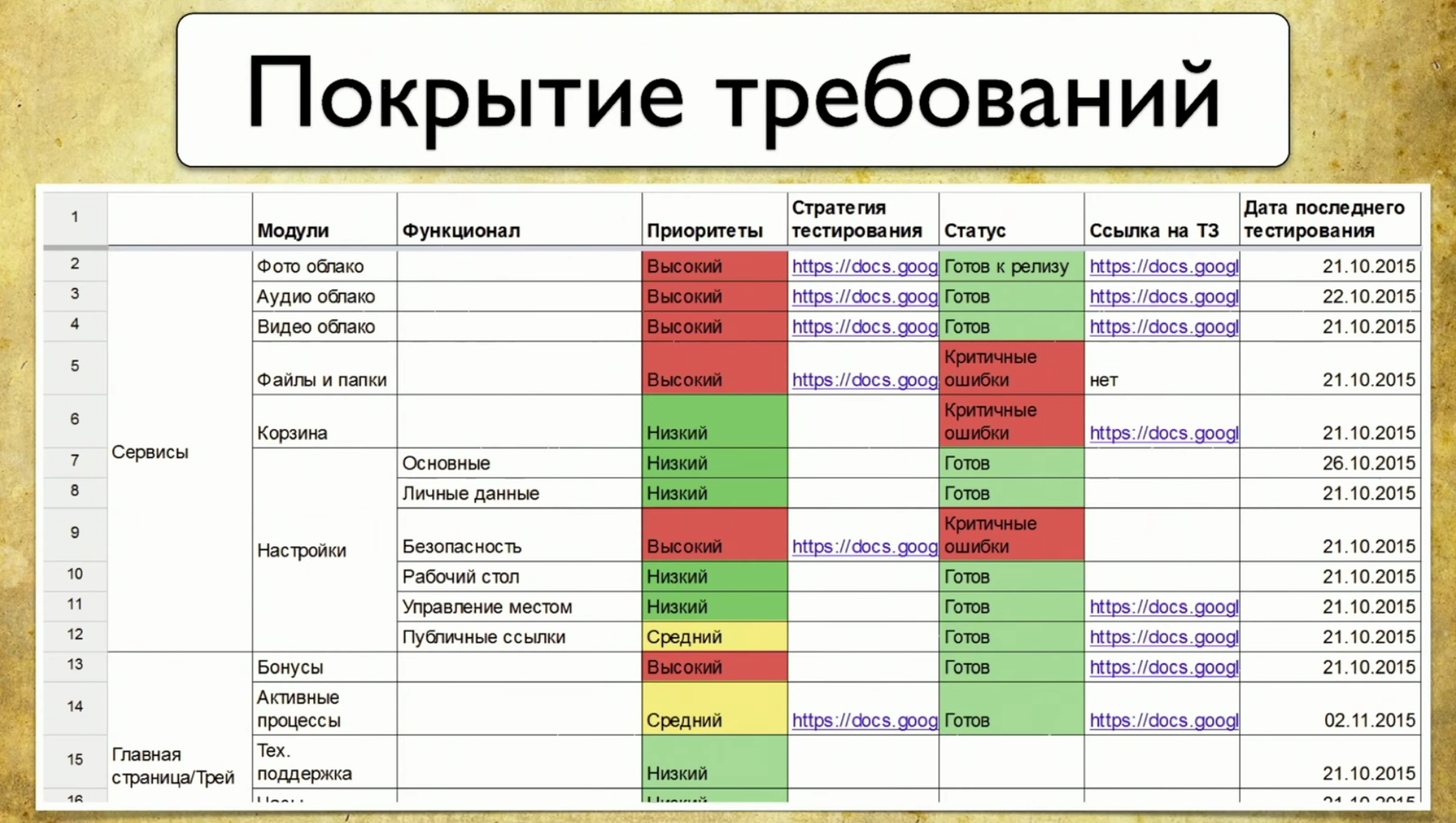 Nesta tabela, os nomes dos requisitos estão escritos à esquerda. Nesse caso: conta, anúncios, verificação e pagamento, ou seja, verificação do anúncio. Em geral, esta é a cobertura. Os detalhes da parte esquerda dependem do nível do testador. Por exemplo, os engenheiros do Google têm 49 tipos de revestimentos testados em diferentes níveis.O lado direito da tabela são os atributos dos requisitos. Podemos usar qualquer coisa na forma de atributos, por exemplo: prioridade, cobertura e estado. Essa pode ser a data do último lançamento.
Nesta tabela, os nomes dos requisitos estão escritos à esquerda. Nesse caso: conta, anúncios, verificação e pagamento, ou seja, verificação do anúncio. Em geral, esta é a cobertura. Os detalhes da parte esquerda dependem do nível do testador. Por exemplo, os engenheiros do Google têm 49 tipos de revestimentos testados em diferentes níveis.O lado direito da tabela são os atributos dos requisitos. Podemos usar qualquer coisa na forma de atributos, por exemplo: prioridade, cobertura e estado. Essa pode ser a data do último lançamento. Assim, alguns dados aparecem na tabela. Você pode usar ferramentas profissionais para manter uma tabela de requisitos, por exemplo, TestRail.Há informações sobre a árvore à direita: as pastas indicam quais requisitos temos, como podem ser atendidos. Existem casos de teste e assim por diante.
Assim, alguns dados aparecem na tabela. Você pode usar ferramentas profissionais para manter uma tabela de requisitos, por exemplo, TestRail.Há informações sobre a árvore à direita: as pastas indicam quais requisitos temos, como podem ser atendidos. Existem casos de teste e assim por diante. Nas verticais, esse processo se parece com o seguinte: um testador manual descreve os requisitos e os casos de teste, depois os passa para a automação de teste, e a ferramenta automatizada grava o código para esses testes. Além disso, anteriormente recebemos casos de teste detalhados nos quais o testador manual descreveu toda a estrutura. Então alguém fez um commit no github e o teste começou a ser benéfico.Quais são os prós e os contras dessa abordagem? A vantagem é que essa abordagem responde às nossas perguntas. Se o gerente perguntar o que abordamos, vou abrir o tablet e mostrar quais recursos são abordados. Por outro lado, esses requisitos devem sempre ser atualizados e se tornam obsoletos muito rapidamente.Quando você tem 15 mil testes, olhar para o TestRail é como olhar para uma estrela no espaço: ela explodiu por um longo tempo e a luz chegou até você agora. Você olha para o caso de teste atual e ele já está desatualizado há muito tempo e irrevogavelmente.Este problema é difícil de resolver. Para nós, esses geralmente são dois mundos diferentes: existe um mundo de automação que gira de acordo com suas próprias leis, onde todo teste que falha é imediatamente corrigido e há um mundo de testes manuais e cartões de requisitos. A parede entre eles é impenetrável, a menos que você use o Allure Server. Agora apenas resolvemos esse problema para eles.O terceiro ponto dos "prós e contras" é a necessidade de trabalho manual. Em um novo projeto, você precisa recriar um mapa de requisitos, gravar todos os casos de teste e assim por diante. Sempre requer trabalho manual e é realmente muito triste.
Nas verticais, esse processo se parece com o seguinte: um testador manual descreve os requisitos e os casos de teste, depois os passa para a automação de teste, e a ferramenta automatizada grava o código para esses testes. Além disso, anteriormente recebemos casos de teste detalhados nos quais o testador manual descreveu toda a estrutura. Então alguém fez um commit no github e o teste começou a ser benéfico.Quais são os prós e os contras dessa abordagem? A vantagem é que essa abordagem responde às nossas perguntas. Se o gerente perguntar o que abordamos, vou abrir o tablet e mostrar quais recursos são abordados. Por outro lado, esses requisitos devem sempre ser atualizados e se tornam obsoletos muito rapidamente.Quando você tem 15 mil testes, olhar para o TestRail é como olhar para uma estrela no espaço: ela explodiu por um longo tempo e a luz chegou até você agora. Você olha para o caso de teste atual e ele já está desatualizado há muito tempo e irrevogavelmente.Este problema é difícil de resolver. Para nós, esses geralmente são dois mundos diferentes: existe um mundo de automação que gira de acordo com suas próprias leis, onde todo teste que falha é imediatamente corrigido e há um mundo de testes manuais e cartões de requisitos. A parede entre eles é impenetrável, a menos que você use o Allure Server. Agora apenas resolvemos esse problema para eles.O terceiro ponto dos "prós e contras" é a necessidade de trabalho manual. Em um novo projeto, você precisa recriar um mapa de requisitos, gravar todos os casos de teste e assim por diante. Sempre requer trabalho manual e é realmente muito triste.Como a cobertura do código é medida
Uma alternativa para essa abordagem é a cobertura do código. Esta parece ser a solução para o nosso problema. É assim que a cobertura do código do produto é exibida: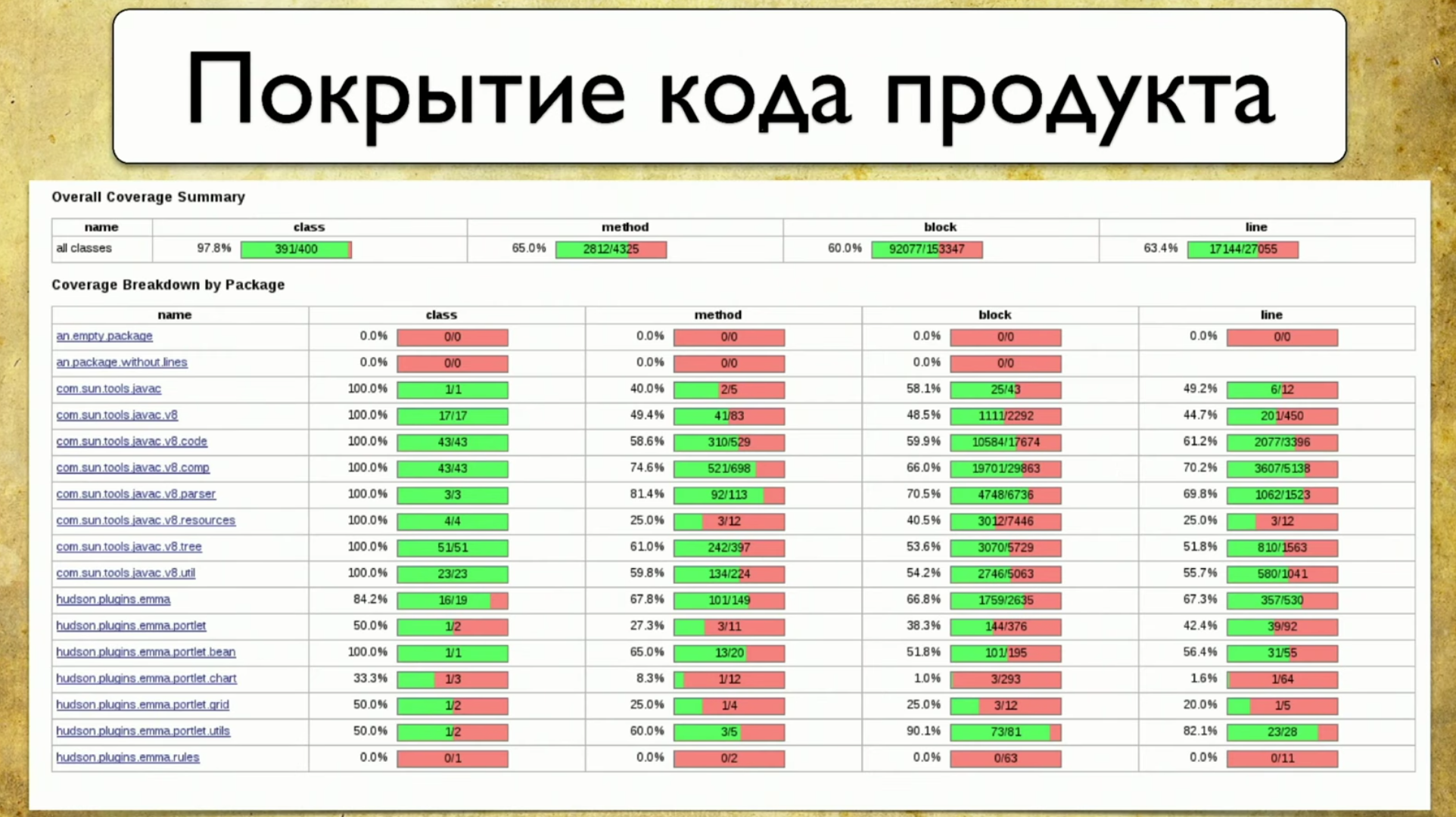 reflete a cobertura do pacote, ou melhor, uma pequena parte do que realmente é geralmente no produto. O pacote está escrito à esquerda, como os recursos foram escritos anteriormente. Ou seja, nosso revestimento está finalmente ligado a algumas coisas tangíveis, neste caso - Pacote. Os atributos estão escritos à direita: cobertura por classe, cobertura por métodos, cobertura por blocos de código e cobertura por linhas de código.O processo de coleta da cobertura é entender qual linha de código o teste passou e quais não foram. Essa é uma tarefa bastante simples, mas recentemente muito relevante.
reflete a cobertura do pacote, ou melhor, uma pequena parte do que realmente é geralmente no produto. O pacote está escrito à esquerda, como os recursos foram escritos anteriormente. Ou seja, nosso revestimento está finalmente ligado a algumas coisas tangíveis, neste caso - Pacote. Os atributos estão escritos à direita: cobertura por classe, cobertura por métodos, cobertura por blocos de código e cobertura por linhas de código.O processo de coleta da cobertura é entender qual linha de código o teste passou e quais não foram. Essa é uma tarefa bastante simples, mas recentemente muito relevante.A primeira menção à cobertura de código foi em 1963, mas um progresso sério nessa direção aparece apenas agora.
Portanto, temos um teste que interage com o sistema. Não importa como ele interage com ela: através do front-end, API ou rasteja diretamente para o back-end - apenas assumiremos que o temos.A instrumentação deve ser feita. Este é um processo que permite entender quais linhas de código foram verificadas e quais não foram. Você não precisa estudá-lo em detalhes, basta procurar o nome da sua estrutura, na qual você escreve, digamos, Spring , depois instrumentação e cobertura - com essas três palavras, você entenderá como isso é feito.Quando seus testes verificam qual linha de código o resultado do teste e quais não foram atingidos, eles salvam arquivos com informações sobre quais linhas são cobertas. Com base nessas informações, você tem dados.Quais são os prós e os contras da cobertura de código?
Cobertura de código que eu chamaria imediatamente de menos . Você não virá ao gerente, não mostrará esta placa e não dirá que todo mundo automatizou, porque esses dados não podem ser lidos, ele solicitará que você retorne dados claros que possam ser vistos e compreendidos rapidamente.Relatório de cobertura de código mais próximo do desenvolvimento. Ele não pode ser usado como uma abordagem normal para fornecer todos os dados a uma equipe se queremos que toda a equipe possa assistir. A vantagem dessa abordagem é que ela sempre fornece dados relevantes. Você não precisa fazer muito trabalho, tudo é automatizado para você. Basta conectar a biblioteca, suas capas começam a decolar - e é muito legal.Outra vantagem dessa abordagem é que ela requer apenas personalização. Não há nada de especial para fazer lá - basta vir com uma instrução específica, ajustar a cobertura e ela funciona automaticamente.A cobertura dos requisitos revela requisitos não cumpridos, mas não permite avaliar a integridade em relação ao código. Por exemplo, você começou a escrever um novo recurso "autorização", basta inserir o "recurso de autorização" e começar a lançar casos de teste nele. Você não pode ver imediatamente essa cobertura no código, mesmo se você escrever alguma nova classe, ainda não haverá informações - há uma lacuna. Por outro lado, isso é um requisito de autorização, mesmo quando já estiver implementado, quando você contar a cobertura, essa parte não pode ser relevante, deve ser atualizada manualmente.Portanto, tivemos uma ideia: e se tirarmos o melhor de todos? Para que a cobertura respondesse às nossas perguntas, era sempre relevante e exigia apenas personalização. Só precisamos olhar para o revestimento de um ângulo diferente, ou seja, usar outro sistema como base do revestimento. Ao mesmo tempo, verifique se ele é coletado completamente automaticamente e traz vários benefícios. E, para isso, abordaremos os testes da API.
