 Em outubro do ano passado, foi realizada a primeira conferência em nuvem Yandex Yandex Scale. Anunciou o lançamento de muitos novos serviços, incluindo o Yandex IoT Core, que permite trocar dados com milhões de dispositivos IoT.Neste artigo, falarei sobre por que o Yandex IoT Core é necessário e como ele funciona, bem como como ele pode interagir com outros serviços Yandex. Você aprenderá sobre a arquitetura, os meandros da interação dos componentes e os recursos da implementação da funcionalidade - tudo isso o ajudará a otimizar o uso desses serviços.Primeiro, vamos relembrar as principais vantagens das nuvens públicas e do PaaS - reduzindo o tempo e os custos de desenvolvimento, bem como os custos de suporte e infraestrutura, que também são relevantes para projetos de IoT. Mas existem alguns recursos úteis menos óbvios que você pode acessar na nuvem. Esse dimensionamento eficaz e tolerância a falhas são aspectos importantes ao trabalhar com dispositivos, especialmente em projetos de infraestrutura de informações críticas.Escala eficaz é a capacidade de aumentar ou diminuir livremente o número de dispositivos sem enfrentar problemas técnicos e observar uma mudança previsível no custo do sistema após as alterações.Tolerância a falhas é a confiança de que os serviços são projetados e implantados de forma a garantir o desempenho mais alto possível, mesmo no caso de uma falha de alguns recursos.Agora vamos entrar em detalhes.
Em outubro do ano passado, foi realizada a primeira conferência em nuvem Yandex Yandex Scale. Anunciou o lançamento de muitos novos serviços, incluindo o Yandex IoT Core, que permite trocar dados com milhões de dispositivos IoT.Neste artigo, falarei sobre por que o Yandex IoT Core é necessário e como ele funciona, bem como como ele pode interagir com outros serviços Yandex. Você aprenderá sobre a arquitetura, os meandros da interação dos componentes e os recursos da implementação da funcionalidade - tudo isso o ajudará a otimizar o uso desses serviços.Primeiro, vamos relembrar as principais vantagens das nuvens públicas e do PaaS - reduzindo o tempo e os custos de desenvolvimento, bem como os custos de suporte e infraestrutura, que também são relevantes para projetos de IoT. Mas existem alguns recursos úteis menos óbvios que você pode acessar na nuvem. Esse dimensionamento eficaz e tolerância a falhas são aspectos importantes ao trabalhar com dispositivos, especialmente em projetos de infraestrutura de informações críticas.Escala eficaz é a capacidade de aumentar ou diminuir livremente o número de dispositivos sem enfrentar problemas técnicos e observar uma mudança previsível no custo do sistema após as alterações.Tolerância a falhas é a confiança de que os serviços são projetados e implantados de forma a garantir o desempenho mais alto possível, mesmo no caso de uma falha de alguns recursos.Agora vamos entrar em detalhes.Arquitetura de script IoT
Primeiro de tudo, vamos ver como é a arquitetura geral do script da IoT. Duas partes grandes podem ser distinguidas:
Duas partes grandes podem ser distinguidas:- O primeiro é a entrega de dados para o armazenamento e a entrega de comandos para os dispositivos. Quando você constrói um sistema de IoT, essa tarefa deve ser resolvida em qualquer caso, independentemente do projeto que você faz.
- O segundo está trabalhando com os dados recebidos. Tudo é semelhante a qualquer outro projeto baseado na análise e visualização de conjuntos de dados. Você tem um repositório com uma matriz inicial de informações, trabalhando com a qual permitirá realizar sua tarefa.
A primeira parte é aproximadamente a mesma em todos os sistemas de IoT: ela é baseada em princípios gerais e se encaixa em um cenário comum adequado para a maioria dos sistemas de IoT.A segunda parte é quase sempre única em termos de funções executadas, embora seja construída sobre componentes padrão. Ao mesmo tempo, sem um sistema de interação de alta qualidade, tolerante a falhas e escalável com hardware, a eficácia da parte analítica da arquitetura é reduzida a quase zero, porque simplesmente não há nada a analisar.É por isso que a equipe do Yandex.Cloud decidiu, em primeiro lugar, concentrar-se na criação de um ecossistema conveniente de serviços que entregaria dados de maneira rápida, eficiente e confiável, dos dispositivos aos armazenamentos, e vice-versa - enviar comandos aos dispositivos. Para resolver esses problemas, estamos trabalhando na funcionalidade e integração dos serviços Yandex IoT Core, Yandex Functions e armazenamento de dados na nuvem:
Para resolver esses problemas, estamos trabalhando na funcionalidade e integração dos serviços Yandex IoT Core, Yandex Functions e armazenamento de dados na nuvem:- O serviço Yandex IoT Core é um broker MQTT escalonável e seguro para falhas de vários inquilinos com um conjunto de funções úteis adicionais.
- O serviço Yandex Cloud Functions é um representante da direção promissora sem servidor e permite que você execute seu código como uma função em um ambiente seguro, tolerante a falhas e escalável automaticamente sem criar e manter máquinas virtuais.
- O Yandex Object Storage é um armazenamento eficaz de grandes matrizes de dados e é muito adequado para registros de arquivamento "históricos".
- , , Yandex Managed Service for ClickHouse, «» . «» , , , .
Se os serviços de armazenamento e análise de dados são serviços de "uso geral" já escritos sobre muito, o Yandex IoT Core e sua interação com o Yandex Cloud Functions geralmente causam muitas perguntas, especialmente para pessoas que estão começando a entender a Internet sobre coisas e tecnologias em nuvem. E como esses serviços oferecem tolerância a falhas e redimensionamento do trabalho com dispositivos, veremos primeiro o que eles têm sob o capô.Como o Yandex IoT Core funciona
O Yandex IoT Core é um serviço de plataforma especializado para troca de dados bidirecional entre a nuvem e os dispositivos que executam o protocolo MQTT. De fato, esse protocolo se tornou o padrão para a transferência de dados para a IoT. Ele usa o conceito de filas nomeadas (tópicos), onde, por um lado, é possível gravar dados e, por outro lado, recebê-los de forma assíncrona, assinando os eventos dessa fila.O serviço Yandex IoT Core é multilocatário, o que significa uma única entidade acessível a todos os usuários. Ou seja, todos os dispositivos e todos os usuários interagem com a mesma instância de serviço.Isso permite, por um lado, garantir uniformidade de trabalho para todos os usuários, por outro lado, escala eficaz e tolerância a falhas, a fim de manter uma conexão com um número ilimitado de dispositivos e processar uma quantidade ilimitada de dados em volume e velocidade.Daqui resulta que o serviço deve ter mecanismos de redundância e capacidade de gerenciar de forma flexível os recursos utilizados - para responder às alterações de carga.Além disso, a multilocação exige uma lógica especial de compartilhamento de direitos de acesso aos tópicos do MQTT.Vamos ver como isso é implementado.Como muitos outros serviços Yandex.Cloud, o Yandex IoT Core é logicamente dividido em duas partes - Plano de Controle e Plano de Dados: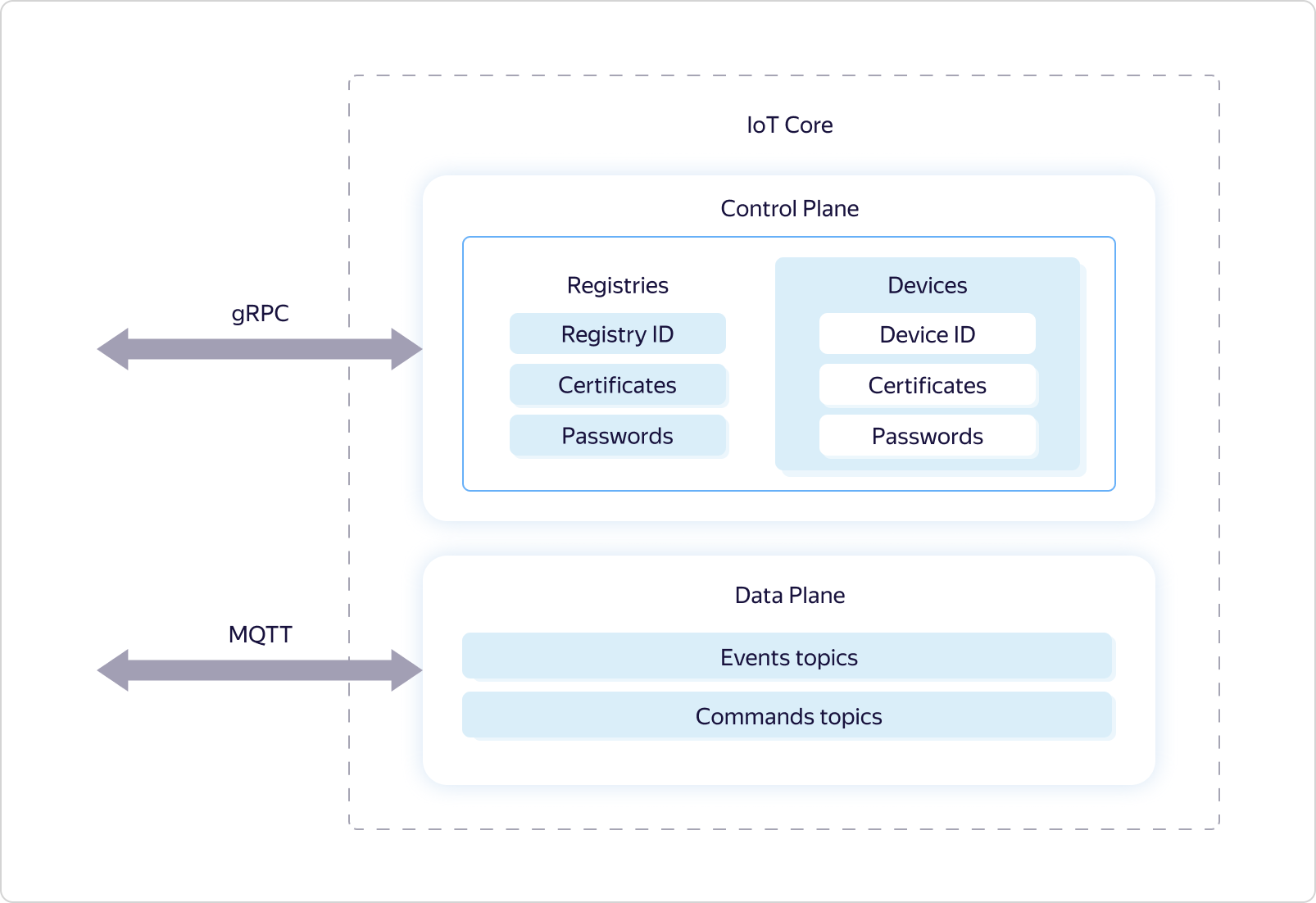 O Data Plane é responsável pela lógica de operação sob o protocolo MQTT e o Control Plane é responsável por delimitar os direitos de acesso a determinados tópicos e usa o registro e o dispositivo de entidades lógicas para esse fim.
O Data Plane é responsável pela lógica de operação sob o protocolo MQTT e o Control Plane é responsável por delimitar os direitos de acesso a determinados tópicos e usa o registro e o dispositivo de entidades lógicas para esse fim. Cada usuário do Yandex.Cloud pode ter vários registros, cada um dos quais pode conter seu próprio subconjunto de dispositivos.O acesso aos tópicos é fornecido da seguinte maneira: Os
Cada usuário do Yandex.Cloud pode ter vários registros, cada um dos quais pode conter seu próprio subconjunto de dispositivos.O acesso aos tópicos é fornecido da seguinte maneira: Os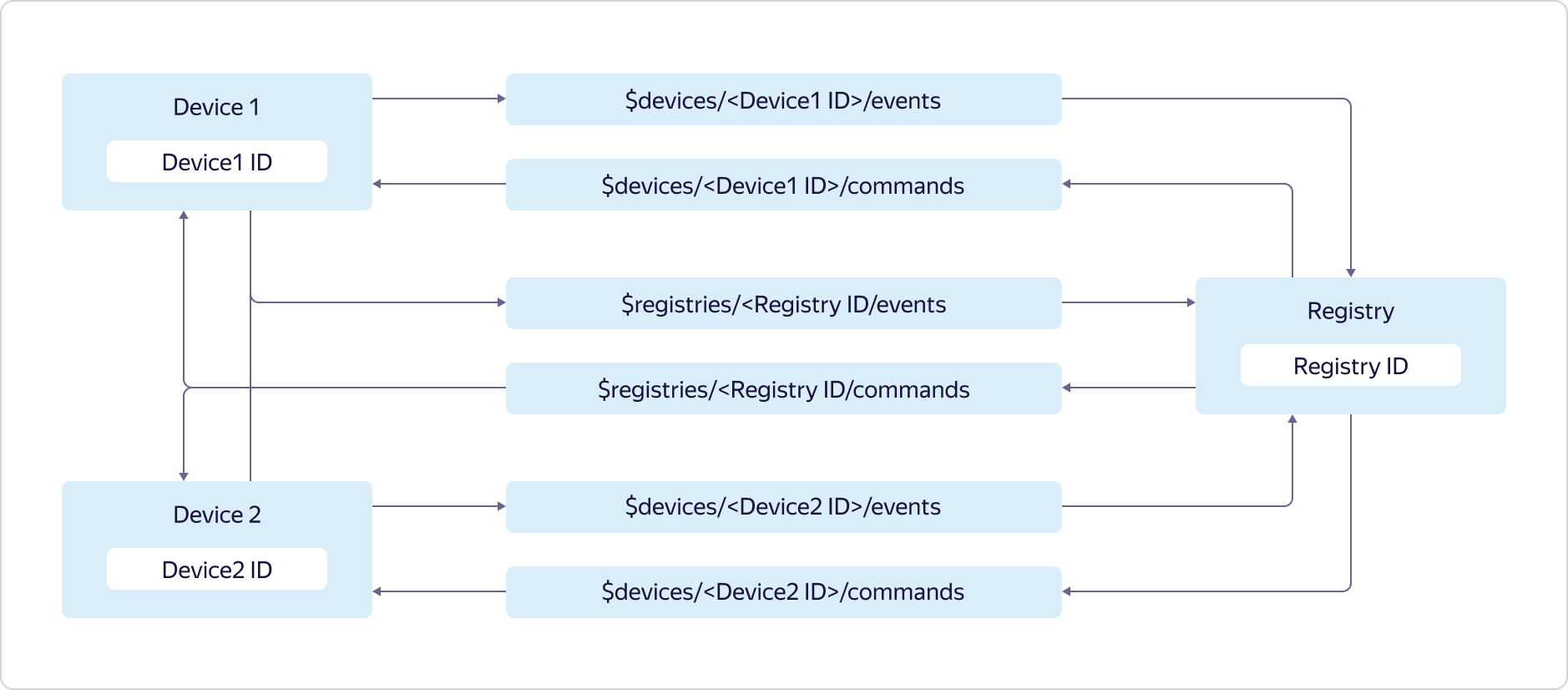 dispositivos podem enviar dados apenas para o tópico de eventos e o evento de registro:
dispositivos podem enviar dados apenas para o tópico de eventos e o evento de registro:$devices/<Device1 ID>/events
$registries/<Registry ID>/events
e assine apenas mensagens do seu tópico de comandos e do tópico de comandos do registro:$devices/<Device1 ID>/commands
$registries/<Registry ID>/commands
O registro pode enviar dados para todos os tópicos de comandos do dispositivo e para o tópico de comandos do registro:$devices/<Device1 ID>/commands
$devices/<Device2 ID>/commands
$registries/<Registry ID>/commands
e assine mensagens de todos os tópicos de eventos do dispositivo e o tópico de eventos do registro:$devices/<Device1 ID>/events
$devices/<Device2 ID>/events
$registries/<Registry ID>/events
Para trabalhar com todas as entidades descritas acima, o Data Plane possui um protocolo gRPC e um protocolo REST, com base no qual o acesso é implementado por meio do console da GUI do Yandex.Cloud e da interface da linha de comandos da CLI.Quanto ao Data Plane, ele suporta o protocolo MQTT versão 3.1.1. No entanto, existem vários recursos:- Ao conectar, certifique-se de usar o TLS.
- Somente conexão TCP é suportada. O WebSocket ainda não está disponível.
- A autorização está disponível por login e senha (em que o login é o ID do dispositivo ou registro, e as senhas são definidas pelo usuário) e usando certificados.
- O sinalizador Reter não é suportado, ao usar o qual o broker do MQTT salva a mensagem marcada com o sinalizador e a envia na próxima vez que você assina o tópico.
- A Sessão Persistente não é suportada, na qual o broker do MQTT salva informações sobre o cliente (dispositivo ou registro) para facilitar a reconexão.
- Com a assinatura e publicação, apenas os dois primeiros níveis de serviço são suportados:
- QoS0 - No máximo uma vez. Não há garantia de entrega, mas não há devolução da mesma mensagem.
- QoS1 - pelo menos uma vez. A entrega é garantida, mas há uma chance de receber novamente a mesma mensagem.
Para simplificar a conexão com o Yandex IoT Core, adicionamos regularmente novos exemplos para diferentes plataformas e idiomas ao nosso repositório no GitHub, e também descrevemos scripts na documentação.A arquitetura do serviço é assim: A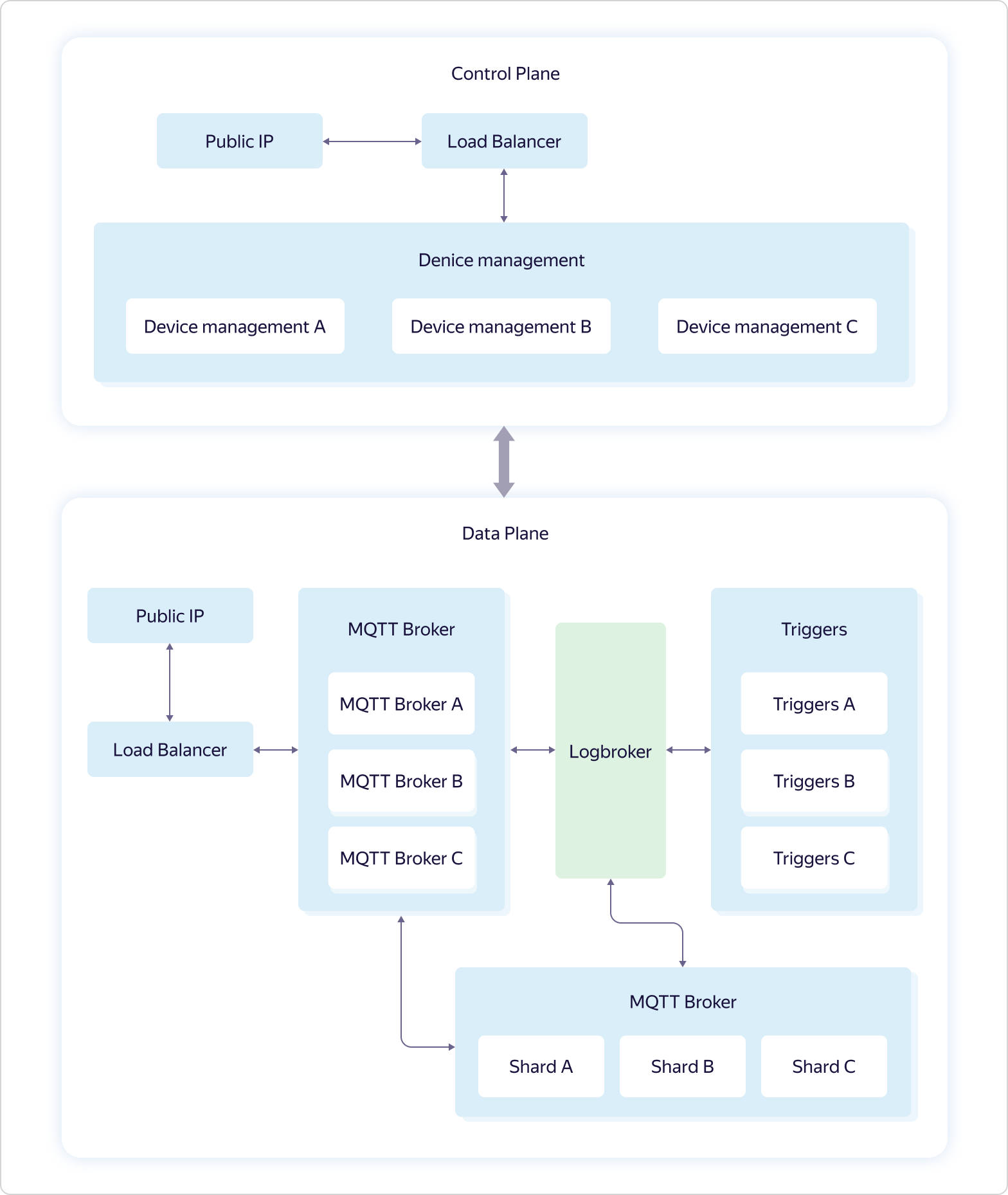 lógica de negócios do serviço inclui quatro partes:
lógica de negócios do serviço inclui quatro partes:- Device management — . Control Plane.
- MQTT Broker — MQTT-. Data Plane.
- Triggers — Yandex Cloud Functions. Data Plane.
- Shards — MQTT- . Data Plane.
Toda interação com o "mundo exterior" passa por balanceadores de carga. Além disso, de acordo com a filosofia de alimentação de cães, o Yandex Load Balancer é usado, disponível para todos os usuários do Yandex.Cloud.Cada parte da lógica de negócios consiste em vários conjuntos de três máquinas virtuais - uma em cada zona de disponibilidade (nos Esquemas A, B e C). Máquinas virtuais são exatamente iguais a todos os usuários do Yandex.Cloud. Quando a carga aumenta, o dimensionamento ocorre com a ajuda de todo o conjunto - três máquinas são adicionadas ao mesmo tempo na estrutura de uma parte da lógica de negócios. Isso significa que, se um conjunto de três máquinas MQTT Broker não puder manipular a carga, outro conjunto de três máquinas MQTT Broker será incluído, enquanto a configuração de outras partes da lógica de negócios permanecerá a mesma.E apenas o Logbroker não está disponível ao público. É um serviço para operação eficiente e à prova de falhas com fluxos de dados. Ele é baseado no Apache Kafka, mas possui muitas outras funções úteis: implementa processos de recuperação de desastres (incluindo exatamente a semântica única quando você tem uma garantia de entrega de mensagens sem duplicação) e processos de serviço (como replicação entre centros, distribuição de dados para clusters de cálculo) e também possui um mecanismo para distribuição uniforme e não duplicada de dados entre os assinantes de fluxo - uma espécie de balanceador de carga.Os recursos de gerenciamento de dispositivos no Plano de controle estão descritos acima. Mas com o Data Plane, tudo é muito mais interessante.Cada instância do MQTT Broker funciona independentemente e não sabe nada sobre outras instâncias. Todos os dados recebidos (publicação dos clientes) são enviados pelos corretores para a Logbroker, de onde são coletados pelos Shards and Triggers. E é nos shards que a sincronização ocorre entre instâncias de corretores. Os shards conhecem todos os clientes MQTT e a distribuição de suas assinaturas (assinatura) entre instâncias de intermediários MQTT e determinam para onde enviar os dados recebidos.Por exemplo, o cliente MQTT A é inscrito no tópico do intermediário A e o cliente MQTT B é inscrito no mesmo tópico do intermediário B. Se o cliente MQTT C publica no mesmo tópico, mas no intermediário C, o shard transfere dados de intermediário C para os corretores A e B, como resultado dos quais os dados serão recebidos pelos clientes MQTT A e MQTT B.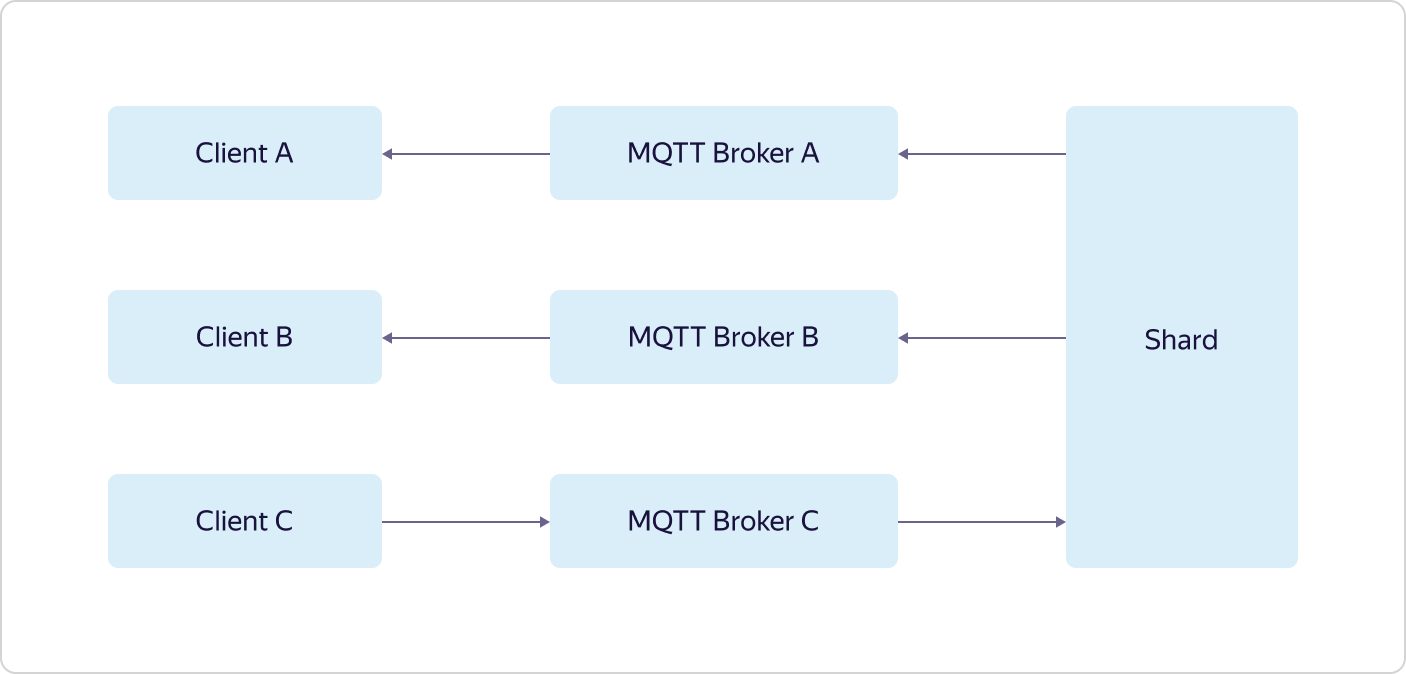 A última parte da lógica de negócios, Triggers, também recebe todos os dados recebidos dos clientes MQTT e, se isso estiver configurado pelo usuário, transfere-os para os acionadores do serviço Yandex Cloud Functions.Como você pode ver, o Yandex IoT Core possui uma arquitetura e lógica de trabalho bastante complicadas, difíceis de repetir em instalações locais. Isso permite que ele resista à perda de até duas das três zonas de disponibilidade e elabore um número ilimitado de conexões e volumes de dados ilimitados.Além disso, toda essa lógica está oculta do usuário "por baixo do capô", mas do lado de fora tudo parece muito simples - como se você estivesse trabalhando com um único broker MQTT.
A última parte da lógica de negócios, Triggers, também recebe todos os dados recebidos dos clientes MQTT e, se isso estiver configurado pelo usuário, transfere-os para os acionadores do serviço Yandex Cloud Functions.Como você pode ver, o Yandex IoT Core possui uma arquitetura e lógica de trabalho bastante complicadas, difíceis de repetir em instalações locais. Isso permite que ele resista à perda de até duas das três zonas de disponibilidade e elabore um número ilimitado de conexões e volumes de dados ilimitados.Além disso, toda essa lógica está oculta do usuário "por baixo do capô", mas do lado de fora tudo parece muito simples - como se você estivesse trabalhando com um único broker MQTT.Acionadores e funções da nuvem Yandex
O Yandex Cloud Functions é um representante dos serviços "sem servidor" (sem servidor) no Yandex.Cloud. A principal essência desses serviços é que o usuário não gasta seu tempo configurando, implantando e dimensionando o ambiente para executar código, mas apenas lida com a coisa mais valiosa para ele - escrever o próprio código que executa a tarefa necessária. No caso de funções, esse é o chamado código sem estado atômico que pode ser acionado por algum evento. "Atômico" e "sem estado" significam que esse código deve executar uma tarefa relativamente pequena, mas integral, enquanto o código não deve usar nenhuma variável para armazenar valores entre as chamadas.Existem várias maneiras de chamar funções: uma chamada HTTP direta, uma chamada de timer (cron) ou uma assinatura de evento. Como o último, o serviço já suporta a inscrição em filas de mensagens (fila de mensagens Yandex), eventos gerados pelo serviço de armazenamento de objetos e (mais valioso para o cenário da IoT) a assinatura de mensagens no Yandex IoT Core.Apesar de você poder trabalhar com o Yandex IoT Core usando qualquer cliente compatível com MQTT, o Yandex Cloud Functions é uma das maneiras mais ótimas e convenientes de receber e processar dados. A razão para isso é muito simples. Uma função pode ser chamada em todas as mensagens recebidas de qualquer dispositivo, e as funções serão executadas paralelamente umas às outras (devido à atomicidade e à abordagem sem estado), e o número de suas chamadas mudará naturalmente à medida que o número de mensagens recebidas dos dispositivos for alterado. Assim, o usuário pode ignorar completamente os problemas de configuração da infraestrutura e, além disso, diferentemente das mesmas máquinas virtuais, o pagamento ocorrerá apenas pelo trabalho realmente executado.Isso permitirá que você economize significativamente em baixa carga e obtenha um custo claro e previsível com o crescimento.O mecanismo para chamar funções em eventos (assinar eventos) é chamado de gatilho (Trigger). Sua essência está representada no diagrama: Um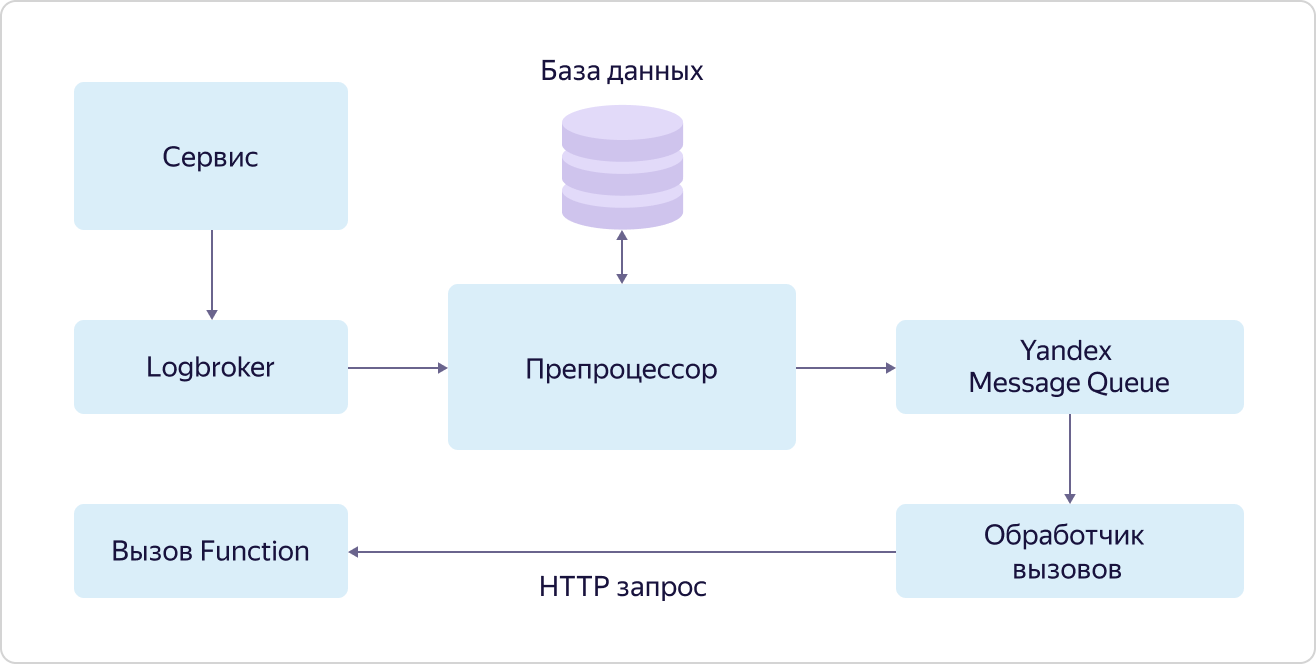 serviço que gera eventos para chamar funções os coloca em uma fila no Logbroker. No caso do Yandex IoT Core, os gatilhos do Data Plane fazem isso. Além disso, esses eventos são realizados pelo pré-processador, que está procurando um registro no banco de dados para esse evento, indicando a função a ser chamada. Se uma entrada desse tipo for encontrada, o pré-processador coloca as informações sobre a chamada de função (ID da função e parâmetros de chamada) na fila no serviço Fila de Mensagens Yandex, de onde o manipulador de chamadas as coleta. O manipulador, por sua vez, envia uma solicitação HTTP para chamar a função para o serviço Yandex Cloud Functions.Ao mesmo tempo, novamente, de acordo com a filosofia dogfooding, o serviço Yandex Message Queue, acessível a todos os usuários, é usado e as funções são chamadas exatamente da mesma maneira que qualquer outro usuário pode chamar suas funções.Digamos algumas palavras sobre a fila de mensagens Yandex. Apesar de esse, como o Logbroker, ser um serviço de fila, há uma diferença significativa entre eles. Ao processar mensagens de filas, o manipulador informa a fila que terminou e a mensagem pode ser excluída. Esse é um importante mecanismo de confiabilidade em tais serviços, mas complica a lógica de trabalhar com mensagens.A Fila de mensagens Yandex permite "paralelizar" o processamento de cada mensagem na fila. Em outras palavras, a mensagem da fila que está sendo processada atualmente não bloqueia a possibilidade de outro "encadeamento" pegar o próximo evento da fila para processamento. Isso é chamado simultaneidade no nível da mensagem.E o LogBroker opera em grupos de mensagens e, até que todo o grupo seja processado, o próximo grupo não poderá ser escolhido para processamento. Essa abordagem é chamada simultaneidade no nível da partição.E é precisamente o uso da fila de mensagens Yandex que permite processar de forma rápida e eficiente em paralelo muitas solicitações para chamar uma função para eventos de um serviço específico.Apesar de os acionadores serem uma unidade independente separada, eles fazem parte do serviço Yandex Cloud Functions. Nós apenas temos que descobrir exatamente como as funções são chamadas.
serviço que gera eventos para chamar funções os coloca em uma fila no Logbroker. No caso do Yandex IoT Core, os gatilhos do Data Plane fazem isso. Além disso, esses eventos são realizados pelo pré-processador, que está procurando um registro no banco de dados para esse evento, indicando a função a ser chamada. Se uma entrada desse tipo for encontrada, o pré-processador coloca as informações sobre a chamada de função (ID da função e parâmetros de chamada) na fila no serviço Fila de Mensagens Yandex, de onde o manipulador de chamadas as coleta. O manipulador, por sua vez, envia uma solicitação HTTP para chamar a função para o serviço Yandex Cloud Functions.Ao mesmo tempo, novamente, de acordo com a filosofia dogfooding, o serviço Yandex Message Queue, acessível a todos os usuários, é usado e as funções são chamadas exatamente da mesma maneira que qualquer outro usuário pode chamar suas funções.Digamos algumas palavras sobre a fila de mensagens Yandex. Apesar de esse, como o Logbroker, ser um serviço de fila, há uma diferença significativa entre eles. Ao processar mensagens de filas, o manipulador informa a fila que terminou e a mensagem pode ser excluída. Esse é um importante mecanismo de confiabilidade em tais serviços, mas complica a lógica de trabalhar com mensagens.A Fila de mensagens Yandex permite "paralelizar" o processamento de cada mensagem na fila. Em outras palavras, a mensagem da fila que está sendo processada atualmente não bloqueia a possibilidade de outro "encadeamento" pegar o próximo evento da fila para processamento. Isso é chamado simultaneidade no nível da mensagem.E o LogBroker opera em grupos de mensagens e, até que todo o grupo seja processado, o próximo grupo não poderá ser escolhido para processamento. Essa abordagem é chamada simultaneidade no nível da partição.E é precisamente o uso da fila de mensagens Yandex que permite processar de forma rápida e eficiente em paralelo muitas solicitações para chamar uma função para eventos de um serviço específico.Apesar de os acionadores serem uma unidade independente separada, eles fazem parte do serviço Yandex Cloud Functions. Nós apenas temos que descobrir exatamente como as funções são chamadas. Todas as solicitações para chamar funções (externas e internas) se enquadram no balanceador de carga, que as distribui para roteadores em diferentes zonas de acesso (AZ), várias partes são implantadas em cada zona. Ao receber uma solicitação, o roteador vai primeiro ao serviço Gerenciador de Identidade e Acesso (IAM) para garantir que a origem da solicitação tenha direitos para chamar essa função. Ele então vira para o agendador e pergunta em qual trabalhador executar a função. Worker é uma máquina virtual com um tempo de execução personalizado de funções isoladas. Além disso, o roteador, tendo recebido do agendador o endereço do trabalhador no qual executar a função, envia um comando para esse trabalhador para iniciar a função com determinados parâmetros.De onde vem o trabalhador? É aqui que toda a magia sem servidor acontece. Agendadores, analisando a carga (o número e a duração das funções), gerenciam (iniciam e param) máquinas virtuais com um tempo de execução específico. NodeJS e Python agora são suportados. E aqui um parâmetro é extremamente importante - a velocidade das funções de inicialização. A equipe de desenvolvimento de serviços fez um ótimo trabalho e agora a máquina virtual inicia no máximo 250 ms, enquanto usa o ambiente mais seguro para isolar funções uma da outra - a virtualização QEMU, que executa todo o Yandex. Ao mesmo tempo, se já houver um trabalhador ativo para a solicitação recebida, a função será iniciada quase instantaneamente.E, de acordo com a mesma abordagem de dogfooding, o Load Balancer usa um serviço público acessível a todos os usuários, e o trabalhador, o planejador e o roteador são máquinas virtuais comuns, iguais a todos os usuários.Assim, a tolerância a falhas do serviço é implementada no nível do balanceador de carga e redundância dos principais componentes do sistema (roteador e planejador), e o dimensionamento ocorre devido à implantação ou redução do número de trabalhadores. Além disso, cada zona de acessibilidade funciona de forma independente, o que permite sobreviver à perda de até duas das três zonas.
Todas as solicitações para chamar funções (externas e internas) se enquadram no balanceador de carga, que as distribui para roteadores em diferentes zonas de acesso (AZ), várias partes são implantadas em cada zona. Ao receber uma solicitação, o roteador vai primeiro ao serviço Gerenciador de Identidade e Acesso (IAM) para garantir que a origem da solicitação tenha direitos para chamar essa função. Ele então vira para o agendador e pergunta em qual trabalhador executar a função. Worker é uma máquina virtual com um tempo de execução personalizado de funções isoladas. Além disso, o roteador, tendo recebido do agendador o endereço do trabalhador no qual executar a função, envia um comando para esse trabalhador para iniciar a função com determinados parâmetros.De onde vem o trabalhador? É aqui que toda a magia sem servidor acontece. Agendadores, analisando a carga (o número e a duração das funções), gerenciam (iniciam e param) máquinas virtuais com um tempo de execução específico. NodeJS e Python agora são suportados. E aqui um parâmetro é extremamente importante - a velocidade das funções de inicialização. A equipe de desenvolvimento de serviços fez um ótimo trabalho e agora a máquina virtual inicia no máximo 250 ms, enquanto usa o ambiente mais seguro para isolar funções uma da outra - a virtualização QEMU, que executa todo o Yandex. Ao mesmo tempo, se já houver um trabalhador ativo para a solicitação recebida, a função será iniciada quase instantaneamente.E, de acordo com a mesma abordagem de dogfooding, o Load Balancer usa um serviço público acessível a todos os usuários, e o trabalhador, o planejador e o roteador são máquinas virtuais comuns, iguais a todos os usuários.Assim, a tolerância a falhas do serviço é implementada no nível do balanceador de carga e redundância dos principais componentes do sistema (roteador e planejador), e o dimensionamento ocorre devido à implantação ou redução do número de trabalhadores. Além disso, cada zona de acessibilidade funciona de forma independente, o que permite sobreviver à perda de até duas das três zonas.Links Úteis
Concluindo, desejo fornecer alguns links que permitirão estudar os serviços com mais detalhes: