Olá, hoje eu gostaria de falar sobre a minha experiência na análise de ações do Sberbank. Às vezes, mostram dinâmicas ligeiramente diferentes - tornou-se interessante para mim analisar o movimento de suas citações.Neste exemplo, baixaremos cotações do site da Finam. Link para download regular do Sberbank .Para operações de coluna, usarei pandas, para visualização matplotlib.Nós importamos:import pandas as pd
import matplotlib.pyplot as plt
Para impedir que as tabelas diminuam, você deve remover as restrições:pd.set_option('display.max_columns', None)
pd.set_option('display.expand_frame_repr', False)
pd.set_option('max_colwidth', 80)
pd.set_option('max_rows', 6000)
Ler dados de estoque
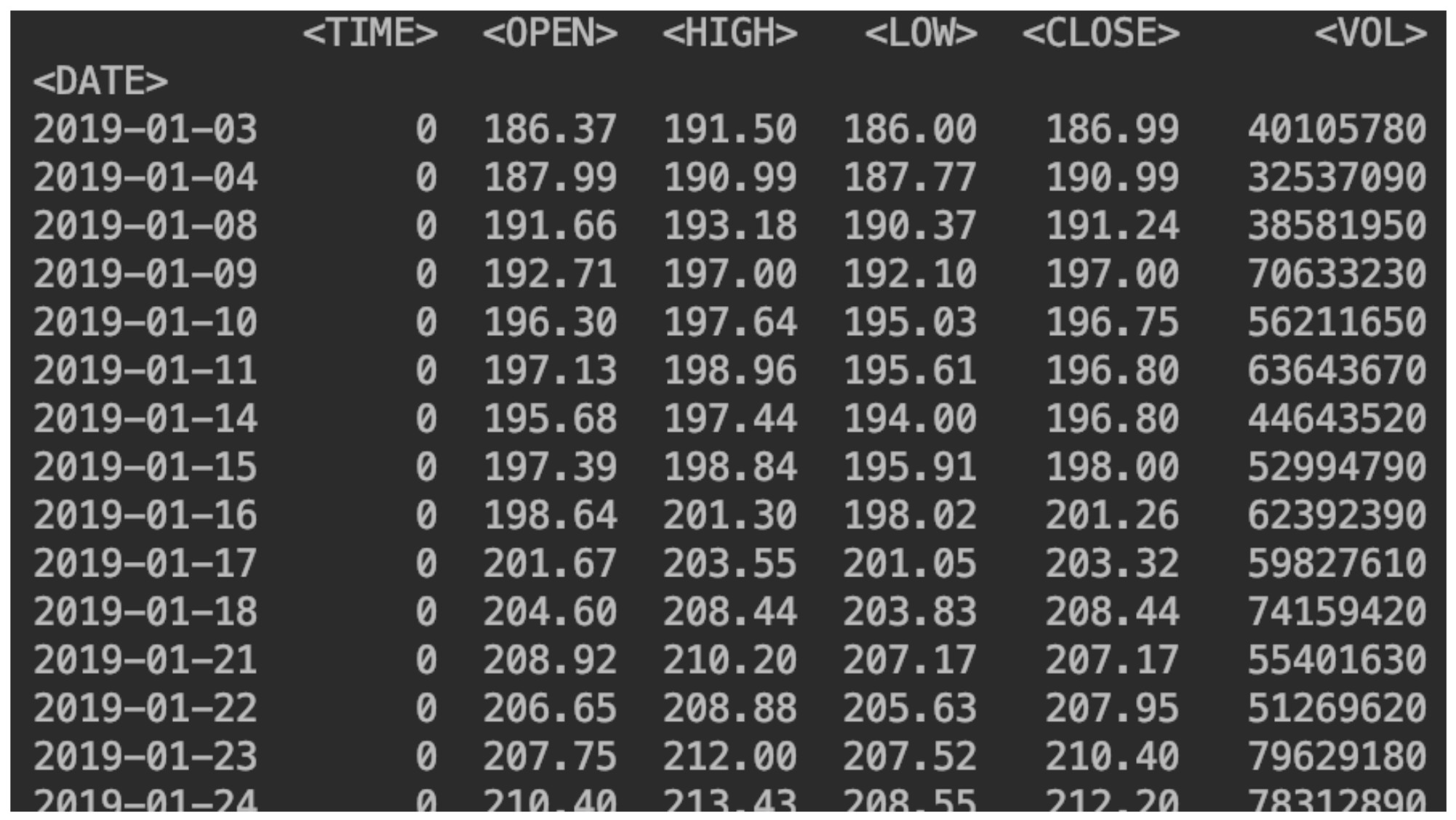
df = pd.read_csv("SBER_190101_200105.csv",sep=';', header=0, index_col='<DATE>', parse_dates=True)
(especifique o separador, onde os nomes das colunas estão localizados, qual coluna será o índice, ative a análise de data).Indique também a classificação:df = df.sort_values(by='<DATE>')
Exibimos nossos dados:print(df)
 Adicione uma coluna com uma alteração de preço
Adicione uma coluna com uma alteração de preçodf['returns']=(df['<CLOSE>']/df['<CLOSE>'].shift(1))-1
Portanto, é possível derivar exatamente a porcentagem:df['returns_pers']=((df['<CLOSE>']/df['<CLOSE>'].shift(1))-1)*100

Adicione um segundo compartilhamento
Faça exatamente da mesma maneira.df2 = pd.read_csv("SBERP_190101_200105.csv",sep=';', header=0, index_col='<DATE>', parse_dates=True)
df = df.sort_values(by='<DATE>')
df2['returns_pers']=((df2['<CLOSE>']/df2['<CLOSE>'].shift(1))-1)*100
df2['returns']=(df2['<CLOSE>']/df2['<CLOSE>'].shift(1))-1
print(df2)
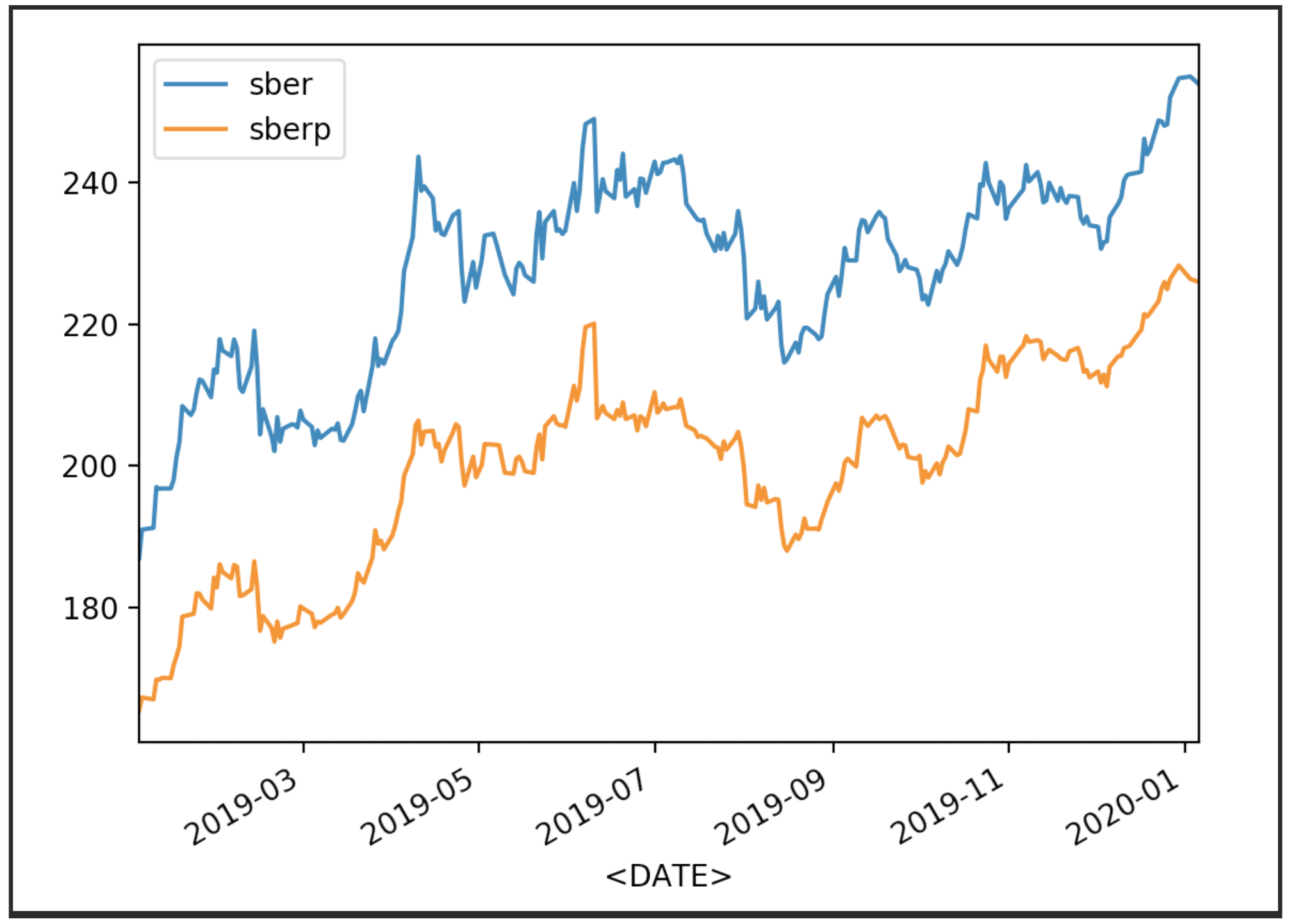
Visualizamos nossas cotações de ações
df['<CLOSE>'].plot(label='sber')
df2['<CLOSE>'].plot(label='sberp')
plt.legend()
plt.show()
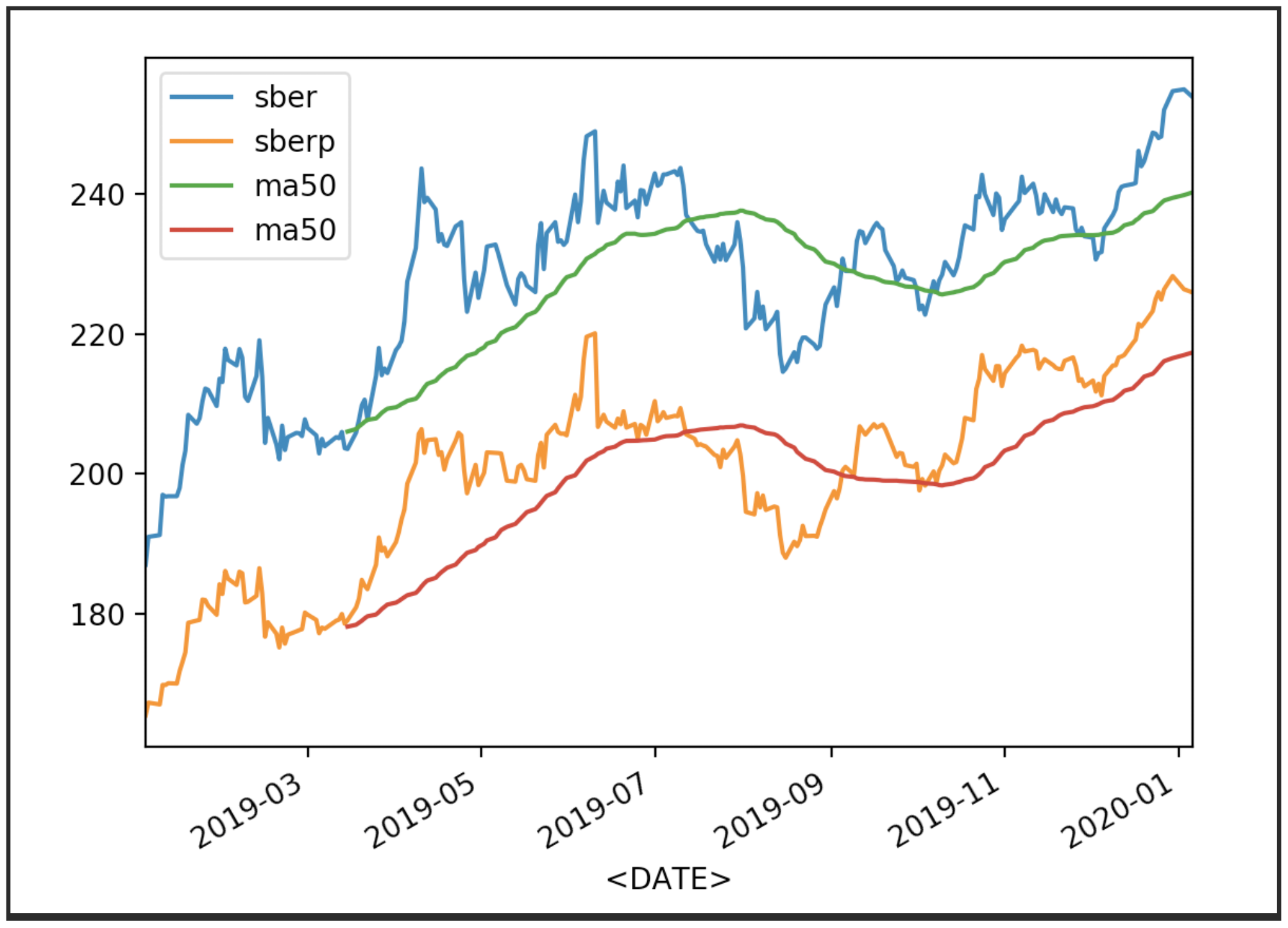
 Agora exiba as cotações com sua média (MA 50):
Agora exiba as cotações com sua média (MA 50):df['<CLOSE>'].plot(label='sber')
df2['<CLOSE>'].plot(label='sberp')
df['ma50'] = df['<OPEN>'].rolling(50).mean().plot(label='ma50')
df2['ma50'] = df2['<OPEN>'].rolling(50).mean().plot(label='ma50')
plt.legend()
plt.show()
 Outras médias também podem ser exibidas.
Outras médias também podem ser exibidas.df['<CLOSE>'].plot(label='sber')
df2['<CLOSE>'].plot(label='sberp')
df['ma100'] = df['<OPEN>'].rolling(100).mean().plot(label='ma100')
df2['ma100'] = df2['<OPEN>'].rolling(100).mean().plot(label='ma100')
plt.legend()
plt.show()
 Agora, exibiremos a rotatividade dos compartilhamentos:adicione também o nome do eixo Ye o tamanho da tela
Agora, exibiremos a rotatividade dos compartilhamentos:adicione também o nome do eixo Ye o tamanho da teladf['total_trade'] = df['<OPEN>']*df['<VOL>']
df2['total_trade'] = df2['<OPEN>']*df2['<VOL>']
df['total_trade'].plot(label='sber',figsize=(16,8))
df2['total_trade'].plot(label='sberp',figsize=(16,8))
plt.legend()
plt.ylabel('Total Traded')
plt.show()

Análise de correlação
Agora vamos dar uma olhada mais de perto na correlação. um gráfico de matriz nos ajudará nisso:crie uma nova tabela com colunas para os dois estoques e dê nomes a eles.all_sber = pd.concat([df['<OPEN>'],df2['<OPEN>']],axis=1)
all_sber.columns = ['sber_open','sberp_open']
print(all_sber)
 Agora importamos a programação necessária
Agora importamos a programação necessáriafrom pandas.plotting import scatter_matrix
E produza:scatter_matrix(all_sber,figsize=(8,8),alpha=0.2,hist_kwds={'bins':100});
plt.show()
Deve-se esclarecer que precisamos adicionar transparência (alfa = 0,2) para ver a sobreposição de pontos.Se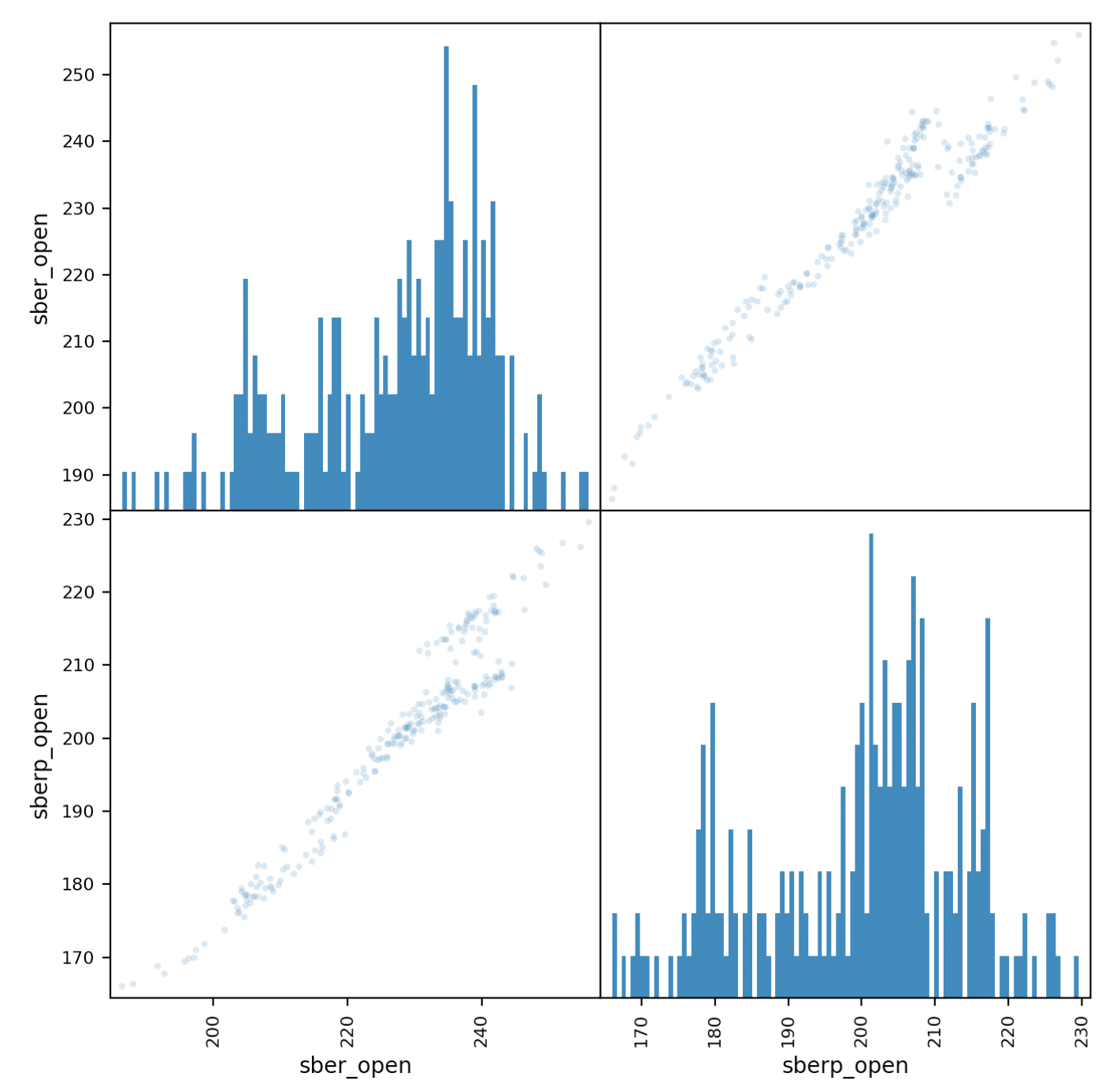 os pontos "vão" ao longo da diagonal, é observada uma correlação.
os pontos "vão" ao longo da diagonal, é observada uma correlação.Avaliação da volatilidade dos valores mobiliários
df['returns_pers'].plot(label='sber')
df2['returns_pers'].plot(label='sberp')
plt.legend()
plt.show()
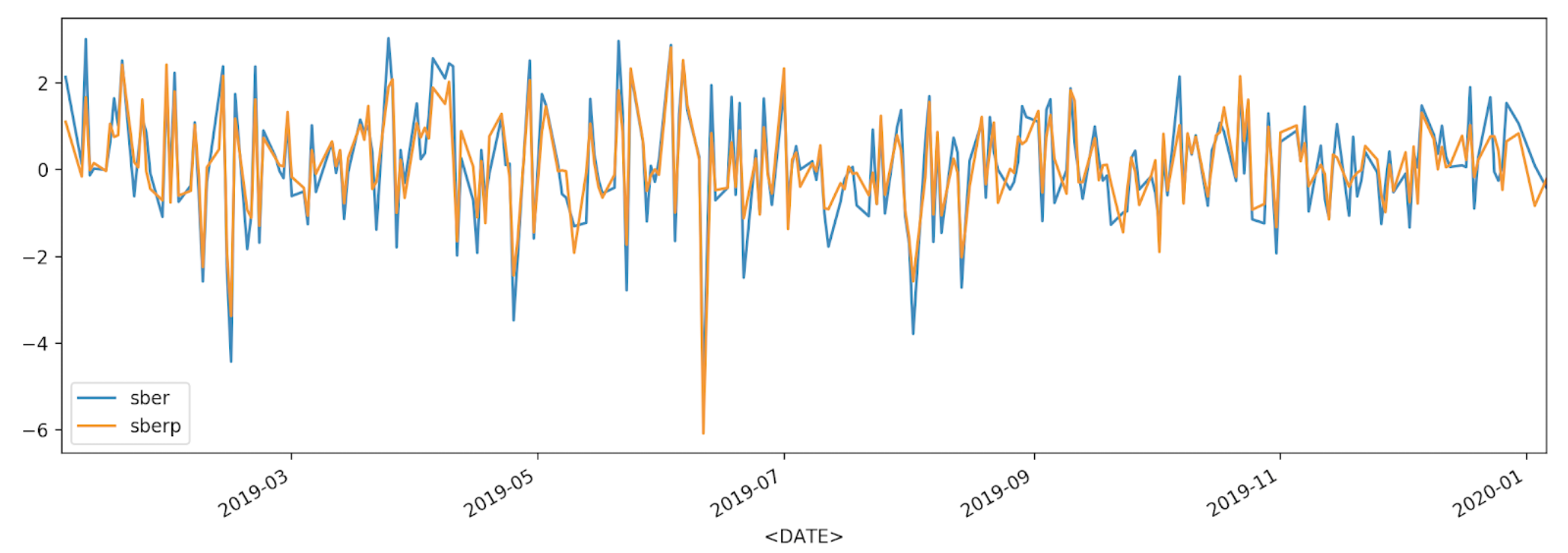 Para uma melhor compreensão, exibiremos a volatilidade em outro gráfico - um histograma
Para uma melhor compreensão, exibiremos a volatilidade em outro gráfico - um histogramadf['returns_pers'].hist(bins=100,label='sber',alpha=0.5)
df2['returns_pers'].hist(bins=100,label='sberp',alpha=0.5)
plt.legend()
plt.show()
 Para fazer uma conclusão mais rápida, você pode simplificar o cronograma (tornaremos o gráfico menos detalhado e menos transparente):
Para fazer uma conclusão mais rápida, você pode simplificar o cronograma (tornaremos o gráfico menos detalhado e menos transparente):df['returns_pers'].hist(bins=10,label='sber',alpha=0.9)
df2['returns_pers'].hist(bins=10,label='sberp',alpha=0.9)
plt.legend()
plt.show()
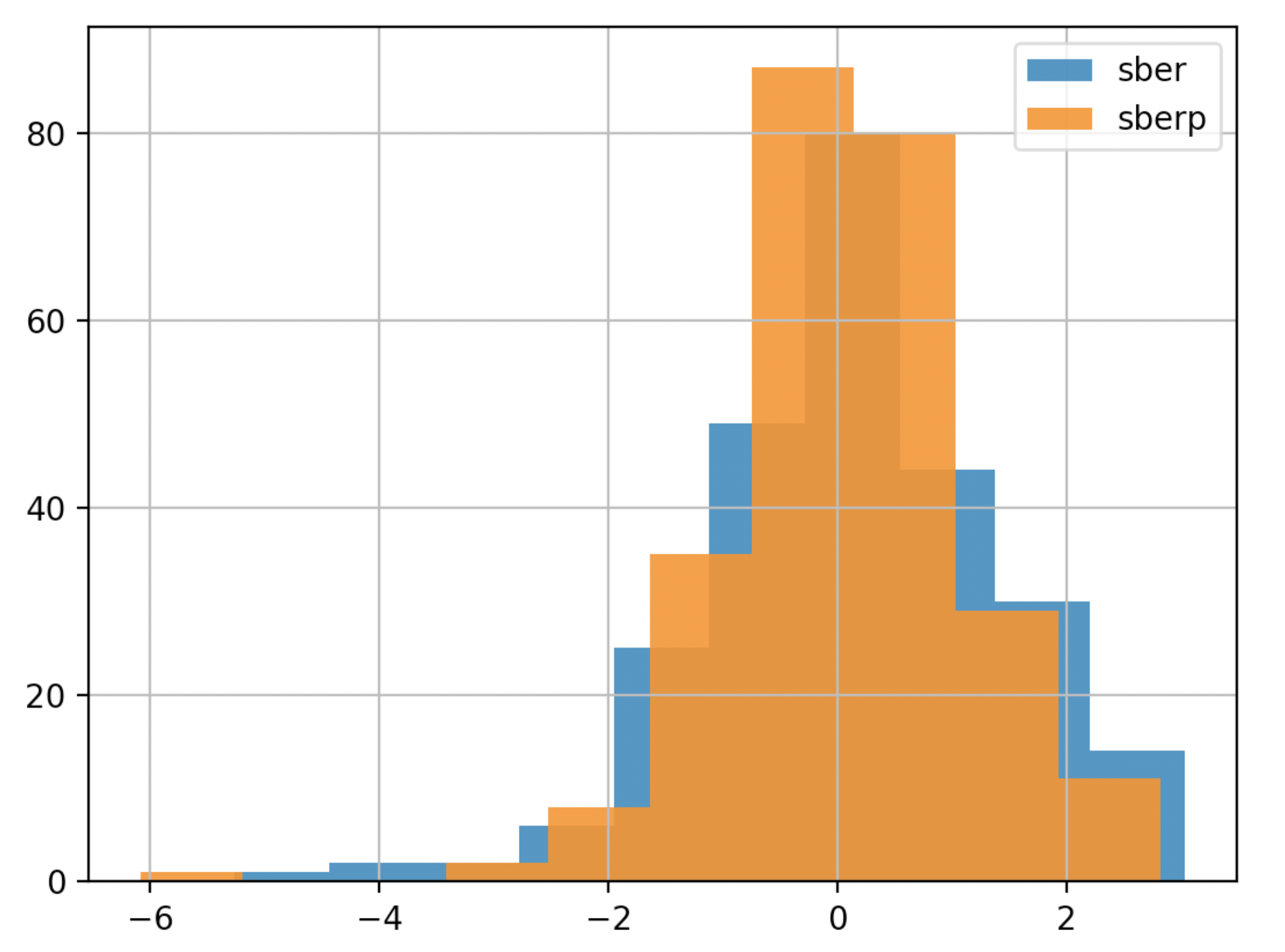
Análise de receita acumulada
Agora derivamos a variação percentual no valor das ações.Para fazer isso, insira a coluna com a receita acumulada.df['Cumulative Return'] = (1+ df['returns']).cumprod()
df2['Cumulative Return'] = (1+ df2['returns']).cumprod()
print(df)
print(df2)
df['Cumulative Return'].plot(label='sber')
df2['Cumulative Return'].plot(label='sberp')
plt.legend()
plt.show()
 Nos gráficos, podemos ver os intervalos de tempo em que uma das ações é subestimada ou reavaliada em relação à outra. Nas circunstâncias atuais (ceteris paribus, observe), isso nos ajudará a escolher uma ação para obter a média quando a capitalização do Sberbank cair.
Nos gráficos, podemos ver os intervalos de tempo em que uma das ações é subestimada ou reavaliada em relação à outra. Nas circunstâncias atuais (ceteris paribus, observe), isso nos ajudará a escolher uma ação para obter a média quando a capitalização do Sberbank cair.