A vantagem dessa abordagem é que ela sempre fornece dados relevantes. Você não precisa fazer muito trabalho, tudo é automatizado para você. Basta conectar a biblioteca, suas capas começam a decolar - e é muito legal.Outra vantagem dessa abordagem é que ela requer apenas personalização. Não há nada de especial para fazer lá - basta vir com uma instrução específica, ajustar a cobertura e ela funciona automaticamente.A cobertura dos requisitos revela requisitos não cumpridos, mas não permite avaliar a integridade em relação ao código. Por exemplo, você começou a escrever um novo recurso "autorização", basta inserir o "recurso de autorização" e começar a lançar casos de teste nele. Você não pode ver imediatamente essa cobertura no código, mesmo se você escrever alguma nova classe, ainda não haverá informações - há uma lacuna. Por outro lado, isso é um requisito de autorização, mesmo quando já estiver implementado, quando você contar a cobertura, essa parte não pode ser relevante, deve ser atualizada manualmente.Portanto, tivemos uma ideia: e se tirarmos o melhor de todos? Para que a cobertura respondesse às nossas perguntas, era sempre relevante e exigia apenas personalização. Só precisamos olhar para o revestimento de um ângulo diferente, ou seja, usar outro sistema como base do revestimento. Ao mesmo tempo, verifique se ele é coletado completamente automaticamente e traz vários benefícios. E, para isso, abordaremos os testes da API.API de cobertura de teste
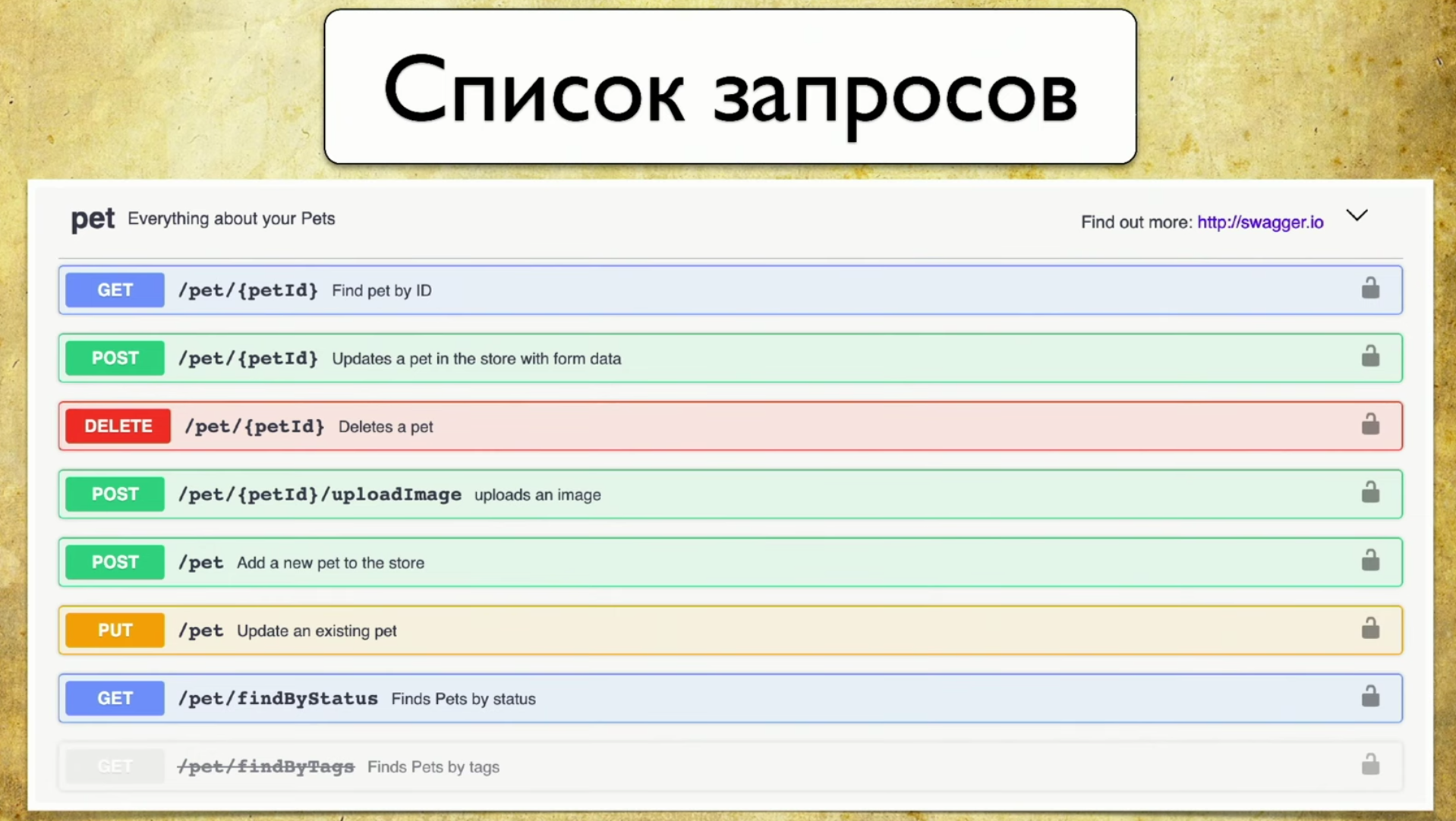
Qual é a base da cobertura? Para fazer isso, usamos o Swagger - esta é a API de documentação. Agora não consigo imaginar meu trabalho sem o Swagger, é uma ferramenta que uso constantemente para testar. Se você não usa o Swagger, eu recomendo visitar o site e se familiarizar. Lá você verá imediatamente um exemplo de uso muito intuitivo e compreensível.De fato, o Swagger é a documentação gerada pelo seu serviço. Contém:- Lista de pedidos.
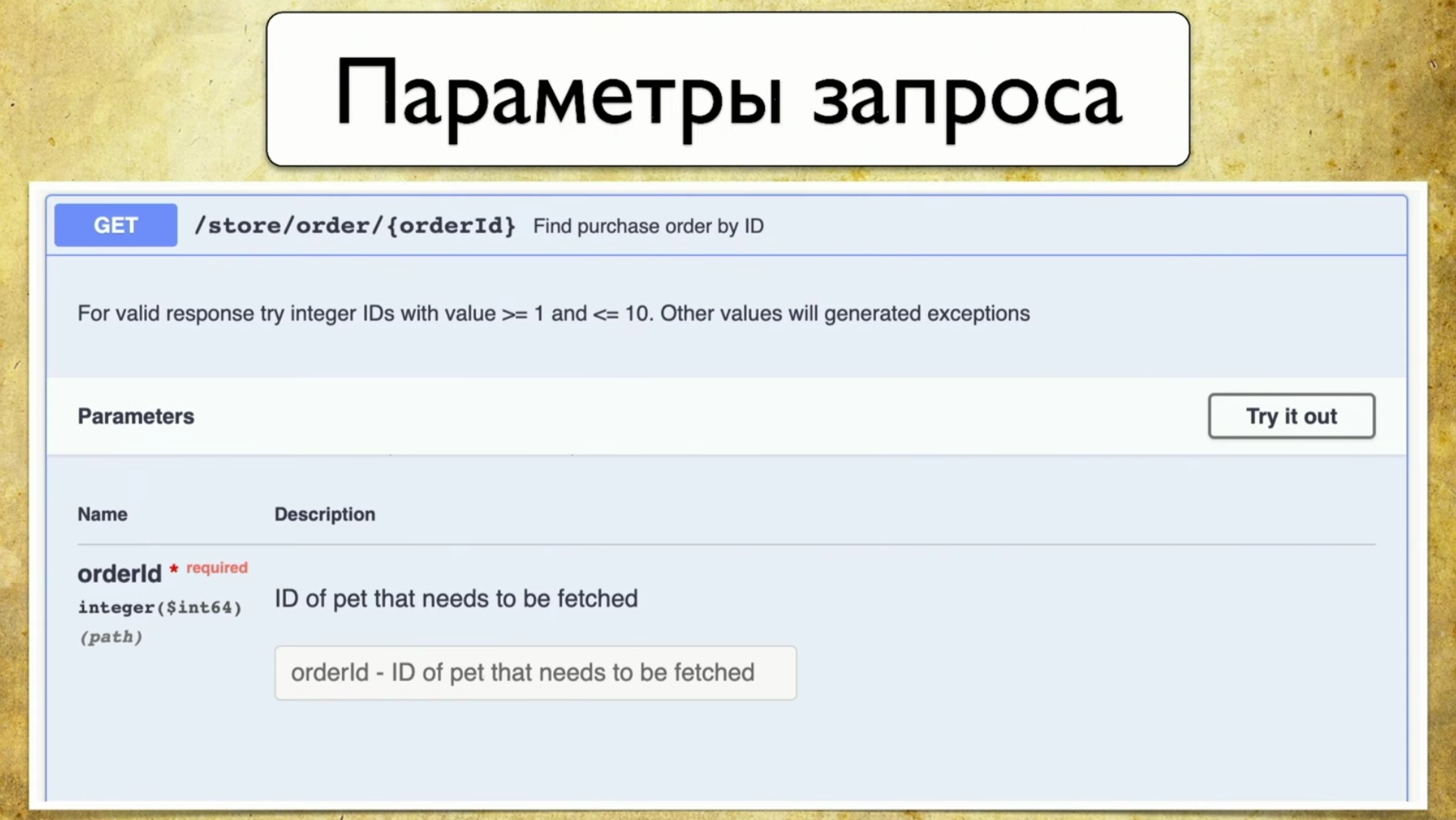
- Parâmetros de solicitação: não há necessidade de puxar o desenvolvedor e perguntar quais são os parâmetros.
- Códigos de resposta

O princípio de operação do Swagger é geração. Não importa qual estrutura você usa. Digamos Spring ou Go Server, você usa o componente Swagger Codegen e gera swagger.json . Esta é uma especificação, com base na qual uma linda interface do usuário é desenhada.É importante para nós que o swagger.json seja usado : seu suporte está disponível para todos os idiomas amplamente usados.Temos a especificação Open API swagger.json . É assim: As solicitações são mais ou menos assim: resumo, descrição, códigos de resposta e um "identificador" (caminho: / users). Também há informações sobre o parâmetro de consulta: tudo está estruturado, existe um parâmetro de ID do usuário, está no caminho em que é necessário, como descrição e tipo - número inteiro.
solicitações são mais ou menos assim: resumo, descrição, códigos de resposta e um "identificador" (caminho: / users). Também há informações sobre o parâmetro de consulta: tudo está estruturado, existe um parâmetro de ID do usuário, está no caminho em que é necessário, como descrição e tipo - número inteiro. Existem códigos de resposta, eles também estão documentados:
Existem códigos de resposta, eles também estão documentados: E a idéia veio à nossa mente: temos um serviço que o Swagger gera e queríamos manter o mesmo Swagger nos testes, para poder compará-los mais tarde. Em outras palavras, quando os testes são executados, eles geram exatamente o mesmo Swagger, jogamos no Swagger Diff, entendemos quais parâmetros, manipuladores, códigos de status verificamos e assim por diante. É a mesma instrumentação, a mesma cobertura, apenas finalmente nos requisitos que entendemos.
E a idéia veio à nossa mente: temos um serviço que o Swagger gera e queríamos manter o mesmo Swagger nos testes, para poder compará-los mais tarde. Em outras palavras, quando os testes são executados, eles geram exatamente o mesmo Swagger, jogamos no Swagger Diff, entendemos quais parâmetros, manipuladores, códigos de status verificamos e assim por diante. É a mesma instrumentação, a mesma cobertura, apenas finalmente nos requisitos que entendemos.Mas e se você criar um diff?
Nós nos voltamos para a biblioteca de diferenças do Swagger , que é o que precisamos para isso. Seu princípio de operação é mais ou menos assim: você tem a versão 1.0, com a API 1.1, ambos geram swagger.json , depois os lança no diff Swagger e vê o resultado.O resultado é mais ou menos assim: você tem informações de que há, por exemplo, uma nova caneta. Você também tem informações sobre o que é excluído. Isso significa que é hora de remover os testes, eles não são mais relevantes. Com o aparecimento de informações sobre mudanças, os parâmetros também mudam, portanto, é óbvio que seus testes cairão nesse momento.Gostamos dessa ideia e começamos a implementar. Como decidimos fazer: temos um Swagger de "referência" que gera a partir do código do desenvolvedor, também temos testes de API que geram o nosso Swagger e diferimos entre eles.Portanto, executamos testes para o serviço: temos a Garantia de Garantia , que acessa os serviços na API. E nós a instrumentamos. Existe uma abordagem: você pode criar filtros, a solicitação vai para ele - e salva as informações sobre a solicitação na forma de swagger.json diretamente para si.Aqui está todo o código que precisávamos escrever, havia 69-70 linhas - este é um código muito simples.
você tem informações de que há, por exemplo, uma nova caneta. Você também tem informações sobre o que é excluído. Isso significa que é hora de remover os testes, eles não são mais relevantes. Com o aparecimento de informações sobre mudanças, os parâmetros também mudam, portanto, é óbvio que seus testes cairão nesse momento.Gostamos dessa ideia e começamos a implementar. Como decidimos fazer: temos um Swagger de "referência" que gera a partir do código do desenvolvedor, também temos testes de API que geram o nosso Swagger e diferimos entre eles.Portanto, executamos testes para o serviço: temos a Garantia de Garantia , que acessa os serviços na API. E nós a instrumentamos. Existe uma abordagem: você pode criar filtros, a solicitação vai para ele - e salva as informações sobre a solicitação na forma de swagger.json diretamente para si.Aqui está todo o código que precisávamos escrever, havia 69-70 linhas - este é um código muito simples. O engraçado é que usamos o cliente nativo do Swagger, que foi escrito ali. Nem precisávamos criar nossos binários, apenas preenchemos a especificação Swagger.
O engraçado é que usamos o cliente nativo do Swagger, que foi escrito ali. Nem precisávamos criar nossos binários, apenas preenchemos a especificação Swagger. Temos muitos arquivos .json com os quais tivemos que fazer algo - eles escreveram um agregador Swagger. Este é um programa muito simples que funciona de acordo com o seguinte princípio:
Temos muitos arquivos .json com os quais tivemos que fazer algo - eles escreveram um agregador Swagger. Este é um programa muito simples que funciona de acordo com o seguinte princípio:- Ela atende a uma nova solicitação, se não estiver em nosso banco de dados, acrescenta ela.
- Ela atende à solicitação, ele tem um novo parâmetro - acrescenta.
- A mesma coisa com os códigos de status.
Assim, obtemos informações sobre todas as canetas, parâmetros e códigos de status que usamos. Além disso, aqui você pode coletar dados com os quais essas solicitações foram executadas: nome de usuário, logins etc. Ainda não descobrimos como usar essas informações, porque tudo é gerado conosco, mas você pode entender com quais parâmetros determinados pedidos foram chamados.Então, estávamos quase a um passo da vitória, mas, como resultado, recusamos o Swagger Diff, porque funciona em um conceito um pouco diferente - no conceito de diferencial.
Swagger Diff diz o que mudou, não o que é coberto, mas queríamos mostrar o resultado da cobertura. Há muitos dados extras, ele armazena informações sobre descrição, resumo e outras meta-informações, mas não temos essas informações. E quando fazemos Diff, eles nos escrevem que "esta caneta não tem uma descrição", mas não existia.Relatório próprio
Fizemos nossa implementação e funciona da seguinte maneira: temos muitos arquivos provenientes de autotestes, temos a API do serviço Swagger e geramos um relatório baseado nela.Um relatório simples é assim: acima, você pode ver informações sobre quantas canetas (349) no total, informações sobre as quais são totalmente cobertas (cada parâmetro, código de status etc.). Você pode escolher seus próprios critérios, por exemplo, abranger vários parâmetros.Também há informações aqui de que 40% são parcialmente cobertos - isso significa que já temos testes para essas canetas, mas algumas coisas ainda não foram cobertas e você precisa procurar com atenção lá. A cobertura vazia também é refletida.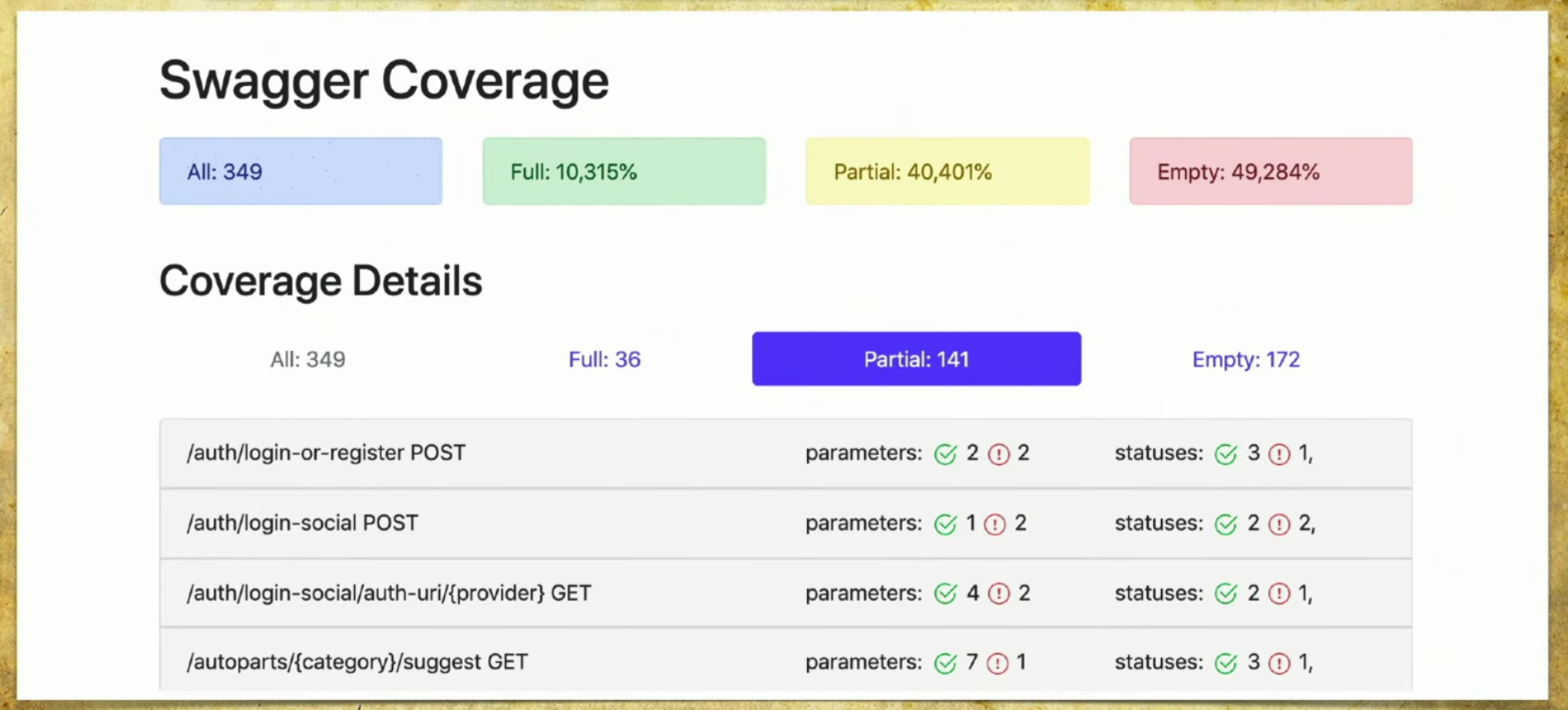 Vamos percorrer as guias. Esta é uma cobertura completa , vemos todos os parâmetros que temos, que são cobertos, códigos de status e assim por diante.
Vamos percorrer as guias. Esta é uma cobertura completa , vemos todos os parâmetros que temos, que são cobertos, códigos de status e assim por diante.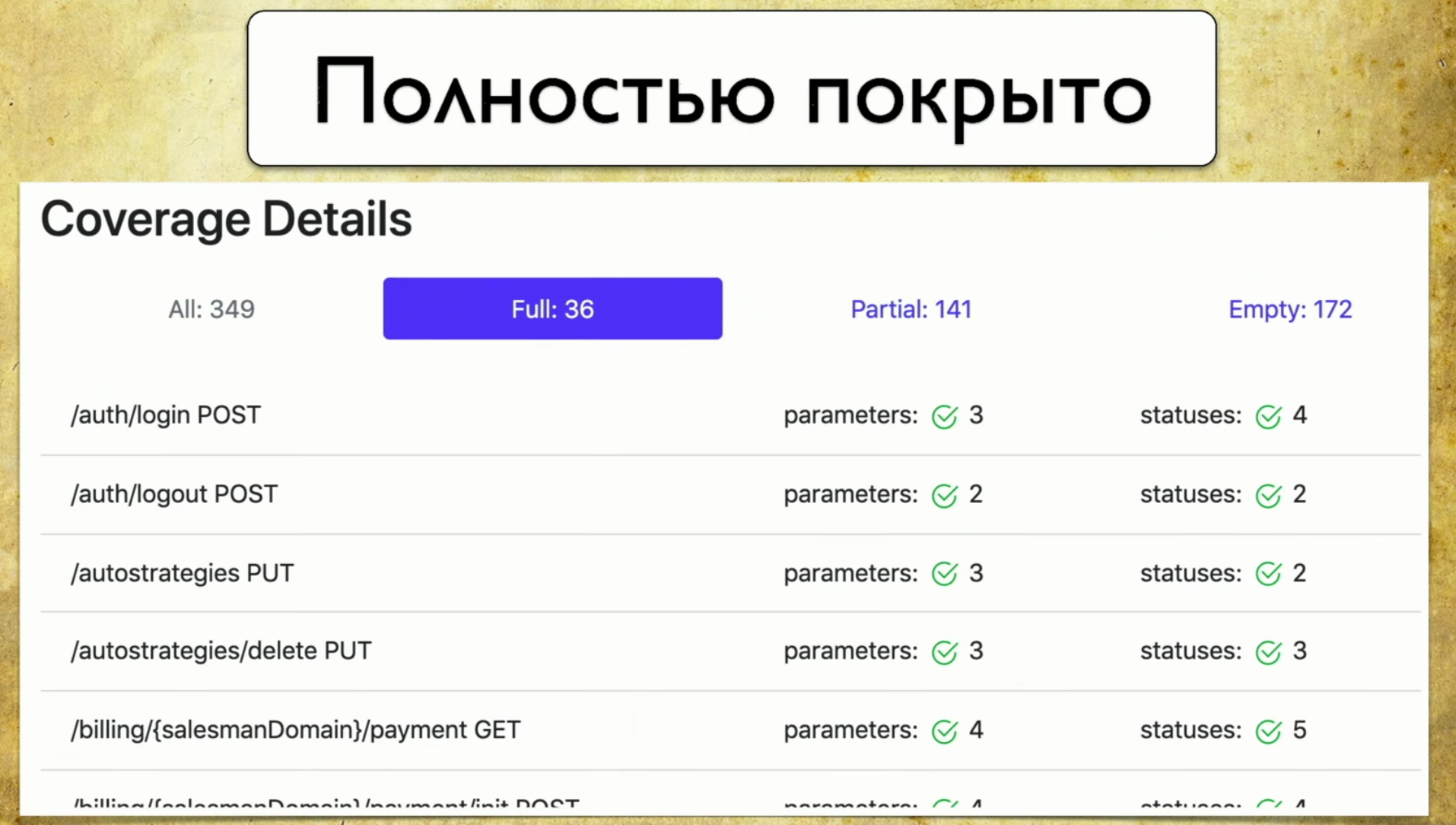 Então temos uma cobertura parcial . Vemos que no identificador social de login um parâmetro é coberto e dois não. E podemos expandi-lo e ver quais parâmetros e códigos de status específicos são abordados. E, neste momento, torna-se muito conveniente para o desenvolvedor: as versões do aplicativo rolam muito rapidamente e muitas vezes podemos esquecer alguns parâmetros.
Então temos uma cobertura parcial . Vemos que no identificador social de login um parâmetro é coberto e dois não. E podemos expandi-lo e ver quais parâmetros e códigos de status específicos são abordados. E, neste momento, torna-se muito conveniente para o desenvolvedor: as versões do aplicativo rolam muito rapidamente e muitas vezes podemos esquecer alguns parâmetros. Essa ferramenta permite que você esteja sempre em boa forma e entenda o que abordamos parcialmente, qual parâmetro é esquecido e assim por diante.Last - Glória da vergonha, ainda temos que fazê-lo. Quando você olha para esta página e vê Vazio lá: 172 - suas mãos caem, e então você começa a ensinar aos testadores de mãos como escrever autotestes, esse é o ponto.
Essa ferramenta permite que você esteja sempre em boa forma e entenda o que abordamos parcialmente, qual parâmetro é esquecido e assim por diante.Last - Glória da vergonha, ainda temos que fazê-lo. Quando você olha para esta página e vê Vazio lá: 172 - suas mãos caem, e então você começa a ensinar aos testadores de mãos como escrever autotestes, esse é o ponto.
Que benefício tivemos quando lançamos nossa solução?
Primeiro, começamos a escrever testes com mais significado. Entendemos que estamos testando e, ao mesmo tempo, temos duas estratégias. Primeiro, automatizamos algo que não existe quando os testadores manuais chegam e dizemos que, para um serviço específico, é fundamental que uma solicitação seja executada pelo menos uma vez e abrimos o Empty.A segunda opção - não esquecemos as caudas. Como eu disse, as APIs serão lançadas muito rapidamente, pode haver alguns lançamentos duas ou três vezes por dia. Alguns parâmetros são constantemente adicionados: em cinco mil testes, é impossível entender o que é verificado e o que não é. Portanto, esta é a única maneira de escolher conscientemente uma estratégia de teste e, pelo menos, fazer alguma coisa.O terceiro lucro é um processo totalmente automático. Emprestamos a abordagem, e a automação funciona: não precisamos fazer nada, tudo é coletado automaticamente.Idéias de desenvolvimento
Primeiro, eu realmente não quero manter o segundo relatório, mas quero integrá-lo à interface do usuário do Swagger. Este é o meu "relatório Photoshop Edition" favorito: um chip que tenho desenvolvido ultimamente. Aqui, imediatamente, há informações sobre os parâmetros que testamos e quais não são. E seria legal fornecer essas informações imediatamente com o Swagger. Por exemplo, o front-end pode ver por si mesmo quais parâmetros não foram testados, priorizar e decidir que, embora não precisem ser levados ao desenvolvimento, não se sabe o quanto eles funcionam. Ou o back-end escreve uma caneta nova, vê o vermelho e chuta os testadores para que tudo fique verde. Isso é muito fácil de fazer, estamos indo nessa direção.A segunda idéia é apoiar outras ferramentas. Na verdade, não quero escrever filtros para implementações específicas: para Java, Python e assim por diante. Existe uma idéia para criar um tipo de proxy que repasse todas as solicitações por si mesmo e salve as informações do Swagger para si. Assim, teremos uma biblioteca universal que pode ser usada, independentemente do idioma que você possui.A terceira ideia de desenvolvimento é a integração com o Allure Report. Eu vejo assim:
Por exemplo, o front-end pode ver por si mesmo quais parâmetros não foram testados, priorizar e decidir que, embora não precisem ser levados ao desenvolvimento, não se sabe o quanto eles funcionam. Ou o back-end escreve uma caneta nova, vê o vermelho e chuta os testadores para que tudo fique verde. Isso é muito fácil de fazer, estamos indo nessa direção.A segunda idéia é apoiar outras ferramentas. Na verdade, não quero escrever filtros para implementações específicas: para Java, Python e assim por diante. Existe uma idéia para criar um tipo de proxy que repasse todas as solicitações por si mesmo e salve as informações do Swagger para si. Assim, teremos uma biblioteca universal que pode ser usada, independentemente do idioma que você possui.A terceira ideia de desenvolvimento é a integração com o Allure Report. Eu vejo assim: Como regra, quando o parâmetro é "testado", isso nem sempre nos diz como é testado. E quero apontar para este parâmetro e ver as etapas específicas do teste.
Como regra, quando o parâmetro é "testado", isso nem sempre nos diz como é testado. E quero apontar para este parâmetro e ver as etapas específicas do teste.Cobertura de Testes na Web
O próximo ponto sobre o qual quero falar é a cobertura para testes na Web. A cobertura é baseada no site que você está testando, escrevendo testes no site. Mas você pode torná-lo uma interface da web para sua cobertura. Por exemplo, ficará assim: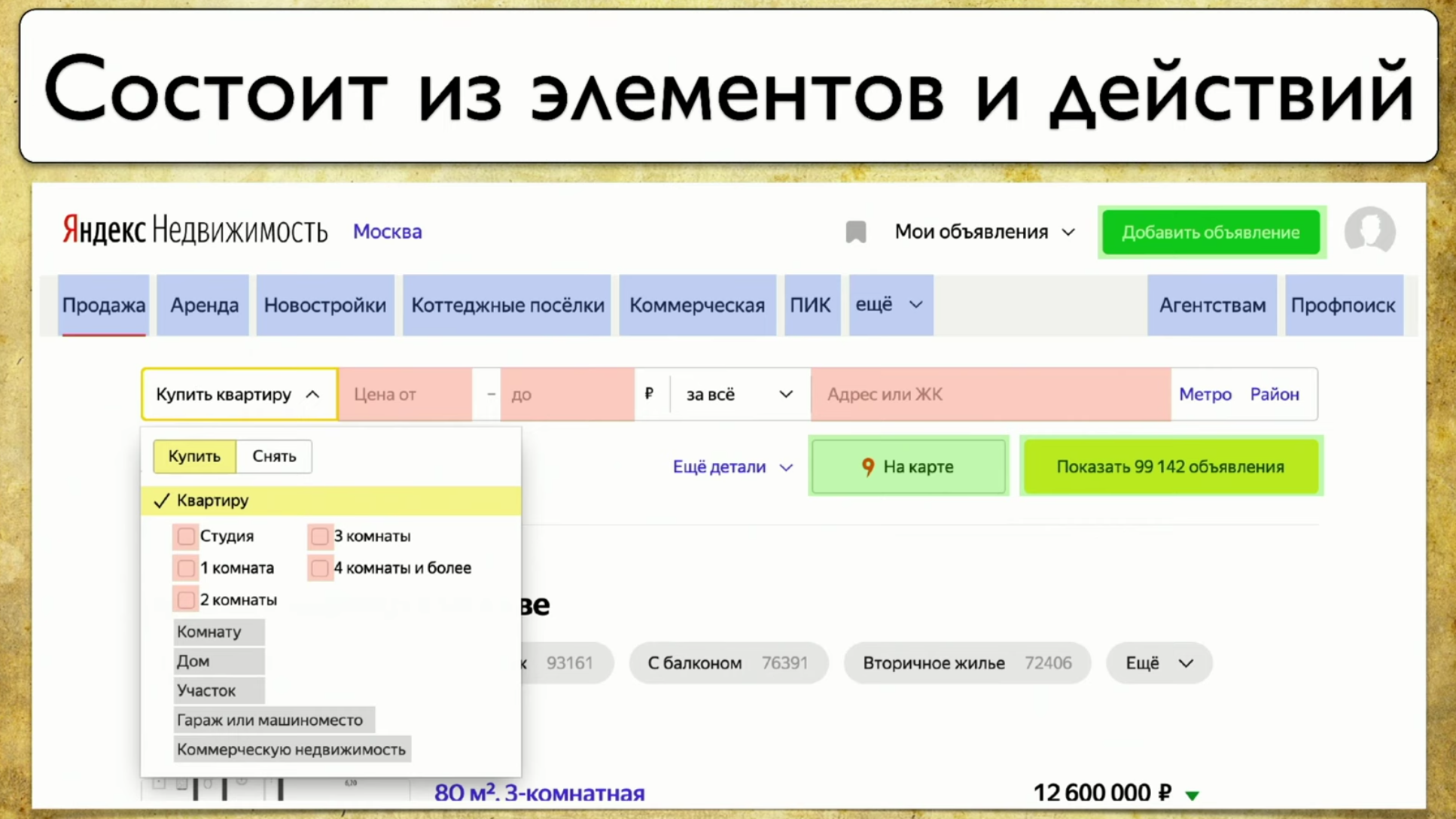 Se você olhar para o seu site - este é um conjunto de elementos e maneiras de interagir com eles. Esta é uma descrição completa: "um elemento é uma maneira de interagir com ele". Você pode clicar no link, copiar o texto, inserir algo na entrada. O site como um todo consiste em elementos e formas de interação:
Se você olhar para o seu site - este é um conjunto de elementos e maneiras de interagir com eles. Esta é uma descrição completa: "um elemento é uma maneira de interagir com ele". Você pode clicar no link, copiar o texto, inserir algo na entrada. O site como um todo consiste em elementos e formas de interação: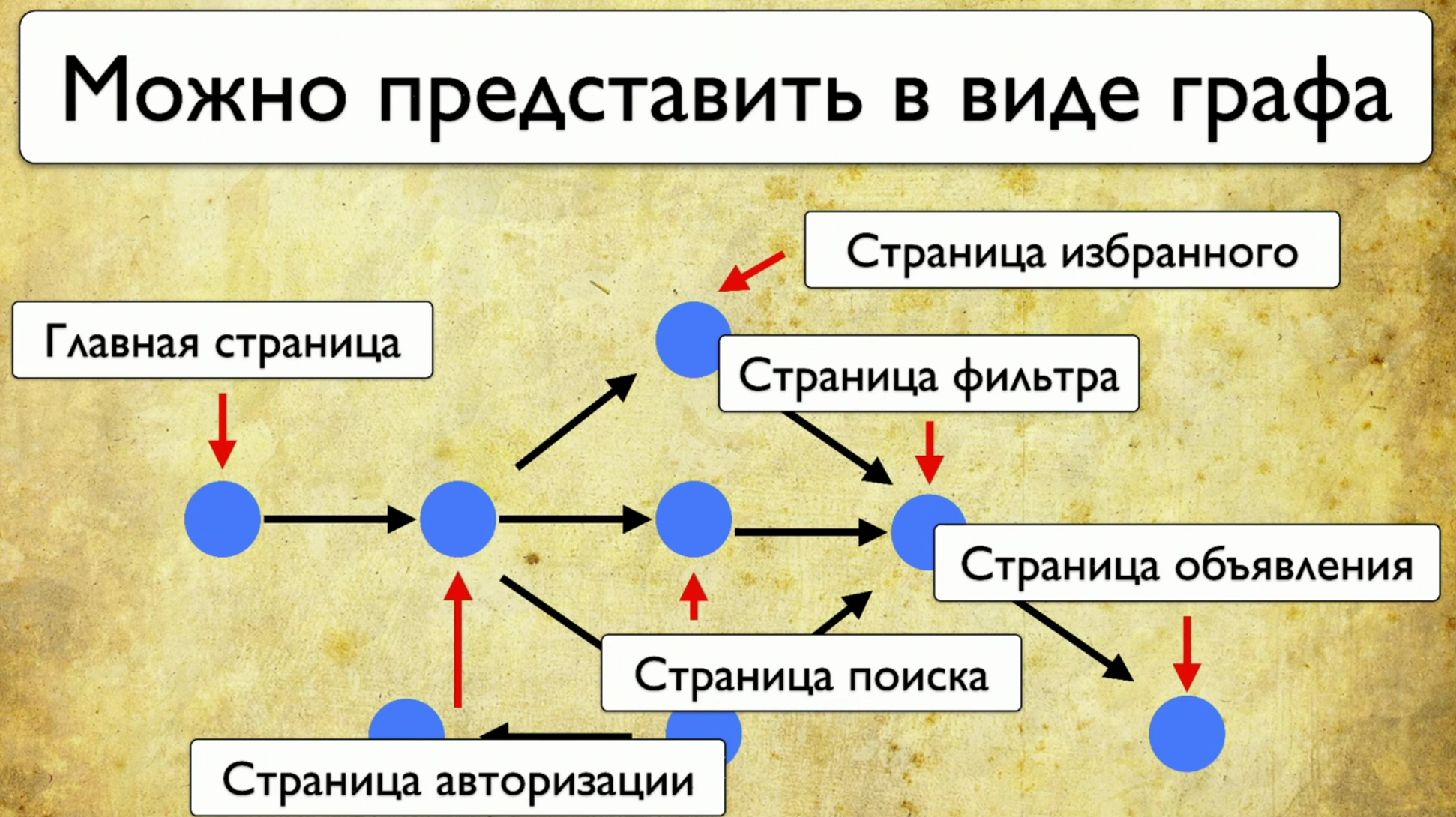 Como os testes são executados: eles começam em algum momento e, por exemplo, preenchem algum formulário, digamos, um formulário de autorização, depois se espalham para outras páginas, depois para outro e para o final .Se o gerente perguntar se um botão específico está sendo testado, mas é difícil responder a essa pergunta: você precisa abrir o código ou acessar o TestRail, desejo ver esta solução para o problema:
Como os testes são executados: eles começam em algum momento e, por exemplo, preenchem algum formulário, digamos, um formulário de autorização, depois se espalham para outras páginas, depois para outro e para o final .Se o gerente perguntar se um botão específico está sendo testado, mas é difícil responder a essa pergunta: você precisa abrir o código ou acessar o TestRail, desejo ver esta solução para o problema: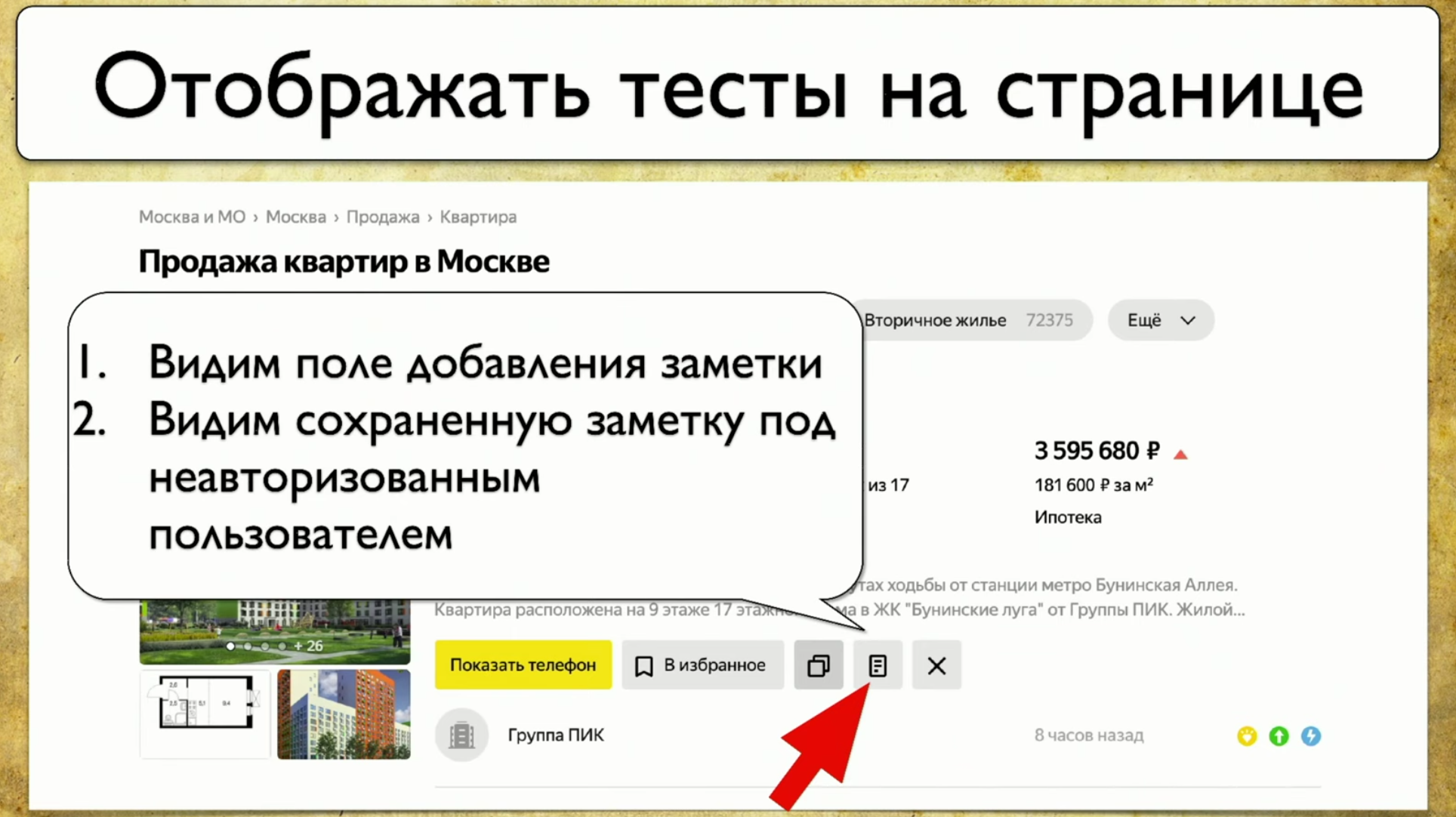 quero apontar para esse elemento e ver todos os testes que temos neste item. Se houvesse esse instrumento, eu ficaria feliz. Quando começamos a pensar nessa idéia, vimos primeiro o Yandex.Metrica. Na verdade, eles têm aproximadamente a mesma funcionalidade que um mapa de links. Uma boa ideia.O ponto principal é que eles são destacados exatamente como se já tivessem as informações de que precisamos. Eles dizem: “Aqui passamos por este link 14 vezes”, o que na tradução para a linguagem de teste significa: “14 testes foram testados neste link” e de alguma forma passaram por ele. Mas esse link vermelho levou até 120 testes, que testes interessantes!Você pode desenhar todos os tipos de tendências, adicionar meta-informações, mas o que acontece se pegarmos tudo e desenharmos do ponto de vista dos testes? Portanto, temos uma tarefa: apontar para algum elemento e fazer uma anotação com uma lista de testes.
quero apontar para esse elemento e ver todos os testes que temos neste item. Se houvesse esse instrumento, eu ficaria feliz. Quando começamos a pensar nessa idéia, vimos primeiro o Yandex.Metrica. Na verdade, eles têm aproximadamente a mesma funcionalidade que um mapa de links. Uma boa ideia.O ponto principal é que eles são destacados exatamente como se já tivessem as informações de que precisamos. Eles dizem: “Aqui passamos por este link 14 vezes”, o que na tradução para a linguagem de teste significa: “14 testes foram testados neste link” e de alguma forma passaram por ele. Mas esse link vermelho levou até 120 testes, que testes interessantes!Você pode desenhar todos os tipos de tendências, adicionar meta-informações, mas o que acontece se pegarmos tudo e desenharmos do ponto de vista dos testes? Portanto, temos uma tarefa: apontar para algum elemento e fazer uma anotação com uma lista de testes. Para implementar isso, você precisa clicar no ícone e escrever uma nota, e este é todo o nosso teste. Usamos o Atlas em nosso lugar, e a integração até agora é apenas com ele.Atlas se parece com isso:
Para implementar isso, você precisa clicar no ícone e escrever uma nota, e este é todo o nosso teste. Usamos o Atlas em nosso lugar, e a integração até agora é apenas com ele.Atlas se parece com isso:SearchPage.open ();
SearchPage.offersList().should(hasSizeGreaterThan(0));
Queremos que pelo menos um resultado seja exibido, caso contrário não iremos testá-lo. Em seguida, movemos o cursor para o elemento e depois clicamos nele.searchPage.offer(FIRST).moveCursor();
searchPage.offer(FIRST).actionBar().note().click();
Em seguida, salvamos na entrada User_Text e a enviamos .searchPage.offer(FIRST).addNoteInput().sendKeys(USER_TEXT);
searchPage.offer(FIRST).saveNote().click();
Depois disso, verificamos se o texto é exatamente o que deveria ter sido. searchPage.offer(FIRST).addNoteInput().should(hasValue(USER_TEXT));
Os testes são executados em um navegador, o Atlas é um proxy para este teste, aplicamos a mesma abordagem aqui que todos usam ao coletar a cobertura: faremos um localizador com .json. Salvaremos as informações sobre todas as aberturas de páginas, todas as iterações com elementos, quem enviou, quem enviou a chave, quem clicou, em quais IDs e assim por diante - manteremos um registro completo.Em seguida, anexamos esse log ao Allure na forma de cada teste e, quando temos muitos locators.json , geramos meta.json . O esquema é o mesmo para todos os elementos.Temos um plugin para o Google Chrome. Queríamos tomar uma decisão na forma de um plugin. Eu fiz especialmente uma captura de tela de curva para que um detalhe importante fosse visível no caminho do slide para locators.json . Se você gerou um relatório agora, existe um mapa de cobertura para hoje. Se você pegar o relatório das duas semanas anteriores e colá-lo aqui, um mapa de cobertura para o período de duas semanas atrás será exibido. Você tem uma máquina do tempo!No entanto, quando você conecta este plug-in, ele desenha uma interface não muito amigável.
Se você gerou um relatório agora, existe um mapa de cobertura para hoje. Se você pegar o relatório das duas semanas anteriores e colá-lo aqui, um mapa de cobertura para o período de duas semanas atrás será exibido. Você tem uma máquina do tempo!No entanto, quando você conecta este plug-in, ele desenha uma interface não muito amigável. Cada elemento possui vários testes que passam por ele: é claro que 40 testes passam por "compre um apartamento", o cabeçalho é testado um teste de cada vez, é legal, e a opção "apartamento" também é exibida. Você obtém um mapa de cobertura completo.Se você passar o mouse sobre algum elemento, ele pegará os dados e imprimirá seus testes reais a partir do seu tms, Allure Board e assim por diante. O resultado são informações completas sobre o que está sendo testado e como.Observe que em cada teste você pode falhar diretamente no relatório Allure.
Cada elemento possui vários testes que passam por ele: é claro que 40 testes passam por "compre um apartamento", o cabeçalho é testado um teste de cada vez, é legal, e a opção "apartamento" também é exibida. Você obtém um mapa de cobertura completo.Se você passar o mouse sobre algum elemento, ele pegará os dados e imprimirá seus testes reais a partir do seu tms, Allure Board e assim por diante. O resultado são informações completas sobre o que está sendo testado e como.Observe que em cada teste você pode falhar diretamente no relatório Allure. Quando você abre alguma coisa, ele carrega novos seletores: se você tiver algum teste que passe por esses seletores e fez alguma coisa com o site, ele processará e exibirá a imagem inteira.
Quando você abre alguma coisa, ele carrega novos seletores: se você tiver algum teste que passe por esses seletores e fez alguma coisa com o site, ele processará e exibirá a imagem inteira.Qual é o lucro?
Assim que implementamos essa abordagem simples, principalmente, começamos a entender o que testamos nos testes.
Agora qualquer um pode entrar e encontrar qualquer "thread" que leve ao script. Por exemplo, você assume que precisa testar o pagamento. O pagamento, obviamente, leva pelo botão de pagamento: clique - todos os testes que passam pelo botão de pagamento são exibidos. Isso é bom! Você entra em qualquer um deles e vê o script.Além disso, você entende o que foi testado antes. Geramos um arquivo estático, você pode especificar o caminho para ele e indicar quais testes foram realizados há duas semanas. Se o gerente disser que há um erro na produção e perguntar se testamos essa ou aquela funcionalidade há algumas semanas, você aceita o relatório Allure, por exemplo, por exemplo, que não o testou.Outro lucro é a revisão após testar a automação. Antes disso, fizemos uma revisão antes de testar a automação, agora você pode fazer seus testes exatamente como os vê. Se você queria fazer um teste - feito, fez uma ramificação, lançou o Allure, soltou o link do plug-in em um testador manual e pediu para ver os testes. Esse é exatamente o processo que permitirá fortalecer a estratégia Agile: o líder da equipe faz a revisão do código e os testadores manuais fazem seus testes (scripts).Outra vantagem dessa abordagem são os elementos usados com frequência. Se substituirmos esse bloco, no qual existem 87 testes, todos eles cairão. Você começa a entender o quão flack seus testes são. E se o bloco "preço de" for revertido, tudo bem, um teste cairá, uma pessoa o corrigirá. Se você alterar o bloco com 87 testes, a cobertura diminuirá consideravelmente, porque 87 testes não serão aprovados e não verificarão nenhum resultado. Esse bloco precisa de mais atenção. Então você precisa informar ao desenvolvedor que esse bloco deve estar com um ID, porque, se ele sair, tudo desmoronará.
E se o bloco "preço de" for revertido, tudo bem, um teste cairá, uma pessoa o corrigirá. Se você alterar o bloco com 87 testes, a cobertura diminuirá consideravelmente, porque 87 testes não serão aprovados e não verificarão nenhum resultado. Esse bloco precisa de mais atenção. Então você precisa informar ao desenvolvedor que esse bloco deve estar com um ID, porque, se ele sair, tudo desmoronará.Como você pode se desenvolver ainda mais?
Por exemplo, você pode seguir o caminho de desenvolvimento de suporte para outras ferramentas, por exemplo, para o Selenide. Eu gostaria mesmo de apoiar não um Selenide específico, mas uma implementação de driver que permita coletar localizadores, independentemente da ferramenta usada. Esse proxy despeja informações e as exibe.Outra idéia é exibir o resultado do teste atual. Por exemplo, é conveniente exibir imediatamente essa imagem para um testador manual: você não precisa pensar em quais testes foram interrompidos, pois pode ir ao site, clicar no teste e passá-lo manualmente sem verificar outros testes. Isso é fácil, você pode pegar essas informações da Allure e desenhá-las aqui.Você também pode adicionar a Pontuação total, porque todo mundo adora gráficos, porque eu quero lidar com testes duplicados muito parecidos entre si, cuja parte central é a mesma, e o começo e a cauda mudaram um pouco.
você não precisa pensar em quais testes foram interrompidos, pois pode ir ao site, clicar no teste e passá-lo manualmente sem verificar outros testes. Isso é fácil, você pode pegar essas informações da Allure e desenhá-las aqui.Você também pode adicionar a Pontuação total, porque todo mundo adora gráficos, porque eu quero lidar com testes duplicados muito parecidos entre si, cuja parte central é a mesma, e o começo e a cauda mudaram um pouco. Eu também gostaria de ver imediatamente o número de seletores duplicados. Se estiver alto, nesta página você precisará refatorar e executar testes, caso contrário, eles cairão em um pacote muito grande. O mesmo vale para o número de elementos com os quais interagimos. Este é um sintoma comum. No entanto, assim que você interagir com a página, a figura será ignorada devido a novos elementos e ao número total de casos de teste; portanto, você precisará adicionar algum tipo de análise, que não será supérflua.Você também pode adicionar a distribuição de testes por camadas, porque deseja ver não apenas que temos esses testes, mas todos os tipos de testes que estão nesta página, possivelmente até testes manuais.Portanto, se houver testes e testes Java no Puppeteer que outra equipe escreve, podemos olhar para uma página específica e dizer imediatamente onde nossos testes se cruzam. Ou seja, falaremos o mesmo idioma com eles e não precisaremos coletar essas informações pouco a pouco. Se tivermos uma ferramenta que mostra tudo na interface da Web, a tarefa de comparar testes em Java e Puppeteer não parece mais insolúvel.Finalmente, vamos falar sobre a estratégia geral. Já falamos sobre quais tipos de cobertura, denominados dois, criaram um terceiro tipo de revestimento, que usamos como resultado. Então, apenas analisamos esse problema de um ângulo diferente.
Eu também gostaria de ver imediatamente o número de seletores duplicados. Se estiver alto, nesta página você precisará refatorar e executar testes, caso contrário, eles cairão em um pacote muito grande. O mesmo vale para o número de elementos com os quais interagimos. Este é um sintoma comum. No entanto, assim que você interagir com a página, a figura será ignorada devido a novos elementos e ao número total de casos de teste; portanto, você precisará adicionar algum tipo de análise, que não será supérflua.Você também pode adicionar a distribuição de testes por camadas, porque deseja ver não apenas que temos esses testes, mas todos os tipos de testes que estão nesta página, possivelmente até testes manuais.Portanto, se houver testes e testes Java no Puppeteer que outra equipe escreve, podemos olhar para uma página específica e dizer imediatamente onde nossos testes se cruzam. Ou seja, falaremos o mesmo idioma com eles e não precisaremos coletar essas informações pouco a pouco. Se tivermos uma ferramenta que mostra tudo na interface da Web, a tarefa de comparar testes em Java e Puppeteer não parece mais insolúvel.Finalmente, vamos falar sobre a estratégia geral. Já falamos sobre quais tipos de cobertura, denominados dois, criaram um terceiro tipo de revestimento, que usamos como resultado. Então, apenas analisamos esse problema de um ângulo diferente.Por um lado, há uma cobertura que foi chutada desde 1963; por outro lado, há testadores manuais que estão acostumados a viver em um mundo mais real que o código. Resta apenas combinar essas duas abordagens.
Os interessados sempre podem se juntar à nossa comunidade. Aqui estão dois repositórios de nossa equipe que lidam com o problema de cobertura: